Wireguard Server 2 Server in OpenWRT
Read more
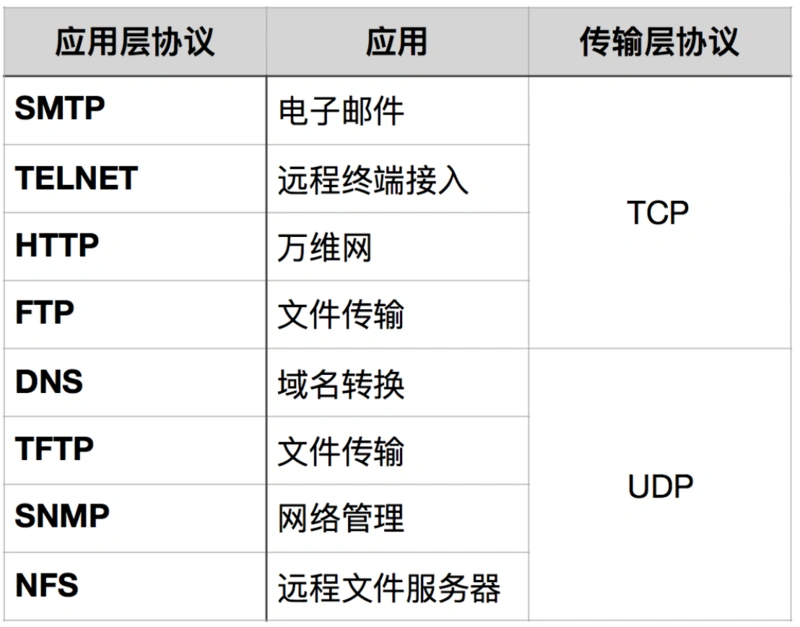
对比如下:
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 是否有序 | 无序 | 有序,消息在传输过程中可能会乱序,TCP 会重新排序 |
| 传输速度 | 快 | 慢 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
总结:
TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
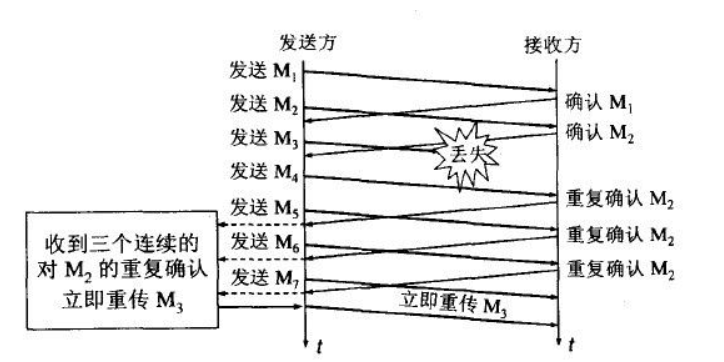
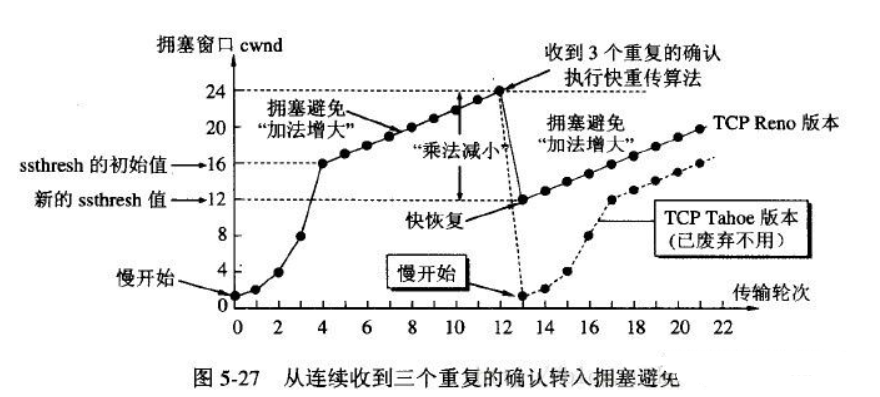
TCP主要提供了检验和、序列号/确认应答、超时重传、滑动窗口、拥塞控制和 流量控制等方法实现了可靠性传输。
TCP 一共使用了四种算法来实现拥塞控制:
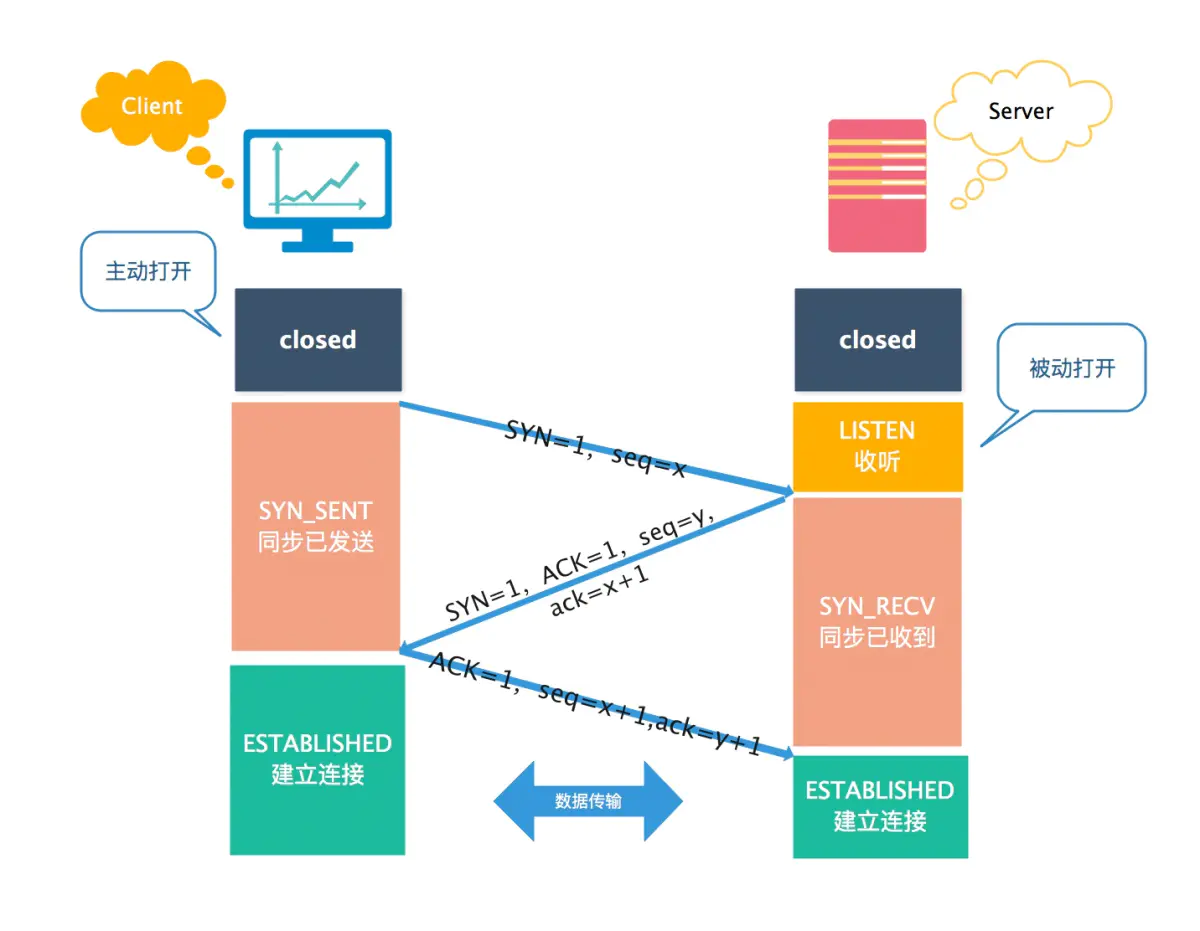
三次握手机制:
seq = x 作为初始序列号,ack = x + 1,同时选择一个随机数 seq = y 作为初始序列号,ack = y + 1,序列号为 seq = x + 1,理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
主要有三个原因:
防止已过期的连接请求报文突然又传送到服务器,因而产生错误和资源浪费。
在双方两次握手即可建立连接的情况下,假设客户端发送 A 报文段请求建立连接,由于网络原因造成 A 暂时无法到达服务器,服务器接收不到请求报文段就不会返回确认报文段。
客户端在长时间得不到应答的情况下重新发送请求报文段 B,这次 B 顺利到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,客户端在收到 确认报文后也进入 ESTABLISHED 状态,双方建立连接并传输数据,之后正常断开连接。
此时姗姗来迟的 A 报文段才到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,但是已经进入 CLOSED 状态的客户端无法再接受确认报文段,更无法进入 ESTABLISHED 状态,这将导致服务器长时间单方面等待,造成资源浪费。
三次握手才能让双方均确认自己和对方的发送和接收能力都正常。
第一次握手:客户端只是发送处请求报文段,什么都无法确认,而服务器可以确认自己的接收能力和对方的发送能力正常;
第二次握手:客户端可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
第三次握手:服务器可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
可见三次握手才能让双方都确认自己和对方的发送和接收能力全部正常,这样就可以愉快地进行通信了。
告知对方自己的初始序号值,并确认收到对方的初始序号值。
TCP 实现了可靠的数据传输,原因之一就是 TCP 报文段中维护了序号字段和确认序号字段,通过这两个字段双方都可以知道在自己发出的数据中,哪些是已经被对方确认接收的。这两个字段的值会在初始序号值得基础递增,如果是两次握手,只有发起方的初始序号可以得到确认,而另一方的初始序号则得不到确认。
因为三次握手已经可以确认双方的发送接收能力正常,双方都知道彼此已经准备好,而且也可以完成对双方初始序号值得确认,也就无需再第四次握手了。
SYN洪泛攻击属于 DOS 攻击的一种,它利用 TCP 协议缺陷,通过发送大量的半连接请求,耗费 CPU 和内存资源。
原理:
[SYN/ACK] 包(第二个包)之后、收到客户端的 [ACK] 包(第三个包)之前的 TCP 连接称为半连接(half-open connect),SYN_RECV(等待客户端响应)状态。如果接收到客户端的 [ACK],则 TCP 连接成功,[SYN] 包,服务器回复 [SYN/ACK] 包,并等待客户的确认。由于源地址是不存在的,服务器需要不断的重发直至超时。[SYN] 包将长时间占用未连接队列,影响了正常的 SYN,导致目标系统运行缓慢、网络堵塞甚至系统瘫痪。检测:当在服务器上看到大量的半连接状态时,特别是源 IP 地址是随机的,基本上可以断定这是一次 SYN 攻击。
防范:
服务端:
客户端:
客户端认为这个连接已经建立,如果客户端向服务端发送数据,服务端将以RST包(Reset,标示复位,用于异常的关闭连接)响应。此时,客户端知道第三次握手失败。
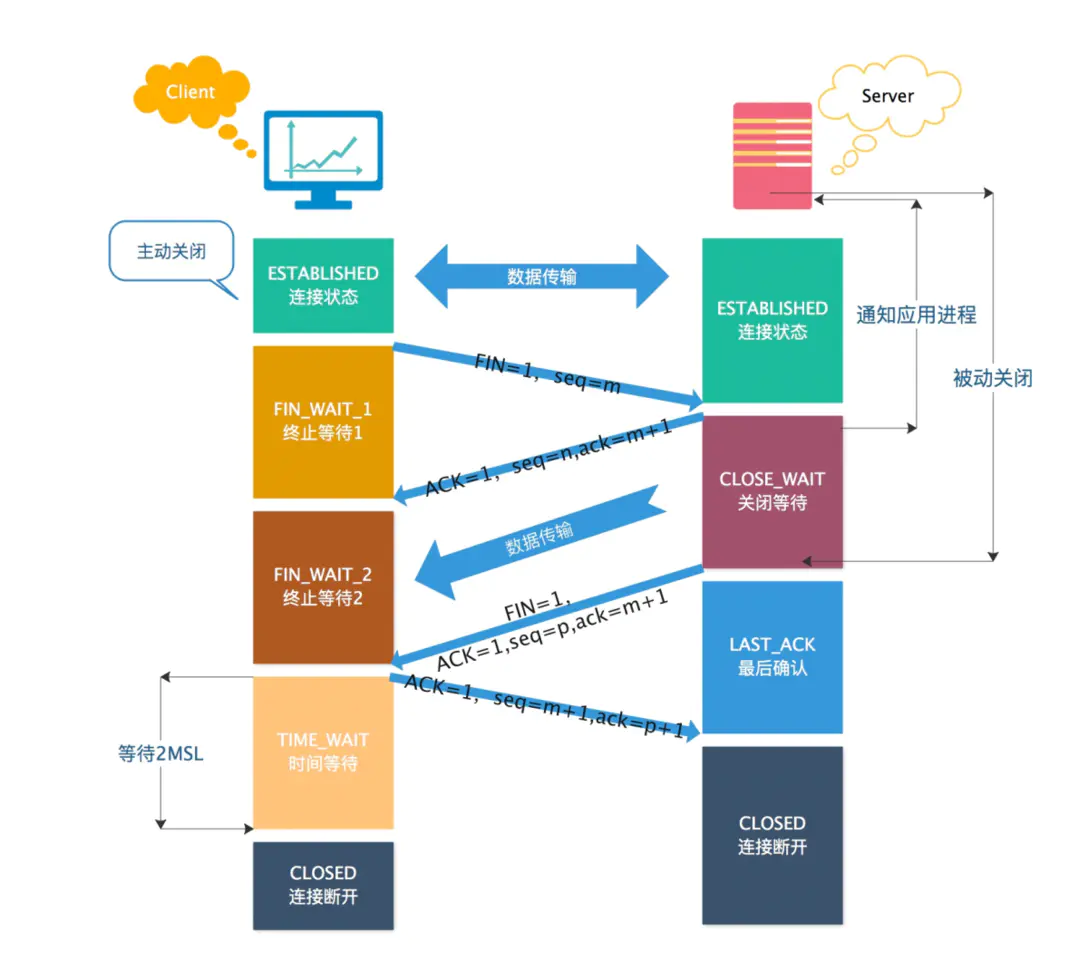
第一次挥手:客户端向服务端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待服务端的确认。
第二次挥手:服务端收到连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = k,确认号 ack = u + 1。
这时 TCP 连接处于半关闭状态,即客户端到服务端的连接已经释放了,但是服务端到客户端的连接还未释放。这表示客户端已经没有数据发送了,但是服务端可能还要给客户端发送数据。
第三次挥手:服务端向客户端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待 A 的确认。
第四次挥手:客户端收到服务端的连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = u + 1,确认号为 ack = w + 1。
此时,客户端就进入了 TIME-WAIT 状态。注意此时客户端到 TCP 连接还没有释放,必须经过 2*MSL(最长报文段寿命)的时间后,才进入 CLOSED 状态。而服务端只要收到客户端发出的确认,就立即进入 CLOSED 状态。可以看到,服务端结束 TCP 连接的时间要比客户端早一些。
服务器在收到客户端的 FIN 报文段后,可能还有一些数据要传输,所以不能马上关闭连接,但是会做出应答,返回 ACK 报文段.
接下来可能会继续发送数据,在数据发送完后,服务器会向客户单发送 FIN 报文,表示数据已经发送完毕,请求关闭连接。服务器的ACK和FIN一般都会分开发送,从而导致多了一次,因此一共需要四次挥手。
主要有两个原因:
确保 ACK 报文能够到达服务端,从而使服务端正常关闭连接。
第四次挥手时,客户端第四次挥手的 ACK 报文不一定会到达服务端。服务端会超时重传 FIN/ACK 报文,此时如果客户端已经断开了连接,那么就无法响应服务端的二次请求,这样服务端迟迟收不到 FIN/ACK 报文的确认,就无法正常断开连接。
MSL 是报文段在网络上存活的最长时间。客户端等待 2MSL 时间,即「客户端 ACK 报文 1MSL 超时 + 服务端 FIN 报文 1MSL 传输」,就能够收到服务端重传的 FIN/ACK 报文,然后客户端重传一次 ACK 报文,并重新启动 2MSL 计时器。如此保证服务端能够正常关闭。
如果服务端重发的 FIN 没有成功地在 2MSL 时间里传给客户端,服务端则会继续超时重试直到断开连接。
防止已失效的连接请求报文段出现在之后的连接中。
TCP 要求在 2MSL 内不使用相同的序列号。客户端在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以保证本连接持续的时间内产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。或者即使收到这些过时的报文,也可以不处理它。
或者说,如果三次握手阶段、四次挥手阶段的包丢失了怎么办?如“服务端重发 FIN丢失”的问题。
简而言之,通过定时器 + 超时重试机制,尝试获取确认,直到最后会自动断开连接。
具体而言,TCP 设有一个保活计时器。服务器每收到一次客户端的数据,都会重新复位这个计时器,时间通常是设置为 2 小时。若 2 小时还没有收到客户端的任何数据,服务器就开始重试:每隔 75 分钟发送一个探测报文段,若一连发送 10 个探测报文后客户端依然没有回应,那么服务器就认为连接已经断开了。
从服务器来讲,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,严重消耗着服务器的资源,此时部分客户端就会显示连接不上。
从客户端来讲,客户端TIME_WAIT过多,就会导致端口资源被占用,因为端口就65536个,被占满就会导致无法创建新的连接。
解决办法:
服务器可以设置 SO_REUSEADDR 套接字选项来避免 TIME_WAIT状态,此套接字选项告诉内核,即使此端口正忙(处于
TIME_WAIT状态),也请继续并重用它。
调整系统内核参数,修改/etc/sysctl.conf文件,即修改net.ipv4.tcp_tw_reuse 和 tcp_timestamps
1 | net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; |
强制关闭,发送 RST 包越过TIME_WAIT状态,直接进入CLOSED状态。
TIME_WAIT 是主动断开连接的一方会进入的状态,一般情况下,都是客户端所处的状态;服务器端一般设置不主动关闭连接。
TIME_WAIT 需要等待 2MSL,在大量短连接的情况下,TIME_WAIT会太多,这也会消耗很多系统资源。对于服务器来说,在 HTTP 协议里指定 KeepAlive(浏览器重用一个 TCP 连接来处理多个 HTTP 请求),由浏览器来主动断开连接,可以一定程度上减少服务器的这个问题。
现在有一个数据部分长度为8192B的数据需要通过UDP在以太网上传播,经过分片化为多个IP数据报片,这些片中的数据部分长度都有哪些?(假设按照最大长度分片), 计网习题
暂无
暂无
vpn:英文全称是“Virtual Private Network”,翻译过来就是“虚拟专用网络”。vpn通常拿来做2个事情:
一句话,vpn在IP层工作,而ss在TCP层工作。

理解 VPN 路由(以及任何网络路由)配置的关键是认识到一个 IP packet 如何被传输,以下描述的是极度简化后的单向传输过程:
为什么机器 A 的本地路由表里会有 172.29.1.0/24 这个网段的路由规则?通常情况下,这是 OpenVPN 服务端推送给客户端,由客户端在建立 VPN 连接时自动添加的。也可以由服务端自定义,比如wireguard
这个时候,如果机器 B 想要回复 A(比如发个 ACK),就会出问题,因为 packet 的来源地址还是 10.8.0.123, 而 10.8.0.0/24 网段并不属于当前局域网,是 VPN 服务端私有的——机器 B 往 10.8.0.123 发送的 ACK 会在某个位置(比如默认网关)遇到 “host unreachable” 而被丢弃。对于机器 A 来说,表面现象可能是连接超时或 ping 不通。
解决方法是,在 packet 离开 VPN 服务端时,将其「伪装」成来自 172.29.0.3(举例VPN 服务端的局域网地址),这样机器 B 发送的 ACK 就能顺利回到 VPN 服务端,然后发给机器 A. 这就是所谓的 SNAT。
在 Linux 系统中由 iptables 来管理,具体命令是:
1 | iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE. |
连接 OpenVPN 的两个 client 之间可以互相通信,这是因为服务端推送的路由里包含了对应的网段。但是想从 Client A 到达 Client B 所在局域网的其他机器,还需要额外的配置。因为 OpenVPN 服务端缺少 Client B 局域网相关的路由规则。
1 | server.conf |
在前两节所给的配置基础上,只需要再加一点配置,就能实现 OpenVPN 服务端所在局域网与客户端所在局域网的互访。配置内容是,在各自局域网的默认网关上添加路由,将对方局域网网段的下一跳设为 OpenVPN 服务端 / 客户端所在机器,同时用 iptables 配置相应的 SNAT 规则。
Based on the info in clashio, we select some cheap vpns to try.
| name | 每月价格(¥/GB/off on holiday) | 每月单价(GB/¥) | 每年单价(GB/¥) | 节点数与稳定性 | 使用速度感觉 |
|---|---|---|---|---|---|
| fastlink 2019 | 20/100/-30% | 5 | 100+, 节点速度高达5Gbps | 峰值 5Gbps (1) | |
| totoro 2023 | 15/100/-20%(2) | 6.6 | ??? | ??? | |
| 冲浪猫 2022 | 16/200/-12%(3) | 12.5 | ??? | 峰值 1Gbps | |
| 奈云机场 2021 | 10.6/168/-30%(4) | 15.8 | 230624购买,240109几天全面掉线 | 峰值 5Gbps (6) | |
| FatCat 2023 | 6/60/-20% | 10 | ??? | 峰值 xx Gbps |
!!! question annotate “My Choice: 单价,大小,速度,优惠码有效期”
1. 优惠码(春节 中秋 双十一)
1. [fastlink](https://v02.fl-aff.com/auth/register?code=rotu) 用了两年了,还是x3很快的。但是相当于一个月只有30GB, 不够用。
3. [奈云机场](https://www.naiun2.top/#/register?code=gL7mHyh9)(可靠性暂时不行),[冲浪猫](https://b.msclm.net/#/register?code=AAUF1Efg) 平衡比较好。
现在组合:奈云机场(2) + fastlink。 等fastlink过期了(1),看要不要转成 冲浪猫。
&flag=clash下载config.yamlbrook vpn+ Amazon American node
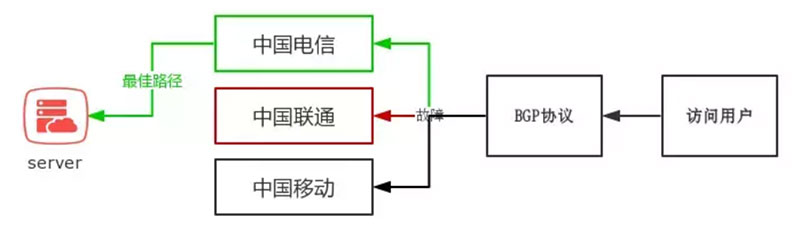
[^1]: BGP 漫谈
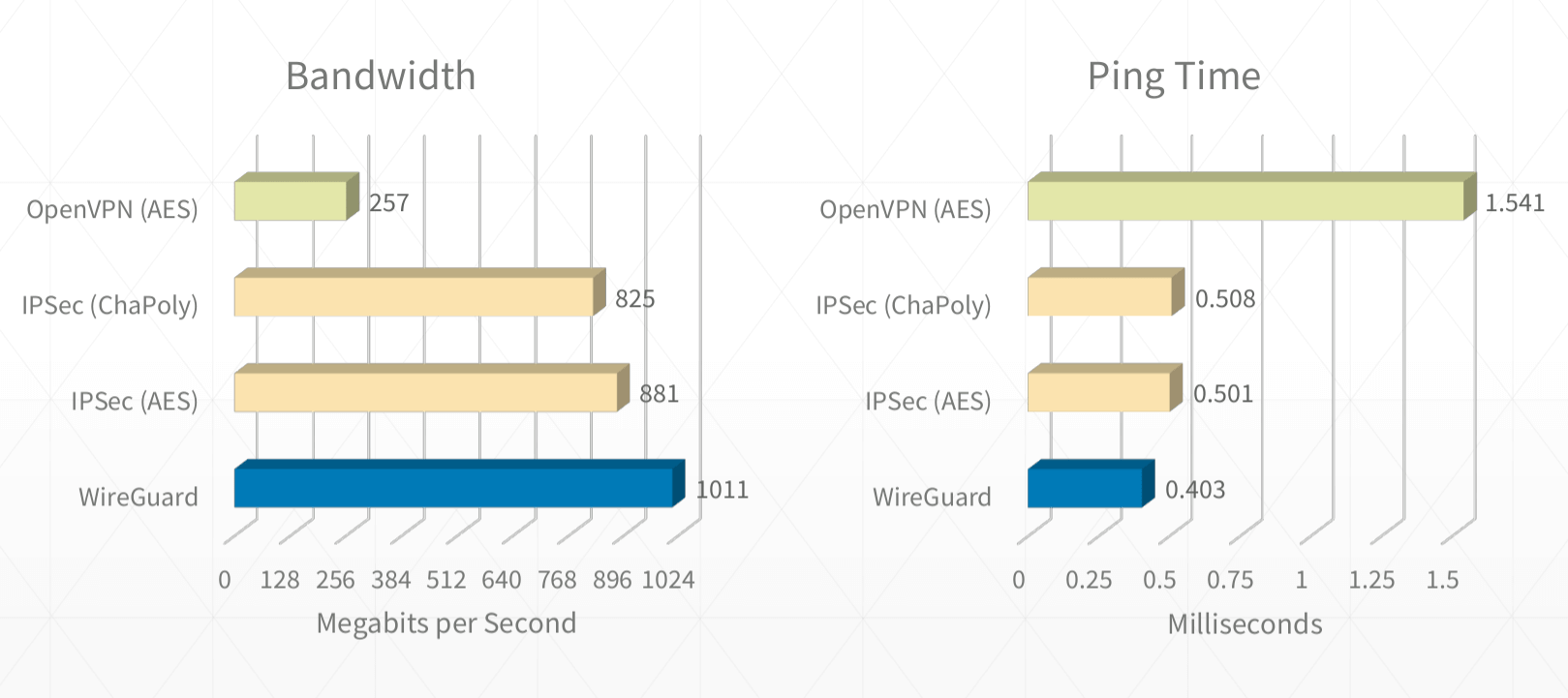
> nc -z -v -u 4.shaojiemike.top 51822,wg是udpAllowedIPs = 192.168.31.0/24,10.0.233.1/24.然后ping 192.168.31.1测试配置详解参考中文文档
[peer]里设定字段 PersistentKeepalive = 25,表示每隔 25 秒发送一次 ping 来检查连接。虽然AllowedIPs = 0.0.0.0/0与AllowedIPs = 0.0.0.0/1, 128.0.0.0/1包含的都是全部的ip。
但是前者在iptable里为default dev wg1,后者为两条0.0.0.0/1 dev wg1和128.0.0.0/1 dev wg1。
由于路由的ip匹配遵循最长前缀匹配规则,如果路由表里原本有一条efault dev eth0。使用前者会导致混乱。但是使用后者,由于两条的优先级会更高,会屏蔽掉原本的default规则。
前者的iptable修改如下:(macbook上)
1 | > ip route |
后者的iptable修改如下
1 | > ip route |
建议看WireGuard 教程:WireGuard 的工作原理 和WireGuard 基础教程:wg-quick 路由策略解读,详细解释了wg是如何修改路由表规则的。
默认会产生51840的路由table,ip rule优先级较高。可以通过配置文件中添加PostUp来修改最后一个default的路由规则。
1 | root@snode6:/etc/wireguard# cat wg0.conf |
PostUp会产生下面的规则
1 | root@snode6:/staff/shaojiemike# ip ro show table default |
OpenVPN原理通过在main添加all规则来实现
1 | # shaojiemike @ node5 in ~ [22:29:05] |
Macbook上的应用上的ClashX Pro的增强模式类似, 会添加如下配置,将基本所有流量代理(除开0.0.0.0/8)
1 | > ip route |
明显有代理死循环问题,如何解决???
1 | shaojiemike@shaojiemikedeMacBook-Air ~/github/hugoMinos (main*) [10:59:32] |
wireguard-go: 安装客户端 wg-quick up config
wireguard-tools: 安装服务端 wg
wg-quick up wg1wg-quick down wg1wg显示全部,或者wg show wg1显示wg11 | systemctl enable wg-quick@wg1 --now |
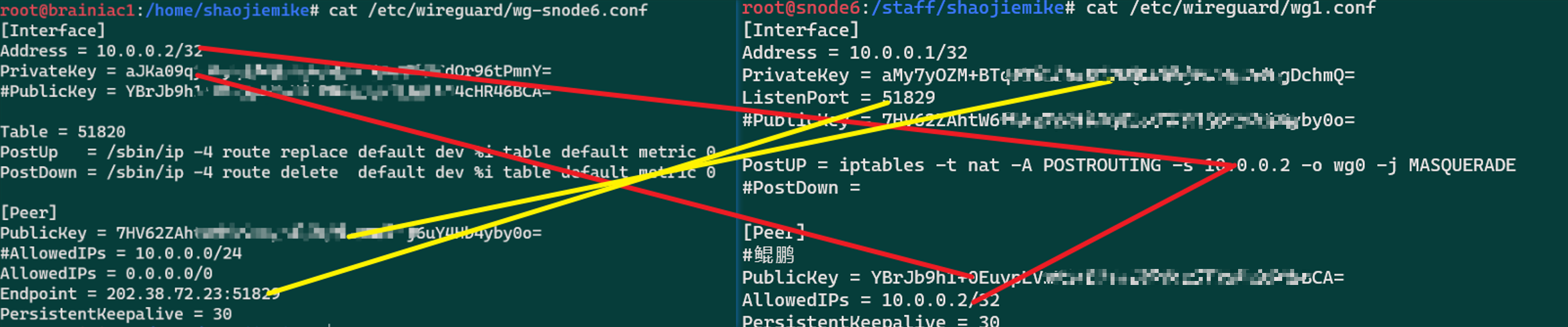
fd00::aaaa:5/128、1 | brainiac1# cat wg-tsj.conf |
修改sysctl.conf文件的net.ipv4.ip_forward参数。其值为0,说明禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
需要执行指令sysctl -p 后新的配置才会生效。
注意中间需要NAT转换, 相当于把kunpeng机器的请求,隐藏成snode6的请求。在后一次wireguard转发时,就不会被过滤掉。
1 | PostUp = iptables -t nat -A POSTROUTING -s 10.1.0.0/24 ! -o %i -j MASQUERADE |
由于换了wg服务端,导致nas变成闭环的网络了。最后是通过群晖助手(Synology Assistant / Web Assistant)的设置静态ip才连接上机器,但是iptable被设置乱了。
静态连接上机器,首先在网页管理页面切换成DHCP(静态ip的DNS解析有误),iptable变成如下
1 | sh-4.4# ip ro |
注意iptable的修改是实时生效的。
为了让nas上网我们需要满足两点
1 | # 重要项如下 |
使用wg1配置如下:
1 | sh-4.4# cat /etc/wireguard/wg1.conf |
要保留没有wg的时候访问服务端的eth0(114.214.233.xxx)的通路
1 | sh-4.4# ip ro s t main |
目的:需要ssh和ping ipv4成功
修改netplan的配置文件
1 | # shaojiemike @ node5 in ~ [22:29:11] |
routing-policy会产生
1 | # shaojiemike @ node5 in ~ [22:30:33] |
由于2优先级高,使得ping和ssh的返回信包(源地址为自身机器IP的包)走table1 规则,而不是走
routes使得所有的table1都会走学校的路由器(202.38.73.254)
1 | $ ip route show table 1 |
开启wg后,网络请求源地址变成了10.0.33.2。不是202.38.73.217
1 | root@node5:/home/shaojiemike# ip ro |
但是外界ping的是202.38.73.217。返回包交换所以会产生源地址为202.38.73.217的包
暂无
暂无
WireGuard 基础教程:使用 Phantun 将 WireGuard 的 UDP 流量伪装成 TCP
/etc/hosts文件即可修改环回的地址。但是十分不建议这样做,很可能导致本地服务崩溃ssh -L 1313:localhost:8020 [email protected]将服务器localhost:1313上的内容转发到本地8020端口hugo server -D -d ~/test/public默认会部署在localhost上hugo server --bind=202.38.72.23 --baseURL=http://202.38.72.23:1313 -D -d ~/test/public暂无
暂无
Z:\shaojiemike\Documents\文献\计算机网络目录下。这里先使用fjw的脚本。register.py,获得私钥和分配的ip1 | [Interface] |
main.sh修改包的3个字节。apt-get install nftables/etc/default/warp-helper文件填写对应的wg-conf里Endpoint。比如: ROUTING_ID=11,45,14
UPSTREAM=[2606:4700:d0::a29f:c001]:500
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2. 最后开启路由表,Root权限运行` ip route add default dev warp proto static scope link table default`
## WARP on OpenWRT
* 目的:为了防止大量流量通过WARP,导致被官方封禁,所以只在OpenWRT上配置WARP分流github的流量。
* 实现思路:
* 运行python脚本,通过github的API获得所有的github域名ip,
* 使用iptables的warp_out表,将目的地址为github域名ip路由到WARP的虚拟网卡上。
### WARP Wireguard Establishment
```bash
python register.py #自动生成warp-op.conf,warp.conf和warp-helper
mv warp-helper /etc/default
# cat main.sh
# cat warp-op.conf
vim /etc/config/network #填写warp-op.conf内容,默认只转发172.16.0.0/24来测试连接
ifup warp #启动warp, 代替wg-quick up warp.conf
bash main.sh #启动防火墙实现报文头关键三字节修改
nft list ruleset #查看防火墙,是否配置成功
wg #查看warp状态,测试是否连接成果
这时还没创建warp_out路由表,所以还不能通过WARP出数据。
1 | #/etc/config/network |
然后WebUI点击apply 或者命令行运行ifconfig warp down && ifup
添加了WARP的网络出口后,路由器不在只是通过WAN出数据。防火墙需要更新: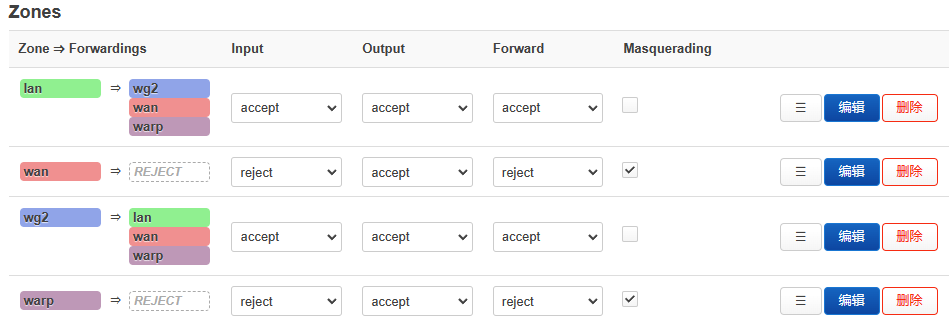
wget --bind-address=WARP_ip来模拟10: from all lookup main suppress_prefixlength 11000: from all lookup warp_out,优先级10001 | root@tsjOp:~/warp# ip rule |
1 | cd ip_route |
对所有github域名的ip执行类似ip ro add 192.30.252.0/22 dev warp proto static table warp_out操作。
1 | mtr www.github.com |
修改/etc/rc.local
1 | # Put your custom commands here that should be executed once |
基于1.1.1.1 的安装windows版本直接白嫖
暂无
暂无
https://gist.github.com/iBug/3107fd4d5af6a4ea7bcea4a8090dcc7e
glados