VeOmni
技术优势
- 显存计算双优化
- 通过 算子级 ROI 分析,动态选择性价比最高的算子进行重计算(如 gate1_mul 省 40MB 显存仅需 180μs),将额外计算开销从 60% 降至 30%。
- 混合并行组合拳
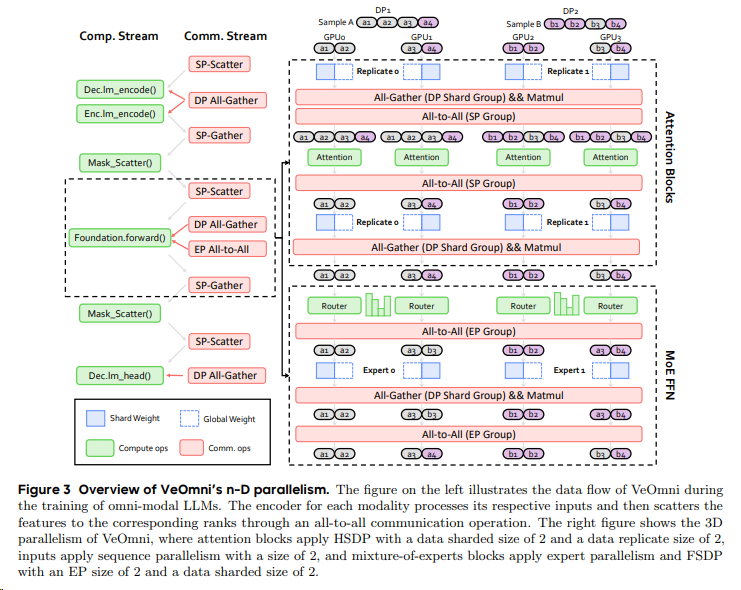
- 支持 FSDP(参数切片)、Ulysses(长序列拆分)、Expert Parallel(MoE 专家网络) 的笛卡尔组合,显存峰值降低 55%(如 720P 视频训练)。
 [^2]
[^2]
- 支持 FSDP(参数切片)、Ulysses(长序列拆分)、Expert Parallel(MoE 专家网络) 的笛卡尔组合,显存峰值降低 55%(如 720P 视频训练)。
- 算子级性能深挖
- 融合注意力-FFN-残差链路为单核 Kernel,访存次数下降百倍,减少显存碎片。
- 跨模型通吃
- 一套框架支持 LLM 长上下文训练、VLM 双塔/单塔架构、DiT 视频生成,无需修改代码即可扩展至千卡集群。
- 蒸馏加速
- 集成 轨迹蒸馏、分布匹配蒸馏(DMD) 等前沿方法,将推理步数降至 4–8 步,降低推理成本 50% 以上。
性能提升
以开源模型 Wan2.1 为例:
- 计算型大卡:I2V 720P 训练速度提升 48%,T2V 720P 提升 44.4%;
- 访存型大卡:I2V 720P 提升 59.5%,T2V 720P 提升 57.4%;
- 小模型(1.3B):T2V 480P 训练速度提升 51%。
参考文献
[^1]: 字节跳动 VeOmni 框架开源:统一多模态训练效率飞跃!
[^2]: VeOmni: Scaling Any Modality Model Training with Model-Centric Distributed Recipe Zoo