DiffusionNFT
动机
- 似然估计困难:自回归模型的似然可精确计算,而扩散模型的似然只能以高开销近似,导致 RL 优化过程存在系统性偏差。^1
- 解释:指扩散模型的打分相对于LLM困难
- 前向–反向不一致:现有方法仅在反向去噪过程中施加优化,没有对扩散模型原生的前向加噪过程的一致性进行约束,模型在训练后可能退化为与前向不一致的级联高斯。
- 采样器受限:需要依赖特定的一阶 SDE 采样器,无法充分发挥 ODE 或高阶求解器在效率与质量上的优势。
- CFG 依赖与复杂性:现有 RL 方案在集成无分类器引导 (CFG) 时需要在训练中对双模型进行优化,效率低下。
思路
为什么不直接在“加噪”的前向过程中融入奖励信号呢?与其在去噪的每一步艰难地“纠正”方向,不如从一开始就引导整个扩散过程,使其“避开”通往低奖励样本的路径。DiffusionNFT 将强化学习的目标巧妙地转化为一个对前向过程的微调任务,从而完全绕开了棘手的似然估计问题。
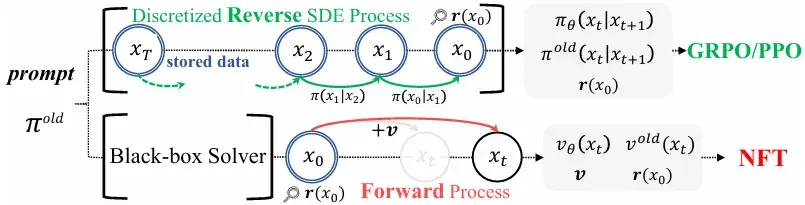
创新点
1 负例感知微调 (Negative-aware FineTuning, NFT)
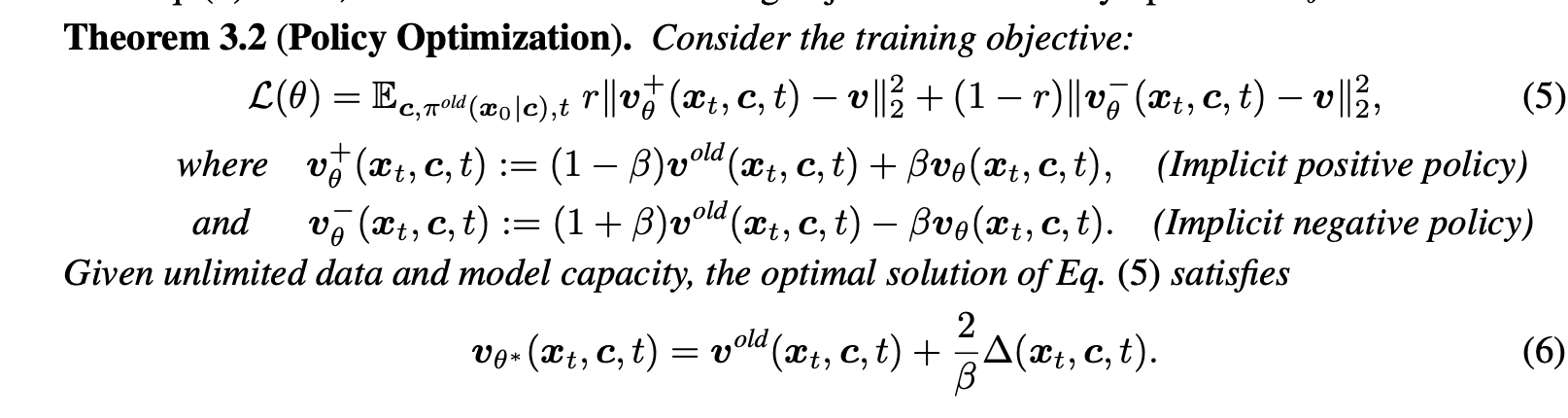
核心公式解释看^1,
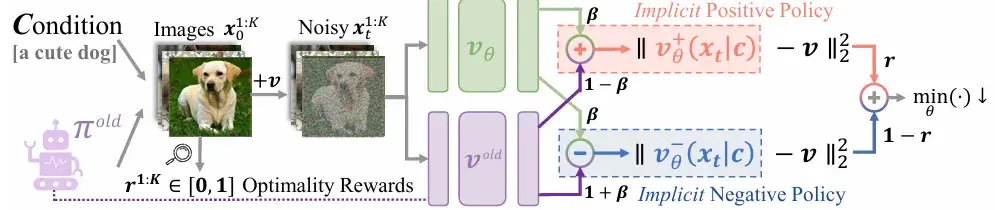
从 DiffusionNFT 到 OmniNFT
DiffusionNFT 的核心转向是:不要在反向去噪轨迹上强行做 policy gradient,而是在前向 diffusion / flow matching 目标里引入 reward 方向。这解决的是“扩散模型如何做在线 RL”的基础问题:避免似然估计、减少轨迹保存、放开采样器约束。[^2]
OmniNFT 则把问题推进到另一个层面:当生成目标从图像或视频扩展到 joint audio-video generation 时,reward 不再只是一个标量质量分数,而是至少包含视频质量、音频质量、音画同步和跨模态语义一致性。此时如果仍然把所有 reward 合成一个 global advantage,再把同一个 advantage 广播给所有分支,就会出现信用分配错误。[^3]
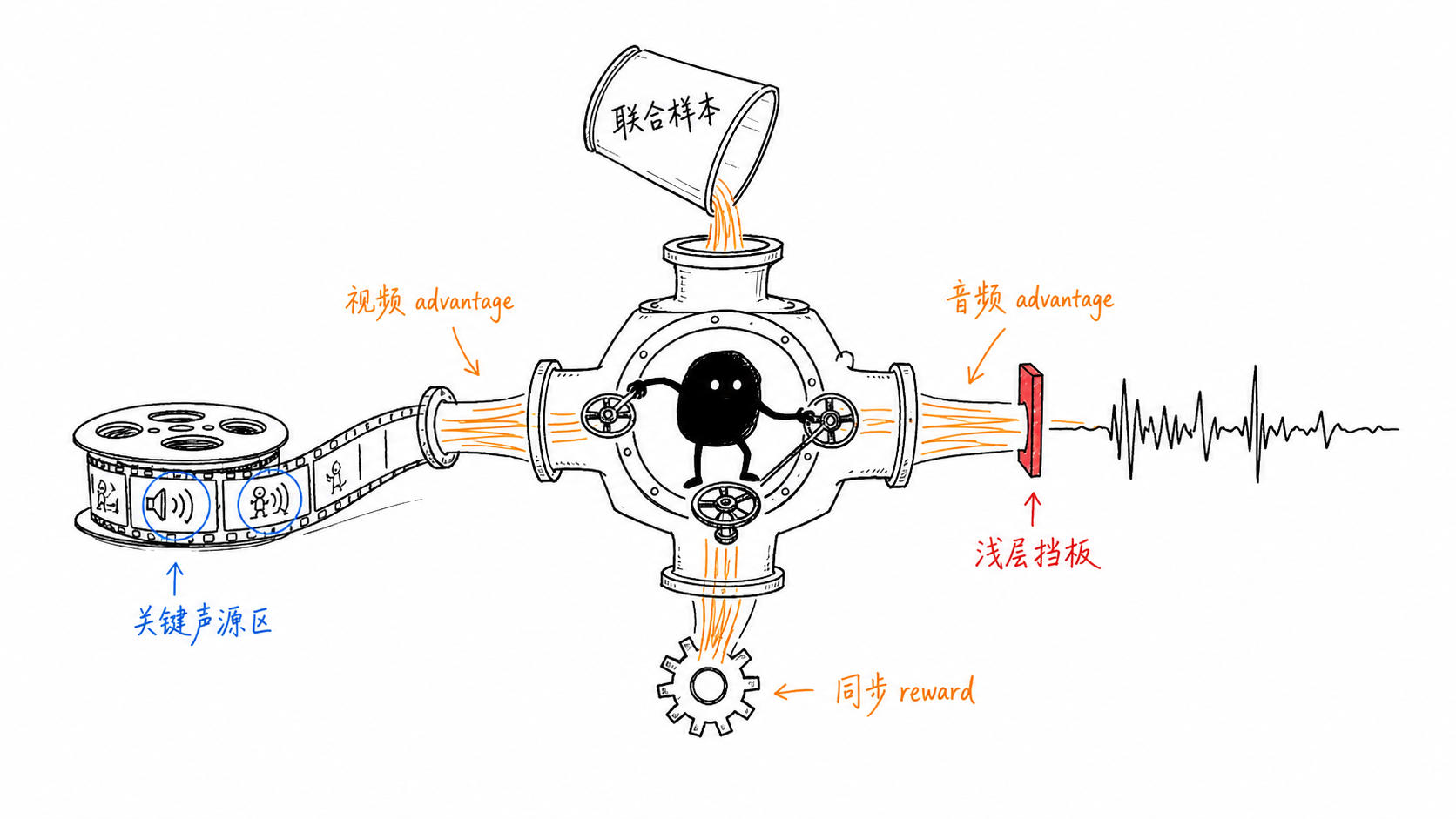
OmniNFT 的三类失配
OmniNFT 论文把 vanilla RLVR / GRPO 直接用于音视频联合生成时的失败原因归纳为三类优化失配:[^3]
- Multi-objective advantage inconsistency
同一个生成样本可能视频 reward 高、音频 reward 低,或音频自然但画面质量差。论文图 2 指出,视频和音频 advantage 的相关性很弱,约一半样本在两个模态上收到相反 reward。此时用一个总分 advantage 更新所有分支,会把错误方向传给本不该惩罚的模态。 - Multi-modal gradient imbalance
音频浅层更偏 intra-modal generation,负责音频自身质量;中后层更偏 audio-video interaction,负责同步和跨模态对齐。如果视频分支梯度泄漏到音频浅层,音频质量会被视频目标污染。 - Uniform credit assignment
音画同步通常只发生在关键发声区域,例如手拍桌、嘴部发声、乐器动作。均匀更新整段视频 latent 会把优化预算浪费在无关区域。
三层信用分配
OmniNFT 的技术主线不是“把奖励加权求和”,而是做更细的 credit routing:
- Modality-wise advantage routing:为 video reward、audio reward、cross-modal synchronization reward 分别计算 advantage;单模态 advantage 只监督对应分支,同步 advantage 才同时影响音频和视频分支。
- Layer-wise gradient surgery:在音频分支浅层对来自视频流的部分梯度做 stop-gradient,避免视频目标污染音频自身生成;在更深的 cross-modal interaction 层保留有效梯度。
- Region-wise loss reweighting:利用 V2A cross-attention map 作为关键发声区域的内部代理,把视频侧 RL loss 权重集中到影响音画同步的区域,而不是均匀更新所有位置。
工程实现线索
OmniNFT 已公开代码、项目页和 LoRA 权重。仓库说明显示,它以 LTX-2 / LTX-2.3 为基础模型,训练时使用 HPSv3、VideoAlign、AudioBox、CLAP、ImageBind、Synchformer 等 reward model;其中 HPSv3 和 VideoAlign 以 remote HTTP server 形式运行,再通过 bash_train_omninft_ltx_fsdp.sh branch_aware_layer_surgery_avweight 启动训练。[^4]
这条工程线有两个值得后续复现实验时优先检查的点:
- Reward server 的延迟和稳定性:音视频 RL 的瓶颈不只在模型前向,还在多个 reward model 的吞吐、队列和失败重试。
- LoRA 合并后的推理差异:Hugging Face 发布的是 LTX-2 / LTX-2.3 的 RL-LoRA,需要 merge 到 base checkpoint 后推理;不同推理端对 LoRA alpha、rank、dtype 的处理可能影响观感。[^5]
和 UniGRPO / DanceGRPO 的关系
如果说 UniGRPO 关心的是 reasoning + image 的 统一 MDP,DanceGRPO / FlowGRPO 关心的是生成轨迹上的 policy gradient,那么 OmniNFT 更像是给 Omni 生成任务补上了一个前提:统一 rollout 不等于共享所有 advantage。
更稳的 Omni RL 结构应当是:
- 统一 rollout:让视频、音频、文本条件和同步关系在同一条生成轨迹中被评估。
- 分模态 reward:分别评估视频质量、音频质量、音画同步和语义对齐。
- 分层 advantage routing:单模态 reward 只更新相应分支,同步 reward 更新交互层和关键区域。
- 前向过程优化:尽量复用 DiffusionNFT 的 forward-process 思想,减少对完整反向采样轨迹和 log-prob ratio 的依赖。
代码跳读
入口scripts/train_nft_sd3.py
1 | for epoch in range(first_epoch, config.num_epochs): |
生成sampling
1 | def run_sampling( |
这部分逻辑和danceGRPO是类似的,但是训练没有对应逻辑,并且all_latents只用于计算x0
1 | x0 = train_sample_batch["latents_clean"] |
参考文献
[^2]: DiffusionNFT: Online Diffusion Reinforcement with Forward Process
[^3]: OmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
[^4]: zghhui/OmniNFT
[^5]: zghhui/OmniNFT RL-LoRA for LTX Video