池调度的实现 需要:
知道总进程/线程数,
增加任务的api
队列
网上的实现c++ : https://zhuanlan.zhihu.com/p/95819747
不知道什么情况,客户端?
队列的一种实现
OpenMP 动态线程池调度 不知道 #pragma omp parallel for num_threads(ndata) schedule(dynamic)行不行
这个动态调度,和openmp的线程池的概念,让我感觉应该是有线程动态调度池的概念的,因为只要有个for子句加任务的api。但是for指令在进行并行执行之前,就需要”静态“的知道任务该如何划分。
for和sections指令的”缺陷“:无法根据运行时的环境动态的进行任务划分,必须是预先能知道的任务划分的情况。
所以OpenMP3.0提供task指令,主要适用于不规则的循环迭代和递归的函数调用。OpenMP遇到了task之后,就会使用当前的线程或者延迟一会后使用其他的线程来执行task定义的任务。
1 2 3 4 5 6 7 8 9 10 11 #pragma omp parallel num_threads(2) { #pragma omp single { for(int i = 0;i < N; i=i+a[i]) { #pragma omp task task(a[i]); } } }
另一个例子,DoSomething(),导致p.n可能会增加。taskwait是为了防止某个task导致p.n增加了,但是for循环已经结束的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #pragma omp single { i = 0; while (i < p.n) { for (; i < p.n; ++i) { #pragma omp task DoSomething(p, i); } #pragma omp taskwait #pragma omp flush } }
对于问题的修改(还没测试)
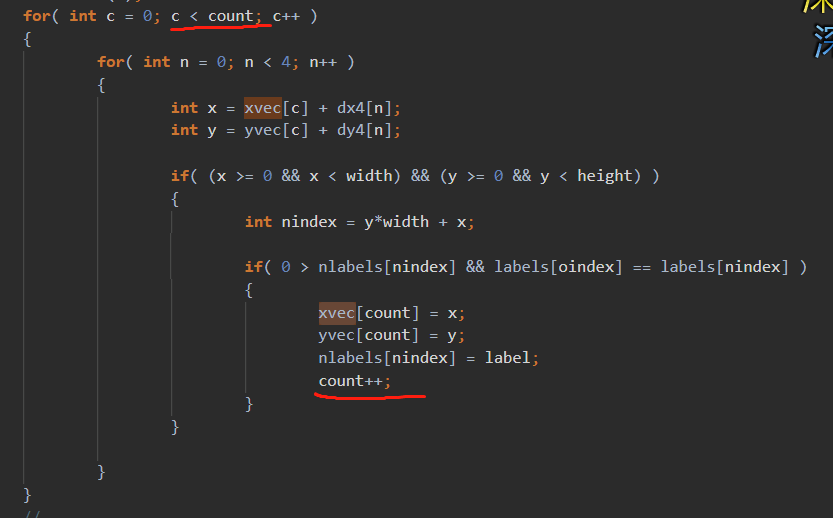
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 int count(1); #pragma omp parallel num_threads(64) { #pragma omp single { int c = 0; while(c < count) { for( ; c < count; c++ ) { #pragma omp task{ for( int n = 0; n < 4; n++ ) { int x = xvec[c] + dx4[n]; int y = yvec[c] + dy4[n]; if( (x >= 0 && x < width) && (y >= 0 && y < height) ) { int nindex = y*width + x; if( 0 > nlabels[nindex] && labels[oindex] == labels[nindex] ) { xvec[count] = x; yvec[count] = y; nlabels[nindex] = label; count++; } } } } } #pragma omp taskwait #pragma omp flush } } }
但是中间的if判断以及内部入队列,需要原子操作(xvec写入x时,别的线程count++了)。这就属于串行BFS的局限性了,导致并行不起来。
MPI 动态进程池调度 python的多进程里有动态进程管理
池调度的存在意义 我感觉,意义在于对于完全不相关的,或者没有顺序关系的任务,可以用池调度来并行。
C++与OpenMP配合的for子句最简线程池 实现每个线程执行完全不同的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <iostream> #include <functional> #include <vector> using namespace std; void fun (int a, int b) { cout<< "fun exec :"<< a << '+' << b << '=' << a + b <<endl; } class C{ private: float m_c = 2.0f; public: void mp( float d) { cout<<"c::mp exec :"<< m_c << 'x' << d << '=' << m_c * d <<endl; } }; int main(int argc, char * argv[]) { const int task_groups = 5; C c [task_groups]; vector<function<void (void) > > tasks; for (int i=0;i<task_groups;++i) { tasks.push_back(bind( fun , 10, i * 10 ) ); tasks.push_back(bind( &C::mp , &c[i], i*2.0f ) ); tasks.push_back(bind( [=] (void) {cout << "lambada :" <<i << endl; } ) ); } size_t sz = tasks.size(); #pragma omp parallel for for (size_t i=0;i<sz;++i) { tasks[i](); } return 0; } 输出: fun exec :10+0=10 c::mp exec :2x0=0 lambada :0 fun exec :10+10=20 c::mp exec :2x2=4 lambada :1 fun exec :10+20=30 c::mp exec :2x4=8 lambada :2 fun exec :10+30=40 c::mp exec :2x6=12 lambada :3 fun exec :10+40=50 c::mp exec :2x8=16 lambada :4
当然可以根据 num_threads 和 omp_get_thread_num()实现不同线程执行完全不同类型任务
1 2 3 4 5 6 7 8 9 10 11 #pragma omp parallel num_threads(2) { int i = omp_get_thread_num(); if (i == 0){ do_long(data1, sub_threads); } if (i == 1 || omp_get_num_threads() != 2){ do_long(data2, sub_threads); } }
也可以来实现二分线程池,来执行两个任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void do_long(int threads) { #pragma omp parallel for num_threads(threads) for(...) { // do proccessing } } int main(){ omp_set_nested(1); int threads = 8; int sub_threads = (threads + 1) / 2; #pragma omp parallel num_threads(2) { int i = omp_get_thread_num(); if (i == 0){ do_long(data1, sub_threads); } if (i == 1 || omp_get_num_threads() != 2){ do_long(data2, sub_threads); } } return 0; }
需要进一步的研究学习 openmp 对不同的子句的关系种类没弄清。
遇到的问题 暂无
开题缘由、总结、反思、吐槽~~ 对于for循环次数增加的情况,这么处理呢。
OpenMP由于是fork/join结构,fork的线程数可以一开始设置,但是for循环任务总数是一开始固定的吗?还是可以中途增加,
参考文献 https://www.it1352.com/359097.html
https://blog.csdn.net/gengshenghong/article/details/7004594