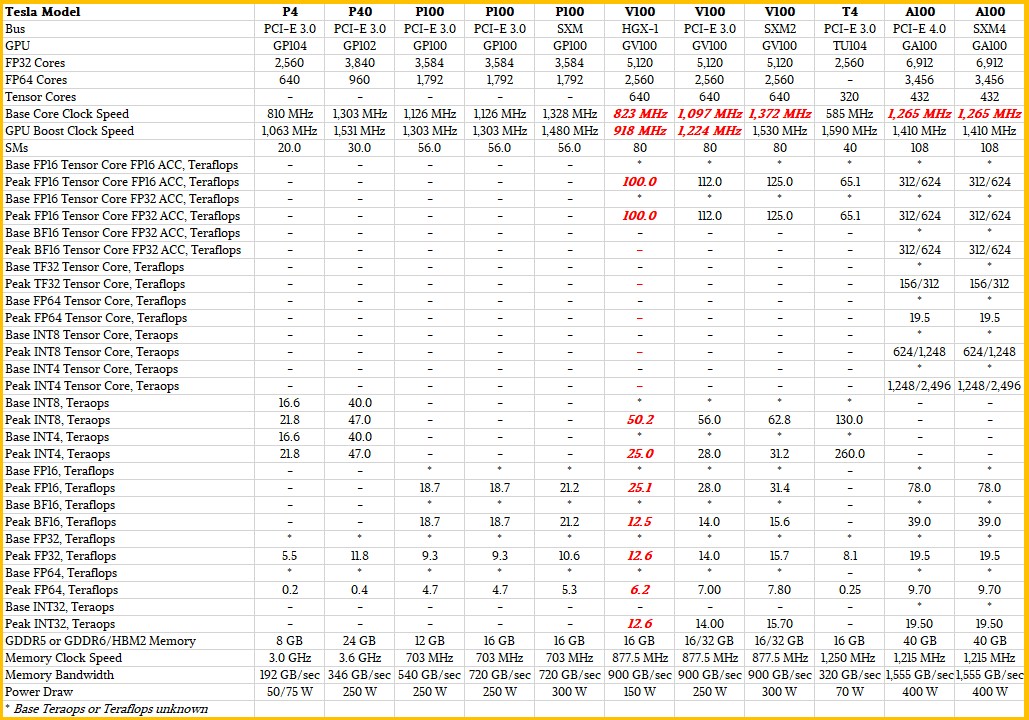
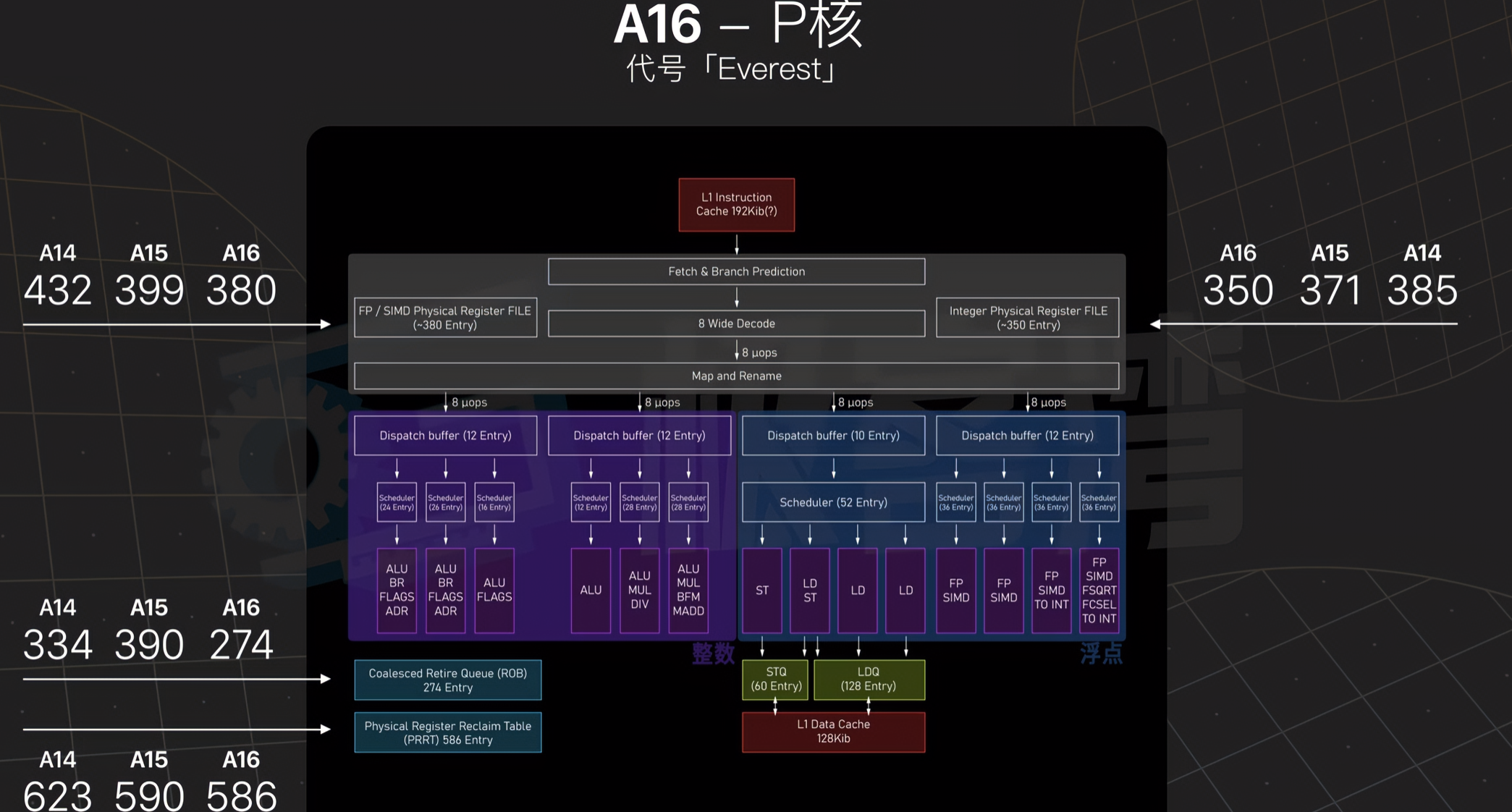
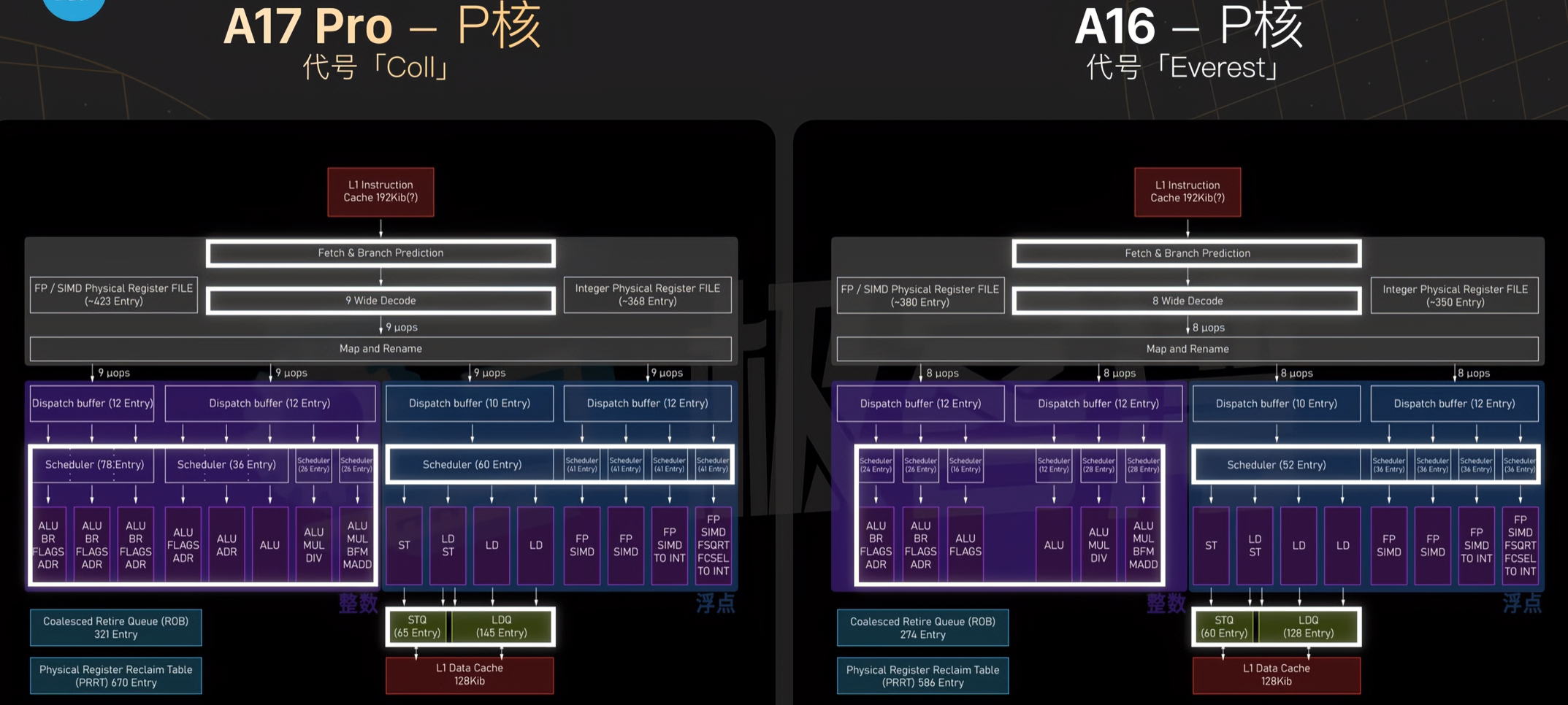
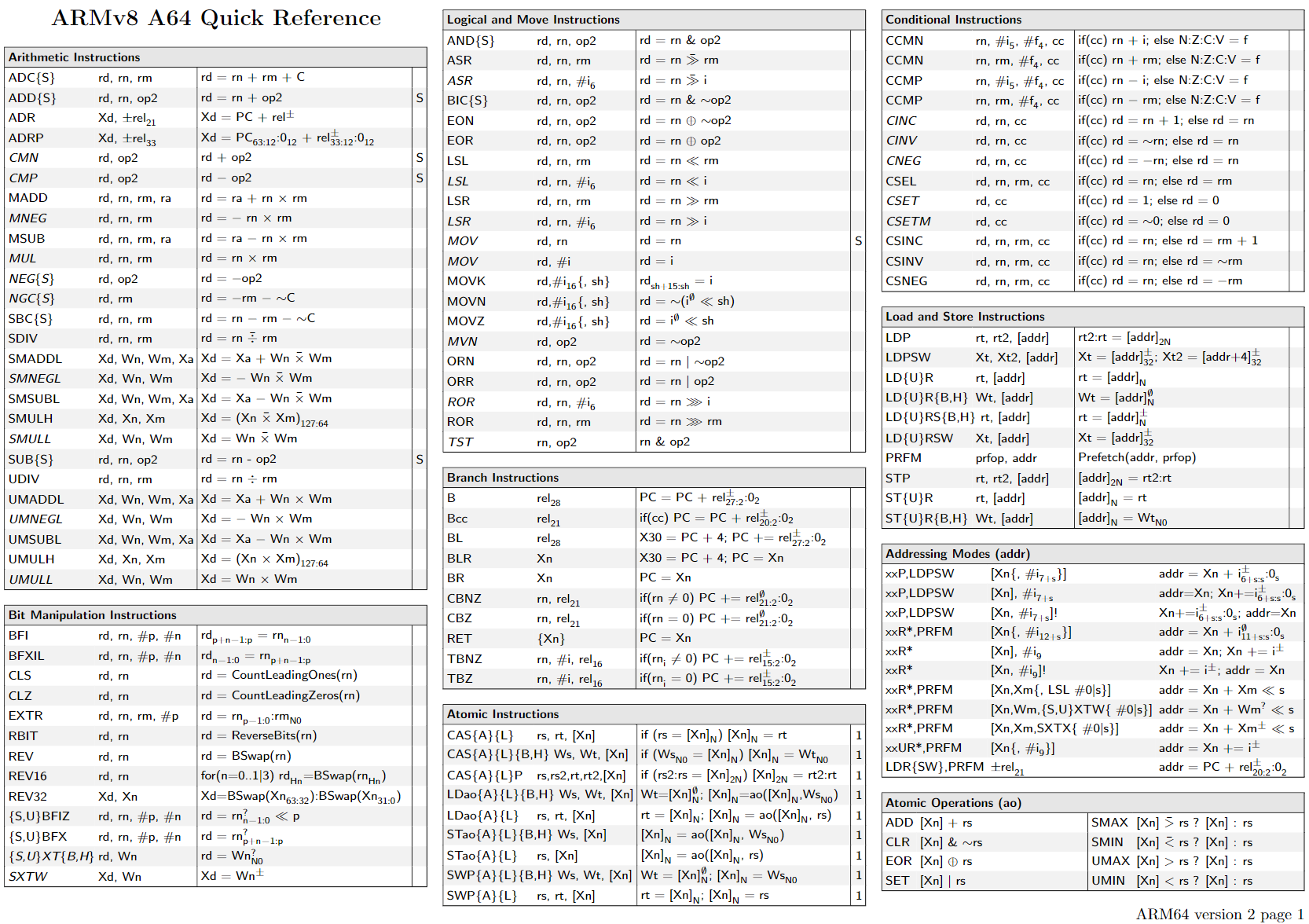
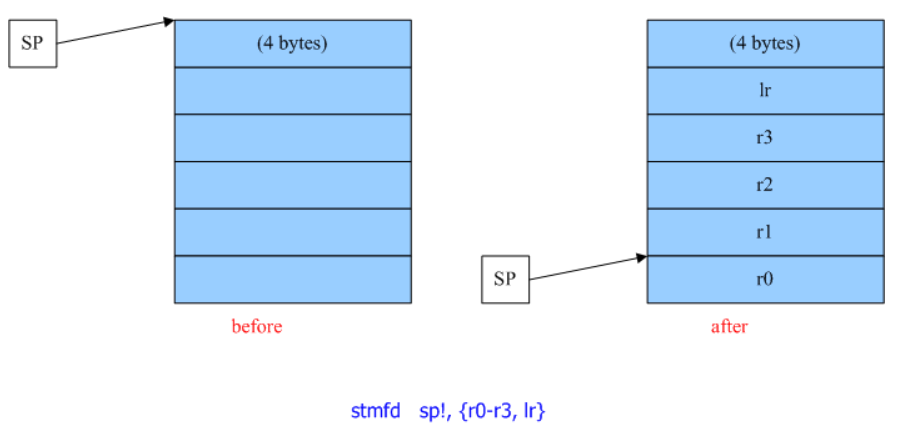
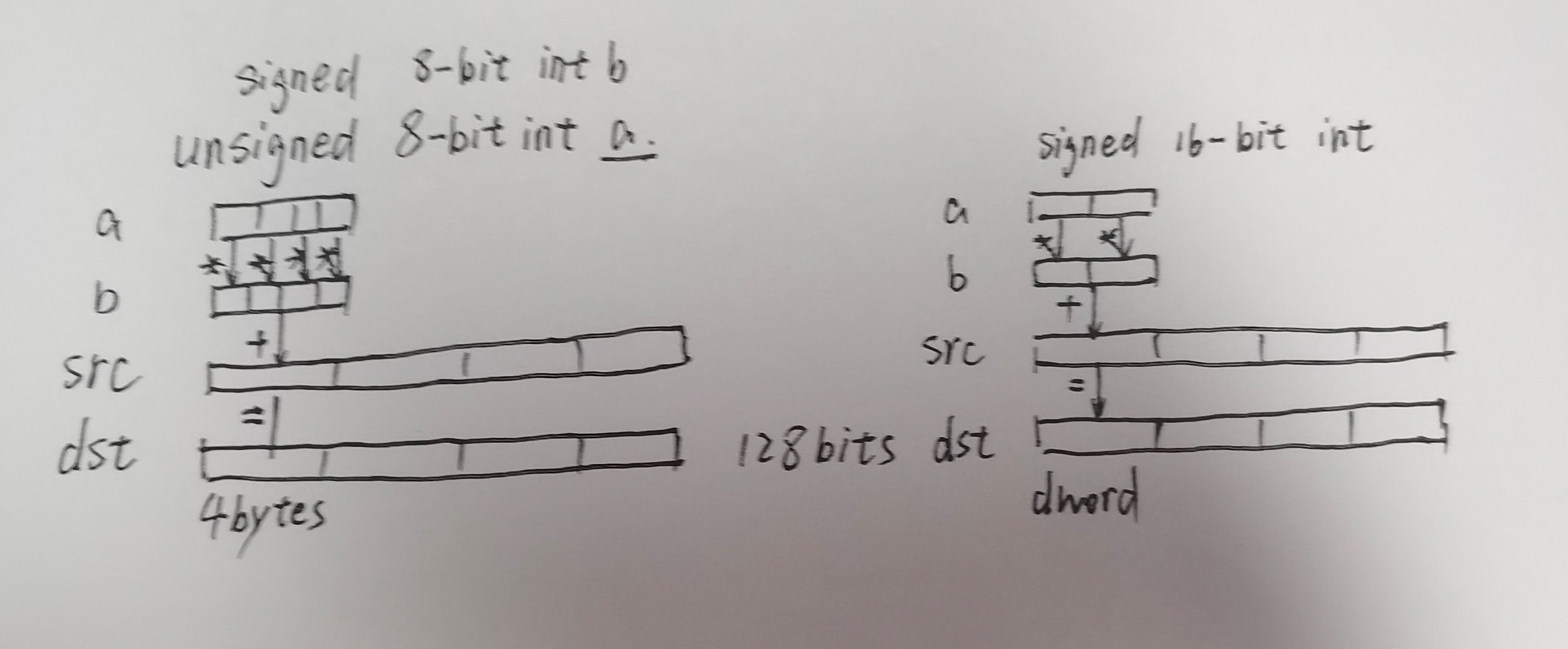
Integer multiply-add with extract: multiply R3 with R5, extract upper half, sum that upper half with constant in bank 0, offset 0x24, store in R7 with carry-in.
line3
1
/*0040*/ LD.E R2, [R6]; //load
LD.E is a load from global memory using 64-bit address in R6,R7(表面上是R6,其实是R6 与 R7 组成的地址对)
summary
1 2 3
R6 = R3*R5 + c[0x0][0x20], saving carry to CC R7 = (R3*R5 + c[0x0][0x24])>>32 + CC R2 = *(R7<<32 + R6)
寄存器是32位的原因是 SMEM的bank是4字节的。c数组将32位的基地址分开存了。
first two commands multiply two 32-bit values (R3 and R5) and add 64-bit value c[0x0][0x24]<<32+c[0x0][0x20],
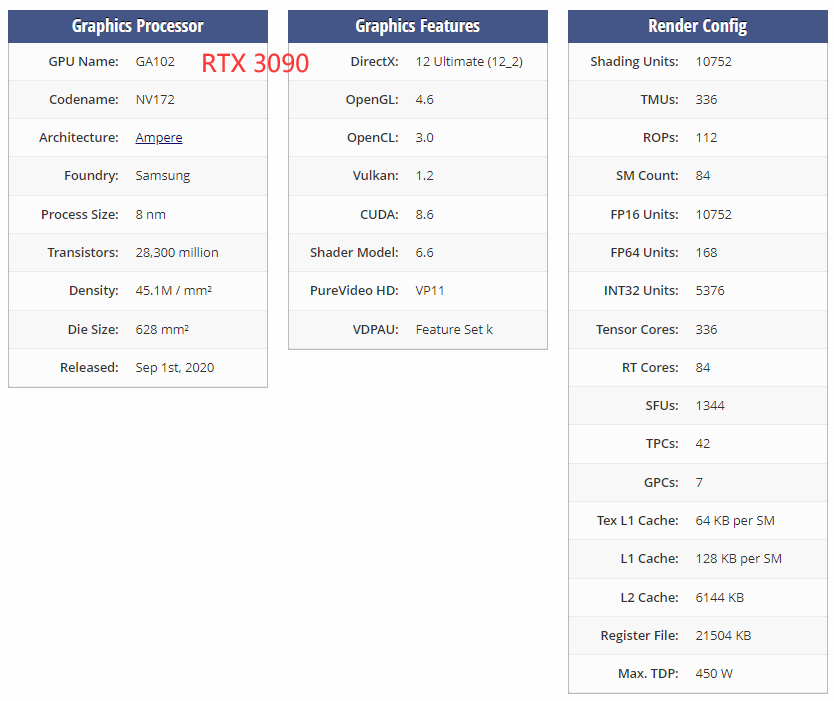
CPU(s):64 = the number of logical cores = “Thread(s) per core” × “Core(s) per socket” × “Socket(s)” = 1 * 32 * 2
One socket is one physical CPU package (which occupies one socket on the motherboard);
each socket hosts a number of physical cores, and each core can run one or more threads.
In this case, you have two sockets, each containing a 32-core AMD EPYC 7452 CPU, and since that not supports hyper-threading, each core just run a thread.
syscall: SYSCALL (Fast System Call) and SYSRET (Return From Fast System Call) nx:执行禁用 # NX 位(不执行)是 CPU 中使用的一项技术,用于分隔内存区域,以供处理器指令(代码)存储或数据存储使用 mmxext: AMD MMX extensions fxsr_opt: FXSAVE/FXRSTOR optimizations pdpe1gb: One GB pages (allows hugepagesz=1G) rdtscp: Read Time-Stamp Counter and Processor ID lm: Long Mode (x86-64: amd64, also known as Intel 64, i.e. 64-bit capable)
constant_tsc:TSC(Time Stamp Counter) 以恒定速率滴答 art: Always-Running Timer rep_good:rep 微码运行良好 nopl: The NOPL (0F 1F) instructions # NOPL is long-sized bytes "do nothing" operation nonstop_tsc: TSC does not stop in C states extd_apicid: has extended APICID (8 bits) (Advanced Programmable Interrupt Controller) aperfmperf: APERFMPERF # On x86 hardware, APERF and MPERF are MSR registers that can provide feedback on current CPU frequency. eagerfpu: Non lazy FPU restore
Intel-defined CPU features, CPUID level 0x00000001 (ecx)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
pni: SSE-3 (“2004年,新内核Prescott New Instructions”) pclmulqdq: 执行四字指令的无进位乘法 - GCM 的加速器) monitor: Monitor/Mwait support (Intel SSE3 supplements) ssse3:补充 SSE-3 fma:融合乘加 cx16: CMPXCHG16B # double-width compare-and-swap (DWCAS) implemented by instructions such as x86 CMPXCHG16B sse4_1:SSE-4.1 sse4_2:SSE-4.2 x2apic: x2APIC movbe:交换字节指令后移动数据 popcnt:返回设置为1指令的位数的计数(汉明权,即位计数) aes/aes-ni:高级加密标准(新指令) xsave:保存处理器扩展状态:还提供 XGETBY、XRSTOR、XSETBY avx:高级矢量扩展 f16c:16 位 fp 转换 (CVT16) rdrand:从硬件随机数生成器指令中读取随机数
More extended AMD flags: CPUID level 0x80000001, ecx
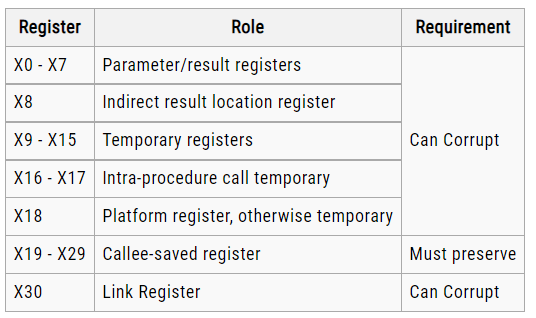
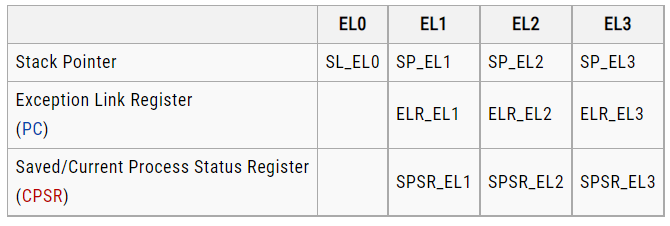
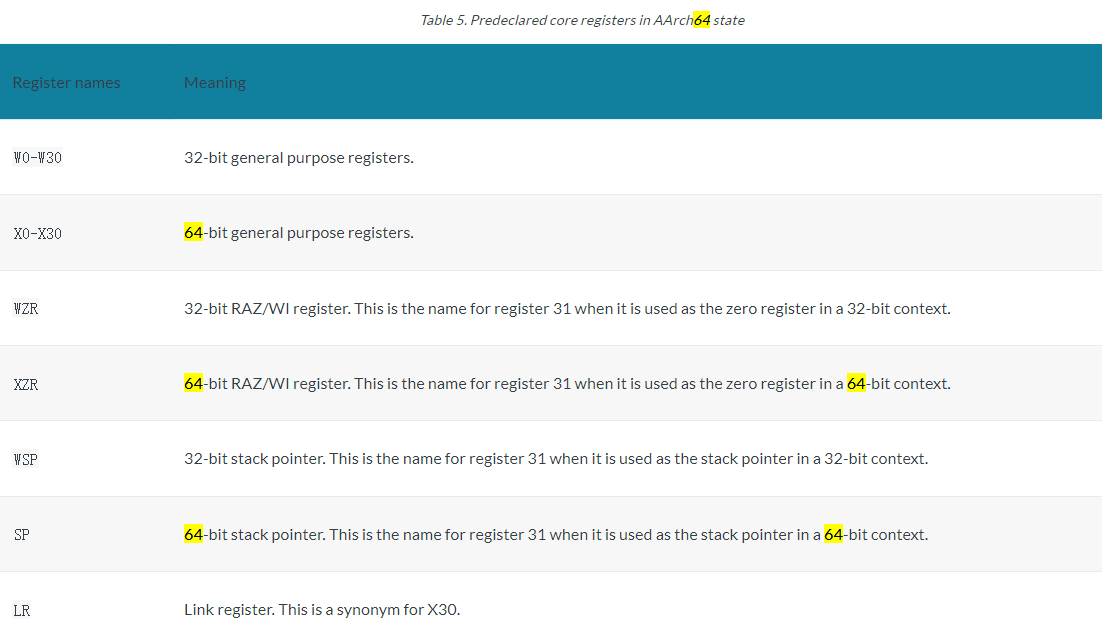
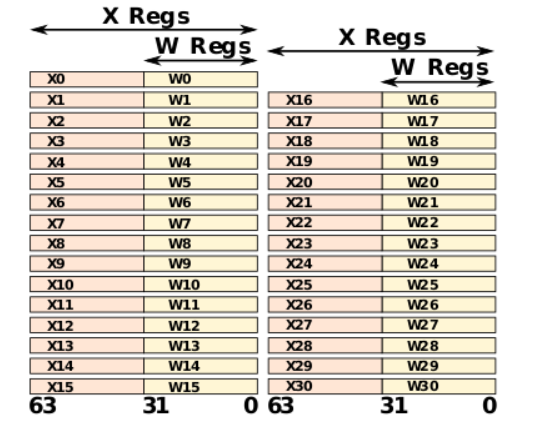
The x86 architecture has 8 General-Purpose Registers (GPR), 6 Segment Registers, 1 Flags Register and an Instruction Pointer. 64-bit x86 has additional registers.
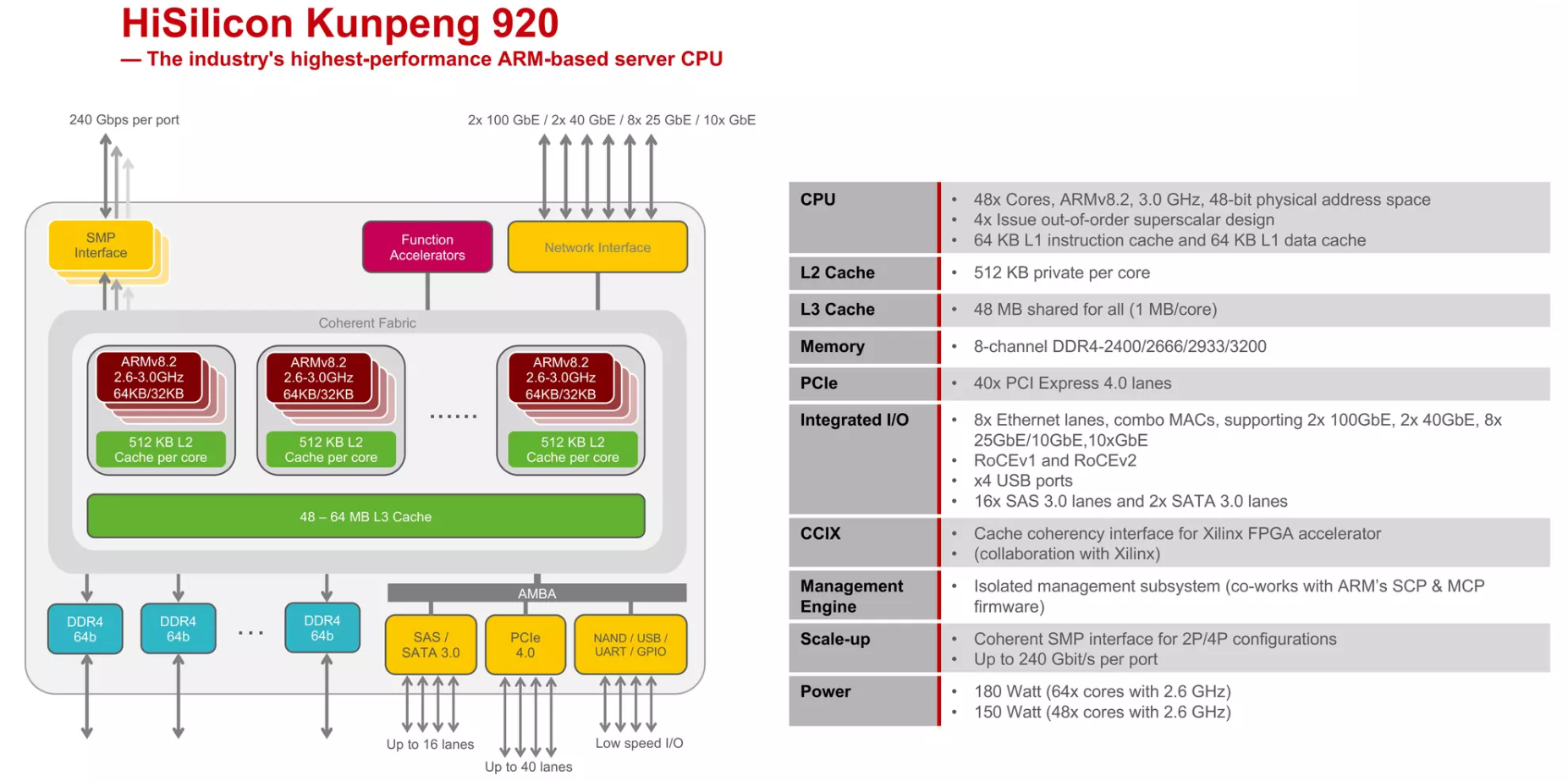
AMBA(Advanced Microcontroller Bus Architecture)是ARM公司定义的一个总线架构,用来连接不同的功能模块(如CPU核心、内存控制器、I/O端口等)。AMBA是一种开放标准,用于连接和管理集成在SOC(System on Chip)上的各种组件。它是为了高带宽和低延迟的内部通信而设计的,确保不同组件之间的高效数据传输。
ARM的SCP和MCP固件(System Control Processor & Management Control Processor firmware)则是指ARM提供的用于系统控制处理器和管理控制处理器的固件。这些固件通常负责处理系统管理任务,例如电源管理、系统启动和监控、安全性管理等。SCP和MCP是ARM架构中用于系统级管理和控制的专门处理器或子系统。
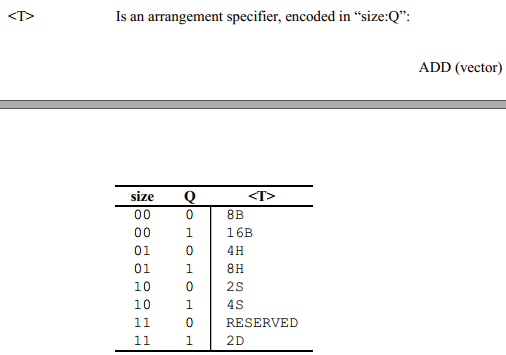
# 128位and and %q3 %q7 -> %q3 and v3.16b, v3.16b, v7.16b
是同一个意思,但是不支持and v3.8h, v3.8h, v7.8h
1 2 3
DUP //Duplicate general-purpose register to vector.or Duplicate vector element to vector or scalar. addp //Add Pair of elements (scalar). This instruction adds two vector elements in the source SIMD&FP register and writes //the scalar result into the destination SIMD&FP register.
calculate
1 2 3 4 5
add addp //Add Pair of elements (scalar). This instruction adds two vector elements in the source SIMD&FP register and writes the scalar result into the destination SIMD&FP register. adds // Add , setting flags. eor // Bitwise Exclusive OR orr // Move (register) copies the value in a source register to the destination register. Alias of ORR.
Address
1
ADRP // Form PC-relative address to 4KB page.
Branch
1 2 3 4 5 6 7
b.cond // branch condition eg. b.ne bl //Branch with Link branches to a PC-relative offset, setting the register X30 to PC+4 //带链接的跳转。 首先将当前指令的下一条指令地址保存在LR寄存器,然后跳转的lable。通常用于调用子程序,可通过在子程序的尾部添加mov pc, lr 返回。 blr //Branch with Link to Register calls a subroutine at an address in a register, setting register X30 to PC+4. cbnz //Compare and Branch on Nonzero compares the value in a register with zero, and conditionally branches to a label at a PC-relative offset if the comparison is not equal. It provides a hint that this is not a subroutine call or return. This instruction does not affect the condition flags. tbnz // test and branch not zero ret //Return from subroutine, branches unconditionally to an address in a register, with a hint that this is a subroutine return.
Load/Store
1 2 3 4 5 6 7 8 9
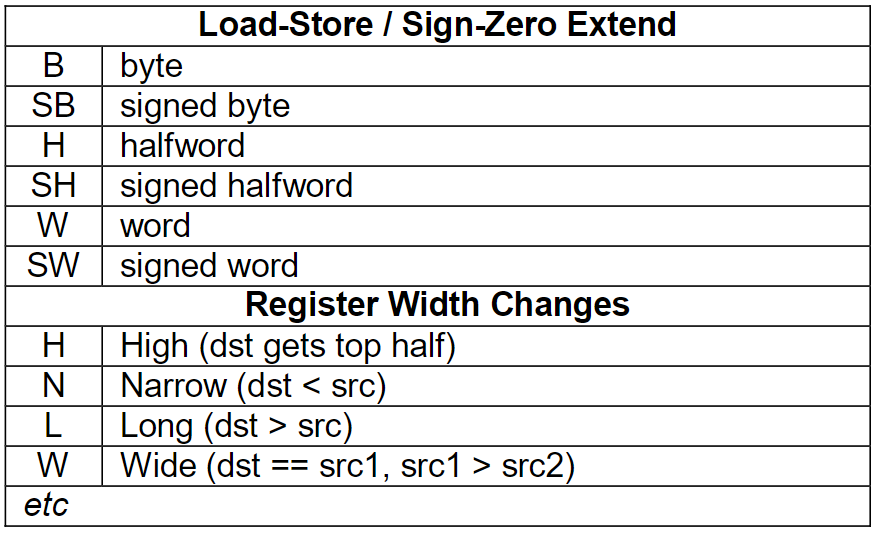
ldrb // b是byte的意思 ldar // LDAR Load-Acquire(申请锁) Register STLR //Store-Release(释放锁) Register ldp // load pair(two) register stp // store pair(two) register ldr(b/h/sb/sh/sw) // load register , sb/sh/sw is signed byte/half/word str // store register ldur // load register (unscaled) unscaled means that in the machine-code, the offset will not be encoded with a scaled offset like ldr uses. or offset is minus. prfm // prefetch memory
Control/conditional
1 2 3 4 5 6
ccmp // comdition compare CMEQ // Compare bitwise Equal (vector). This instruction compares each vector element from the frst source SIMD&FP register with the corresponding vector element from the second source SIMD&FP register CSEL // If the condition is true, Conditional Select writes the value of the frst source register to the destination register. If the condition is false, it writes the value of the second source register to the destination register. CSINC //Conditional Select Increment returns CSINV //Conditional Select Invert returns CSNEG //Conditional Select Negation returns
Logic&Move
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
ASRV //Arithmetic Shift Right Variable lsl //logic shift left orr //bitwise(逐位) or eor //Bitwise Exclusive OR TST/ANDS //Test bits (immediate), setting the condition flags and discarding the result. Alias of ANDS. MOVZ //Move wide with zero moves an optionally-shifted 16-bit immediate value to a register UBFM // Unigned Bitfield Move. This instruction is used by the aliases LSL (immediate), LSR (immediate), UBFIZ, UBFX, UXTB, and UXTH BFM //Bitfield Move BIC (shifted register) //Bitwise Bit Clear CLZ // Count Leading Zeros counts the number of binary zero bits before the frst binary one bit in the value of the source register, and writes the result to the destination register. REV, REV16, REVSH, and RBIT // below REV //Reverse byte order in a word. REV16 //Reverse byte order in each halfword independently. REVSH //Reverse byte order in the bottom halfword, and sign extend to 32 bits. RBIT //Reverse the bit order in a 32-bit word.
Modifier
1
uxtb // zero extend byte 无符号(Unsigned)扩展一个字节(Byte)到 32位
system
1 2
dmb //data memory barrier SVC //The SVC instruction causes an exception. This means that the processor mode changes to Supervisor,
_mm_sin_ps intrinsic is a packed 128-bit vector of four32-bit precision floating point numbers.The intrinsic computes the sine of each of these four numbers and returns the four results in a packed 128-bit vector.
ISA
AVX2 & AVX
AVX2在AVX的基础上完善了256位寄存器的一些实现
FMA
float-point multiply add/sub
include 128/256 bits regs
AVX_VNNI
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. It provides the same set of operations, but is limited to 256-bit vectors and does not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. This extension allows to support VNNI operations even when full AVX-512 support is not implemented by the processor.
1 2 3
dpbusd //_mm_dpbusd_avx_epi32 dpwssd // b 与 w 是 byte 和dword。 us和ss是ab两数是不是signed dpwssds // 最后的s是 signed saturation饱和计算的意思,计算不允许越界。
AVX-512
有时间再看吧
KNC
current generation of Intel Xeon Phi co-processors (codename “Knight’s Corner“, abbreviated KNC) supports 512-bit SIMD instruction set called “Intel® Initial Many Core Instructions” (abbreviated Intel® IMCI).
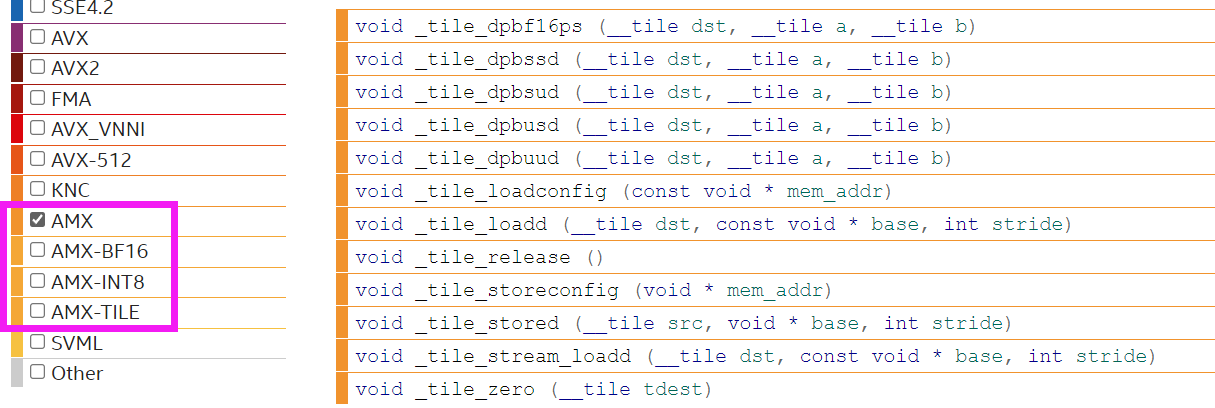
Intel® Advanced Matrix Extensions (Intel® AMX) is a new 64-bit programming paradigm consisting of two components:
A set of 2-dimensional registers (tiles) representing sub-arrays from a larger 2-dimensional memory image
An accelerator that is able to operate on tiles; the first implementation of this accelerator is called TMUL (tile matrix multiply unit).
这个不适用于特殊矩阵和稀疏矩阵,这类一般先转换化简再SIMD
SVML
Short Vector Math Library Operations (SVML)
The Intel® oneAPI DPC++/C++ Compiler provides short vector math library (SVML) intrinsics to compute vector math functions. These intrinsics are available for IA-32 and Intel® 64 architectures running on supported operating systems. The prototypes for the SVML intrinsics are available in the immintrin.h file.
Using SVML intrinsics is faster than repeatedly calling the scalar math functions. However, the intrinsics differ from the scalar functions in accuracy.
_mm256_hadd_epi16 // Horizontally add eg.dst[15:0] := a[31:16] + a[15:0] _mm256_mulhi_epi16 // Multiply the packed signed 16-bit integers in a and b, producing intermediate 32-bit integers, and store the high 16 bits of the intermediate integers in dst. _mm256_sign_epi16 // 根据b的值,将-a/0/a存入dst // 乘加,乘减,的计算组合也有