Omni-Modal: AR vs DiT
AR 和 DiT 的区别
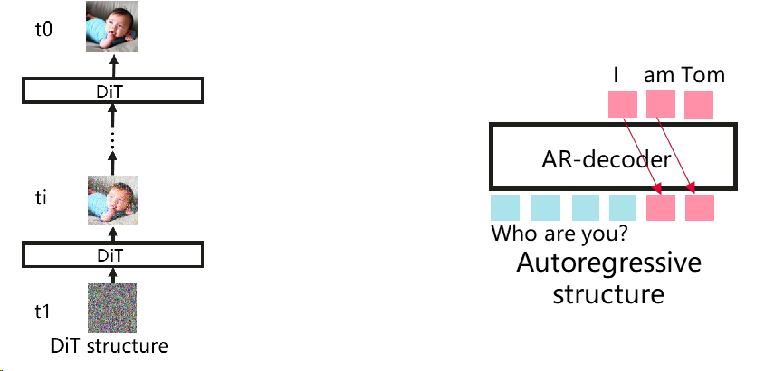
- Diffusion Transformer(DiT):在采样时间戳的控制下,利用随机潜在噪声初始化,变换器模型迭代地预测多个步骤的潜在输出。最后,由变分自动编码器 (VAE) 的解码器对其进行解码。vLLM不支持。^1
- 自回归(Autoregressive):文本的主导生成范式,vLLM支持。它生成令牌的条件在以前的令牌一个接一个。vLLM提供的高效KV缓存管理可以有效地加速推理。
| 特性 | 自回归(AR) | DiT(Diffusion-based Iterative Transformer) |
|---|---|---|
| 场景 | 文本生成 | 多模态生成 |
| 生成方式 | Token-by-token,从左到右 | 连续向量,迭代细化 |
| 主要优势 | 局部一致性好 | 全局一致性、多样性和可控制性强 |
| 效率 | 更高效的 KV 缓存 | 需要反复生成,速度较慢 |
| 误差累积 | 容易累积 | 可在后续迭代中修复 |
| 主要挑战 | 全局规划能力有限,长上下文生成困难 | 全局计算成本巨大 |
| 序列长度 | 可变长度 | 固定长度 |
| 注意力掩码 | 下三角形(因果掩码) | 全双向矩阵 |
| 并行策略 | TP, DP, PP 等 | DP, CP 等 |
| vLLM 支持 | 支持 | 不支持 |
全模态模型的AR和DiT构成
广义的理解:AR可以给模型引入理解能力,DiT能给模型带来生成能力。所以两者不同的占比,带来了不同的模型设计:^1
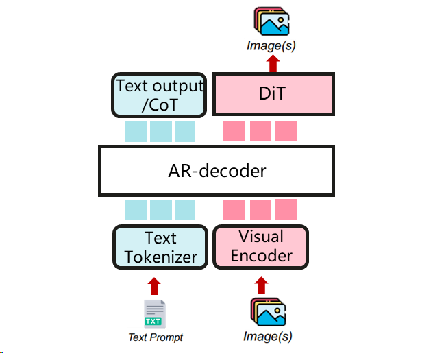
DiT作为主要结构,AR作为文本编码器
用于图像生成和编辑的流行模型。主要的视觉生成模型与结构相似,如Flux。(例如: qwen-image)
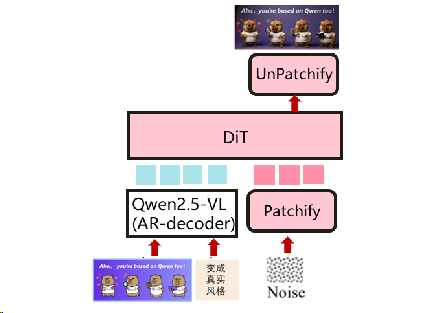
AR作为主要结构,DiT作为多模式生成器
一个统一的多模态理解和生成模型。视觉生成可以利用CoT文本生成输出。主要的统一多模态模型与结构相似。 (例如BAGEL)
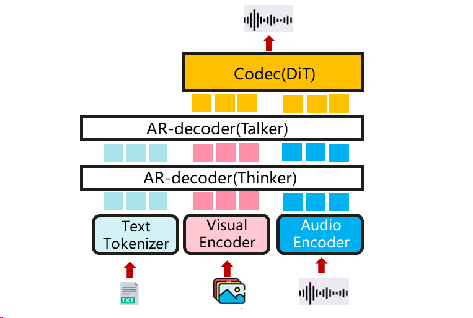
扩展,multi-AR + DiT
多模态输入输出的新模型。它设计了thinker-talker-codec结构,该结构是双AR+DiT格式。(例如qwen-omni)