导言
Split address translation (virtual-to-physical mapping) part to individual post
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
#include语句以及一些宏插入程序文本中,得到main.i和sum.i文件。main.i和sum.i编译成文本文件main.s和sum.c的汇编语言程序。main.s和sum.s翻译成机器语言的二进制指令,并打包成一种叫做可重定位目标程序的格式,并将结果保存在main.o和sum.o两个文件中。这种文件格式就比较接近elf格式了。main.o和sum.o,得到可执行目标文件,就是elf格式文件。
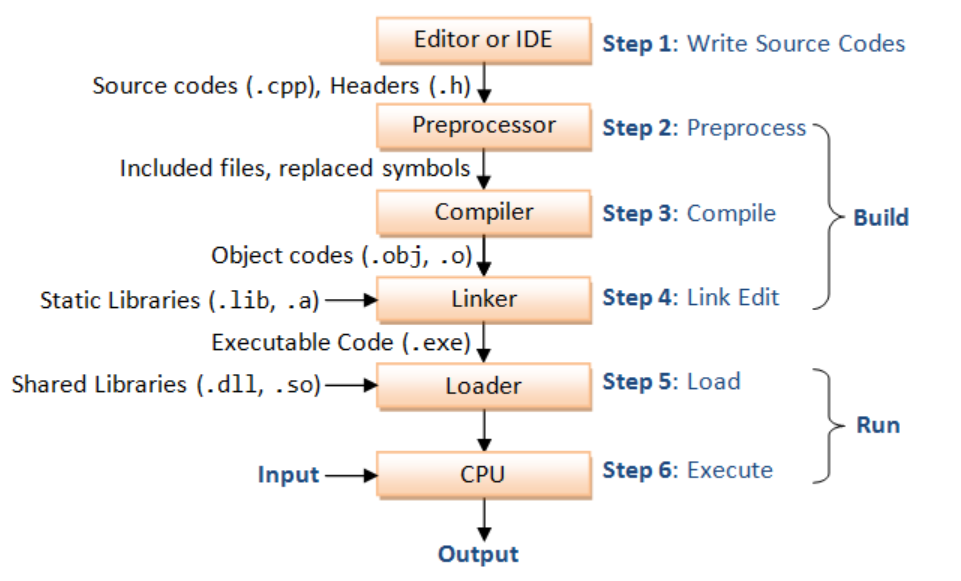
目标文件有三种形式:
.c 文件转化成 .i文件.gcc –E filename.cpp -o filename.i-E Preprocess only; do not compile, assemble or link.-C能保留头文件里的注释,如gcc -E -C circle.c -o circle.cgcc -save-temps -c -o main.o main.ccpp filename.cpp -o filename.i命令linemarkers类似# linenum filename flags的注释,这些注释是为了让编译器能够定位到源文件的行号,以便于编译器能够在编译错误时给出正确的行号。flags meaning除开注释被替换成空格,包括代码里的预处理命令:
#error "text" 的作用是在编译时生成一个错误消息,它会导致编译过程中断。 同理有#warning#define a b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。#ifdef SNIPER,#if defined SNIPER && SNIPER == 0,#ifndef,#else,#elif,#endif等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉-DSNIPER=5#include "FileName"或者#include 等。LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。#include "" vs #include <> 区别在于前者会在文件的当前目录寻找,但是后者只会在编译器编译的official路径寻找
通常的搜索顺序是:
包含指定源文件的目录(对于在 #include 命令中以引号包括的文件名)。
采用-iquote选项指定的目录,依照出现在命令行中的顺序进行搜索。只对 #include 命令中采用引号的头文件名进行搜索。
所有header file的搜寻会从-I开始, 依照出现在命令行中的顺序进行搜索。(可以使用-I/path/file只添加一个头文件,尤其是在编译的兼容性修改时)
采用环境变量 CPATH 指定的目录。
采用-isystem选项指定的目录,依照出现在命令行中的顺序进行搜索。
然后找环境变量 C_INCLUDE_PATH,CPLUS_INCLUDE_PATH,OBJC_INCLUDE_PATH指定的路径
再找系统默认目录(/usr/include、/usr/local/include、/usr/lib/gcc-lib/i386-linux/2.95.2/include......)
通过如下命令可以查看头文件搜索目录 gcc -xc -E -v - < /dev/null 或者 g++ -xc++ -E -v - < /dev/null*. 如果想改,需要重新编译gcc
或者在编译出错时,g++ -H -v查看是不是项目下的同名头文件优先级高于sys-head-file
.c/.h或者.i文件转换成.s文件,gcc –S filename.cpp -o filename.s,对应于-S Compile only; do not assemble or link.gcc –S filename.i -o filename.s 也是可行的。但是我遇到头文件冲突的问题error: declaration for parameter ‘__u_char’ but no such parametercc –S filename.cpp -o filename.s cc1命令-O3)如果想把 C 语言变量的名称作为汇编语言语句中的注释,可以加上 -fverbose-asm 选项:
1 | gcc -S -O3 -fverbose-asm ../src/pivot.c -o pivot_O1.s |
请阅读 GNU assembly file一文
汇编器:将.s 文件转化成 .o文件,
gcc –c,-c Compile and assemble, but do not link.as;
objdump -Sd ../build/bin/pivot > pivot1.s-S 以汇编代码的形式显示C++原程序代码,如果有debug信息,会显示源代码。nm file.o 查看目标文件中的符号表注意,这时候的目标文件里的使用的函数可能没定义,需要链接其他目标文件.a .so .o .dll(Dynamic Link Library的缩写,Windows动态链接库)
List symbol names in object files.
/lib,/usr/lib,/lib64(在64位系统上),/usr/lib64(在64位系统上)遍历 LD_LIBRARY_PATH 中的每个目录,并查找包括软链接在内的所有 .so 文件。
1 | IFS=':' dirs="$LD_LIBRARY_PATH" |
ldconfig 命令用于配置动态链接器的运行时绑定。你可以使用它来查询系统上已知的库文件的位置()。
ldconfig 会扫描
/lib 和 /usr/lib,以及 /etc/ld.so.conf 中列出的目录),查找共享库文件(.so 文件),/etc/ld.so.cache。这个缓存文件会被动态链接器(ld.so 或 ld-linux.so)使用,以加快共享库的查找速度。1 | # 查看所有是path 的库 |
ldd会显示动态库的链接关系,中间的nm为U没关系,只需要最终.so对应符号是T即可。ldd 时避免对不可信的可执行文件运行,因为它可能会执行恶意代码。readelf -d 或 objdump -p 来查看库依赖。通过使用ld命令,将编译好的目标文件连接成一个可执行文件或动态库。
Foo::bar(int,long)会变成bar__3Fooil。其中3是名字字符数见 Linux Executable file: Structure & Running
undefined reference to一旦链接器完成了符号解析这一步,就把代码中的每个符号引用和正好一个符号定义(即它的一个输入目标模块中的一个符号表条目)关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
.data 节被全部合并成一个节,这个节成为输出的可执行目标文件的.data 节。当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。
代码的重定位条目放在 .rel.text 中。已初始化数据的重定位条目放在 .rel.data 中。
下面 展示了 ELF 重定位条目的格式。
R_X86_64_PC32。重定位一个使用 32 位 PC 相对地址的引用。回想一下 3.6.3 节,一个 PC 相对地址就是距程序计数器(PC)的当前运行时值的偏移量。当 CPU 执行一条使用 PC 相对寻址的指令时,它就将在指令中编码的 32 位值加上 PC 的当前运行时值,得到有效地址(如 call 指令的目标),PC 值通常是下一条指令在内存中的地址。(将 PC 压入栈中来使用)R_X86_64_32。重定位一个使用 32 位绝对地址的引用。通过绝对寻址,CPU 直接使用在指令中编码的 32 位值作为有效地址,不需要进一步修改。1 | typedef struct { |
链接器通常从左到右解析依赖项,这意味着如果库 A 依赖于库 B,那么库 B 应该在库 A 之前被链接。
静态库static library就是将相关的目标模块打包形成的单独的文件。使用ar命令。
静态库的优点在于:
问题:
深入理解计算机系统P477,静态库例子
1 | gcc -static -o prog2c main2.o -L. -lvector |
图 7-8 概括了链接器的行为。-static 参数告诉编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到内存并运行,在加载时无须更进一步的链接。-lvector 参数是 libvector.a 的缩写,-L. 参数告诉链接器在当前目录下查找 libvector.a。

共享库是以两种不同的方式来“共享”的:

如上创建了一个可执行目标文件 prog2l,而此文件的形式使得它在运行时可以和 libvector.so 链接。基本的思路是:
dlopen() interface.情况:在应用程序被加载后执行前时,动态链接器加载和链接共享库的情景。
核心思想:由动态链接器接管,加载管理和关闭共享库(比如,如果没有其他共享库还在使用这个共享库,dlclose函数就卸载该共享库。)。
.interp 节,这一节包含动态链接器的路径名,动态链接器本身就是一个共享目标(如在 Linux 系统上的 ld-linux.so). 加载器不会像它通常所做地那样将控制传递给应用,而是加载和运行这个动态链接器。然后,动态链接器通过执行下面的重定位完成链接任务:最后,动态链接器将控制传递给应用程序。从这个时刻开始,共享库的位置就固定了,并且在程序执行的过程中都不会改变。
情况:应用程序在运行时要求动态链接器加载和链接某个共享库,而无需在编译时将那些库链接到应用。
实际应用情况:
思路是将每个生成动态内容的函数打包在共享库中。
编译器yasm的参数-DPIE
如果同一份代码可能被加载到进程空间的任意虚拟地址上执行(如共享库和动态加载代码),那么就需要使用-fPIC生成位置无关代码。
问题:多个进程是如何共享程序的一个副本的呢?
问题。
可以加载而无需重定位的代码称为位置无关代码(Position-Independent Code,PIC)
在一个 x86-64 系统中,对同一个目标模块中符号的引用是不需要特殊处理使之成为 PIC。可以用 PC 相对寻址来编译这些引用,构造目标文件时由静态链接器重定位。
然而,对共享模块定义的外部过程和对全局变量的引用需要一些特殊的技巧,接下来我们会谈到。
解决方法:延迟绑定(lazy binding),将过程地址的绑定推迟到第一次调用该过程时。
动机:使用延迟绑定的动机是对于一个像 libc.so 这样的共享库输出的成百上千个函数中,一个典型的应用程序只会使用其中很少的一部分。把函数地址的解析推迟到它实际被调用的地方,能避免动态链接器在加载时进行成百上千个其实并不需要的重定位。
结果:第一次调用过程的运行时开销很大,但是其后的每次调用都只会花费一条指令和一个间接的内存引用。
实现:延迟绑定是通过两个数据结构之间简洁但又有些复杂的交互来实现的,这两个数据结构是:GOT 和过程链接表(Procedure Linkage Table,PLT)。如果一个目标模块调用定义在共享库中的任何函数,那么它就有自己的 GOT 和 PLT。GOT 是数据段的一部分,而 PLT 是代码段的一部分。
首先,让我们介绍这两个表的内容。
PLT[0] 是一个特殊条目,它跳转到动态链接器中。PLT[1](图中未显示)调用系统启动函数(__libc_start_main),它初始化执行环境,调用 main 函数并处理其返回值从 PLT[2] 开始的条目调用用户代码调用的函数。在我们的例子中,PLT[2] 调用 addvec,PLT[3](图中未显示)调用 printf。
上图a 展示了 GOT 和 PLT 如何协同工作,在 addvec 被第一次调用时,延迟解析它的运行时地址:
上图b 给出的是后续再调用 addvec 时的控制流:
静态库
动态库
1 | shaojiemike@snode6 /lib/modules/5.4.0-107-generic/build [06:32:26] |
加载器:将可执行程序加载到内存并进行执行,loader和ld-linux.so。
将可执行文件加载运行
| 命令 | 描述 |
|---|---|
| ar | 创建静态库,插入、删除、列出和提取成员; |
| stringd | 列出目标文件中所有可以打印的字符串; |
| strip | 从目标文件中删除符号表信息; |
| nm | 列出目标文件符号表中定义的符号; |
| size | 列出目标文件中节的名字和大小; |
| readelf | 显示一个目标文件的完整结构,包括ELF 头中编码的所有信息。 |
| objdump | 显示目标文件的所有信息,最有用的功能是反汇编.text节中的二进制指令。 |
| ldd | 列出可执行文件在运行时需要的共享库。 |
ltrace 跟踪进程调用库函数过程
strace 系统调用的追踪或信号产生的情况
Relyze 图形化收费试用
-g选项,可以生成调试信息,这样在gdb中可以查看源代码。1 | objdump -g <archive_file>.a |
gcc -E -g testBigExe.cpp -o testDebug.i相对于无-g的命令,只会多一行信息# 1 "/staff/shaojiemike/test/OS//"gcc -S -g testBigExe.cpp -o testDebug.s,对比之前的汇编文件,由72行变成9760行。具体解析参考 GNU assembly file一文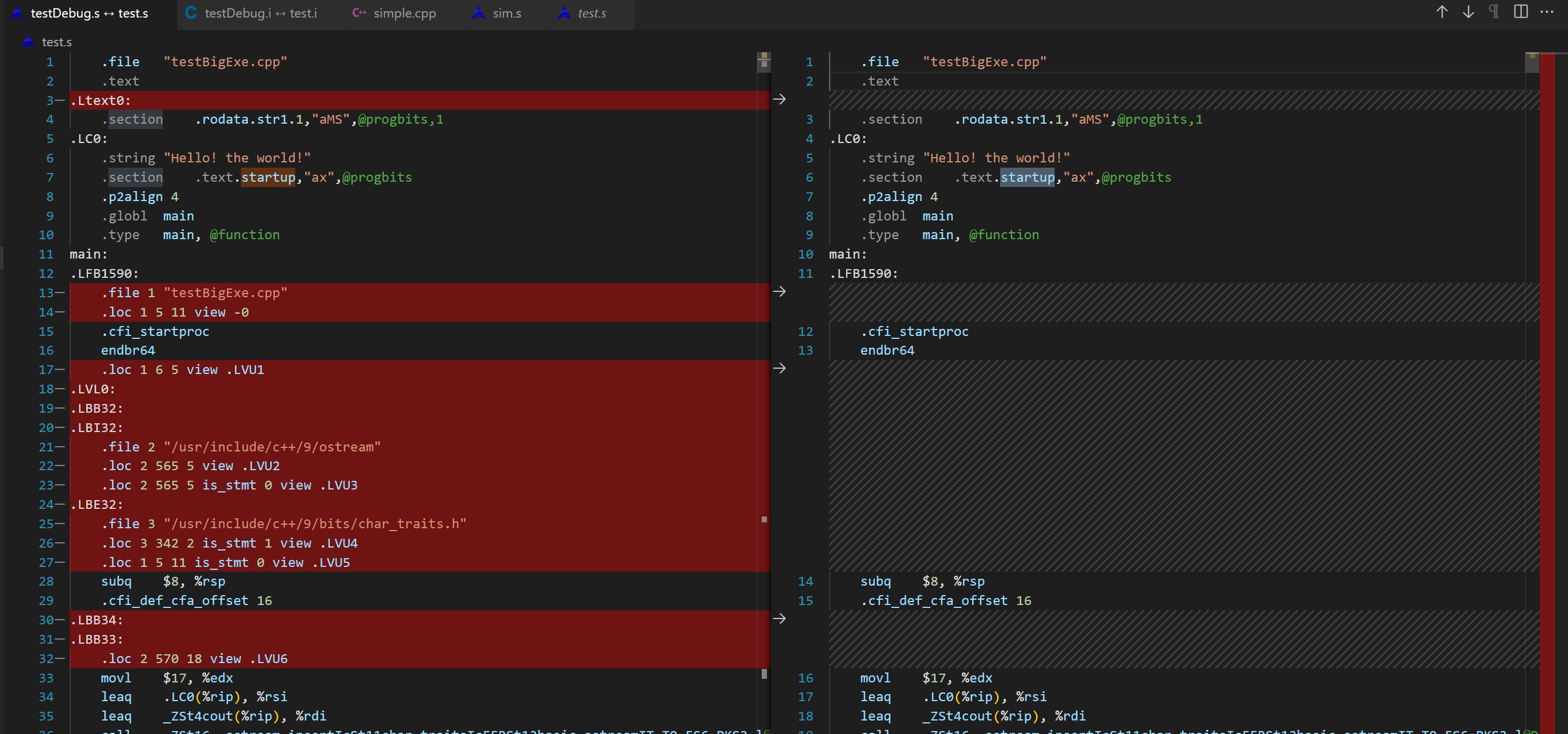
简单的#pragma omp for,编译后多出汇编代码如下。当前可以创建多少个线程默认汇编并没有显示的汇编指令。
1 | call omp_get_num_threads@PLT |
某些atomic的导语会变成对应汇编
暂无
基础不牢,地动山摇。ya 了。
https://www.cnblogs.com/LiuYanYGZ/p/5574601.html
https://hansimov.gitbook.io/csapp/part2/ch07-linking/7.5-symbols-and-symbol-tables
Linux Executable file: Structure & Running 2
要运行可执行目标文件 prog,我们可以在 Linux shell 的命令行中输入它的名字:linux> ./prog
因为 prog 不是一个内置的 shell 命令,所以 shell 会认为 prog 是一个可执行目标文件。
执行完上述操作后,其实可执行文件的真正指令和数据都没有别装入内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚拟内存之间的映射关系而已。

除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到 CPU 引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存。
比如,现在程序的入口地址为 0x08048000 ,刚好是代码段的起始地址。当CPU打算执行这个地址的指令时,发现页面 0x8048000 ~ 0x08049000 (一个页面一般是4K)是个空页面,于是它就认为是个页错误。此时操作系统根据虚拟地址空间与可执行文件间的映射关系找到页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,并在虚拟地址页面与物理页面间建立映射,最后把EXE文件中页面拷贝到内存的物理页面,进程重新开始执行。该过程如下图所示:
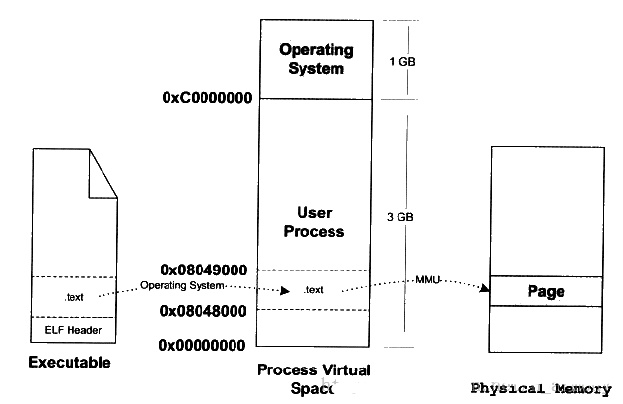
接下来,加载器跳转到程序的入口点,也就是 _start函数的地址。这个函数是在系统目标文件 ctrl.o 中定义的,对所有的 C 程序都是一样的。_start 函数调用系统启动函数 __libc_start_main,该函数定义在 libc.so 中。它初始化执行环境,调用用户层的 main 函数,处理 main 函数的返回值,并且在需要的时候把控制返回给内核。
1 | # shaojiemike @ snode6 in ~/github/sniper_PIMProf/PIMProf/gapbs on git:dev o [15:15:29] |
是一种用于管理计算机内存的算法,旨在有效地分配和释放内存块,以防止碎片化并提高内存的使用效率。这种算法通常用于操作系统中,以管理系统内核和进程的内存分配。
Buddy 内存分配算法的基本思想是将物理内存划分为大小相等的块,每个块大小都是 2 的幂次方。每个块可以分配给一个正在运行的进程或内核。当内存被分配出去后,它可以被分割成更小的块,或者合并成更大的块,以适应不同大小的内存需求。
算法的名称 “Buddy” 来自于分配的块之间的关系,其中一个块被称为 “buddy”,它是另一个块的大小相等的邻居。这种关系使得在释放内存时,可以尝试将相邻的空闲块合并成更大的块,从而减少内存碎片。
Buddy 内存分配算法的工作流程大致如下:
初始时,整个可用内存被视为一个大块,大小是 2 的幂次方。
当一个进程请求内存分配时,算法会搜索可用的块,找到大小合适的块来满足请求。如果找到的块比所需的稍大,它可以被分割成两个相等大小的 “buddy” 块,其中一个分配给请求的进程。
当一个进程释放内存时,该块会与其 “buddy” 块合并,形成一个更大的块。然后,这个更大的块可以与其它相邻的块继续合并,直到达到较大的块。
Buddy 内存分配算法在一些操作系统中用于管理内核和进程的物理内存,尤其在嵌入式系统和实时操作系统中,以提高内存使用效率和避免碎片化问题。
是一个用于教育目的的微内核操作系统
我们可window写程序占满16G内存
但是linux,用了3GB就会seg fault
猜想是不是有单进程内存限制 https://www.imooc.com/wenda/detail/570992
而且malloc alloc的空间在堆区,我们可以明显的发现这个空间是被栈区包住的,有限的。windows是如何解决这个问题的呢?
动态数据区一般就是“堆栈”。“栈 (stack)”和“堆(heap)”是两种不同的动态数据区,栈是一种线性结构,堆是一种链式结构。进程的每个线程都有私有的“栈”,所以每个线程虽然 代码一样,但本地变量的数据都是互不干扰。一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,本地变量分配在动态数 据区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量。
当进程初始化时,系统会自动为进程创建一个默认堆,这个堆默认所占内存的大小为1M。堆对象由系统进行管理,它在内存中以链式结构存在。
1 | /etc/security/limits.conf |
文件描述符
文件句柄数
这些限制一般不会限制内存。
调用malloc(size_t size)函数分配内存成功,总会分配size字节VM(再次强调不是RAM),并返回一个指向刚才所分配内存区域的开端地址。分配的内存会为进程一直保留着,直到你显示地调用free()释放它(当然,整个进程结束,静态和动态分配的内存都会被系统回收)。
GNU libc库提供了二个内存分配函数,分别是malloc()和calloc()。glibc函数malloc()总是通过brk()或mmap()系统调用来满足内存分配需求。函数malloc(),根据不同大小内存要求来选择brk(),还是mmap(),阈值 MMAP_THRESHOLD=128Kbytes是临界值。小块内存(<=128kbytes),会调用brk(),它将数据段的最高地址往更高处推(堆从底部向上增长)。大块内存,则使用mmap()进行匿名映射(设置标志MAP_ANONYMOUS)来分配内存,与堆无关,在堆之外。
malloc不是直接分配内存的,是第一次访问的时候才分配的?
https://www.zhihu.com/question/20836462
暂无
暂无
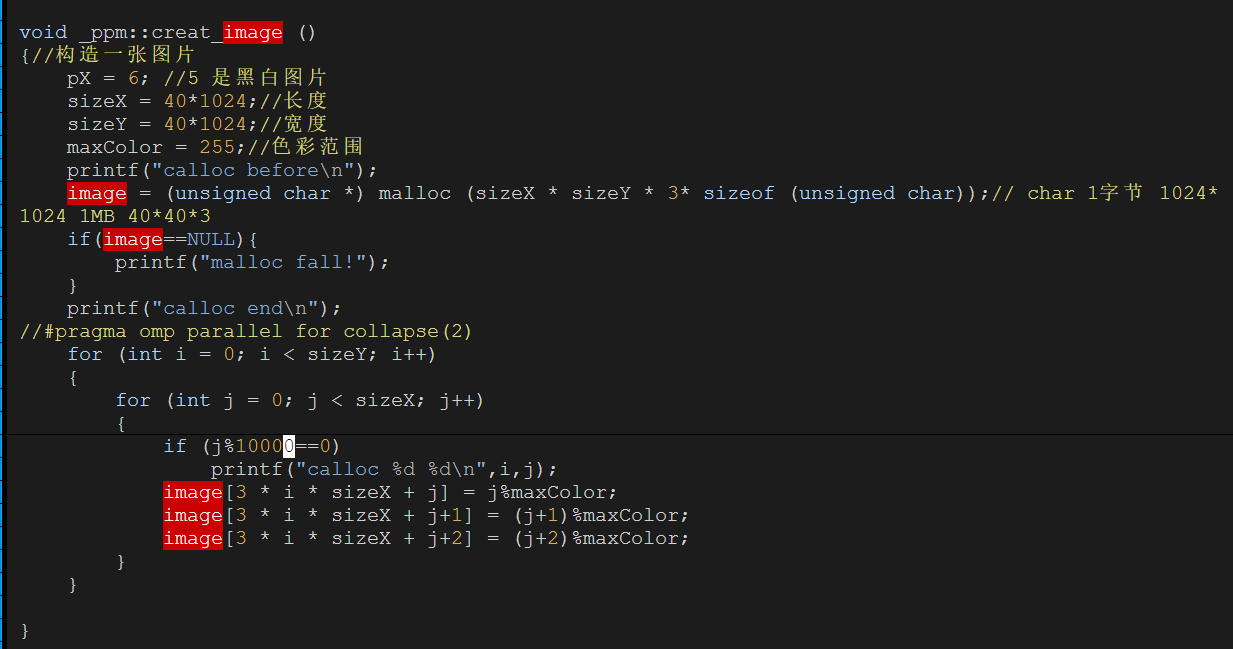
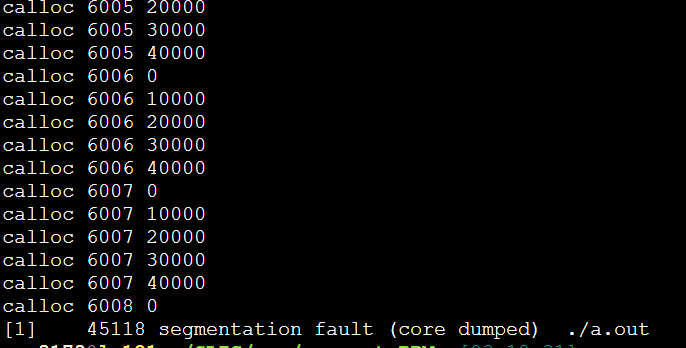
每次都是6008这里,40000*6008*3/1024/1024=687MB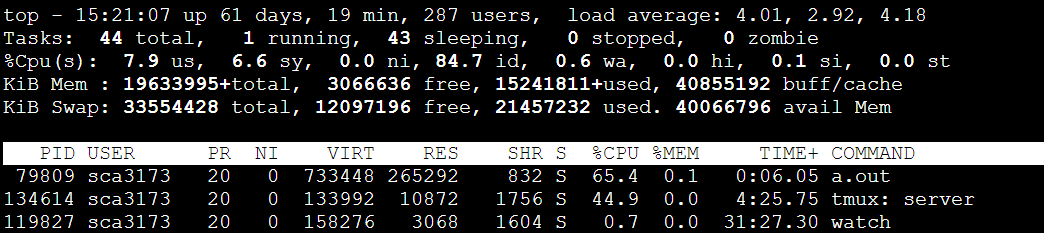
733448/1024=716MB
问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)
Linux Executable file: Structure & Running

可执行目标文件的格式类似于可重定位目标文件的格式。
.text、.rodata 和 .data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。.init 节定义了一个小函数,叫做 _init,程序的初始化代码会调用它。.rel 节。7.4 可重定位目标文件一节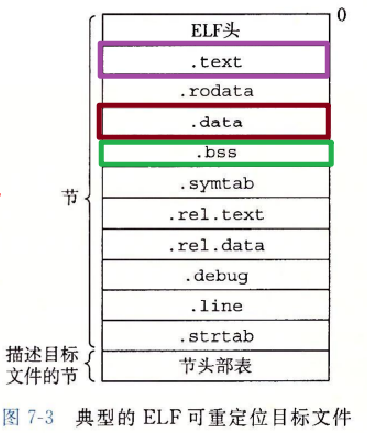
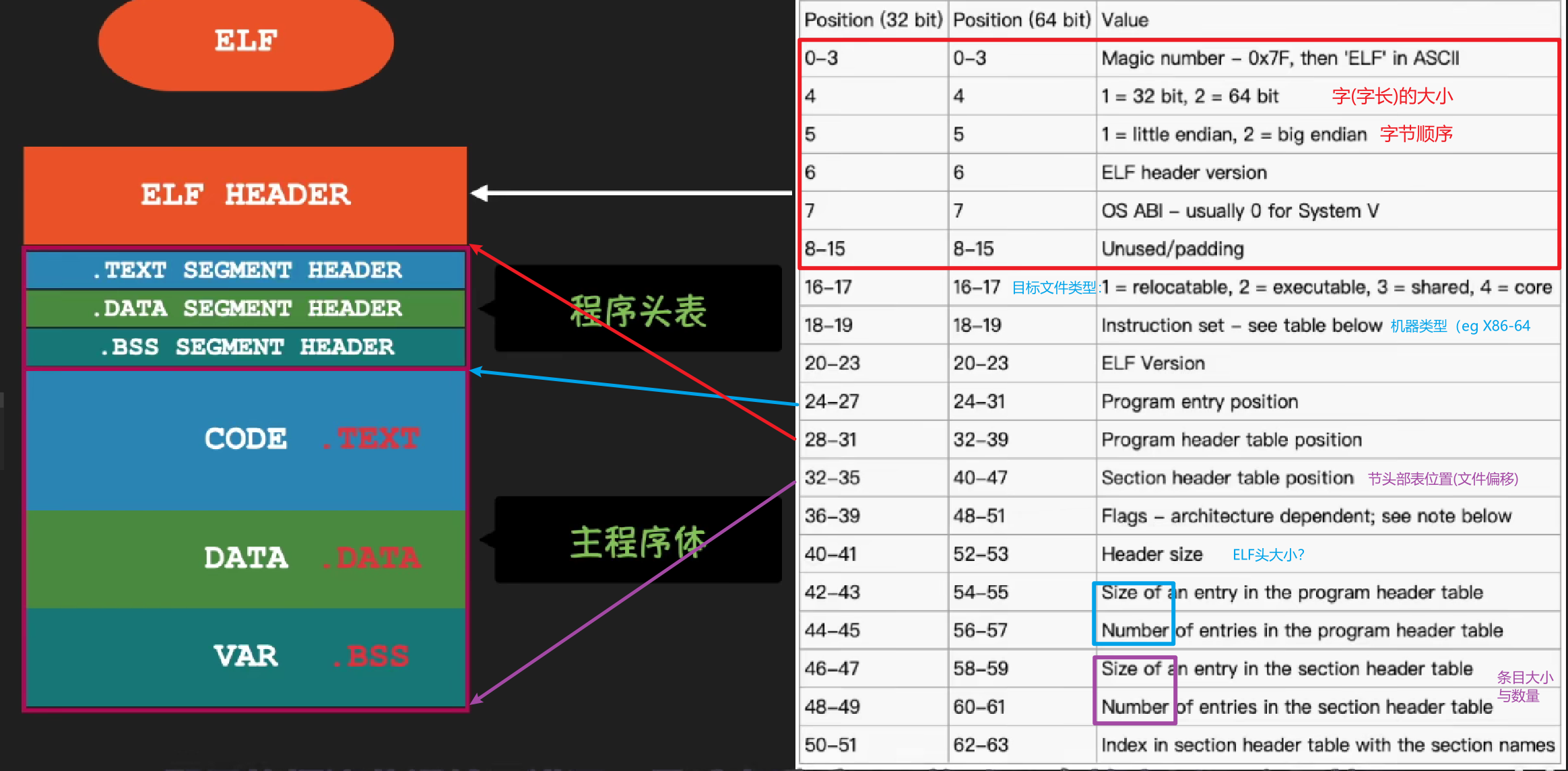
夹在 ELF 头和节头部表之间的都是节。一个典型的 ELF 可重定位目标文件包含下面几个节:
.data 节中,也不岀现在 .bss 节中。.bss 来表示未初始化的数据是很普遍的。它起始于 IBM 704 汇编语言(大约在 1957 年)中“块存储开始(Block Storage Start)”指令的首字母缩写,并沿用至今。.data 和 .bss 节的简单方法是把 “bss” 看成是“更好地节省空间(Better Save Space)” 的缩写。.symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。.symtab 符号表不包含局部变量的条目。-g 选项调用编译器驱动程序时,才会得到这张表。.text 节中机器指令之间的映射。-g 选项调用编译器驱动程序时,才会得到这张表。.symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。每个可重定位目标模块 m 都有一个符号表**.symtab**,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
(出)由模块 m 定义并能被其他模块引用的全局符号。
(入)由其他模块定义并被模块 m 引用的全局符号。
只被模块 m 定义和引用的局部符号。
本地链接器符号和本地程序变量的不同是很重要的。
.symtab 中的符号表不包含对应于本地非静态程序变量的任何符号。有趣的是,定义为带有 C static 属性的本地过程变量是不在栈中管理的。
使用命令readelf -s simple.o 可以读取符号表的内容。
示例程序的可重定位目标文件 main.o 的符号表中的最后三个条目。

开始的 8 个条目没有显示出来,它们是链接器内部使用的局部符号。
全局符号 main 定义的条目,
其后跟随着的是全局符号 array 的定义
外部符号 sum 的引用。
type 通常要么是数据,要么是函数。
binding 字段表示符号是本地的还是全局的。
Ndx=1 表示 .text 节

1 | # read ELF header |
小结:开辟局部变量、全局变量、malloc空间会影响可执行文件大小吗?对应汇编如何?存放的位置?运行时如何?
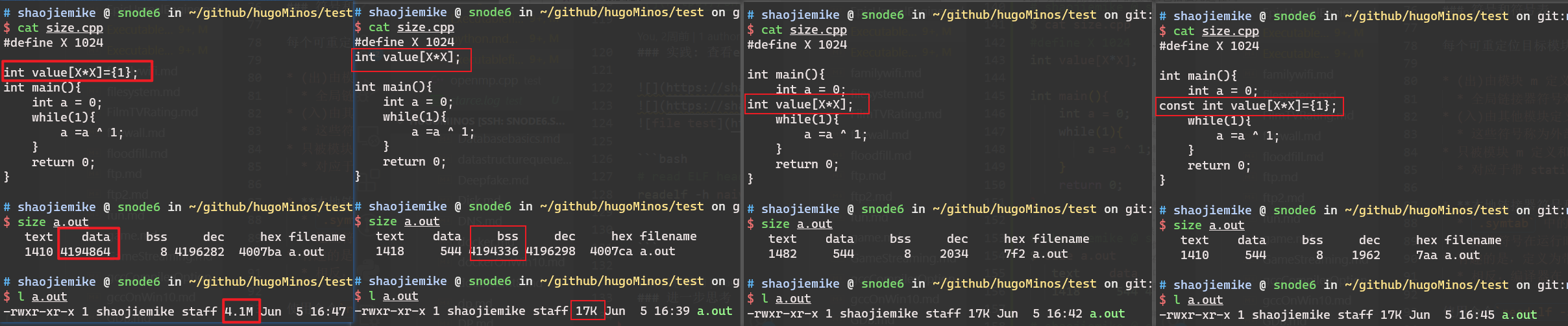
将exe各节内容可视化解释(虽然现在是二进制)
编译的时候,头文件是怎么处理的?
data 与 bbs在存储时怎么区分全局与静态变量
请给出 .rel.text .rel.data的实例分析
线程和进程都可以用多核,但是线程共享进程内存(比如,openmp)
超线程注意也是为了提高核心的利用率,当有些轻量级的任务时(读写任务)核心占用很少,可以利用超线程把一个物理核心当作多个逻辑核心,一般是两个,来使用更多线程。AMD曾经尝试过4个。

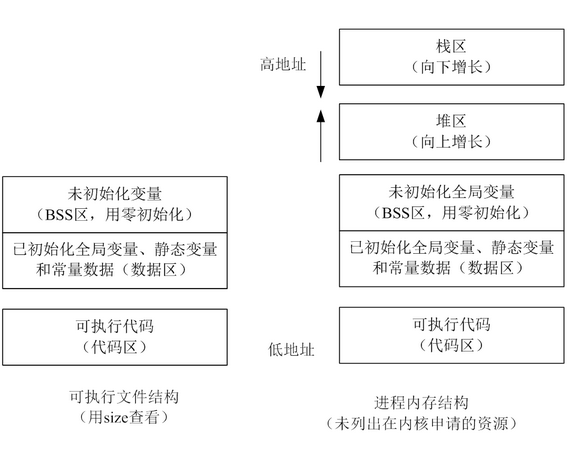
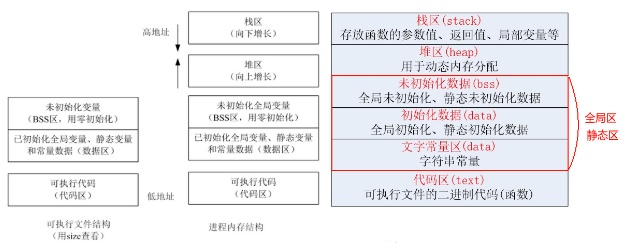
正在运行的程序,叫进程。每个进程都有完全属于自己的,独立的,不被干扰的内存空间。此空间,被分成几个段(Segment),分别是Text, Data, BSS, Heap, Stack。
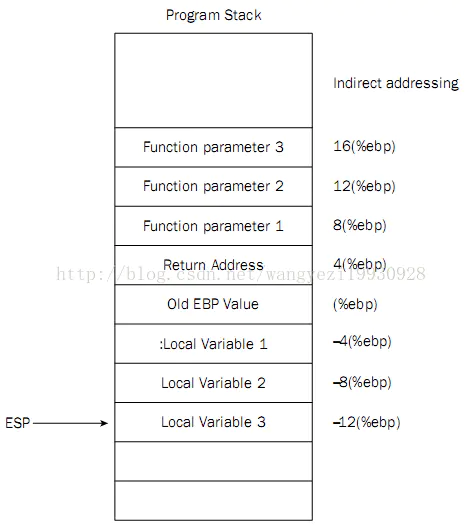
push pop %ebp 涉及到编译器调用函数的处理方式 application binary interface (ABI).EAX 寄存器中返回,浮点值在 ST0 x87 寄存器中返回。寄存器 EAX、ECX 和 EDX 由调用方保存,其余寄存器由被叫方保存。x87 浮点寄存器 调用新函数时,ST0 到 ST7 必须为空(弹出或释放),退出函数时ST1 到 ST7 必须为空。ST0 在未用于返回值时也必须为空。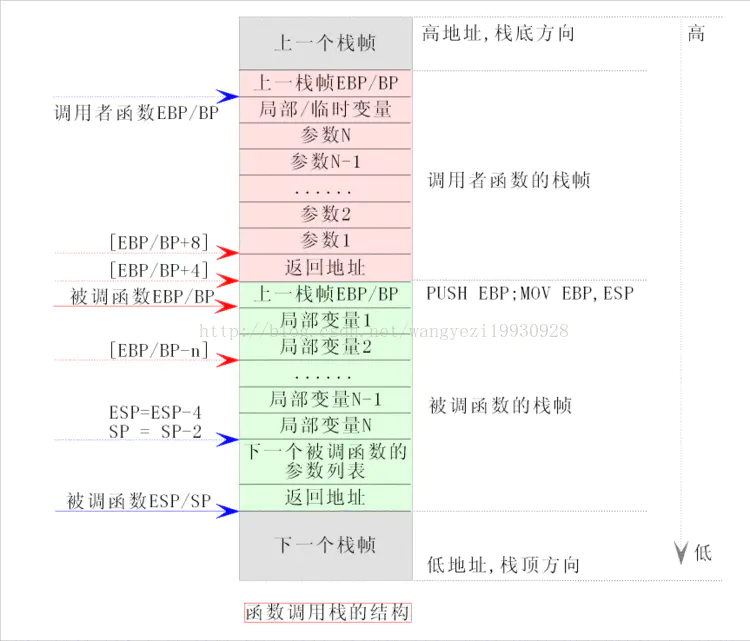
1 | 0000822c <func>: |
arm PC = x86 EIP
ARM 为什么这么设计,就是为了返回地址不存栈,而是存在寄存器里。但是面对嵌套的时候,还是需要压栈。
由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
WIndow系统一般是2MB。Linux可以查看ulimit -s ,通常是8M
栈空间最好保持在cache里,太大会存入内存。持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。
函数参数传递一般通过寄存器,太多了就存入栈内。
栈区(stack segment):由编译器自动分配释放,存放函数的参数的值,局部变量的值等。
局部变量空间是很小的,我们开一个a[1000000]就会导致栈溢出;而全局变量空间在Win 32bit 下可以达到4GB,因此不会溢出。
或者malloc使用堆的区域,但是记得free。
用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
用户堆,每个进程有一个,进程中的每个线程都从这个堆申请内存,这个堆在用户空间。所谓内训耗光,一般就是这个用户堆申请不到内存了,申请不到分两种情况,一种是你 malloc 的比剩余的总数还大,这个是肯定不会给你了。第二种是剩余的还有,但是都不连续,最大的一块都没有你 malloc 的大,也不会给你。解决办法,直接申请一块儿大内存,自己管理。
除非特殊设计,一般你申请的内存首地址都是偶地址,也就是说你向堆申请一个字节,堆也会给你至少4个字节或者8个字节。
堆有一个堆指针(break brk),也是按照栈的方式运行的。内存映射段是存在在break brk指针与esp指针之间的一段空间。
在Linux中当动态分配内存大于128K时,会调用mmap函数在esp到break brk之间找一块相应大小的区域作为内存映射段返回给用户。
当小于128K时,才会调用brk或者sbrk函数,将break brk向上增长(break brk指针向高地址移动)相应大小,增长出来的区域便作为内存返回给用户。
两者的区别是
内存映射段销毁时,会释放其映射到的物理内存,
而break brk指向的数据被销毁时,不释放其物理内存,只是简单将break brk回撤,其虚拟地址到物理地址的映射依旧存在,这样使的当再需要分配小额内存时,只需要增加break brk的值,由于这段虚拟地址与物理地址的映射还存在,于是不会触发缺页中断。只有在break brk减少足够多,占据物理内存的空闲虚拟内存足够多时,才会真正释放它们。
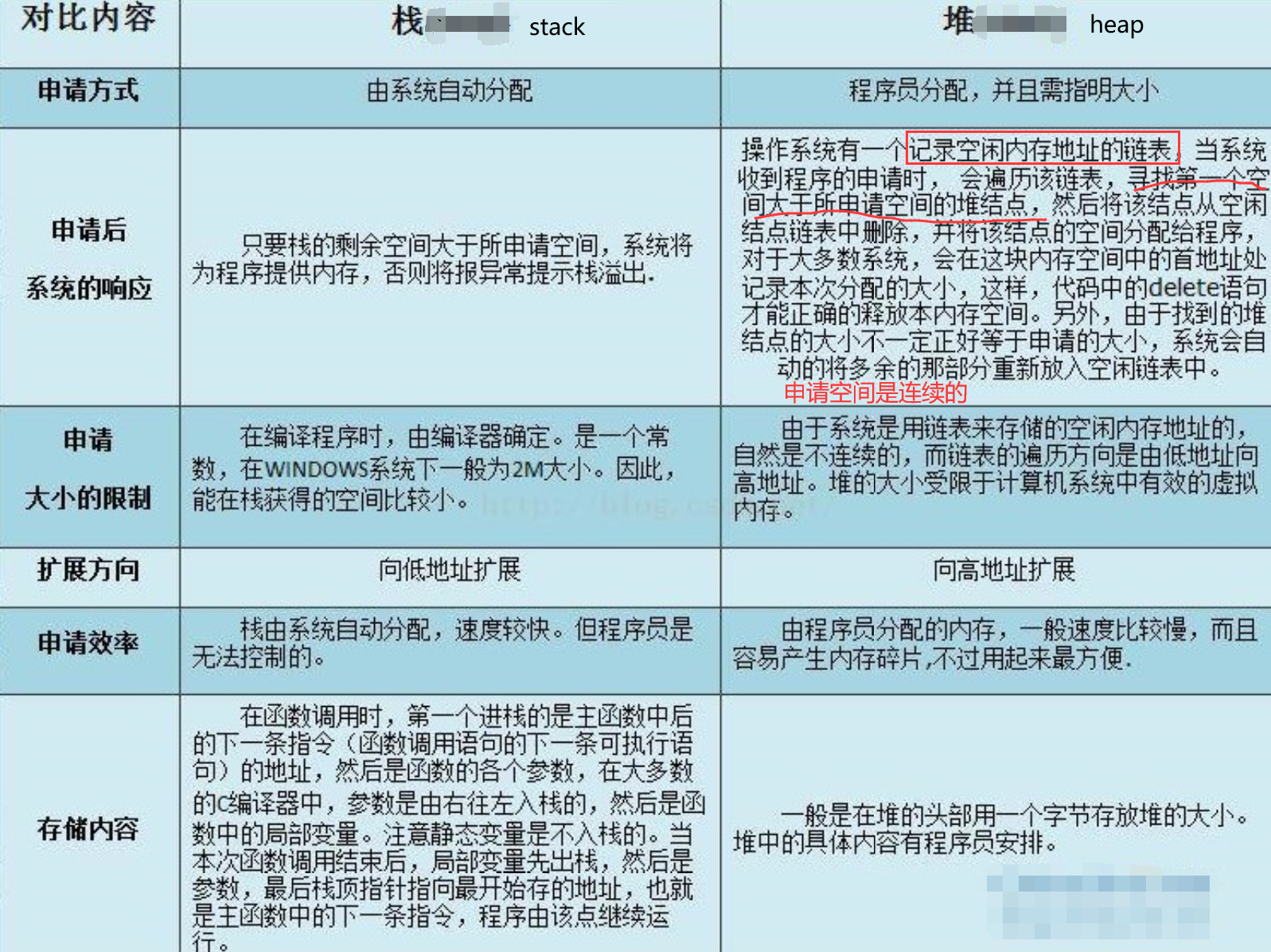
对栈而言,则不存在碎片问题,因为栈是先进后出的队列,永远不可能有一个内存块从栈中间弹出。
用户进程内存空间,也是系统内核分配给该进程的VM(虚拟内存),但并不表示这个进程占用了这么多的RAM(物理内存)。这个空间有多大?命令top输出的VIRT值告诉了我们各个进程内存空间的大小(进程内存空间随着程序的执行会增大或者缩小)。
虚拟地址空间在32位模式下它是一个4GB的内存地址块。在Linux系统中, 内核进程和用户进程所占的虚拟内存比例是1:3,如下图。而Windows系统为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。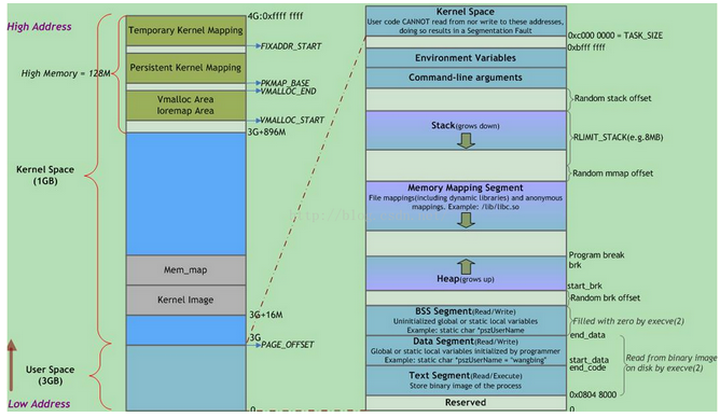
值得注意的是,每个进程的内核虚拟地址空间都是映射到相同的真实物理地址上,因为都是共享同一份物理内存上的内核代码。除此之外还要注意内核虚拟地址空间总是存放在虚拟内存的地址最高处。
其中,用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,灰白区域表示未映射的部分。这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
上图中Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。
execve(2)负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外,execve(2)还会将BSS段清零。
VIRT = SWAP + RES # 总虚拟内存=动态 + 静态
RES >= CODE + DATA + SHR. # 静态内存 = 代码段 + 静态数据段 + 共享内存
MEM = RES / RAM
1 | DATA CODE RES VIRT |
top 里按f 可以选择要显示的内容。
暂无
暂无
Light-weight Contexts: An OS Abstraction for Safety and Performance
https://blog.csdn.net/zy986718042/article/details/73556012
https://blog.csdn.net/qq_38769551/article/details/103099014
https://blog.csdn.net/ywcpig/article/details/52303745
https://zhuanlan.zhihu.com/p/23643064
https://www.bilibili.com/video/BV1N3411y7Mr?spm_id_from=444.41.0.0


