BT简述 BitTorrent (简称 BT) 协议是和点对点(point-to-point)的协议程序不同,它是用户群对用户群(peer-to-peer, 或简写为 P2P) 传输协议, 它被设计用来高效地分发文件 (尤其是对于大文件、多人同时下载时效率非常高)。该协议基于HTTP协议,属于TCP/IP应用层。
将文件划分成多块(默认256Kb一块),每块可以从网络中不同的用户的BT客户端处并行下载。
1 2 3 BT 下载的文件都是别人上传给你的。 BT 下载速度均来自其他下载同一资源的用户上传速度。 上传的用户越多,你的下载速度越快,相反没用户上传你就没有下载速度。
比特彗星,包括其他 BT 软件(迅雷除外,迅雷不是会员会限速,高速通道下载提高的速度一部分就是接触限速后获得的)都不会限制下载速度。
BT分享规则 与迅雷不同,BT旨在“人人为我,我为人人”。用户和用户之间对等交换自己手中已有的资源。如果任何一方试图白嫖另外一方的资源,而自己不愿意上传自己的资源,那么那方就会被人视作吸血者而被踢出这个交换,下场是没有人会愿意和你交换数据,你的下载速度也就归零。
如果把上传速度限制为了10KB/s,10KB/s是BitComet上传最低限速,很大时候就这10KB会被包含DHT查询、向Tracker服务器注册,连接用户所产生的上传全部占满。在下载种子的时候,其他用户连上你是只能拿到1~2KB/s甚至一点都没有的。
现在的BT下载客户端都可以做到智能反吸血,所以基本想和交换数据的用户都把你当作Leecher(吸血鬼)Ban(封禁)处理了,故没有下载速度不足为奇。
一般来说,只要预留50KB/s的上传给其他网页浏览、聊天就可以了,在下载时应该尽量把上传留给那些和你交换资源的用户,这样才不会被他们视作你在吸血进而屏蔽你。
如果上传不足,就应该主动限制自己的下载速度,否则单位时间下载量远超过上传量反而会遭来更多的屏蔽,对下载速度提升更加不利。
BT基本流程 .torrent 种子文件本质上是文本文件,包含Tracker信息和文件信息两部分。Tracker信息主要是BT下载中需要用到的Tracker服务器的地址和针对Tracker服务器的设置。
下载时,BT客户端首先解析种子文件得到Tracker地址,然后连接Tracker服务器。
Tracker服务器回应下载者的请求,提供下载者其他下载者(包括发布者)的IP。
下载者再连接其他下载者,根据种子文件,两者分别告知对方自己已经有的块,然后交换对方所没有的数据。
此时不需要其他服务器参与,分散了单个线路上的数据流量,因此减轻了服务器负担。
下载者每得到一个块,需要算出下载块的Hash验证码与种子文件中的对比,如果一样则说明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容准确性的问题。
常规部署
安装qBittorrent-nox , tmux下运行,在8080端口挂载WebUI
安装qbittorrent, 用户运行qbittorrent, x11弹出应用窗口
问题:
怎么维持窗口?sudo XAUTHORITY=/home/qcjiang/.Xauthority qbittorrent
关于写文件权限,如何写网络硬盘
node5 上传很快, 网络原因?种子原因?(不是,是因为网络硬盘,所以下载多少要占用多少上传)
docker部署 以qBit的docker为例,参考linuxsever 的docker-compose如下:(qBit相对于Transmission有多线程IO的优势) 也可以使用其余docker镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 --- version: "2.1" services: qbittorrent: image: lscr.io/linuxserver/qbittorrent:latest container_name: qbittorrent environment: - PUID=0 # 这里是root 如果想以其他用戶A修改文件,可以改成其他用户的UID。通過id A 查看 - PGID=0 - TZ=Etc/UTC - WEBUI_PORT=8080 volumes: - /addDisk/DiskNo4/qBit:/config - /addDisk/DiskNo4/bt:/downloads network_mode: host restart: unless-stopped
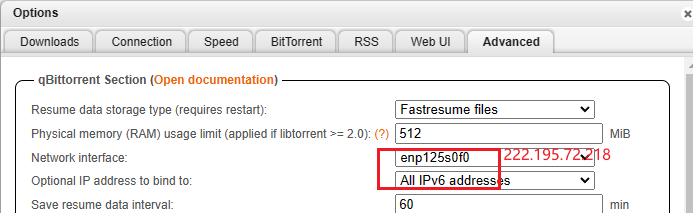
默认账号 admin 默认密码 adminadminhttp://222.195.72.218:8080/管理。
如果不想网络通过wireguard,而是本地可以如下设置
同一台机器实现两个账号做种
思路:两个docker,同一个网络出口
問題:
qBit要有权限写文件
两个docker兼容性:
WebUI有bug,不一定会显示。重启刷新即可
其次有一个docker会没有网络。
这是由于端口随机错误导致的,会导致下面连接状态显示火焰。换端口刷新即可解决。
关于封号
由于国内环境下载一般都是大内网。同一个网络出去应该没有问题。
大多数做种是通过ipv6,会被检测出同一个机器多个账户做种,导致封号
还有关于盒子刷上传,一方面通过速度,另一方面由于盒子的ip是固定的,所以会被检测出重复导致封号。
测速
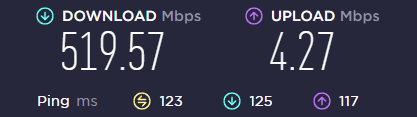
先用 https://www.speedtest.net 测速
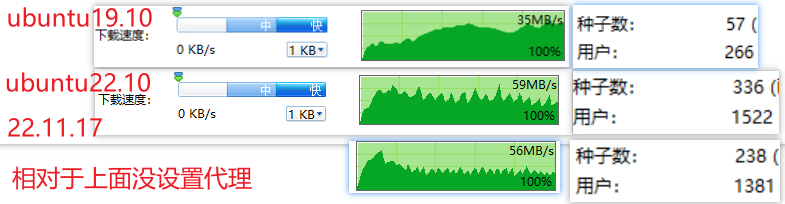
考虑热门种子测试 http://releases.ubuntu.com/19.10/ubuntu-19.10-desktop-amd64.iso.torrent
没通过代理能找到的用户变少,速度也变慢了。
如果跑不到网络上限,可能和软件设置有关
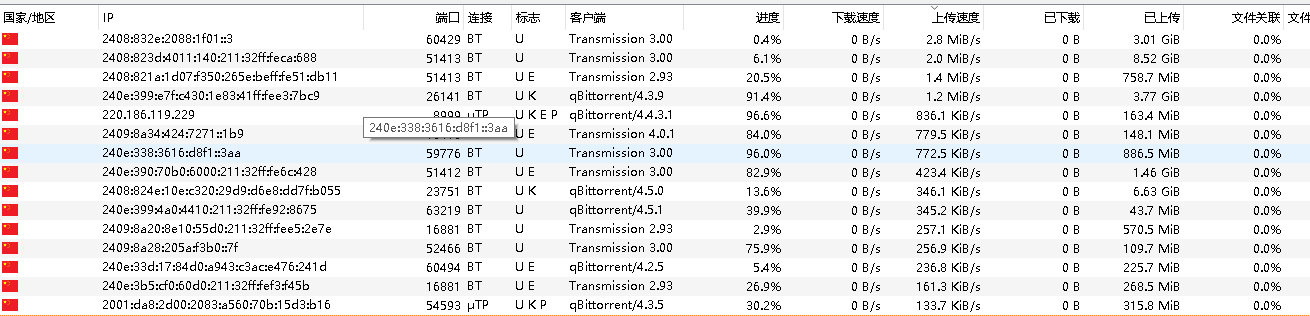
上传速度 m站刷上传的时候,发现基本都是对方基本都是通过ipv6下载
BT连接是一种基于TCP的协议,它可以保证数据的完整性和可靠性,但是可能会占用较多的网络带宽和资源。
在qBittorrent中,标志U K E P分别表示以下含义:
1 2 3 4 U:表示你正在上传数据给对方,或者对方正在从你那里下载数据。 K:表示对方支持uTP协议,即基于UDP的传输协议。 E:表示对方使用了加密连接,即通过加密算法保护数据的安全性。 P:表示对方使用了代理服务器或VPN服务,即通过第三方网络隐藏自己的真实IP地址。
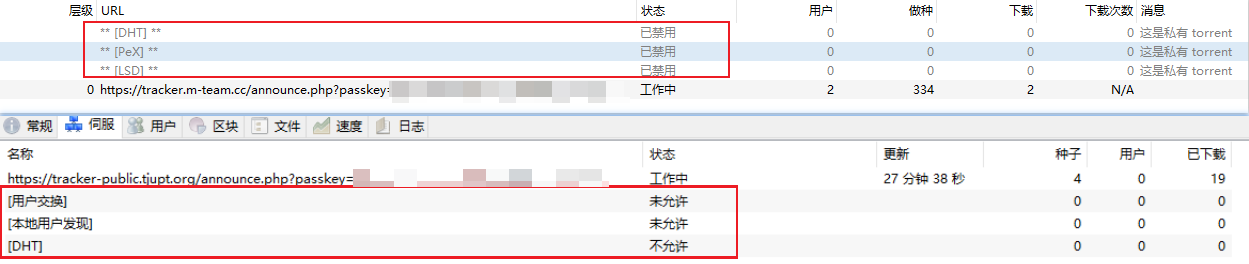
PT设置
虽然说PT下载,客户端要关闭DHT,PeX, LSD。
但是其实种子是默认关闭的,无序额外设置,北洋和M站一样。
基本概念 Tracker 收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。
种子 指一个下载任务中所有文件都被某下载者完整 的下载,此时下载者成为一个种子。发布者本身发布的文件就是原始种子。
做种 发布者提供下载任务的全部 内容的行为;下载者下载完成后继续提供给他人下载的行为。
分享率 上傳資料量 / 下傳資料量的比率,是一種BT的良心度,沒實際作用.(一般为了良心,至少大于1)
长期种子 BitComet的概念,相对于种子任务的上传能够控制。
长效种子就是你不开启 任务做种,只要你启动了比特彗星,软件挂后台,当有其他用户也是用比特彗星下载你列表里的存在的文件时候就会被认为是长效种子 。
DHT .DHT全称叫分布式哈希表(Distributed Hash Table),是一种分布式存储方法。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储。新版BitComet允许同行连接DHT网络和Tracker,也就是说在完全不连上Tracker服务器的情况下,也可以很好的下载,因为它可以在DHT网络中寻找下载同一文件的其他用户。
类似Tracker的根据种子特征码返回种子信息的网络。
在BitComet中,无须作任何设置即可自动连接并使用DHT网络,完全不需要用户干预。
用户交换Pex Peer Exchange (PEX), 每个peer客户端的用户列表,可以互相交换通用。可以将其理解为“节点信息交换”。前面说到了 DHT 网络是没有中心服务器的,那么我们的客户端总不能满世界去喊:“我在下载这个文件,快来连我吧.”(很大声)。所以就通过各个 BT 客户端自带的节点去同步路由表实现 DHT 网络连接。
本地用户发现 LSD(LPD)就是本地网络资源,内网下载,没什么几把用的东西,可能学校等私有网络好使
ISP 網絡業務提供商(Internet Service Provider,簡稱ISP),互聯網服務提供商,即向廣大用户綜合提供互聯網接入業務、信息業務、和增值業務的電信運營商。
反吸血机制 基本原理
根据流量 : 默认设置为120秒,持续对某个peer产生上传,并且从该peer用户获取的下载流量没有超过1KB文件(1024字节)大小,即拉黑该peer,预警颜色为黄色,合法为绿色,红色为封禁。
可组合检测指定客户端 进行反吸血,比如说指定屏蔽qbittorrent、utorrent等吸血客户端选择(可多选客户端,可对下载任务和做种任务生效)
可组合检测客户端连接端口号 进行反吸血,比如说指定屏蔽15000迅雷X版本客户端等吸血端口(可多选端口号,可对下载任务和做种任务生效)
可组合检测客户端连接peer_id标志符 进行反吸血屏蔽,例如屏蔽XL0018客户端等吸血标志符(可多选标志符,可对下载任务和做种任务生效)
高级设置 1 2 3 4 5 bittorrent.anti_leech_min_byte 设定反吸血保护流量:要求对方在指定时间(秒)内需要上传的最少流量(byte), 取值范围:1-10000。 bittorrent.anti_leech_min_stable_sec 设定反吸血保护时间:指定与对方连接多长时间(秒)后开始检查流量(byte),取值范围:1-10000。
常见问题 需要软件开着吗? 需要
原文件改名或者移动,还会上传吗? 文件下载后不能移动,不能删除,不能重命名(但可以在软件内改)。 一但BT 软件找不到文件,或删除了任务,就无法做种上传了。
晚上避免上传 可以在Bitcomet高级设置 里设置时段限速
对硬盘损害大吗? 分享上传也需要频繁读取硬盘。
以Bitcomet为例,该软件就是通过磁盘缓存技术减小频繁随机读写对硬盘的损伤。
磁盘缓存就是利用物理内存作为缓冲,将下载下的数据先存放于内存中,然后定期的一次性写入硬盘,以减少对硬盘的写入操作,很大的程度上降低了磁盘碎片。
因为通常我们设置内存(磁盘缓存)为每任务XX兆,意味着,这个缓冲区可以存放数兆甚至几十兆的“块”,基本上可以杜绝碎片了。
现在BT软件都是自动设置缓存的,它是根据你物理内存的大小分配的。
注意设置
设置了“反吸血”,应对迅雷
校园网设置9,不限制P2P
国内各省份不同运营商限速策略(QOS)
需要进一步的研究学习 路由器下载?
参考文献