Ideas around T2I2V models
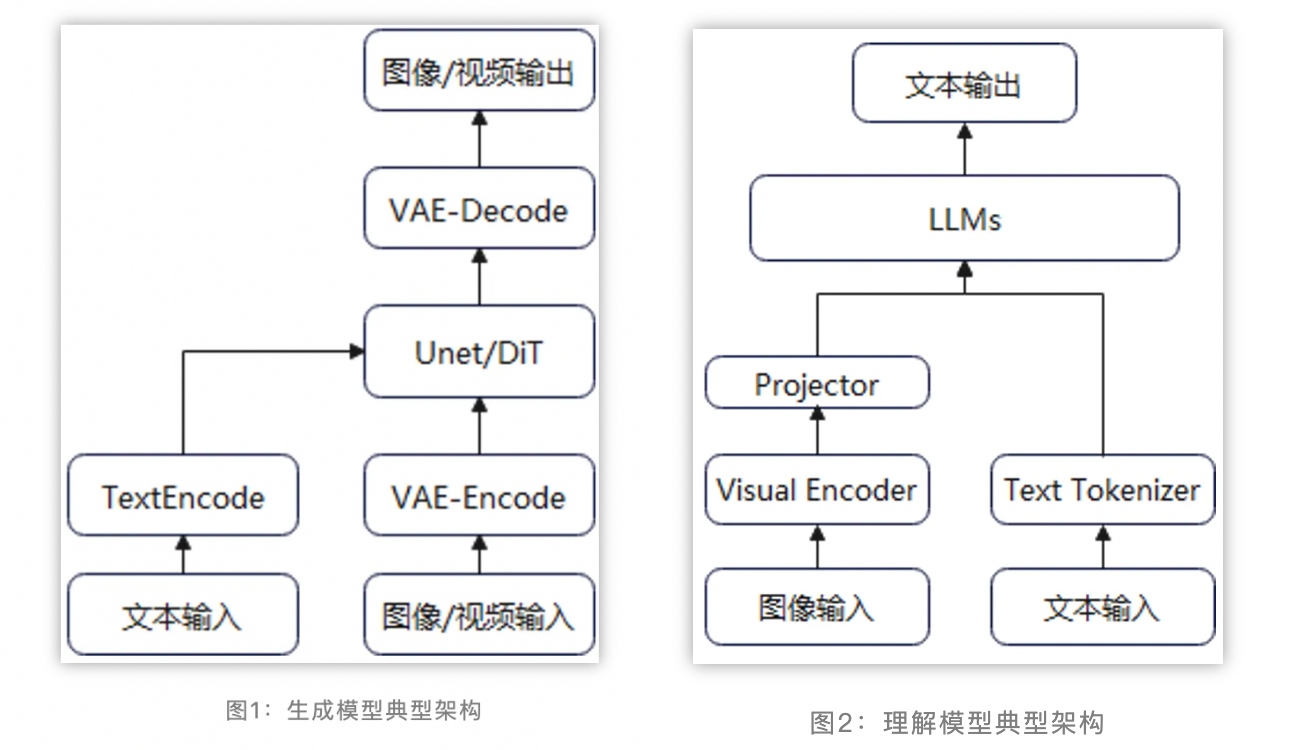
T2I (+Edit)
260210 Qwen-Image-2
- 支持 2K 分辨率
- 支持特别复杂的文本
260114 GLM-Image 智谱
RL:
- 算法上,在训练后阶段,GLM-Image采用解耦强化学习策略,分别优化其自回归生成器和扩散解码器,从而提升语义对齐和视觉细节质量。这两个模块均使用GRPO优化进行训练。对于扩散解码器,GLM-Image采用flow-GRPO。
- 奖励设计上,自回归模块专注于低频奖励,以指导语义一致性和美学,从而提高指令遵循性和艺术表现力。它结合了多个奖励来源,包括用于美学评分的HPSv3、用于增强文本渲染精度的OCR,以及用于生成内容整体语义正确性的VLM。解码器模块则针对高频奖励,以细化细节保真度和文本精确度。它利用LPIPS提升感知纹理和细节相似度,整合OCR信号进一步增强文本准确性,并采用专门的打分模型来提高生成手部的正确性。
251218 Qwen-Image-Layered
分辨图层的图片编辑[^22]
设计:
- RGBA-VAE : 多透明度维度
- VLD-MMDiT(Layer3D RoPE): 多个图层维度
- 多阶段训练(消融实验证明必要性)
2512 MiniMax VTP
encoder 也有scaling law
251204 Seedream 4.5 字节
- 在主体一致性、指令遵循精准度、空间逻辑理解及美学表现力等方面实现全面升级。
- 还没文章
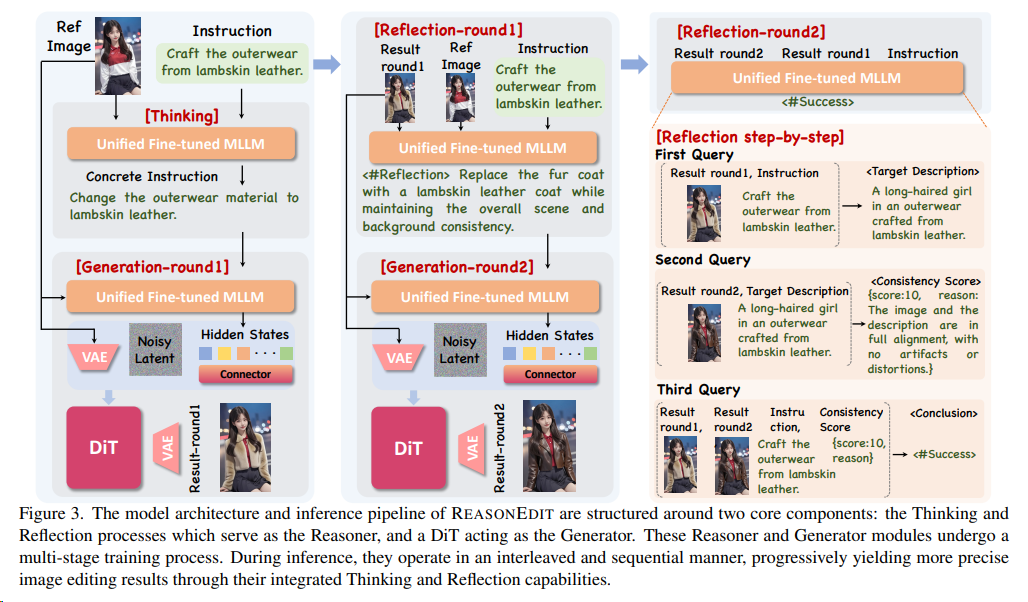
251127 Step1X-Edit-v1p2(ReasonEdit) StepFun
在图片生成编辑时,解锁MLLM的推理能力(如思维链、反思)可显著提升编辑精度与泛化性。
251126 Z-image/Edit 阿里
Z-Image-Turbo:Z-Image 的蒸馏版本,在仅需 8 次函数评估(Number of Function Evaluation,NPE)的情况下,可达到或超过领先模型的性能。
特点:
- 可扩展的单流 DiT(S3-DiT)架构。在这种架构,文本、视觉语义token和图像VAE token在序列级别上进行拼接,以作为统一的输入流,与双流方法相比最大化参数效率。[^18].[^19]
- Decoupled-DMD 是赋能 8 步 Z-Image 模型的核心:少步蒸馏算法(Few-Step Distillation, 将生成去噪的步数从百步变成8步)。团队在 Decoupled-DMD 中的核心洞察是,现有分布匹配蒸馏(Distributaion Matching Distillation,DMD)方法的成功来源于两个独立且协作的机制:通过识别并解耦这两个机制,能够独立地研究和优化它们。这最终促使团队开发出了一种改进的蒸馏流程,大幅提升了少步生成的性能。
- CFG 增强(CA):驱动蒸馏过程的主要引擎 ,这是以前工作中大多被忽视的因素。
- 分布匹配(DM):更像是一种正则化器 ,确保生成结果的稳定性和质量。
- 强化学习方法设计了 DMDR 相比于传统的DMD方法,DMDR在学生模型中引入了外部奖励信号,使其能够超越教师模型并避免“零强迫”问题。强化学习(RL)与分布匹配蒸馏(DMD)可以在少步模型的后训练阶段协同整合。团队展示了:RL 解锁了 DMD 的性能;DMD 有效规范了 RL。来在语义对齐、美学质量和结构一致性方面实现进一步提升,同时生成具有更丰富高频细节的图像。
DMDR
Distribution Matching Distillation Meets Reinforcement Learning
2511 Flux 2.0
FLUX.2系列是基于Latent Flow Macthing架构的Transformer大模型,在FLUX.1系列基础上,对Text Encoder、DiT backbone以及VAE三大架构都做了优化改进。[^21].^20
- 在Text Encoder部分,文本编码器不再使用T5和CLIP,而是改用了Mistral-3-24B视觉语言大模型(VLM大模型,Mistral-Small-3.2-24B-Instruct-2506),视觉语言大模型提供真实世界知识和上下文理解,增强了对世界、材质、空间关系和构图的建模能力。同时使用单个文本编码器极大地简化了Prompt Embeddings的计算过程。
- FLUX.2的VAE也进行了升级,新的VAE在可学习性、质量和压缩率之间实现了优化的平衡。
- 在DiT Backbone部分,FLUX.2沿用了与FLUX.1相同的MM-DiT + 并行DiT相结合的整体架构。简言之,MM-DiT模块首先在独立处理图像潜变量和条件文本,仅在注意力计算环节将二者融合,因此被称为“双流”块。随后的并行DiT模块则对拼接后的图像与文本流进行操作,可视为“单流”块。从FLUX.1到FLUX.2,DiT架构的核心改进如下:
- 对DiT部分进行了Scaling,参数量从FLUX.1的12B增加32B。
- 时间与引导信息(Timestep and Guidance Scale,以 AdaLayerNorm-Zero 调制参数的形式)分别在所有双流块和所有单流块间共享,而非如FLUX.1中为每个块单独设置调制参数,从而降低整体参数量。
- 模型中所有层均不再使用偏置参数。具体而言,两种变换器块中的注意力子块与前馈子块在其任何层中均未使用偏置参数。
- 在FLUX.1中,单流变换器块将注意力输出投影与前馈网络输出投影进行了融合。FLUX.2的单流块进一步将注意力QKV投影与前馈网络的输入投影相融合,从而实现了完全并行的Transformer块结构:
250928 HunyuanImage 3.0
原生多模态统一框架:
- 混合建模范式:传统DiT模型仅专注于图像生成任务,而混元Image 3.0通过离散-连续混合建模实现统一架构:
- 文本模态:采用自回归的下一个词预测(Autoregressive Next-Token Prediction)
- 图像模态:基于扩散机制预测图像标记(Diffusion-Based Image Token Prediction)
- 统一入口:通过共享的Transformer主干网络处理多模态序列
- 双编码器策略: 与DiT模型单一视觉编码器不同,该模型创新性地融合两种视觉特征:
- VAE编码器:提取图像生成所需潜在特征(32维隐空间,16倍下采样)
- 视觉编码器:处理图像理解任务(固定512px分辨率)
- 特征对齐:通过时间步调制残差块(Timestep-Modulated Residual Block)实现跨模态对齐

250909 Seedream 4.0 字节
文章没透露什么。
250804 Qwen-image /Qwen-Image-Edit
- 双流MMDiT架构
- 采用 Qwen2.5-VL 作为语义编码器,提取文本/图像输入的高层语义特征。
- VAE编码器 负责图像重建,支持256×256至1328×1328分辨率训练。
- MSRoPE位置编码:创新性地将文本沿图像对角线嵌入,解决多模态位置对齐问题(图8)。
- 双编码机制提升编辑一致性
- 输入图像同时通过 Qwen2.5-VL(语义特征) 和 VAE(重建特征) 编码,平衡编辑中的语义一致性与视觉保真度(图6)。

Editing:

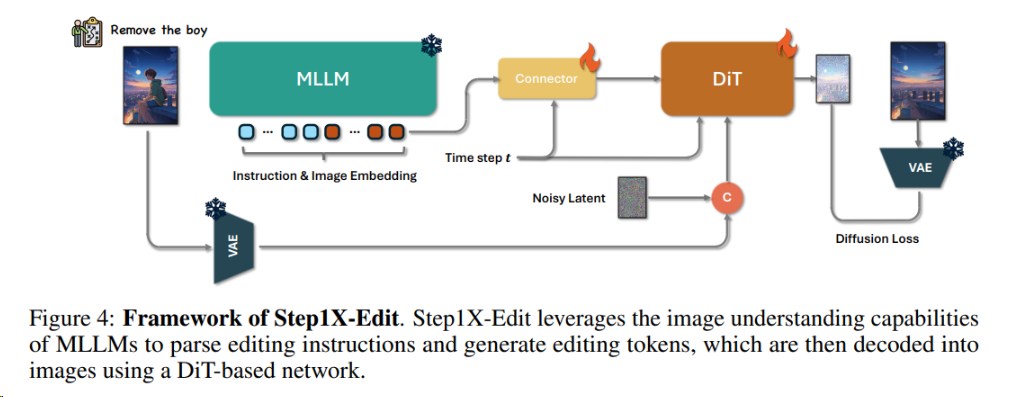
2504 Step1X-Edit StepFun
Step1X-Edit的核心架构包括三部分:
- 多模态大语言模型(MLLM):如Qwen-VL,解析图像和指令,生成语义嵌入。
- 连接模块(Token Refiner):将MLLM的输出转换为紧凑的文本特征。
- 扩散模型(DiT):如FLUX,根据文本特征生成目标图像。
T2V (+Edit)
260207 Seedance 2.0
在电影感,分镜,动作和时长上有明显进步,据说是200B MoE。
2512 NextStep 1.1 阶跃星辰
Flow-based RL?
251216 Seedance 1.5 Pro 字节
字节音视频生成模型
- Seedance 1.5 Pro 采用双分支 Diffusion Transformer 架构,结合跨模态联合模块与多阶段数据流水线,在音视频同步性和生成质量方面实现了卓越表现。
- 为确保模型具备实际应用价值,研究团队在后训练阶段进行了精细化优化,包括基于高质量数据集的监督微调(SFT),以及结合多维度奖励模型的人类反馈强化学习(RLHF)。
- 此外,还设计了一套推理加速框架,将整体推理速度提升至原来的 10 倍以上。
- Seedance 1.5 Pro 在多语言与多方言的精准口型同步、电影级动态镜头控制以及叙事连贯性方面表现突出,定位为面向专业级内容创作的高性能生成引擎。
2511 HunyuanVideo 1.5
特点:
- 两阶段DiT,后面用于视频分辨率超分;
- 稀疏注意力机制: 选择性滑动分块注意力(SSTA)
- Muon 优化器
- RL 使用 类似GRPO思想的OPA-DPO
2510 self-forcing++ 字节
- 问题:针对长视频生成时,训练时长短,但是要求推理时时长长,当生成时长超出训练范围时,视频质量往往急剧下降,易出现画面停滞、结构崩坏等问题。
- 特点:[^17]
- 基于滑动窗口的Distribution Matching Distillation (DMD) 监督(最小化生成分布与真实分布的反向KL散度)
- GRPO: 引入基于光学流幅度的奖励函数,抑制长视频中的突兀场景切换(ps 光学流幅度(Optical Flow Magnitude)是计算机视觉中的一个重要概念,通过计算视频中连续帧之间的像素位移矢量(即光学流场)的模长得到的标量值。它量化了物体在时间维度上的运动强度, 用于描述视频序列中物体运动的速度和方向)
2509 Wan-Preview 2.5
图生视频重回前三
2507 Wan 2.2
特点:
- 首个Moe的适配生成模型;
- 数据扩容与美学精调
- 高压缩率3D VAE架构,时间与空间压缩比: 4×16×16,信息压缩率: 64
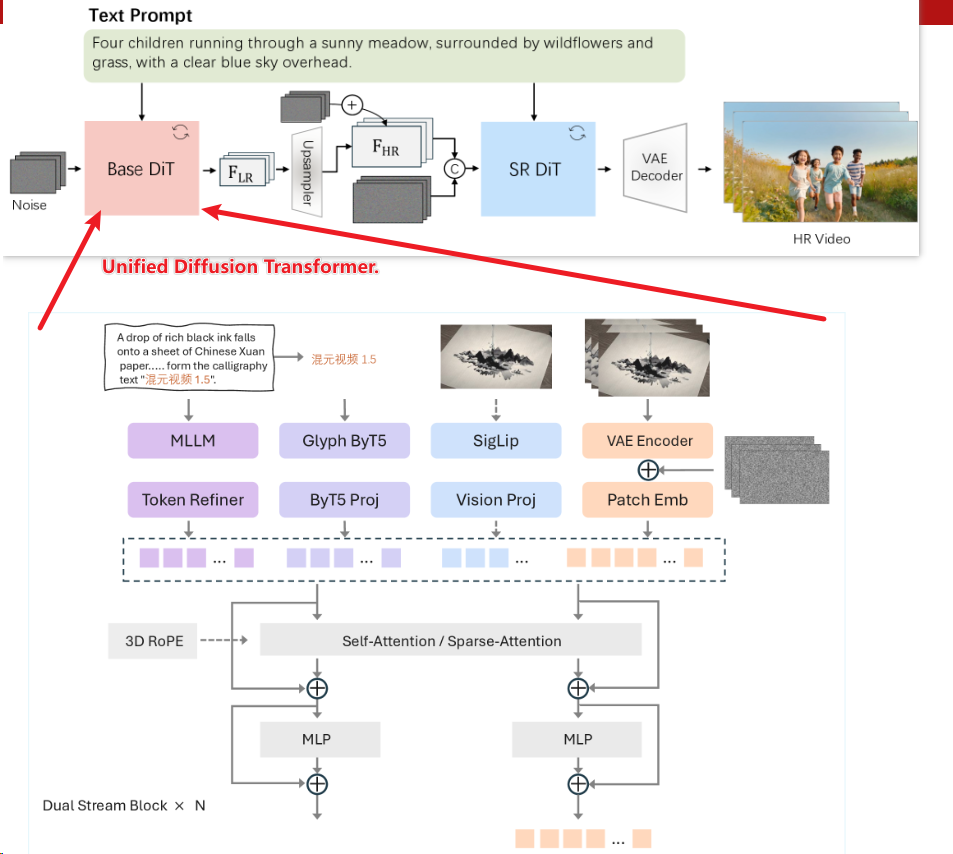
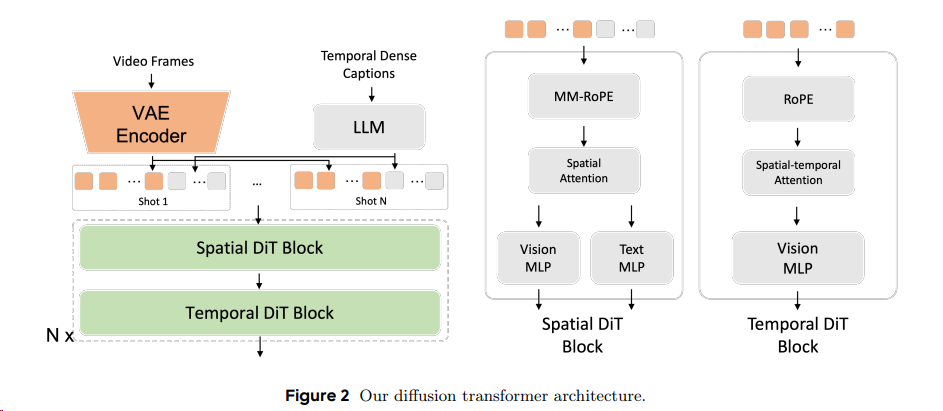
2506 Seedance 1.0 T2V 字节
- 变分自编码器(VAE):采用时间因果压缩架构,统一处理图像/视频输入,压缩比优化
- 扩散Transformer(DiT):解耦时空注意力层,引入窗口注意力机制提升效率;支持多镜头多模态RoPE(MM-RoPE)编码。
- 扩散精炼器(Refiner):级联扩散框架,将基础模型(480p)输出精炼至1080p,增强纹理细节。
2506 self-forcing (Adobe, NeurIPS 2025)
- 问题:传统方法(如Teacher Forcing/DF)训练时依赖真实帧或噪声帧作为上下文,但推理时需基于模型自身生成的帧预测下一帧,导致分布不匹配和误差累积。
- 特点:边训边推;滚动KV缓存生成加速[^16]
2505 Wan2.1-VACE
阿里巴巴团队提出 VACE(Video tasks within All-in-one framework for Creation and Editing),首个基于视频扩散Transformer(DiT)架构的统一视频生成与编辑模型。其核心创新是通过
- 视频条件单元(VCU)
- 上下文适配器(Context Adapter)

实现多任务兼容,支持参考
- 视频生成(R2V)、
- 视频编辑(V2V)、
- 掩码视频编辑(MV2V)
- 及任务组合(如长视频重渲染),
显著降低部署成本并提升创作灵活性。

VACE基于两个预训练视频生成模型作为基础框架:
- LTX-Video-2B:轻量级模型,支持快速生成(单卡A100生成5秒视频约24秒),适合实时应用。
- Wan-T2V-14B:高质量模型,支持720p分辨率,生成效果媲美商业产品(如Pika、Vidu),但资源消耗较高。
这两个模型均为预训练的视频扩散Transformer(DiT)架构,VACE在此基础上通过视频条件单元(VCU)和上下文适配器(Context Adapter)扩展多任务能力。
2502 Wan-Video
- 亮点:闭源版本重新成为vbench榜首模型
- 来自阿里云
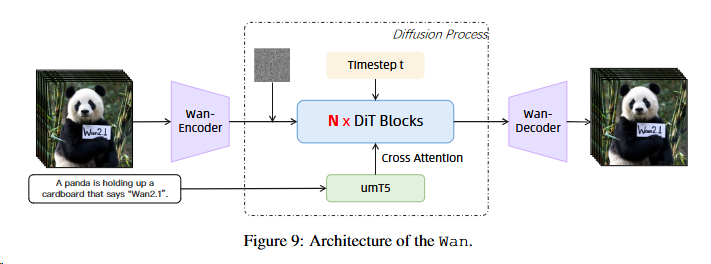 [^15]
[^15]
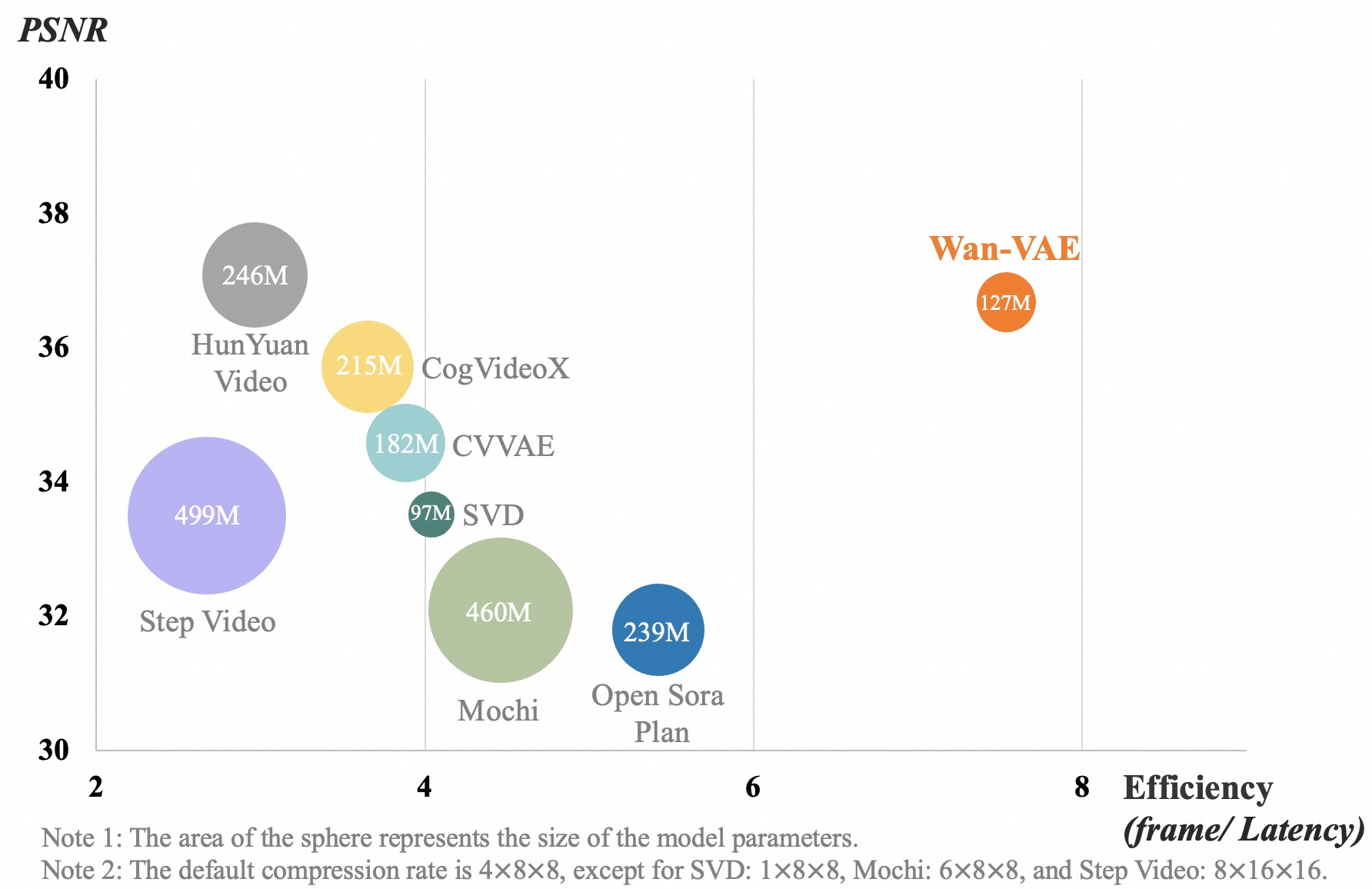
高效VAE
- wan-vae实现了参数量小情况下的,输出效率最高,图像质量也数一数二。
- PSNR全称为Peak Signal to Noise Ratio,即峰值信噪比,经常用于计算两幅图像的可视化误差,最小值为0,越大代表两张图片差异越小。
DiT
- Flow Matching
- 特殊:(待研究)
- time embeddings: an MLP with a Linear layer and a SiLU layer to process
- 单独训练权重?predict six modulation parameters individually. This MLP is shared across all transformer blocks, with each block learning a distinct set of biases
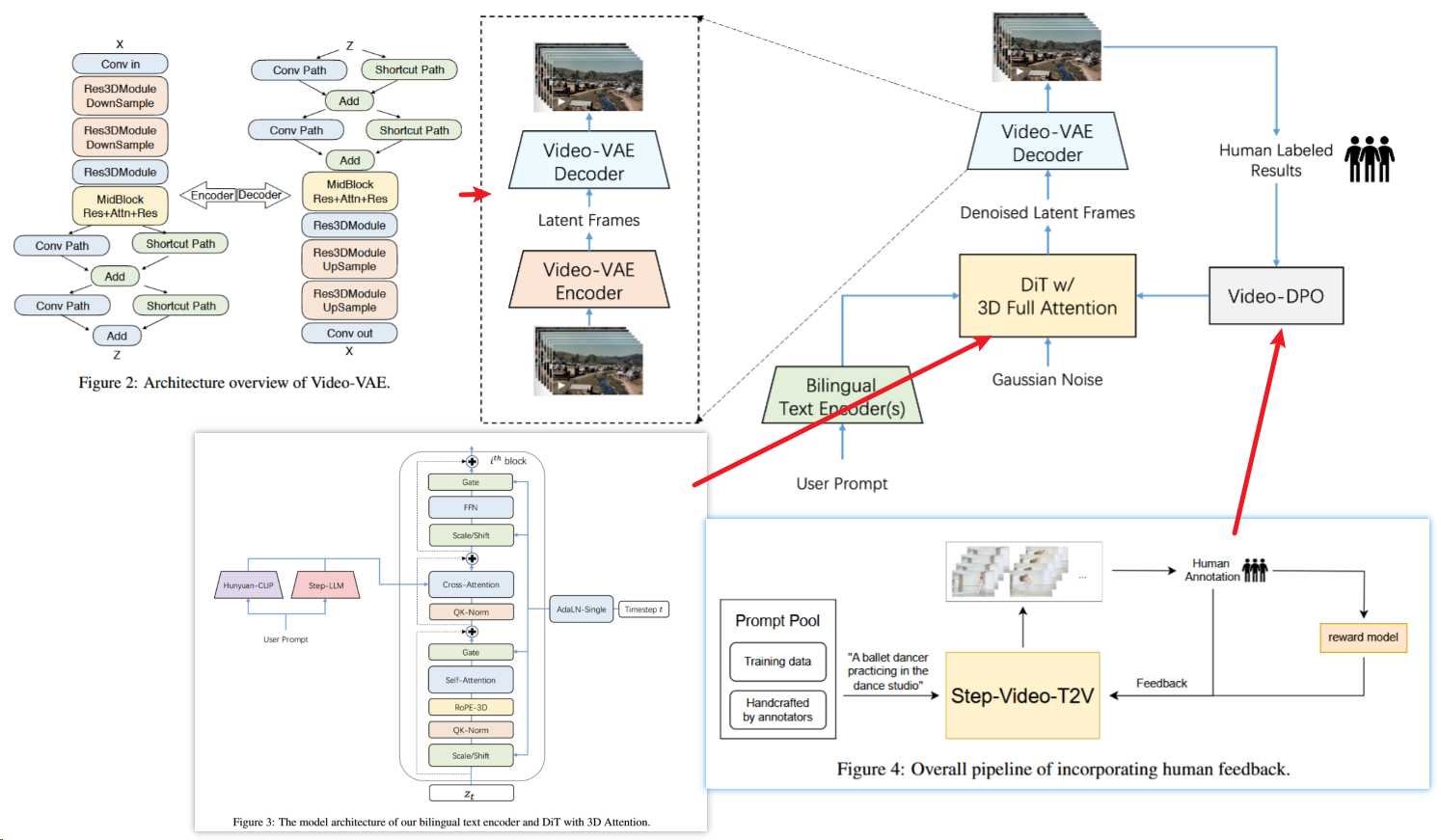
2502 Step-Video-T2V 30B
4大技术特点:
- 第一,当前最大参数30 billion开源视频生成模型,可直接生成最长204帧、540P分辨率的视频,确保生成的视频内容具有极高的一致性和信息密度。
- 第二,针对视频生成任务设计并训练了高压缩比的Video-VAE,在保证视频重构质量的前提下,能够将视频在空间维度压缩16×16倍,时间维度压缩8倍。
- 当下市面上多数VAE模型压缩比为8x8x4,在相同视频帧数下,Video-VAE能额外压缩8倍,故而训练和生成效率都提升64倍。
- 第三,针对DiT模型的超参设置、模型结构和训练效率,Step-Video-T2V了进行深入的系统优化,确保训练过程的高效性和稳定性。
- 第四,详细介绍了预训练和后训练在内的完整训练策略,包括各阶段的训练任务、学习目标以及数据构建和筛选方式。
- 此外,Step-Video-T2V在训练最后阶段引入Video-DPO(视频偏好优化)——这是一种针对视频生成的RL优化算法,能进一步提升视频生成质量,强化生成视频的合理性和稳定性。
训练系统相关细节请看AI Training System 一文。
VideoVAE
基础:文本到视频扩散-Transformer模型的效率依赖于潜在空间压缩能力。由于注意力计算成本与token数量的平方成正比,通过高效压缩减少时空冗余至关重要——既能加速训练/推理,又符合扩散过程对紧凑表示的天然偏好。
Video-VAE在编码器后期和解码器初期引入双路径架构,通过统一时空压缩实现8×16×16下采样:
- 因果3D卷积模块:
- 编码器前期包含3个阶段,每阶段含两个Causal Res3DBlock和下采样层,后接融合卷积与注意力的MidBlock。
- 采用时间因果3D卷积(公式1):当前帧仅依赖历史帧,实现因果性建模,支持图像与视频联合训练。
- 双路径潜在融合:
- Conv路径:结合因果3D卷积与像素重排(公式2),保留高频细节。
- Shortcut路径:通过分组通道平均(公式3)保留低频结构。
- 输出融合:残差求和(公式4)平衡两类信息,解决传统VAE模糊问题。
多阶段训练
- 文本到图像预训练: 使模型学习丰富的视觉知识。
- 文本到视频预训练: 在低分辨率下学习运动动态。
- SFT(监督微调): 使用高质量、精确标注的视频数据进行微调,提升指令遵循和风格。
- DPO: 基于偏好数据进一步优化视觉质量。 这种分阶段、逐步求精的策略有助于稳定训练、加速收敛,并充分利用不同质量的数据集。
多模态生成预训练, 为什么用“图文对”依然算预训练?”
请看机器学习基础一文。
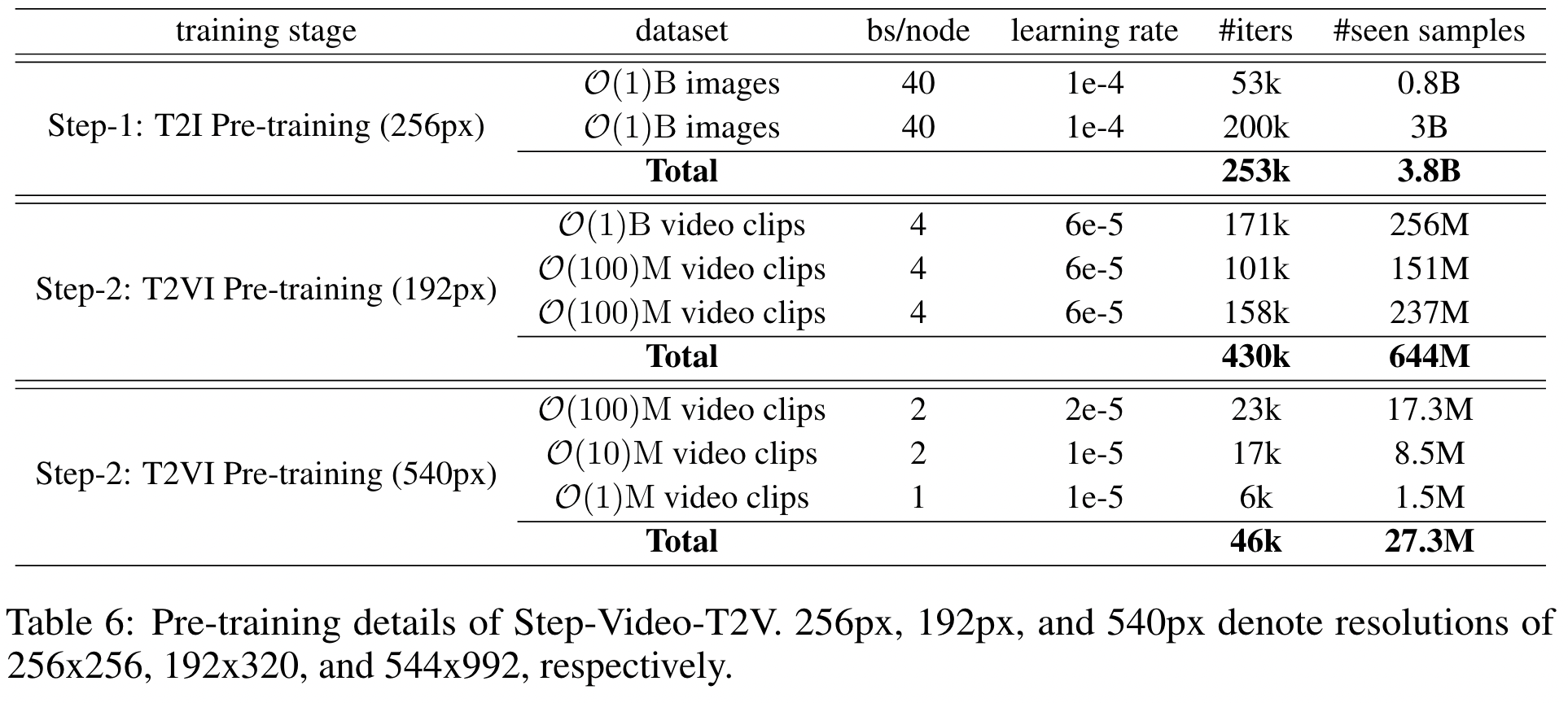
- text-to-image (T2I) pre-training,
- 我们有意避免直接进行文本到视频(T2V)预训练,
- 因为早期实验表明:当在40亿参数模型上尝试从头开始T2V预训练时,模型对新概念的学习能力显著下降且收敛速度大幅减缓。
- 通过先进行T2I预训练,模型可以建立对视觉概念的扎实理解,为后续处理视频时序动态奠定基础。
- text-to-video/image (T2VI) pre-training,模型进入T2VI联合训练阶段,同步进行文本到图像和文本到视频训练。该步骤进一步分为两个子阶段:
- 低分辨率预训练(192x320,192P):在此阶段使用低分辨率视频,使模型专注于运动模式的学习而非细节特征。我们观察到模型在此阶段主要获取运动知识。
- 高分辨率预训练(544x992,540P):提升视频分辨率后继续训练,促使模型学习更精细的视觉细节。实验显示此阶段模型学习重点转向细节捕捉。
- 基于以上发现,我们在步骤二的第1子阶段分配更多计算资源,以强化运动特征的获取能力。
- text-to-video (T2V) fine-tuning,
- 由于预训练视频数据在领域和质量的多样性,直接使用预训练模型生成视频时可能引入伪影和风格不一致的问题。
- 为缓解此类问题,通过T2V微调步骤进一步完善训练流程。在此阶段,我们使用少量文本-视频配对数据,并移除文本到图像(T2I)任务,使模型专注于文本到视频生成的适配优化。
- direct preference optimization (DPO) training.
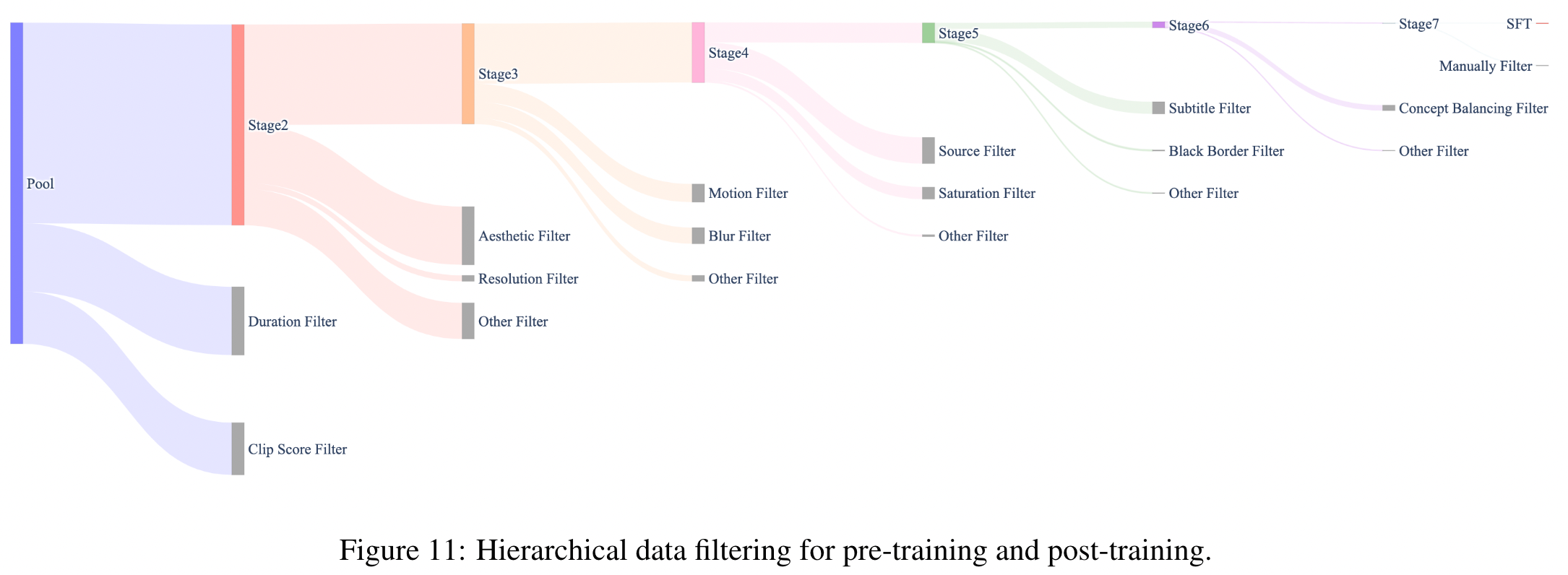
训练数据集构建
通过一系列逐步提高阈值的过滤器:
- 为步骤二的T2VI预训练创建了六个预训练子集。
- 并最终通过人工筛选构建监督微调(SFT)数据集。
图中展示了每个阶段应用的关键过滤器:灰色条表示被过滤的数据,彩色条为保留数据。
蒸馏Turbo
- 问题:传统扩散模型通过50-100步迭代求解ODE(Ordinary Differential Equation,常微分方程),逐步将随机噪声转化为视频帧(如Step-Video-T2V需50步生成204帧),导致生成1分钟视频需数十分钟计算。
- 关键:减少迭代(函数评估次数Number of Function Evaluations,NFE)对提升推理效率至关重要。
- 改进:通过自蒸馏(self-distillation)结合修正流目标(rectified flows)和专用推理策略,大规模训练的Video DiT模型可将NFE降至仅8步且性能几乎无损。具体实现如下:
修正流蒸馏框架
基模型(Base Model)通过修正流(rectified flow)训练,蒸馏目标则是训练2-修正流模型(Liu等,2022),以在推理时构造更直接的ODE路径。如Lee等(2024)所述,2-修正流的损失函数为:
[
L(\theta, t) := \frac{1}{t^2} \mathbb{E}\left[ |v - u_\theta(x_t, t)|_2^2 \right] = \frac{1}{t^2} \mathbb{E}\left[ |x - \mathbb{E}[x|x_t]|_2^2 \right] + \tilde{L}(\theta, t) \tag{10}
]
由于所有训练样本均由1-修正流基模型生成,不可约损失(第一项)较小,而可约误差(第二项)可通过加权困难时间步高效优化。具体而言,2-修正流的训练损失在时间区间(t \in [0,1])两端较大、中间较小。数据与训练策略
使用SFT数据提示的精选分布生成约95,000个样本(50 NFE),并通过设计的正/负提示构建蒸馏数据集。修改时间步采样策略为U型分布:
[
p_t(u) \propto \exp(a u) + \exp(-a u) \quad (u \in [0,1], a=5)
]
较大的(a)值适应视频模型对时间偏移的更高需求。推理时观察到,随着训练推进,模型需要更大的采样时间偏移和更低的分类器无关引导(CFG)规模。通过结合线性衰减的CFG调度(式11),我们的模型能以10倍更少步骤达到同等生成质量。图6展示了Turbo模型以10 NFE生成的204帧样本。
2412 HunyuanVideo 13B
HunyuanVideo 是一个隐空间模型,训练时它采用了 3D VAE 压缩时间维度和空间维度的特征。文本提示通过一个大语言模型编码后作为条件输入模型,引导模型通过对高斯噪声的多步去噪,输出一个视频的隐空间表示。最后,推理时通过 3D VAE 解码器将隐空间表示解码为视频。^12

统一的图视频生成架构
HunyuanVideo 采用了 Transformer 和 Full Attention 的设计用于视频生成。具体来说,我们使用了一个“双流到单流”的混合模型设计用于视频生成。在双流阶段,视频和文本 token 通过并行的 Transformer Block 独立处理,使得每个模态可以学习适合自己的调制机制而不会相互干扰。在单流阶段,我们将视频和文本 token 连接起来并将它们输入到后续的 Transformer Block 中进行有效的多模态信息融合。这种设计捕捉了视觉和语义信息之间的复杂交互,增强了整体模型性能。使用了Flow Matching.

MLLM 文本编码器
过去的视频生成模型通常使用预训练的 CLIP 和 T5-XXL 作为文本编码器,其中 CLIP 使用 Transformer Encoder,T5 使用 Encoder-Decoder 结构。HunyuanVideo 使用了一个预训练的 Multimodal Large Language Model (MLLM) 作为文本编码器,它具有以下优势:
- 与 T5 相比,MLLM 基于图文数据指令微调后在特征空间中具有更好的图像-文本对齐能力,这减轻了扩散模型中的图文对齐的难度;
- 与 CLIP 相比,MLLM 在图像的细节描述和复杂推理方面表现出更强的能力;
- MLLM 可以通过遵循系统指令实现零样本生成,帮助文本特征更多地关注关键信息。
由于 MLLM 是基于 Causal Attention 的,而 T5-XXL 使用了 Bidirectional Attention 为扩散模型提供更好的文本引导。因此,我们引入了一个额外的 token 优化器来增强文本特征。

3D VAE
我们的 VAE 采用了 CausalConv3D 作为 HunyuanVideo 的编码器和解码器,用于压缩视频的时间维度和空间维度,其中时间维度压缩 4 倍,空间维度压缩 8 倍,压缩为 16 channels。这样可以显著减少后续 Transformer 模型的 token 数量,使我们能够在原始分辨率和帧率下训练视频生成模型。

Prompt 改写
为了解决用户输入文本提示的多样性和不一致性的困难,我们微调了 Hunyuan-Large model 模型作为我们的 prompt 改写模型,将用户输入的提示词改写为更适合模型偏好的写法。
我们提供了两个改写模式:正常模式和导演模式。两种模式的提示词见这里。正常模式旨在增强视频生成模型对用户意图的理解,从而更准确地解释提供的指令。导演模式增强了诸如构图、光照和摄像机移动等方面的描述,倾向于生成视觉质量更高的视频。注意,这种增强有时可能会导致一些语义细节的丢失。
Prompt 改写模型可以直接使用 Hunyuan-Large 部署和推理. 我们开源了 prompt 改写模型的权重,见这里.
2408 CogVideoX 5B
2024年8月,智谱开源视频生成模型CogVideoX,先是2B模型,而后是5B模型,近期还开源了V1.5的模型:
技术特点:
- 自主研发了一套高效的三维变分自编码器结构(3D VAE)。降低了视频扩散生成模型的训练成本和难度。结合 3D RoPE 位置编码模块,该技术提升了在时间维度上对帧间关系的捕捉能力,从而建立了视频中的长期依赖关系。
- 拓展视频模型规模到5B,提升了模型的理解能力,使得模型能够处理超长且复杂的 prompt 指令。
- 模型与Stable Diffusion 3一致,将文本、时间、空间融合在一起,通过 Full Attention 机制优化模态间的交互效果。
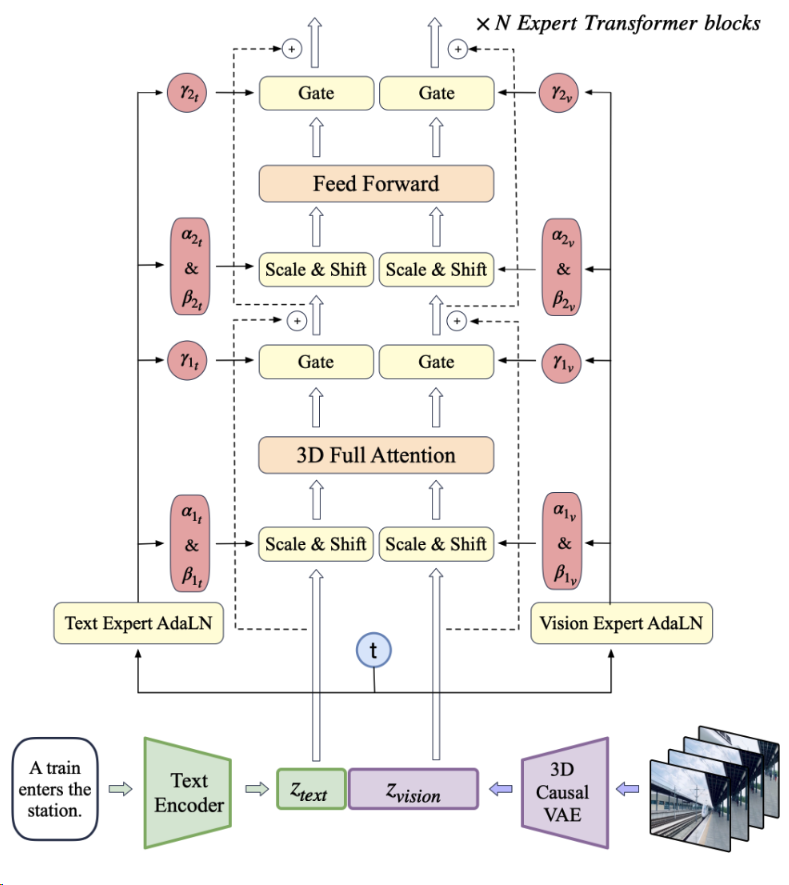
多阶段训练
- 低分辨率到高分辨率训练
- 高质量数据微调
2404 EasyAnimate 12B
EasyAnimate是阿里云人工智能平台PAI自主研发的DiT-based视频生成框架。^13
- 更新到v5.1版本,应用Qwen2 VL作为文本编码器,支持多语言预测,使用Flow作为采样方式,除去常见控制如Canny、Pose外,还支持轨迹控制,相机控制等。[ 2025.01.21 ]
- 使用奖励反向传播来训练Lora并优化视频,使其更好地符合人类偏好,详细信息请参见此处。EasyAnimateV5-7b现已发布。[ 2024.11.27 ]
- 更新到v5版本,最大支持1024x1024,49帧, 6s, 8fps视频生成,拓展模型规模到12B,应用MMDIT结构,支持不同输入的控制模型,支持中文与英文双语预测。[ 2024.11.08 ]
- 更新到v4版本,最大支持1024x1024,144帧, 6s, 24fps视频生成,支持文、图、视频生视频,单个模型可支持512到1280任意分辨率,支持中文与英文双语预测。[ 2024.08.15 ]
- 更新到v3版本,最大支持960x960,144帧,6s, 24fps视频生成,支持文与图生视频模型。[ 2024.07.01 ]
- 更新到v2版本,最大支持768x768,144帧,6s, 24fps视频生成。[ 2024.05.26 ]
以下是EasyAnimate各版本更新的Markdown表格整理,综合公开资料与官方技术报告:
| 版本 | 发布时间 | 核心功能升级 | 技术特性 | 分辨率与帧率 |
|---|---|---|---|---|
| v2 | 2024.05.26 | 文生视频 | - 采用DiT基础架构 - 初步实现文本到视频生成 |
最大768×768@24fps (144帧/6秒) |
| v3 | 2024.07.01 | 新增图生视频功能 支持双图起止画面控制 |
- 引入Hybrid Motion Module - 集成Slice VAE时间轴压缩技术 - 支持CLIP图像编码器 |
最大960×960@24fps (144帧/6秒) |
| v4 | 2024.08.15 | 支持视频生视频 动态分辨率适配 |
- 跨模态特征融合优化 | 最大1024×1024@24fps (144帧/6秒) |
| v5 | 2024.11.08 | 中英双语支持 多模态控制模型 |
- 采用MMDIT架构 - 模型参数扩展至12B - 集成7种控制信号(OpenPose/Canny等) |
1024×1024@8fps (49帧/6秒) |
| v5.1 | 2025.01.21 | 轨迹与相机控制 多语言预测优化 |
- Qwen2-VL作为文本编码器 - Flow采样方式改进 - 奖励反向传播训练机制 |
动态分辨率支持 |
关键技术演进路径
架构升级
v2-v3实现从基础DiT到时空混合运动模块的跨越,通过奇数层全局注意力与偶数层时序注意力的交替堆叠,解决视频连贯性问题;v5引入MMDIT架构,为不同模态设计独立映射网络,实现多模态特征高效对齐。生成能力突破
通过Slice VAE技术实现时序压缩率1/4,使v4支持动态分辨率;v5的12B参数模型结合7种控制信号,可生成带精确构图引导的工业级视频。交互方式创新
v3首创双图起止画面控制,v5.1新增轨迹/相机控制,支持通过运动路径曲线和镜头参数调整视频运镜效果[用户提供信息]。
该框架现已在PAI平台实现一键式训练部署,最新版支持通过LoRA微调实现风格迁移。具体技术细节可参考官方技术报告与GitHub仓库。
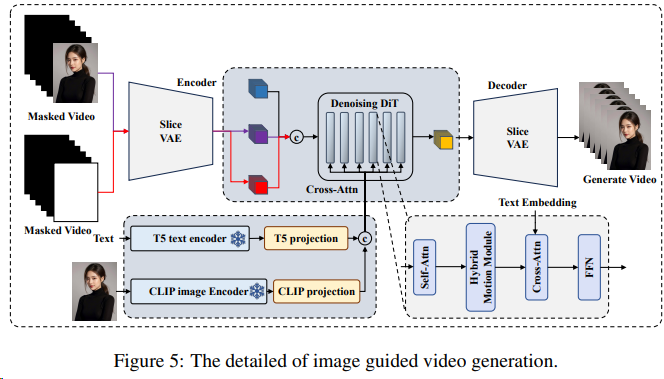
V2 V3
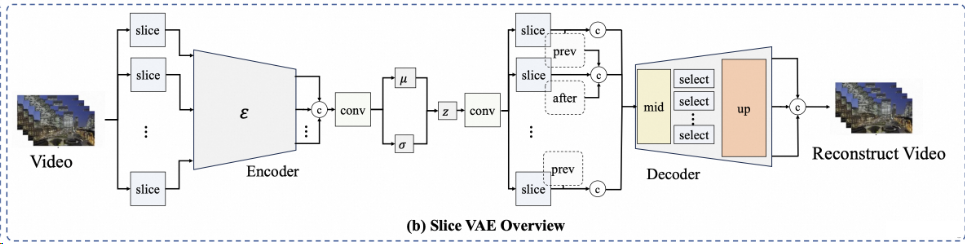
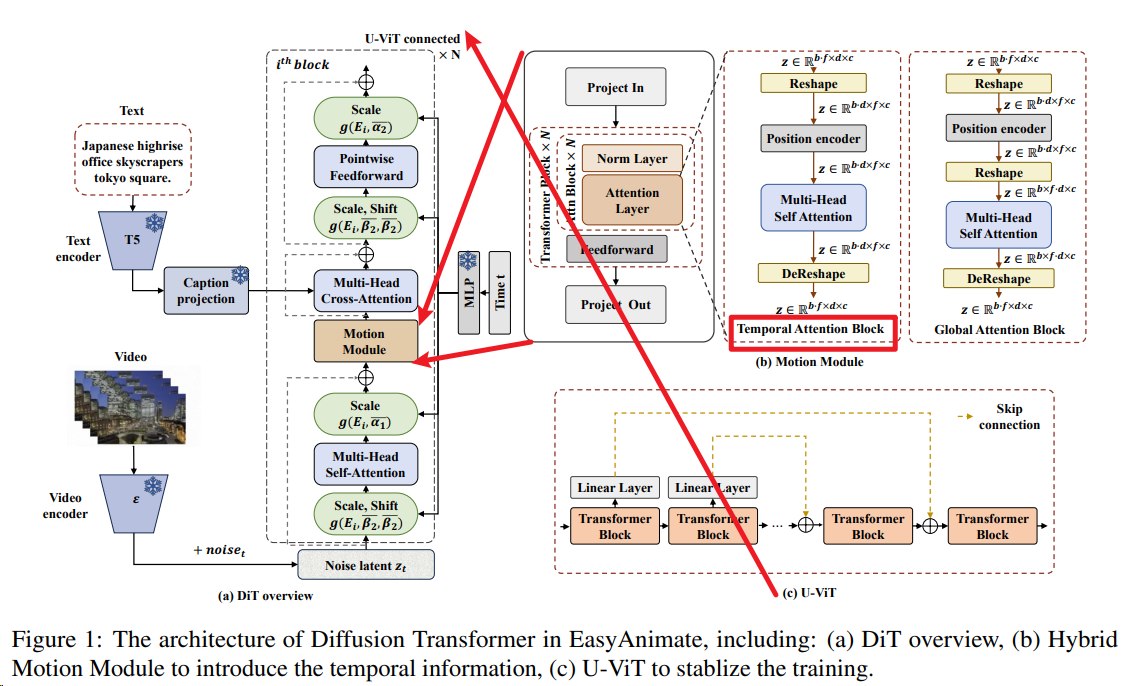
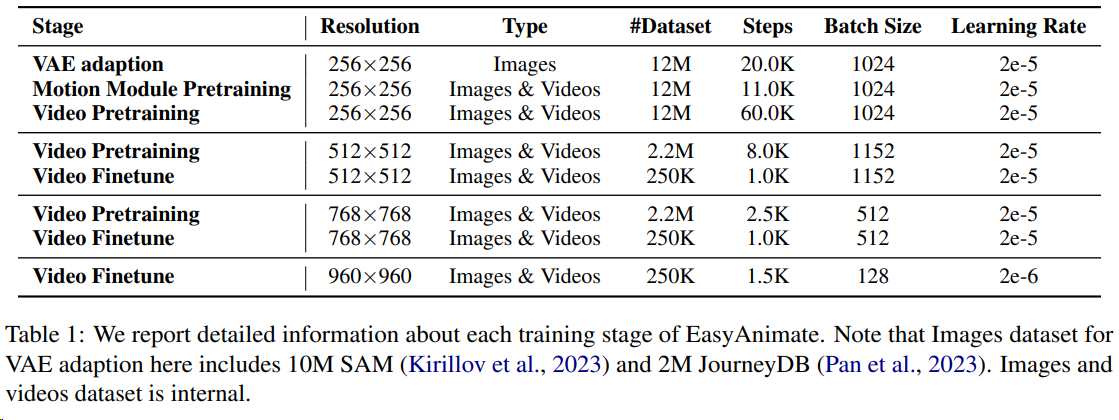
V5
数据规模:在大约10m SAM图片数据+26m 图片视频混合的预训练数据上进行了从0开始训练。^11
对比EasyAnimateV4,EasyAnimateV5还突出了以下特点:
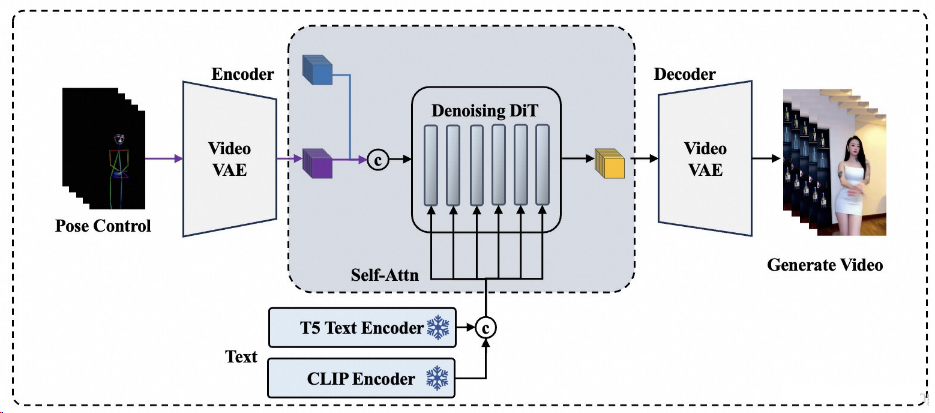
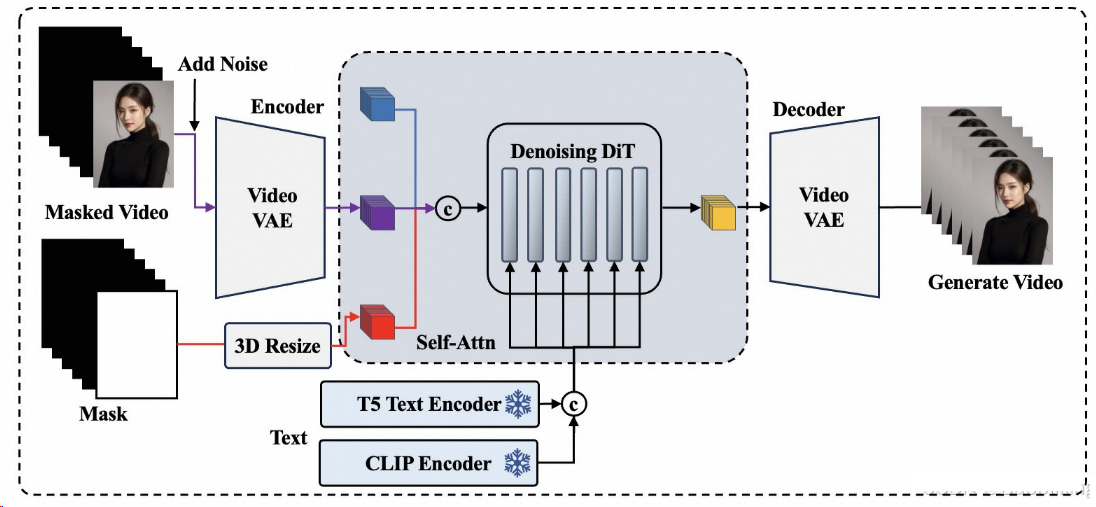
V5.1
对比EasyAnimateV5,EasyAnimateV5.1主要突出了以下特点:^10
在MMDiT结构的基础上,将EasyAnimateV5的双text encoders替换成alibaba近期发布的Qwen2 VL;相比于CLIP与T5这样的传统编码模型,使用LLM作为Text Encoder慢慢在生成领域里流行起来,比如最近大火的HunyuanVideo模型。
尽管LLM的主力工作是生成,但对文本的编码与理解能力依然优秀,Qwen2 VL是多模态LLM中性能的佼佼者,对语义理解更加精准。而相比于Qwen2本身,Qwen2 VL由于和图像做过对齐,对图像内容的理解更为精确。
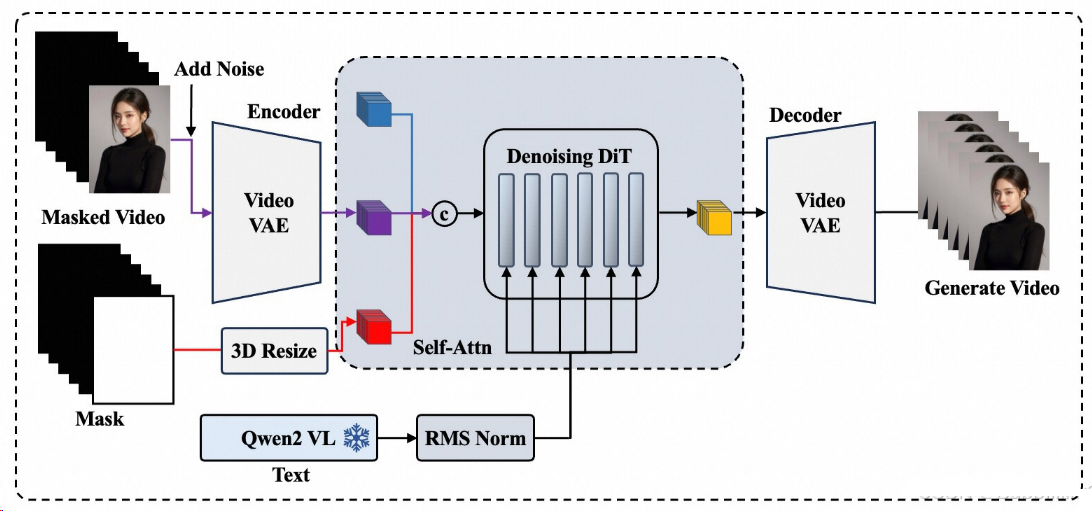
通过取出Qwen2 VL hidden_states的倒数第二个特征输入到MMDiT中,与视频Embedding一起做Self-Attention。在做Self-Attention前,由于大语言模型深层特征值一般较大(可以达到几万),为其做了一个RMSNorm进行数值的矫正再进行全链接,这样有利于网络的收敛。
基础
2402 SD3
- 2024年2月发布了 Stable Diffusion 3,
技术要点:
- Self-Attention:文本信息注入的方式,DiT模型在最初引入文本时,通常使用Cross Attention的方法结合文本信息,如Pixart-α、hunyuan DiT等。Stable Diffusion 3通过Self-Attention引入文本信息。相比于Cross Attention,使用Self-Attention引入文本信息不仅节省了Cross Attention的参数量,还节省了Cross Attention的计算量。^9
- 引入了RMS-Norm,在每一个attention运算之前,对Q和K进行了RMS-Norm归一化,用于增强模型训练的稳定性。
- 同时使用了更大的VQGAN,VQGAN压缩得到的特征维度从原来的4维提升到16维等。
MMDiT
关键核心是新的多模态扩散 Transformer(Multimodal Diffusion Transformer,MMDiT)架构。
- MMDiT 架构结合了 DiT 和矩形流(RF)形式。它使用两个独立的变换器来处理文本和图像嵌入,并在注意力操作中结合两种模态的序列。这意味着对于文本和图像两种不同的输入模态,MMDiT 分别使用不同的权重参数来进行编码和处理,以此能够更好地捕捉每种模态的特征和信息。

2023 SDXL
- SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , 人如其名是SD的改进版
- 内容:
- 在原本的扩散模型后加Refiner模型(也是扩散模型), 参数量达到2.6B(10GB左右)
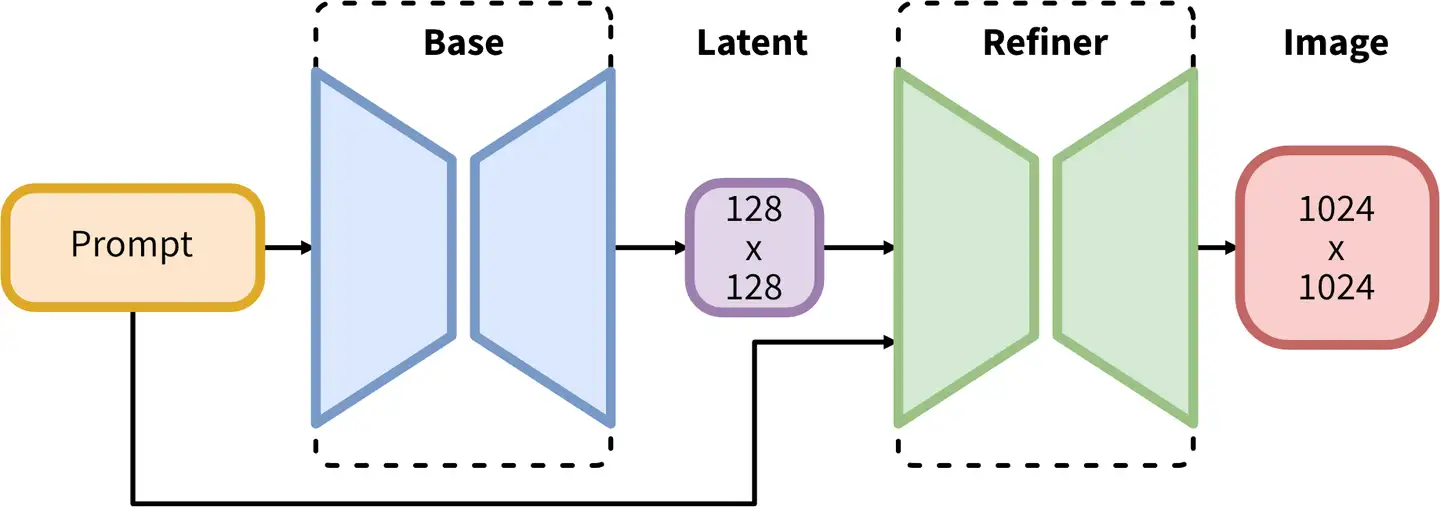 在Latent特征进行小噪声去除和细节质量提升。[^7]
在Latent特征进行小噪声去除和细节质量提升。[^7]
- 在原本的扩散模型后加Refiner模型(也是扩散模型), 参数量达到2.6B(10GB左右)
SDXLStable Diffusion XL是Stable Diffusion的最新优化版本, 如果Stable Diffusion是图像生成领域的“YOLO”,那Stable Diffusion XL就是“YOLOv3”。- You Only Look Once (YOLO) 最流行的目标检测算法。
- Huggingface: SDXL and SD Turbo
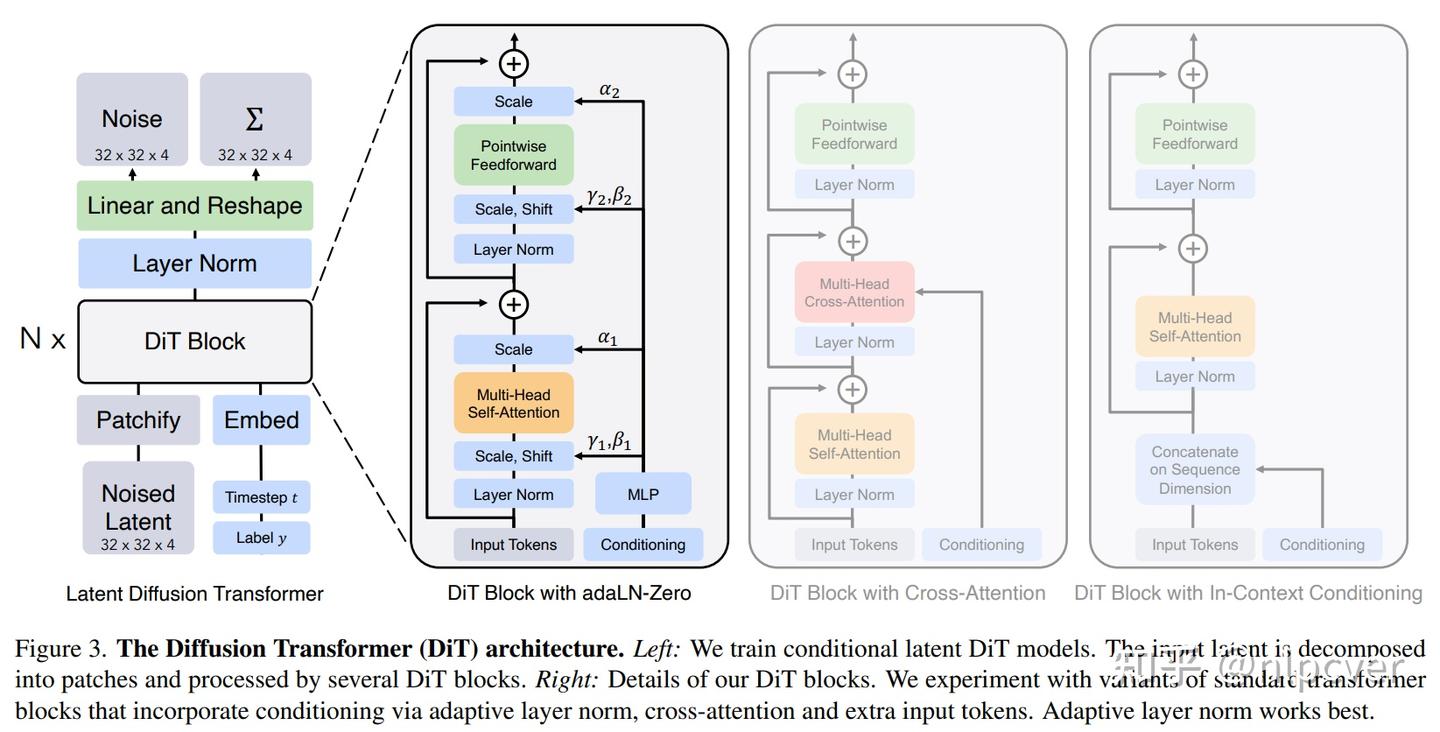
2023 DiTs
- 使用Transformers替换扩散模型中U-Net主干网络,发现不仅速度更快,在许多任务上效果也更好。
- 影响:扩散模型架构中U-Net并非不可替代,并且很容易使用诸如Transformers的结构替代U-Net
202210 Flow Matching(FM)
Flow Matching(FM)是一种训练多模态生成模型的方法,它通过学习与概率路径相关的向量场(Vector Field)来训练模型,并使用ODE求解器来生成新样本。
扩散模型是Flow Matching的一个应用特例,使用FM可以提高其训练的稳定性。原本扩散模型的思想,它依然有“加噪”和“去噪”的概念,只不过FM重新定义了加噪的路径。它把原本杂乱无章、随机性很强的扩散路径,用 Flow Matching 的数学方法归纳成了直线路径。
生成趋势:全面使用
现在业内的共识是:如果你要做大规模视频生成或超高分辨率图像,Flow Matching 是更好的选择。
- 统一性:Flow Matching 的数学公式非常统一。无论你生成的是音频、视频还是文字的 Embedding,都可以用同一套“向量场”理论来处理。
- 算力效率:在视频生成中,每一帧都非常耗资源。Flow Matching 因为路径更直,可以用更少的计算量(Steps)达到同样的质量,这对多模态大模型来说是“救命”的性能提升。
- 兼容性:它完美兼容 Transformer 架构。现在的 DiT (Diffusion Transformer) 架构几乎都在转向 Flow Matching 训练目标。
2022 Stable Diffusion
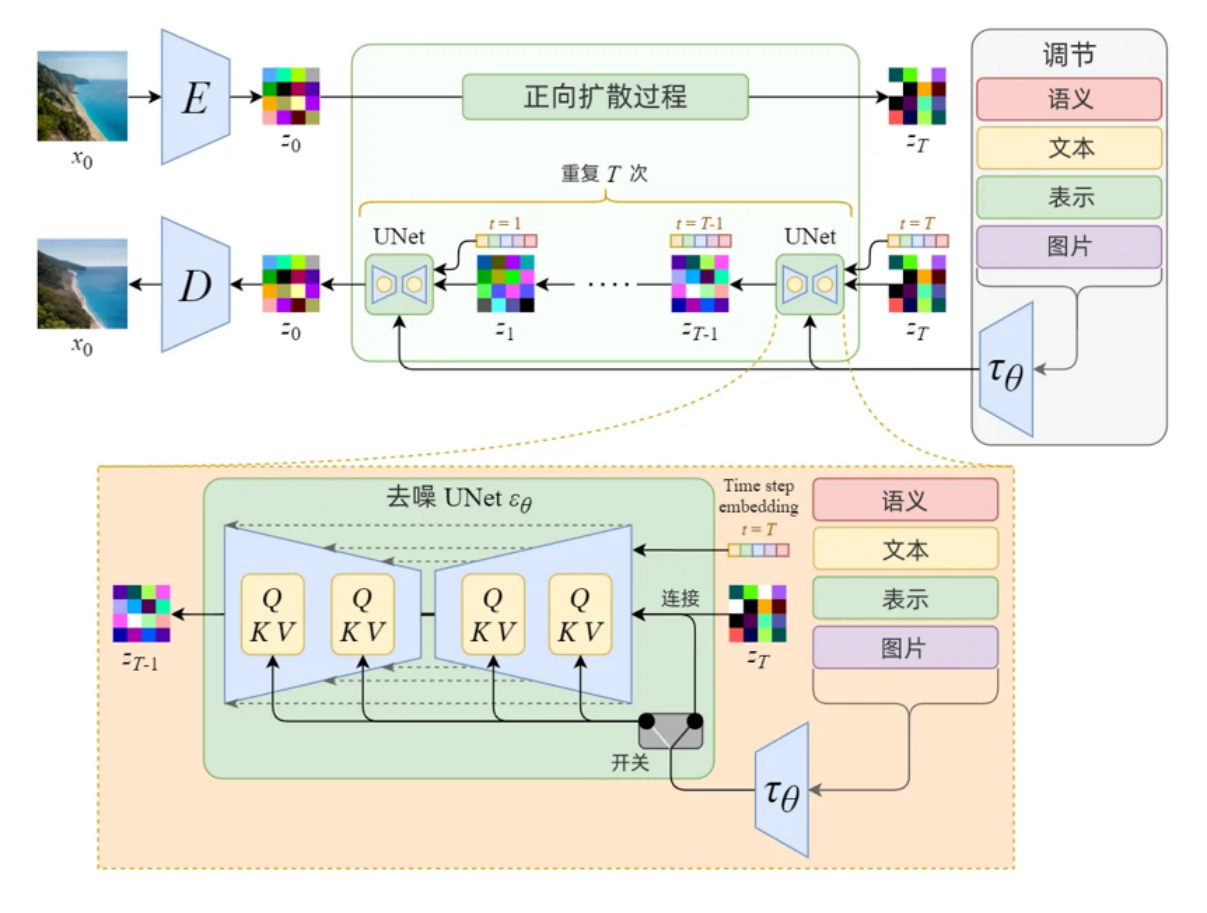
- High-Resolution Image Synthesis with Latent Diffusion Models 是Stable Diffusion开源出来的方法。
- 目的:在Diffusion模型的基础上,使用类似CLIP的text encoder来实现 text to image
- 改进点:
- 如何引入多头Attention,来使得U-Net中文本与图像结合?
- Diffusion的过程移动到被压缩后的图片上(latent space), 使得速度加快很多
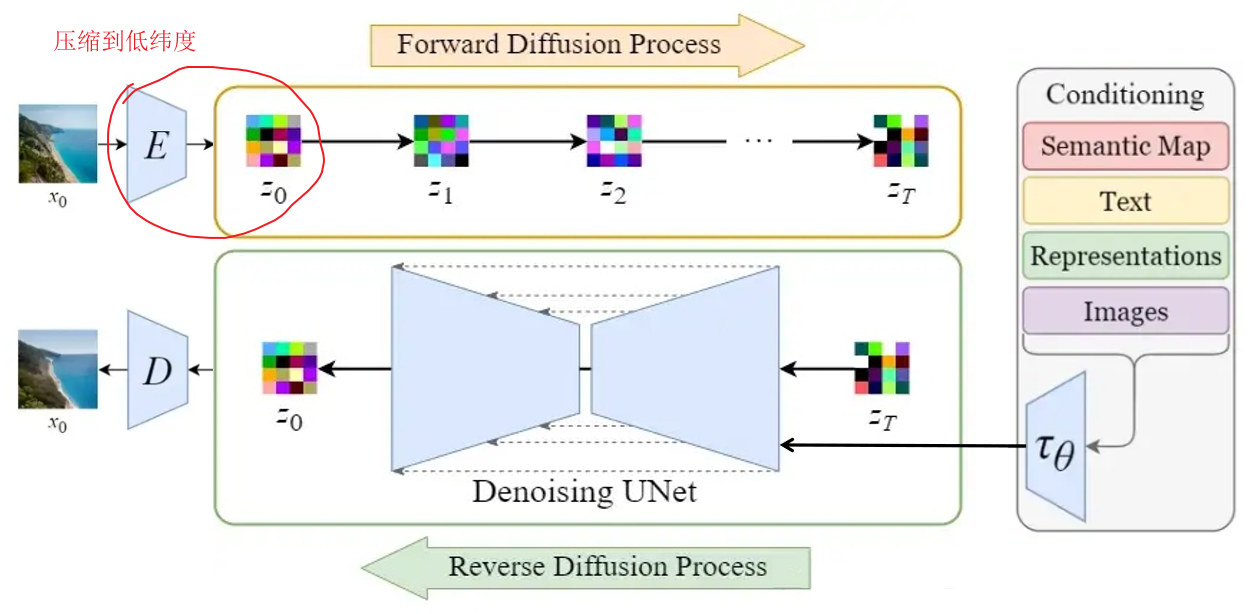
- 原理图例:
 [^6]
[^6] - 详细:
2021 CLIP (对比语言-图像预训练)
- Learning Transferable Visual Models From Natural Language Supervision 是OpenAI提出的用于生成文字embedding的方法
- 目的:借助带文字标签的图片数据集,来学习文字图片间的联系
- 原理图例:
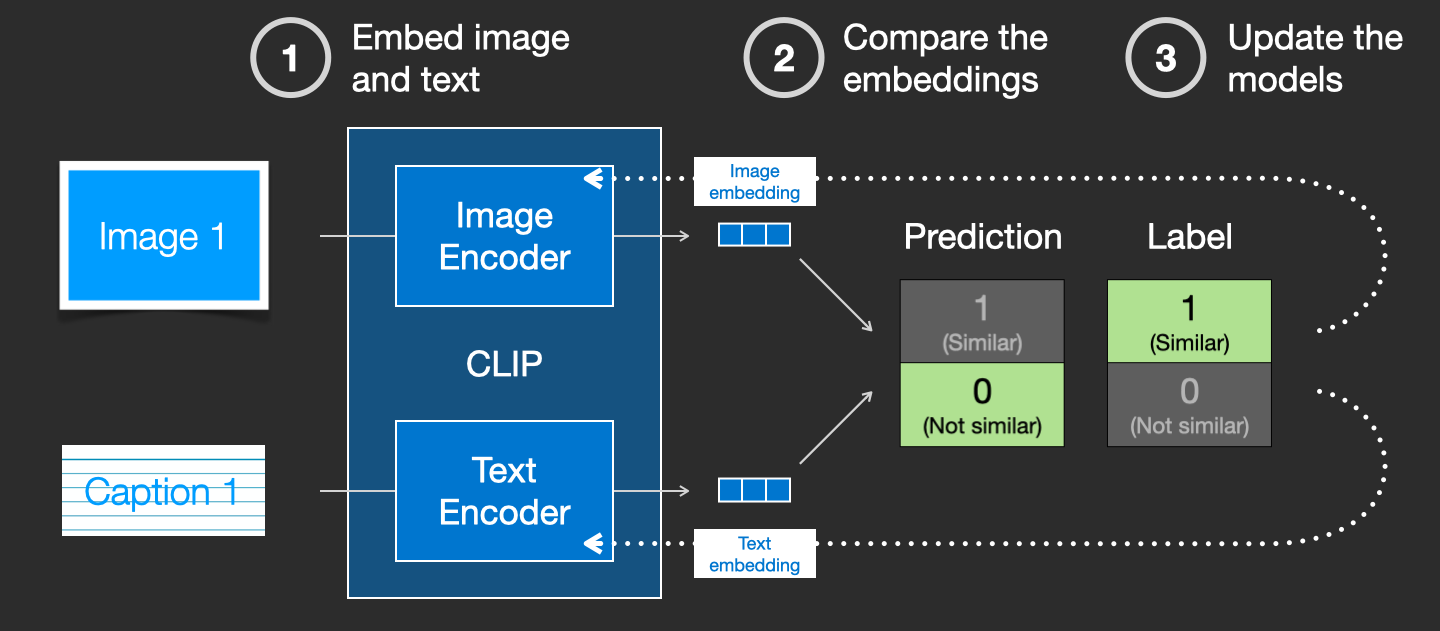 [^6]
[^6]
跨模态的自监督
CLIP 是多模态生成模型的“大脑”,负责连接文字和图像。
- 任务: 丢给模型 1 万张图和 1 万句描述,让它自己找哪句话对应哪张图。这被称为“对比学习”(Contrastive Learning)。
- 为什么是自监督: 它利用的是互联网上现成的“图文对”(比如新闻图片和它的说明文字)。虽然看起来像是有监督(有文字标签),但由于这些标签是数据自带的、未经人工清理的“弱监督”,在算法层面通常被归类为大规模自监督。
- 作用: 它让模型明白“狗”这个词在图像中长什么样,是实现 Prompt 控制生成 的关键。
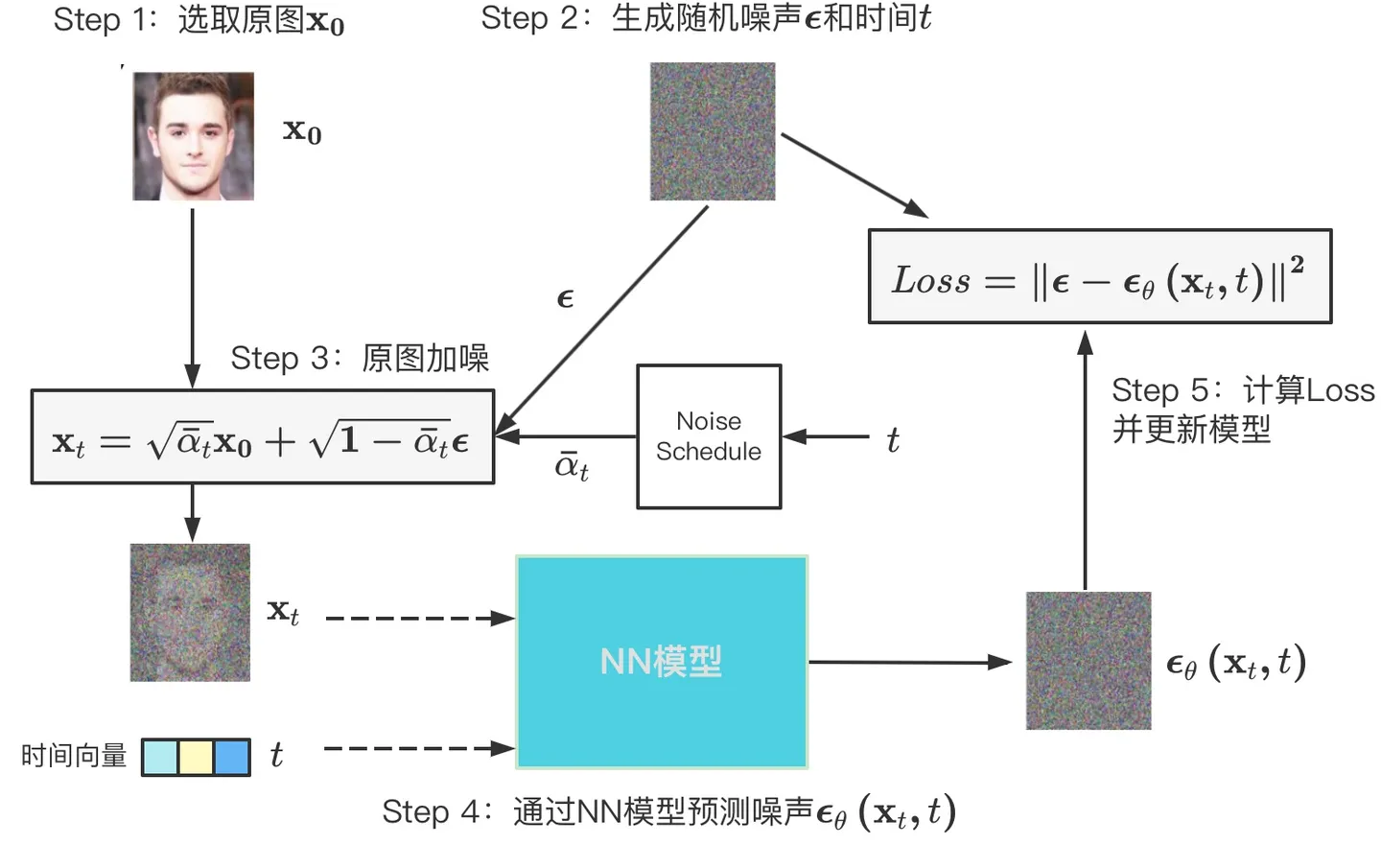
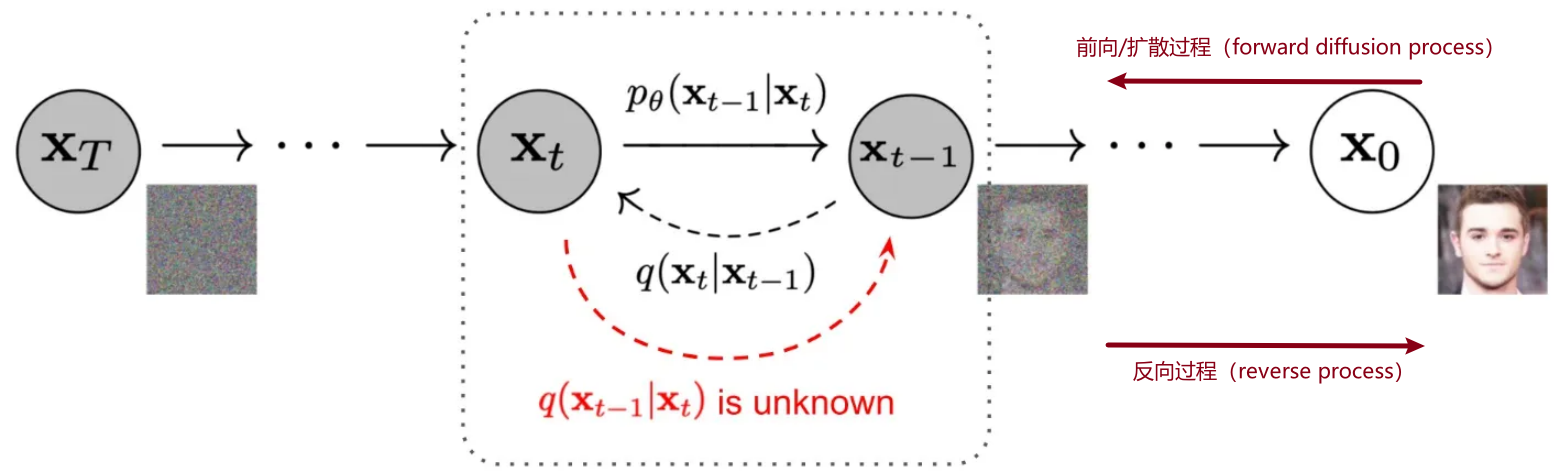
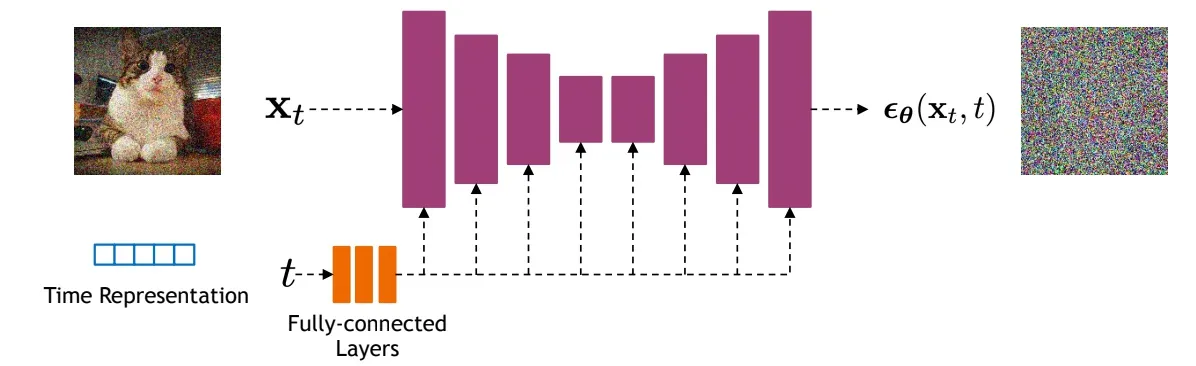
2020 扩散基础 DDPM
- DDPM: Denoising Diffusion Probabilistic Models 提出了扩散模型
- 核心思想:
- GAN也是生成图,但是两者原理完全不同;
- GAN模型通过使得生成器拟合真实图片;
- DDPM是拟合整个从真实图片到随机高斯噪声的过程,再通过反向过程生成新的图片。^4
- 特点:由于是一步步扩散出来的,可以看到演变的中间图过程。
- 训练过程:
- 原理图例:
- 拓展:使用ResNet效果差,一般换成U-Net
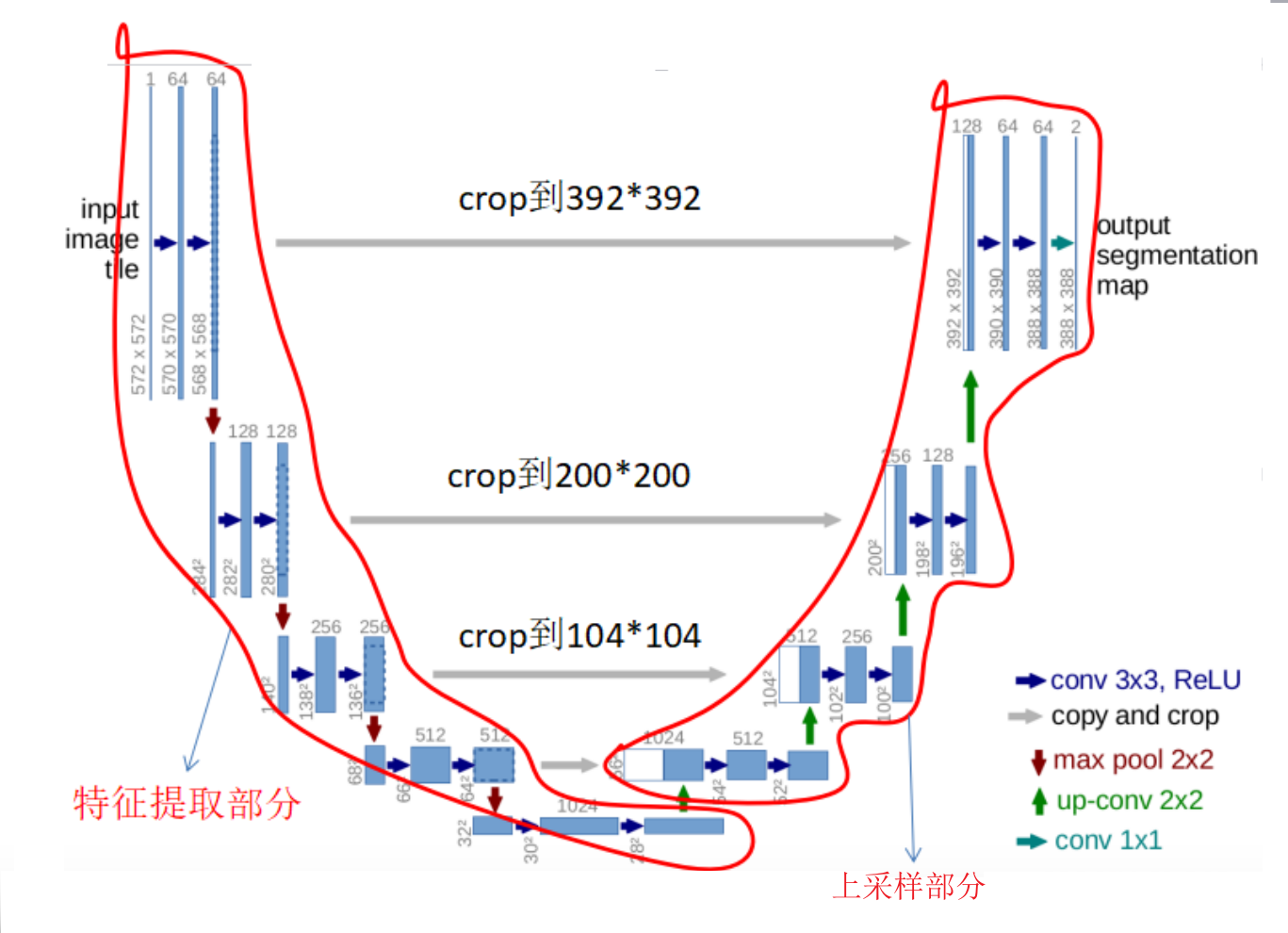
2015 简单图像分割 UNet
- U-Net: Convolutional Networks for Biomedical Image Segmentation是最常用、最简单的一种分割模型了,它简单、高效、易懂、容易构建、可以从小数据集中训练。[^5]
- 目的:医疗影像语义分割任务
- 网络结构:Unet网络非常的简单,前半部分就是特征提取,后半部分是上采样。在一些文献中把这种结构叫做编码器-解码器结构,由于网络的整体结构是一个大些的英文字母U,所以叫做U-net
- Encoder:左半部分,由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块(后面代码可以看出);
- Decoder:有半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成(代码中可以看出来);
- 特点:对于图像语义较为简单、结构固定,并且数据量小的医疗图像,效果好
- 原理图例:
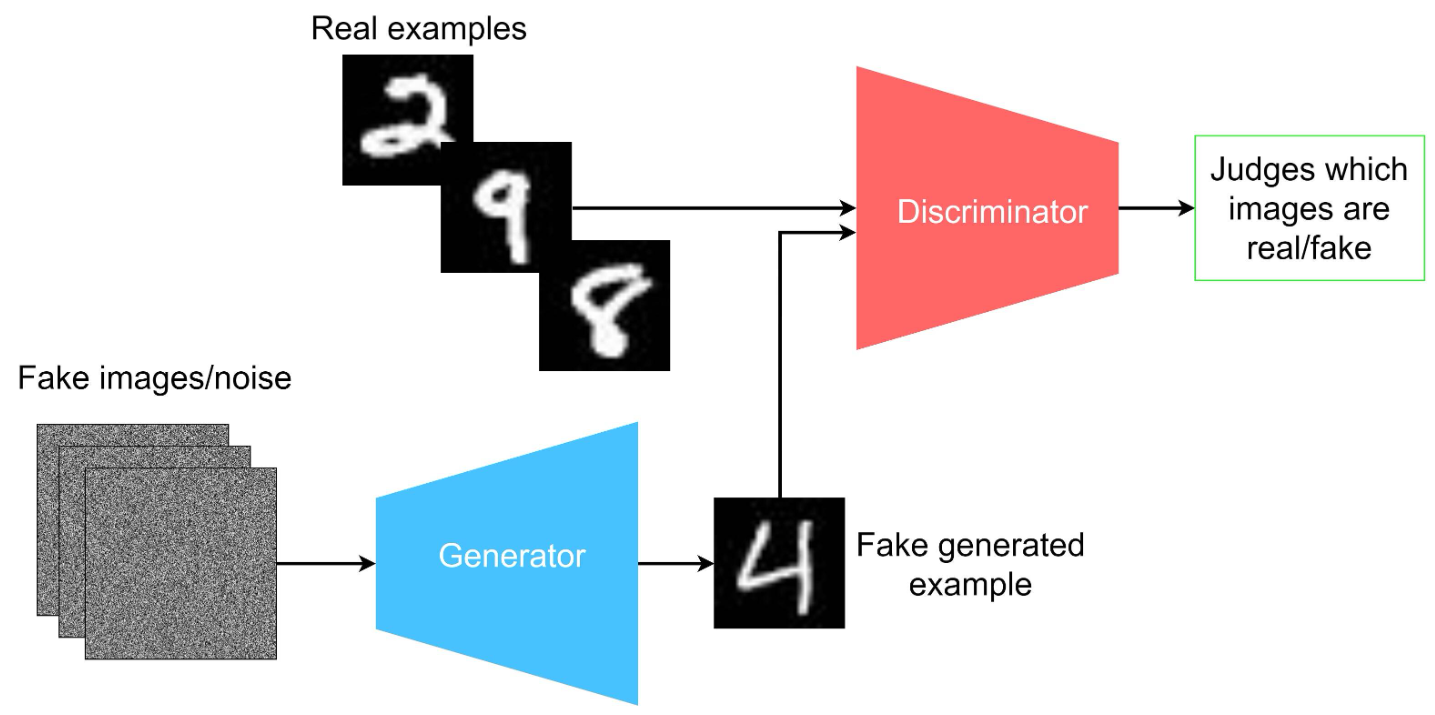
2014 对抗网络 GAN
- generative adversarial network (GAN)是2014年提出的无监督训练方法[^1]
- 目的:给定一个训练集,学习生成与训练集具有相同统计数据的新数据。例如,在照片上训练的GAN可以生成新的照片,这些照片至少在人类观察者看来是真实的,具有许多真实的特征。
- 网络结构:有两个网络,G(Generator)和D(Discriminator)功能分别是:^3
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
- 核心思想:生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。 这意味着generator 没有被训练来最小化到特定图像的距离,而是欺骗了机器人。最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此
D(G(z)) = 0.5。- 换句话来说discriminator保存了generator网络训练出来的复杂loss函数^2
- 数学推导:基于概率论的两个网络的零和博弈(TODO)
- 训练过程:
- 第一步训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。
- 第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。
- 整个训练过程交替进行。
- 推理过程:(猜测的)输入随机噪声,产生图片。
- 拓展:DCGAN将CNN与GAN结合,把上述的G和D换成了两个卷积神经网络(CNN)
- 缺点与局限性:Mode collapse(模式坍塌):generator 生成的图像都特别像。和训练的数据集太像了,导致几乎没有新亮点。
- 原理图例:
概率分布级的自监督
GAN 引入了一种“博弈论”式的自监督。
- 任务: 生成器(Generator)拼命造假图,判别器(Discriminator)拼命识破假图。
- 为什么是自监督: 判别器通过“真实图片”和“生成的假图”之间的差异来学习,整个系统不需要外部标注,只需要一堆原始数据即可。
- 作用: GAN 擅长处理细节和清晰度,现在的 Flow Matching 模型在最后一步往往会挂载一个类似 GAN 的 Decoder 来确保图像边缘锐利。
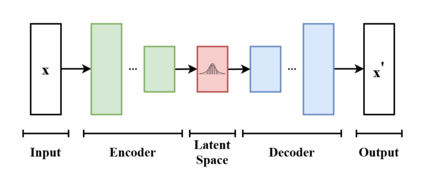
2013 VAE
- VAE(Variational Autoencoder,变分自编码器)是一种生成模型,结合了概率图模型和深度学习,主要用于学习数据的潜在表示并生成新数据。
- VAE属于概率生成模型(Probabilistic Generative Model),神经网络仅是其中的一个组件,依照功能的不同又可分为编码器和解码器。
- 编码器可将输入变量映射到与变分分布的参数相对应的潜空间(Latent Space),这样便可以产生多个遵循同一分布的不同样本。
- 解码器的功能基本相反,是从潜空间映射回输入空间,以生成数据点。
- 影响:变分自编码器(VAE)是一类常见的生成模型。纯VAE的生成效果不见得是最好的,但VAE还是经常会被用作大模型的子模块。
像素级的自监督
VAE 是多模态生成中的“压缩机”。它的预训练任务是“自己重建自己”。
- 任务: 把一张高分辨率图片压缩成一个很小的数学向量(编码),再想办法把它还原回原图(解码)。
- 为什么是自监督: 不需要任何人工标签。原图既是输入,也是“正确答案”。
- 作用: 它是生成模型(如 SD, Flux)的底层,让模型不需要在繁琐的像素空间工作,而是在更高效的“潜空间”(Latent Space)里生成。
参考文献
[^1]: GAN wiki
[^5]: 图像分割必备知识点 | Unet详解 理论+ 代码
[^6]: The Illustrated Stable Diffusion
[^7]: 深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
[^14]: 通俗易懂理解Flow Matching
[^15]: WAN : OPEN AND ADVANCED LARGE-SCALE VIDEO GENERATIVE MODELS
[^16]: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
[^17]: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
[^18]: z-image 知乎
[^19]: Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
[^21]: FLUX.2: Analyzing and Enhancing the Latent Space of FLUX – Representation Comparison
[^22]: Qwen新作 | 还在为AI修图“一改全崩”而头疼?QwenImage-Layered,用“图层思维”让编辑零误差!
https://arxiv.org/pdf/2405.18991
https://blog.csdn.net/weixin_48534929/article/details/139430996
https://blog.csdn.net/weixin_44791964/article/details/139223972?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_44791964/article/details/140025591?spm=1001.2014.3001.5502