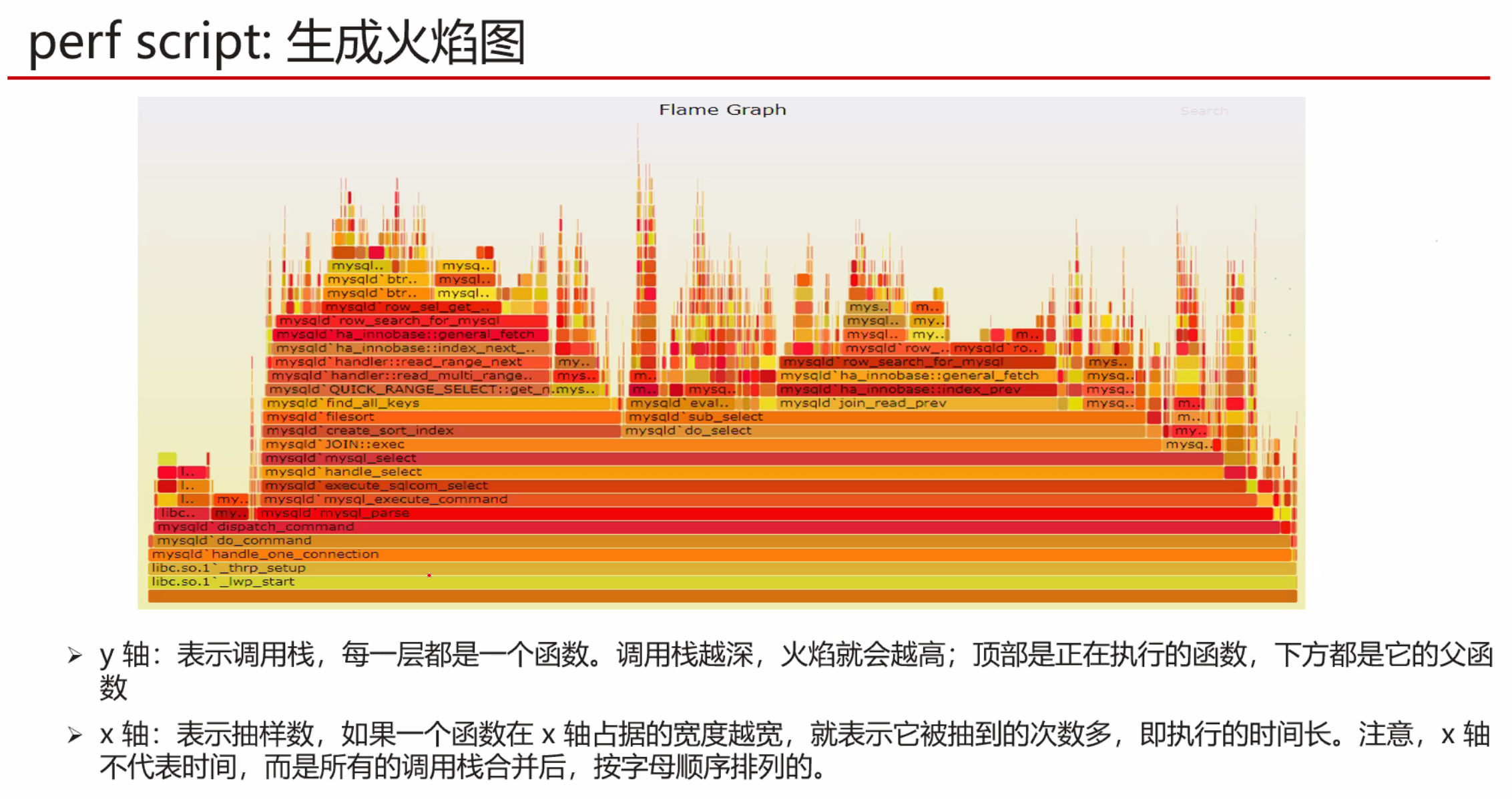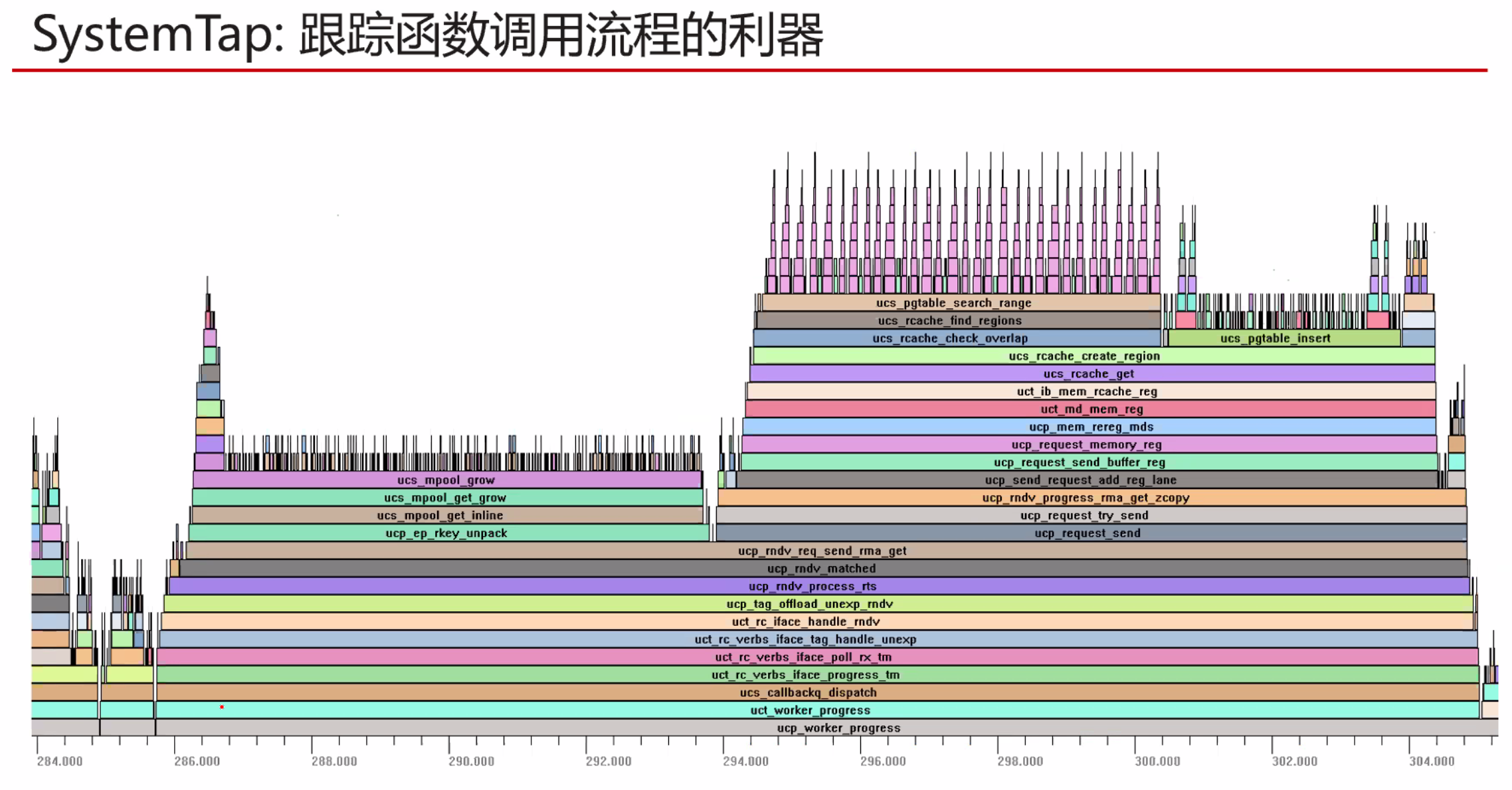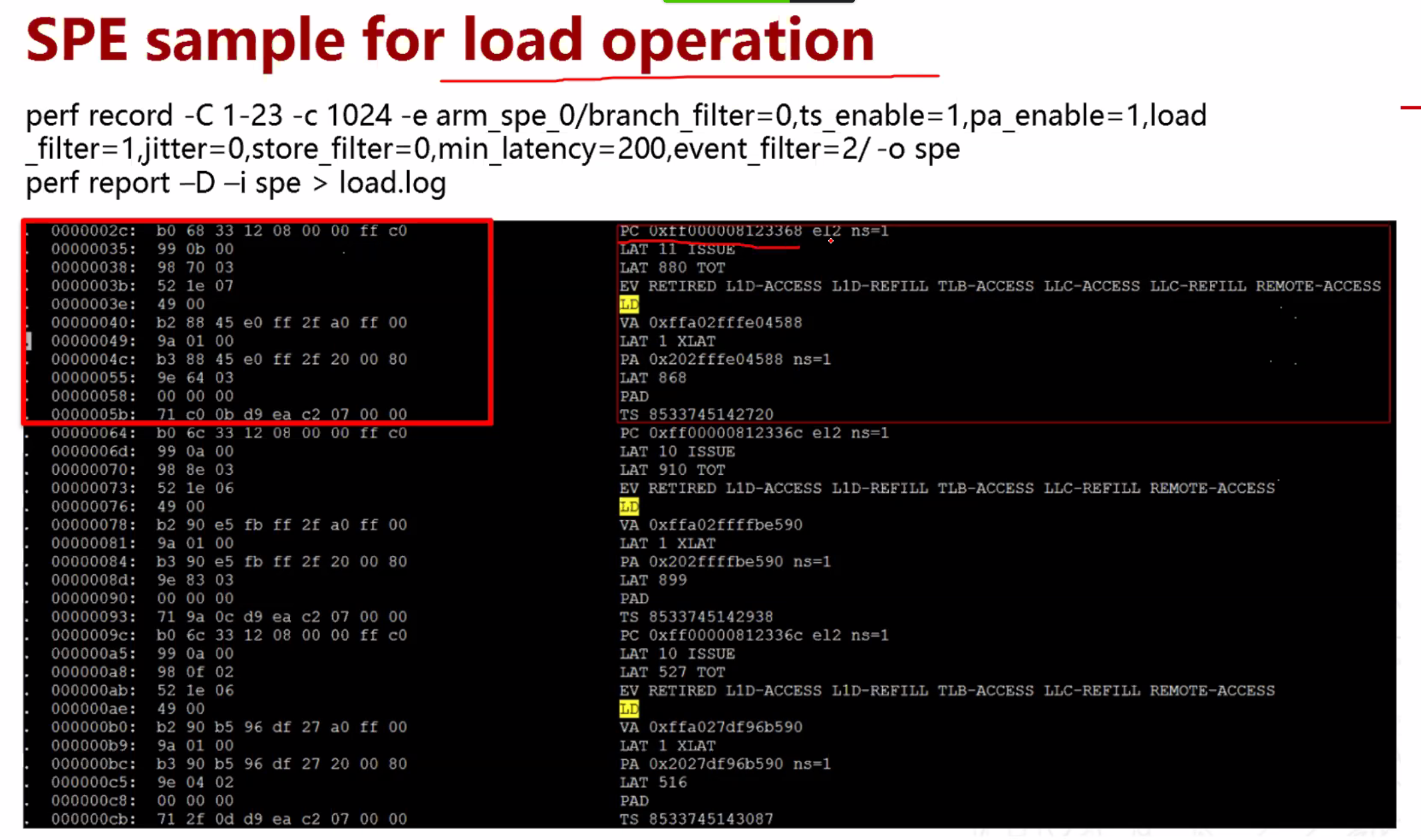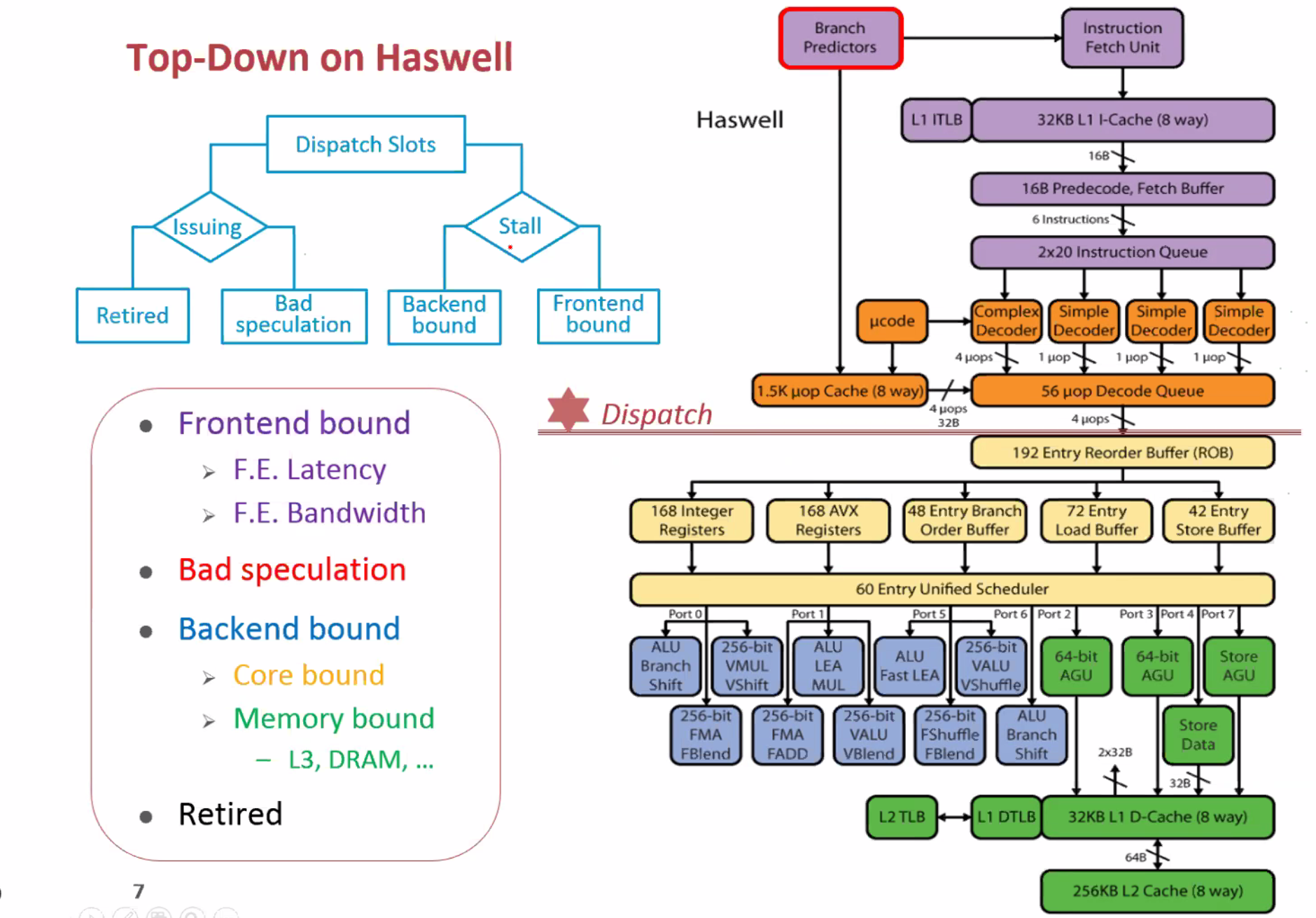
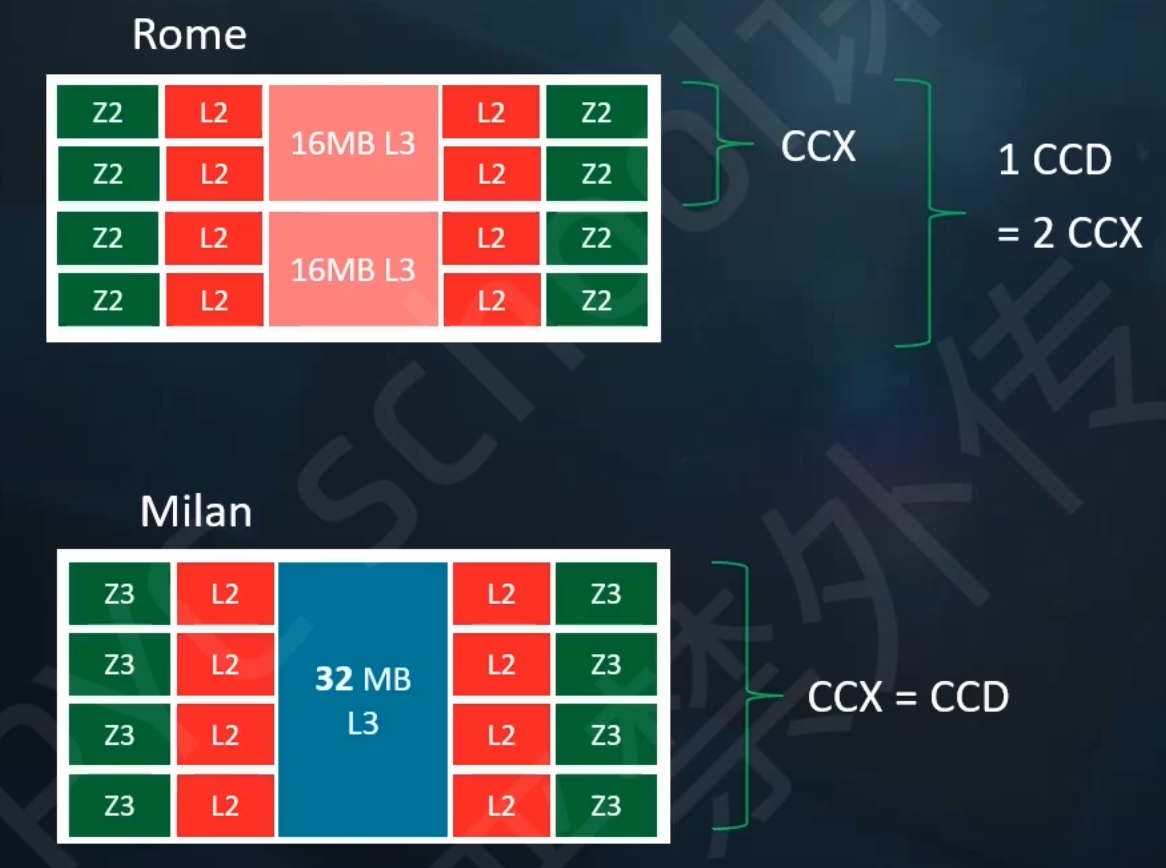
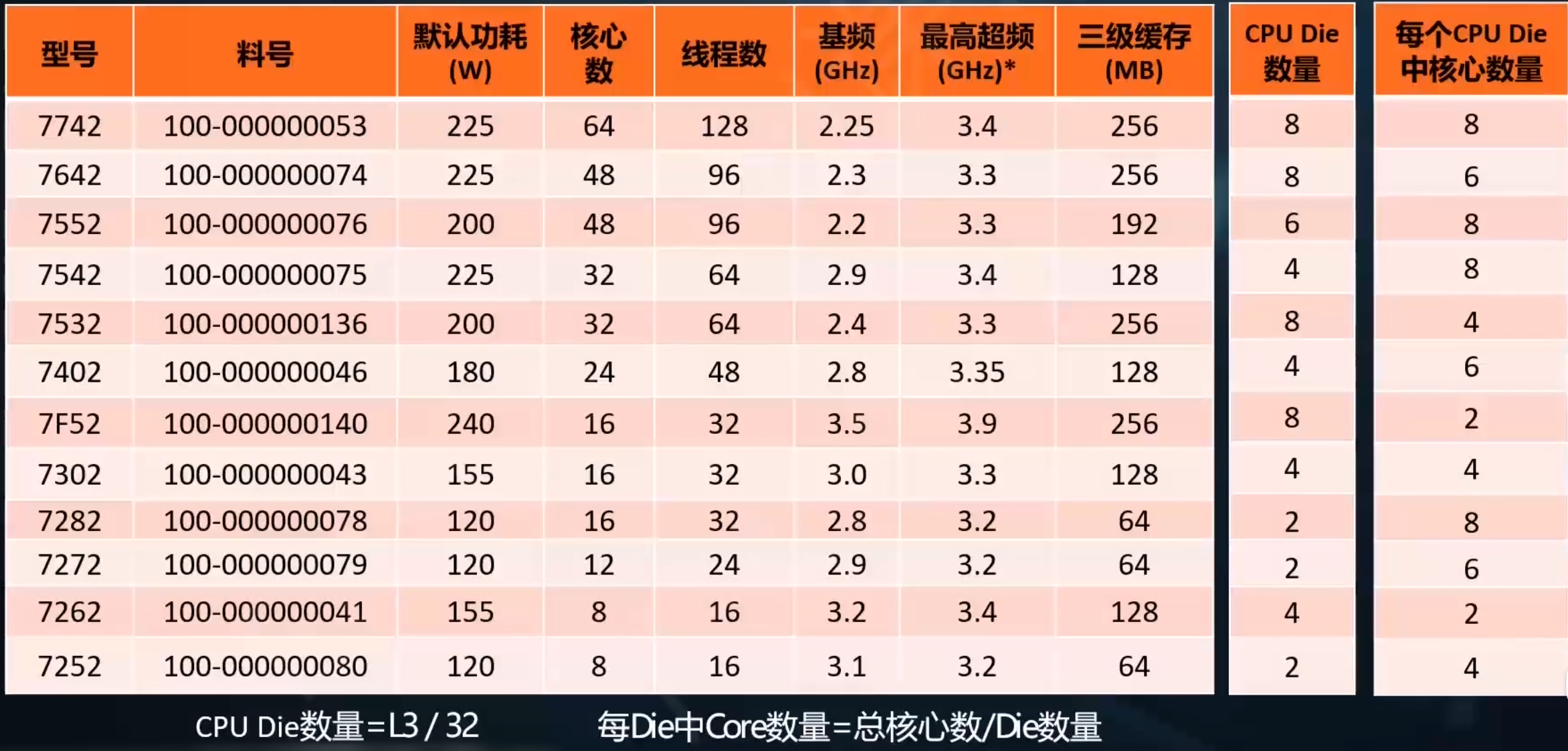
Arm cpu 向量化支持判断
向量化指令
需要进一步的研究学习
暂无
遇到的问题
暂无
CSAPP: Machine Programming III: Procedures
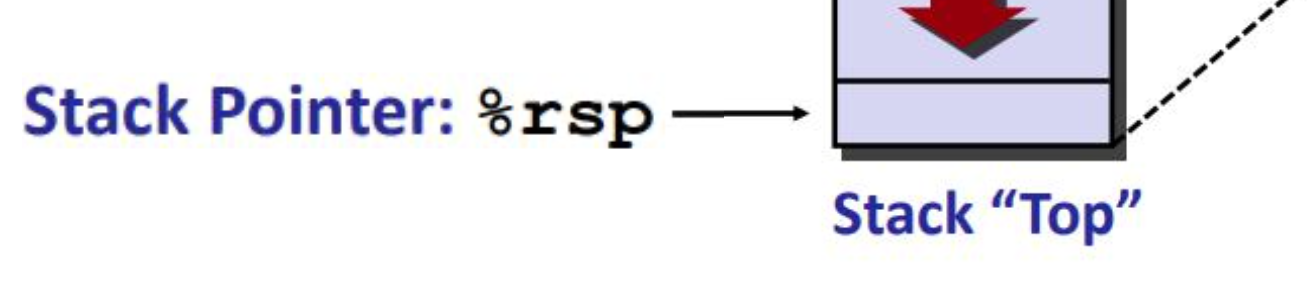
1 | rax 返回/传出寄存器 |
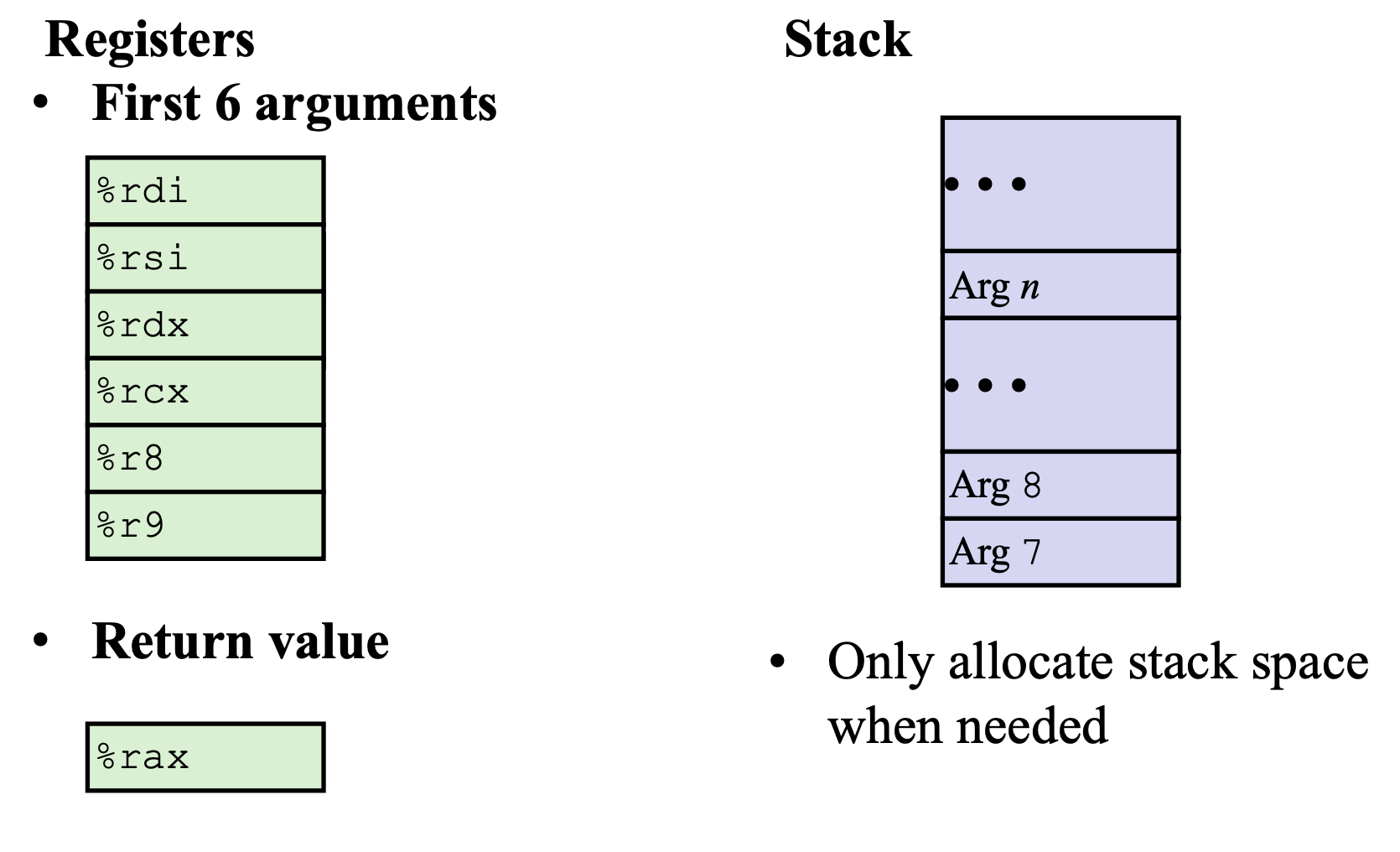
1 | 寄存器 %rsp 存放栈顶地址 (lowest stack address) pushq %rsp-8 popq %rsp+8 |
caller 调用者 callee 被调用者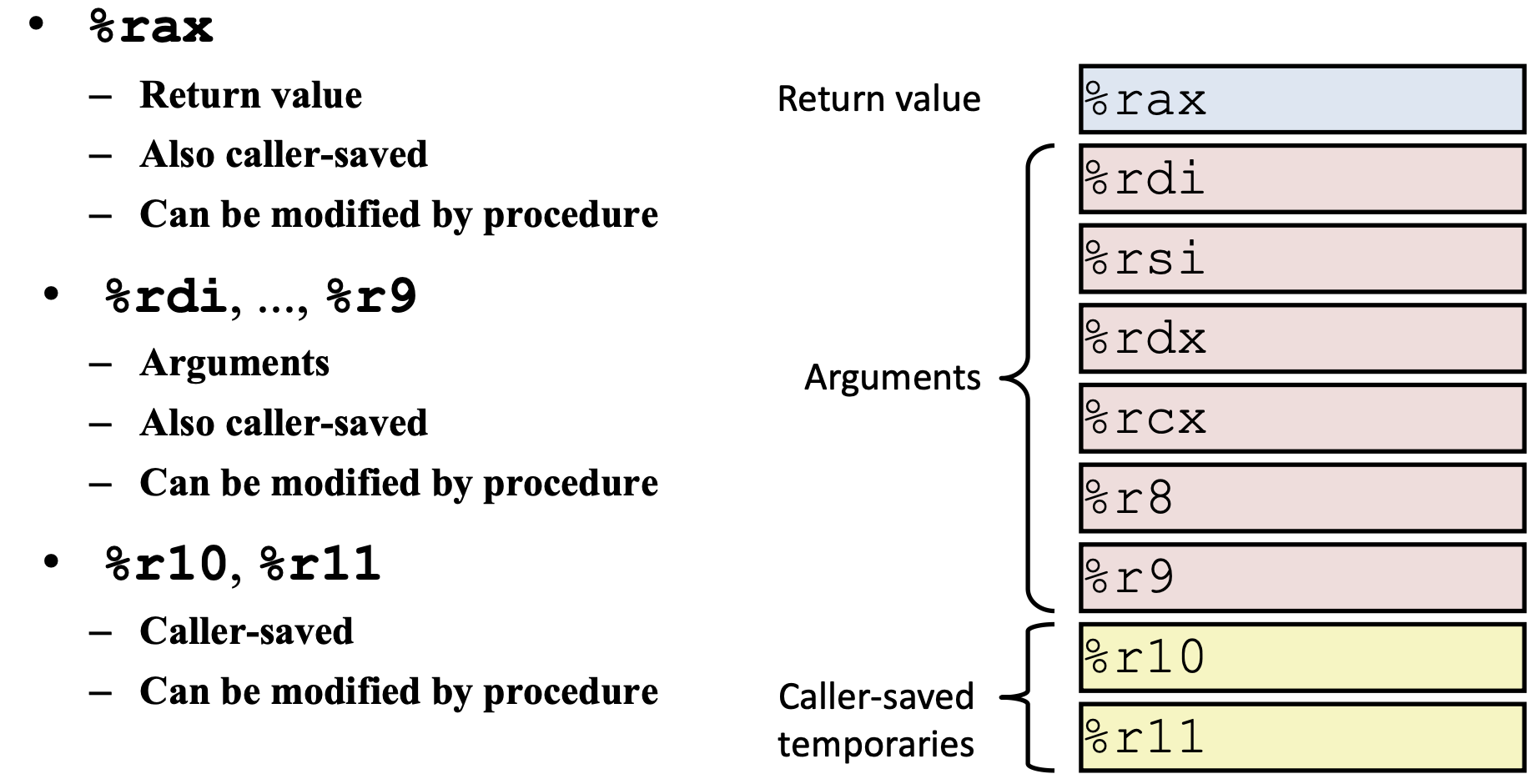
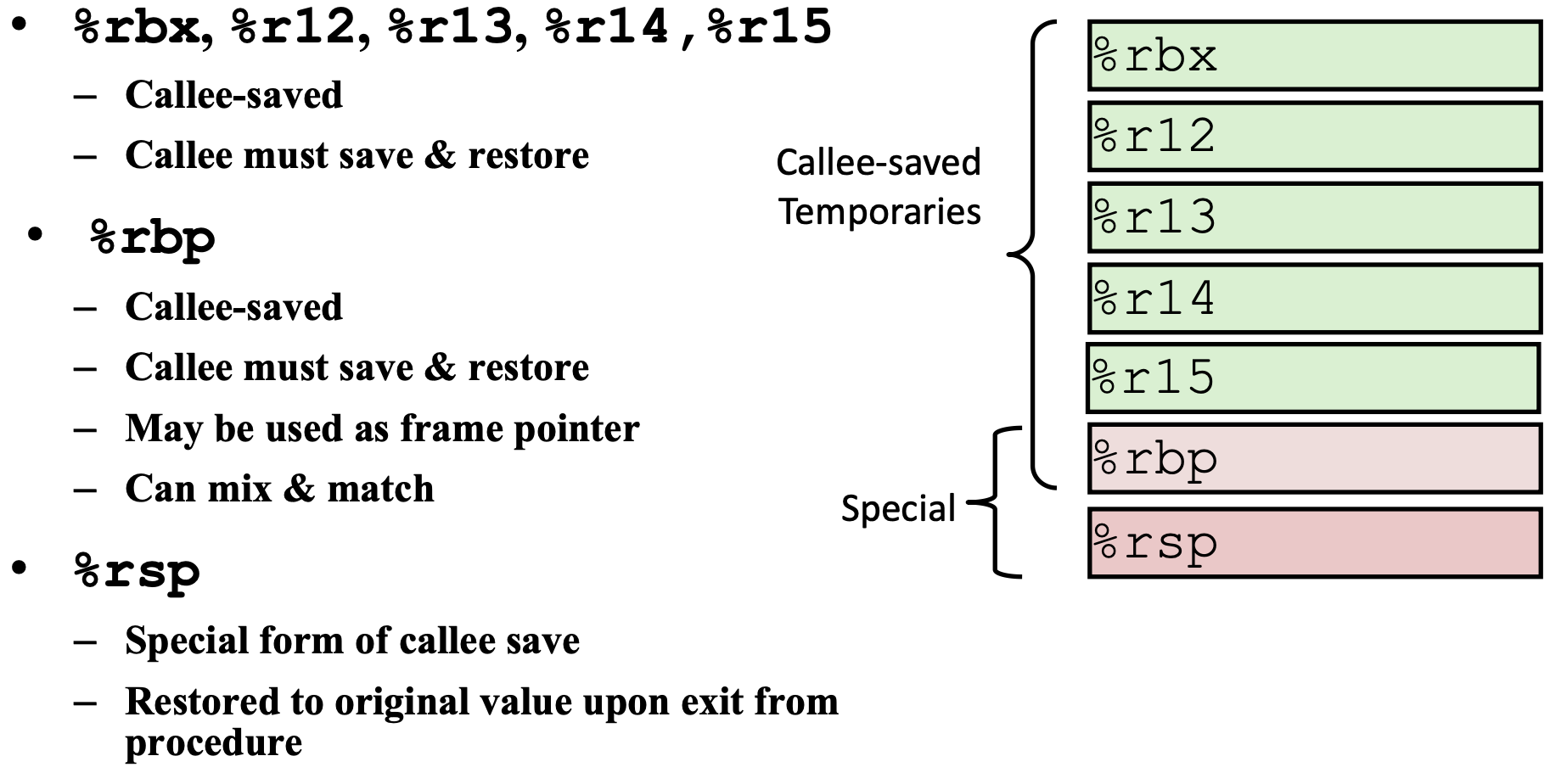
1 | callq 调用 |
https://bkfish.github.io/2018/12/21/CSAPP又双叒叕来一遍之函数调用过程栈帧的变化/

暂无
暂无
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
通过使用矢量寄存器,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如 AMD的3D NOW!技术
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE为Streaming SIMD Extensions的缩写。Intel SSE指令通过128bit位宽的专用寄存器, 支持一次操作128bit数据. float是单精度浮点数, 占32bit, 那么可以使用一条SSE指令一次计算4个float数。注意这些SSE指令要求参数中的内存地址必须对齐于16字节边界。
SSE有8个128位寄存器,XMM0 ~XMM7。此外SSE还提供了新的控制/状态寄存器MXCSR。为了回答这个问题,我们需要了解CPU的架构。每个core是独占register的
addps xmm0, xmm1 ; reg-reg
addps xmm0, [ebx] ; reg-mem
sse提供了两个版本的指令,其一以后缀ps结尾,这组指令对打包单精度浮点值执行类似mmx操作运算,而第二种后缀ss

Advanced Vector Extensions。较新的Intel CPU都支持AVX指令集, 它可以一次操作256bit数据, 是SSE的2倍,可以使用一条AVX指令一次计算8个float数。AVX指令要求内存地址对齐于32字节边界。


根据参考文章,其中用gcc编译AVX版代码时需要加-mavx选项.
开启-O3选项,一般不用将代码改成多次计算和内存对齐。
1 | gcc -march=native -c -Q --help=target # 查看支持的指令集 |
c++函数在linux系统下编译之后会变成如下样子
1 | _ZNK4Json5ValueixEPKc |
在linux命令行使用c++filter
1 | $ c++filt _ZNK4Json5ValueixEPKc |
可以得到函数的原始名称, 展开后续追踪
1 | -Rpass=loop-vectorize |
1 | xmm 寄存器 |

循环展开8次
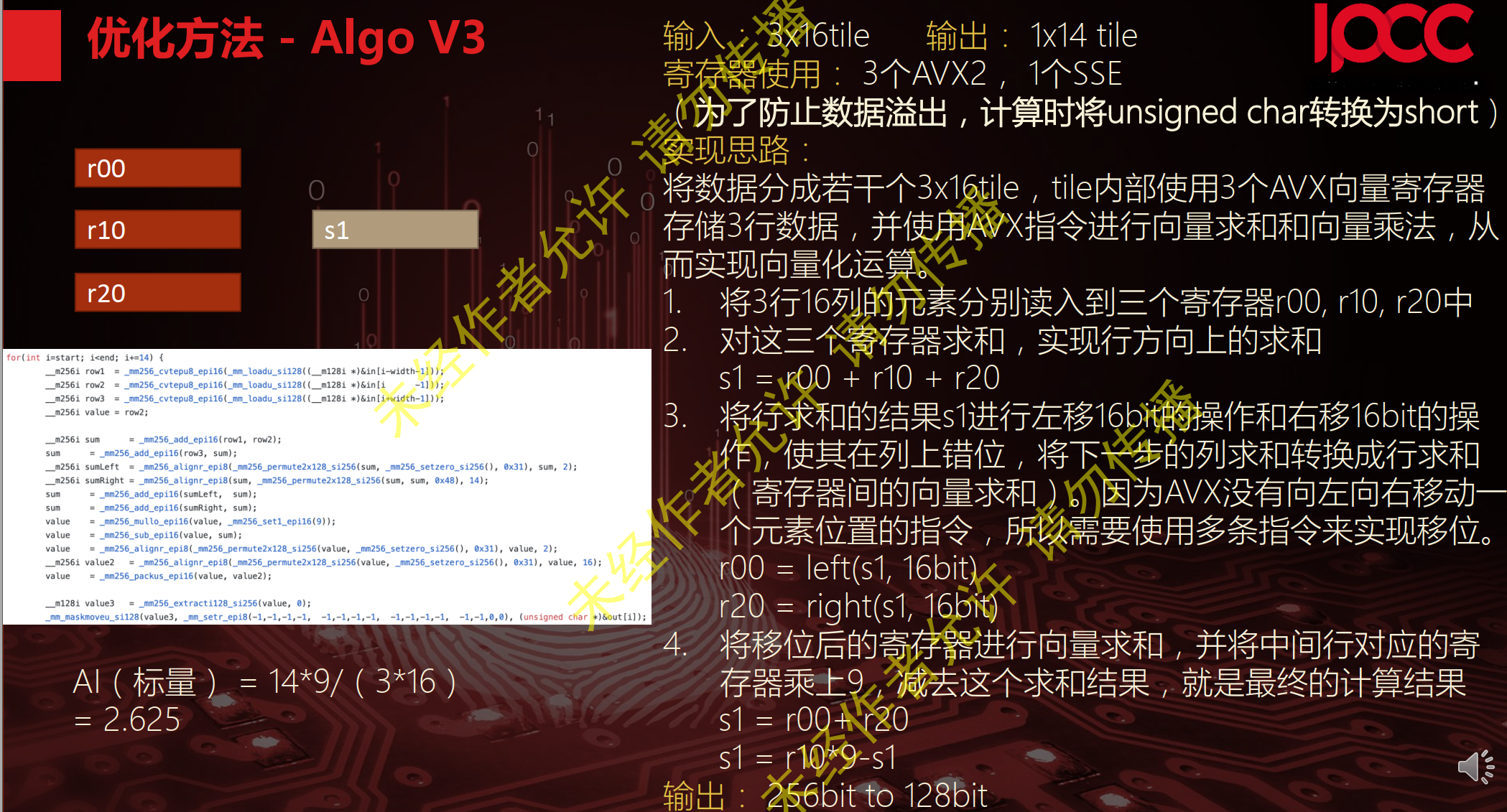
暂无
暂无
https://www.dazhuanlan.com/2020/02/01/5e3475c89d5bd/
https://software.intel.com/sites/landingpage/IntrinsicsGuide/
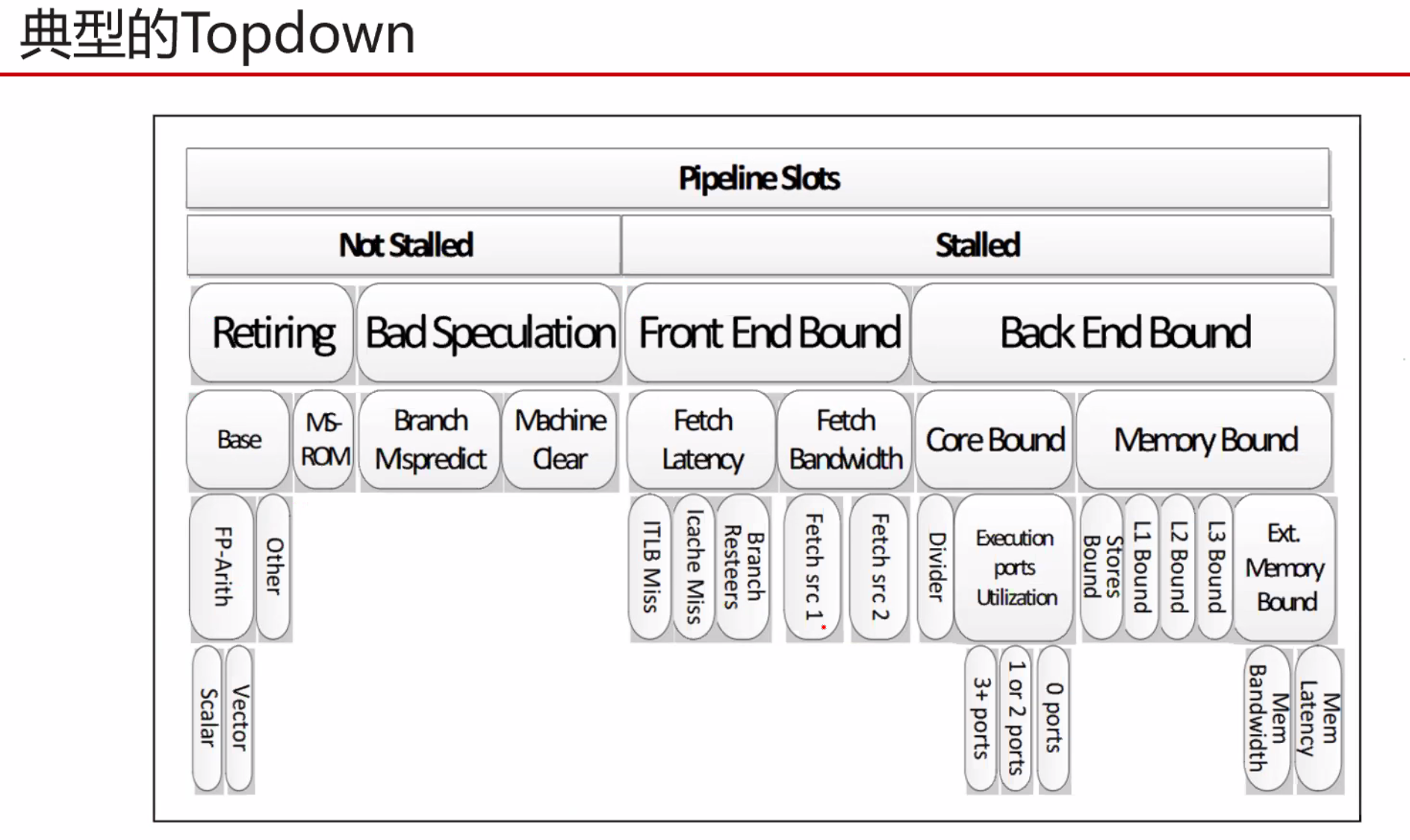
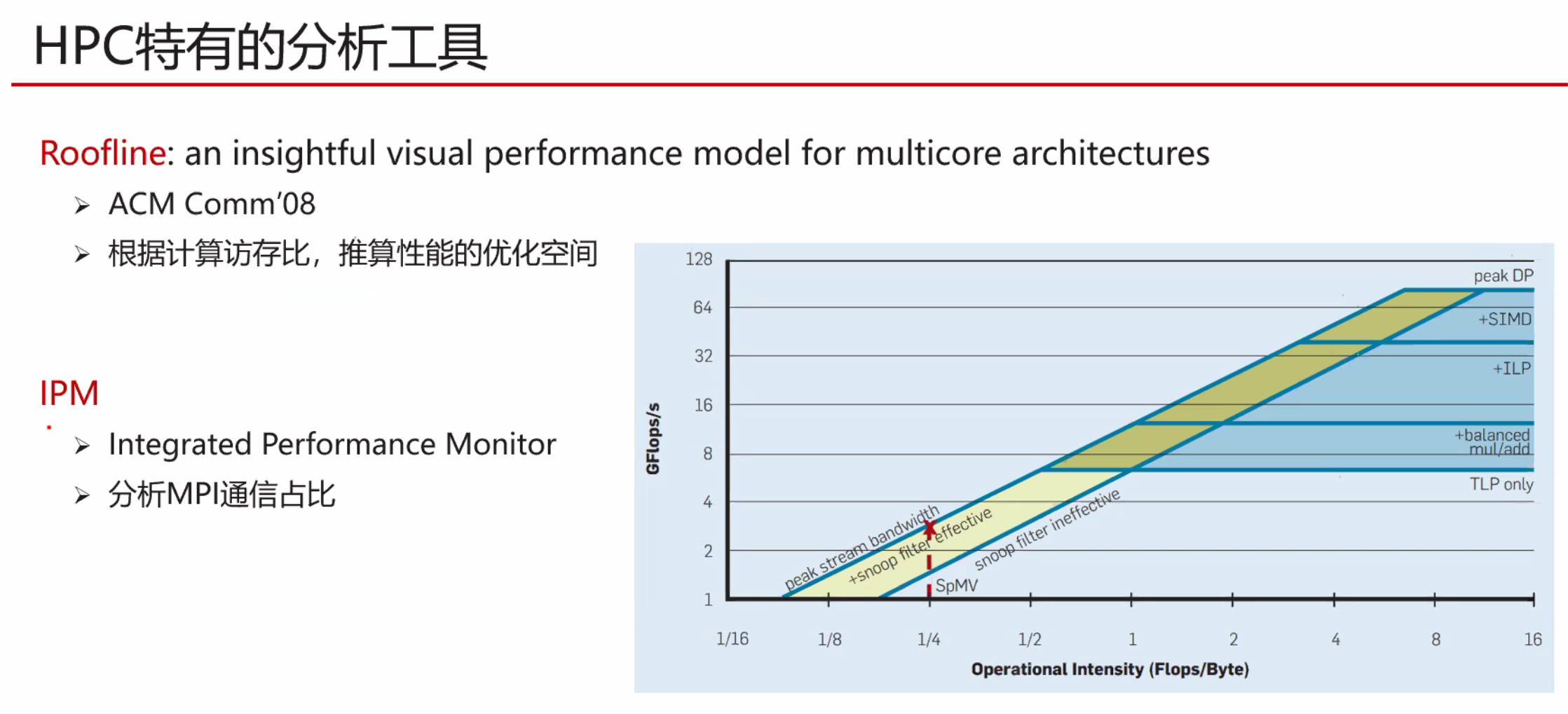
现代计算机微架构是最复杂的几个人造系统。在上面预测,解释和优化软件是困难的。我们需要其运行行为的可信模型,但是事实是稀缺的。
本文设计和实现了一种构建X86指令的延迟,吞吐量和端口使用的可信模型。并仔细探究了这三个指标的定义。尤其是latency的值在不同的操作数情况时是如何确定的。
同时其结果也是机器可读的。并且对已有的所有Intel架构都进行了测试。
官网有结果 http://www.uops.info
We also plan to release the source code of our tool as open source
balabala~
我们的工具可以用来优化llvm-mca等软件。
Future work includes adapting our algorithms to AMD x86 CPUs. 官网已经实现了。
We would also like to extend our approach tocharacterize other undocumented performance-relevant aspects of the pipeline, e.g., regarding micro and macro-fusion, or whether instructions use the simple decoder, the complex decoder, or the Microcode-ROM.
暂无
暂无
BHive : An Infrastructure for Adaptive Dynamic Optimization 2003 IEEE
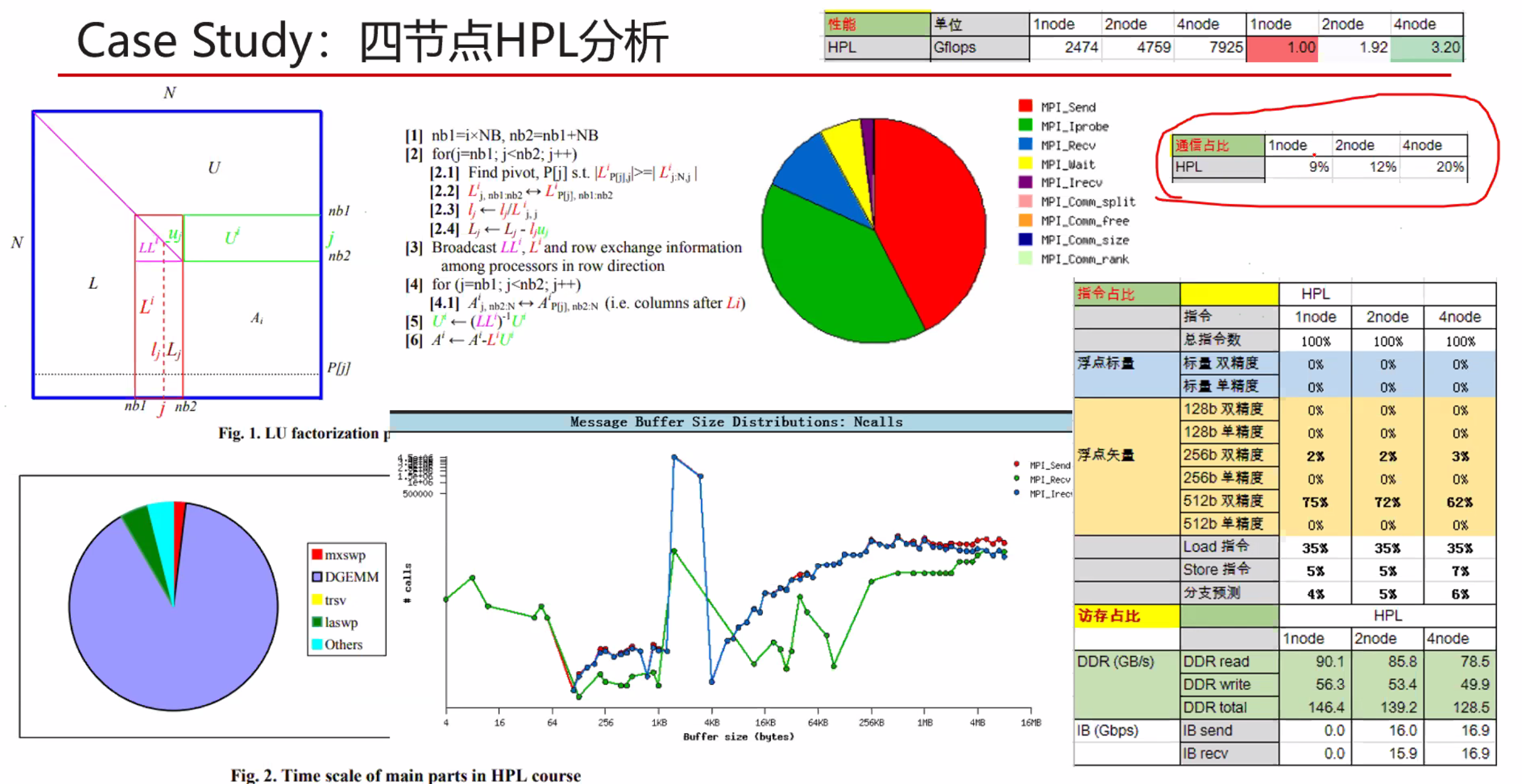
动态优化逐渐显现出是一种解决传统静态汇编困难的好方法。 但是市面上有大量的针对开发静态优化的编译器框架,但是少有针对动态优化的。
我们实现了一种动态分析和优化的框架,为DynamoRIO动态代码修改系统提供了一种创建额外模块的交互界面。通过简单轻量的API就可以提炼许多DynamoRIO运行时的底层细节,但是只能在单指令流下,而且不同指令显示的细节也是不同的。
该API不仅可以用来优化,也可以instrumentation,热点分析和动态翻译。
为了展现架构的有效性,我们实现了若干优化,一些例子有40%提升,基于DynamoRIO平均有12%加速。
随着现代软件的复杂,还有动态load,共享库等特性,静态分析越来越衰弱。静态分析器去分析整个程序是困难或者不可能的,而静态优化又受限于静态代码分析器的准确性。而且静态优化过多会导致出错时难以debug。
就是这个动态框架好,使用范围广,前途光明
https://github.com/DynamoRIO/dynamorio/blob/master/api/samples/bbbuf.c
暂无
暂无
鸡蛋从哪头打破,怎么会有哪种更合适呢?对个人生活和社会发展又有什么意义呢?Swift写这段故事,其实是讽刺当时法国和英国的时政,认为真正重要的事情得不到关注、而在一些毫无意义的事情上争论不休。
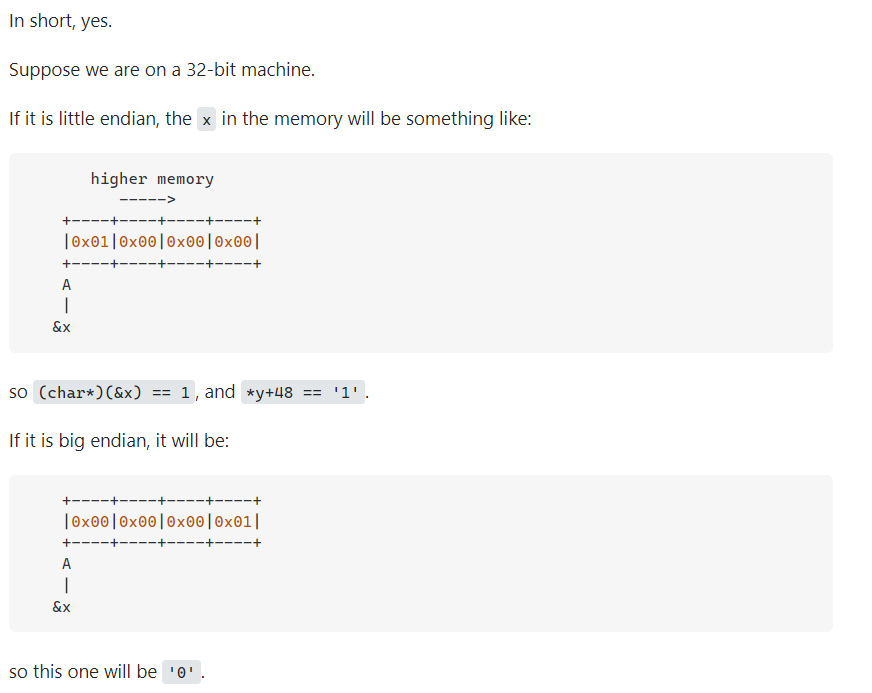
Motorola的PowerPC系列CPU采用Big-Endian方式存储数据,
而Intel的x86系列则采用Little-Endian方式存储数据。
JAVA虚拟机中多字节类型数据的存放顺序,也就是JAVA字节序是Big-Endian。
很多的ARM,DSP(Digital signal processor)都为小端模式。有些ARM处理器还可以随时在程序中(在ARM Cortex 系列使用REV、REV16、REVSH指令)进行大小端的切换。
得益于高级语言的发展,在现在的软件开发基本不需关心字节序(除非是socket编程),如Java这类跨平台移植的语言由虚拟机屏蔽了字节序问题。
对于大小端的处理也和编译器的实现有关,在C语言中,默认是小端(但在一些对于单片机的实现中却是基于大端,比如Keil 51C),Java是平台无关的,默认是大端。在网络上传输数据普遍采用的都是大端
华为鲲鹏AArch64 和 Intel x86 都是little-endian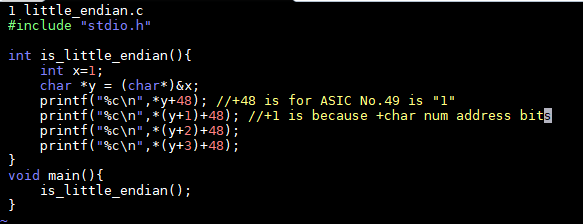

暂无
暂无
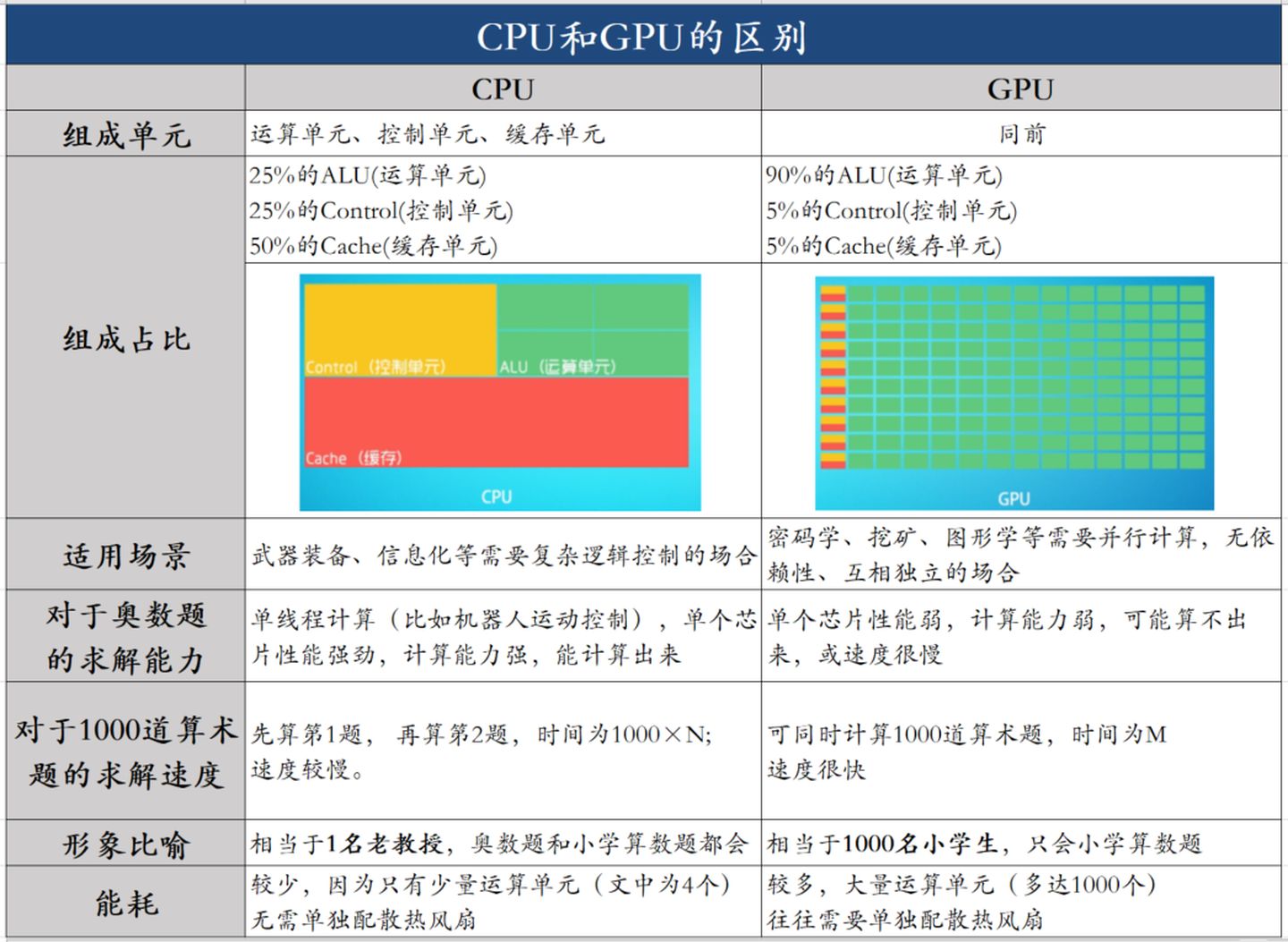
低延时的设计思路
相比之下计算能力只是CPU很小的一部分。擅长逻辑控制,串行的运算。
大吞吐量设计思路
0 cycles and can happen every cycle.[^2]对带宽大的密集计算并行性能出众,擅长的是大规模并发计算。
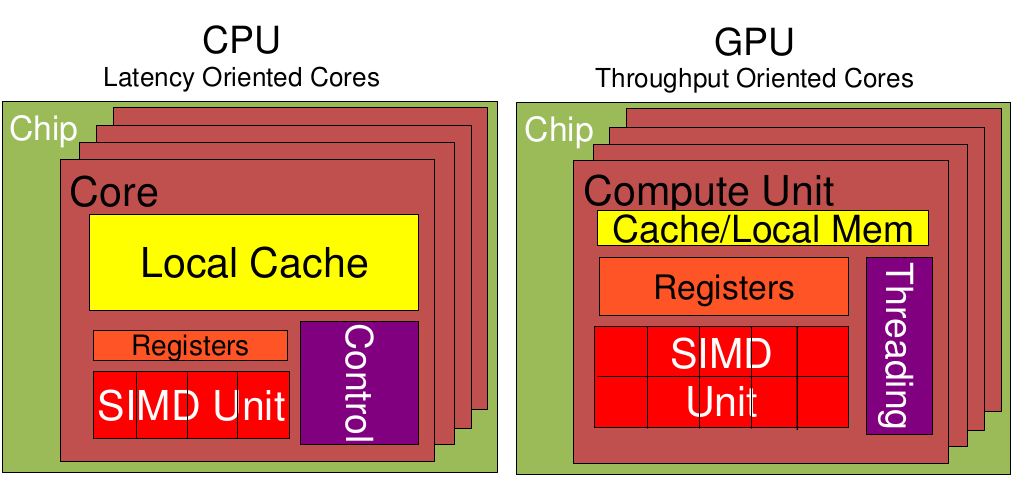
| 对比项 | CPU | GPU | 说明 |
|---|---|---|---|
| Cache, local memory | 多 | 低延时 | |
| Threads(线程数) | 多 | ||
| Registers | 多 | 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。 | |
| SIMD Unit | 多 | 单指令多数据流,以同步方式,在同一时间内执行同一条指令 |
其实最早用在显卡上的DDR颗粒与用在内存上的DDR颗粒仍然是一样的。后来由于GPU特殊的需要,显存颗粒与内存颗粒开始分道扬镳,这其中包括了几方面的因素:
1 | sudo dmidecode|grep -A16 "Memory Device"|grep "Speed" |
因为显存可以在一个时钟周期内的上升沿和下降沿同时传送数据,所以显存的实际频率应该是标称频率的一半。
从GDDR5开始用两路传输,GDDR6采用四路传输(达到类似效果)。
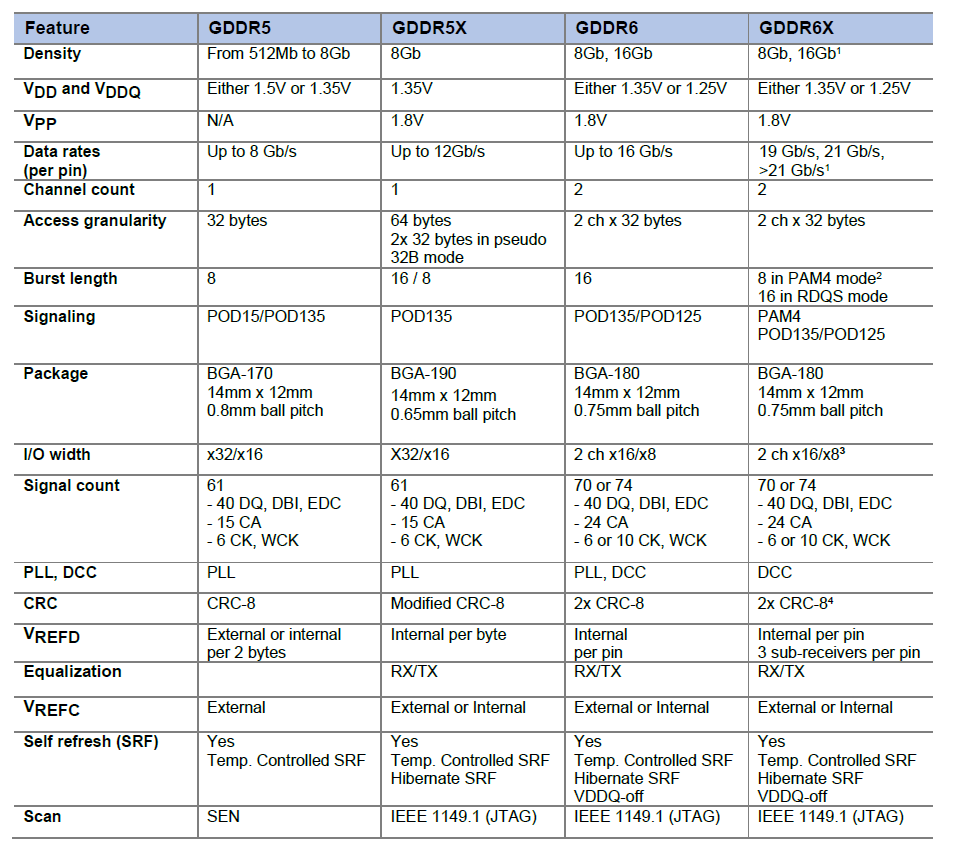
GDDR6X的频率估计应该至少从16Gbps(GDDR6目前的极限)起跳,20Gbps为主,这样在同样的位宽下,带宽比目前常见的14Gbps GDDR6大一半。比如在常见的中高端显卡256bit~384位宽下能提供512GB/s~768GB/s的带宽。
RTX 3090的GDDR6X显存位宽384bit,等效频率19Gbps到21Gbps,带宽可达912GB/s到1006GB/s,达到T级。(384*19/8=912)
RTX 3090 加速频率 (GHz) 1.7, 基础频率 (GHz) 1.4
1 | 19/1.4 = 13.57 |
912GB/s到1006GB/s 附近3.2 Gbps * 64 bits * 2 / 8 = 51.2GB/s可见两者差了20倍左右。
通过上面的例子,大致能知道: 需要高访存带宽和高并行度的SIMD的应用适合分配在GPU上。
$$ 144 SM * 4 warpScheduler/SM * 32 Threads/warps = 18432 $$
https://zhuanlan.zhihu.com/p/156171120?utm_source=wechat_session
https://www.cnblogs.com/biglucky/p/4223565.html
https://www.zhihu.com/question/36825227/answer/69351247
https://baijiahao.baidu.com/s?id=1675253413370892973&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/62234511
https://kknews.cc/digital/x6v69xq.html
[^1]: 并行计算课程-CUDA 密码pa22

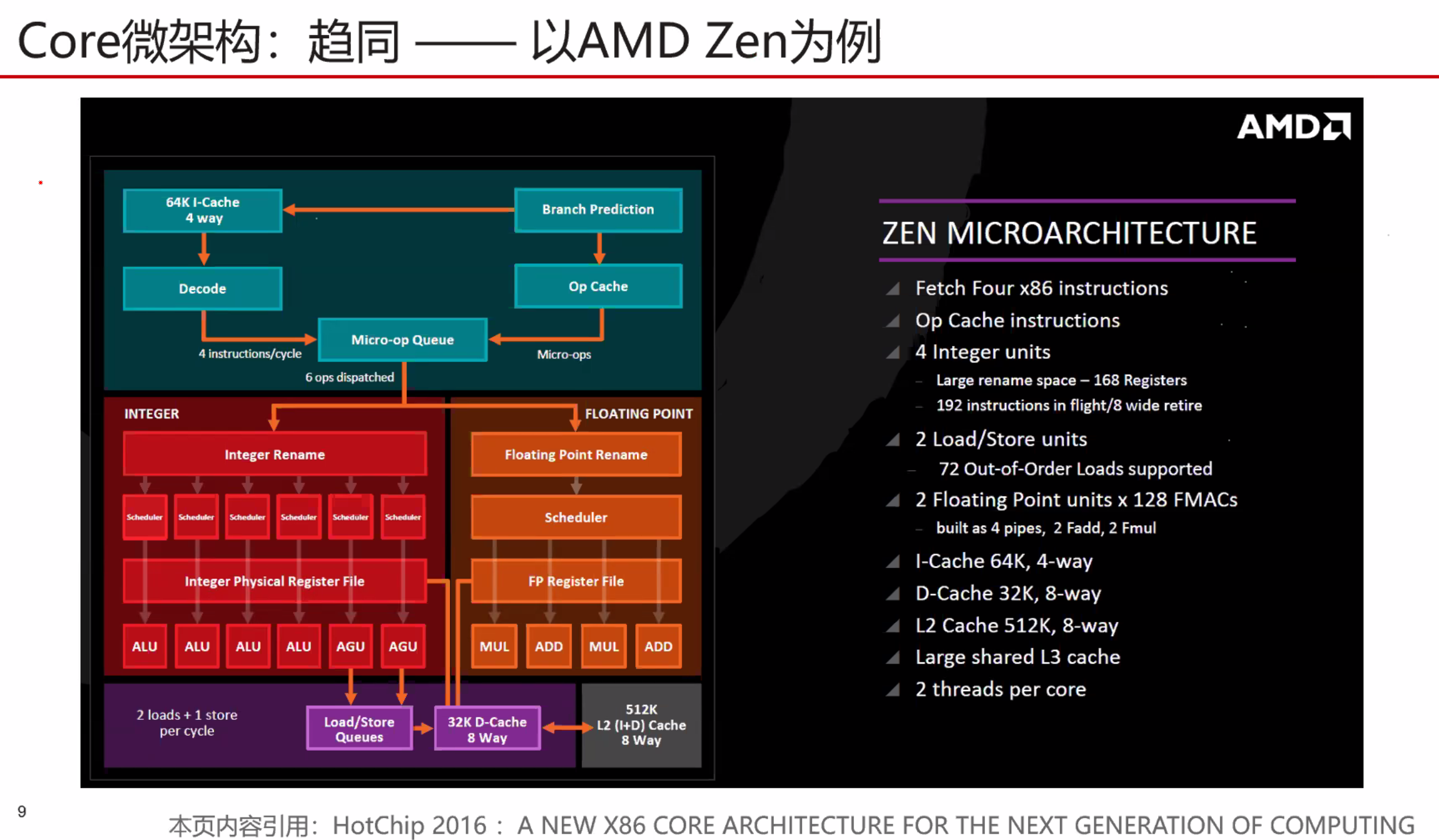
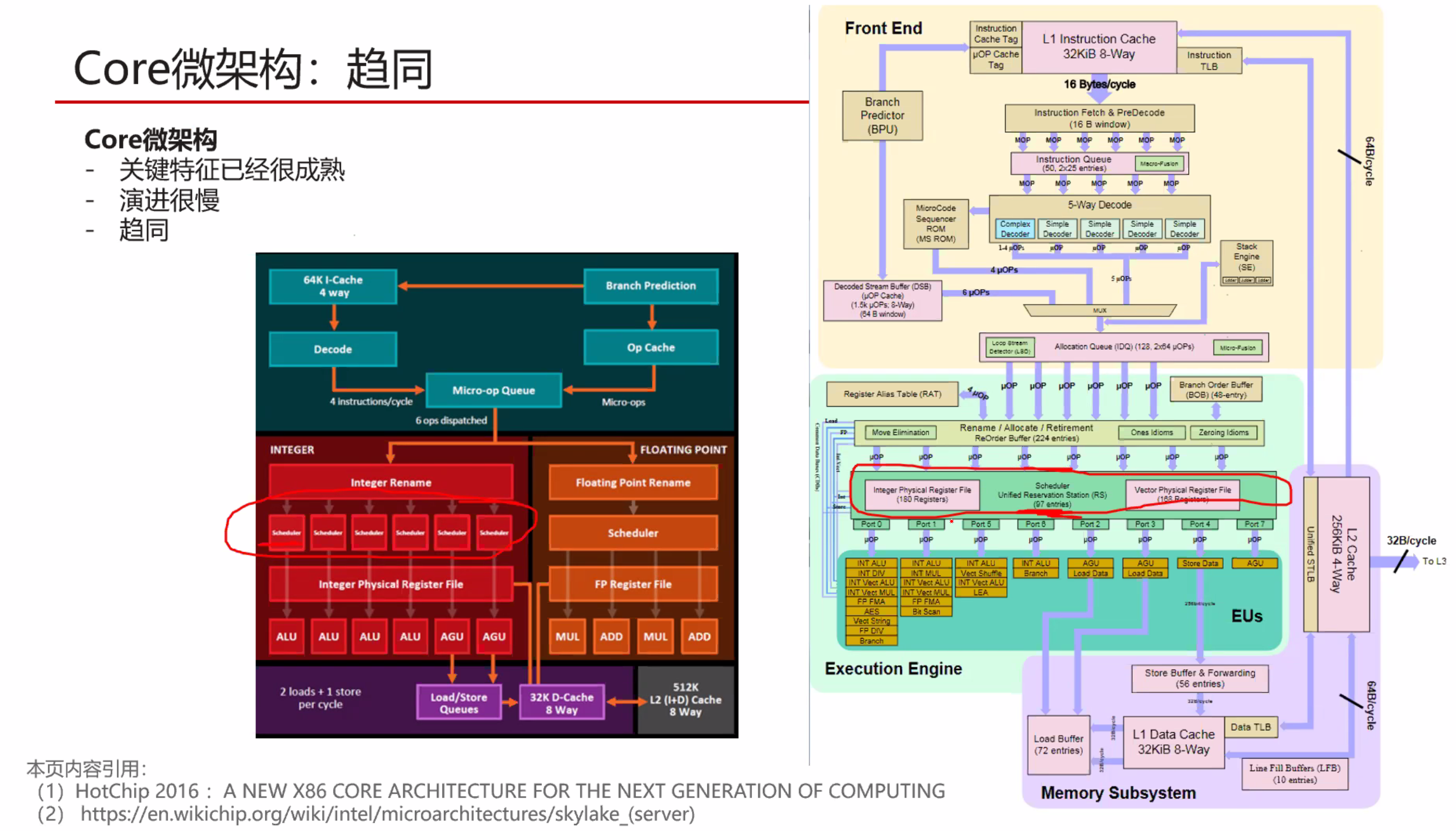
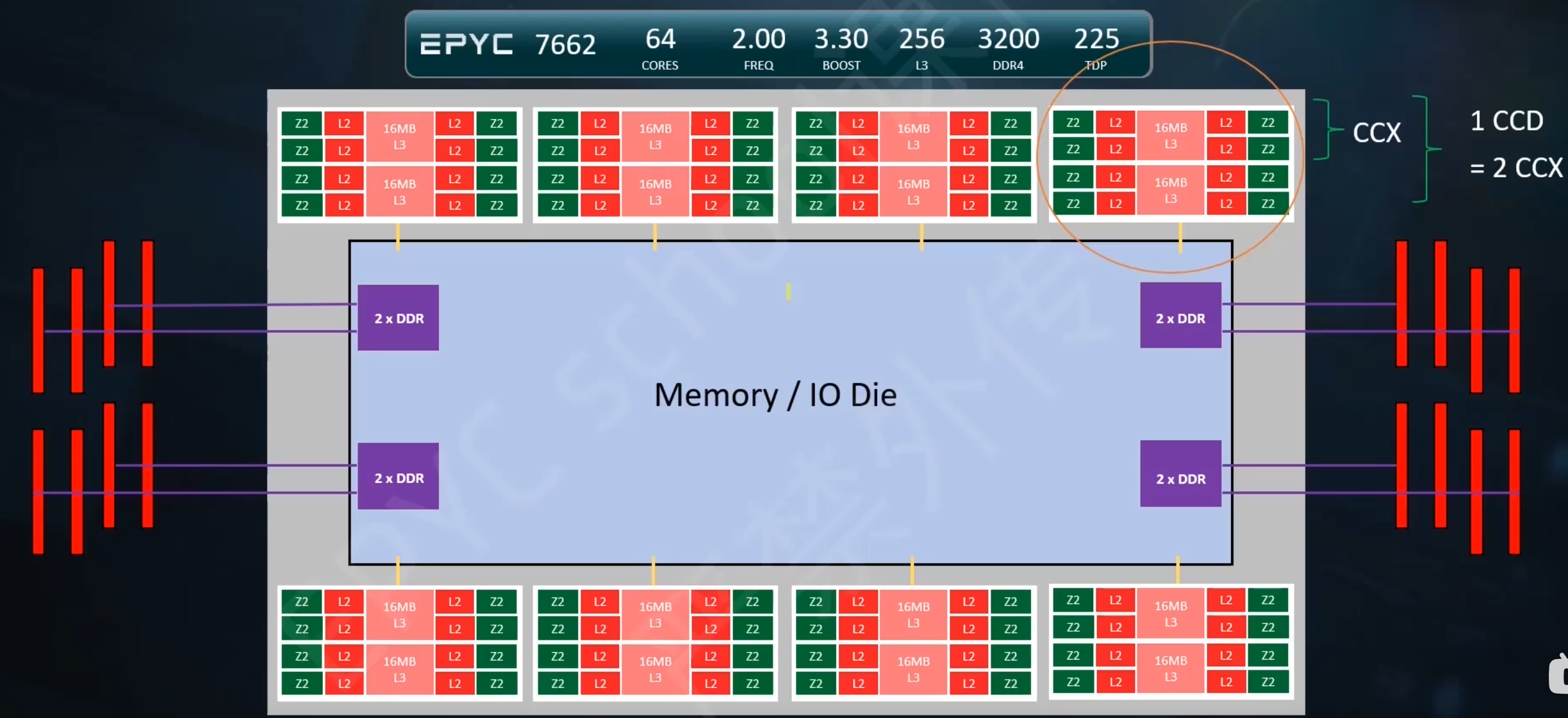
Zen 2 使用所谓的 TAGE 分支预测器,它比其前身具有更深的分支历史。这通过比 Zen (+) 更大的分支目标缓冲区 (BTB) 得到增强,L1 BTB(512 个条目)增加了一倍,L2 BTB 几乎增加了一倍(现在为 7K)。随着 MOP 缓存增长到 4K,更大更好的主题仍在继续。这特别方便,因为没有处理器想要多次解码微操作。将它们解码一次并将它们放入大(r)缓存中可以加快速度并使处理器更高效。
有趣的是,在分析了大量应用程序及其数据集大小后,指令缓存实际上从 64KB 下降到 32KB,但关联性从 4 路增加到 8 路。原因是,根据 Mike Clark 的说法,这种减少几乎不会降低性能:无论如何,大多数数据集都需要超过 64KB。新的缓存还具有改进的预取和更好的利用率。
这一切意味着 Zen 2 的前端更高效——有助于 IPC——但确实以占用更多空间为代价。


https://hexus.net/tech/news/cpu/131549-the-architecture-behind-amds-zen-2-ryzen-3000-cpus/