导言
mkdocs在今年支持了blog的基本功能,而且已经有探路者实践过了[^1]。也是时候升级博客生成器了。
1 | tmux new -t $NAME |
<prefix> + maximizes the current pane to a new window
1 | sudo yum install -y \ |
1 | git clone https://github.com/tmux/tmux.git |
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
其余cmake有的, Scons 也有。
Sconstruct python file as compile entryadd option for scons command
1 | AddOption('--buildDir', |
add sub scons config file and build result path using variant_dir
1 | env.SConscript("src/SConscript", variant_dir=buildDir, exports= {'env' : env.Clone()}) |
achive debug mode
using scons debug=1 command.
1 | env = Environment() |
Define the Build Environment:
In the SConstruct file, define the build environment by creating an Environment object. You can specify compiler options, flags, include paths, library paths, and other build settings within this object.
1 | env = Environment(CXX='g++', CCFLAGS=['-O2', '-Wall'], CPPPATH=['include'], LIBPATH=['lib']) |
Specify Source Files and Targets:
Define the source files for your C++ program and specify the target(s) you want to build using the Program() function.
1 | source_files = ['main.cpp', 'util.cpp', 'other.cpp'] |
In this example, main.cpp, util.cpp, and other.cpp are the source files, and my_program is the name of the target executable.
static or dynamic lib
1 | # static |
allSrcs, ".git/index", or "SConstruct") change.1 | env.Command( |
1 | scons -c # Clean |
TODO: multipim how to add a singel head file during compilation process.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
工作外的内容聚焦于几个方面:
淡而不厌,简而文,温而理,知远之近,知风之自,知微之显,可与人德矣。
华为实习部门的都是手握A会的博士大佬。本人望尘莫及,我会狠狠吸收的。
体系结构量化分析方法,重点就在于量化分析开销,比较然后进行tradeoff。当前前提是你要有基本的相关概念。
具体知识来源的优先级,或者说如何使用搜索引擎:
在理解概念,量化了具体场景的数值后,就可以开心进行tradeoff了。
注意项目的可读性和可拓展性一般与性能是不兼容的。这取决于项目的checkpoint/middleValue的保存,在性能优化时往往会消除中间变量。这样会导致代码的可读性和可拓展性下降。
困难的定义可以基于以下几个要素进行评估:
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
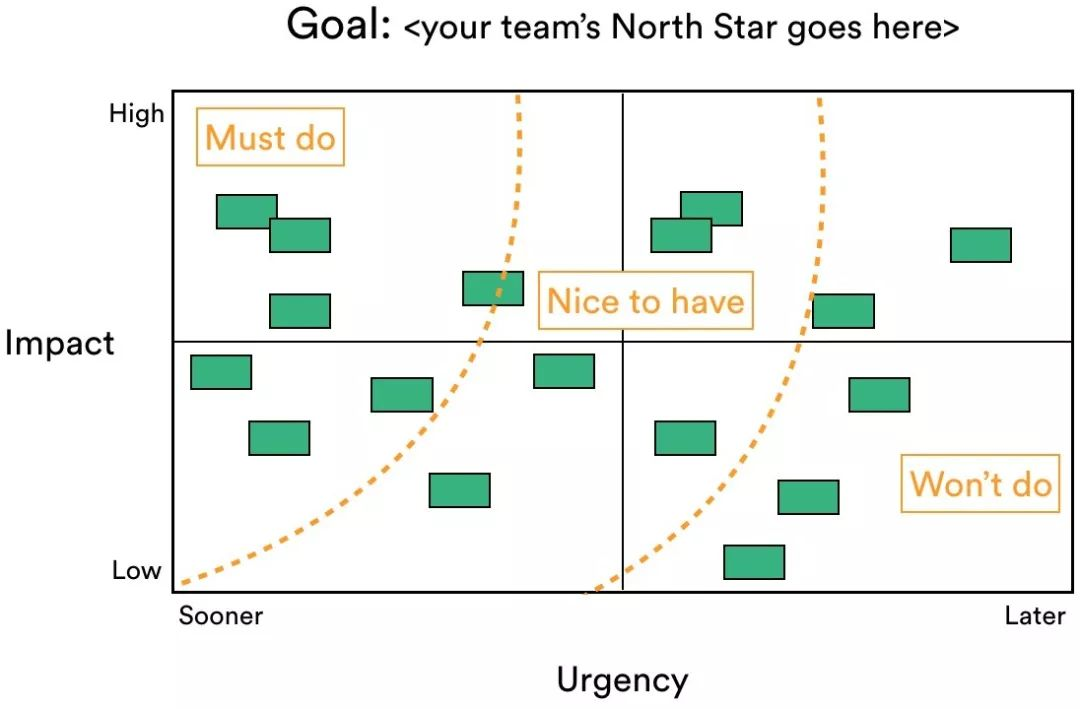
专注度要求不是正交的关系,是集合的包含关系。需要动脑的事情,肯定是未知的)相同的指标
不同的指标:
两者结合:纯思考 > 阅读加稍微思考 > 初步的阅读收集信息 > 纯机械工作
之前的任务优先级评判,都是从完成任务的角度考虑。但是实际情况是每个任务都需要很久(许多任务周期)才能完成。
按照优先级的指标,例如:
| 紧急性(3) | 重要性(3) | 喜好(1) | 工作量(3) | 总分 | 分配 | 要求 | |
|---|---|---|---|---|---|---|---|
| report | 3 | 0 | 0 | 0 | 3 | 一天欠 | 2 |
| thesis | 3 | 3 | 0 | 3 | 9 | 两天多 | 3 |
| AI | 2 | 2 | 1 | 2 | 7 | 两天欠 | 1 |
| OpenCL | 2 | 1 | 1 | 1 | 5 | 一天多 | 1 |
| web | 1 | 0 | 0 | 1 | 2 | 一天欠 | 1 |
| Summary | 26 |
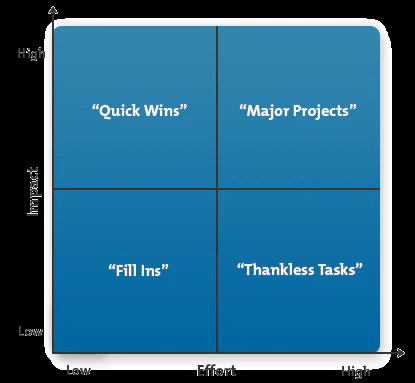
对象:领导、部门的同事团队( 其余部门的同事团队),个人主体。
思考的基础与前提(多沟通,深分析,找关键):
情形:
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
架构(软件和硬件):一个组件的变更可能破坏另一个组件导致它停止运行
专业知识:从专家那里获得建议或帮助(需要怎样做某事)
活动:直到活动完成才能取得进展
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
内存为两根8GB DDR4-3200内存组成双通道。 如果要拓展,需要全部升级为 16GB * 2。 拓展视频和图文教程
可以加装一条2280的固态, 但是无法加机械了。
PCIe 3.0的数据传输速度每通道1GB/s,PCIe 2.0是其一半
B450迫击炮有两个M2插槽,一个是满速pcie3.0×4(4GB/s) 一个是半速的pcie2.0×4(2GB/s)。价格差不多的话还是用M2 nvme协议 的SSD
一点没人提过的,b450m迫击炮装上第二个m2以后,第二个pcie2.0*16的扩展(pcie_4)是没法用的。
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无