https://developer.amd.com/amd-aocc/
Install
1 | cd <compdir>\ |
Using AOCC

Libraries
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
https://developer.amd.com/wp-content/resources/AOCC_57223_Install_Guide_Rev_3.1.pdf
https://developer.amd.com/amd-aocc/
1 | cd <compdir>\ |
暂无
暂无
https://developer.amd.com/wp-content/resources/AOCC_57223_Install_Guide_Rev_3.1.pdf
Latest release: 2.1, Nov 2019
https://developer.amd.com/amd-aocc/Advanced

暂无
https://prace-ri.eu/wp-content/uploads/Best-Practice-Guide_AMD.pdf#page35
对于大部分选项,Intel编译器在Win上的格式为:/Qopt,那么对应于Lin上的选项是:-opt。禁用某一个选项的方式是/Qopt-和-opt-。
在Win上,编译器为icl.exe,链接器为xilink.exe,VS的编译器为cl.exe,链接器为link.exe。
在Linux下,C编译器为icc,C++编译器为icpc(但是也可以使用icc编译C++文件),链接器为xild,打包为xiar,其余工具类似命名。
GNU的C编译器为gcc,C++编译器为g++,链接器为ld,打包为ar
如果选项 O2 或更高版本有效,则启用 OpenMP* SIMD 编译。
告诉自动并行程序为可以安全地并行执行的循环生成多线程代码。
要使用此选项,您还必须指定选项 O2 或 O3。
如果还指定了选项 O3,则此选项设置选项 [q 或 Q]opt-matmul。
启用或禁用编译器生成的矩阵乘法(matmul)库调用。
必须至少与-O2一起使用,在Linux系统上,如果既不指定-x也不指定-m,则默认值为-msse2。
On macOS* systems: -ipo, -mdynamic-no-pic,-O3, -no-prec-div,-fp-model fast=2, and -xHost
On Windows* systems: /O3, /Qipo, /Qprec-div-, /fp:fast=2, and /QxHost
On Linux* systems: -ipo, -O3, -no-prec-div,-static, -fp-model fast=2, and -xHost
指定选项 fast 后,您可以通过在命令行上指定不同的特定于处理器的 [Q]x 选项来覆盖 [Q]xHost 选项设置。但是,命令行上指定的最后一个选项优先。
必须至少与-O2一起使用,如果同时指定 -ax 和 -march 选项,编译器将不会生成特定于 Intel 的指令。
指定 -march=pentium4 设置 -mtune=pentium4。
告诉编译器它可以针对哪些处理器功能,包括它可以生成哪些指令集和优化。
1 | AMBERLAKE |

告诉编译器它可能针对哪些功能,包括它可能生成的指令集。
生成基于多个指令集的代码。
High-level Optimizations,高级(别)优化。O1不属于
更广泛的优化。英特尔推荐通用。
在O2和更高级别启用矢量化。
在使用IA-32体系结构的系统上:执行一些基本的循环优化,例如分发、谓词Opt、交换、多版本控制和标量替换。
此选项还支持:
1 | 内部函数的内联 |
O3选项对循环转换(loop transformations)进行更好的处理来优化内存访问。
比-O2更激进,编译时间更长。建议用于涉及密集浮点计算的循环代码。
既执行O2优化,并支持更积极的循环转换,如Fusion、Block Unroll和Jam以及Collasing IF语句。
此选项可以设置其他选项。这由编译器决定,具体取决于您使用的操作系统和体系结构。设置的选项可能会因版本而异。
当O3与options-ax或-x(Linux)或options/Qax或/Qx(Windows)一起使用时,编译器执行的数据依赖性分析比O2更严格,这可能会导致更长的编译时间。
O3优化可能不会导致更高的性能,除非发生循环和内存访问转换。在某些情况下,与O2优化相比,优化可能会减慢代码的速度。
O3选项建议用于循环大量使用浮点计算和处理大型数据集的应用程序。
与非英特尔微处理器相比,共享库中的许多例程针对英特尔微处理器进行了高度优化。
-O3 plus some extras.
Interprocedural Optimizations,过程间优化。
典型优化措施包括:过程内嵌与重新排序、消除死(执行不到的)代码以及常数传播和内联等基本优化。
过程间优化,当程序链接时检查文件间函数调用的一个步骤。在编译和链接时必须使用此标志。使用这个标志的编译时间非常长,但是根据应用程序的不同,如果与-O*标志结合使用,可能会有明显的性能改进。
内联或内联展开,简单理解,就是将函数调用用函数体代替,主要优点是省去了函数调用开销和返回指令的开销,主要缺点是可能增大代码大小。
PGO优化是分三步完成的,是一个动态的优化过程。
PGO,即Profile-Guided Optimizations,档案导引优化。
此标志对特定的处理器类型进行额外的调整,但是它不会生成额外的SIMD指令,因此不存在体系结构兼容性问题。调优将涉及对处理器缓存大小、指令优先顺序等的优化。
为支持指定英特尔处理器或微体系结构代码名的处理器优化代码。
不启用 提高浮点除法的精度。
不用动态库
自动向量化时按照固定精度,与OpenMP的选项好像有兼容性的问题
展开所有循环,即使进入循环时迭代次数不确定。此选项可能会影响性能。
此选项决定编译器是否对某些循环使用更激进的展开。期权的积极形式可以提高绩效。
此选项可对具有较小恒定递增计数的回路进行积极的完全展开。
将循环对齐到 2 的幂次字节边界。
-falign-loops[=n]是最小对齐边界的可选字节数。它必须是 1 到 4096 之间的 2 的幂,例如 1、2、4、8、16、32、64、128 等。如果为 n 指定 1,则不执行对齐;这与指定选项的否定形式相同。如果不指定 n,则默认对齐为 16 字节。
关闭所有优化选项,-O等于-O2 (Linux* and macOS*)
在保证代码量不增加的情况下编译,
1 | icpc -dM -E -x c++ SLIC.cpp |
parallel 与mpicc 或者mpiicc有什么区别呢
讲实话,IPO PGO我已经晕了,我先列个list,之后再研究
IPCC Preliminary SLIC Optimization 2
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 21872 ms | 1 | |
| 核心循环openmp | 未指定 | 8079ms | ||
| 核心循环openmp | 单节点64核 | 7690ms | 2.84 | |
| 换intel的ipcp | 基于上一步 | 3071 ms | 7.12 | |
| -xHOST | 其余不行,基于上一步 | 4012ms | ||
| -O3 | 基于上一步 | 3593ms |
Intel(R) Xeon(R) Platinum 8153 CPU @ 2.00GHz
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 29240 ms | 1 | |
| 核心循环openmp | 未指定(htop看出64核) | 12244 ms | ||
| 去除无用计算+两个numk的for循环 | 080501 | 11953 ms 10054 ms | ||
| 计算融合(去除inv) | 080502 | 15702 ms 14923 ms 15438 ms 11987 ms | ||
| maxlab openmp | 基于第三行080503 | 13872 ms 11716 ms | ||
| 循环展开?? | 14436 ms 14232 ms 15680 ms |
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT, AVX2, AVX512F, ADX and AVX512CD instructions. |
-xCORE-AVX2
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT and AVX2 instructions |
没有 FXSAVE,BMI,LZCNT 有BMI1,BMI2
使用-xAVX,或者-xHOST 来选择可用的最先进指令集
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT and AVX instructions. |
1 | ld: cannot find -lstdc++ |
icpc -Ofast -march=core-avx2 -ipo -mdynamic-no-pic -unroll-aggressive -no-prec-div -fp-mode fast=2 -funroll-all-loops -falign-loops -fma -ftz -fomit-frame-pointer -std=c++11 -qopenmp SLIC_openmp.cpp -o SLIC_slurm_intel_o3
基于核心的openmp并行
1 | delete all maxxy |
暂无
暂无
无
IPCC Preliminary SLIC Optimization 1
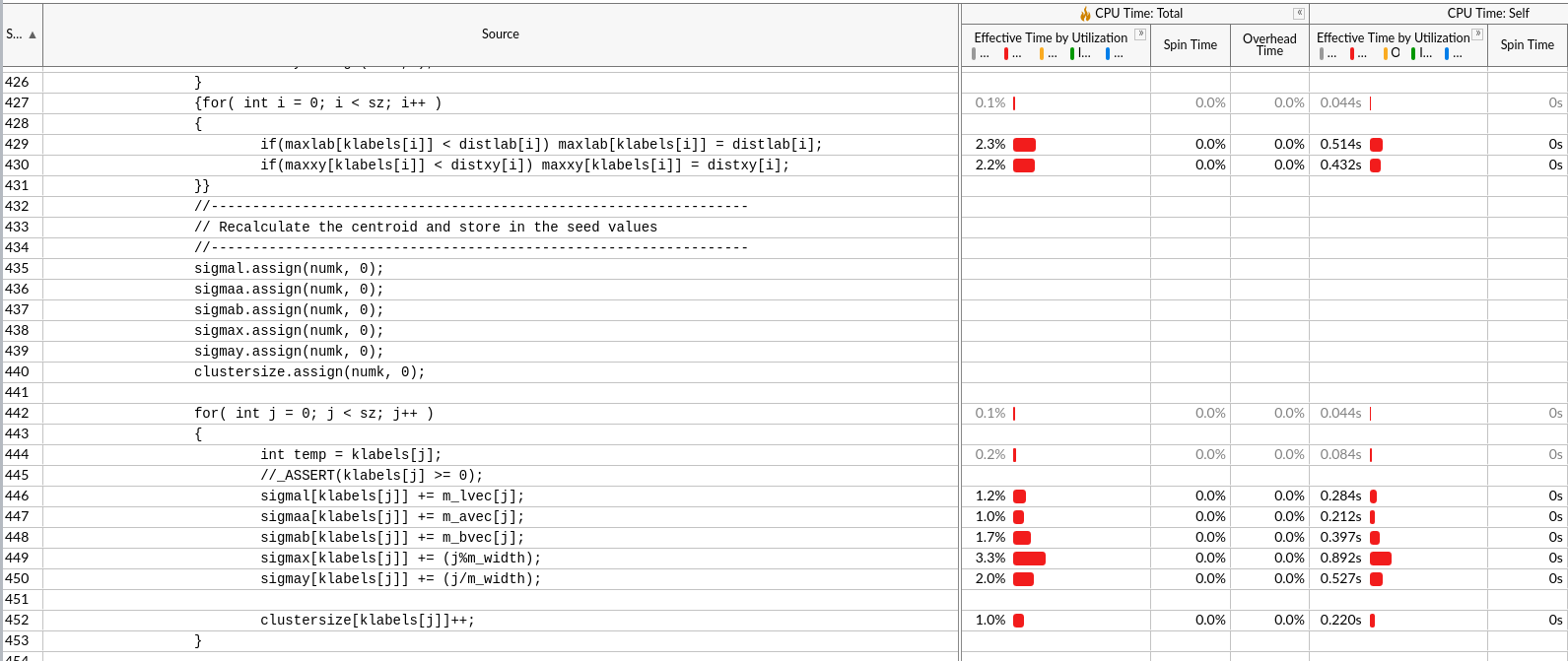
从数据重用(不重复计算,降低计算量)、计算融合(减少访存次数)、循环重组、改变数据结构入手
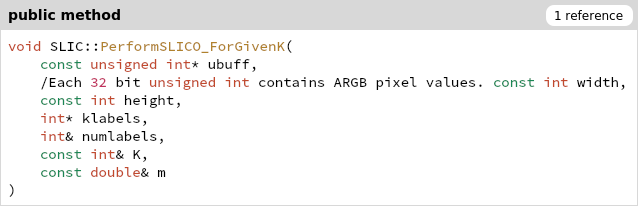
一开始所有的RGB颜色在ubuff里,klabel存分类结果
首先经过转换,将ubuff的RGB转换为lvec avec bvec三个double[sz]数组
存在私有变量m_lvec m_avec m_bvec,供class内访问
优化建议:lab三种颜色存在一起,访问缓存连续
DoRGBtoLABConversion(ubuff, m_lvec, m_avec, m_bvec);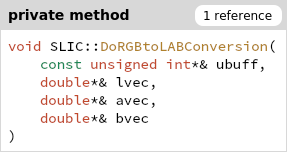
计算冗余一:

计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
优化建议:要用edges时再计算(保证了去除不必要计算和计算融合)

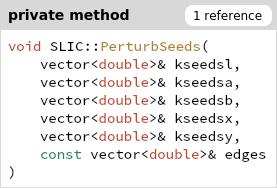
优化建议:kseedsl/a/b/x/y 分别用5个vector存是不好的,每个中心的5元组要存在一起,因为访问和修改都是一起的。
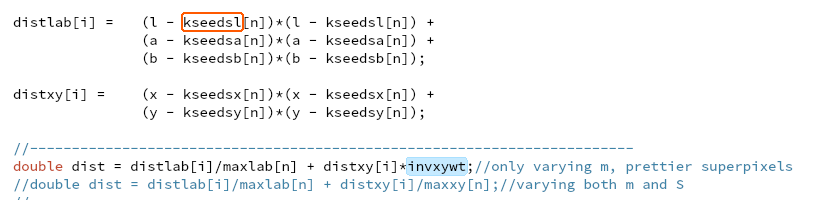
优化建议:

优化建议:
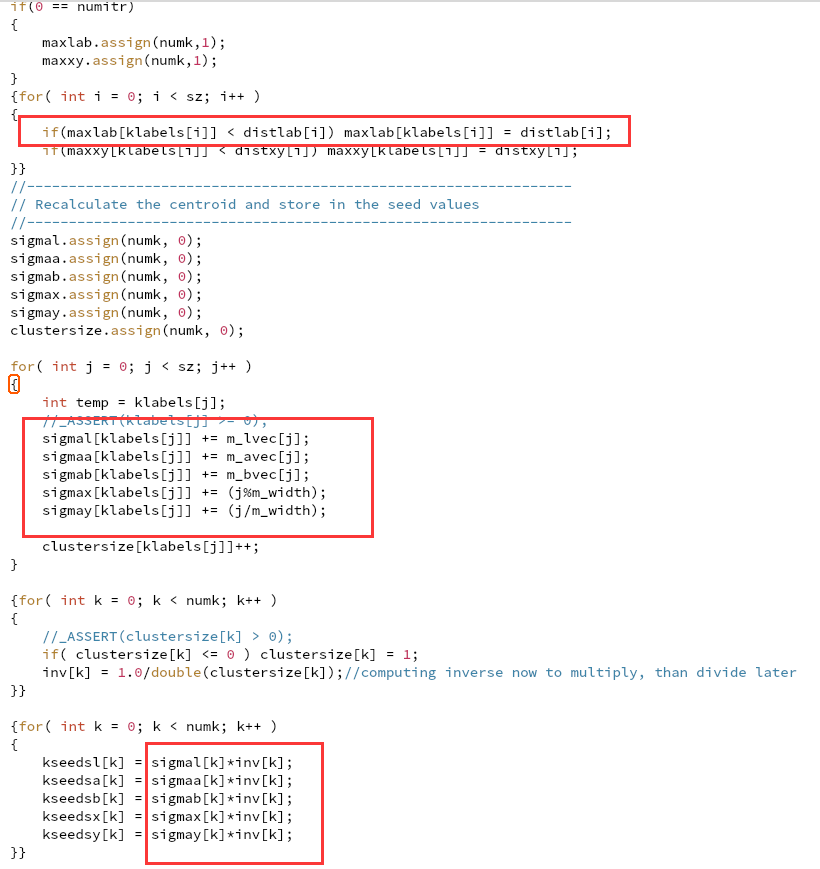
优化建议:
vector中的元素在内存中是连续存储的.
vector的实现是由一个动态数组构成. 当空间不够的时候, 采用类似于C语言的realloc函数重新分配空间. 正是因为vector中的元素是连续存储的, 所以vector支持常数时间内完成元素的随机访问. vector中的iterator属于Random Access Iterator.
每级cache难道只存读取数据周围的所有地址数据吗?还是一块一块读的。
假如调度是一块一块读取的而且cache足够大存下时,对于m_lvec m_avec m_bvec,假如各读取同一块,会导致和将其存储在一起是一样的效果。对于m_lvec[i]的下一个元素m_lvec[i+1],m_avec[i+1],m_bvec[i+1]也在cache中。
1 | #pragma omp parallel for collapse(2) |
minicoda for tmux zsh htop gcc9
pip install gdbgui to localhost
gdb tui enable
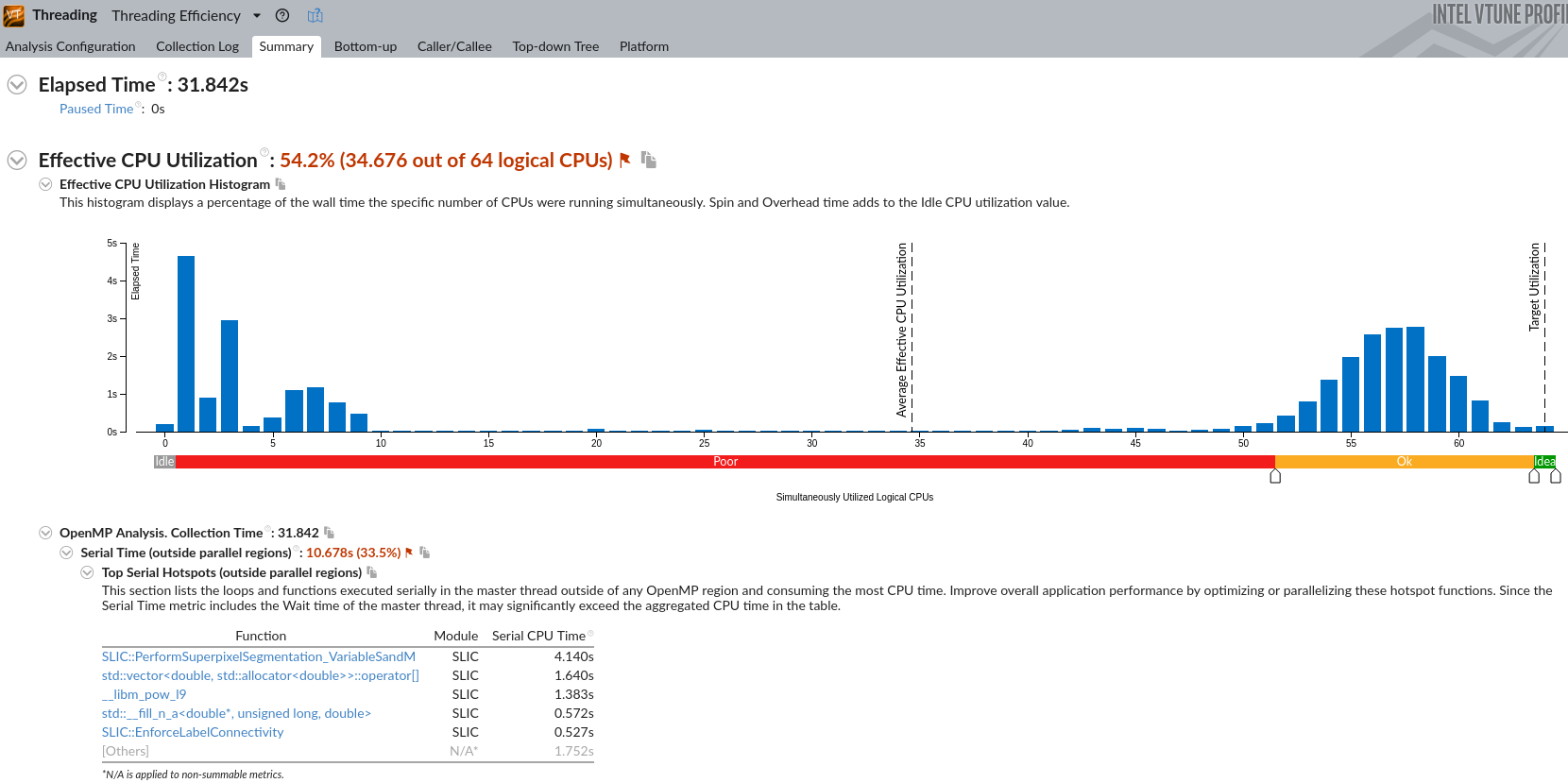
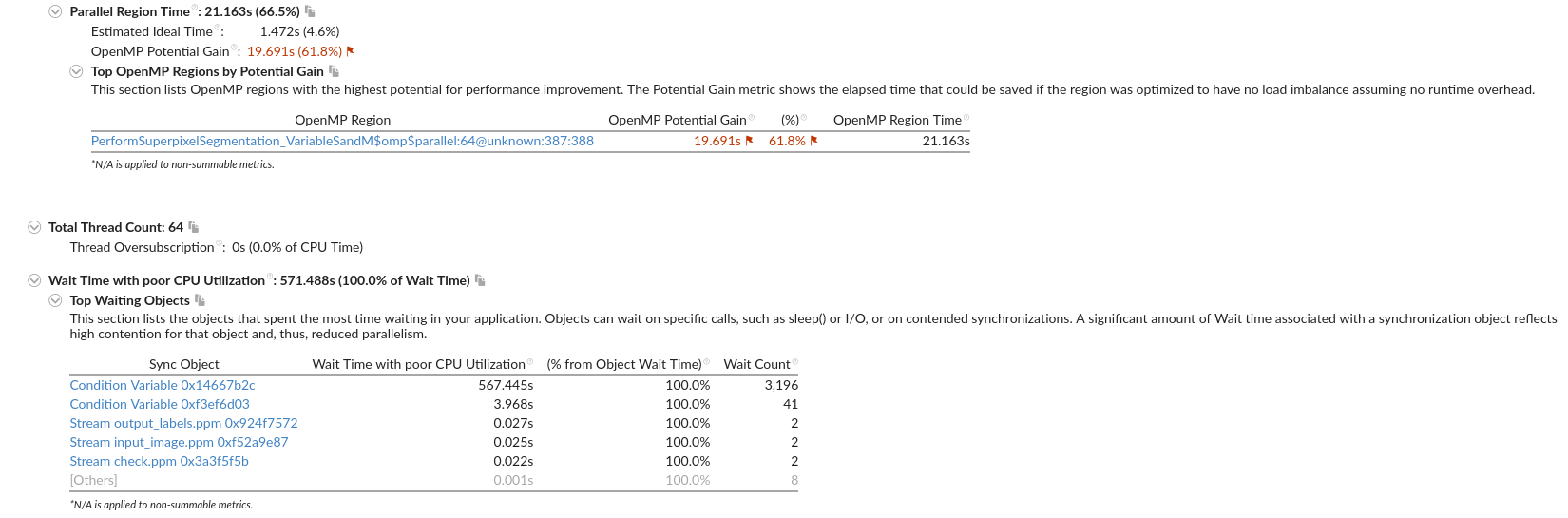
暂无
暂无
无
1 | # 华为ARM |
root用户需要加–allow-run-as-root

1 | % mpirun -x DISPLAY -x OFILE=/tmp/out ... |
设置 MCA(Modular Component Architecture ) 参数
-mca 开关允许将参数传递给各种 MCA(模块化组件架构)模块。 MCA 模块对 MPI 程序有直接影响,因为它们允许在运行时设置可调参数(例如使用哪个 BTL 通信设备驱动程序,向该 BTL 传递什么参数等)。
-mca 开关接受两个参数:<key> 和 <value>。 <key> 参数通常指定哪个 MCA 模块将接收该值。例如,<key> “btl” 用于选择用于传输 MPI 消息的 BTL。 <value> 参数是传递的值。
1 | mpirun -mca btl tcp,self -np 1 foo |
告诉 Open MPI 使用“tcp”和“self”BTL,并运行一个已分配的“foo”节点。
可以多次使用以指定不同的 <key> 和/或 <value> 参数。如果多次指定相同的 <key>,则 <value> 将用逗号 (“,”) 连接起来,将它们分隔开。
未知的<key>值不会报warning
OMPI_MCA_<key>=<value>
-tune, –tune <tune_file>
-mca选项会覆盖环境变量,也会覆盖默认文件
$OPAL_PREFIX/etc/openmpi/openmpi-mca-params.conf
或者$OPAL_PREFIX/etc/openmpi-mca-params.conf
或者$HOME/.openmpi/mca-params.conf
https://stackoverflow.com/questions/36635061/how-to-check-which-mca-parameters-are-used-in-openmpi
set mpi_show_mca_params to all
ompi_info - 显示有关 Open MPI 安装的信息
三种常见场景:
比如不清楚 –mca btl vader,可以运行 ompi_info –param btl vader –level 9
MPI point-to-point byte transfer layer, used for MPI
BTL 组件框架负责处理所有点对点消息传送,该层只是简单地移动字节序列,不考虑上层点对点通信协议,包含了一组用于发送/接收或RDMA 的通信组件单元。BTL 不受 MPI 语义的影响,它仅仅是通过最基本的传递功能来在进程间进行数据交换(包括连续的和非连续的数据)。这样的组件框架为网络设备的开发商提供了便利,同时也可以支持更广泛的结点间通信设备。
btl 参数的值是一个由逗号分隔的组件列表,带有可选的前缀 ^(插入符号)来表示排除之后的组件。
1 | % mpirun --mca framework comp1, comp2 ^comp3 # ^comp3前注意没有,号 |
在此示例中,组件 comp1 和 comp2 包含在 –mca 框架指定的框架中。组件 comp3 被排除在外,因为它前面有 ^(插入符号)符号。
1 | % mpirun --mca framework ^comp3,comp1 |
因为,号的原因是一个整体,所以是排除comp3,comp1两项
例如,以下命令从 BTL 框架中排除 tcp 和 openib 组件,并隐式包含所有其他组件
1 | % mpirun --mca btl ^tcp,openib ... # ...是rest的意思 |
在命令中使用插入符号后跟省略号表示“对其余组件执行相反的操作”。 当 mpirun –mca 命令指定要排除的组件时,省略号后面的插入符号隐式包含该框架中的其余组件。 当 mpirun –mca 命令专门包含组件时,后面跟有省略号的表示“并排除未指定的组件”。
例如,以下命令仅包含 btl 的 self、sm 和 gm 组件,并隐式排除其余部分:
1 | % mpirun --mca btl self,sm,gm ... |

MPI point-to-point management layer
PML 组件框架负责管理所有消息的传递,实现了 MPI 点点通信原语,包括标准、缓冲、准备和同步四种通信模式。PML 根据具体的调度策略对 MPI 消息进行调度,该策略是根据 BTL 的具体属性决定的。短消息传递协议和长消息传递协议也是在 PML 中实现的。所有控制信息(ACK/NACK/MATCH)也都由 PML 进行管理。这种结构的优点是将传输协议从底层互连中分离出来,显著的降低了代码的复杂度和冗余度,增强了可维护性。


不使用btl??
暂无
https://docs.oracle.com/cd/E19923-01/820-6793-10/mca-params.html
https://www.open-mpi.org/faq/?category=openfabrics
http://blog.sysu.tech/MPI/OpenMPI/OpenMPI%E5%B8%B8%E7%94%A8%E6%8A%80%E5%B7%A7/
http://blog.sysu.tech/MPI/OpenMPI/OpenMPI%E5%B8%B8%E7%94%A8%E6%8A%80%E5%B7%A7/
IPCC Preliminary SLIC Analysis part4 : cluster environment
id
1 | [sca3173@ln121%bscc-a5 ~]$ id sca3173 |
cpu
1 | Intel(R) Xeon(R) Silver 4208 CPU @ 2.10GHz |
slurm
1 | ON AVAIL TIMELIMIT NODES STATE NODELIST |
memery
1 | [sca3173@ln121%bscc-a5 ~]$ cat /proc/meminfo |
architecture
1 | [sca3173@ln121%bscc-a5 public1]$ lsb_release -d | awk -F"\t" '{print $2}' |
GPU 集显
1 | [sca3173@ln121%bscc-a5 public1]$ lshw -numeric -C display |
disk
1 | [sca3173@ln121%bscc-a5 public1]$ df -h /public1 |
IP 内网IP
1 | [sca3173@ln121%bscc-a5 public1]$ hostname -I | awk '{print $1}' |
1 | > cat lscpu.txt |

没有gcc/7.3.0
比赛是2节点128核的环境
我们是A5 分区。
没有找到手册,只有一个官网图。但是虽然频率是2.35GHz,但是内存只有251GB啊,什么情况。

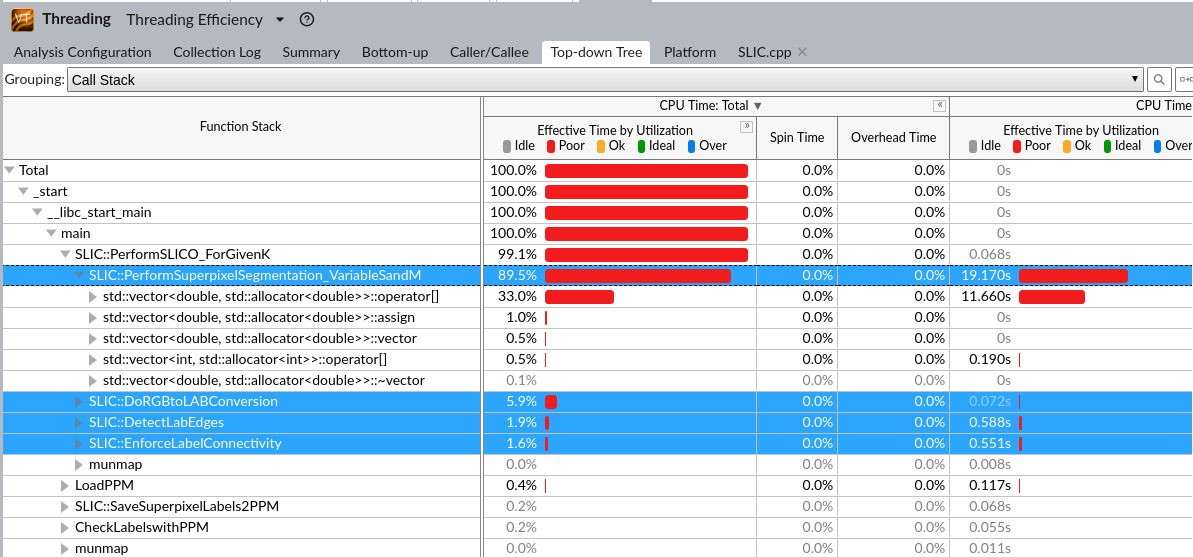
IPCC Preliminary SLIC Analysis part3 : Hot spot analysis






1 | g++ -pg -g -std=c++11 SLIC.cpp -o SLIC |


没什么用
根据具体资源情况来,貌似是一个节点,那可以从OpenMP入手
Intel编译器的自动并行化功能可以自动的将串行程序的一部分转换为线程化代码。进行自动向量化主要包括的步骤有,找到有良好的工作共享(worksharing)的候选循环;对循环进行数据流(dataflow)分析,确认并行执行可以得到正确结果;使用OpenMP指令生成线程化代码。
/Qparallel:允许编译器进行自动并行化
/Qpar-reportn:n为0、1、2、3,输出自动并行化的报告
说明:/Qparallel必须在使用O2/3选项下有效
所谓的向量化,简单理解,就是使用高级的向量化SIMD指令(如SSE、SSE2等)优化程序,属于数据并行的范畴。
向量化的目标是生成SIMD指令,那么很显然,要对代码进行向量化,
第一是依靠编译器来生成这些指令;
第二是使用汇编或Intrinsics函数。
Intel编译器中,利用其自动向量分析器(auto-vectorizer)对代码进行分析并生成SIMD指令。另外,也会提供一些pragmas等方式使得用户能更好的处理代码来帮助编译器进行向量化。
基本向量化
/Qvec:开启自动向量化功能,需要在O2以上使用。在O2以上,这是默认的向量化选项,默认开启的。此选项生成的代码能用于Intel处理器和非Intel处理器。向量化还可能受其他选项影响。由于此选项是默认开启的,所以不需要在命令行增加此选项。
针对指令集(处理器)的向量化
/QxHost:针对当前使用的主机处理器选择最优的指令集优化。
对于双重循环,外层循环被自动并行化了,而内层循环并没有被自动并行化,内层循环被会自动向量化。
看汇编代码
没成功需要手动内联向量化汇编代码???
暂无
暂无
https://blog.csdn.net/gengshenghong/article/details/7027186