Overview of Compute system
Our technology,our machines,is part of our humanity.We created them to extend ourself,and that is what is unique about human beings. - Ray Kurzweil”
Computation in brain and machines
Brain
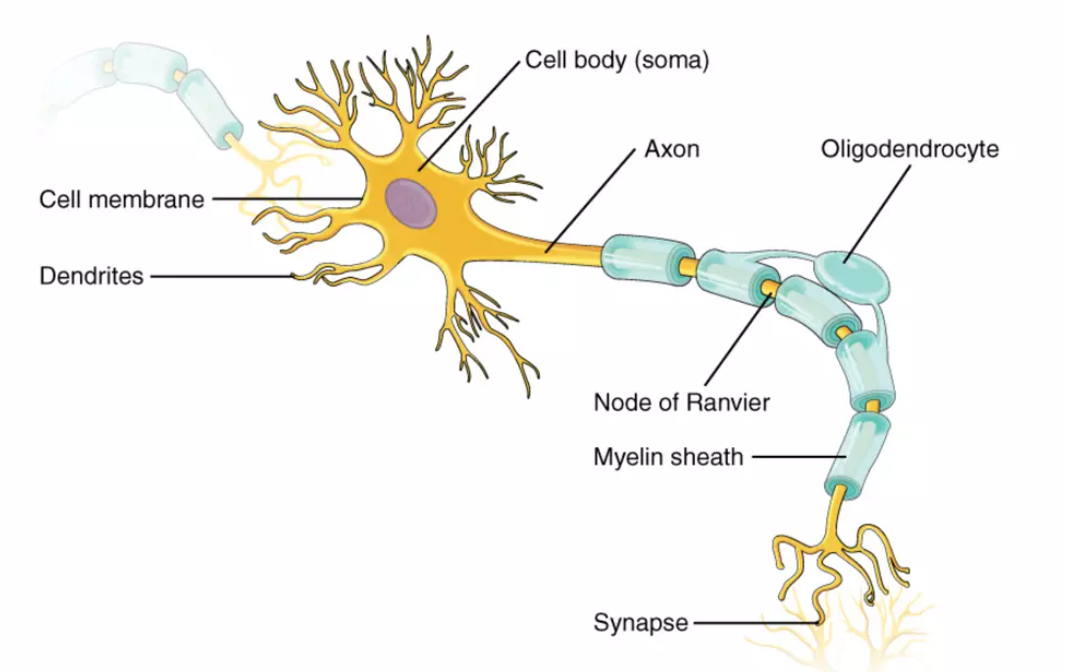 { width=”30%”;align=left }
{ width=”30%”;align=left }
- 1.3kg, 占 2% 的人体总总量[^13]
- $10^{11}$ 神经元(neuron), $10^{14}$ 突触连接(synapses)
- 操作频率 异步平均
10Hz, 不超过100Hz

Machine
- M1 Ultra的晶体管数量达到了1140亿个,等于$1.14×10^{11}$
- Kunpeng 920 是 200亿,等于$2×10^{10}$
- 操作频率 同步平均
3GHz
计算机系统
描述和评价一个计算机系统
计算机系统的抽象层次
ISA 是软硬件设计的分界线
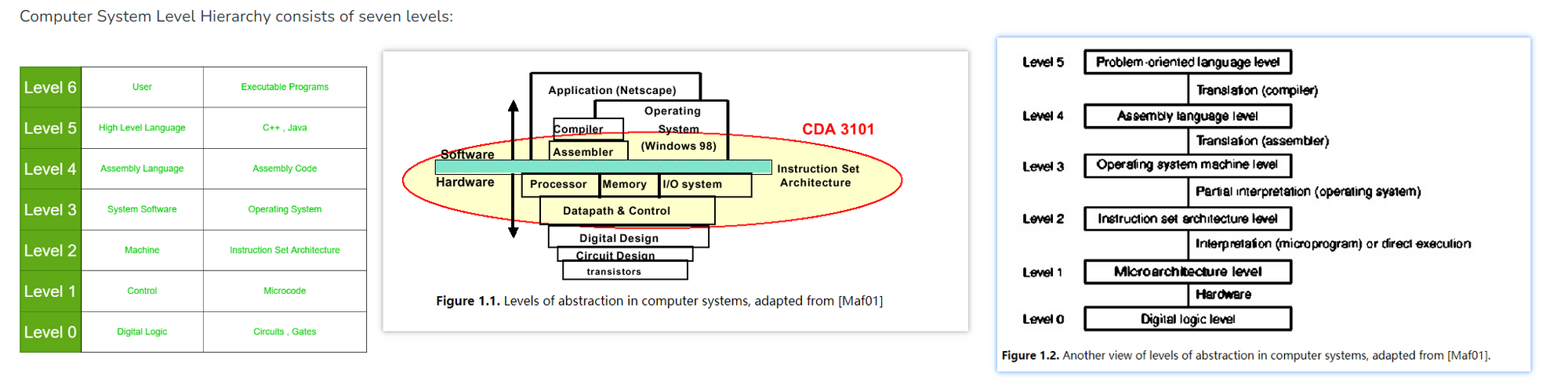
计算机系统的一般/通用设计
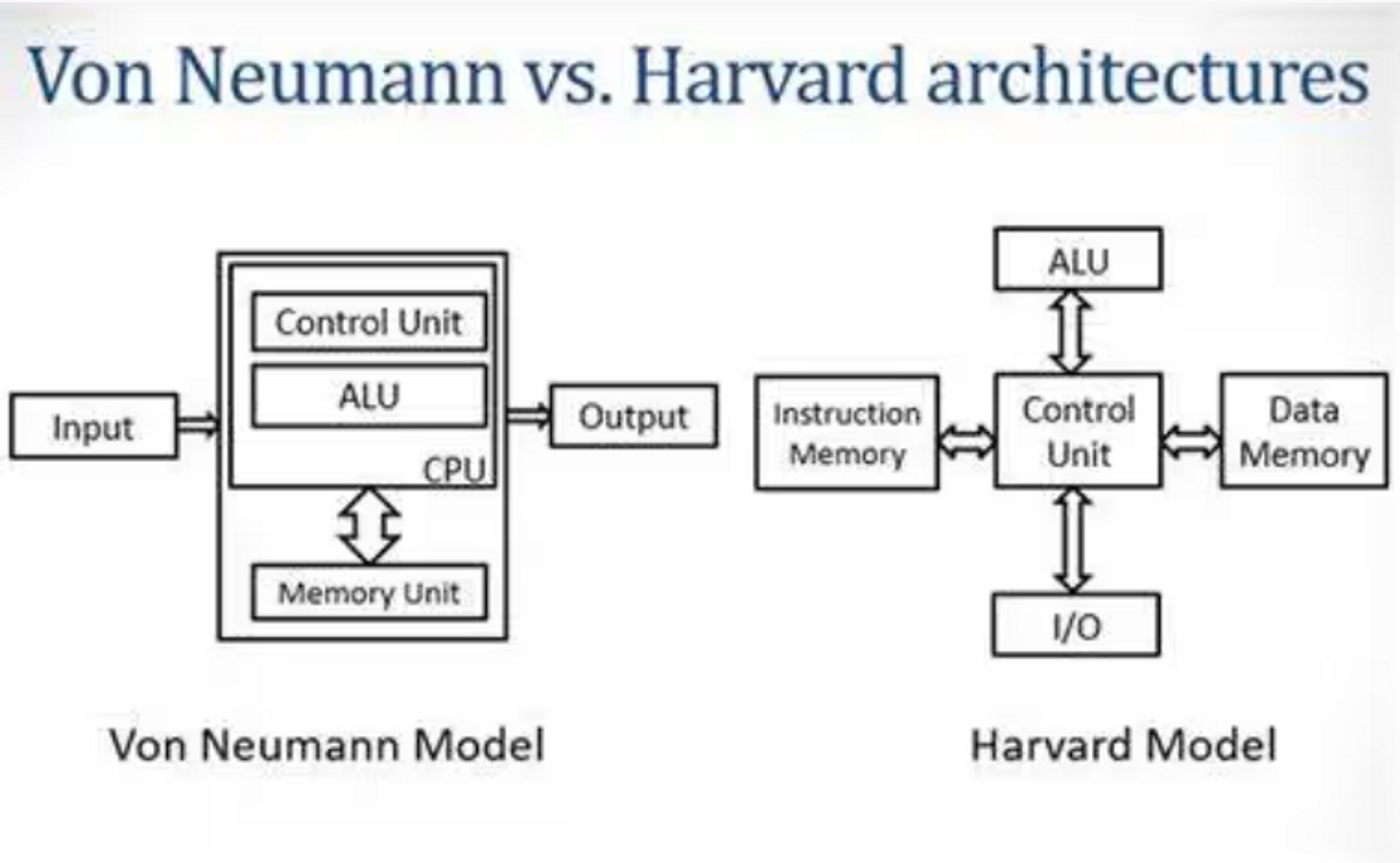 { width=”50%” }
{ width=”50%” }产业的需求
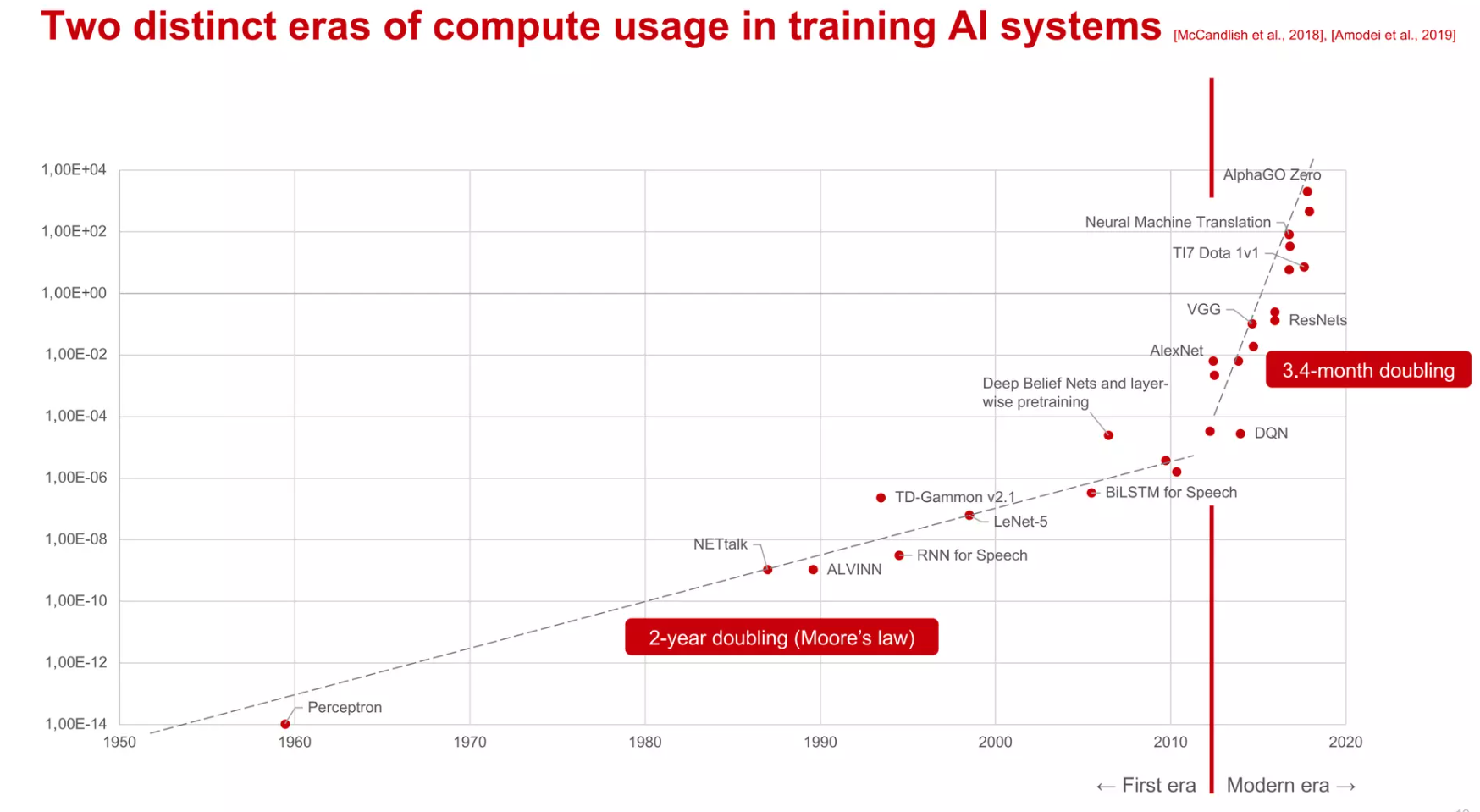 [^13]
[^13]发展趋势
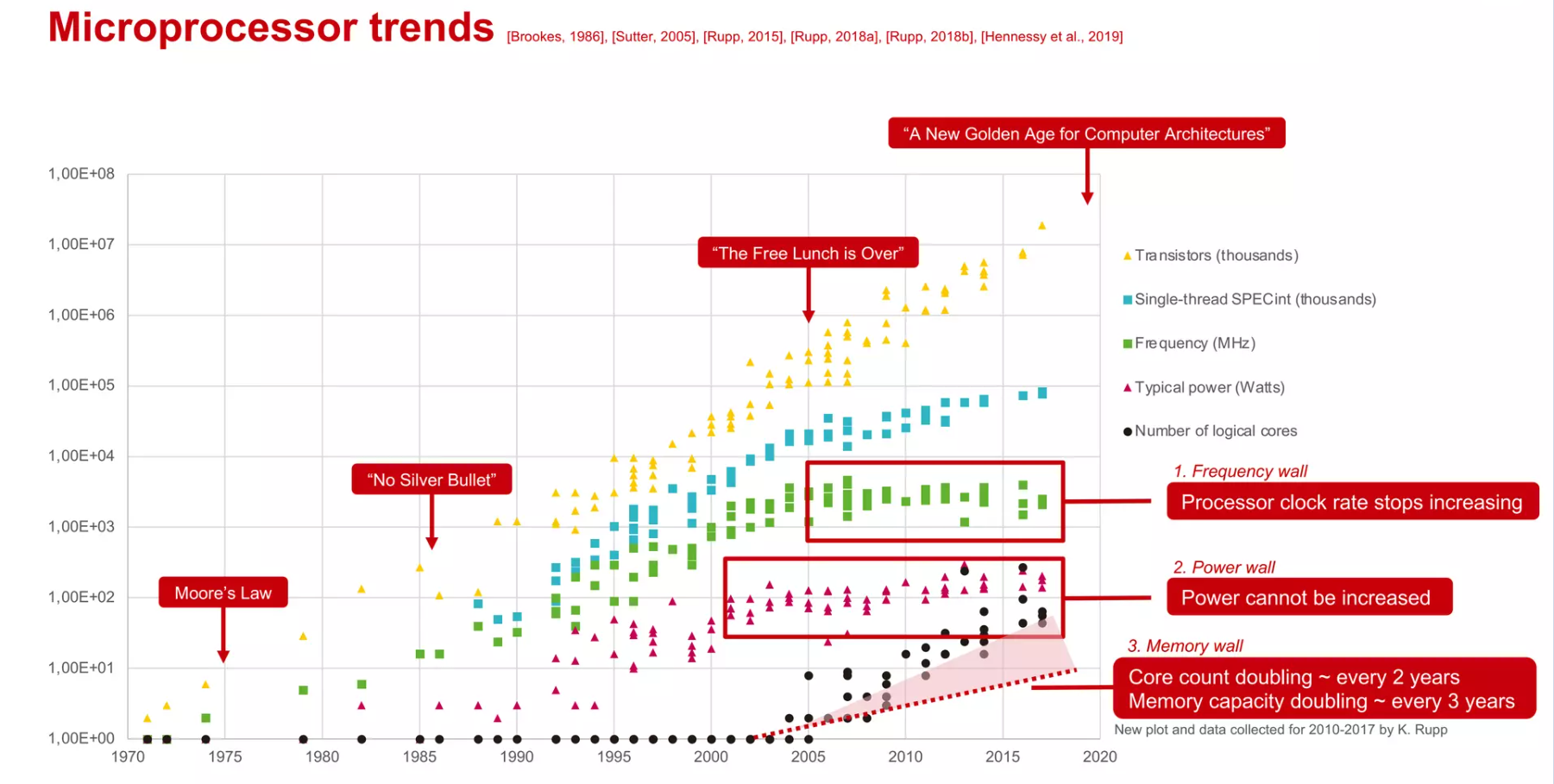
- No Silver Bullet — 这句话来自弗雷德·布鲁克斯的一篇论文,指出软件工程没有万能的解决方案(即“银弹”)能迅速和轻易地提升生产力和质量。
- The Free Lunch is Over — 这是赫伯特·萨特尔指出的一个概念,意味着仅依靠硬件的性能提升来推动软件性能的时代已经结束,软件开发者现在需要更多关注并行计算和代码优化来提升性能。
- A New Golden Age for Computer Architecures — 由于摩尔定律和丹纳德缩放结束所带来的计算机架构的新机遇,特定领域的语言和架构、开放指令集以及改进的安全性将引领这个新时代的到来。
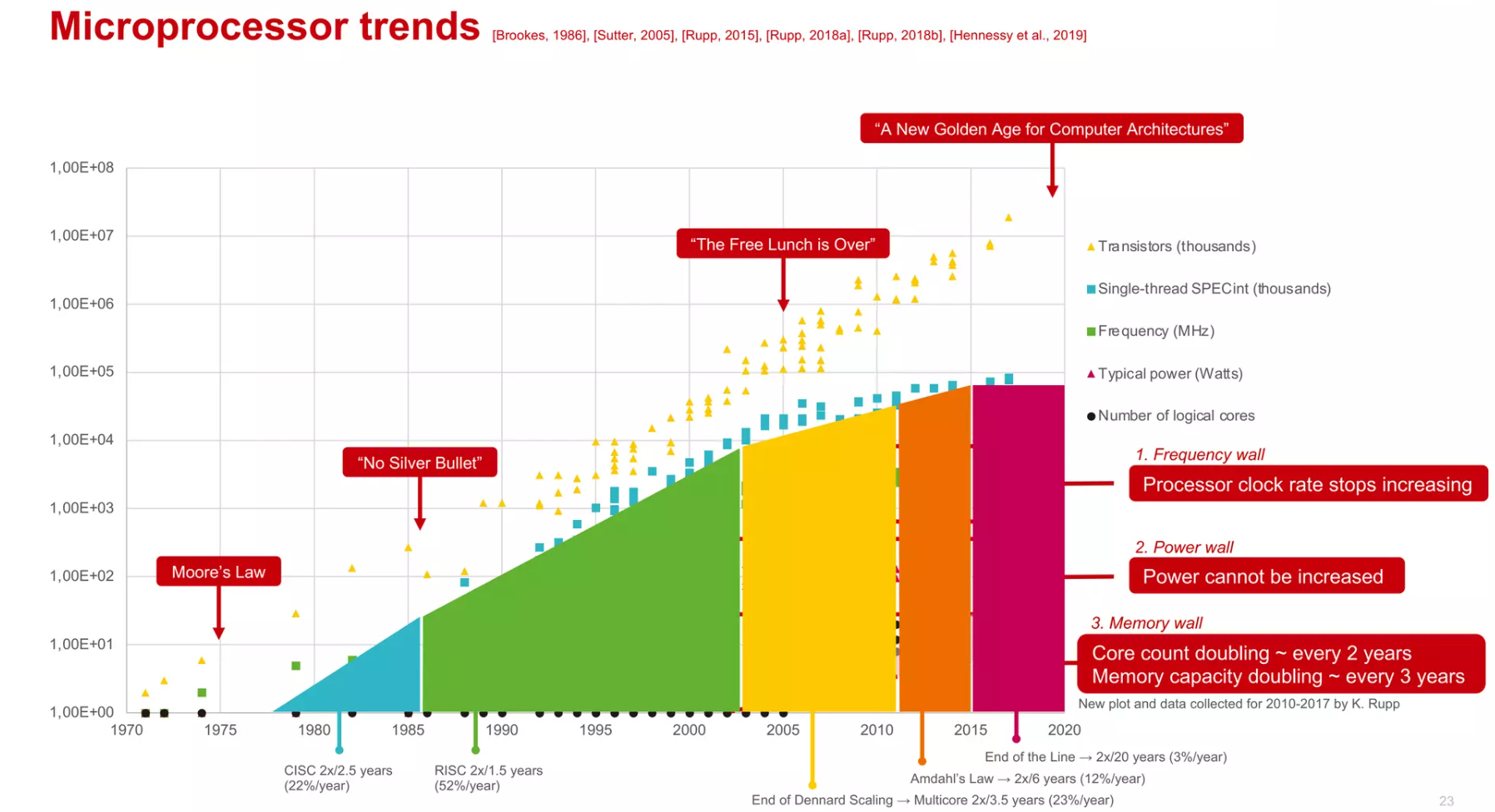
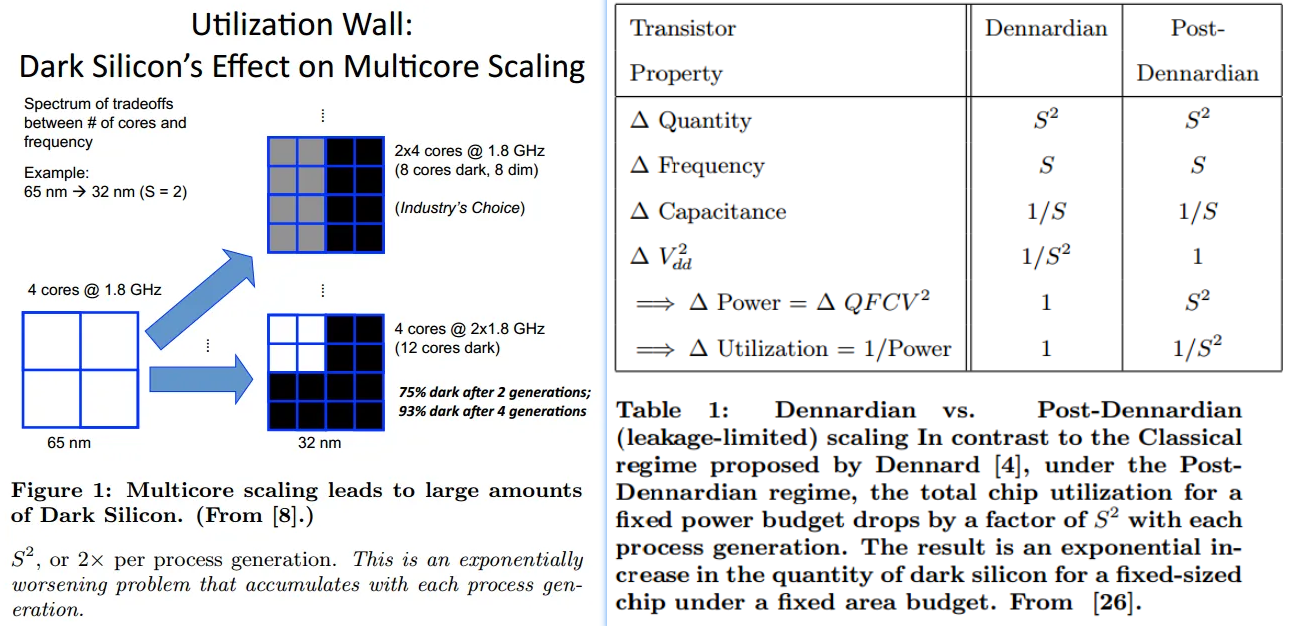
摩尔定律的放缓和多核收益的衰弱
- 摩尔定律由Gordon Moore博士在1965年提出:“集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍,性能也提升一倍。时至今日,虽然晶体管的集成度还在提高,只是逐渐放缓,但是性能的提升却被物理规律所限制。一个处理器上的晶体管的数目越来越多,但是因为功耗和互连的限制,并不能直接提供很高的性能,即晶体管没有充分的利用起来。
- 丹纳德缩放(Dennard scaling),也称为动态缩放或者是电力、电压和尺寸的缩放,是1974年由罗伯特·丹纳德(Robert Dennard)和他的同事在IBM提出的。丹纳德缩放描述了一个观察到的现象:随着晶体管尺寸缩小,它们的功率密度保持不变。
- 解释:如果所有的尺寸维度都缩小一定比例,电压也降低相应的比例,那么频率可以增加而功耗保持不变。这意味着晶体管可以变得更小、更快且效率更高。
- 失效:然而,进入21世纪后,当晶体管尺寸缩小到接近原子层级时,丹纳德缩放原则不再适用,因为无法进一步降低电压而不影响晶体管的功能和可靠性。(也称为Post-Dennardian:随着工艺尺寸的缩小,chip的供电电压保持不变。)此外,量子效应和电力泄漏开始占主导地位,导致功率密度增加。因此,芯片设计者不得不寻找新的方法来继续提升计算性能,比如多核处理器(Interconnect也是问题)、异构计算和能效优化设计。
- Dark silicon,也叫“暗硅”。意思是说,由于功耗的限制,一个很高端的处理器,比如多核的,其实同一时刻只能有很少的一部分门电路能够工作,其余的大部分处于不工作的状态,这部分不工作的门电路,就叫做“暗硅”。
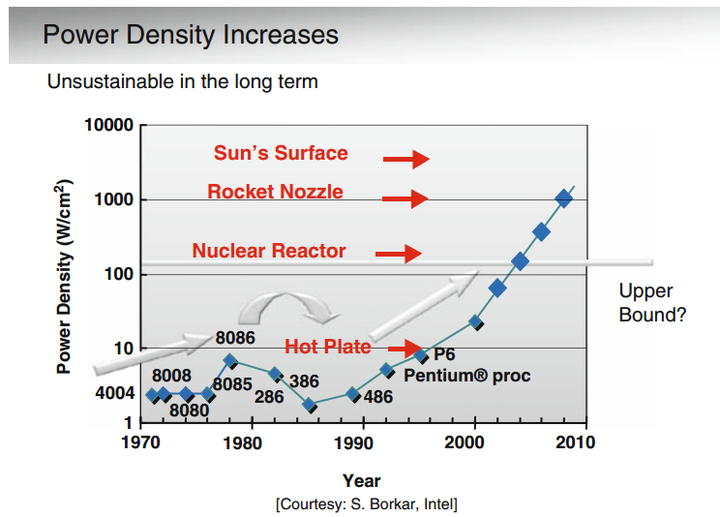 [^15]
[^15]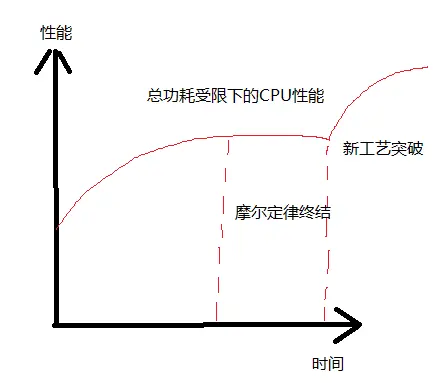
- 阿姆达尔定律(Amdahl’s Law, 1967年)在并行计算中用来预测使用多个处理器与单个处理器相比理论上的最大性能提升。
- 如果一个程序有一部分代码无法并行化(比如,10%的代码必须串行执行),那么即使在无限多的处理器的理想情况下,最大的性能提升也只能是10倍,因为那10%的代码决定了整个程序的最小执行时间。
- 在实际应用中,由于不是所有的任务都能完全并行化,阿姆达尔定律表明性能提升存在一个明显的上限。所以,即使技术不断进步,处理器核心数量翻倍,我们也不能期望性能提升与处理器核心数量增加成正比。这就是文本中所说的“性能预计每6年才能翻一倍,相当于每年12%的提升”的含义。这反映出即使硬件的发展速度很快,实际的应用性能提升仍然受限于代码的可并行化程度。
- 牧本定律由1987年牧村次夫提出,半导体产品的发展历程总是在“标准化”和“定制化”之间交替摆动,大概每十年摆动一次,揭示了半导体产品性能功耗和开发效率之间的平衡,这对于处理器来说,就是专用结构和通用结构之间的平衡—专用结构性能功耗优先,通用结构开发效率优先。
- 贝尔定律是由戈登贝尔在1972年提出的一个观察,即每隔10年,会出现新一代计算机(新编程平台、新网络连接、新用户接口、新使用方式),形成新的产业,贝尔定律指明了未来一个新的发展趋势,这将会是一个处理器需求再度爆发的时代,不同的领域、不同行业对芯片需求会有所不同,比如集成不同的传感器、不同的加速器等等。
异构计算和Domain-Specific Architectures
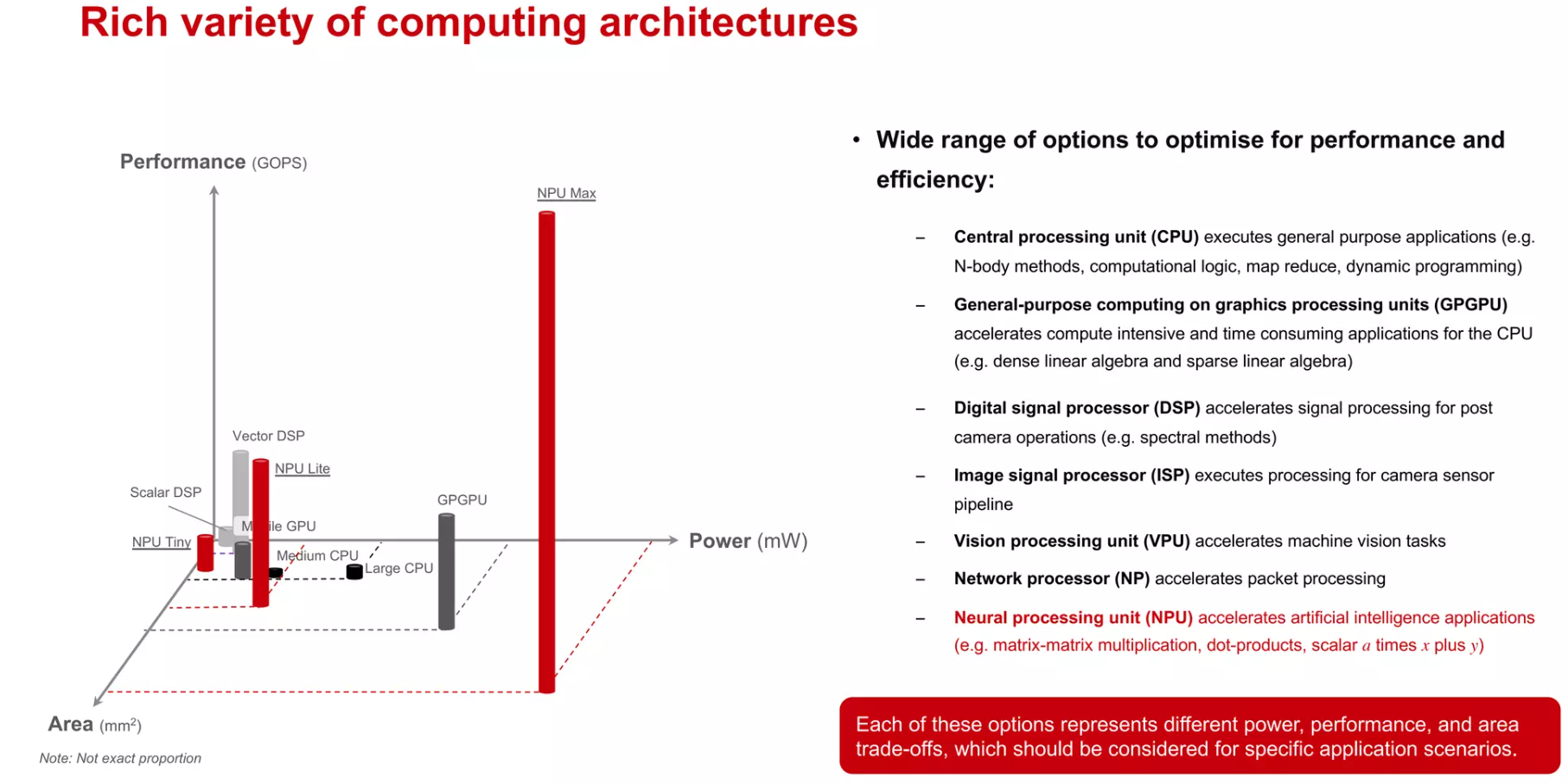
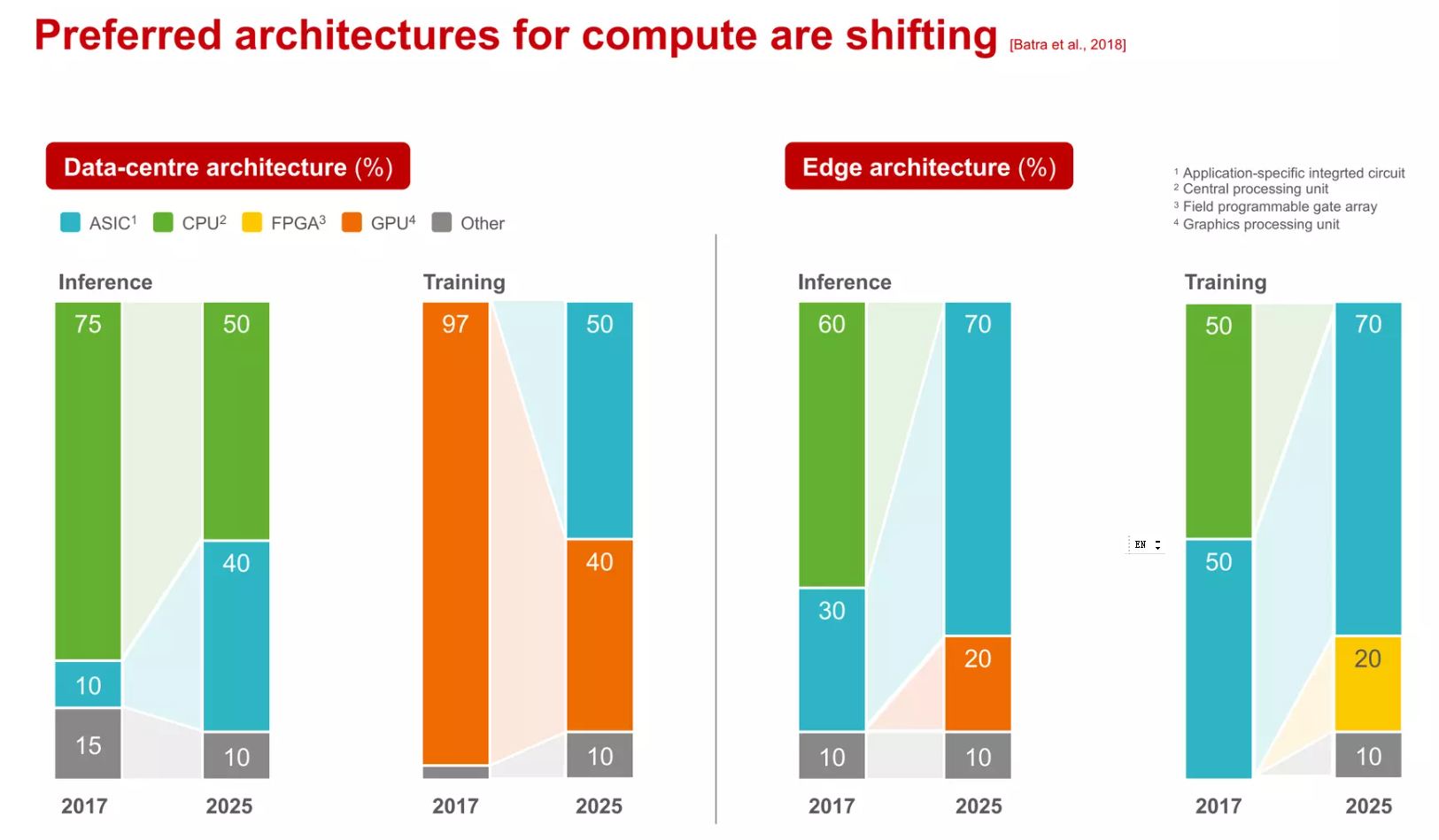
从寒武纪的“DIANNAO”到Google的TPU再到华为的达芬奇,AI芯片的设计呈现出百花齐放的场景。有单一针对卷积神经网络的ASIC加速器,有支持简单编程的通用型处理器;有的通过硬件可重构进行算法映射,有的通过VLIW指令支持高并发运算;有一个超大矩阵支持大规模AI运算,有通过众核进行任务切割运算;有的作为协处理器,有的可以独立运行。可以说计算机发展史中出现的各种架构在其中都有体现。
性能模型
Analytical model
- CPU
- Roofline模型
- ECM模型
- GPU
- Memory-level and Thread-level Parallelism Awareness[^7]
Mechanistic Performance Model
A mechanistic model has the advantage of directly** displaying the performance effects of individual, underlying mechanisms**, expressed in terms of program characteristics and machine parameters, such as Instruction-Level Parallelism (ILP), misprediction rates, processor width, and pipeline depth.(1) [^11]
{ .annotate }
- Our proposed mechanistic model, in contrast, is built up from internal processor structure and does not need detailed processor simulation to fit or infer the model; however, we do use detailed simulation to demonstrate the accuracy of the model after it has been constructed.[^11]
Detailed timing simulations
cycle-level simulation
- CPU: gem5
- GPU: GPUSim
RTL simulation
Others: machine learning performance model
Empirical and hybrid approaches typically lump together program characteristics and/or microarchitecture effects, often characterizing multiple effects with a single parameter.[^11]
性能关键指标 - 处理器峰值计算能力
| Arch | Product | SP Scalar/core | DP Scalar/core | SP SIMD/core | DP SIMD/core | Total SP/chip | Total DP/chip |
|---|---|---|---|---|---|---|---|
| ARMv8 | Kunpeng 920 (Internally: Hi1620) | 7.9Gflops[^8] | 7.9Gflops | 31.9 Gflops | 7.9 Gflops | 1536 Gflops(48 cores) | 384 Gflops |
| X86 | Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz | 972.8 Gflops (32 cores)[^9] | |||||
| GPU | Nvidia H100 | 354.1 Gflops (per SM) | 180.5 Gflops | 51 Tflops (144 SM)[^10] | 26 Tflops | ||
| GPU | Nvidia H100 + Tensor Cores | 756 Tflops (144 SM)[^10] | 51 Tflops |
1 TFLOPS is equivalent to 1,000 GFLOPS
芯片设计 成本与收益的tradeoff
工艺的限制是设计的当前理论上限。各种现实的成本考虑进一步限制了设计。
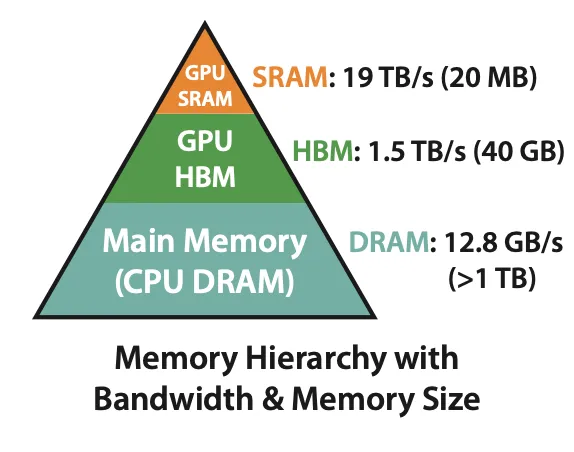
性能关键指标 - 访存与互联速度
建议研究 https://www.francisz.cn/2022/05/12/lmbench/
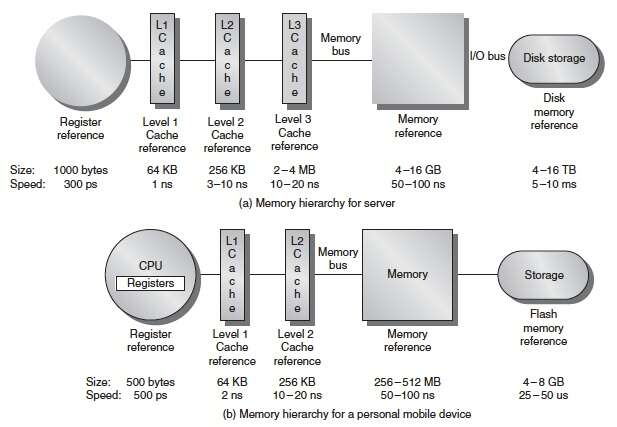
Memory hierarchy Latency / Size
| Type\Level | Register | L1 Cache | L2 Cache | LLC | DRAM (2666Mhz DDR4) | SSD | HHD | Ethernet Network |
|---|---|---|---|---|---|---|---|---|
| Latency(cycle) | 1 | 3 | 9-30 | 30-60 | 150-300 | 15k-30k | ||
| Latency(ns) | 0.3 | 1 | 3-10 | 10-20 | 50-100 | 5k-10k | 30ms=3*10^7 ns | |
| Bandwidth(GB/s) | 3000 | 80 | 28 | 25 | 21.3 * n | 0.5 | 0.2 | 0.1 |
| Size | 1KB | 64KB | 256KB | 2-4MB | 8-512GB | 8-16TB | 16TB | |
| Price | 19RMB/GB DDR4 | 250RMB/TB | 65-125RMB/TB | |||||
| Area | ||||||||
| Power |
 [^1]
[^1]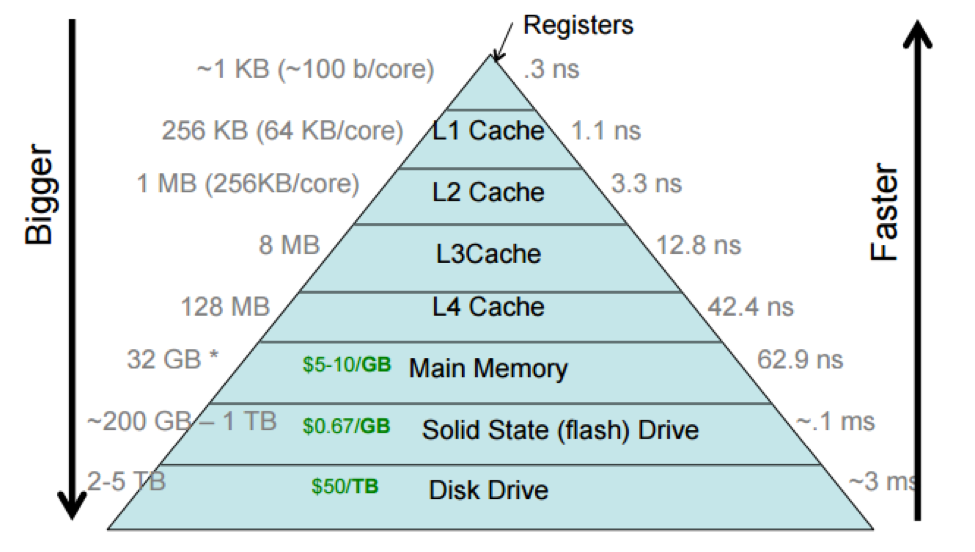 [^2]
[^2]
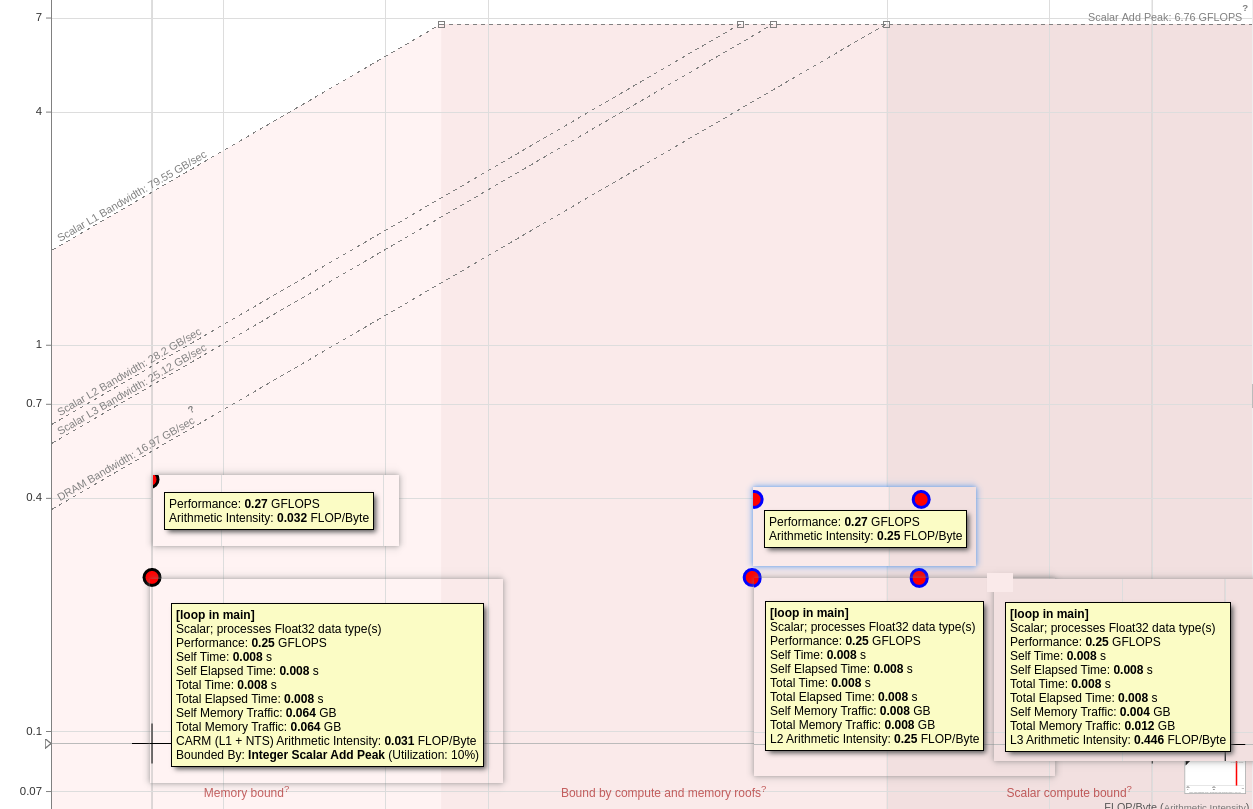
Address Translation Latency
- Utopia:Figure 4 shows the average PTW latency (in processor cycles) for Radix and ECH. We observe that Radix spends
137cycles and ECH86cycles, on average, to complete the PTW. - measure real PTW cost ???
- time breakdown of ALU, Address Translaton and Mem-access ???
20-40%of the instructions reference memory[^4]- compulsory miss rate is
1%or less, caches with more realistic miss rates of2-10%.
TLB
Measurement tools from code
PIM Latency
UPMEM:
- CPU2MRAM 256bytes ~150us
- 线程同步 ~45us
Interconnect Bandwidth
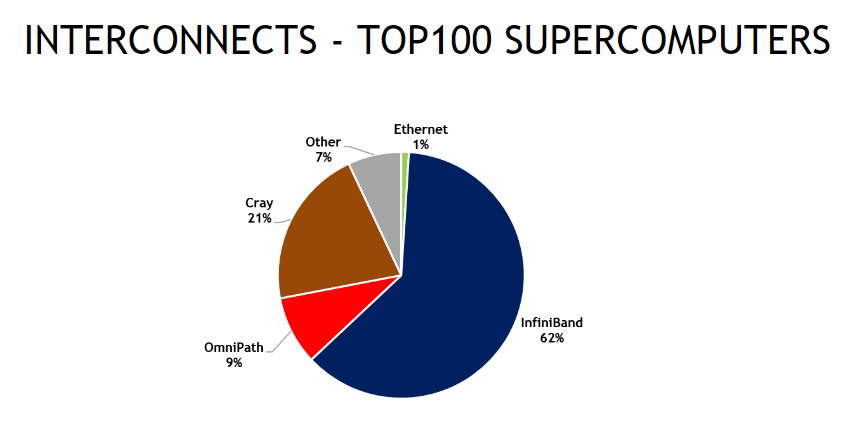 [^2]
[^2]Real SuperComputer Design
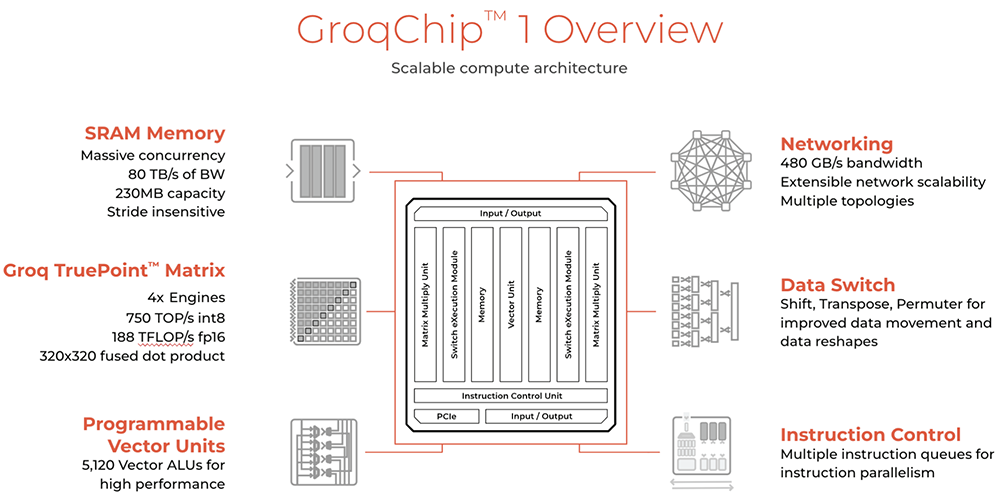
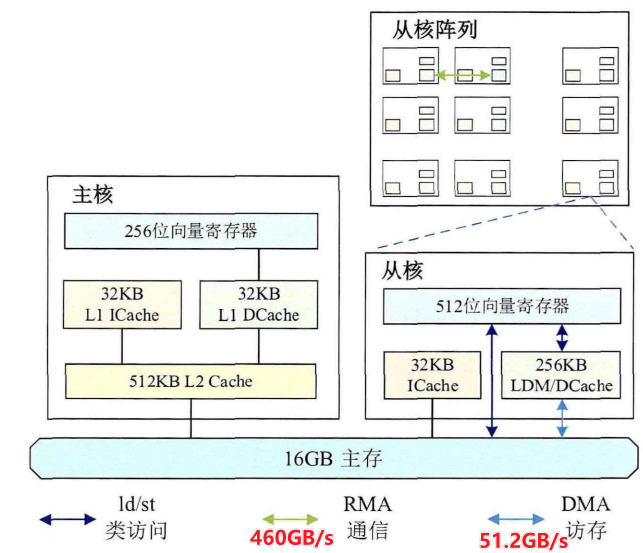
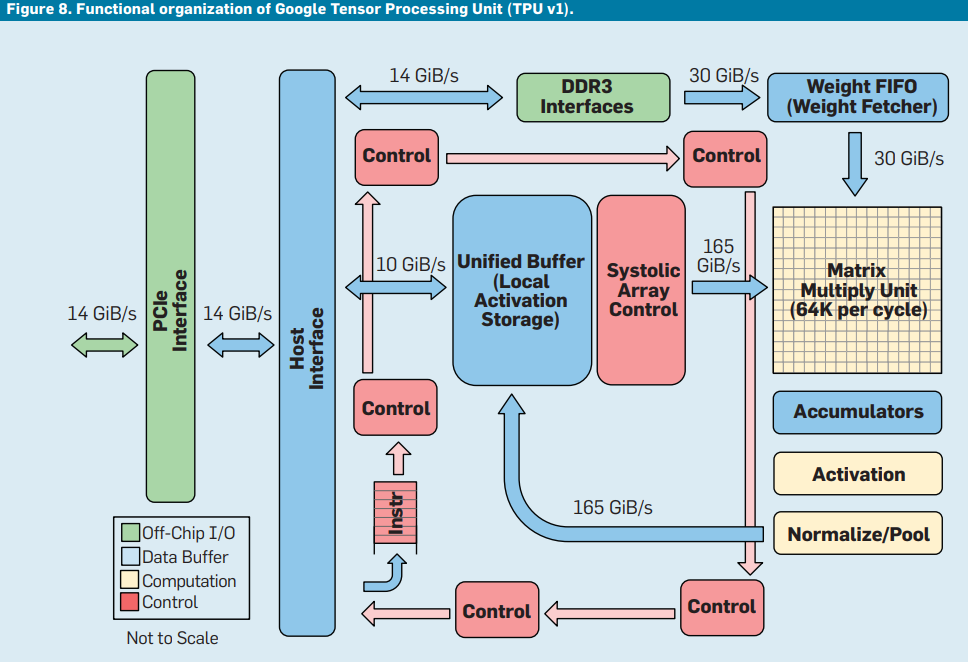
计算机领域的划分
计算机专业课程
计算机科学与技术专业的课程设置会因学校和国家的不同而有所差异,但通常包括以下核心课程:
- 编程基础:通常包括多门编程语言(如C/C++、Java、Python)的基础课程,教授编程概念、算法和数据结构等。
- 计算机体系结构:介绍计算机硬件和体系结构的基本原理,包括处理器、存储器、输入/输出设备等。
- 数据结构与算法:深入讲解各种常见数据结构(如链表、树、图)和算法(如排序、搜索、图算法),培养学生解决实际问题的能力。
- 操作系统:介绍操作系统的原理和设计,包括进程管理、内存管理、文件系统等内容。
- 数据库系统:学习数据库的基本原理和SQL语言,了解数据库的设计和管理。
- 网络与通信:介绍计算机网络的基本原理、协议和技术,包括网络体系结构、路由、传输控制协议(TCP)、因特网协议(IP)等。
- 软件工程:学习软件开发的方法和流程,包括需求分析、设计、编码、测试和维护等。
- 计算机安全:介绍计算机系统和网络的安全问题,包括密码学、网络安全、软件安全和信息安全管理等。
- 人工智能与机器学习:介绍人工智能和机器学习的基本概念和算法,包括神经网络、决策树、支持向量机等。
- 软件开发实践:实践性课程,学生通过实际项目开发,学习软件开发的实践技能和团队合作能力。
此外,还可能包括课程如计算理论、编译原理、图形学、嵌入式系统、分布式系统等,以及选修课程供学生根据个人兴趣和专业方向选择。
计算机产业的布局与计算机行业的分类
- 云计算:云计算是通过网络提供计算资源和服务的模式,包括基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。在云计算领域,主要的参与者包括云服务提供商(如亚马逊AWS、微软Azure、谷歌云等),它们通过数据中心提供灵活的计算和存储资源,为用户提供可扩展的计算能力和服务。
- 人工智能(AI):人工智能是计算机科学的一个分支,涉及模拟和实现人类智能的技术和方法。AI在计算机产业中扮演了重要角色,包括机器学习、深度学习、自然语言处理和计算机视觉等领域。大型科技公司如谷歌、微软、IBM等在AI领域投入了大量资源,并开发了各种AI相关的工具、框架和平台。
- 边缘计算:边缘计算是一种分布式计算模型,将数据处理和分析推向边缘设备。这个领域涉及边缘设备、传感器、物联网技术和边缘计算平台等。大型云服务提供商也在布局边缘计算,以支持边缘设备上的实时计算和决策。
- 物联网(IoT):物联网是指将日常物品连接到互联网,实现物品之间的通信和互操作。物联网涉及传感器、嵌入式系统、网络和云平台等技术。各大科技公司和设备制造商都在物联网领域进行布局,以实现智能家居、智能城市、工业自动化等应用。
- 数据中心:数据中心是集中存储、处理和管理大量数据的设施,为云计算和大数据应用提供支持。数据中心通常由大型云服务提供商和企业自建,它们需要高性能计算、存储和网络设备来处理大规模的数据和应用。
- 超级计算机:超级计算机是具有强大计算能力的大型计算机系统,用于解决复杂的科学、工程和商业问题。超级计算机通常由政府、研究机构和大型企业建设和使用,它们在气候模拟、基因组学、物理模拟等领域发挥着重要作用。
开题缘由、总结、反思、吐槽~~
秋招的时候发现,对计算机系统,课程,学科,行业的全局的掌握确实很缺乏。
为了能更清晰的学习,应该自顶向下的了解和计算机相关的全局的知识。
实践
如何测量计算机系统的如上数值
参考文献
[^1]: SC19: Parallel Transport Time-Dependent Density Functional Theory Calculations with Hybrid Functional on Summit
[^2]: What is InfiniBand Network and the Difference with Ethernet?
[^4]: Hitting the Memory Wall: Implications of the Obvious
[^5]: 深度了解 NVIDIA Grace Hopper 超级芯片架构
[^6]: Frontier Compute Nodes
[^7]: (ISCA09) An Analytical Model for a GPU Architecture with Memory-level and Thread-level Parallelism Awareness
[^8]: Kunpeng 920 (ARMv8) - Hardware-specific Support Alex Margolin UCX Hackathon, Dec. 2019
[^9]: Intel APP Metrics for Intel MicroProcessors
[^10]: NVIDIA H100 Tensor Core GPU
[^11]: (TOCS09) A Mechanistic Performance Model for Superscalar Out-of-Order Processors
[^13]: Da Vinci - A scaleable architecture for neural network computing (updated v4)
[^14]: Dark Silicon(暗硅)的起源与分析
Overview of Compute system