AI Training Optimization
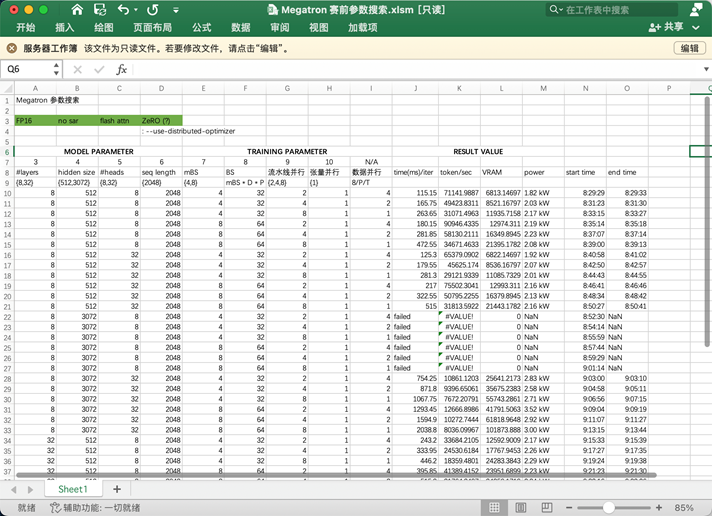
优化实例: ASC 源LLM训练
Different Training Frameworks
- LightSeq
- DeepSpeed
- ColossalAI
- Megatron
- GPT-neox
- HuggingFace
Different Hyperparameters
- Parallel Size
- Batchsize / Micro Batchsize
Miscellaneous Techniques
- ZeRO Redundancy Optimizer
- optimized kernel impl.
- Flash Attention
- Sparse Attention
- gradient accumulation
- communication warm-up
任务基本流程(图像处理)
数据预处理
- 中值滤波(去噪)
- (图像)数据标准化
- 边缘检测
- 轮廓提取
- 图像裁剪
- 去重/训练数据平权
- 定义相似关系(偏序):满足自反,传递和对称性
- 并查集聚类(大于一定阈值)
- 原因:(假如原本只有pic1/2,两个图片,如果第一个图片重复了一万次,训练出来的网络,只要无脑选1就可以正确度很高)
- 数据特征提取
数据增强
- 通过等价性质,拓展训练数据集
- 伽马变换(颜色变换漂白、变暗),高斯模糊(像素平滑化),颜色抖动
- 仿射变换
- 随机旋转,水平垂直翻转,尺寸缩放
- 随机擦除
- 通过等价性质,拓展训练数据集
选择网络模型
- eg 预训练的EfficientNet-b5
- 魔改网络
- 采用多分支:不同分支使用不同大小的卷积核
- 卷积核大小(扩大感受野)、通道数调整
- 并行的多层空洞卷积提取多尺度特征
- 调整参数
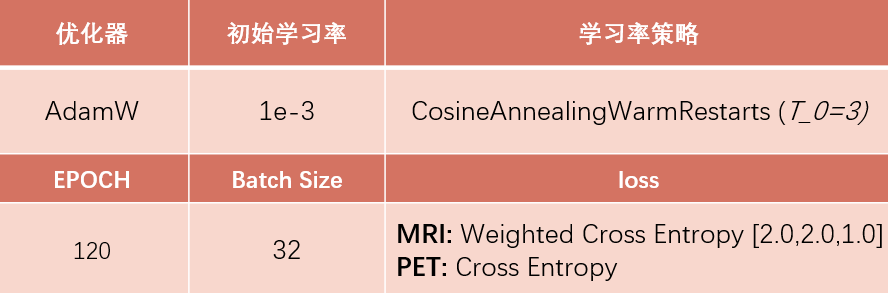
- 注意是否过拟合或者欠拟合
对数据多折迭代训练
伪标签 + 多折融合 + 测试时增强(TTA)
-
在机器学习的建模工作中,首先会将数据集分为训练集和测试集,在训练集上对模型进行训练以及参数的调优,在测试集上对模型进行评估,但是测试集的选择会对模型的效果产生影响,在随机切分训练集/测试集的情况下,可能刚好选择了比较容易预测的数据点作为测试集,所以采用交叉验证(cross validation)的方式,通过获取模型在多个测试集上的平均效果来总体评估模型的效果。
而交叉验证中常用的方法K折交叉检验法(k-fold cross validation)用于模型调优,可以缓解过拟合现象的产生,具体实现方法:
将样本数据集分为k组大小相似的互斥子集,每次抽取出k份中的一份作为测试集,剩下来的k-1份作为训练集,尽量保证每个子集数据分布的一致性。依次得到测试结果
S1,S2,...,Sk,然后求其平均值得到模型在多个测试集上的平均效果,用求得的平均值评估模型的总体效果。
通过分析结果相似性等,修正结果
训练阶段的优化技巧:
1. 学习率调整:
- 使用学习率调度器(Learning Rate Schedulers)来动态调整学习率,以确保在训练的不同阶段获得更好的性能。
2. 批量归一化(Batch Normalization):
- 加速训练收敛,有助于处理梯度消失和梯度爆炸问题。
3. 正则化技术:
- 使用 L1 或 L2 正则化来防止过拟合。
- 使用丢弃(Dropout)来随机关闭神经元,减少过拟合。
4. 数据增强:
- 增加训练数据集的多样性,提高模型的泛化能力。
5. 模型蒸馏/ 知识蒸馏 / 迁移学习
- 模型蒸馏(Knowledge Distillation):主要目标是通过从一个大型教师模型中传递知识到一个小型学生模型,提高学生模型的性能。
- 知识蒸馏(Knowledge Transfer): 类似于模型蒸馏,也是通过将知识从一个模型传递到另一个模型,但不限定于教师-学生的关系,可能是模型之间的互相传递。知识蒸馏是一个更广泛的概念,可以包括模型蒸馏,同时还可以涵盖其他情况,如在不同领域之间传递知识。
- 迁移学习:利用在大规模数据集上预训练的模型,通过微调适应新任务,减少训练时间和数据需求。
模型蒸馏(Knowledge Distillation)、知识蒸馏(Knowledge Transfer),以及迁移学习(Transfer Learning)是三种相关但不同的概念,它们在目标、方法和应用方面有一些区别。
1. 模型蒸馏(Knowledge Distillation):
1. **目标:** 主要目标是通过从一个大型教师模型中传递知识到一个小型学生模型,提高学生模型的性能。
2. **方法:**
- **教师模型:** 通常是一个大型、高性能的模型,例如深度神经网络。
- **学生模型:** 一个较小的模型,可以是浅层网络或具有较少参数的模型。
- **Softmax温度调整:** 通过调整Softmax输出的温度,使学生模型更容易学到教师模型的软标签。
3. **应用:** 模型蒸馏主要应用于通过利用大型模型的知识来提高小型模型的性能,尤其在数据不足的情况下。
2. 知识蒸馏(Knowledge Transfer):
1. **目标:** 类似于模型蒸馏,也是通过将知识从一个模型传递到另一个模型,但不限定于教师-学生的关系,可能是模型之间的互相传递。
2. **方法:**
- **知识传递:** 可以通过软标签、隐藏层表示等方式传递知识。
3. **应用:** 知识蒸馏是一个更广泛的概念,可以包括模型蒸馏,同时还可以涵盖其他情况,如在不同领域之间传递知识。
3. 迁移学习(Transfer Learning):
1. **目标:** 通过将从一个任务中学到的知识迁移到另一个相关或不相关的任务上,提高模型性能。
2. **方法:**
- **预训练模型:** 在一个大规模数据集上进行训练,然后将学到的权重应用于目标任务。
- **Fine-tuning:** 在目标任务上对预训练模型进行微调,以适应新任务的特定要求。
3. **应用:** 迁移学习适用于在源任务上训练的模型在目标任务上表现良好的情况。它可以包括预训练的模型或从一个领域到另一个领域的知识传递。
总结区别:
- **目标差异:**
- 模型蒸馏和知识蒸馏的主要目标是通过知识传递提高模型性能。
- 迁移学习的主要目标是在一个任务上学到的知识迁移到另一个任务上。
- **方法差异:**
- 模型蒸馏和知识蒸馏是在模型间进行知识传递。
- 迁移学习涉及在不同任务之间传递知识。
- **应用领域差异:**
- 模型蒸馏和知识蒸馏更侧重于模型之间的知识传递。
- 迁移学习更注重在不同任务之间迁移学到的知识。
这三个概念可以有重叠,但它们在重点和应用上存在一些差异。
层的冻结
训练的时候不同阶段冻结不同的层也可能可以加速。
论文: smartFRZ。 SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing.
6. 早停策略:
- 监控验证集的性能,当性能不再提高时停止训练,以防止过拟合。
训练网络的特殊设计
- 函数的连续平滑化处理
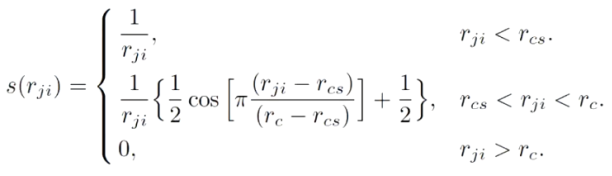
- 为保证结果的特殊性质而特别设计的网络(平移旋转不变性,拓展不变性
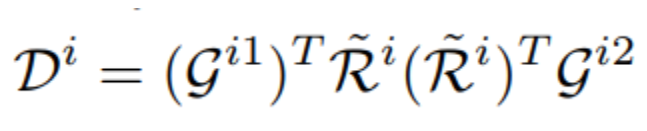
- 已知结果分布的情况下修正
训练基础知识
batch size
- 扩大batch size,像并行训练,deepspeed都是为了扩大batch size的。
- batch size扩大需要调整学习率,warmingup这些参数来提高精度
loss曲线
loss曲线的震荡:数据集用同一个就是这样的,只要保证一个step的global batch相同,跑出来的loss曲线会相同。
因为有一些数据点会导致图里面的这种震荡,文本中有些数据点的震荡更夸张。比如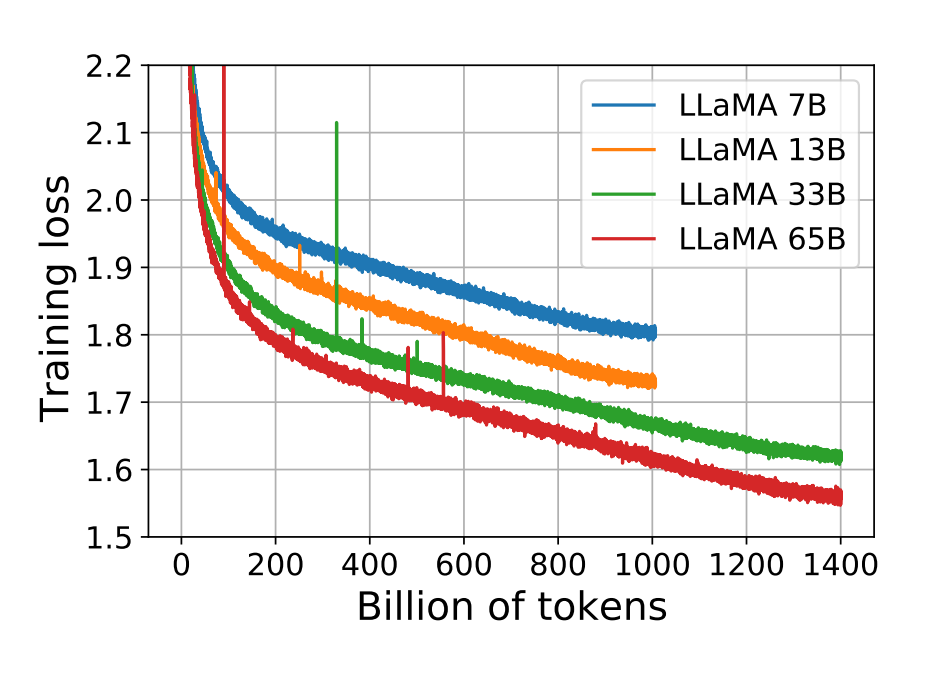
梯度累加
为了应对batchsize(训练cover的数据量)不够大的问题,将多次迭代的梯度累加后再统一一次反向传播更新。
下采样
对于一个样值序列间隔几个样值取样一次,这样得到新序列就是原序列的下采样。
在图像上, 缩小图像就是下采样。
Fine tune Model
- 2019年 Houlsby N 等人提出的 Adapter Tuning,
- 2021年微软提出的 LORA(LOW-RANK ADAPTATION) [^1],
LORA已经被 HuggingFace 集成在了 PEFT(Parameter-Efficient Fine-Tuning) 代码库里。使用也非常简单.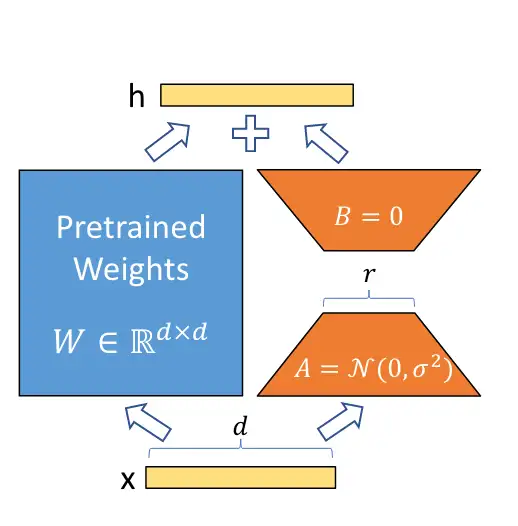
- 斯坦福提出的 Prefix-Tuning,谷歌提出的 Prompt Tuning,
- 2022年清华提出的 P-tuning v2。
组合拳
常见问题处理
样本不均衡的解决方法
- 数据处理
- 数据扩增- 通过变换或者转换产生一堆相同的正例子数据
- 只用一部分negative的样本
- loss计算改变权重
- 加权交叉熵
- focal Loss
其余各种优化技巧
https://mp.weixin.qq.com/s/bs-E6lVkc9U_5a6ej5Y9EQ
参考文献
[^1]: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
[^2]: 知乎 LoRA