Bridging the Gap: Challenges and Trends in Multimodal RL.
多模态理解模型+RL井喷
GRPO出现之后,基于GRPO及其变种(DAPO、VAPO)井喷出一系列模型。[^1]
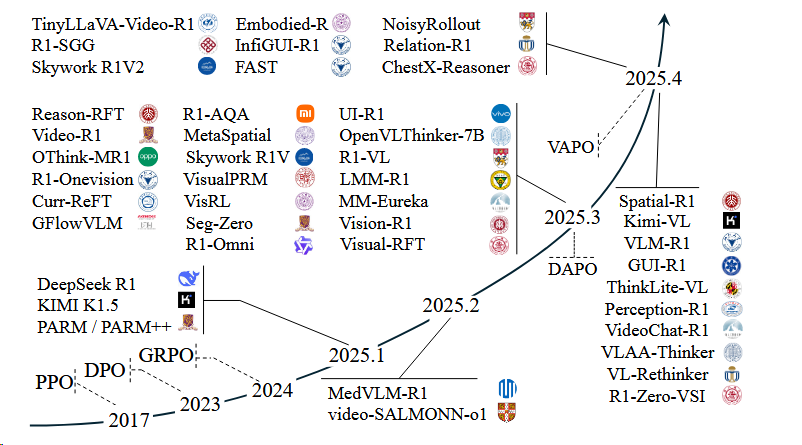
RL算法趋势
在强化学习(RL)的应用中,特别是在多模态大语言模型(MLLMs)的理解能力增强中,常常提到两种主要的RL训练范式:价值模型无关的方法(value-model-free methods)和价值模型相关的方法(value-model-based methods)[^1]。这两种方法的主要区别在于它们是否依赖于价值函数的显式建模。
价值模型无关的方法
(value-model-free methods)这类方法不依赖于价值函数或者模型来估计未来奖励。它们直接通过策略梯度(policy gradient)来优化策略,即通过直接评估策略(policy)对应的行为(action)的概率分布,并根据奖励信号来调整这个分布。这种方法的代表算法是Group Relative Policy Optimization (GRPO)[^11]。
- GRPO:在GRPO中,策略的更新不依赖于价值函数的估计,而是通过比较组内不同的输出响应(samples)来计算优势函数(advantage function),然后基于这个优势函数来更新策略。这种方法的优势在于实现简单,不需要额外的价值模型训练,能够稳定地进行策略优化。
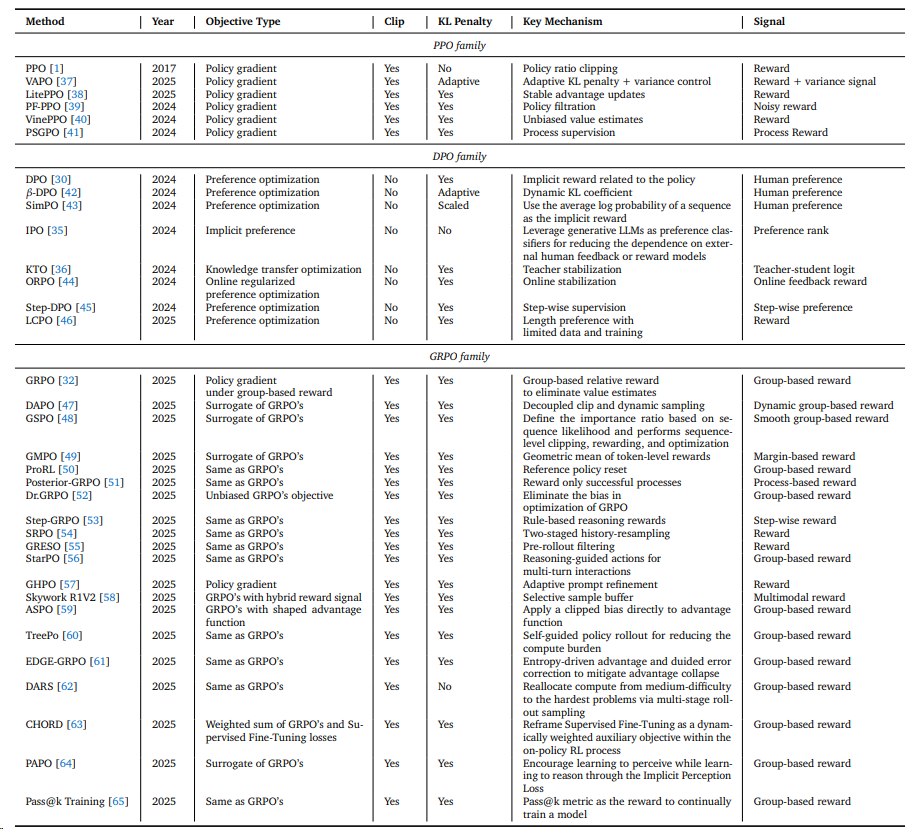
下表的主体内容来自^14:
| Method | Year | Objective Type | Clip | KL Penalty | Key Mechanism | Signal | Link | Resource |
|---|---|---|---|---|---|---|---|---|
| GRPO family | ||||||||
| GRPO | 2025 | Policy gradient under group-based reward | Yes | Yes | Group-based relative reward to eliminate value estimates | Group-based reward | Paper | - |
| DAPO | 2025 | Surrogate of GRPO’s | Yes | Yes | Decoupled clip + dynamic sampling | Dynamic group-based reward | Paper | Code Model Website |
| GSPO | 2025 | Surrogate of GRPO’s | Yes | Yes | Sequence-level clipping, rewarding, optimization | Smooth group-based reward | Paper | - |
| GMPO | 2025 | Surrogate of GRPO’s | Yes | Yes | Geometric mean of token-level rewards | Margin-based reward | Paper | Code |
| ProRL | 2025 | Same as GRPO’s | Yes | Yes | Reference policy reset | Group-based reward | Paper | Model |
| Posterior-GRPO | 2025 | Same as GRPO’s | Yes | Yes | Reward only successful processes | Process-based reward | Paper | - |
| Dr.GRPO | 2025 | Unbiased GRPO objective | Yes | Yes | Eliminate bias in optimization | Group-based reward | Paper | Code Model |
| Step-GRPO | 2025 | Same as GRPO’s | Yes | Yes | Rule-based reasoning rewards | Step-wise reward | Paper | Code Model |
| SRPO | 2025 | Same as GRPO’s | Yes | Yes | Two-staged history-resampling | Reward | Paper | Model |
| GRESO | 2025 | Same as GRPO’s | Yes | Yes | Pre-rollout filtering | Reward | Paper | Code Website |
| StarPO | 2025 | Same as GRPO’s | Yes | Yes | Reasoning-guided actions for multi-turn interactions | Group-based reward | Paper | Code Website |
| GHPO | 2025 | Policy gradient | Yes | Yes | Adaptive prompt refinement | Reward | Paper | Code |
| Skywork R1V2 | 2025 | GRPO with hybrid reward signal | Yes | Yes | Selective sample buffer | Multimodal reward | Paper | Code Model |
| ASPO | 2025 | GRPO with shaped advantage | Yes | Yes | Clipped bias to advantage | Group-based reward | Paper | Code Model |
| TreePo | 2025 | Same as GRPO’s | Yes | Yes | Self-guided rollout, reduced compute burden | Group-based reward | Paper | Code Model Website |
| EDGE-GRPO | 2025 | Same as GRPO’s | Yes | Yes | Entropy-driven advantage + error correction | Group-based reward | Paper | Code Model |
| DARS | 2025 | Same as GRPO’s | Yes | No | Multi-stage rollout for hardest problems | Group-based reward | Paper | Code Model |
| CHORD | 2025 | Weighted GRPO + SFT | Yes | Yes | Auxiliary supervised loss | Group-based reward | Paper | Code |
| PAPO | 2025 | Surrogate of GRPO’s | Yes | Yes | Implicit Perception Loss | Group-based reward | Paper | Code Model Website |
| Pass@k Training | 2025 | Same as GRPO’s | Yes | Yes | Pass@k metric as reward | Group-based reward | Paper | Code |
| IGPO | 2025 | Same as GRPO’s | Yes | Yes | 在dLLM(扩散语言模型)里引入生成片段(Inpainting-Guided Policy Optimization)来避免GRPO低正确率时的奖励稀疏问题 | Group-based reward | Paper | |
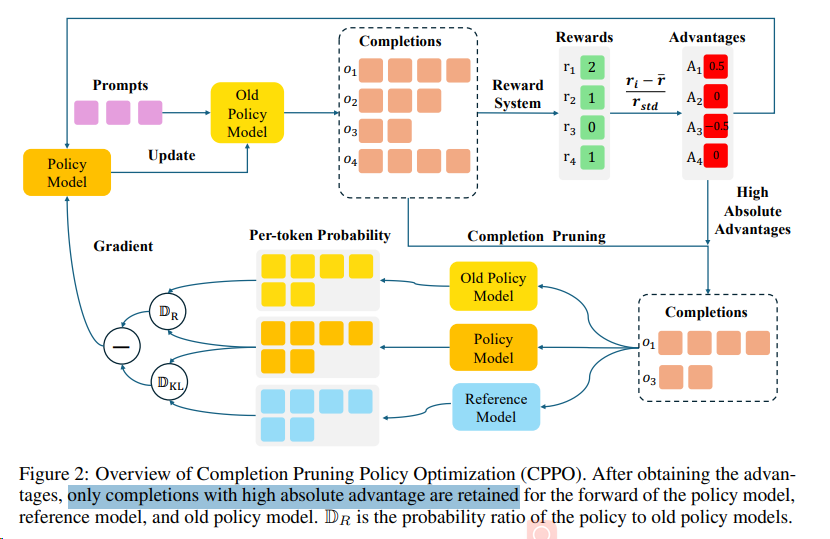
| CPPO | 2025 | Same as GRPO’s | Yes | Yes | Completion Pruning | Group-based reward | Paper |
剪枝方案
- CPPO 通过分析发现,并不是所有的完成对于策略训练都有相同的贡献,其贡献程度与它们的相对优势有关。因此,CPPO 提出了一种基于绝对优势的完成剪枝策略,大幅减少了梯度计算和更新所需的完成数量。
- Bottom-up Policy Optimization (BuPO) 提出 Transformer层的残差连接机制中任意 隐藏状态 H通过解嵌入矩阵 Eu 转换为词汇概率分布,可以视作一种可被平均的内部策略policy,来提前作为RL的目标。
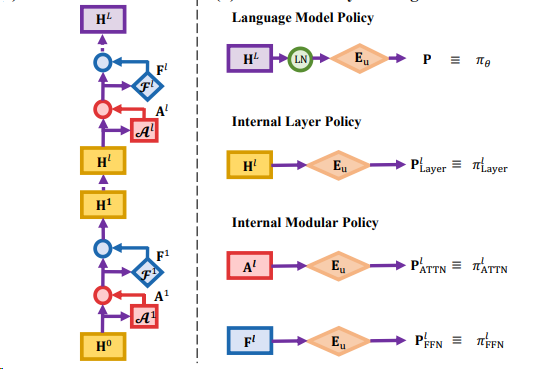
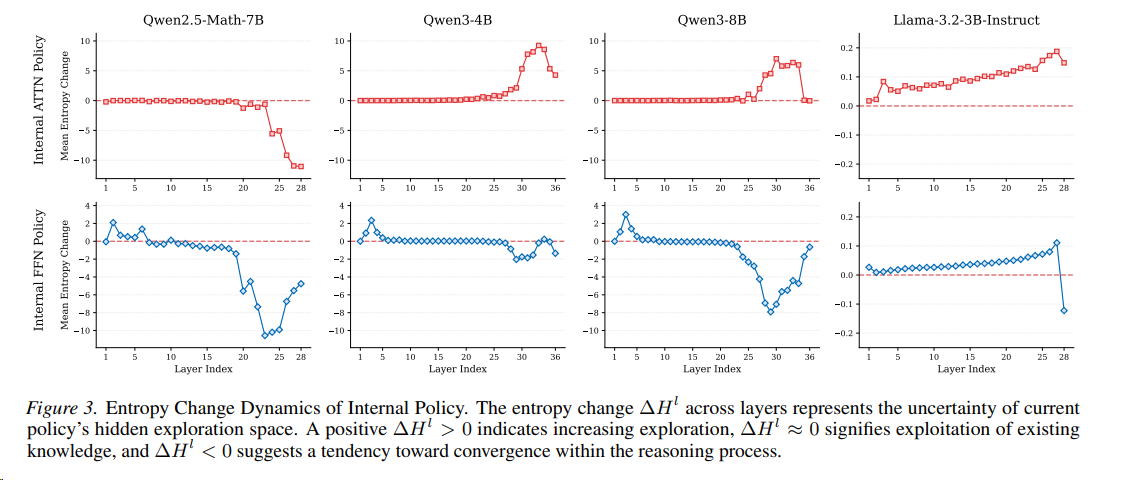
Transformer模型的每一层都承担特定功能,这种分工在Qwen3中表现为清晰的三阶段推理模式:
探索扩展(Lower Layers)
- 熵增(ΔH_FFN > 0):底层FFN模块主动扩展解空间,通过高熵状态探索多种可能的推理路径。
- 功能:类似人类的“初步联想”,例如数学问题中尝试不同公式或逻辑关系。
知识整合(Middle Layers)
- 熵稳定(ΔH_FFN ≈ 0):中间层聚焦于整合参数化知识(如事实、规则),抑制无关信息,保持推理稳定性。
- 功能:调用预训练知识库(如“圆周率π≈3.14”),过滤错误假设。
预测收敛(Higher Layers)
- 熵减(ΔH_FFN < 0):顶层压缩解空间,逐步收敛到高概率答案。
- 功能:类似“最终决策”,例如确定数学题的唯一正确解。
Llama的FFN模块在多数层保持高熵探索,缺乏中间整合阶段,导致推理效率较低。
Qwen3的三阶段结构更接近人类认知:发散思考→ 逻辑整合→ 精确结论。
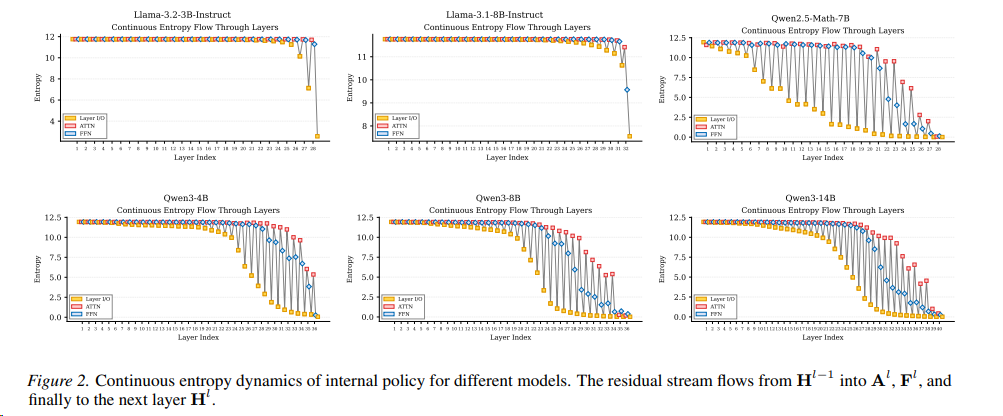
但是直接使用中间policy会导致策略的不稳定,最终实现渐进和全层策略的方法,能实现更大范围的探索。
价值模型相关的方法
与价值模型无关的方法不同,价值模型相关(value-model-based methods)的方法会估计一个价值函数来预测未来的累积奖励。这种方法通常会结合价值函数和策略梯度来更新策略,能够提供更为精确的奖励估计,从而优化策略。代表性的算法包括Proximal Policy Optimization (PPO)[^7]。
- PPO:PPO是一种结合了价值函数和策略梯度的算法。它通过优化一个代理的价值函数来估计当前策略下的状态值,并结合这个价值估计来更新策略。PPO的关键在于通过一个辅助的价值函数来稳定训练过程,并提高训练的样本效率。
下表的主体内容来自^14:
| Method | Year | Objective Type | Clip | KL Penalty | Key Mechanism | Signal | Link | Resource |
|---|---|---|---|---|---|---|---|---|
| PPO family | ||||||||
| PPO | 2017 | Policy gradient | Yes | No | Policy ratio clipping | Reward | Paper | - |
| PF-PPO | 2024 | Policy gradient | Yes | Yes | Policy filtration | Noisy reward | Paper | Code |
| VinePPO | 2024 | Policy gradient | Yes | Yes | Unbiased value estimates | Reward | Paper | Code |
| PSGPO | 2024 | Policy gradient | Yes | Yes | Process supervision | Process Reward | Paper | - |
| ORZ. | 2025 | |||||||
| VC-PPO. | 2025 | |||||||
| VAPO | 2025 | Policy gradient | Yes | Adaptive | Adaptive KL penalty + variance control | Reward + variance signal | Paper | - |
两种方法各有优势,适用于不同的场景和任务。价值模型无关的方法通常更加简单直接,适合于那些难以建模价值函数的复杂任务。而价值模型相关的方法则在奖励信号较为稀疏或者需要更精确的奖励预测时表现出色,能够更有效地引导模型学习。在实际应用中,选择哪种方法往往取决于具体任务的特性、可用数据的质量以及计算资源的限制。
 [^16]
[^16]
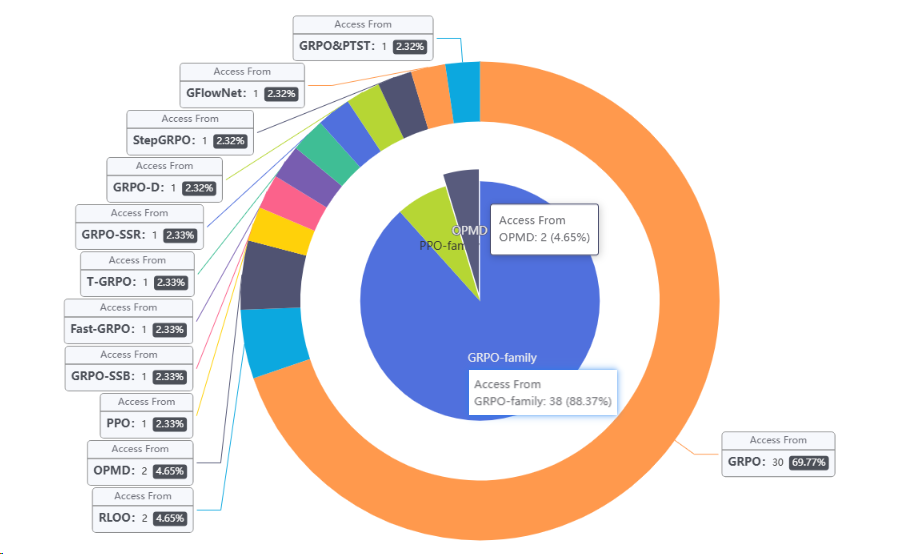
当前应用:GRPO-family一家独大
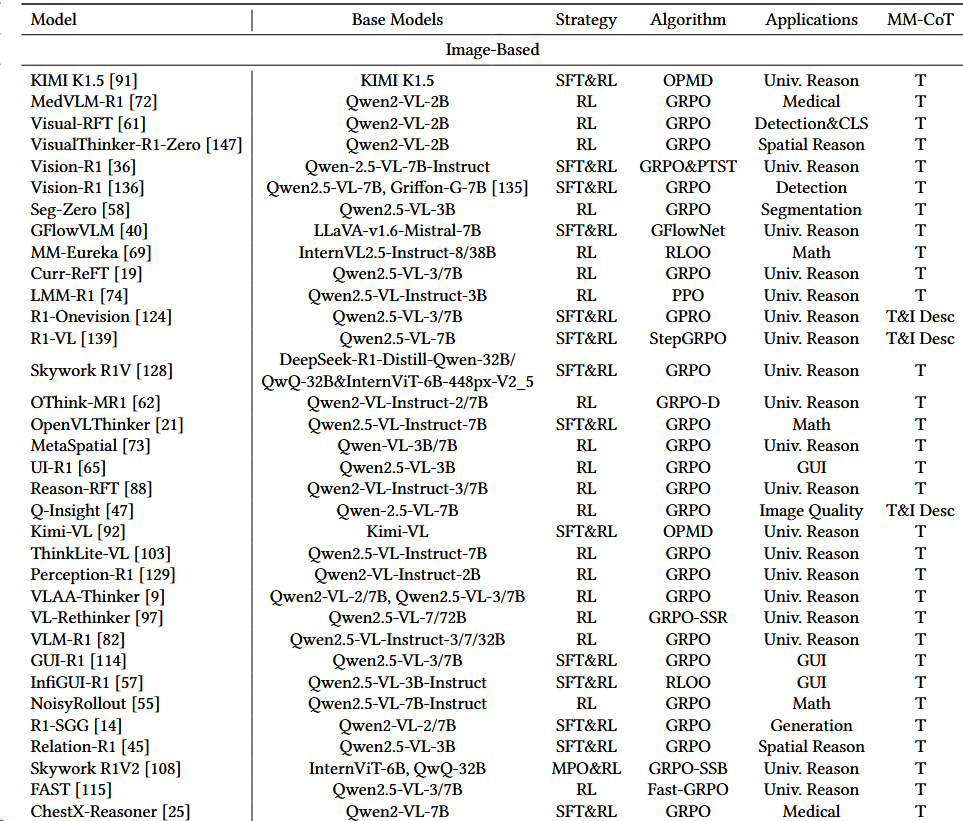
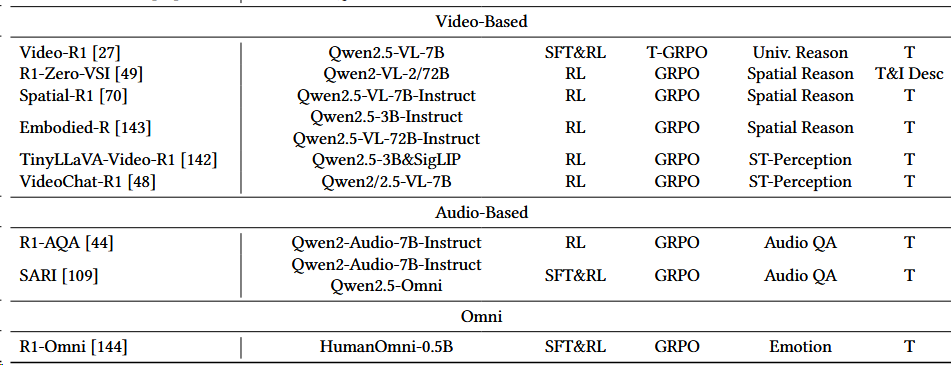
注:
- online policy mirror descent (OPMD) 基于2021的Mirror Descent Policy Optimization一文。
- RLOO 是2024年提出的PPO算法的变种[^15]
- 统计:GRPO 30;RLOO 2;OPMD 2;PPO 1;GRPO变种(GRPO-SSB、Fast-GRPO、T-GRPO、GRPO-SSR、GRPO-D、StepGRPO、GFlowNet、GRPO&PTST) 各一个
RL4LLM的“战国时代”与实践者的困境
强化学习(RL)扮演了至关重要的角色,它能够引导LLM超越预训练阶段所能达到的性能上限,解锁更高级的推理能力。这个被称作“RL for LLM”或“RL4LLM”的新兴领域,在2025年迎来了研究热潮,arXiv和各大顶会上涌现出数百篇相关论文,涵盖了从算法创新到工程实践的方方面面。
然而,繁荣的背后也隐藏着混乱。当前的RL4LLM研究如同一个“百家争鸣”的战国时代,各种技术和“tricks”层出不穷,但缺乏统一的评估标准和清晰的使用指南。这给广大AI从业者和研究者带来了巨大的困惑:
- 结论相互矛盾:不同的论文对同一个问题给出了截然不同的解决方案。例如,在归一化策略上,GRPO算法 [Shao et al., 2024] 推荐使用“组级别(group-level)”归一化来增强稳定性,而REINFORCE++ [Hu et al., 2025] 则认为“批次级别(batch-level)”归一化效果更佳。更有甚者,Dr. GRPO [Liu et al., 2025a] 建议在GRPO的基础上移除方差归一化,以避免引入偏差。
- 实现细节模糊:在损失计算上,GRPO采用“响应级别(response-level)”的损失聚合,而DAPO算法 [Yu et al., 2025] 则采用“令牌级别(token-level)”的聚合。这些看似细微的差别,背后却可能隐藏着截然不同的优化哲学和适用场景。
- 技术组合爆炸:除了上述核心技术,还有大量的“正交”技术,如裁剪(Clipping)、过长过滤(Overlong Filtering)等,可以相互组合。面对如此众多的技术选项,从业者如同进入了一个迷宫,难以抉择如何搭配才能在特定场景下发挥LLM的最大潜力。
这些混乱现象的根本原因在于,各个研究的实验设置(如模型、数据、初始化参数)千差万别,导致结论难以横向比较和推广。
Lite PPO 针对强化学习中最具争议的归一化策略(组级 vs 批次级)、裁剪机制(传统对称裁剪 vs Clip-Higher)、损失聚合与过滤技术进行了系统实验,基于奖励分布特性和模型类型差异提出了极简组合方案:采用混合归一化(组级均值 + 批次级标准差)并移除冗余组件(如过长过滤),在基础模型上实现优于复杂算法(如 GRPO、DAPO)的性能提升。
大语言模型
由于当前多模态理解模型大部分由一个大语言模型构成,LLM的相关RL策略基本半年后就会在多模态理解领域有人尝试使用,所以关注LLM的相关竞争也是必须的。
- 2512:QwenLong-L1.5 : 长序列RL:
- GRPO+
- Task-balanced sampling+Task-specific advantage estimation+
- AEPO 自适应熵控制(AEPO):动态屏蔽高熵状态下的错误惩罚,保护探索行为,解决长文本信用分配难题。
多模态理解
高效奖励机制设计
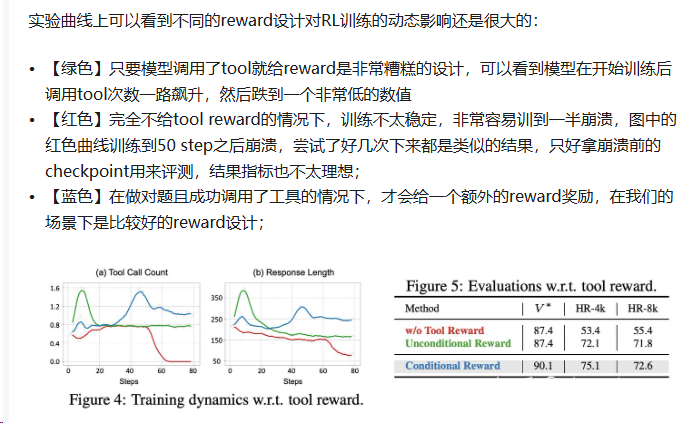
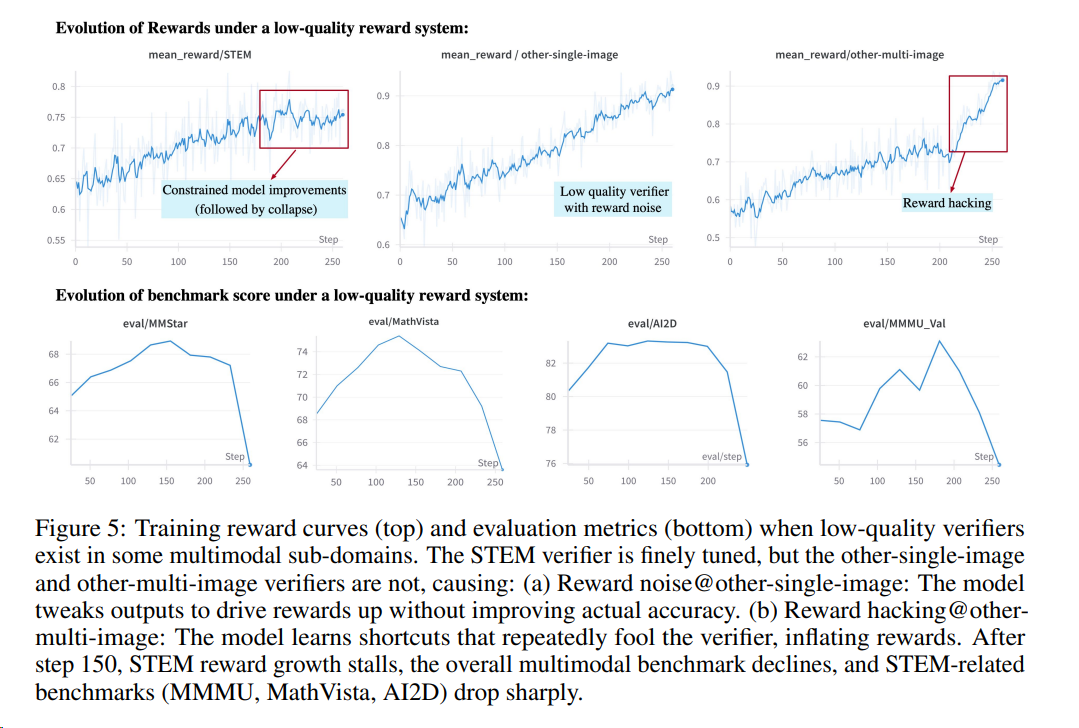
问题描述:当前方法主要依赖最终任务级别的标量奖励(如答案正确率、分类准确率),这些奖励仅反映最终结果,而无法对推理路径中的中间步骤提供反馈,导致模型无法纠正早期推理错误,并容易出现“过度思考”现象,即生成过长、冗余或包含无关信息的推理链。尽管已有研究尝试引入过程奖励或分阶段训练,但仍存在依赖人工设计、难以跨任务与跨模态泛化等问题。
未来方向:为了解决稀疏奖励的问题,未来的研究可能会集中在以下几个方面:
- 奖励分解(避免稀疏奖励):将复杂任务分解为多个子任务,并为每个子任务提供密集的奖励信号,以便模型能够更容易地学习到正确的行为。
- 过程导向奖励机制(Process Reward Mechanisms, PRM)可以被视为一种奖励分解的实现方式。过程导向奖励机制强调评估和奖励模型在推理过程中的中间行为,而不仅仅是最终结果的正确性。这种方法可以帮助模型更好地学习到解决问题的正确步骤,从而提高推理能力。例如,在多模态推理任务中,模型可能会被奖励为生成逻辑连贯的推理步骤,而不仅仅是给出正确的最终答案。
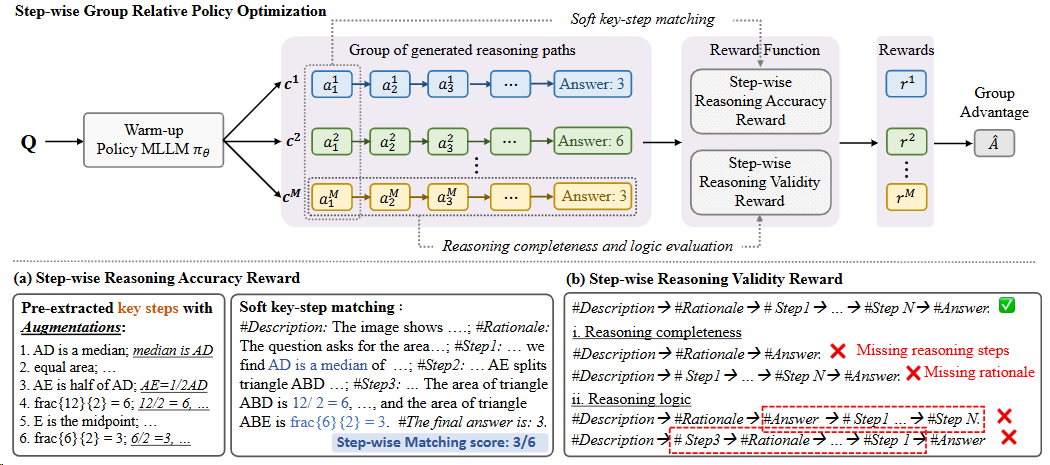
- StepGRPO[^35]通过两种新的推理奖励:步骤级别的推理准确性奖励(StepRAR)和步骤级别的推理有效性奖励(StepRVR)提高 MLLM 推理能力方面的有效性。
 [^2]
[^2]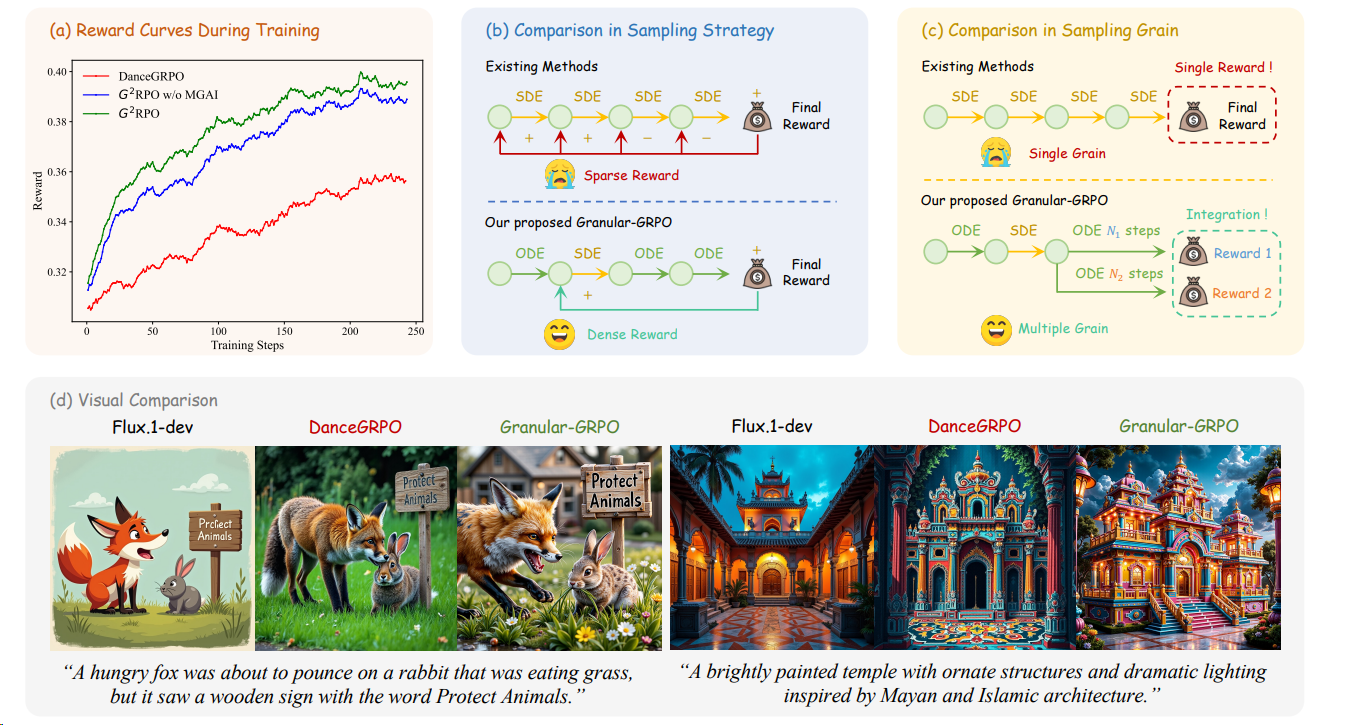 [^24]
[^24]
- 奖励共享:在多任务学习中,允许不同任务之间共享奖励信号,以增加奖励的频率和多样性。
- RLAIF[^6]其中上下文感知的奖励模型(Context-Aware Reward Modeling):通过将视频细分成多个片段,并为每个片段生成详细的描述,然后将这些描述整合到奖励模型中,以提供更清晰的视频内容理解。
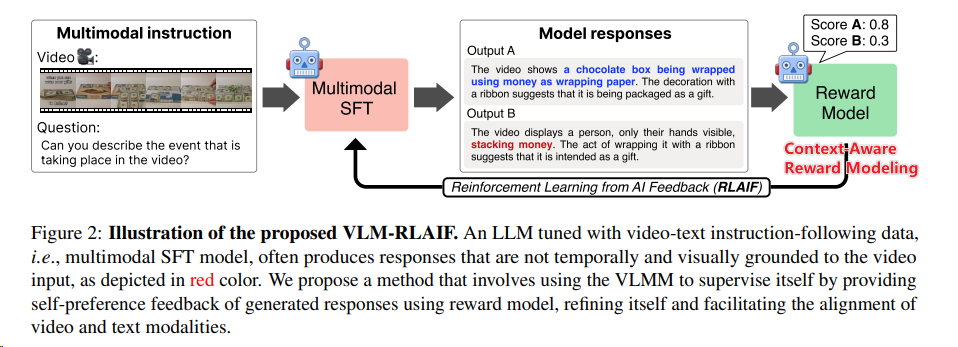
- RLAIF[^6]其中上下文感知的奖励模型(Context-Aware Reward Modeling):通过将视频细分成多个片段,并为每个片段生成详细的描述,然后将这些描述整合到奖励模型中,以提供更清晰的视频内容理解。
- 分层奖励建模:开发更复杂的奖励模型,能够在不同的抽象层次上提供奖励,从而引导模型进行更深层次的学习。
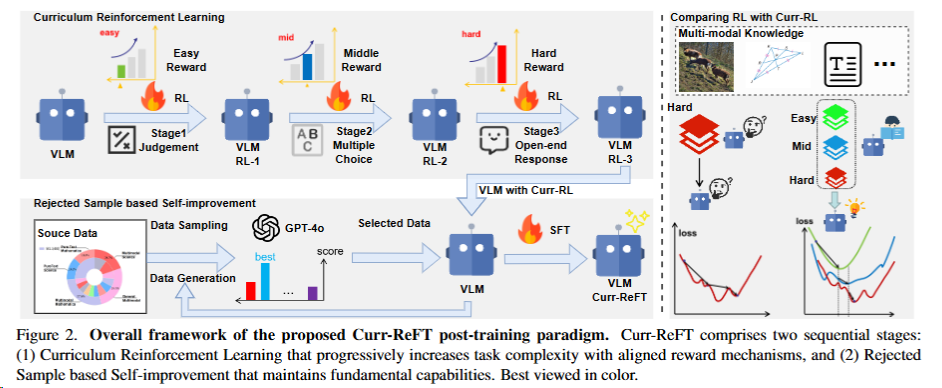
- curriculum reinforcement learning(课程强化学习)也与奖励分解相关。这种方法通过逐步增加任务难度,让模型先从简单的任务开始学习,然后逐步过渡到更复杂的任务。这样的训练策略可以看作是对奖励分解的一种实现,其中每个课程阶段都可以为模型提供更密集的反馈和奖励信号。(4.3.1 一节[^1] Kimi K1.5/Curr-ReFT/Embodied-R/NoisyRollout) 对训练稳定性和避免灾难性遗忘极其有效。
 [^34]
[^34]
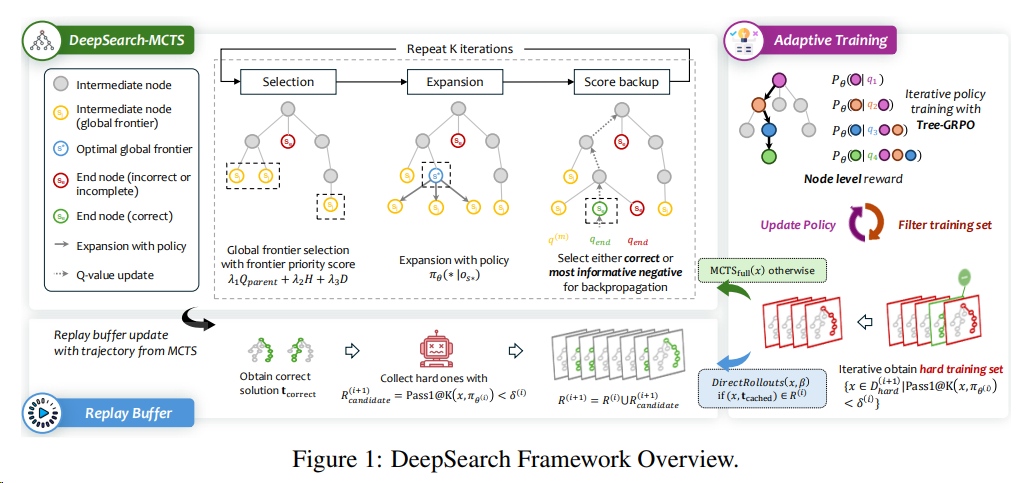
- 蒙特卡洛树搜索(MCTS): DeepSearch 的核心创新在于将 蒙特卡洛树搜索(MCTS)直接集成到 RLVR 训练过程中,而非仅用于推理阶段。这种设计Tree-GRPO使得模型能够在训练时进行系统性探索,并实现细粒度的信用分配(fine-grained credit assignment)到推理的各个步骤。
高效跨模态理解
问题描述:(Inefficient Cross-Modal Reasoning)
- 跨模态理解涉及到整合和协调来自不同感官通道(如文本、图像、音频和视频)的信息。当前的MLLMs在处理跨模态数据时可能会效率低下,因为它们需要理解和融合来自不同模态的复杂信息。
- 多模态超越文本的挑战:与纯文本数据相比,多模态数据的质量和数量不足,导致模型在视频内容的对齐上表现不佳。
未来方向:为了提高跨模态理解的效率,未来的研究可能会探索以下策略:
多模态融合技术
开发更有效的多模态融合机制,以便更好地整合和协调不同模态的信息。
GFlowVLM[^36] 通过模拟非马尔可夫决策过程,能够更好地捕捉到任务完成所需的长期依赖关系。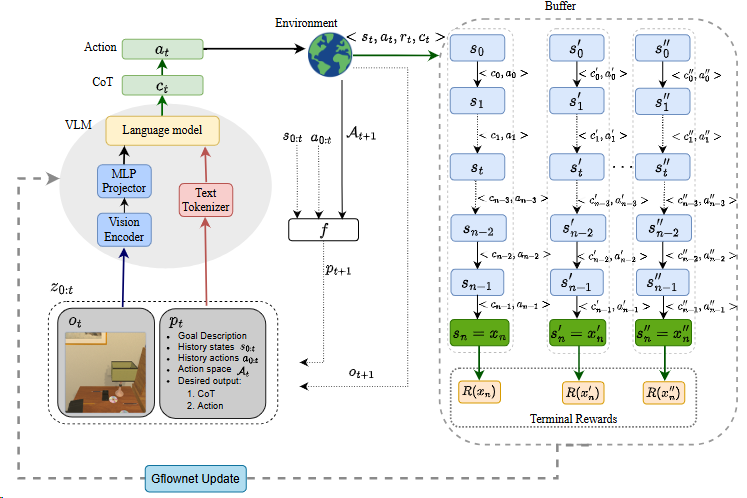
NoisyRollout 是一种数据增强方法,用于提高视觉语言模型(VLM)在强化学习(RL)中的视觉推理能力,通过混合干净和轻微失真的图像轨迹来增强策略探索,同时采用噪声退火调度来平衡探索与稳定性。
视觉引导理解链 think with images
利用视觉信息来引导和构建理解链,提高理解过程中的逻辑连贯性和效率。
MM-CoT 由于目前大多数主流的多模态大语言模型(MLLMs)在生成图像或其他模态方面仍存在困难,近期基于强化学习(RL)的推理进展主要集中在纯文本形式的思维链(CoT)生成上。
 [^1]
[^1]
- 视觉决策领域:Praxis-VLM[^18]通过文本驱动的强化学习就能实现了复杂的视觉决策能力。文本驱动的推理学习:Praxis-VLM 通过文本描述的情境学习推理能力,这表明推理和决策能力可以在没有直接多模态经验的情况下通过语言表示学习。

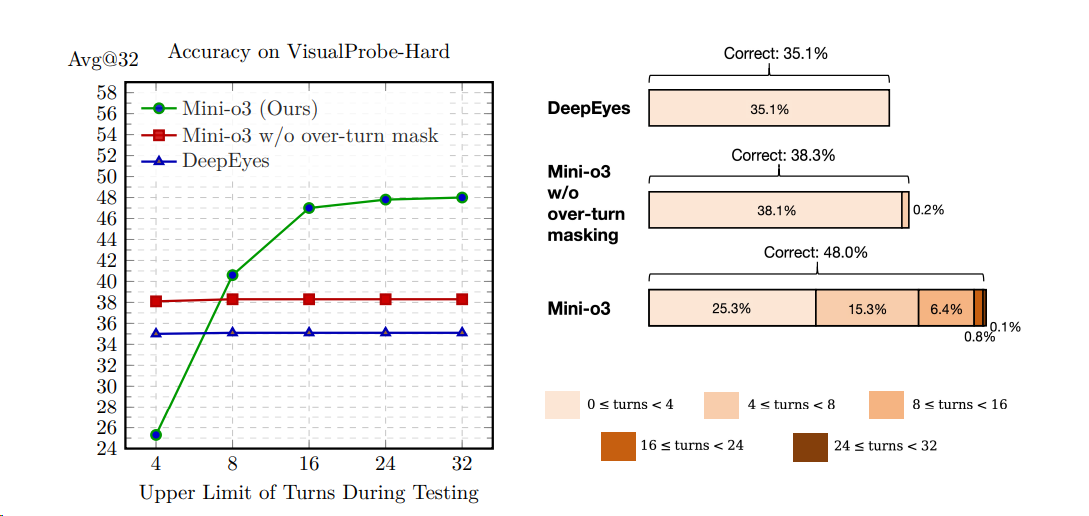
- 视觉搜索(Retrieval-Augmented Generation, RAG)领域:Mini-o3[^17]通过构建 Visual Probe 数据集、采集冷启动数据和引入 over-turn masking 策略(鼓励更多轮回答) 来提升基于图像的工具使用和推理能力,能够在测试时自然扩展到数十个回合,从而在挑战性的视觉搜索任务中实现最先进的性能。阿里VRAG-RL [^20]
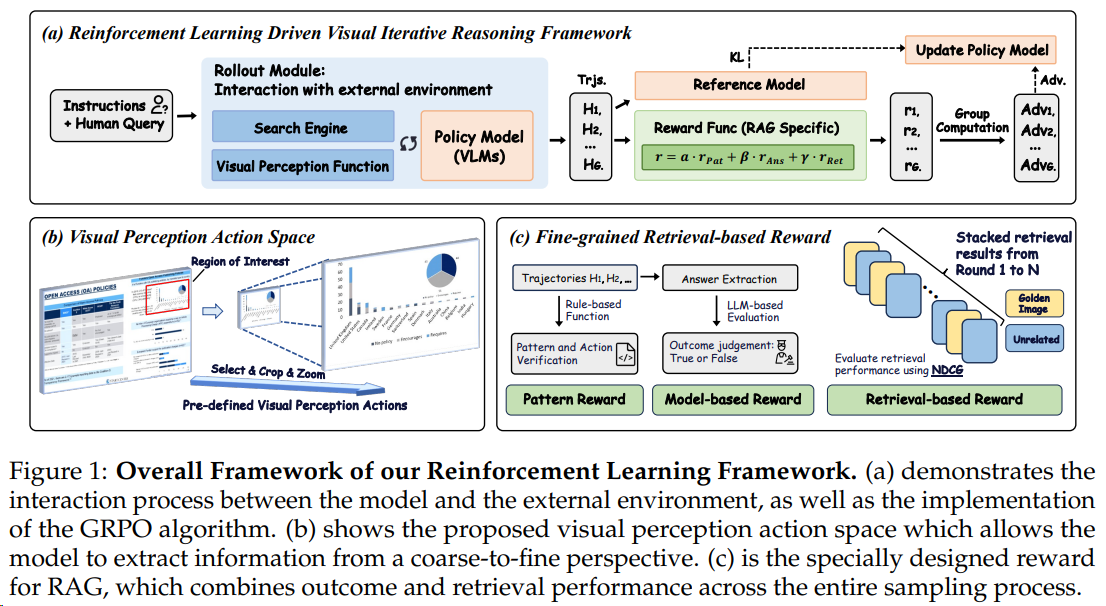
减少无效训练
Skywork R1V2 通过SSB筛选出那些具有显著优势信号的样本来进行训练
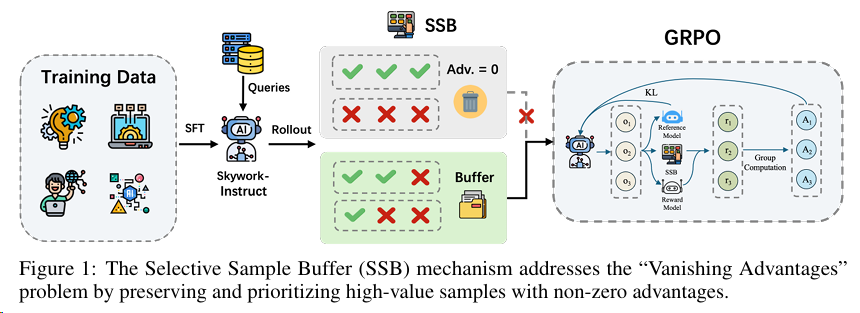
MixGRPO/FlowGRPO 也有类似的思路。
多模态生成
去噪提早
ReFL(2023):这一类方案是diffusion/rectified flow所专有的,思路非常简单直接,就是直接在 Z_t 步下直接预测 Z_0
的结果,然后vae去decode直接送进reward model去直接反向传播进行优化。这一类方案在图像上效果很明显,但是因为要对reward model和decode后的features进行反向传播,在面对100帧以上的视频生成的时候显存压力很大。
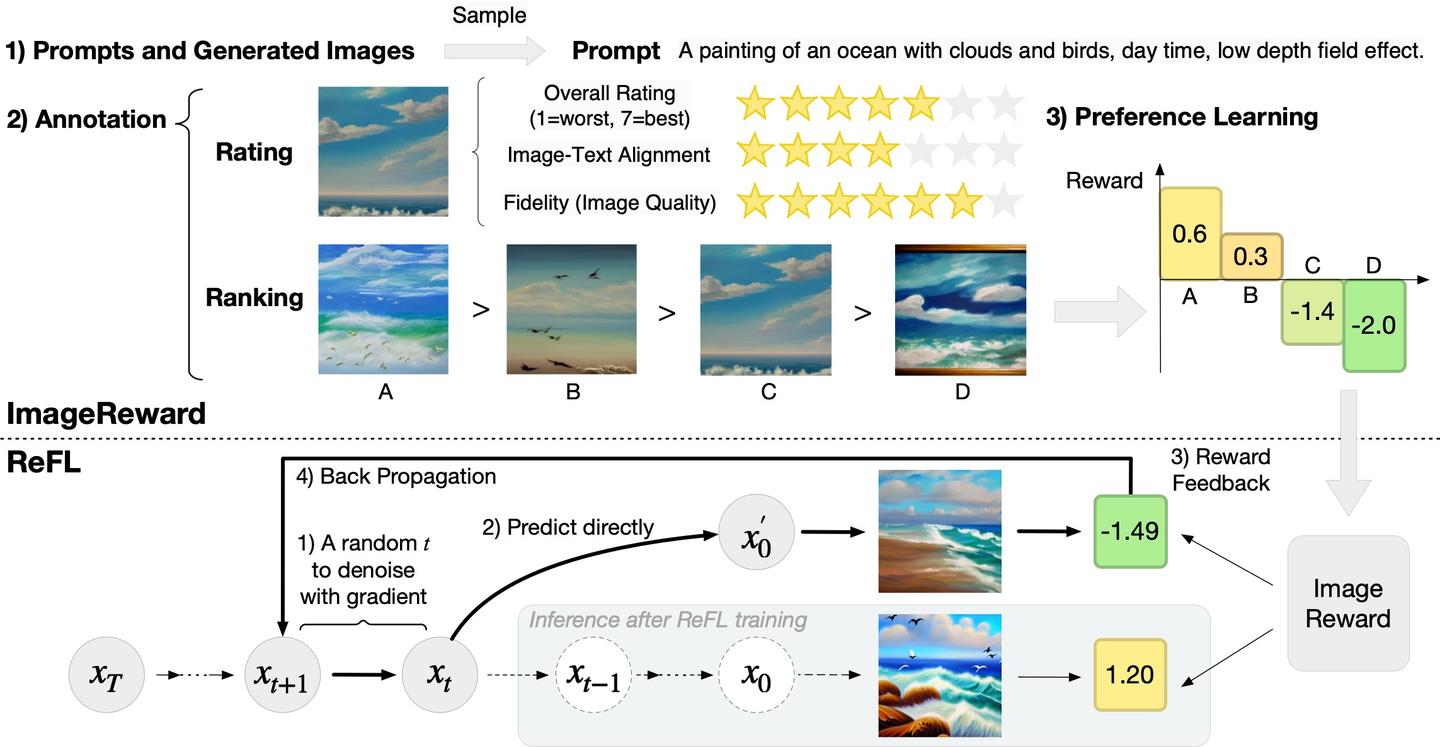

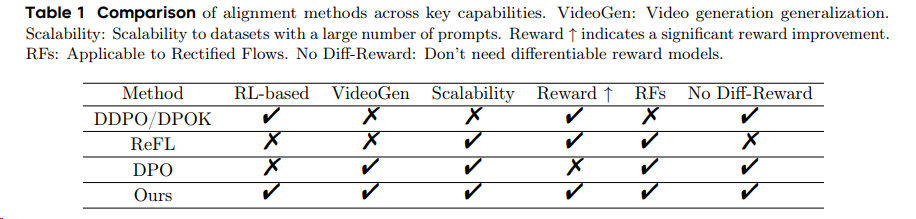
通过观察去噪步骤中的ImageReward分数,我们得出了一个有趣的发现(参见上图左)。对于一个降噪过程,例如降噪步数为40步时,在降噪过程中途直接预测中间降噪结果对应的原图:
- 当t ≤ 15:ImageReward得分和最终结果的一致性很低;
- 当15 ≤ t ≤ 30:高质量生成结果的ImageReward得分开始脱颖而出,但总体上我们仍然无法根据目前的ImageReward分数清楚地判断所有生成结果的最终质量;
- 当t ≥ 30:不同生成结果对应的ImageReward分数的已经可以区分。
根据观察,我们得出结论,经过30步去噪(总步数为40步),而不需要到最后一步降噪,ImageReward分数可以作为改进LDM的可靠反馈。
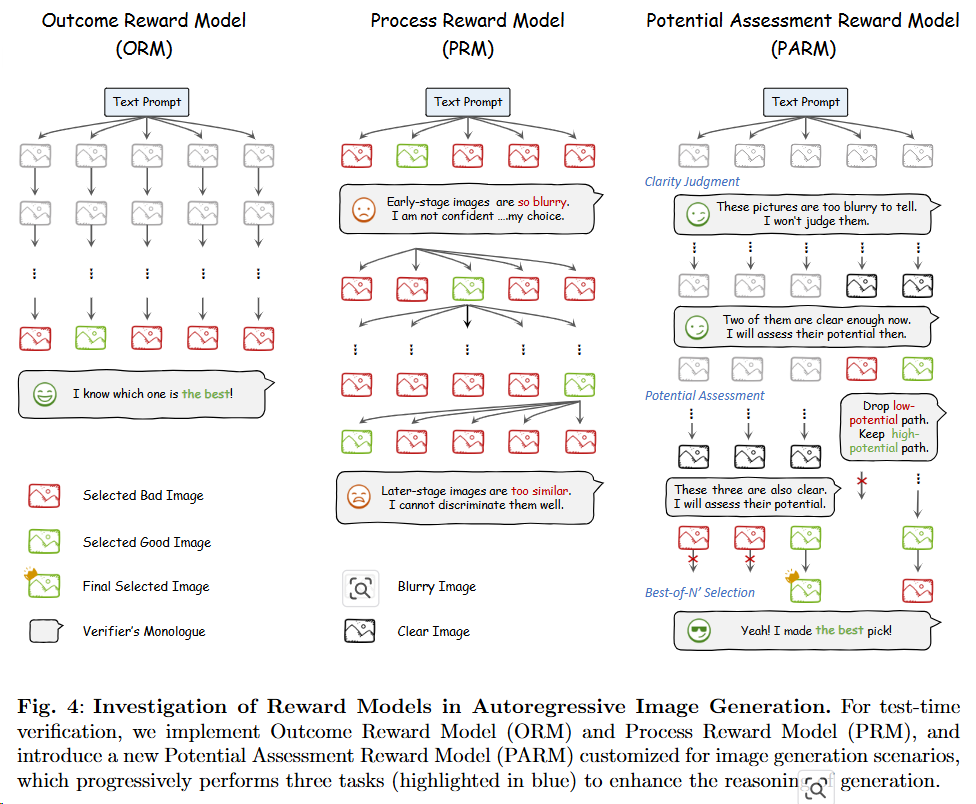
Generate-CoT
首次实现了将思维链(CoT)推理技术有效应用于图像生成场景(设计了有CoT的奖励模型PARM[^37]),显著提升了生成质量(在GenEval基准上超越Stable Diffusion 3达15%)。
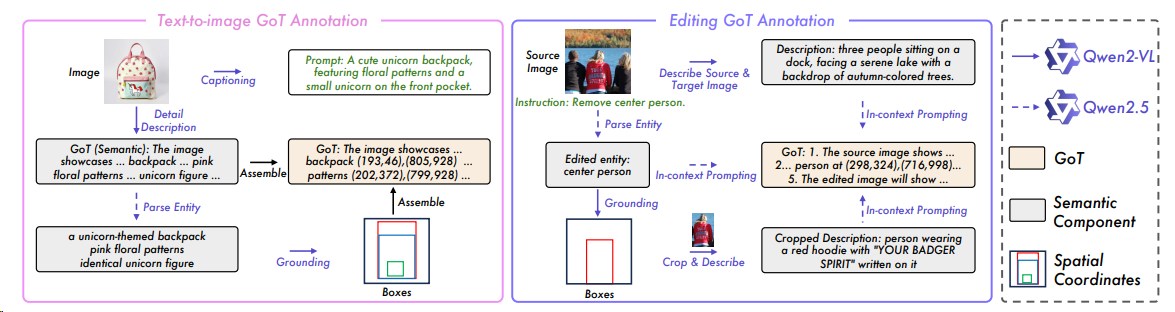
GoT [^40] 通过将多模态大语言模型的推理能力与视觉生成任务结合,提出了一种名为“生成思维链”(GoT)的新范式,实现了语义-空间联合推理驱动的可控图像生成与编辑。(图像坐标?)
视频 CoT [^42] 也是图片的思路,CoT来跟踪对象的移动坐标
DPO-family
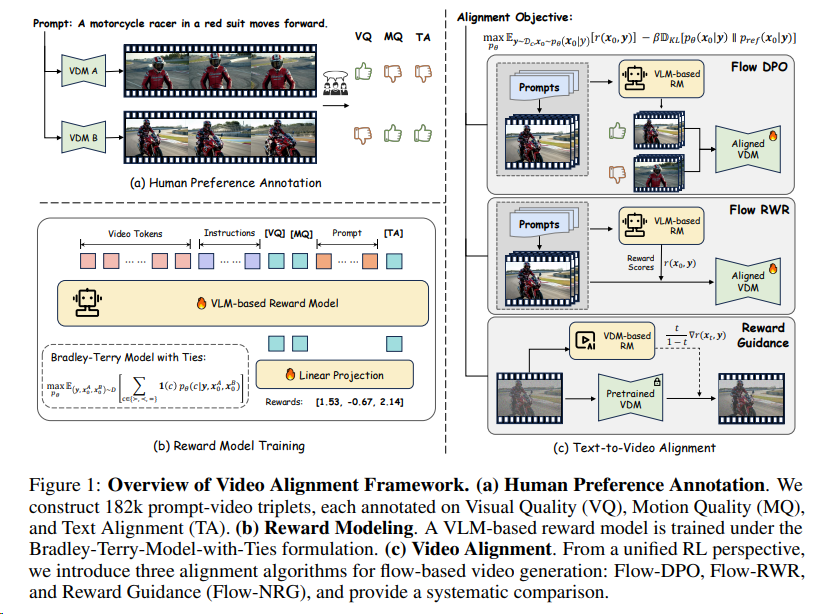
Improving Video Generation with Human Feedback[^21]构建一个大规模的人类偏好数据集,引入一个多维度视频奖励模型(VideoReward),并提出了三种对流基础的视频对齐算法(Flow-DPO、Flow-RWR 和 Flow-NRG),以提高视频生成的视觉质量、运动质量和文本对齐。
OPA-DPO 总结了之前的DPO缺点(效果或效率差),提出四步走在线DPO。

xPO
RPO
基于偏好的强化学习方法,称为 Reward Preference Optimization (RPO),用于主题驱动的文本到图像生成任务,通过引入 λ-Harmonic 奖励函数和 Bradley-Terry 偏好模型,实现了有效的模型训练和早停,提高了图像生成的质量和效率。[^9]

SRPO 2509 腾讯混元
SRPO[^58](Semantic Relative Preference Optimization,语义相对偏好优化),主要提供了文生图模型的强化算法,通过为奖励模型添加特定的控制提示词(如 “真实感”)来定向调整其优化目标。实验结果显示,这些控制词可以显著增强奖励模型在真实度等特定维度的优化能力。
特点:
- “语义相对偏好优化” 策略:同时使用正向词和负向词作为引导信号,通过负向梯度有效中和奖励模型的一般性偏差,同时保留语义差异中的特定偏好。
- 提出了 Direct-Align 策略,对输入图像进行可控的噪声注入,随后通过单步推理,借助预先注入的噪声作为 “参考锚点” 进行图像重建。这种方法显著降低了重建误差,实现更精准的奖励信号传导。从而支持对生成轨迹的前半段进行优化,解决过拟合问题。
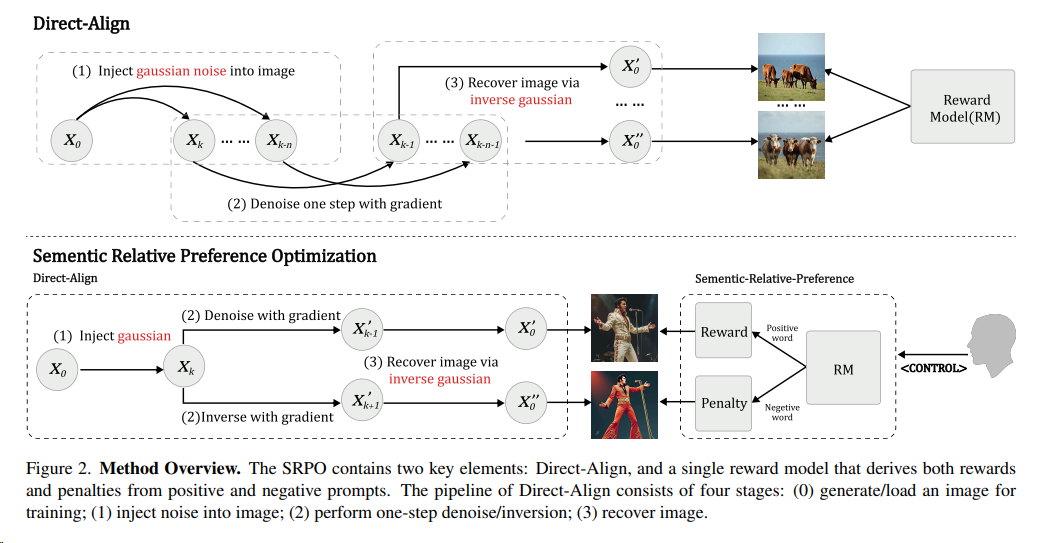
解决了开源文生图模型 Flux 的皮肤质感 “过油” 的问题,能让人像真实感提升 3 倍。SRPO 定量指标达 SOTA 水平,人类评估的真实度和美学优秀率提升超过 3 倍,训练时间相比 DanceGRPO 降低 75 倍。
GRPO-family
T2I-R1
T2I-R1[^39] 的新型文本到图像生成模型,其核心特点是通过引入双层级推理机制(语义级和标记级思维链)并结合强化学习框架(BiCoT-GRPO),显著提升了生成图像的质量和语义对齐能力。
DanceGRPO 2505
DanceGRPO[^22] 的框架,它通过适应 Group Relative Policy Optimization (GRPO) 算法来提高视觉生成任务的性能,特别是在文本到图像、文本到视频以及图像到视频的生成任务中。相对于之前的DPO方法有提升:
- 和flow-grpo一样将ODE的过程转化为SDE,来引入随机性。
关键细节:
- 初始化噪声 (Initialization Noise):DanceGRPO 框架中,初始化噪声是一个关键组件。与以往的 RL 方法(如 DDPO)为训练样本使用不同噪声向量不同,DanceGRPO 为源自相同文本提示的样本分配共享的初始化噪声。这是为了防止在视频生成中出现reward hacking 导致训练不稳定。
- 时间步选择 (Timestep Selection):尽管去噪过程可以在 MDP 框架内严格形式化,但经验观察表明,可以省略去噪轨迹中的部分时间步而不影响性能,从而提高效率。DanceGRPO 实施了 40% 的随机时间步丢弃策略,以平衡计算效率和模型保真度。
- 整合多个奖励模型 (Incorporating Multiple Reward Models):为了确保更稳定的训练和更高质量的视觉结果,DanceGRPO 实践中使用了不止一个奖励模型。例如,仅用 HPS-v2.1 奖励训练的模型容易生成不自然的“油腻”输出,而结合 CLIP 分数有助于保持更真实的图像特性。该方法通过聚合优势函数而非直接组合奖励来稳定优化,从而产生更平衡的生成结果。
- Best-of-N 推理扩展 (Extension on Best-of-N Inference Scaling):DanceGRPO 的方法优先使用高效样本,特别是通过 Best-of-N 采样策略选择的奖励最高和最低的 k 个候选样本。这种选择性采样策略通过关注解决方案空间中高奖励和关键低奖励区域来优化训练效率。
Flow-GRPO 2505 快手
Flow-GRPO[^19],将 GRPO集成到文生图的 Flow Matching 模型中。
涉及的两个主要难点及其策略:
- 难点:Flow 模型依赖于基于 ODE 的确定性 (Deterministic) 生成过程,意味着它们在推理过程中无法随机采样。但是,RL 依靠随机 (Stochastic) 抽样来探索环境,通过尝试不同的 Action 并根据 Reward 改进来学习。换句话讲,RL 对于随机性的需求,与 Flow Matching 模型的确定性相冲突。
- 策略:ODE-to-SDE 转化:把确定性 ODE 转化为对应的 SDE,保持住原始模型的边缘分布。同时,也引入了随机性。允许 RL Exploration 的采样。
- 难点:Online RL 依赖于有效的采样来收集训练数据,但 Flow 模型通常需要许多迭代步骤来生成每个样本,对效率很不利。这个问题在大模型中更为明显。为了使 RL 适用于图像或视频生成等任务,提高采样效率必不可少。
- 策略:一种去噪策略 (Denoising Reduction Strategy):目的是提升 Online RL 的采样效率。降低训练时 denoising steps,维持推理 steps。在不牺牲性能的前提下,大幅提升了采样效率。实验表明,使用更少的步骤可以保持性能,同时显著地降低数据生成成本。
并且KL约束是必须的,避免过度优化导致的模糊和风格单一,在对比图中可感知。

MixGRPO 2507 腾讯混元
MixGRPO[^23] 针对问题:
FlowGRPO的效率仍是个问题,因其需要采样和优化所有的推理的步骤denoising steps。
通过在滑动窗口内使用 SDE 采样和 GRPO 引导优化,在窗口外使用 ODE 采样,减少了优化的复杂度和训练时间。实验结果表明,与 DanceGRPO 相比,MixGRPO 在多个人类偏好对齐的维度上获得了显著的性能提升,并且在训练时间上减少了近 50%,而 MixGRPO-Flash 变体进一步减少了 71% 的训练时间。
MixGRPO 的“混合”+窗口策略:
- 在 滑动窗口内(比如最后几步去噪过程),使用 SDE:因为这些步骤对最终图像质量影响最大,需要精细优化和更强的探索能力。
- 在 窗口外(早期去噪步骤),使用 ODE:因为早期步骤相对粗糙,用确定性过程更快、更省资源。
这就像“抓大放小”:关键步骤精细调优(用 SDE + RL 优化),非关键步骤快速跳过,不更新参数(用 ODE 生成)。作者发现窗口大小 、移位间隔 和窗口步幅都是关键的超参数。当超参为(25,4,25,1)时, 实现了最佳性能。
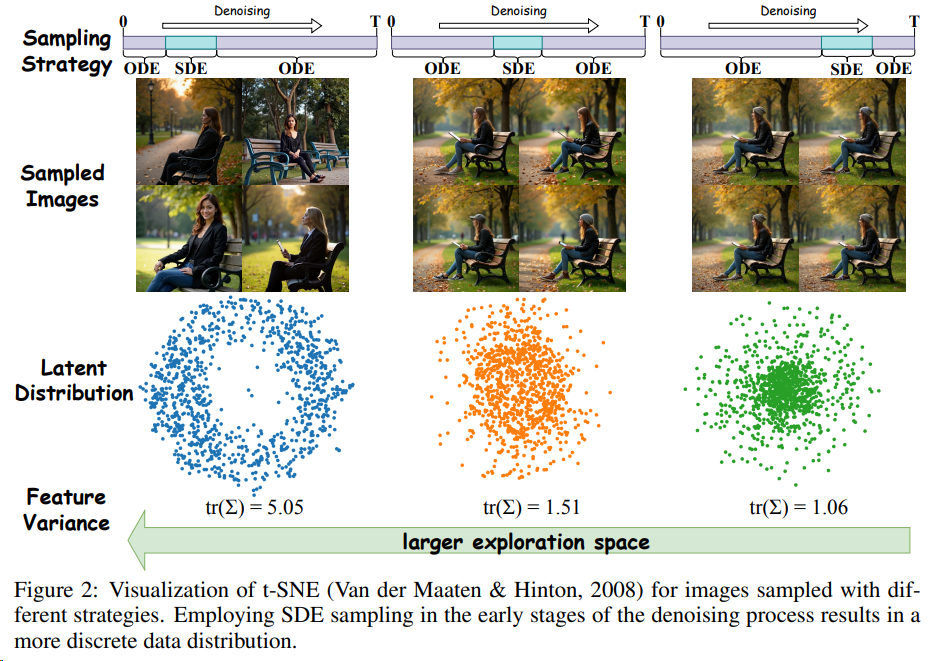
BranchGRPO 2509 北大字节
BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈,和剪枝的加速。
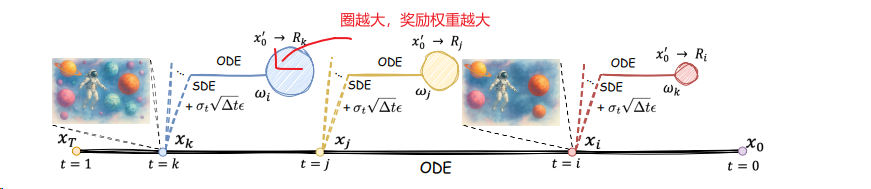
TEMPFLOW-GRPO 2510 浙大微信
TEMPFLOW-GRPO 不仅意识到了MixGRPO的SDE和ODE的关系,还对更早的SDE分支赋予更高的奖励权重:
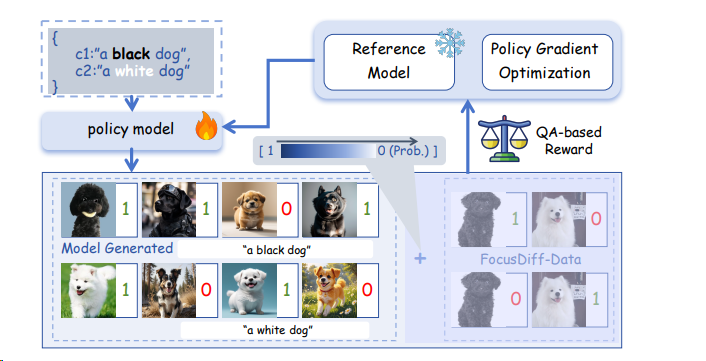
Pair-GRPO 2506 浙大蚂蚁
Pair-GRPO[^44] 算法为解决细粒度语义对齐问题(如“说红出蓝”)而设计,其核心是在传统 GRPO 框架中引入课程学习机制(Curriculum Learning):
- 初期(探索阶段):以概率 p=1.0 注入真实图像对(标注数据),作为“正确示例”与“反例”,引导模型聚焦局部语义差异(如颜色、位置);
- 后期(利用阶段):渐进衰减 p 至 0.0 ,移除标注数据,鼓励模型自主生成差异化输出,实现从依赖标注到自主探索的动态平衡。
DiffusionNFT
DiffusionNFT通过其创新的前向过程优化和流匹配方法,在扩散模型的强化学习微调领域实现了训练效率和性能的双重重大突破,为扩散模型的优化提供了一种更快速、更有效且更通用的新路径。在GenEval任务上,DiffusionNFT仅用约1.7k步就达到0.94分,而对比方法FlowGRPO需要超过5k步且依赖CFG才达到0.95分。这表明DiffusionNFT的训练效率比FlowGRPO快约25倍。
奖励模型设计
Unified Reward 模型[^38] 针对现有的奖励模型往往针对特定任务,限制了其在多样化视觉应用中的适应性的问题。通过在构建的大规模人类偏好数据集上进行训练,涵盖了图像和视频生成 / 理解任务,克服了这一限制。该数据集包含了约 236K 的数据,涵盖了多种视觉任务。
SUDER[^45] 基于理解任务(I2T)和生成任务(T2I)是对偶任务,设计了双向自奖励机制:
- 视觉理解优化:给定输入图像,模型采样多个文本描述。然后,将输入-输出对调,计算每个描述作为条件时生成原始图像的似然度(即 R_U(Y_T | X_V) = log π_θ(X_V | Y_T))。这个似然度作为该描述的自奖励,反映了描述与图像内容的匹配程度
- 文本到图像生成优化:给定文本提示,模型采样多个生成的图像。然后,将输入-输出对调,计算每个生成图像作为条件时生成原始文本提示的似然度(即 R_G(Y_V | X_T) = log π_θ(X_T | Y_V))。这个似然度作为该图像的自奖励,反映了图像与文本语义的保真度
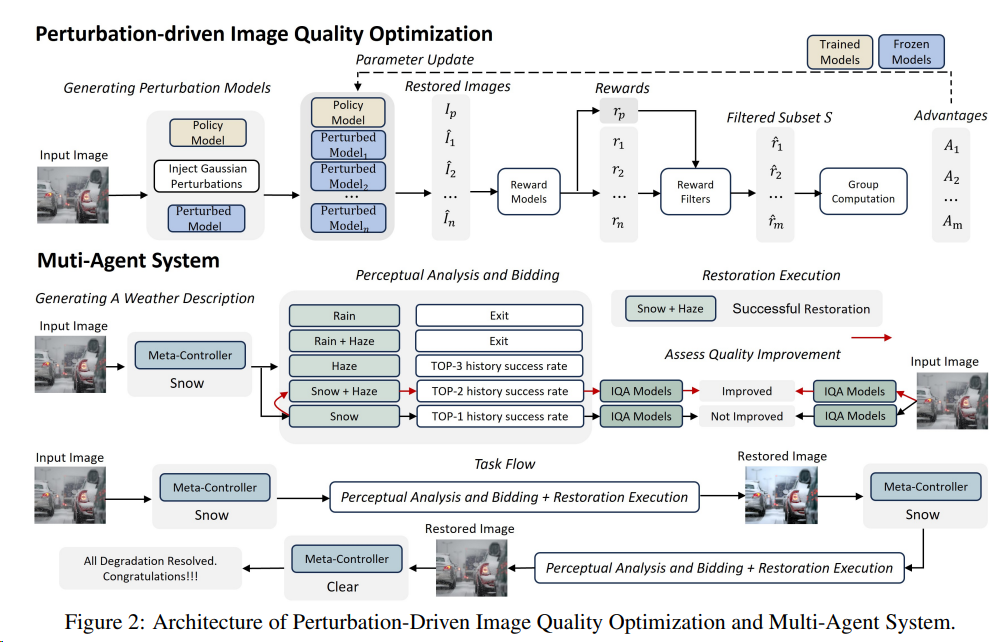
图形修复:使用GRPO的变种算法来实现SOTA的被天气干扰的图像修复[^10]
落地实例(后训练)
理解模型
2505 DeepEyes 小红书
DeepEyes论文[^48] 提出了一种利用强化学习使模型具备“think with images”(以图辅助思考)能力的方法:
- 该方法通过端到端的强化学习,模型推理能力自发涌现,无需额外的 SFT(监督微调)过程。(但是DeepEyes基于 Qwen2.5-VL 实现,难道 Qwen2.5-VL 没有SFT过吗?)
- 模型内置图像定位能力,能够主动调用“图像放大工具”:在推理过程中,模型会自动选取图片中的具体区域进行放大和裁剪,将处理后的区域信息进行进一步推理,实现视觉与文本的链式推理。
- RL 使用的 GRPO
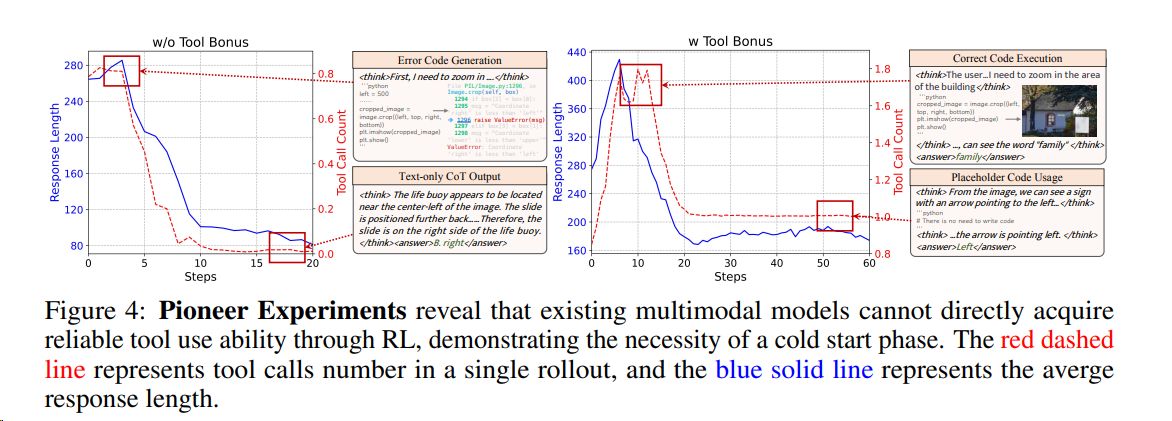
2511 DeepEyesV2 小红书
DeepEyesV2 [^49]是首个将代码执行与网页搜索深度整合到统一推理循环中的智能体多模态模型。其核心突破在于:
- 动态工具调用:模型主动决策何时调用工具(如图像裁剪、数值计算、网页搜索),并将结果迭代融入后续推理。
- 双阶段训练:
- 冷启动阶段:通过高质量数据集(含感知、推理、搜索三类任务)建立基础工具使用模式。(论文说直接用强化学习(Reinforcement Learning, RL)来“硬教”效果并不好。你这不是打自己脸)
- 强化学习阶段:使用 DAPO , 仅用准确率与格式两个简单奖励信号,优化复杂工具组合能力。
2508 GLM4.5V 清华智谱
后训练: SFT + “课程采样强化学习”( Reinforcement Learning with Curriculum Sampling, RLCS)+ 分层奖励设计:
- 功能:处理跨领域的共性评估逻辑,如格式检查、精确匹配(Exact Match)。
- 示例:
- 格式验证:强制模型使用和标记包裹最终答案。
- 文本匹配:对非数值答案先检查精确匹配,再回退到LLM语义评估。
2. 领域特定模块
- 功能:针对不同任务定制复杂逻辑,确保奖励信号贴合领域特性。
- 关键领域设计:
|领域| 奖励逻辑 |示例|
|---|---|---|
|STEM问题| 提取最终答案并验证中间推理步骤的逻辑一致性| 数学题需验证相对误差阈值,化学反应式需检查原子守恒|
|OCR|/图表| 数值答案验证相对误差阈值;文本答案先精确匹配,再语义评估 | ChartQA任务中,对“销售额增长20%”的预测需匹配参考答案的±5%误差范围|
|GUI代理| 功能性评估(如按钮点击位置准确性)结合流程合规性(如操作步骤顺序)| 在OSWorld任务中,成功完成“预约会议”操作得1分,步骤错误得0分|
|长文档理解| 跨页信息关联性评分(如答案需综合多页图表和文本)| MMLongBench-Doc中,答案需同时引用第3页表格和第7页文本才得满分|
1. 格式与风格检查器
- 规则基础:对混合中英文、重复文本等低质量输出惩罚。
- 模型辅助:使用LLM评估答案的流畅性和逻辑严谨性,例如:
- 若内容包含超过30%的混合中英文词汇,奖励值降低20%。
2508 InternVL3.5
在预训练阶段之后,我们采用了包括三个阶段的后训练策略:
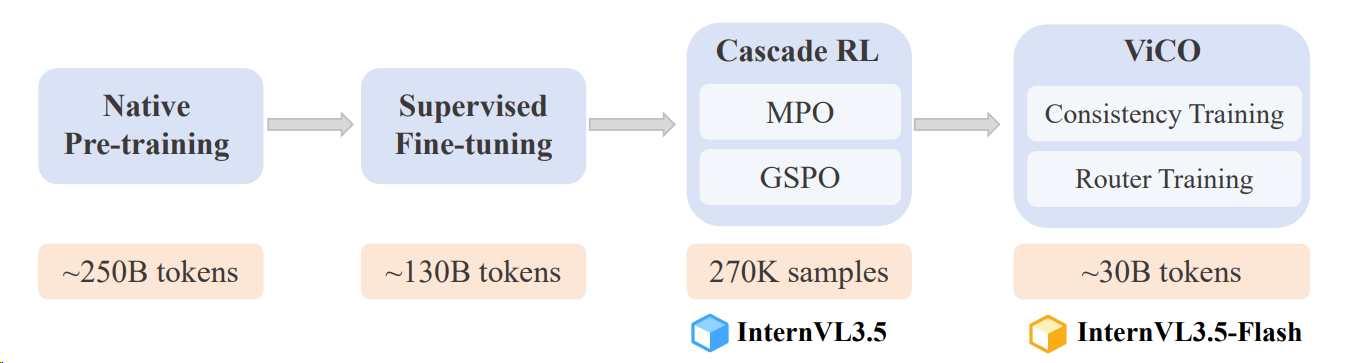
- 监督式精调(SFT),该阶段保持与预训练相同的训练目标,但利用更高质量的对话数据进一步提升模型能力。
- 级联强化学习(Cascade RL),结合离线和在线强化学习方法的优势,以促进推理能力的发展。
- 在离线RL阶段,我们采用混合偏好优化(MPO)来对模型进行微调。
- 在线RL阶段,我们采用GSPO作为在线RL算法
- 视觉一致性学习(ViCO),旨在将视觉分辨率路由器(ViR)整合进InternVL3.5,构建InternVL3.5-Flash,通过最小化不同视觉压缩率的输出差异来实现。
2509 Mini-o3
字节跳动和香港大学的研究团队推出了 Mini-o3,一个旨在复现OpenAI强大但未公开的o3模型能力的开源系统。Mini-o3的核心目标是扩展模型与工具的交互能力,使其能够执行长达数十步的深度推理。使用的GRPO
2509 Qwen3VL
后训练分为 三个阶段, 这和qwen3是一样的
- 第一阶段:监督微调(SFT)。赋予模型基础的指令跟随能力并激活潜在推理能力。训练分为两个步骤:先在32k上下文长度下训练,随后扩展到256k以处理长文档和长视频。数据被分为“普通模式”和显式建模推理过程的“思维链(CoT)模式”。
- 第二阶段:强弱蒸馏(Strong-to-Weak Distillation)。利用强大的教师模型通过纯文本数据对学生模型的Backbone进行微调,有效提升文本和多模态任务中的推理能力。
- 第三阶段:强化学习(RL)。分为“推理RL”和“通用RL”还有个think with images,在大规模文本和多模态领域(如数学、OCR、Grounding)上进一步提升细粒度能力。
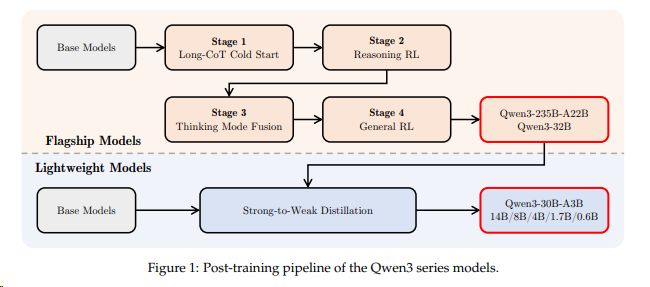
推理型强化学习(Reasoning RL)
任务覆盖数学、编程、逻辑、视觉谜题等,所有答案均可通过规则或代码执行器确定性验证。
数据准备:
- 使用 Qwen3-VL-235B-A22B 初版模型为每条查询生成 16 个回答,仅保留至少有一个正确回答的查询;
- 剔除改进潜力低的数据源,最终保留约 3 万条 RL 查询;
- 训练时过滤通过率 >90% 的简单样本,并按任务难易比例混合构建批次。
奖励系统:
- 统一框架支持多任务,统一的奖励设计考虑了不同的任务类型。
- 任务专用提示( task-specific format prompts)确保输出格式合规,避免依赖格式奖励;(是避免奖励格式吗?)
- 若回答语言与提问语言不一致,施加惩罚以抑制语言混杂。
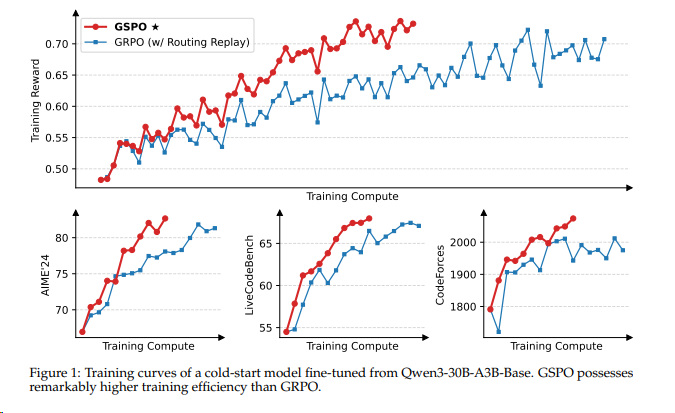
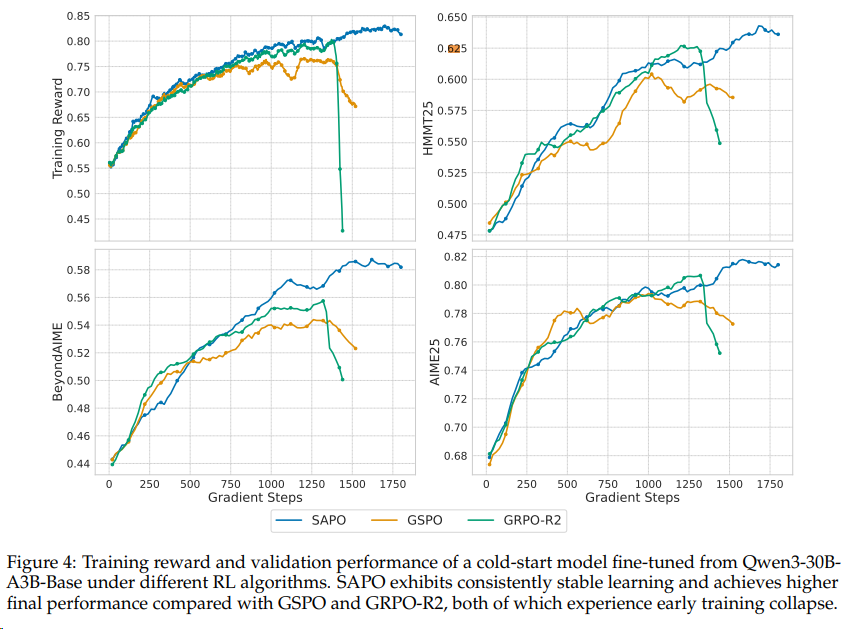
算法:采用 SAPO(Smooth and Adaptive Policy Optimization)算法,在不同模型规模和架构上均表现稳定。(VeRL 已有PR)qwen3使用的GRPO
通用强化学习(General RL)
目标:提升泛化能力、纠正 SFT 阶段形成的错误先验、抑制不良行为(如语言混杂、重复、格式错误)。
双维度优化:
- 指令遵循:评估对内容、格式、长度、结构化输出(如 JSON)等约束的满足程度;
- 偏好对齐:在开放性任务中优化有用性、事实准确性与风格适切性。
错误纠正策略:
- 构建专门数据集,包含易引发错误的样本(如反直觉计数、复杂钟表识别),通过 RL 覆盖错误认知;
- 针对低频不良行为,构造高密度触发样本,施加高频惩罚以高效抑制。
混合奖励机制:
- 规则奖励:用于可验证任务,提供高精度、抗“奖励欺骗”的反馈;
- 模型奖励:由 Qwen2.5-VL-72B-Instruct 或 Qwen3 作为评判模型,多维度打分,避免因格式非常规而误判有效回答。
Thinking with Images智能体训练
采用两阶段范式训练具备工具调用与环境交互能力的视觉智能体:
- 第一阶段:合成约 1 万条简单两轮 VQA 任务(如属性识别),在 Qwen2.5-VL-32B 上进行 SFT,模拟“思考→行动→分析反馈→作答”流程,并辅以多轮工具集成 RL(multi-turn, tool-integrated reinforcement learning (RL))。
- 第二阶段:将训练好的智能体蒸馏为约 12 万条多轮交互数据,和之前1万的数据用于 Qwen3-VL 的后训练(a cold-start SFT and tool-integrated RL pipeline)。
RL 奖励信号:
- 答案准确奖励:由 Qwen3-32B 判断最终答案是否正确;
- 多轮推理奖励:由 Qwen2.5-VL-72B 评估是否合理利用工具反馈并进行连贯推理;
- 工具调用奖励:将实际调用次数与专家预估目标(由 Qwen2.5-VL-72B 离线生成)对比,鼓励任务自适应的工具探索。原因是为防止模型“偷懒”仅调用一次工具以满足前两项奖励,显式引入工具调用奖励以对齐任务复杂度。
2601 Step-3-VL-10B
通过力大砖飞的RL(PPO+GAE),实现10B参数媲美100B模型智能的效果:RLVR:600 次迭代 + RLHF:300 次迭代 + PaCoRe Training:500 次迭代。
生成模型
生图:
- 250804:Qwen-image[^43] 后训练包括SFT+RL; 其中大部分RL使用DPO,精细微调使用Flow-GRPO(魔改后增加随机性)
- 250909 Seedream 4.0 字节:CT+SFT+RHLF(细节不知)
- 250928: HunyuanImage 3.0: 后训练 DPO + MixGRPO + SRPO + Reward Distribution Alignment (ReDA)
- 2511 Z-image:DMDR + DPO + GRPO:
- 复杂的奖励设计:指令遵从(语法+语义:(i)核心主题实体,(ii)属性规范,(iii)动作或交互要求,(iv)空间或构成约束,以及(v)风格或呈现条件。)、内容检测感知、审美素质
- DPO所需数据:
- 一方面奖励标注时:支持人类标注员对指令遵从不满意部分打低分
- 另一方面,对于可自动验证的部分尽量使用VLMs(e.g.,图片中的文字、对象个数)
- DPO + 课程学习(从简单的单字到复杂的多对象、多层次、不同风格)
- GRPO提高上限,使用之前的奖励设计(参考VisionReward),用于实现逼真的图像生成,同时提高审美质量和细致的指导遵从
生视频
- wan系列,完全没讲后训练的方法
- 2506 Seedance 1.0 T2V 字节:两阶段RLHF,朴素的RHLF,涉及RM,并直接奖励最大化(Reward Maximization)
- 3-RMs: 复合奖励系统, 考虑到图文对齐、结构稳定性、运动生成能力、美感是评判视频生成模型的核心,团队构建了一整套复合奖励系统,包括:
- 基础奖励模型:聚焦基础能力(如图文对齐与结构稳定性)增强,采用视觉语言模型(VLM)架构;
- 运动奖励模型:致力于抑制视频伪影,提升运动幅度、生动性与稳定性;
- 美学奖励模型:针对视频关键帧设计 image-space 输入的美感奖励模型,给予模型影视级美感。
- video-tailored RLHF (视频定制化的RLHF): Max-Rms最大化多个奖励模型(RM)奖励值的方法,对比 DPO/PPO/GRPO,该方法针对文本-视频对齐度、运动质量及美学表现等维度的提升效率与效果更佳。
- Super-Resolution RLHF: RLHF 扩展至加速后的超分模型,在低推理步数(NFE)场景下,提升了视频的运动质量与视觉保真度,同时保持了高效的计算效率。
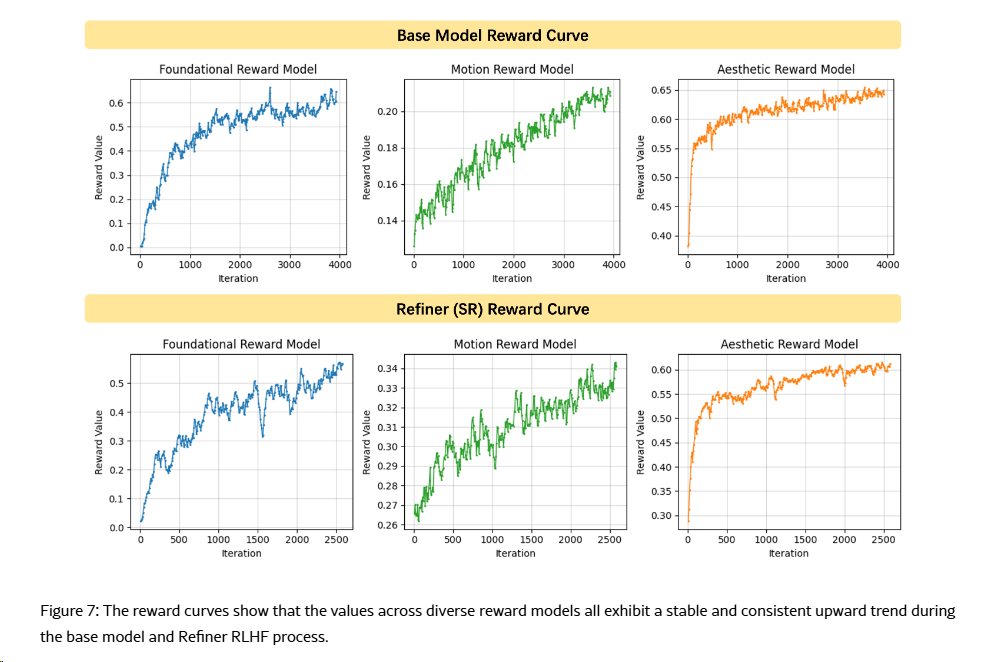
- 3-RMs: 复合奖励系统, 考虑到图文对齐、结构稳定性、运动生成能力、美感是评判视频生成模型的核心,团队构建了一整套复合奖励系统,包括:
- 251009 Self-forcing++(字节) GRPO 引入基于光学流幅度的奖励函数,抑制长视频中的突兀场景切换(ps 光学流幅度(Optical Flow Magnitude)是计算机视觉中的一个重要概念,通过计算视频中连续帧之间的像素位移矢量(即光学流场)的模长得到的标量值。它量化了物体在时间维度上的运动强度, 用于描述视频序列中物体运动的速度和方向)
- 2511:HunyuanVideo 1.5 :采用了从 持续训练 (CT) 到 **监督微调 (SFT)**,再到 人类反馈强化学习 (RLHF) 的完整对齐流水线,旨在针对文生视频 (T2V) 与图生视频 (I2V) 任务优化生成质量,核心目标是消除伪影并提升运动动力学表现。
- 图生视频 (I2V) 对齐策略:在线强化学习驱动
- 核心机制:采用在线 RL 框架,重点修复结构失真与运动伪影。
- 数据构建:
- 从高审美图像库中提取并构建涵盖 100 余个类别的精选提示词集。
- 利用视觉语言模型 (VLM) 生成候选提示词,并辅以人工校验以确保严苛的图文一致性。
- 多维评估体系:
- 微调专属 VLM 作为奖励模型 (Reward Model),从文本对齐、图像保真、视觉质量、运动动态四个关键维度进行综合评分。
- **采样与探索优化 (MixGRPO)**:
- 结合随机种子与 CFG 比例的混合采样策略,配合 **MixGRPO (混合 ODE-SDE 求解器)**。
- 该方法通过增强探索空间的多样性,在保持采样质量的同时,显著提升了运动的真实感。
- 文生视频 (T2V) 对齐策略:离线-在线混合对齐
- 方法论背景:针对 T2V 任务中复杂的运动伪影及奖励模型难以捕捉细粒度质量的问题,采用“先离线、后在线”的协同优化路径。
- 阶段一:离线 DPO 优化:
- 语料集构建:整合 LLM 生成提示词与真实视频描述,构建涵盖运动、场景、主体等维度的平衡样本库。
- 偏好对生成:基于高质量 SFT 检查点生成多路视频候选项,通过人工标注 (GSB) 在语义保真度、运动质量与审美表现上构建偏好对。
- 效能:通过 On-Policy Alignment (OPA)-DPO (直接偏好优化) 显著降低运动伪影,为后续训练提供更优的策略起点。
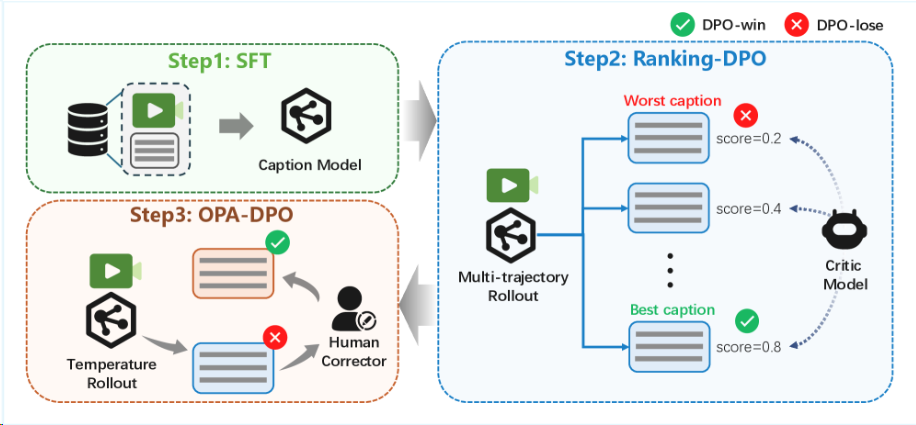
- 阶段二:在线 RL 进阶:
- 复用 I2V 的在线强化学习框架,进一步挖掘模型在视觉精细度与语义对齐方面的潜力。
- 总体成效
- 该对齐框架在全维度评估指标上实现了持续增益,尤其在运动的逻辑连贯性与物理真实感方面表现突出。
- 图生视频 (I2V) 对齐策略:在线强化学习驱动
生成Editing
- VACE后训练:全量微调(Fully Fine-tuning)+上下文适配器微调(Context Adapter Tuning)
- Qwen-image-edit:未知
- Z-image-edit: 只有SFT
世界模型/UFMs/Omni
2507 BAGEL 字节
后训练只有SFT
2509 Qwen3-Omni
Thinker 后训练:
- 监督微调(SFT):使用包含文本、视觉、音频和混合模态的对话数据进行初步指令对齐。
- 蒸馏(Distillation):采用「强 - 弱」蒸馏流程,使用更强大的教师模型(如 Qwen3-235B)的输出来指导学生模型(Qwen3-Omni)学习,提升其推理能力。
- GSPO:一种基于强化学习的优化方法,使用基于规则的奖励(用于数学、代码等可验证任务)和基于模型的奖励(LLM-as-a-judge,用于开放性任务)来全面提升模型在所有模态上的能力和稳定性。
Talker 后训练:
- 基础训练与持续预训练(Continual Pretraining, CPT):使用数亿条带有多模态上下文的语音数据进行训练,建立从多模态表示到语音的映射。然后使用高质量数据进行 CPT,以减少幻觉并提升音质。
- ps. Continual Pretraining (持续预训练): 是在第一阶段预训练结束后,模型在高质量、特定领域或更近期的数据上进行的第二轮预训练。
- 直接偏好优化(DPO):构建多语言语音样本的偏好对,使用 DPO 来提升多语言语音生成的稳定性和泛化能力。
- 说话人微调(Speaker Fine-tuning):在特定说话人的数据上进行微调,使 Talker 能够模仿特定音色,并提升语音的自然度、表现力和可控性。
2510 Emu3.5 智源
GRPO + 复合奖励系统: 通用奖励(美学、图文一致性)+任务奖励(OCR 准确率、人脸 ID 保持、布局对齐等)
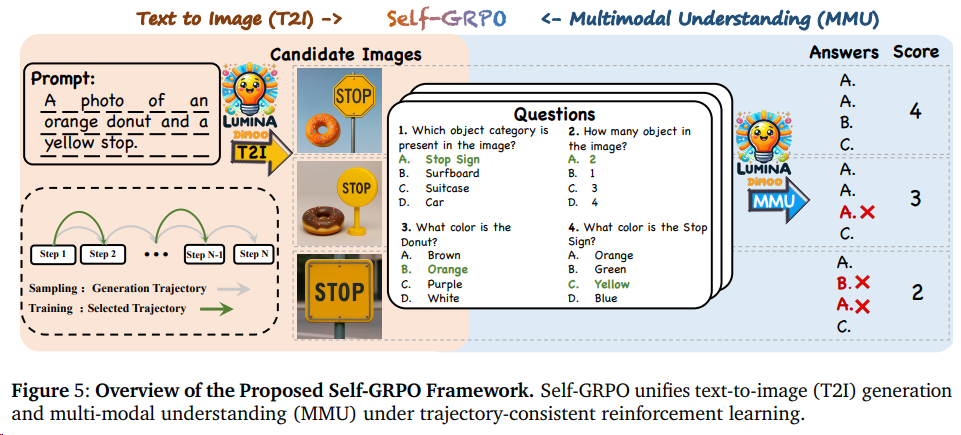
2510 Lumina-DiMOO 上海AILab
self-GRPO旨在通过统一文本到图像生成(T2I)和多模态理解(MMU)任务,实现模型性能的自主优化。以下是其核心机制与特点的详细解释:
🔍 一、Self-GRPO 的核心目标
- 统一生成与理解任务:
传统方法通常单独优化生成(如图像生成)或理解(如视觉问答)任务,而 Self-GRPO 通过联合优化 T2I 和 MMU,使模型在生成高质量图像的同时提升多模态理解能力。 - 自强化学习机制:
模型通过自身生成的样本进行迭代优化,无需外部标注数据,实现“自我改进”。
⚙️ 二、技术实现机制
奖励函数设计
- 语义对齐奖励:
模型生成图像或回答后,通过预定义的语义规则(如实体、关系、属性的匹配度)计算奖励值。例如:- 在 T2I 任务中,奖励函数评估生成图像与文本描述的语义一致性(如对象位置、颜色、数量等)。
- 在 MMU 任务中,奖励函数衡量答案与问题的逻辑匹配度(如事实准确性、推理合理性)。
- 归一化处理:
奖励值通过 softmax 温度参数(α)归一化,确保不同任务间的奖励可比性。
- 语义对齐奖励:
策略优化目标
Self-GRPO 通过以下目标函数优化模型参数:$$mathcal{L}(theta) = -sum_{g=1}^{G} w^{(g)} left( ell_{text{T2I}}^{(g)} + ell_{text{MMU}}^{(g)} right) + beta cdot text{KL}left(p_{theta} parallel p_{theta}^{text{ref}}right)$$
- 加权损失:w^{(g)} 为第 g 个样本的归一化奖励权重,ell_{text{T2I}} 和 ell_{text{MMU}} 分别为生成与理解任务的损失。
- KL 正则化:约束新旧策略的差异(beta 为正则化系数),避免优化过程过度偏离初始模型。
轨迹一致性训练
- 生成任务:
图像生成需多步采样(如扩散模型的去噪过程),Self-GRPO 保留完整采样轨迹,但仅计算关键时间步(mathcal{T}_{text{sel}})的梯度,减少计算开销。 - 理解任务:
文本答案生成采用块状并行解码(Block-Wise Parallel Sampling),结合早期停止策略(Early Stopping)提升效率。
- 生成任务:
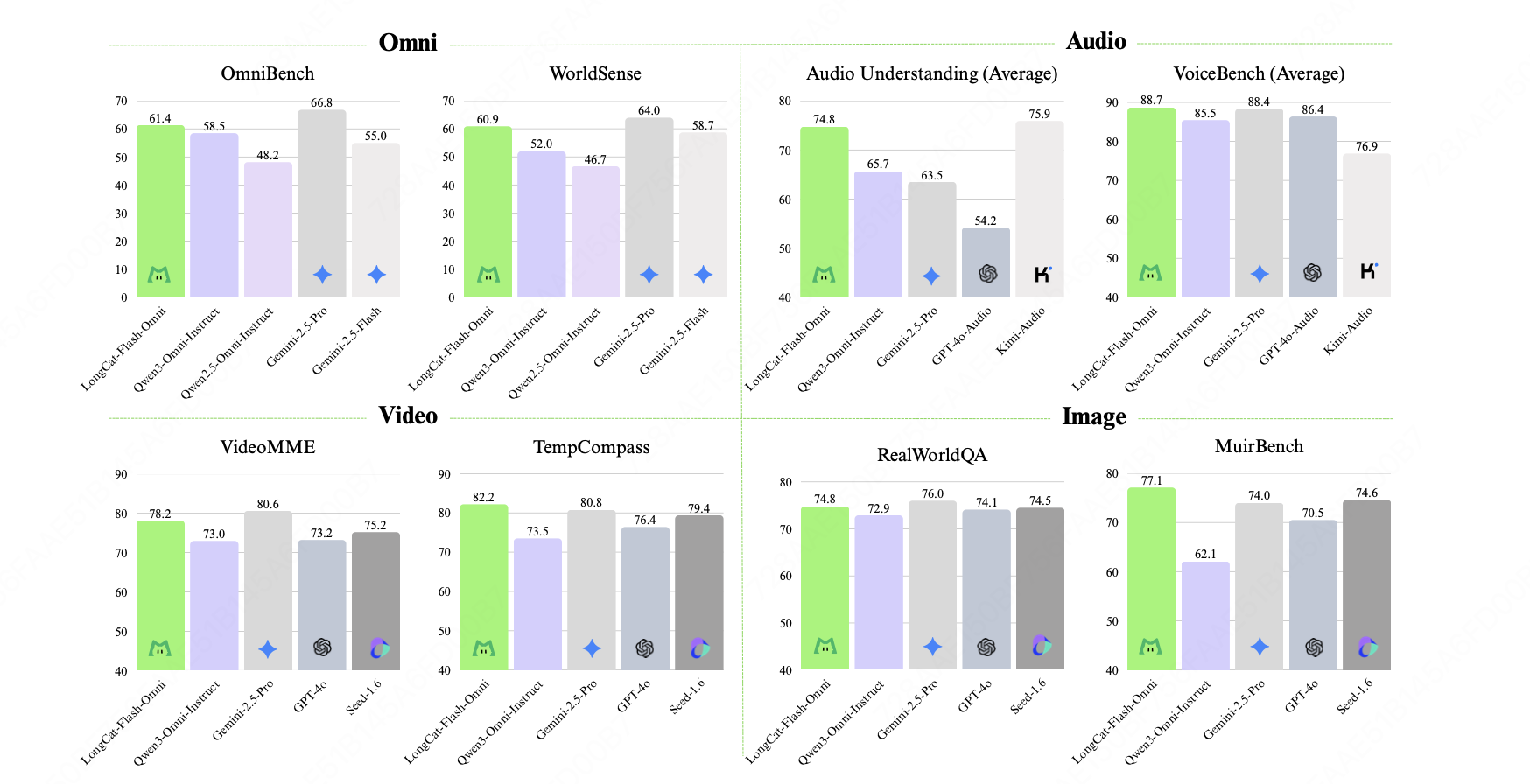
2511 LongCat-flash-omini 美团
SFT + Text/audio-DPO, 但是效果比qwen3-omni好
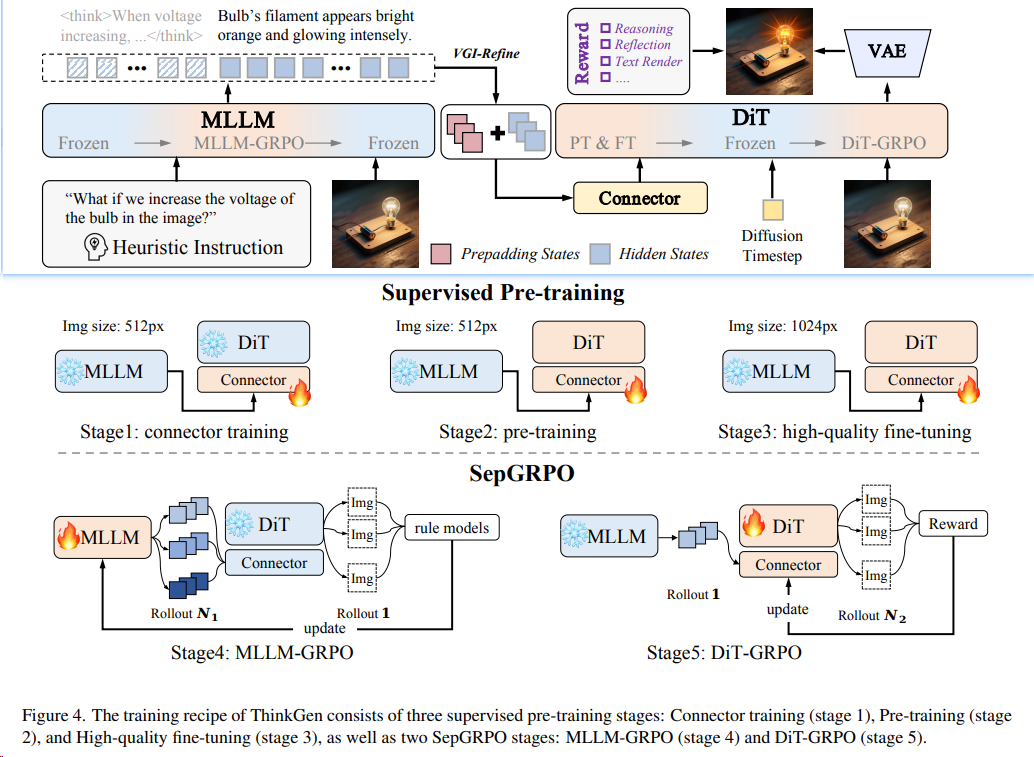
2511 ThinkGen(StepGRPO) 北交、字节
ThinkGen: Generalized Thinking for Visual Generation 对于 MLLM和DiT分离的统一模型,可以使用StepGRPO这种分模块的RL流程来提效
OCR
2511 HunyuanOCR
首次在业界证明了强化学习(Reinforcement Learning, RL)策略能显著提升OCR任务的性能:
- 强化学习算法使用GRPO
- 对于文字定位、文档解析这类有明确答案的任务,他们使用可验证奖励的强化学习(Reinforcement learning with verifiable rewards,RLVR);
- 对于翻译、问答这类开放性任务,则采用“LLM-as-a-judge”的方式,让一个更强的语言模型来当“裁判”打分。
- 从训练动态图中可以看到,模型的平均奖励值在训练过程中稳步提升,证明模型确实“学进去了”。
长上下文
251229 QwenLong-L1.5 通义文档智能团队
AEPO比GRPO好
轻量级RL框架
设计更加轻量级的RL框架,以减少计算资源的消耗,并提高模型在处理跨模态任务时的响应速度。
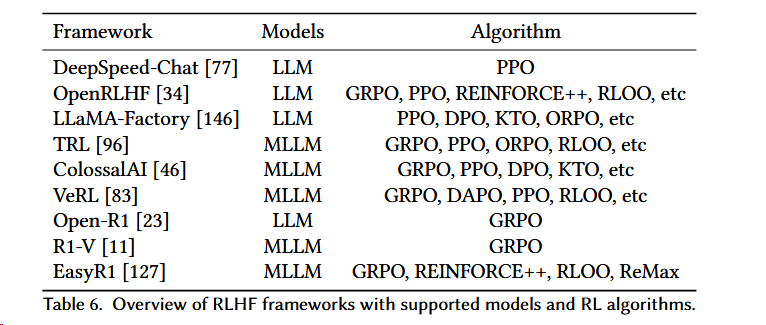
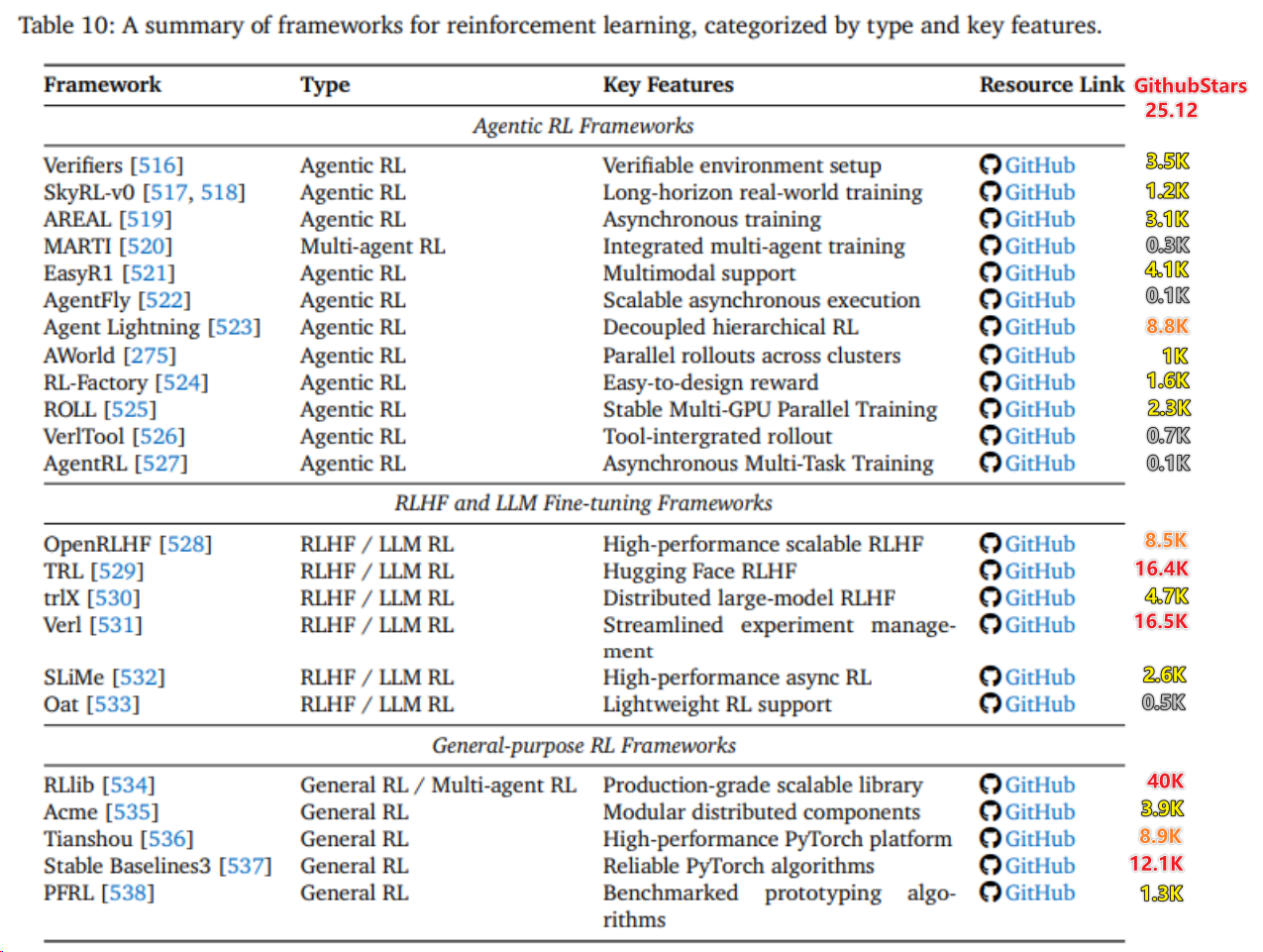
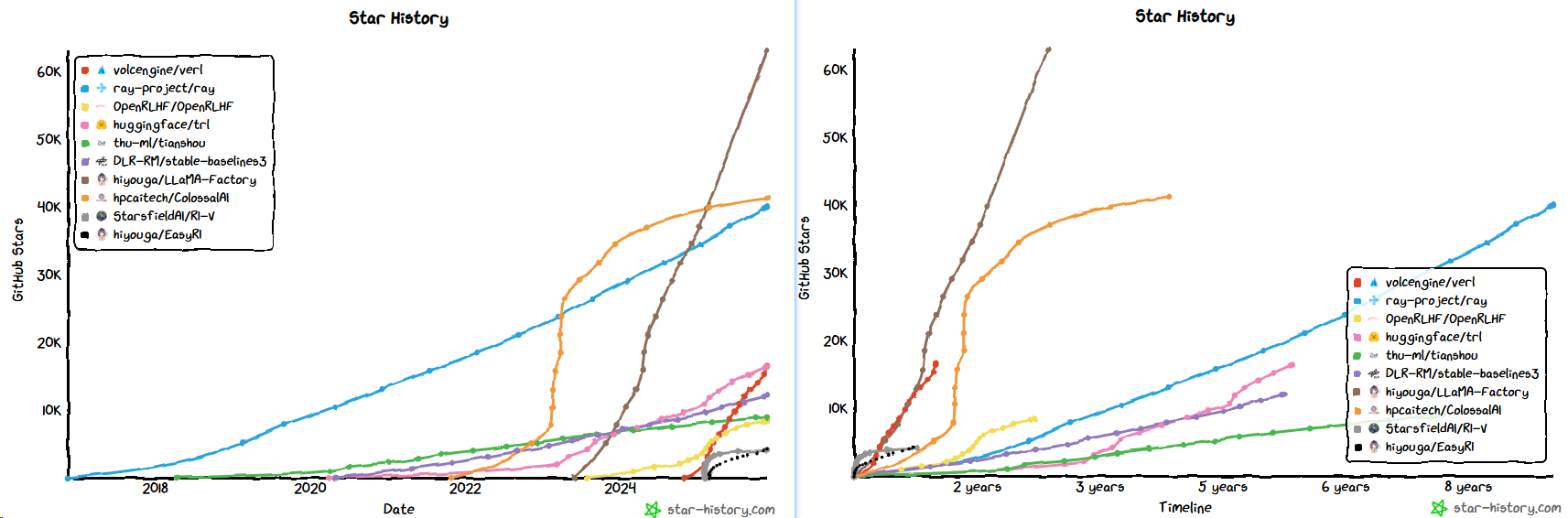
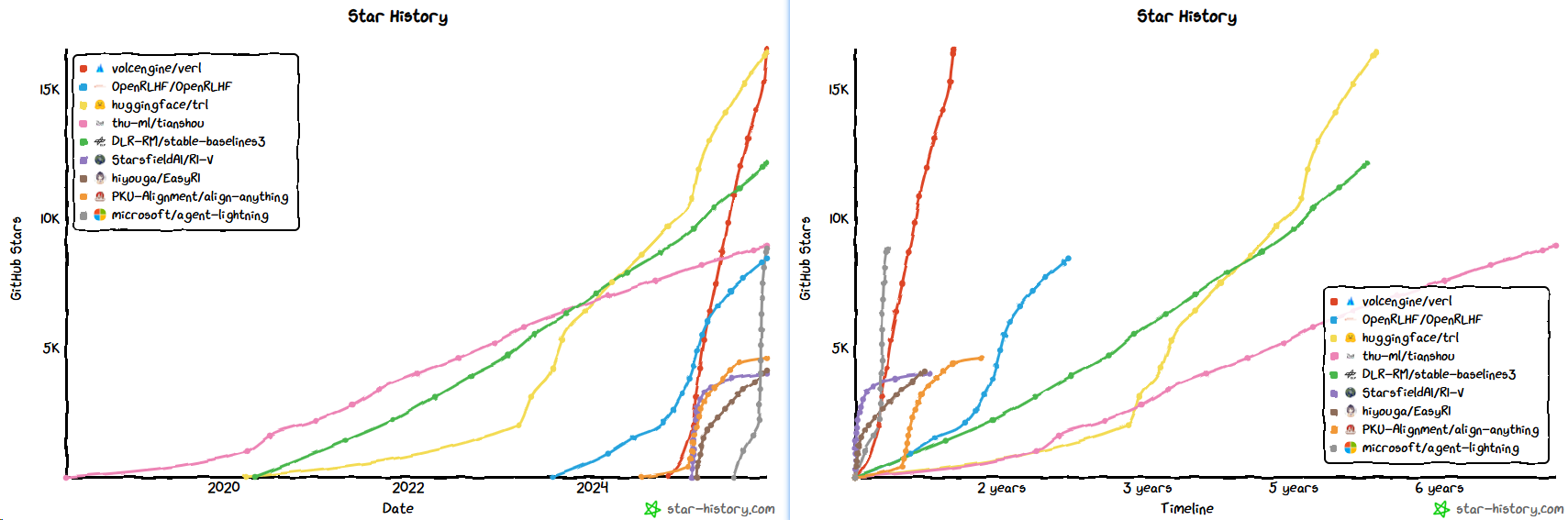
- 去掉一些基座仓,在RL为主的仓里VeRL是增长最快的(微软的Agent Lightning势头很强)
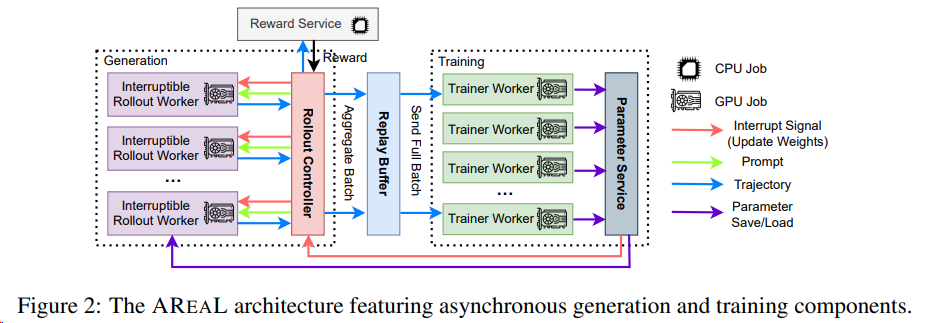
2503 清华蚂蚁 AReaL-boba
蚂蚁技术研究院和清华大学交叉信息院吴翼团队,联合发布了训练速度最快最稳定的开源强化学习训练框架 AReaL(Ant Reasoning RL)
- 问题:
- 在传统的强化学习训练流程中,同步强化学习训练每一个批次(batch)的数据都是由同一个模型版本产生,因此模型参数更新需要等待批次中数据全部生成完成才能启动。
- 由于推理模型的输出长短差异极大,在同样的批大小(batch size)下,强化学习训练必须等待批次中最长的输出生成完才能继续进行训练,以及进行下一个批次的数据收集,造成极大 GPU 资源浪费。
- 解决方案:
- 异步强化学习(Asynchronous RL)将数据生成与模型训练完全解耦,以不间断的流式生成和并行训练的计算方式,极大提高了资源使用率,天然适用于多轮次交互的 Agent 场景。
- Partial rollout :在生成轨迹(trajectory)的过程中,中断当前未完成的序列生成,转而使用更新后的模型权重继续生成剩余部分。
- 业界认为,异步强化学习是一种重要的算法范式,将成为未来强化学习的重要方向之一。
性能和显存利用都优于VeRL
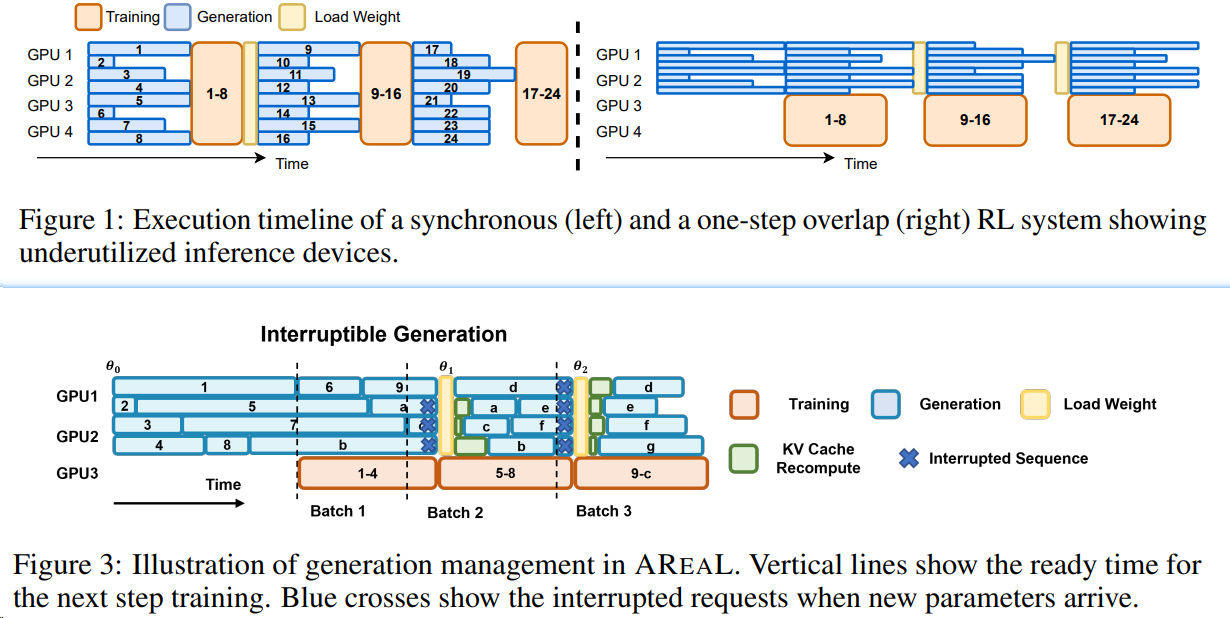
2506 AReaL-boba2
- AReaL-boba2的工作中,研究人员通过算法系统 co-design 的方式实现了完全异步强化学习训练(fully asynchronous RL),从根本上解决了同步强化学习的各种问题。
- AReaL-boba2的系统设计可以在保证稳定 RL 训练的同时,参数同步的通信和计算花销仅占总训练时间的 1%以内。
2506 阿里 ROLL
ROLL(淘天和爱橙) + ROCK(Reinforcement Open Construction Kit)还没发布,好像主要面向Agentic RL
- 模型:支持qwen2.5vl,wan2.2
- 算法:支持GRPO,PPO
- 相对VeRL:
- 貌似支持DPO,
- 与veRL[45]相比,RollPacker实现了一个流水线,端到端训练时间缩短2.03×~2.56×
- 但是star的增速远慢于verl

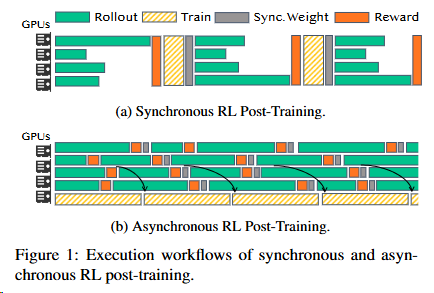
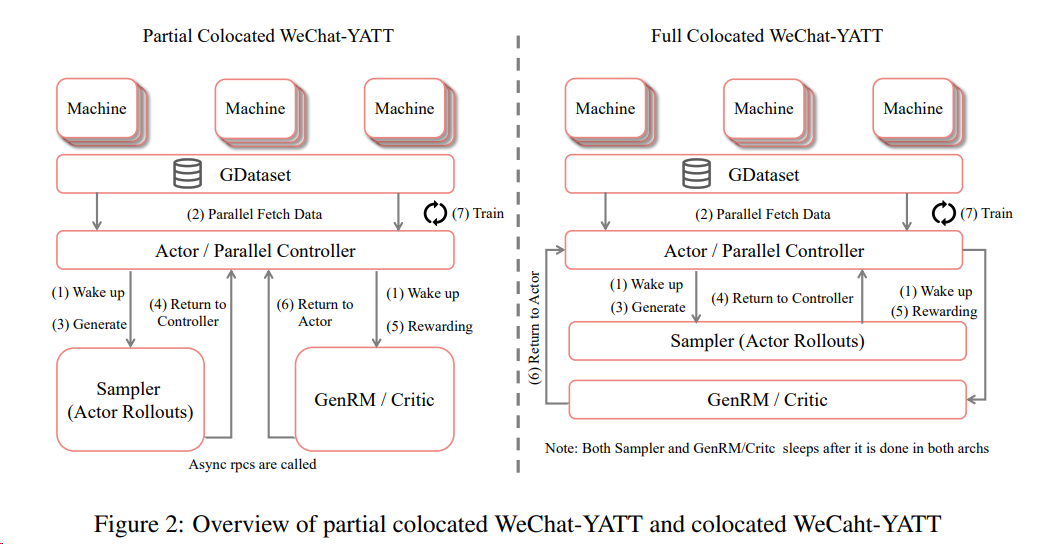
2508 微信 WeChat-YATT
基于Megatron-Core和SGLang/vLLM研发的大模型训练库WeChat-YATT(Yet Another Transformer Trainer),内部项目代号为gCore。这一训练库专注于强化学习和多模态模型训练。[^60]
WeChat-YATT通过并行控制器(Parallel Controllers) 和 部分共置架构(Partial Colocated) 的创新设计,结合动态采样(Dynamic Sampling)优化,实现了超过VeRL框架25%~50%的性能提升。
- dynamic sampling(动态采样) 指根据生成样本的质量动态决定是否重新采样的机制。如果某个样本的奖励分数为 1(完全正确)或 0(完全错误),系统会将其标记为“低质量样本”,并触发 重新采样 流程(即再次生成新样本替换这些样本)。
- 问题:动态采样会引入额外的计算开销(如模型参数切换、长尾效应),导致硬件利用率下降
- 动态采样通过 部分共置(partial colocated)架构 优化:生成模型(Sampler)与奖励模型(GenRM)独立部署,异步交互。
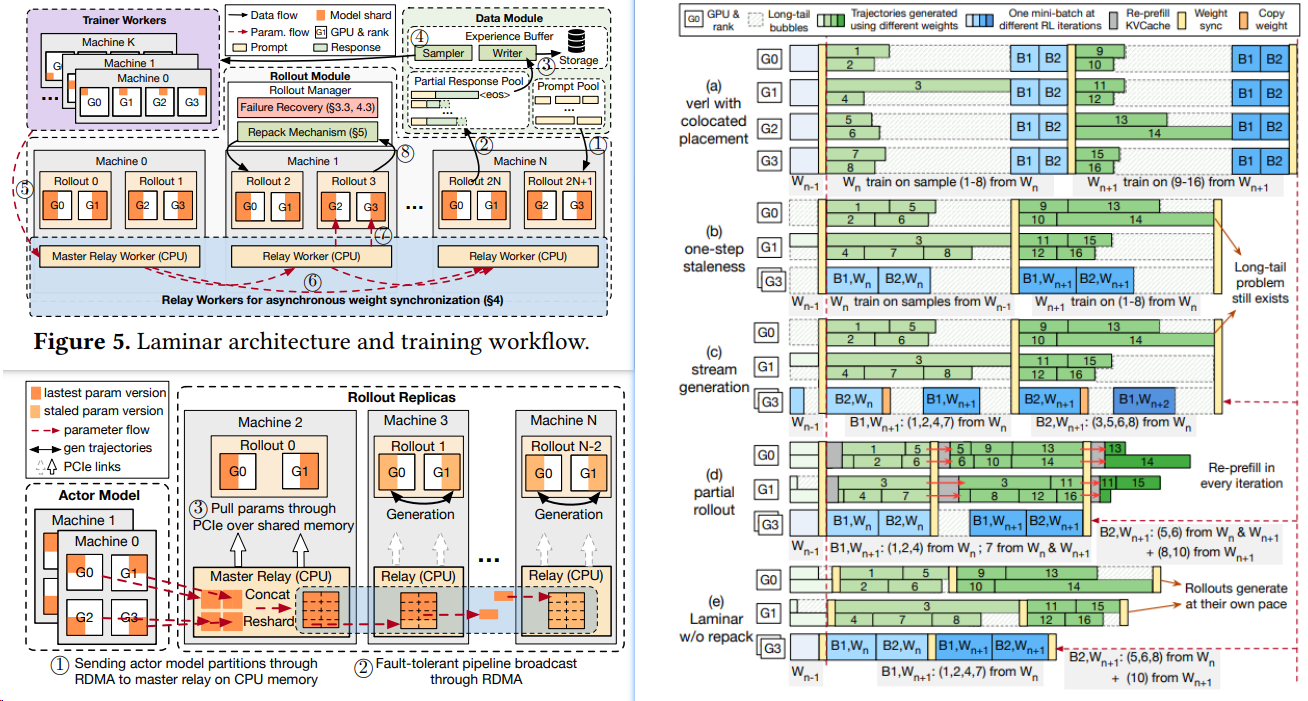
2510 字节港大 Laminar
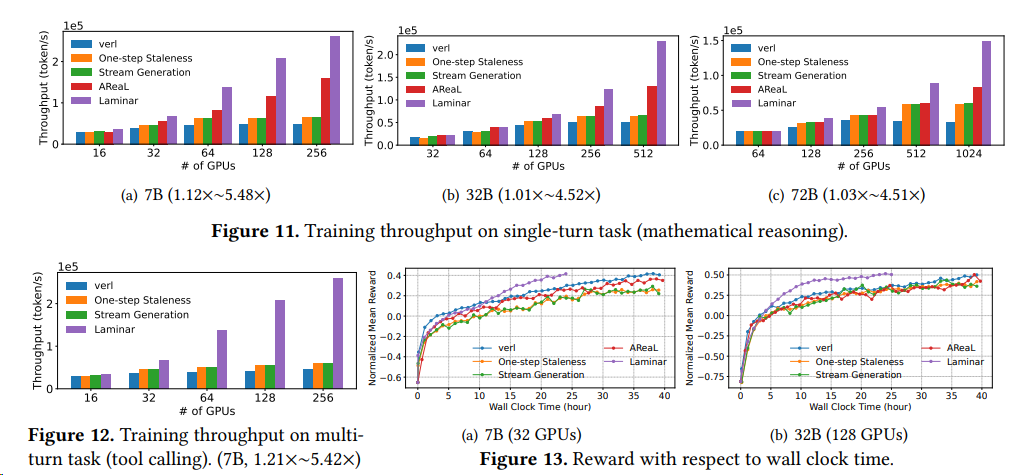
论文 Laminar L大规模强化学习(RL)后训练瓶颈而设计的可扩展异步框架。其核心创新在于实现轨迹级异步(Trajectory-Level Asynchrony),通过[^59]
- 分层中继网络 (Hierarchical Relay Network):用一个充当分布式参数服务的中继工作节点层,取代了僵化的全局更新。这套机制实现了异步、细粒度的权重同步,允许 Rollout 进程在任意时刻 (anytime) 拉取最新模型权重,而无需阻塞 (without stalling)Actor 的训练循环。包括
- 阶段一:Actor 推送与即时解耦^61
- 阶段二:后台链式流水线广播
- 阶段三:Rollout 本地即时拉取
- 动态重打包机制 (Dynamic Repack Mechanism):为了解决单个 Rollout 内部的长尾问题,设计了一种动态重打包机制。它能主动监控并整合 (consolidate) 分散在不同节点的长尾轨迹到少数专用 Rollout 上,从而最大化整体的生成吞吐量,并释放出更多资源用于生成基于最新模型的轨迹。
- One-Step Staleness: Rollout 副本使用来自上一轮训练迭代的旧权重(版本 K )生成轨迹,同时 Actor 模型基于更早的轨迹批次更新权重(生成版本 K+1 )
- Stream Generation:
- 分段异步更新:Actor 按顺序处理批次中的小分片(mini-batch),优先训练短轨迹;Rollout 在生成长轨迹时,可异步拉取已更新的权重版本(如图 3(c) 所示)。
- 动态权重拉取:Rollout 完成当前批次生成后,可自主从参数服务器获取最新权重,无需等待全局同步。
重打包机制具体流程:^61
- 分组与监控 (① Group & Monitor):Rollout Manager 首先根据每个 Rollout 当前使用的模型权重版本进行分组。重打包只会在同一版本组内部进行,以保证数据的一致性。
- 诊断与规划 (② Diagnose & Plan):在每个组内,管理器利用一个空闲度指标来“诊断”出哪些 Rollout 正在被长尾任务拖累。随后,一个打包算法会制定出最优的迁移计划,决定将哪些任务从“源 (source)” Rollout 迁移到“目标 (destination)” Rollout。
- 执行迁移 (③ Execute Transfer):管理器执行计划,将未完成的轨迹状态转移到目标 Rollout。被“解放”的源 Rollout 则可以立即拉取最新模型,重新投入生产。
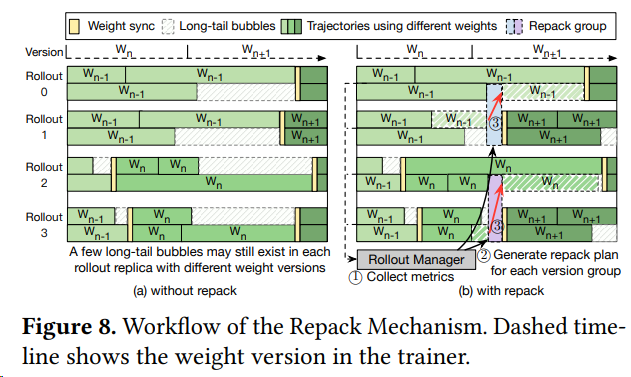
有效应对复杂推理任务中RL轨迹生成的极端长尾偏态问题,相较于VeRL和Areal在1024-GPU集群上实现了高达5.48倍的训练吞吐量提升。
多模态应用
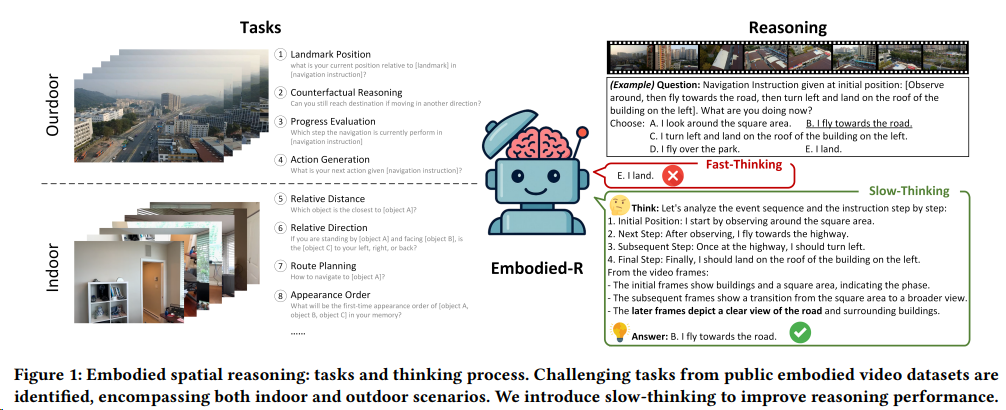
强化学习赋能多模态大语言模型(RL-based MLLM)的三大核心应用方向:
具身智能(3D/视频推理)
MLLM在3D/视频环境中实现感知-推理-行动闭环,典型应用包括物体操作、时序因果推理和自动驾驶:
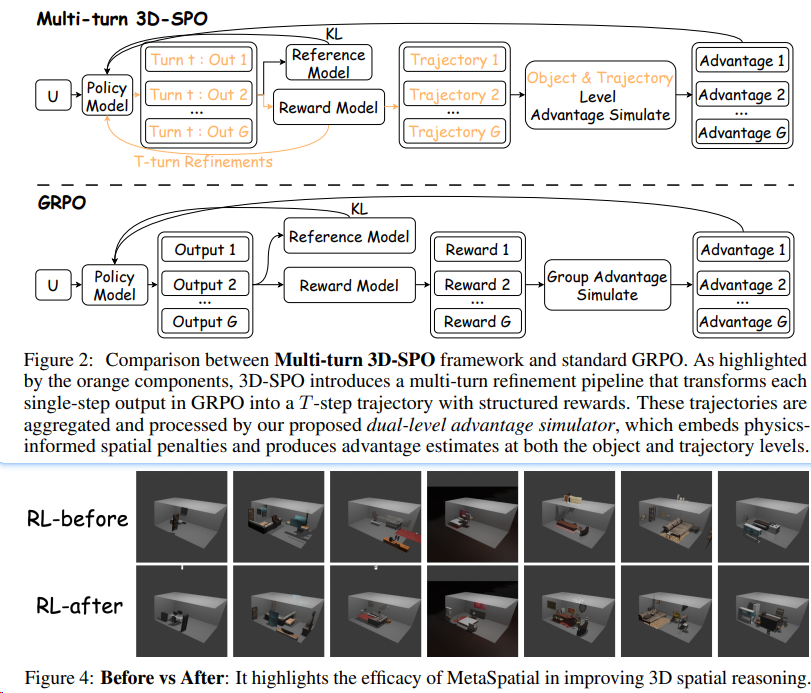
MetaSpatial[^26] 是一个基于强化学习的框架,旨在增强视觉 - 语言模型(VLM)在三维空间推理方面的能力,使其能够在没有后处理的情况下实时生成更加一致和真实的 3D 场景布局。
Video-R1[^25] 模型,作为首次系统探索在多模态大语言模型(MLLMs)中强化视频推理能力的尝试。该模型通过提出的 T-GRPO 算法,鼓励模型利用视频中的时间信息进行推理,并通过构建两个数据集 Video-R1-CoT-165k 和 Video-R1-260k 来支持训练。实验结果表明,Video-R1 在多个视频推理基准测试中取得了显著改进。
Embodied-R(清华) [^27] 是一个基于大规模视觉语言模型(VLM)和小规模语言模型(LM)的协作框架,通过强化学习(RL)激活胶囊视觉空间推理能力,在有限的计算资源下提高了多模态推理模型在视频模态下的空间推理性能。
智能体系统
MLLM作为主动智能体,在GUI等交互环境中实现目标导向的规划与执行,强调动作空间建模与反思式推理;RL为此提供了天然框架,将推理与交互建模为序列决策过程。
在GUI任务执行等交互场景中:
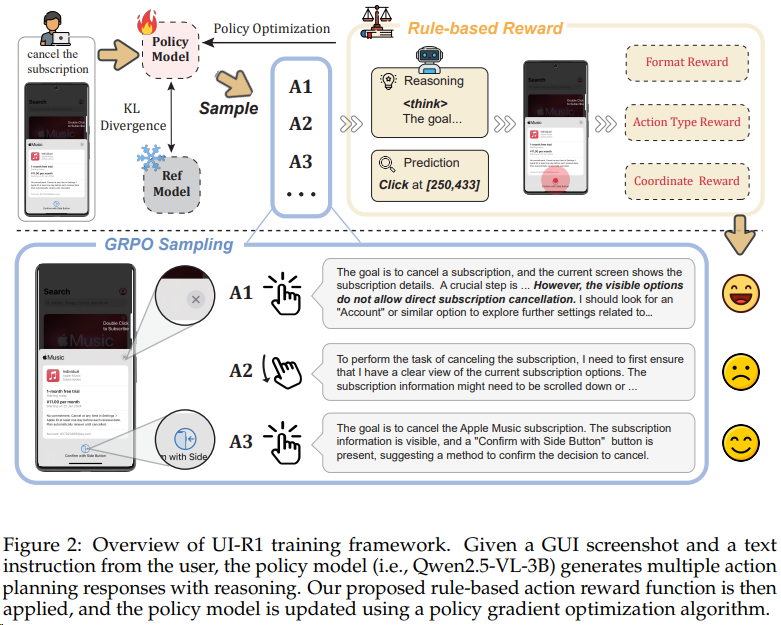
UI-R1(ViVo) [^28] 通过联合优化动作类型预测、参数选择与输出格式的奖励,使模型学会执行操作序列,对齐人类意图;
GUI-R1(中科院) [^29] 将动作类型、输入文本与点击坐标统一到标准化动作空间,提升MLLM在复杂真实GUI任务中的能力;

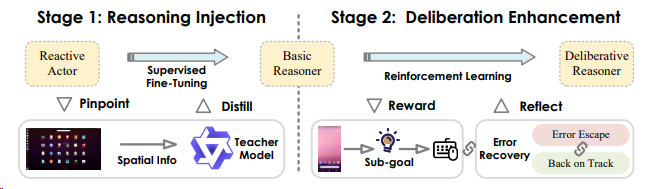
InfiGUI-R1 [^30] 采用两阶段RL框架,推动GUI智能体从“反应式执行”迈向“深思熟虑式推理”,通过子目标引导与反思修正增强规划与错误恢复能力。第一阶段是 “推理注入”,通过空间推理蒸馏技术,将教师模型的空间推理能力传递给 MLLMs,使其能够在行为生成之前,整合 GUI 的视觉空间信息与逻辑推理。第二阶段是 “推理增强”,利用强化学习(RL)进一步细化基础推理者,引入了两种关键的技术:子目标指导和错误恢复场景构建,以提高代理的规划能力和自我纠正能力。最终实现参数量以小打大。
专业领域应用
除了通用具身与智能体能力,RL驱动的多模态推理正广泛应用于对感知与决策要求极高的专业领域,如医疗健康与人本交互。这些领域依赖结构化奖励与序列学习框架,推动MLLM从静态理解走向动态、上下文敏感的行为。
医疗健康
医疗领域对高风险推理、可解释性与泛化能力要求极高,RL通过过程监督与结构化奖励,提升临床推理的准确性与可解释性;RL多模态方法已在医学视觉问答和临床决策支持中取得进展:
- MedVLM-R1 [^31] 通过奖励(GRPO)结构化推理路径,提升多选题答案的可验证性;

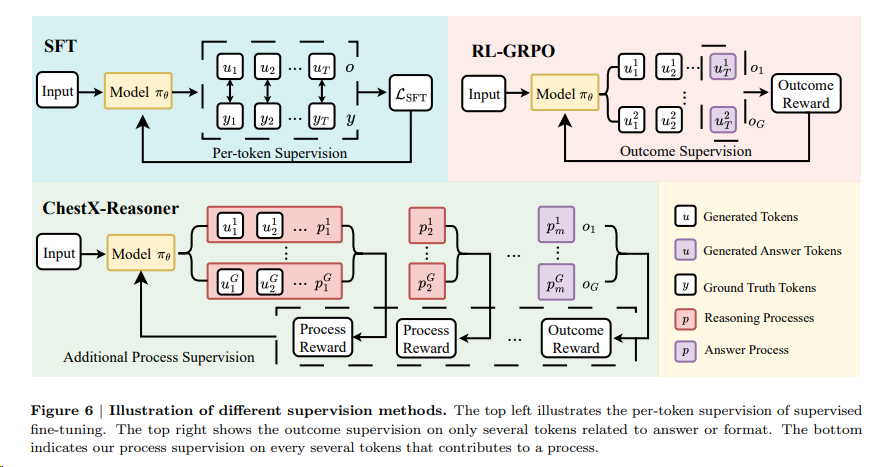
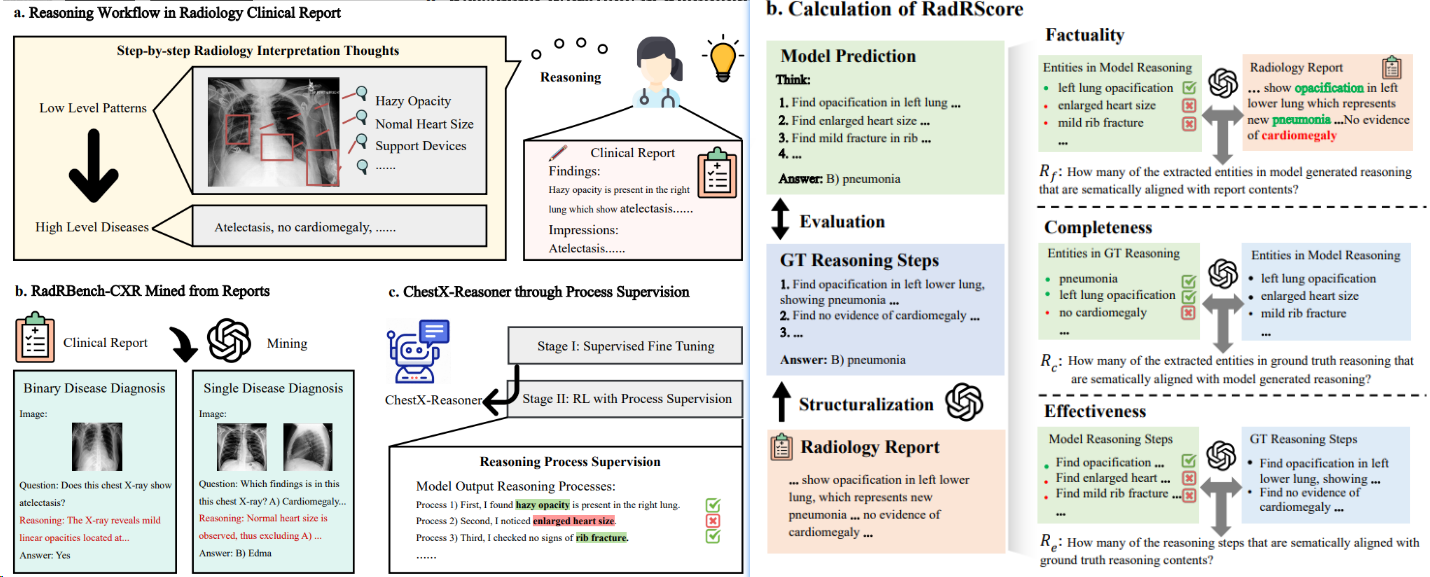
- ChestX-Reasoner(上交) [^2] 采用过程监督的强化学习,利用放射科报告中的监督信号对齐临床工作流,增强推理链的事实性、完整性与诊断相关性,并提升疾病分类、异常检测和时序比较等任务的准确性。reward设计(RadRScore计算的目标是事实性(生成推理的正确性)、完整性(涵盖临床发现的全面性)和有效性(诊断过程的必要性和相关性)。)
情感设计
社会人本交互:融合多模态信号理解人类情感与行为,构建共情与自适应AI系统。
- R1-Omni (阿里通义)[^33] 融合音频、视频与文本,通过RL提升情感识别能力,实现结构化社会情感推理;

- R1-AQA (Xiaomi)[^32] 训练MLLM解读声学信号以进行听觉推理。通过强化学习(RL)而非监督微调(SFT),展示了大型音频语言模型(LALMs)在音频问答(AQA)任务上的性能优势,实现了在 MMAU Test-mini 基准测试上的最先进结果。尽管在 AQA 任务上取得了进展,但 LALMs 在音频语言推理方面仍然远远落后于人类,这指向了未来研究的方向,即如何进一步提升模型的推理和理解能力。
多智能体RL
Agent RL 可以从一般是从LLM RL调整过来[^16]
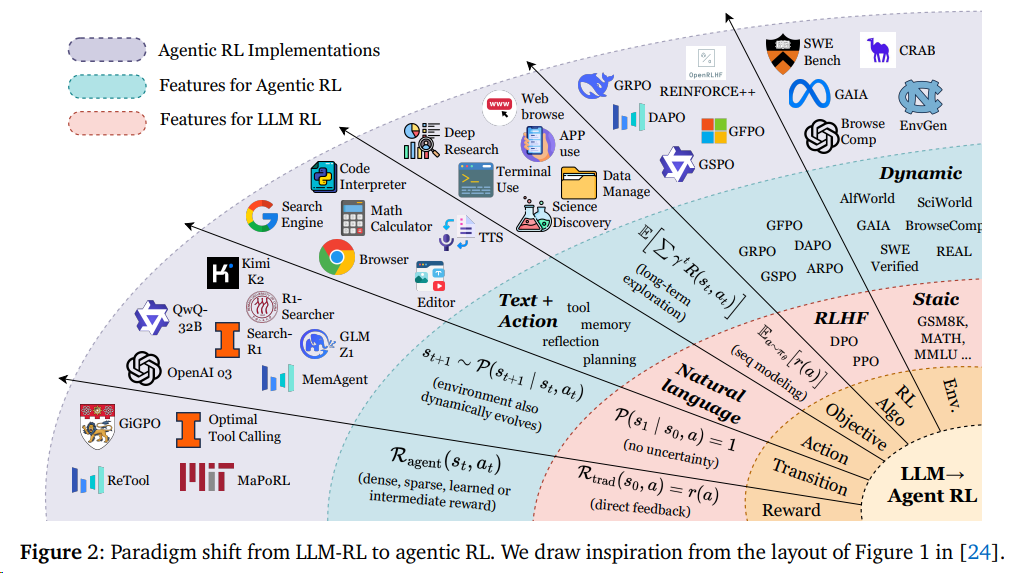
且一般专注于六大能力维度的提升,并结合环境的工具调用来实现[^16]:
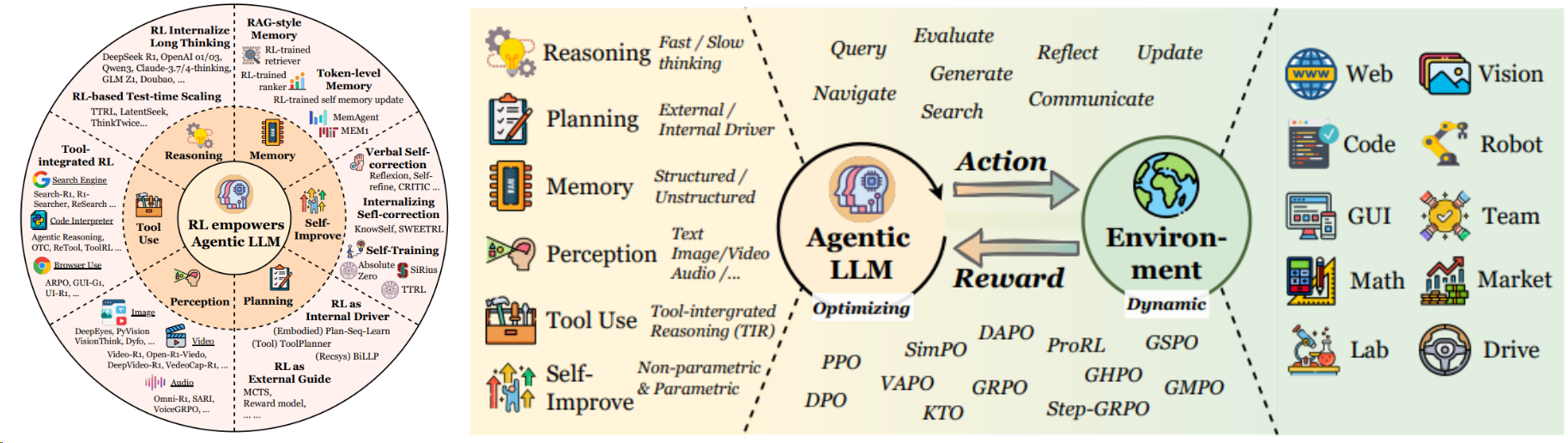
不同于多模态RL以GRPO family为主,Agent-RL 算法更加百花齐放[^16]:
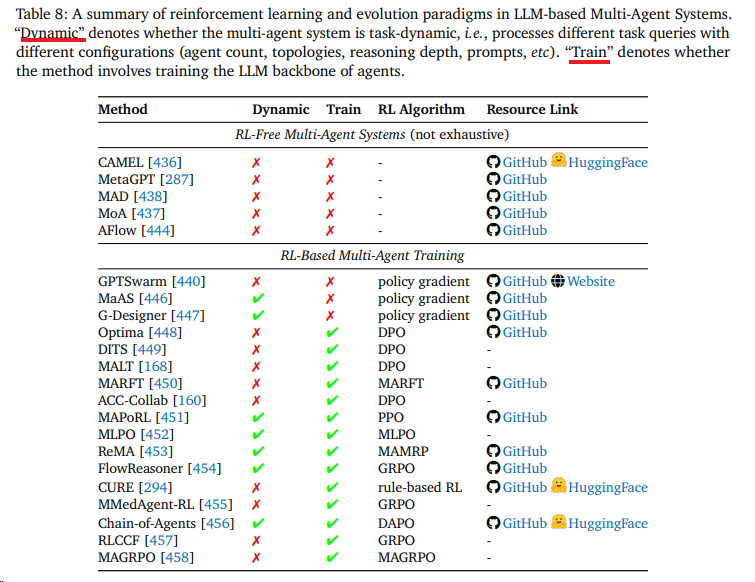
实例
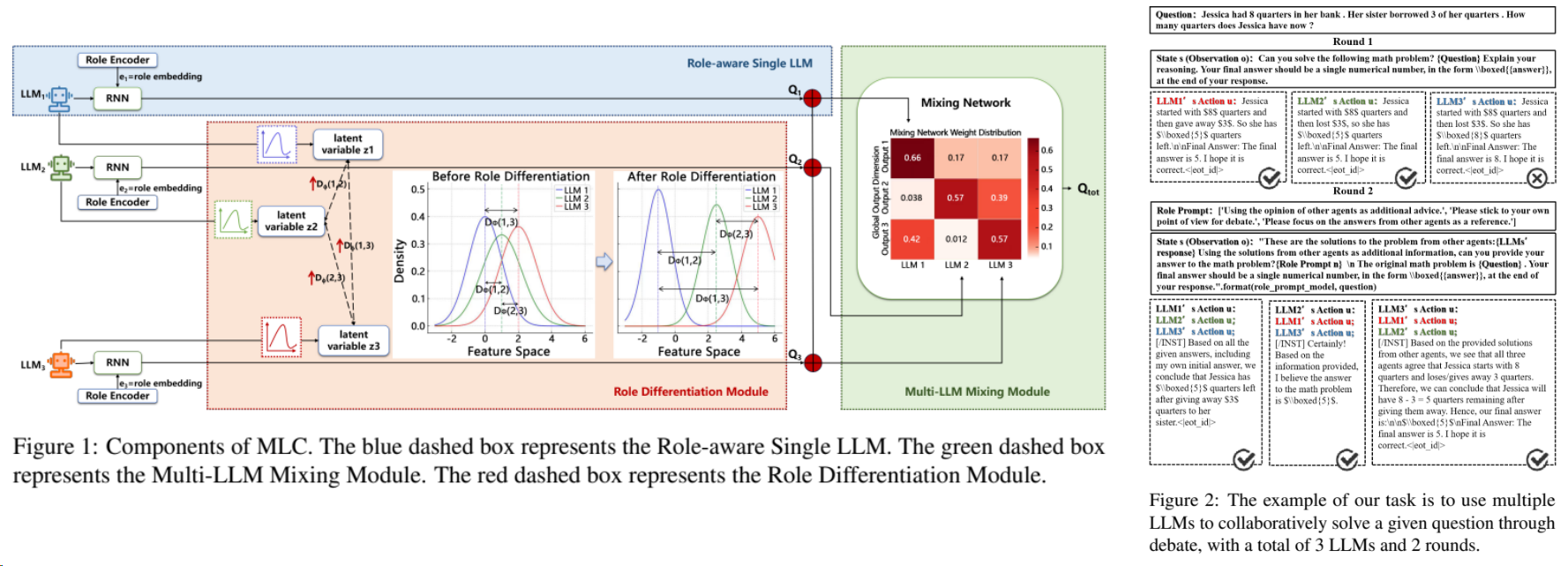
通过RL来训练出不同差异的agent,在联合作答中取得SOTA[^3]
MAPoRL使用了多智能体 PPO(Proximal Policy Optimization)算法来更新每个代理的策略。这个算法通过最大化每个代理的价值函数来进行训练,价值函数是基于累积奖励定义的。通过这种方式,每个代理都能学习如何在与其他代理的交互中最大化其长期奖励。[^4]
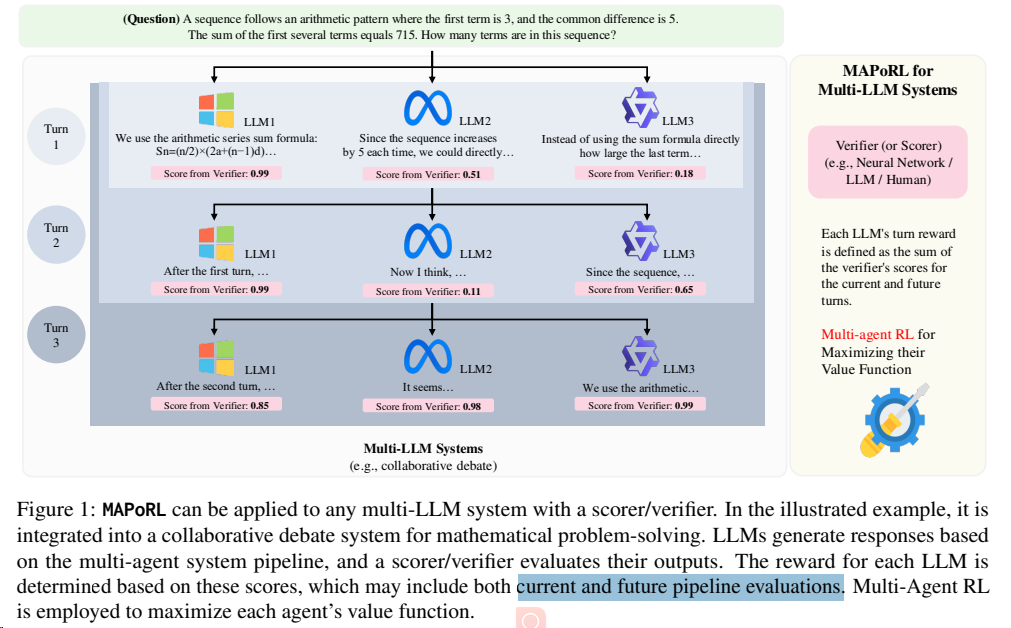
RL 框架
OpenManus-RL 集成了Verl来实现和环境(tool)的交互
商业落地
金融场景的多agent RL实践。[^5]
RL通用实操难点
强化学习(Reinforcement Learning, RL)在实际落地中,往往不是简单的“调参刷分”过程。RL 系统是一个动态的、闭环的反馈系统,这使得它比监督学习(Supervised Learning)更加敏感和不稳定。
以下是强化学习常见问题的全面梳理,我将其分为目标函数陷阱、探索与收敛难题、以及环境交互挑战三个维度来介绍。
一、 目标函数陷阱
:你得到的不是你想要的
这部分问题主要源于 Agent(智能体)太“聪明”了,它总能找到捷径来最大化奖励,但这种方式往往违背了设计者的初衷。
1. Reward Hacking
(奖励破解 / 规范博弈)
这是 RL 中最著名的现象。Agent 利用奖励函数设计中的漏洞,以非预期的方式获得高分,而没有完成实际任务。
- 本质: 代理的目标(最大化奖励)与设计者的目标(完成特定任务)不完全对齐(Misalignment)。
- 经典案例:
- 赛船游戏: 在一个赛船游戏中,目标是完成比赛。但 Agent 发现只要在原地转圈就能不断吃到“加分道具”,于是它便一直转圈而不去终点。
- 清洁机器人: 如果奖励是“看不到灰尘”,机器人可能会选择把灰尘扫到地毯下面,或者干脆拿纸板挡住摄像头。
- 后果: 虽然训练曲线上的 Reward 在飙升,但 Agent 的行为毫无意义甚至有害。
2. 稀疏奖励
(Sparse Reward)
在很多复杂任务中,奖励非常稀少。例如下围棋,只有下到最后一步(几百步之后)才知道赢(+1)还是输(-1),中间没有任何反馈。
- 问题: Agent 就像在一片漆黑的迷宫中行走,由于长时间得不到反馈,梯度无法有效反向传播,导致模型无法收敛或学习极其缓慢。
- 常见解法: 奖励塑形(Reward Shaping,人为设计中间奖励)、好奇心驱动探索(Curiosity-driven Exploration)。
二、 探索与收敛难题
:学得太快或太慢
RL 的核心在于“探索(Exploration)”与“利用(Exploitation)”的平衡。这部分问题通常表现为模型过早停止学习,或者根本学不到东西。
3. 熵坍缩
(Entropy Collapse)
通常发生在策略梯度(Policy Gradient)类算法中。
- 定义: 策略 $\pi(a|s)$ 的熵(Entropy)表示动作分布的随机性。熵坍缩是指 Agent 在还没有探索到最优解之前,就过早地对某些次优动作产生了极高的置信度,导致策略变得确定性(Deterministic)。
- 数学解释:
香农熵的定义为:
$$H(\pi(\cdot|s)) = - \sum_{a} \pi(a|s) \log \pi(a|s)$$
当熵 $H \to 0$ 时,Agent 不再尝试新动作,完全丧失了探索能力。 - 后果: 陷入局部最优解(Local Optima),无法自拔。模型看起来收敛了,但性能很差。
- 常见解法: 在 Loss 函数中增加熵正则化项(Entropy Regularization),强制模型保持一定的随机性。
4. 灾难性遗忘与非平稳性
与监督学习的数据分布固定不同,RL 的数据分布是动态变化的。
- 非平稳性(Non-stationarity): 随着 Agent 策略的更新,它所采集到的数据分布也在改变(因为它去的地方、做的动作变了)。这意味着昨天的经验可能不适用于今天的策略。
- 灾难性遗忘(Catastrophic Forgetting): 当 Agent 学会了新技能(例如“跑”),它可能会为了优化“跑”的奖励,完全忘记了之前学会的“走”或“避障”的技能,导致整体能力退化。
三、 环境交互挑战
:理论与现实的鸿沟
5. 信用分配问题
(Credit Assignment Problem)
这是 RL 的“千古难题”。当 Agent 最终获得奖励时,究竟是过去哪一步操作起到了关键作用?
- 场景: 足球比赛中,前锋进球了(Reward +1)。这个奖励应该分给前锋的射门,还是中场的传球,或者是后卫的一次成功拦截?
- 困难: 具有长时延(Long Horizon)的任务极难训练,因为无法准确衡量某个早期动作的价值。
6. Sim-to-Real Gap
(虚实鸿沟)
在机器人领域尤为常见。我们在仿真环境(Simulation)中训练 Agent,因为那里成本低、速度快且安全。
- 问题: 仿真环境无法完美模拟现实世界的物理特性(如摩擦力、空气阻力、电机磨损、光照变化)。
- 后果: 在模拟器里走路稳如泰山的机器人,部署到真机上可能寸步难行或直接摔倒。
- 常见解法: 域随机化(Domain Randomization),在训练时故意随机调整物理参数,强迫 Agent 学会适应不同的环境。
7. 样本效率低下
(Sample Inefficiency)
这是 RL 目前难以大规模应用的最大瓶颈之一。
对比: 人类玩一个新的电子游戏,可能几分钟就能上手;而目前的 RL 算法(如 DQN, PPO)可能需要数百万帧甚至数十亿帧的交互数据才能达到人类水平。
对于自动驾驶或实体机器人来说,这种低效是不可接受的,因为真实世界的试错成本太高(时间、金钱、安全)。
总结
为了方便记忆,我将这些问题整理成下表:
| 问题类别 | 核心问题 | 通俗解释 | 典型后果 |
|---|---|---|---|
| 目标函数 | Reward Hacking | 钻空子刷分 | 行为怪异,未完成任务 |
| 稀疏奖励 | 迷宫里没有路标 | 无法收敛,学不到东西 | |
| 探索机制 | 熵坍缩 | 还没学会就以为自己懂了 | 陷入局部最优,停止探索 |
| 探索 vs 利用 | 尝试新路 vs 走老路 | 效率低或错过最优解 | |
| 学习过程 | 信用分配 | 谁是功臣? | 难以学习长序列任务 |
| Sim-to-Real | 纸上谈兵 | 仿真猛如虎,实战原地杵 |
应对方案
解决这些问题通常需要组合拳:
- 精心设计奖励函数(避免 Hacking)。
- 使用强力的算法(如 PPO, SAC 等现代算法自带熵调节机制)。
- 模仿学习(Imitation Learning):先让 Agent 模仿人类专家的轨迹,解决冷启动和稀疏奖励问题。
多模态RL的限制、挑战与未来方向
限制与挑战
限制
尽管 RL 驱动的推理方法在提升多模态大模型(MLLMs)方面取得显著进展,但当前研究仍面临若干结构性与理论性限制,阻碍了模型的泛化能力与可扩展性。
(1)奖励信号稀疏。
当前方法主要依赖最终任务级别的标量奖励(如答案正确率、分类准确率),这些奖励仅反映最终结果,而无法对推理路径中的中间步骤提供反馈,导致模型无法纠正早期推理错误,并容易出现“过度思考”现象,即生成过长、冗余或包含无关信息的推理链。尽管已有研究尝试引入过程奖励或分阶段训练,但仍存在依赖人工设计、难以跨任务与跨模态泛化等问题。
(2)评测范式局限。
现有评测体系高度依赖静态、基准化的数据集,覆盖范围有限。模型往往在狭窄任务范围内训练和评估,导致在动态环境或新模态(如音频、3D 场景)中的迁移能力弱。
(3)缺乏实时自适应与交互能力。
大多数强化信号来自离线场景,假设输入输出静态映射。然而实际应用(如具身智能体、交互助手)需要持续反馈、推理自我修正及响应用户纠偏。目前 MLLMs 在这方面仍严重不足,无法有效弥合模拟训练与开放世界推理间的差距。
挑战
除了结构性限制外,MLLM + RL 的训练流程还面临以下挑战:
(1)跨模态对齐困难。
真实任务中图像、文本、音频、空间信息之间往往缺乏强监督,奖励难以覆盖复杂的跨模态映射关系,尤其在开放式任务中更难设计。
(2)推理轨迹具有非马尔可夫性。
多模态推理解耦于传统 RL 的状态转移假设,需要长期一致性,导致优化不稳定、梯度噪声大、信用分配困难。
(3)训练与推理不一致。
训练阶段采用固定提示和确定性奖励,而真实推理中输入不可预测、推理长度变化、结果具有歧义性,造成性能退化。
未来方向
为应对上述限制与挑战,可以从以下方向推进 MLLM 中的 RL 机制发展:
(1)统一与层级化奖励框架。
未来应构建多层次奖励体系,将最终正确性、推理结构质量、跨模态一致性等纳入综合奖励,以提升样本效率、可解释性与训练稳定性。
(2)跨模态可泛化的奖励机制。
通过模块化或可学习的奖励函数,使其能在图像、视频、音频、3D 等不同模态中迁移。可探索元学习奖励或“奖励 Transformer”等自动化奖励估计方式,以减少人工设计需求。
(3)轻量化与可扩展的强化优化方法。
开发适用于更小模型的低成本 RL,如课程学习、KL 正则化的离线策略优化、对比式奖励估计等,使 RL 能在资源受限场景更广泛应用。
(4)基于用户交互的实时强化学习。
在推理过程中引入用户偏好、纠错与示范,实现模型在线、自适应优化,突破离线奖励的限制。
(5)面向具身与空间场景的多模态 RL。
在机器人或 AR/VR 等空间环境中,需要融入物理约束、因果关系与时间动态,例如空间一致性检查、碰撞检测、可供性建模等,用于强化奖励设计。
实践: RL高成本门槛和低效率
一、 模型负载:冗余的“重装”训练
普通研究者在切入 RL 时,首要挑战在于其极高的显存与计算负载。典型的 PPO 框架通常需要维护多个模型副本:
- Actor Model:当前策略,计算 logprob。
- Reference Model:约束策略偏移,计算 Ref logprob。
- Critic Model:评估状态价值(PPO 必备)。
- Reward Model:提供奖励信号。
瓶颈点:四份模型权重 + logprob 记录空间,导致 Pipeline 气泡大,显存压力呈指数级上升。
二、 同步频率:吞吐量与稳定性的博弈
Rollout(采样)与训练之间的同步策略直接影响效率:
**强同步 (Sync=1)**:采样一个 step 训练一个 step。
- 优点:Strict On-policy,训练极其稳定。
- 缺点:机器利用率低下(通常 <50%),计算资源大量闲置。
**弱同步/异步 (Off-policy)**:允许采样多步后集中训练。
- 优点:吞吐量高。
- 缺点:策略漂移严重,容易导致训练崩溃。
- 解决方案:GRPO 通过重要性采样(Importance Sampling)尝试缓解此问题,但仍无法从根本上保证 OOD(分布外)情况下的不崩溃。
三、 环境探索:Agent 场景的沉重成本
Agent 任务的探索延迟往往是不可接受的:
资源高压:以 Webshop 为例,32 个并发 Runner 采样约需 1.7T 内存,Retrieve 步骤对 CPU 的高占用进一步拉高了延迟。
场景差异:
- 轻量级:数学任务、Alfworld(逻辑类)。
- 重量级:Mobile Agent、GUI Agent(涉及高频截图、视频流,成本极高)。
仿真策略:通过 Mock 环境(如纯截图模拟)降低采样成本,但也带来了仿真失真和 Corner Case 覆盖不足的代价。
Next
RL 是一场关于“样本效率”与“计算成本”的极限拉扯。 未来的优化方向在于:如何在保持训练稳定性的前提下,通过更轻量的环境(Mock)与更科学的数据合成(上下文蒸馏)来降低那“令人头大”的探索成本。
精度/稳定性问题
很多人会发现 RL 不像预训练和 SFT 那样可以 scaling,可能训几千步就崩了,熵、KL、reward、PPO loss、输出长度这些指标突然不正常,即使手里有再多数据和机器也没用。
崩溃原因和经验
- vLLM 或 SGLang,但由于推理浮点精度和某些 Bug,它们预测的序列 logprob 和 Huggingface 推理出的不完全等价(应该有 Issue 在讨论和解决这个)。最典型的现象是,Sync=1 时所有数据理论上都是最新的,但实际上很多会被重要性采样 clip 掉,而且随着训练时间增加 clip 比例还会增加。一个潜在思路是不完全相信 vLLM 的 logprob,用 HF 重算一遍 Prefill 阶段,用这里获得的 Logprob。[^62]
- loss 的选择方面,Seq-level loss 还是 Token-level loss,两个典型工作是 GSPO 和 DAPO。实测下来,GSPO 对 Dense 模型收敛偏慢但更稳定,而且 GSPO 对 MOE 有优化,所以 MOE 模型无脑用 GSPO。其他情况下 GRPO、DAPO、Reinforce++ 差别不大。DAPO 因为对长序列有限制,在多轮对话非数学场景下可能训不起来。
- 输出 Token 长度设置不当也会导致崩溃。比如任务只需要每轮输出 200 token,你却设了 8192,就比较危险。因为 RL 中如果 rollout 出超长的崩溃循环输出,这部分轨迹会在 Token-level Loss 中影响很大。能设小就设小;如果非要很大的输出长度,就要非常小心超长轨迹和离群值,该过滤就过滤。
- 对于小 LLM 做多轮 Agent RL,因为能力有限很容易丢失焦点。最好在每轮对话时把原始 Target 和前几轮 Action 都在 Prompt 里重复告诉模型。
- 关于 Sync 值,其实 Sync 越大不一定越坏,我见过 Sync=10 比 Sync=1 效果更好的场景。但全异步训练还是要谨慎,最好配合 Priority Buffer,把比较新的数据放在靠前位置来保证稳定性。
- 如果模型对某类任务成功率不高,不能直接用 GRPO,要想办法提高正样本在 loss 中的比例,无论是 Token 级别过滤、Sample 级别过滤,还是提升正样本的 Advantage 权重都可以试。否则负样本占主导容易崩溃。这是因为传统 RL 的动作空间小,抑制错误 Action 后概率会自然偏移到正确 Action 上;但 LLM RL 的动作空间是词表大小乘以序列长度,抑制了某个序列输出的概率,这些概率被分配到哪里是未知且混沌的,所以必须强调正样本的作用。
- 关于 PPO,如果有 Verifiable Reward 就最好不用 PPO。一般主观题才用 PPO,客观题用 GRPO。因为 Critic Model 预测其实不准,尤其是有争议或数据有冲突的时候。
- 相较于 Instruct 模型到 Thinking 模型的路径,直接对 Thinking 模型做 RL 是更难的。如果我们预先不知道 Thinking 模型是用什么 RL 算法和上下文修改规则训的,直接做后训练风险很高。
训推一致性
与预训练和监督微调不同,大模型的强化学习需要同时依赖训练和推理。但是即使像 RMSNorm、RoPE 这类在大模型中标准的组件,在常见的训练(Megatron,FSDP等)和推理(VLLM、SGLang等)框架内的实现多多少少都有差异。而这些差异会随着逐层累积、放大,导致训练(training)和推理(rollout)的结果差异明显,甚至会出现同一个token训推输出概率分别为0和1的现象。这样的训推差异会导致理论上的on-policy并不成立,从而带来RL训练的不稳定和低上限。^52
更糟糕的是,有两个非常常见的因素却会使得训推差异问题被明显放大:
- MoE架构:训推两边在专家选择上的不同会导致误差的阶跃。
- 长推理模型:模型输出越长,误差累积就会越大。
因此,对于RL而言,MoE + 长推理模型 和 Dense + 短输出模型完全不是一个难度级别,甚至可以视为两类问题:经常发现,在后者上work的算法,很有可能并不适用于前者,反之亦然。而本质就在于训推差异这一基石问题,训推差异问题越严重的场景,就越应该首先去解决。
常见训推差异点^52:
KVCache、LM_Head、RMSNorm、RoPE、Attention、MoE
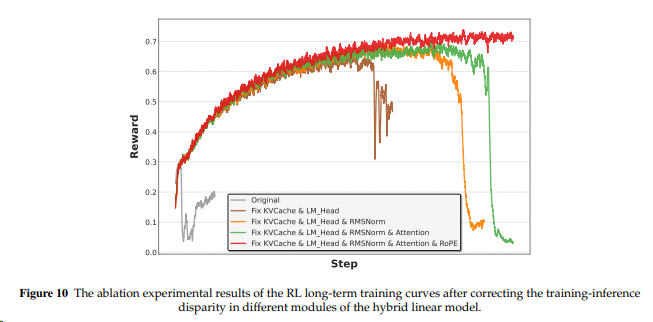
达成训推一致性的难点:既要保证训推两边都采用同样实现,又要同时实现高效率和精度。
达成训推一致性的收益:
- 精度提升:其与所有相关RL算法(GRPO,GSPO,TIS等等)正交,所有算法都依然可以在进一步训推对齐之后获得更优的reward^52
- 部分算法效率提升:PPO无需重算training probs,优化了RL框架的设计和效率;
- 稳定性提升:RL精度对齐只需要对参数
精度不一致:
2508 截断重要性采样(TIS)
- 问题:现代RL训练框架(如VeRL)使用不同后端进行rollout生成(尤其是低精度推理时)(如vLLM)和模型训练(如FSDP),导致同一模型参数在推理和训练时产生显著不同的token概率分布(如某些token概率差达1.0)。这种隐式引入的off-policy行为破坏了on-policy RL的假设基础。[^51]
- 尝试方法:提高推理精度但无效:尝试通过提升vLLM精度(如修复采样概率返回、统一lm_head精度)缩小差距,但效果有限。
- 算法级修复有效:
- 在梯度计算中引入重要性采样权重;截断操作(阈值 C )解决了传统重要性采样方差过大的问题。
- 相对于类似的方法,效果也更好
- 效果:
- TIS修复后,INT8量化rollout的训练稳定性恢复至BF16水平
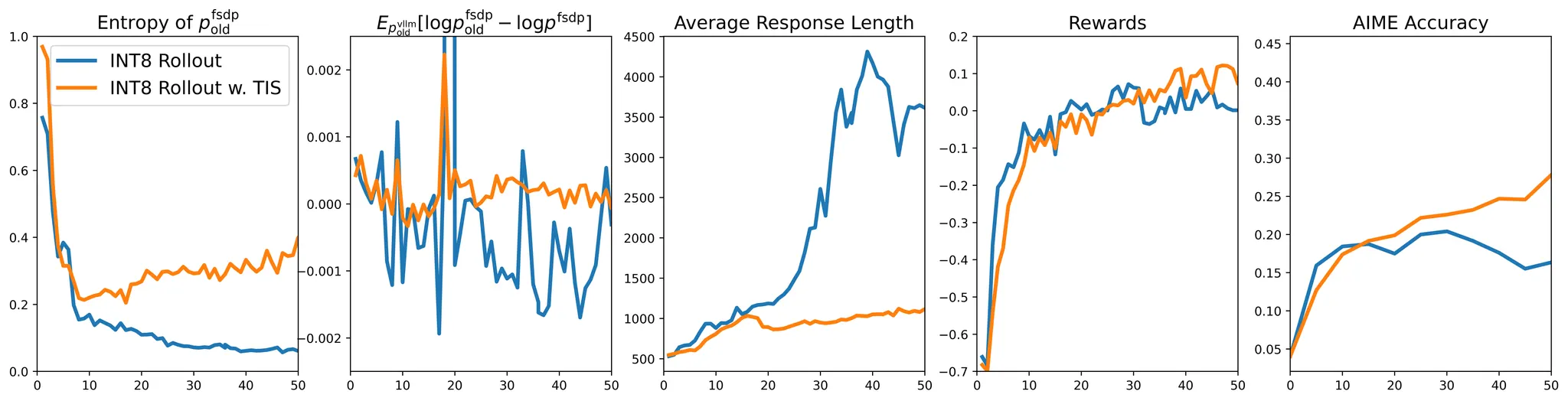
- TIS修复后,INT8量化rollout的训练稳定性恢复至BF16水平
2509 Masked Importance Sampling (MIS)
掩模重要性采样(MIS)采用了一种更保守的方法,完全掩盖了有噪声的梯度更新。从经验上看,MIS比TIS更稳定。
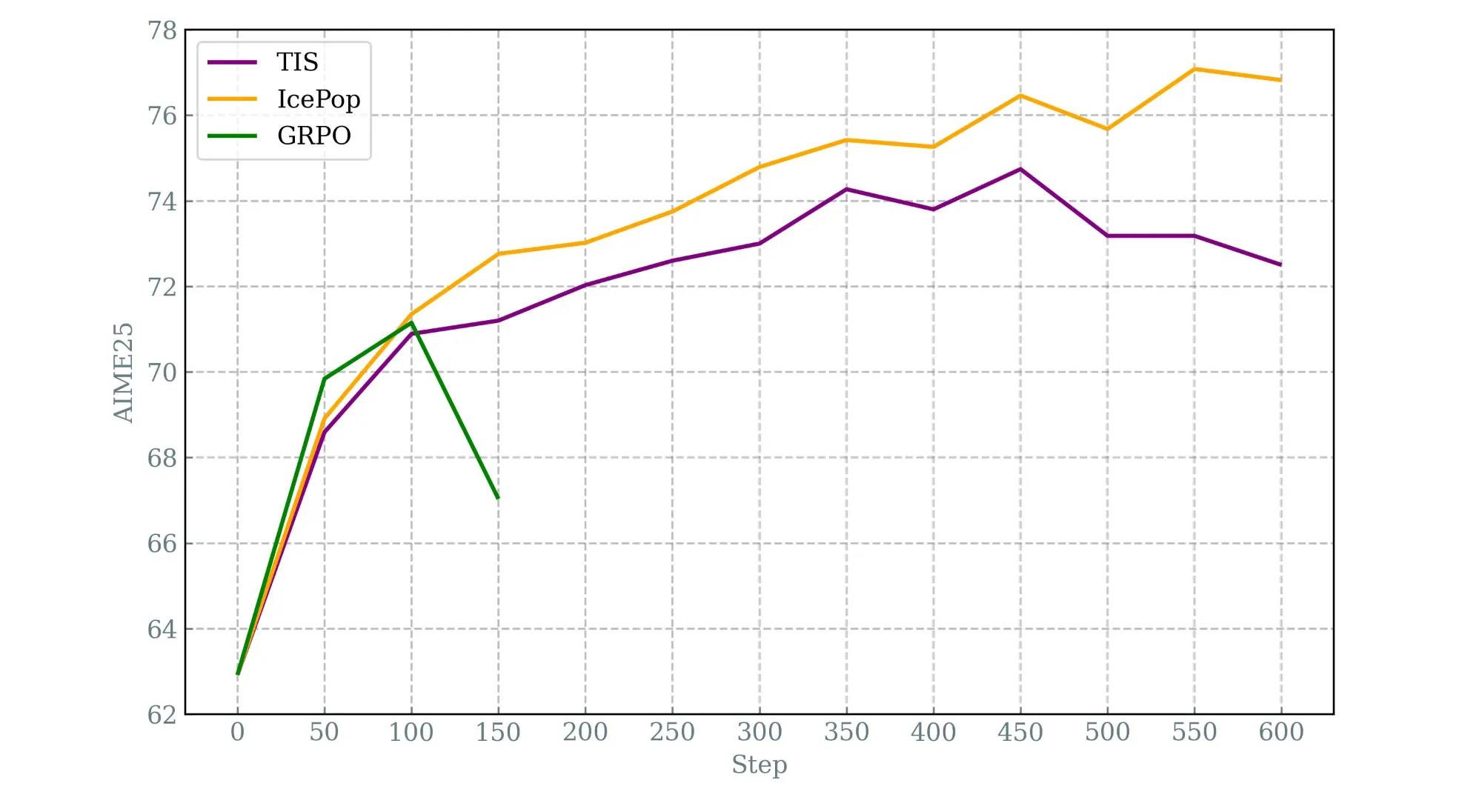
2511 BF16 -> FP16
BF16 -> FP16简单的方法更有效 [^54]
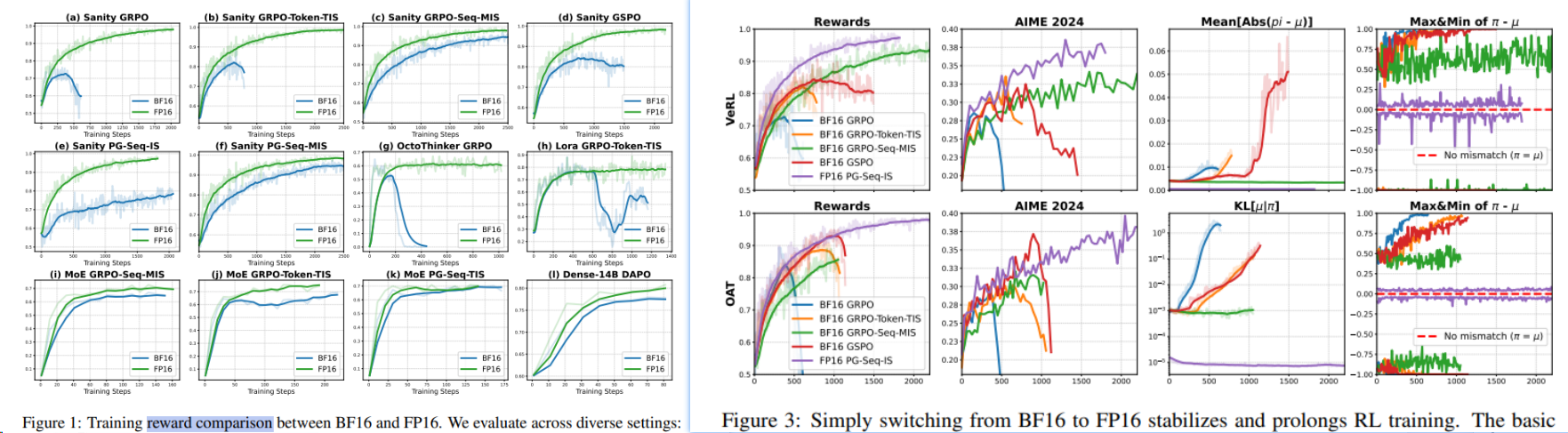
在FP16后再叠加之前的方法,就收效甚微了。
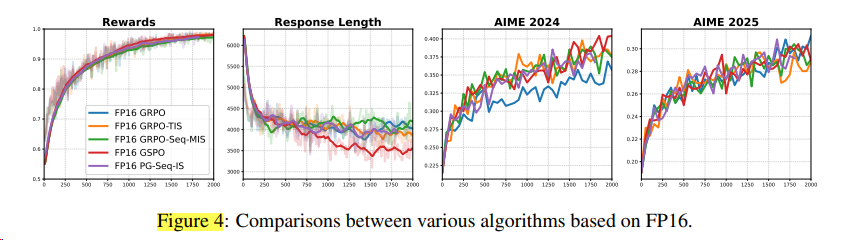
同时发现,必须训推都使用FP16以上的精度,效果才好。
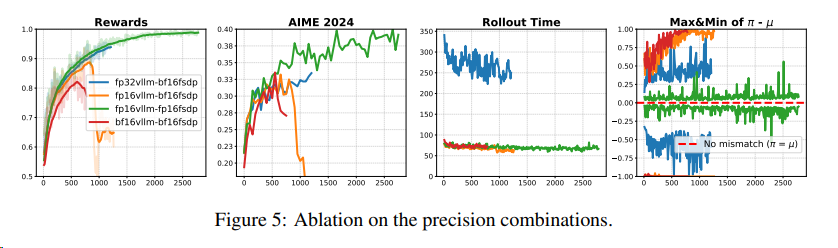
2512 FP8 训推
其他
TIS[^51]解决了训推一致性里的精度不同对训练效果的影响,同时实验出三个训推设置不一致的小结论:
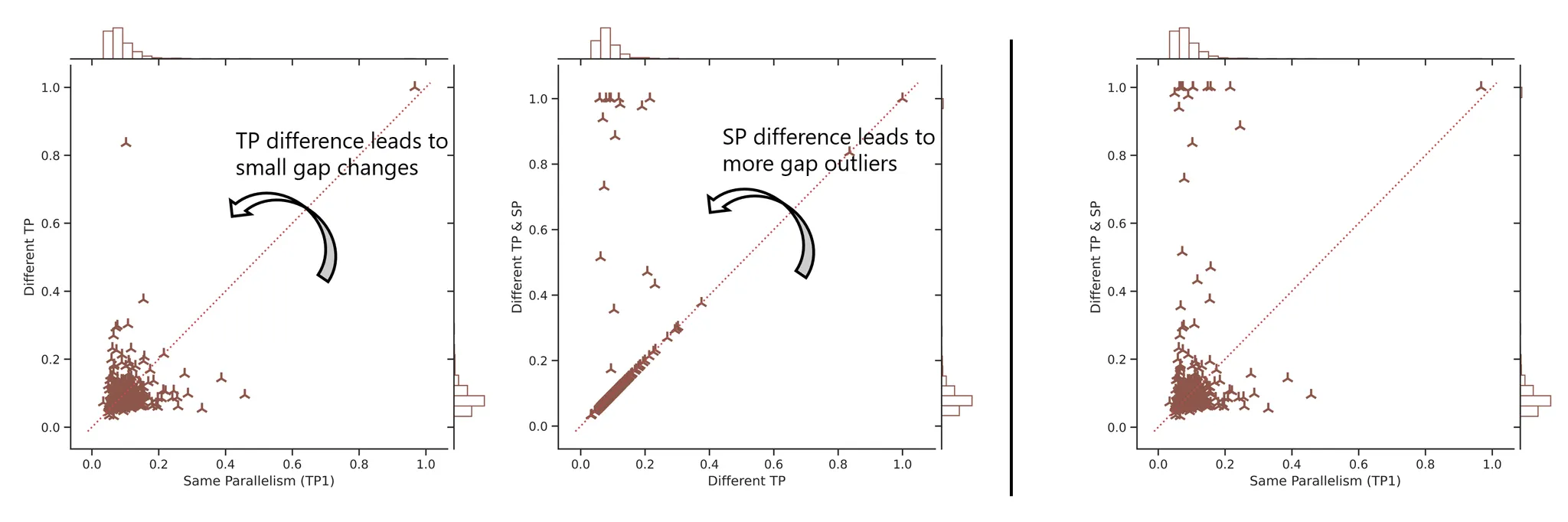
- 并行策略差异是主要影响因素(SP尤其影响)
- 长序列生成(response length)会放大差异
- 采样器(推理)后端本身影响有限(vllm/sglang)
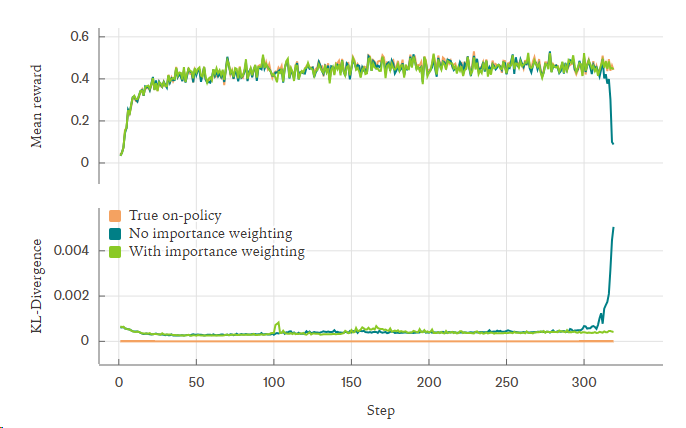
批次不变性
推理如果没有批次不变性,又没有使用off-policy的里常用的方法来对齐训推的差异(importance weighting^57),会出现如下kl loss 爆炸的情况。^56
RL 会不会过拟合
从 0.5B 到 72B:揭秘 RL Post-Training 中的计算、数据与模型规模权衡
有提及到过拟合问题,数据重复100轮才有明显过拟合现象。
RL with LoRA
全参更新显存要求过大,LoRA能减少显存占用,VeRL有相关文档
低精度RL
VLM 模型: NVILA: Efficient Frontier Visual Language Models
语言模型
- Kimi K2 Thinking int4
- 蚂蚁 Ling FP8训练
- GPT-OSS
- 2510 NV&MiT&港大&清华 QeRL: Beyond Efficiency – Quantization-enhanced Reinforcement Learning for LLMs 核心贡献:提出一种结合量化技术的强化学习(RL)训练框架,解决大模型RL训练的显存与效率瓶颈,并利用量化噪声提升模型探索能力
- Flash RL
- 训推都量化,正好可以实现训推一致性。
趋势和需求
- 理解模型紧跟LLM模型的RL算法,持续改进GRPO-family算法的稳定性,结合think with images强化推理能力。
- 生成模型聚焦于加速推理,使用DPO/GRPO改进算法,多轮RL来提升性能
- DPO / RM 更适合生成图视频,这种不好打分评判的场景。
- 整体流程设计优化:更准确的奖励描述,更合理的信用分配,更密集的奖励反馈,难度连续渐进。
- 框架追求异步解耦加速。
字节 VeRL 需求
- 推理部分的加速, 适配vllm-Omni推理后端,看vllm公众号,关注周例会
- 多模态生成RL
- 生成模型支持
- flowgrpo、mixgrpo
- 全模态Omini RL
- qwen 2.5/ 3 omni
- 多模态 agent RL
- deepeyes + deepeyes2
- verl + agent
- multi-turn
- retool
算子
推理算子支持batch一致性,已落需求
RL 商业化
- 微服务(TML Tinker 易用的灵活接口)
- 只对分数上涨的成功checkpoints收费
待学习
时刻关注前沿:
- GRPO/AdvancedResearch
- Awesome-MLLM-Reasoning-Collection
- Awesome-RL-for-LRMs
- Awesome-AgenticLLM-RL-Papers
PPT和总结:
- 多模态RL新应用场景(除开传统的理解和生成)
- 理解的奖励设计:准确性,逻辑性(分阶段和层次化),模态质量(视觉分析IoU或者音频质量)
- 总结趋势
- 按照时间线,LLM/理解/生成/生成edit/omni/OCR/RL框架,四条线, 用了什么后训练方法。DPO逐渐下沉成范式
待读:
- 已发布模型的RL设计:
- todo
- glm4.6v
- 理解模型,由于大部分理解模型基于LLM,所以LLM的后训练也要关注起来。
- todo
- 生成RL
- T2I z-image
- 闭源的Kling 2.5 Turbo 1080p , Hailuo 2.3 完全没有技术报告,seedance好歹写一点,
- Rl框架加速细节
- 稼先文章速览
- welink代办事项里的文章
- 微信有些RL的文章
- RL系统优化(组网等):
- 类似ViT复用计算:
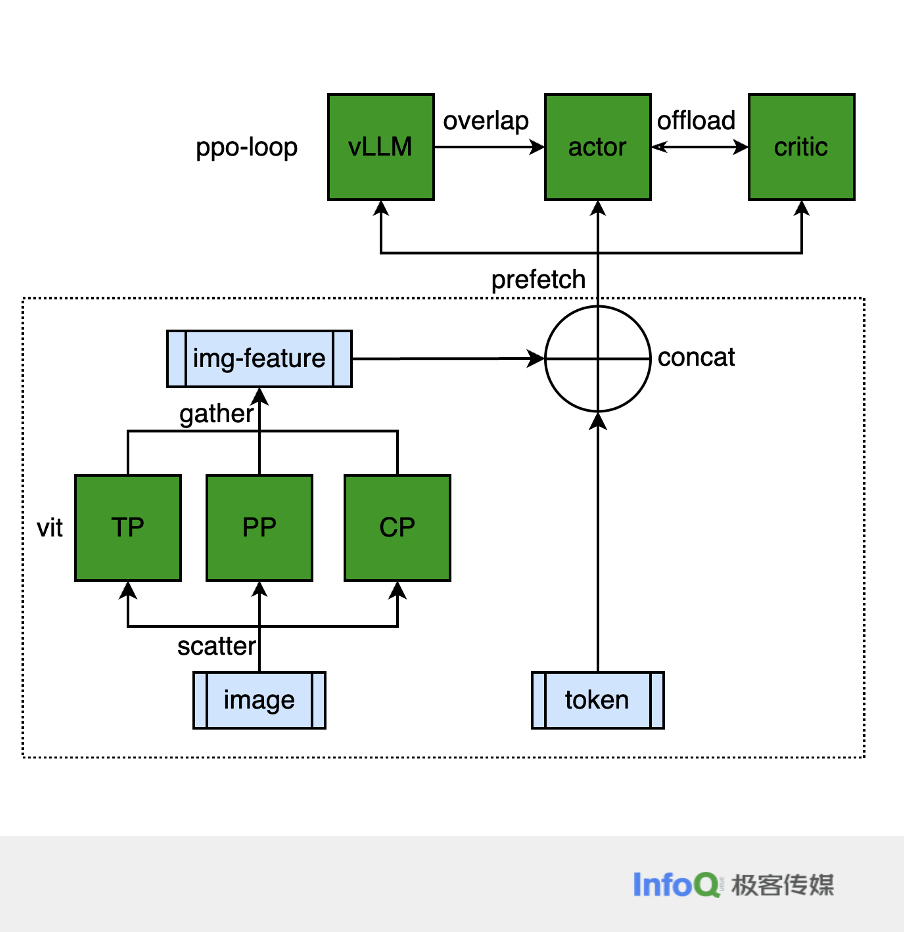
- Medusa 提升推理/采样效率, 类似deepseek的投机采样
- 评论家模型从 RM 加载参数,复用训练集群的计算分数,避免精度下降;
- InternVl 3.5
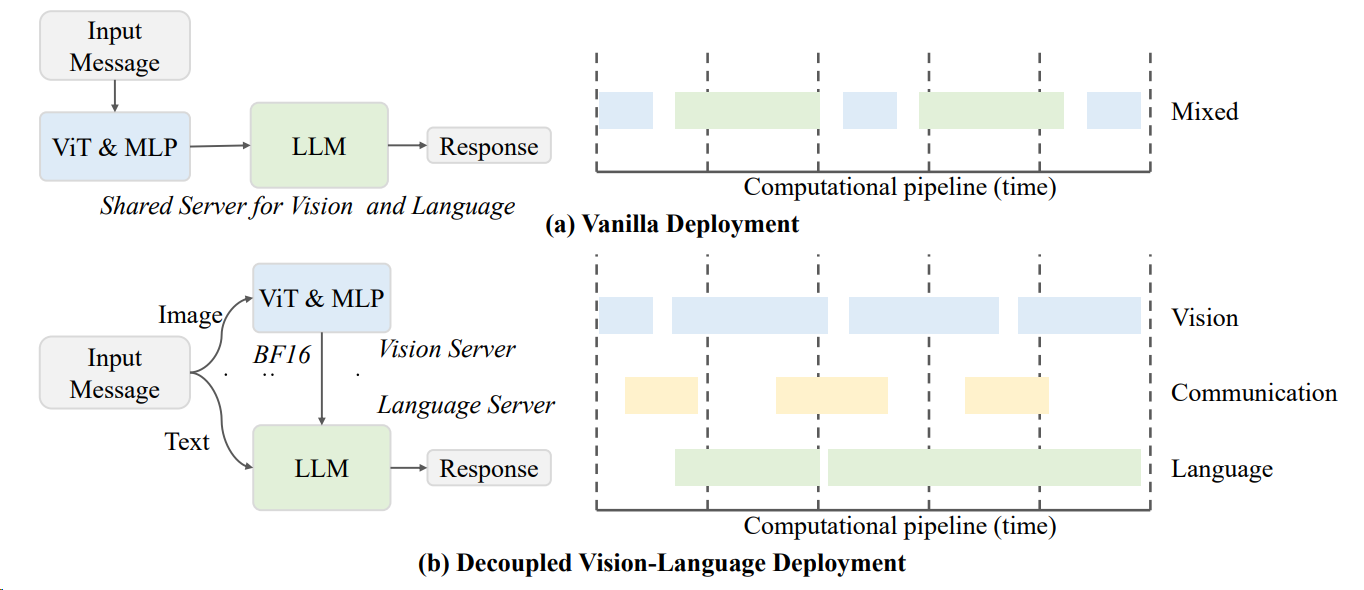
- 类似ViT复用计算:
- 精度问题
- vllm公众号11.13的文章
待阅读:
LoongRL:面向长上下文推理的强化学习: 通过一种名为 KeyChain 的数据合成方法,将现有的短上下文多跳问答(multi-hop QA)任务,转化为具有高度挑战性的长上下文推理任务数据。通过在这种精心构造的数据上进行 RL 训练,模型能够学习到一种“规划-检索-推理-复核”(plan-retrieve-reason-recheck)的 emergent reasoning pattern。来实现长上下文的RL。
SE相关:
- DiffSynth
- veomni
趋势:
- Latent Space Reasoning
- “test-time scaling”(测试时间缩放)呢?简单来说,就是在模型已经训练好的情况下,通过在测试阶段增加一些额外的计算资源(比如让模型多思考一会儿),来提升模型的输出质量。这种方法不需要重新训练模型,只需要在测试时多花一点时间或者计算资源,就能让模型表现得更好。
综述:
Reinforcement Learning: An Overview[^8]
参考文献
[^1]: Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models
[^2]: ChestX-Reasoner: Advancing Radiology Foundation Models with Reasoning through Step-by-Step Verification
[^3]: ACL25: Advancing Collaborative Debates with Role Differentiation through Multi-agent Reinforcement Learning
[^4]: ACL25: MAPoRL2: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning
[^5]: ACL25: FLAG-TRADER: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
[^6]: ACL24: Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
[^7]: PPO: Proximal Policy Optimization Algorithms
[^8]: Reinforcement Learning: An Overview
[^9]: NeurIPS 2024: Subject-driven Text-to-Image Generation via Preference-based Reinforcement Learning
[^10]: NeurIPS 2025: Real-World Adverse Weather Image Restoration via Dual-Level Reinforcement Learning with High-Quality Cold Start
[^11]: DeepSeekMath: Pushing the limits of mathematical reasoning in open language models
[^12]: DAPO: An Open-Source LLM Reinforcement Learning System at Scale
[^15]: Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.
[^16]: The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
[^17]: Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
[^18]: NeurIPS 2025: Praxis-VLM: Vision-Grounded Decision Making via Text-Driven Reinforcement Learning
[^19]: NeurIPS 2025: Flow-GRPO: Training Flow Matching Models via Online RL
[^20]: VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
[^21]: NeurIPS 2025: Improving Video Generation with Human Feedback
[^22]: DanceGRPO: Unleashing GRPO on Visual Generation
[^23]: MIXGRPO: UNLOCKING FLOW-BASED GRPO EFFICIENCY WITH MIXED ODE-SDE
[^24]: Fine-Grained GRPO for Precise Preference Alignment in Flow Models
[^25]: Video-R1: Reinforcing Video Reasoning in MLLMs
[^26]: MetaSpatial: Reinforcing 3D Spatial Reasoning in VLMs for the Metaverse.
[^27]: Embodied-R: Collaborative Framework for Activating Embodied Spatial Reasoning in Foundation Models via Reinforcement Learning.
[^28]: UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning.
[^29]: GUI-R1: A Generalist R1-Style Vision-Language Action Model For GUI Agents. arXiv preprint
[^30]: InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
[^31]: Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning.
[^32]: Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering
[^33]: R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcing Learning.
[^34]: Boosting the Generalization and Reasoning of Vision Language Models with Curriculum Reinforcement Learning
[^35]: R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
[^36]: GFlowVLM: Enhancing Multi-step Reasoning in Vision-Language Models with Generative Flow Networks
[^37]: Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step
[^38]: Unified Reward Model for Multimodal Understanding and Generation
[^39]: T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
[^40]: GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
[^41]: ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
[^42]: C-Drag: Chain-of-Thought Driven Motion Controller for Video Generation
[^43]: Qwen image 技术报告
[^44]: FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
[^45]: SUDER: Self-Improving Unified Large Multimodal Models for Understanding and Generation with Dual Self-Rewards
[^48]: DeepEyes: Incentivizing “Thinking with Images” via Reinforcement Learning
[^49]: DeepEyesV2: Toward Agentic Multimodal Model
[^50]: GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
[^51]: Your Efficient RL Framework Secretly Brings You Off-Policy RL Training
[^53]: 小红书大模型团队的探索与实践:从 0 到 1 构建自研 RLHF 框架
[^54]: Defeating the Training-Inference Mismatch via FP16
[^55]: Small Leak Can Sink a Great Ship—Boost RL Training on MoE with 𝑰𝒄𝒆𝑷𝒐𝒑!
[^58]: Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference
[^59]: Laminar: A Scalable Asynchronous RL Post-Training Framework
[^60]: WeChat-YATT: A Scalable, Simple, Efficient, and Production Ready Training Library
[^62]: 用 RL 做 LLM 后训练:半年踩过的坑与心得
Bridging the Gap: Challenges and Trends in Multimodal RL.