int main() { const float PI = 3.1415927; const int N = 150; const float h = 2 * PI / N; float x[N] = { 0.0 }; float u[N] = { 0.0 }; float result_parallel[N] = { 0.0 }; for (int i = 0; i < N; ++i) { x[i] = 2 * PI*i / N; u[i] = sinf(x[i]); } ddParallel(result_parallel, u, N, h); }
Kernel Launching
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
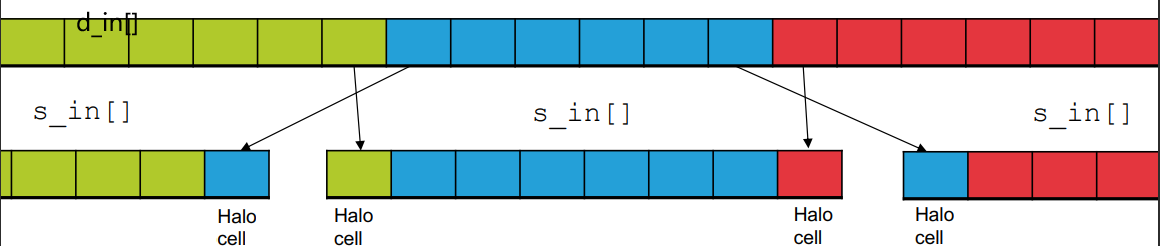
#define TPB 64 #define RAD 1 // radius of the stencil … void ddParallel(float *out, const float *in, int n, float h) { float *d_in = 0, *d_out = 0; cudaMalloc(&d_in, n * sizeof(float)); cudaMalloc(&d_out, n * sizeof(float)); cudaMemcpy(d_in, in, n * sizeof(float), cudaMemcpyHostToDevice);
// Set shared memory size in bytes const size_t smemSize = (TPB + 2 * RAD) * sizeof(float); ddKernel<<<(n + TPB - 1)/TPB, TPB, smemSize>>>(d_out, d_in, n, h); cudaMemcpy(out, d_out, n * sizeof(float), cudaMemcpyDeviceToHost); cudaFree(d_in); cudaFree(d_out); }
Kernel Definition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
__global__ void ddKernel(float *d_out, const float *d_in, int size, float h) { const int i = threadIdx.x + blockDim.x * blockIdx.x; if (i >= size) return; const int s_idx = threadIdx.x + RAD; extern __shared__ float s_in[];