Huawei Ascend Domain-Specific Architectures : DaVinci
DaVinci 架构
初衷
达芬奇架构追求的是一个全场景的scalable设计,以一个通用的硬件架构,实现从低端到高端的全覆盖。[^9]
- “unified”: basic instruction set
- “scalable”: as efficient extensions from the core to SOC to server to cluster.
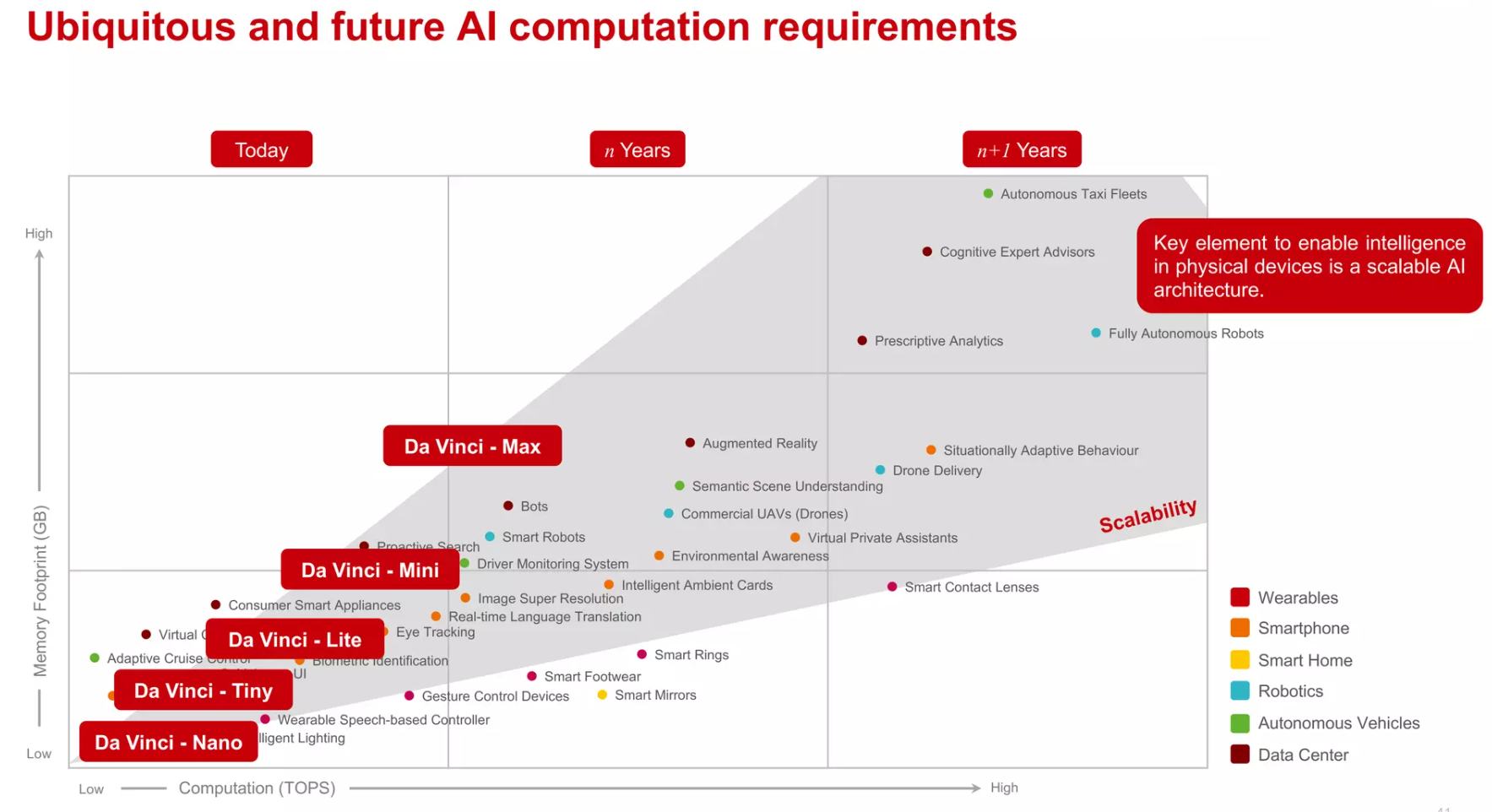 [^10]
[^10]
- IP camera, 网络监视器
- Drones, 无人机
Special Compute Unit : Cube Unit
面对矩阵乘密集的应用,相对于Vector的计算单元,能实现相同芯片面积,有8.63倍的计算峰值性能提升。[^10] In the actual design, we flat the 3D cube’s layout to 2D to arrange it on the silicon die.[^7]
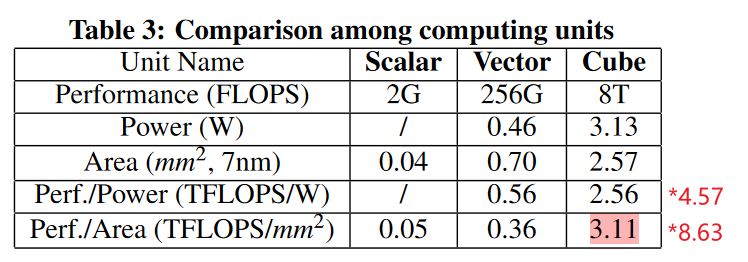 [^7]
[^7]
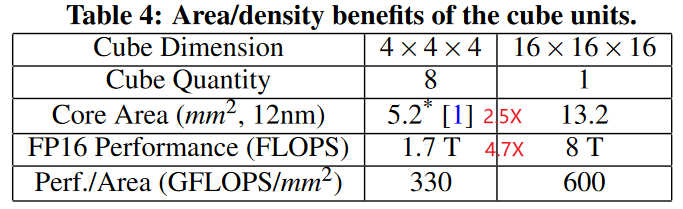
Nevertheless, if the cube gets larger, such as 32 ×32 ×32 , it becomes inefficient due to lower MAC utilization in several neural networks.
Da Vinci Core Architecture
相对于GPGPU,Da Vinci是类似Google TPU的DSA设计:(区别于GPGPU大道至简的设计感)
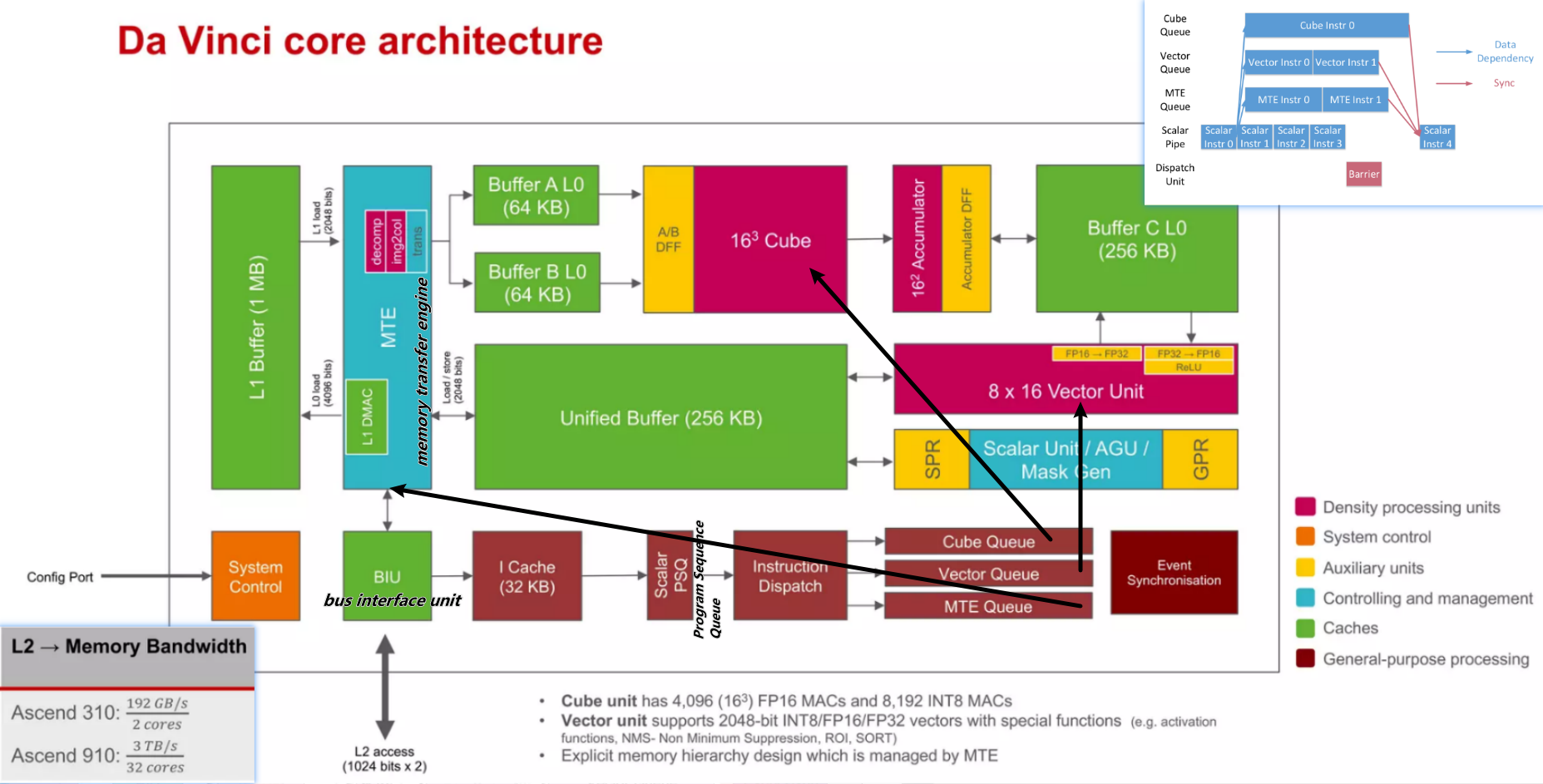 [^10]
[^10]
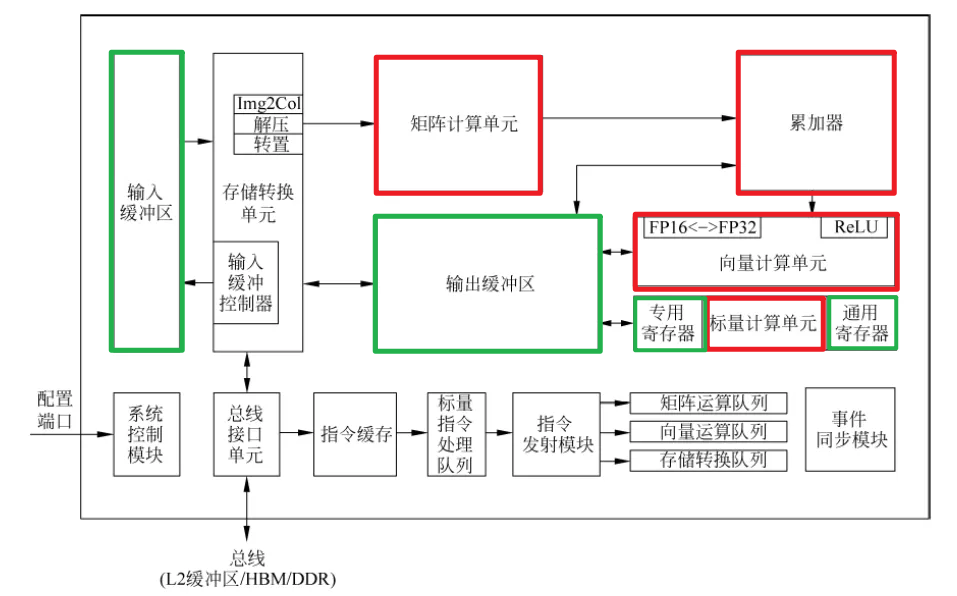
特点:
- heterogeneous computing units
- 初衷:既然大家都喜欢CPU(Scalar)+GPU(SIMD)等灵活异构计算,我们为什么不把它们做在一个chip上呢?
- 多种计算单元(张量、向量和标量)三种常见的计算模式,在实际的计算过程中各司其职,形成了三条独立的执行流水线。
- scalar负责控制流和简单运算,相当于通用的CPU^12
- vector来解决MAC矩阵所不擅长的pooling,activation等卷积和全连接之后的后处理运算(operation fusion,和TPU以及NVDLA的结构类似)
- cube加速规整的矩阵操作
- 多种Buffer(整理计算单元数据)
Buffer A L0,Buffer B L0, andBuffer C L0.是cube单元的专属Buffer。- 多buffer的设计有可能是为了减少数据加载和保存时的延迟,以及提高数据处理过程中的并行性。每个缓冲区都可能专门针对不同类型的数据或处理阶段进行优化。
- 与谷歌TPU设计中的统一缓冲区设计理念相类似,AI Core采用了大容量的片上缓冲区设计,通过增大的片上缓存数据量来减少数据从片外存储系统搬运到AI Core中的频次,从而可以降低数据搬运过程中所产生的功耗,有效控制了整体计算的能耗。
- MTE加速数据准备:
- The
decompmodule decompresses the data for sparse network, with the help of Zero-Value Compression like algorithms. Theimg2colmodule is applied to transfer convolution to matrix multiplication. And thetransmodule transposes the matrix. - MTE的作用可能是优化和管理内存访问模式,减少CPU的负担,提高整体数据处理效率。MTE可以处理复杂的内存操作,如数据重排(tiling)、转置等,这些在深度学习计算中很常见。
- 这是达芬奇架构的特色之一,主要的目的是为了以极高的效率实现数据格式的转换。比如前面提到GPU要通过矩阵计算来实现卷积,首先要通过Im2Col的方法把输入的网络和特征数据重新以一定的格式排列起来。这一步在GPU当中是通过软件来实现的,效率比较低下。达芬奇架构采用了一个专用的存储转换单元来完成这一过程,将这一步完全固化在硬件电路中,可以在很短的时间之内完成整个转置过程。由于类似转置的计算在深度神经网络中出现的极为频繁,这样定制化电路模块的设计可以提升AI Core的执行效率,从而能够实现不间断的卷积计算。^11
- 输入数据从总线接口读入后就会经由存储转换单元进行处理。MTE(存储转换单元)作为AI Core内部数据通路的传输控制器,负责AI Core内部数据在不同缓冲区之间的读写管理,以及完成一系列的格式转换操作,如补零,Img2Col,转置、解压缩等。存储转换单元还可以控制AI Core内部的输入缓冲区,从而实现局部数据的缓存。
- The
- Register File上图不直接展示,是计算单元内部的一部分。
数据通路 Datapath
多级存储与计算单元的关系:
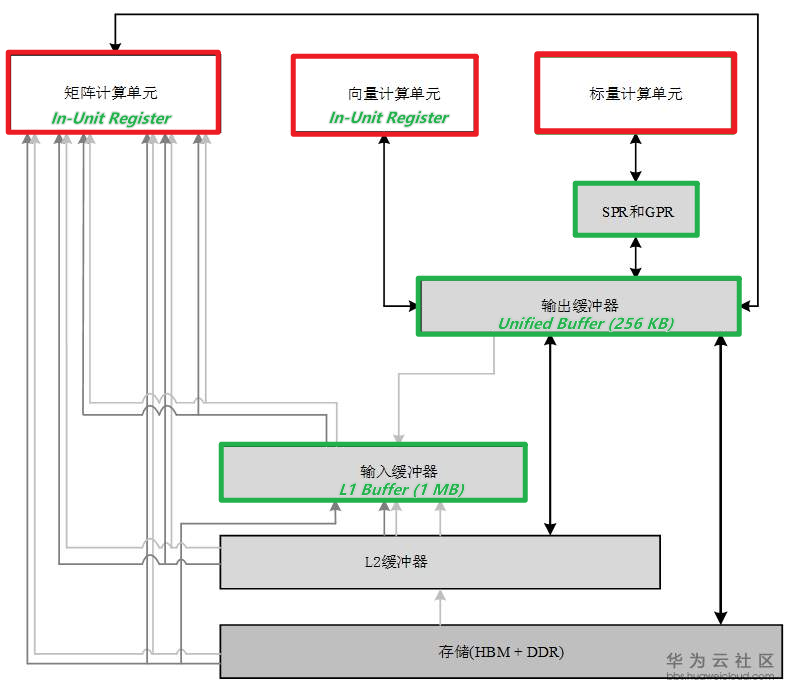
达芬奇架构数据通路的特点是多进单出。
- 数据流入AI Core可以通过多条数据通路:
- 可以从外部直接流入矩阵计算单元、
- 输入缓冲区
- 和输出缓冲区中的任何一个,流入路径的方式比较灵活,在软件的控制下由不同数据流水线分别进行管理。
- 数据输出则必须通过输出缓冲区,最终才能输出到核外存储系统中。不能直写DRAM。
疑问:
- 貌似没有warp概念,那么SIMT还是存在的吗?
- 最核心的运算还是在cube,主要面向流行的深度学习算法,在其他AI算法上使用vector和scalar运算,算力比cube低不少,因此这类算法的性能是低于SIMT结构的GPU的。^12
- Da Vinci架构可能有自己的方式来组织和同步工作项(work-items)或线程组(thread-groups)。
- 貌似论文后半部分有讨论[^7]
Micro-architecture Exploration
SADS: Same Architecture, targeting Different Scenarios
初衷:面对AI模型的多样性:The behavior and resource demands differ substantially from model to model and even layer to layer. 如何设计微调的微架构(select proper configurations)来适应不同的应用场景(targeting different scenarios)。
思想:optimal resource balance among different components of the core architecture.
TODO
小结
对于DSA来说的通用思路:
- Massive dedicated Processing elements (PEs) 是加速common operation的常用方法。
- To match computing throughput, the memory hierarchy is optimized for data reuse exploration.[^7]
AI编译器:达芬奇的整体结构是经指令执行的众核系统,它将三种运算类型集成一体的思路很好的体现了专用型和灵活性。但是如何高效的使用这三种运算资源以及存储调度,这个就非常考验软件和编译的实力了。华为最大的优势其实是作为系统供应商的软硬件结合设计的能力,这一点和Google、Amazon发展自定义的AI加速器是同样的道理。通过云端收集数据进行反馈调整,反复迭代升级,不断完善硬件对基本算子的良好支持和软件编译的高效性和友好性,最终形成生态闭环。期待华为在AI领域再创辉煌。^12
历代产品
Ascend 310
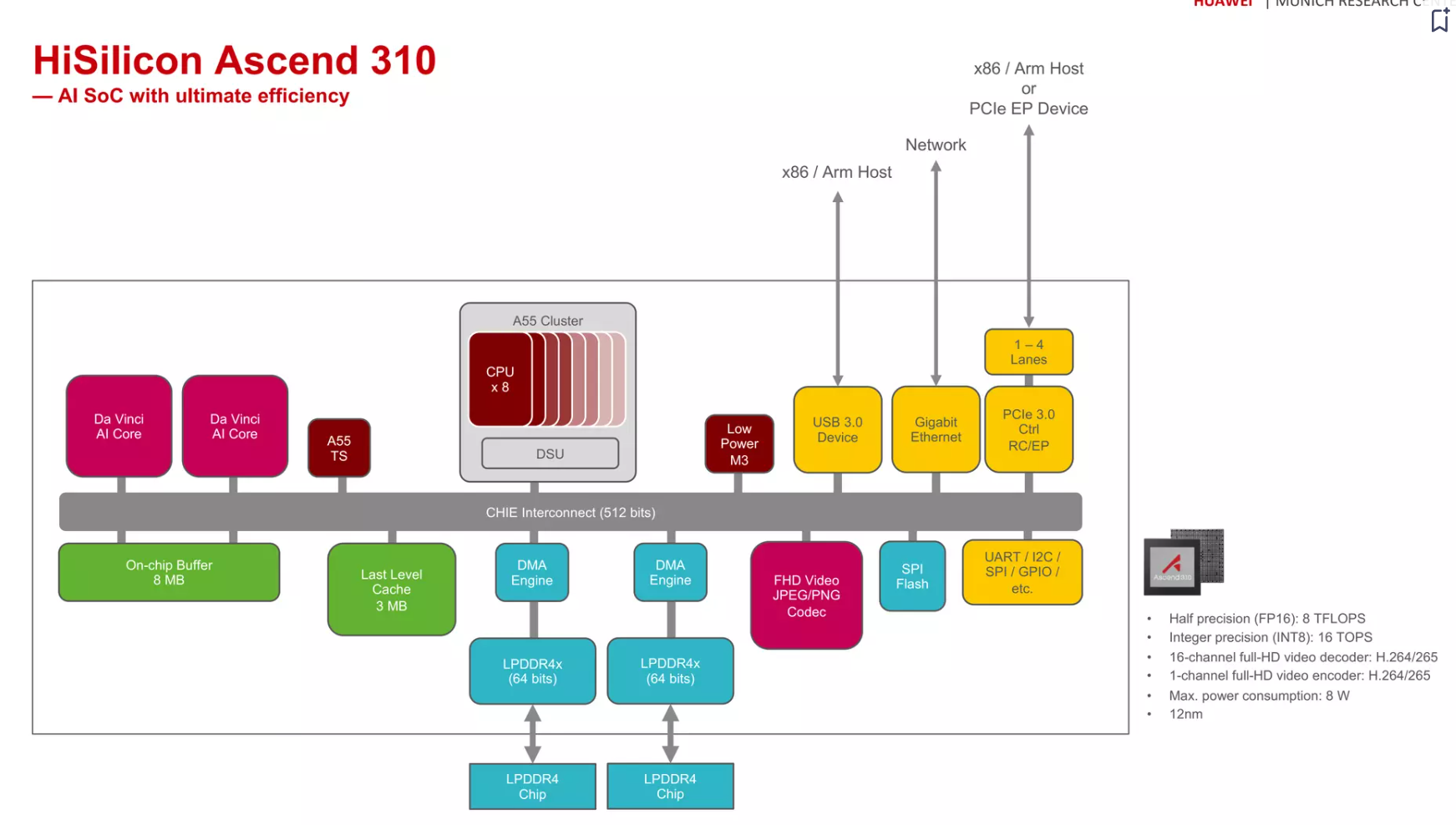 [^10]
[^10]
Ascend 910
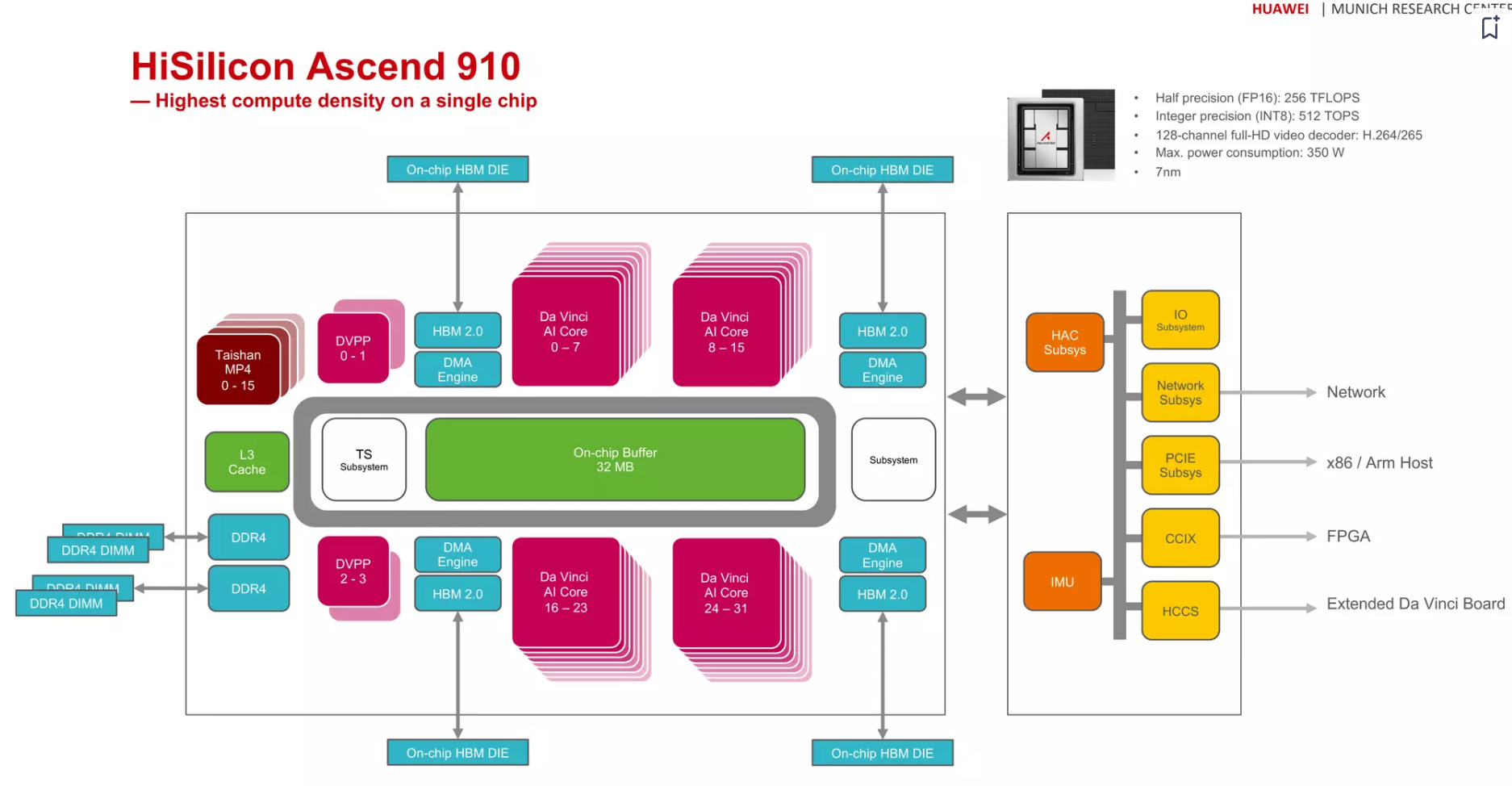 [^10]
[^10]
2023年 Ascend 910B
- 在2019年发布了异腾910。基于异腾910,华为做了一款训练服务器,命名为
Atlas800-9000。这款训练服务器主要分两个配置,一个是四颗芯片的半配,另一个是八颗芯片的满配。半配方案之间的两个NPU板子是通过PCle进行互联的。(来自韭研公社APP) - 最近,华为发布了910B的芯片,其与上一代的区别是
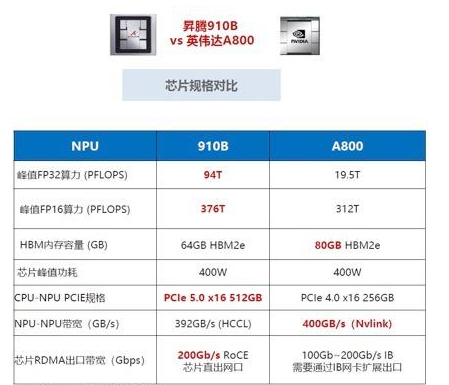
- FP32的性能提升。
- 910B将八个NPU模组互联互通,同时每个NPU模组提供了56GB的HCCS的双向带宽。模组间的互联带宽传输速度是
392GB/s,与英伟达A100400GB/s的NVLink带宽基本持平。同时,910B芯片植入200G的网口,上一代是100G。(来自韭研公社APP)
横向对比
与 NVIDIA 术语对应关系
大部分人目前还是对 NVIDIA GPU 更熟悉,所以先做一个大致对照,方便快速了解华为 GPU 产品和生态[^8]:
| NVIDIA | HUAWEI | 功能 |
|---|---|---|
| GPU | NPU: Neural-network Processing Unit/GPU | 通用并行处理器 |
| NVLINK | HCCS: Huawei Cache Coherence System | GPU 卡间高速互连技术 |
| HCCL(Huawei Collective Communication Library) | 基于昇腾AI处理器的高性能集合通信库,提供单机多卡、多机多卡集合通信原语 | |
| InfiniBand | HCCN: Huawei Cache Coherence Network | RDMA 产品/工具 |
nvidia-smi |
npu-smi |
GPU 命令行工具 |
| CUDA | CANN: Compute Architecture for Neural Networks | GPU 编程库 |
与 NVIDIA GPU的参数比较
芯片禁令的机遇
- 2023年,华为从中国主要互联网公司获得了至少5000个Ascend 910B芯片的订单。该芯片被认为是与英伟达被禁止出口的高性能A100芯片最接近的中国替代产品。消息人士说,由于美国的制裁,华为面临生产限制,这些芯片的交付期将持续到2024年。^3
- 中国的官方采购,如国有电信运营商的采购,都要求采用华为等国产芯片。根据公司采购文件,中国电信在10月份采购了价值约3.9亿美元、采用华为芯片的人工智能服务器,而中国联通在2022年至少花费了2000万美元。上述人士表示,华为已加大力度拓展其软件生态系统,并计划最快于2024年下半年推出新的高端人工智能芯片。自2022年美国实施限制以来,一些政府支持的人工智能计算中心已采购了华为的芯片。
- 2023年11月8日消息,据国内媒体报道称,百度为200台服务器订购了1600片昇腾910B AI芯片。到10月份,华为已向百度交付了超过60%的订单。
当前的社会评价
目前在大模型推理方面,国内 AI 芯片910B仅能达到A100的60%-70%左右,集群的模型训练难以为继;同时,910B在算力功耗、发热等方面远高于英伟达A100/H100系列产品,且无法兼容CUDA,很难完全满足长期智算中心的模型训练需求。[^4]
整体来看,如果大模型企业要进行GPT-4这类参数的大模型训练,算力集群规模则是核心,目前只有H800、H100可以胜任大模型训练,而国产910B的性能介于A100和H100之间,只是“万不得已的备用选择”。
如今英伟达推出的新的H20,则更适用于垂类模型训练、推理,无法满足万亿级大模型训练需求,但整体性能略高于910B,加上英伟达CUDA生态,从而阻击了在美国芯片限制令下,国产卡未来在中国 AI 芯片市场的唯一选择路径。
国内的AI芯片公司
目前,国产AI相关芯片企业有寒武纪、景嘉微、海光信息、百度昆仑、阿里含光、燧原、沐曦、壁仞、摩尔线程、天数智芯等,不过,能够进行大模型预训练的芯片,仍只有华为、海光等寥寥数家。[^5]
参考文献
[^4]: 英伟达阻击国产 AI 芯片,“中国特供版”H20综合算力比H100降80%
[^5]: 英伟达“退场” 华为新一代昇腾910B蓄势待发,已进入规模商业化前夜
[^7]: Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing, HPCA, 2021
[^8]: GPU 进阶笔记(二):华为昇腾 910B GPU 相关(2023)
[^9]: DaVinci: A Scalable Unified Architecture for Neural Network Computing from Nano-level to High Performance Computing, Liao Heng, Huawei, PPT is here
[^10]: Da Vinci - A scaleable architecture for neural network computing (updated v4)
Huawei Ascend Domain-Specific Architectures : DaVinci
http://icarus.shaojiemike.top/2024/01/10/Work/Architecture/GPU/huaweiDaVinci/