Cuda Program Basic
CUDA编程水平高低的不同,会导致几十上百倍的性能差距。但是这篇将聚焦于CUDA的编程语法,编译与运行。
编程语法
函数前缀
与函数调用设备有关
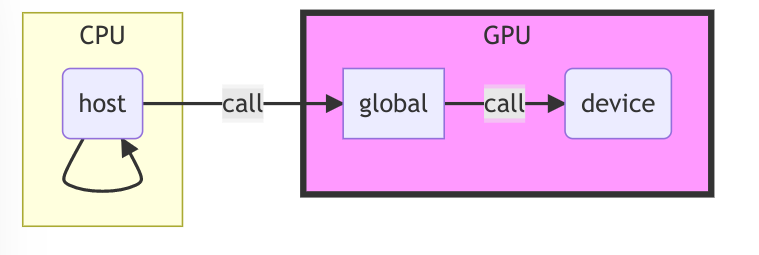
| 函数前缀名称 | 作用 | 目的 |
|---|---|---|
| global | 指定函数是CPU上调用,GPU上执行 | GPU设置规模参数<<<1,12>>> |
| device | 指定函数是GPU上调用,GPU上执行 | GPU内执行函数 |
| host | 指定函数是CPU上调用,CPU上执行(最正常的函数,平常就省略不写) | CPU内执行函数 |
- 如果一个函数不加修饰,默认他是
_device_函数,正如上面的 main 一样。 - functions that are decorated with both
__host__and__device__labels will be compiled to runon both, the host and the device.
变量修饰符
| 变量修饰符 | 作用 |
|---|---|
| device | 数据存放在显存中,所有的线程都可以访问,而且CPU也可以通过运行时库访问 |
| shared | 数据存放在共享存储器在,只有在所在的块内的线程可以访问,其它块内的线程不能访问 |
| constant | 数据存放在常量存储器中,可以被所有的线程访问,也可以被CPU通过运行时库访问 |
| Texture | 纹理内存(Texture Memory)也是一种只读内存。 |
| / | 没有限定符,那表示它存放在寄存器或者本地存储器中,在寄存器中的数据只归线程所有,其它线程不可见。 |
SMEM 静态与动态声明
1 | // array with a fixed size |
动态的s_in大小,在kernel的第三个参数指定smemSize字节数
1 | int smemSize = (TPB + 2)*sizeof(float); |
配置运算符


执行配置运算符 <<< >>>,用来传递内核函数的执行参数。执行配置有四个参数,
第一个参数声明网格的大小,
第二个参数声明块的大小,
第三个参数声明动态分配的共享存储器大小,默认为 0,
最后一个参数声明执行的流,默认为 0.
1 | add<<<grid,block>>>(a,b); |
stream

CUDA内置变量
| 变量 | 意义 |
|---|---|
| gridDim | gridDim 是一个包含三个元素 x,y,z 的结构体,分别表示网格在x,y,z 三个方向上的尺寸(一般只有2维度) |
| blockDim | blockDim 也是一个包含三个元素 x,y,z 的结构体,分别表示块在x,y,z 三个方向上的尺寸 |
| blockIdx | blockIdx 也是一个包含三个元素 x,y,z 的结构体,分别表示当前线程块在网格中 x,y,z 三个方向上的索引 |
| threadIdx | 是一个包含三个元素 x,y,z 的结构体,分别表示当前线程在其所在块中 x,y,z 三个方向上的索引 |
| warpSize | 在计算能力为 1.0 的设备中,这个值是24,在 1.0 以上的设备中,这个值是 32 |
三维的举例
1 | __global__ void kernel() { |
二维的例子,最后一个维度都是 0, 我们使用结果的时候不使用 z 维度即可
1 | __global__ void kernel() { |
常用函数
调用 GPU 的函数声明和定义不要分离,写在同一个文件里。分开(如:CUDA_SEPARABLE_COMPILATION)可能影响内联导致性能损失。
访存
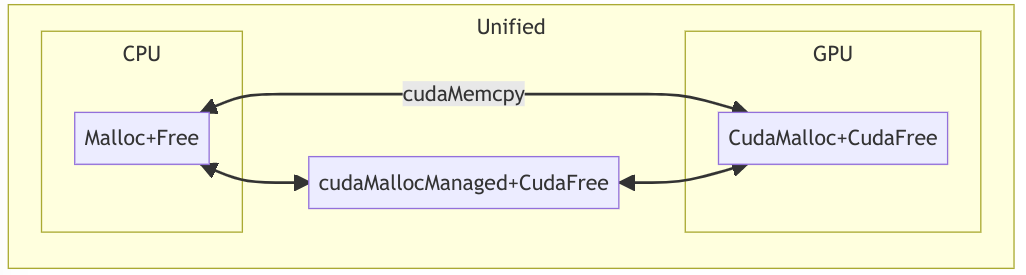
1 | __host____device__cudaError_t cudaMalloc ( void** devPtr, size_t size ) |
- where kind specifies the direction of the copy, and must be one of cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice, or cudaMemcpyDefault.
- Passing cudaMemcpyDefault is recommended, in which case the type of transfer is inferred from the pointer values. However, cudaMemcpyDefault is only allowed on systems that support
unified virtual addressing. - Calling
cudaMemcpy()with dst and src pointers that do not match the direction of the copy results in an undefined behavior.
cudaMemcpy可以自动实现同步工作,可以省去cudaDeviceSynchronize。
可以通过 cudaMallocManaged(&a, sizeof(int) * 12)申请在 Host 和 Device 上都直接使用的Unified Memory。性能多数情况会损失。
同步
1 | __host____device__cudaError_t cudaDeviceSynchronize ( void ) |
Stream
CUDA enables developers to define independent streams of commands, where it is assumed that commands in different streams do not depend on each other.
字符打印输出
很明显CPU和GPU打印是异步的,需要同步。
而且cuda暂时不支持cout等流输出语句。
Debug打印
cudaError_t是不能理解的输出。 cuda samples 里面提供了 helper_cuda.h 头文件解决问题。 Debug 的时候也可以直接把 gridDim 改成 1, 更方便
1 | # CMakeLists.txt |
时间统计打印
1 | cudaEvent_t begin, end; |
函数指针和lambda算子
1 | template <class Func> |
1 | // lambda算子 |
1 | // lambda算子例子2 |
cuda 容器的实现——thrust
STL 容器 cuda 并没有很好的适配和实现,CUDA对应的叫做thrust 库被称为: Template library for CUDA
ref1 and ref2
1 | thrust::host_vector<float> x_host(n); |
全局变量传递
GPU计算的全局变量 sum最后传递到CPU的 result里
1 | __device__ float sum = 0; |
常见原子操作
1 | atomicAdd (dst, src) |
他们都有返回值,返回违背更改前的数值。
也可以通过 atomicCAS自定义原子操作。但是前面的原子操作有特殊设计的,会基于blockDim和gridDim,并行各块串行执行然后规约。
单卡多GPU的实现
1 | int gpu_numbers = cudaGetDeviceCount(); |
指定某卡运行程序
通过环境变量实现
1 | export CUDA_VISIBLE_DEVICES=1 |
GPU 编译器
相对于CPU编译器简单一些
可能要手动循环展开, 消除分支,GPU分支预测几乎没有
#pragma unroll 一句即可展开
nvcc优化选项
1 | target_compile_options(${exe} PUBLIC $<$<COMPILE_LANGUAGE:CUDA>: |
fast math
–-use_fast_math对于频繁的数学函数:三角函数、快速傅立叶变换、幂次、根号有5~15%的效率提升。
ECC
ECC(error correcting code, 错误检查和纠正)能够提高数据的正确性,随之而来的是可用内存的减少和性能上的损失。对于Tesla系列伺服器该功能默认开启。
通过命令 nvidia-smi -i n可查看第n个个显卡的简要信息(详细信息可通过 nvidia-smi -q -i 0获取),其中有一项是volatile Uncorr。
通过 nvidia-smi -i n -e 0/1 可关闭(0)/开启(1)第n号GPU的ECC模式。
通过实践,关闭ECC程序的性能能得到13%~15%的提升。
测试运行
现有cuda 是兼容 C++17 语法的,可以减少移植工作量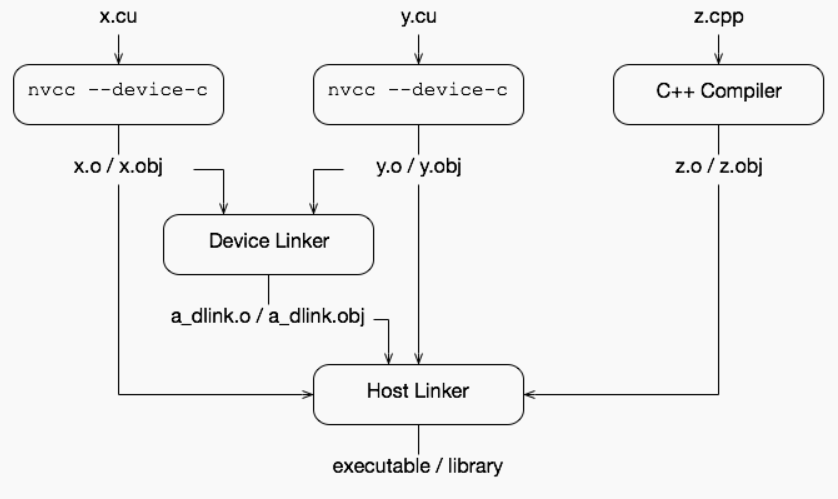
1 | export CUDA_ROOT=/usr/local/cuda/bin |
发现版本太老了不支持更新的gcc,自己安装最新cuda
CUDA实例
CUDA项目
https://github.com/Kirrito-k423/StencilAcc
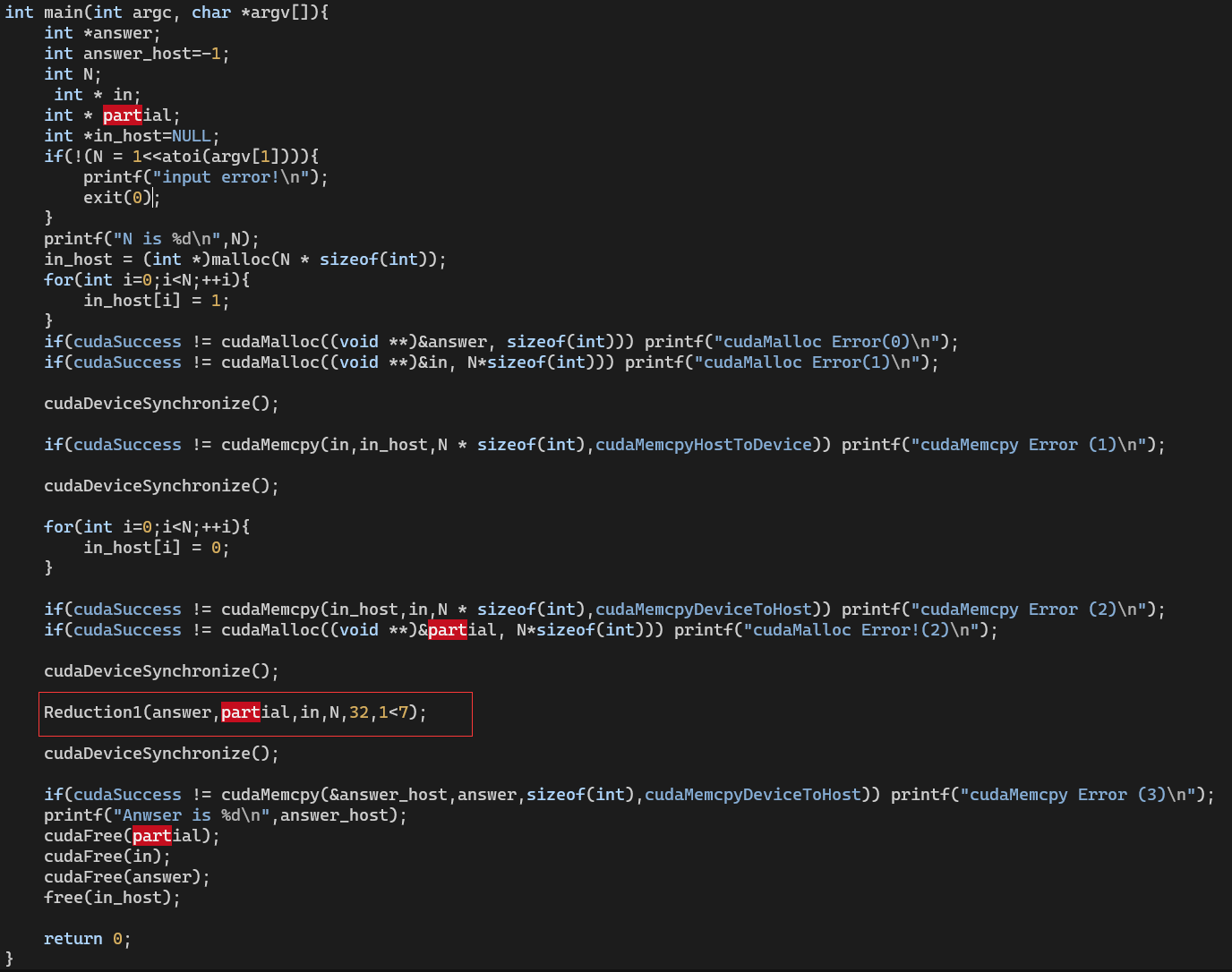
杂项
GPU线程的创建与调度
shared memory In Stencil Computing
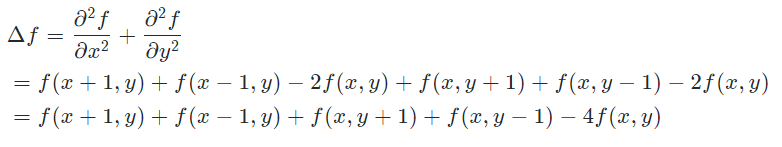
问题
- thread 和硬件的关系?
- shared memory位置和cache的关系(根据GA100,L1 data cache=shared memory)
- 联合访问搬数据,没有cache line的概念吗?
- shared memory VS streaming Multiprocessor
参考文献
实例:手写 CUDA 算子,让 Pytorch 提速 20 倍
https://docs.nvidia.com/cuda/cuda-c-programming-guide/#function-parameters
例子代码:
https://github.com/chivier/cutests
https://chivier.github.io/2022/02/20/2022/2202-CudaProgramming/
https://comzyh.com/blog/archives/967/
https://itlanyan.com/cuda-enable-disable-ecc/
[^1]: 并行计算课程-CUDA 密码pa22