导言
原本是想写些网站建设的计划(但别人关心的只是他们搜索的内容)。所以就讲讲所在的团队吧(每个人都关心自己的下一站在哪里)
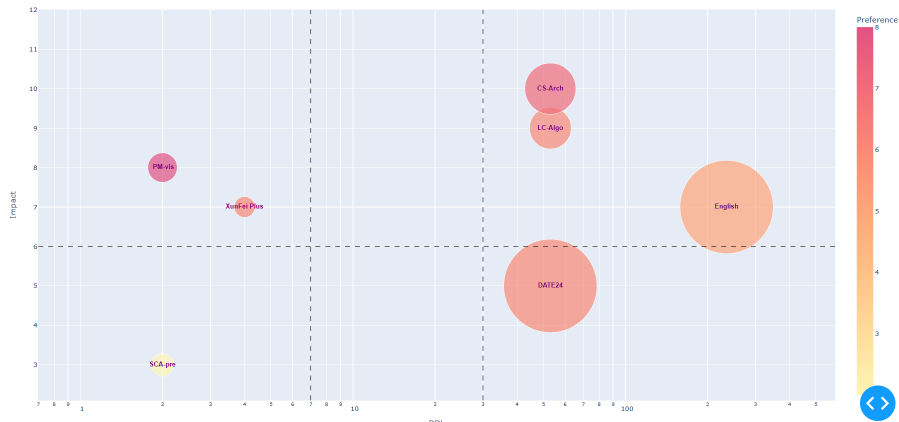
侧重于测量方法的研究, 给出了并发存储的测量方法和尺度。
在 APC 中, 周期是存储活动周期 (memory
active cycle), 不是通用的 CPU 周期,所以 APC 也叫 APMAC( 存储活动周期平均访问数, access per
memory active cycle)。
同时 APC 采用重叠 (overlapping) 的访存时间统计方法 : 在有两个或多个存储访
问同时进行时, 周期只增加一次。
HPL.dat file detailed explanation
1 | HPLinpack benchmark input file |
https://plotly.com/python/builtin-colorscales/
same in matplotlib

使用Dash: A web application framework for your data., 默认部署在localhost:8050端口
本地机器打通ssh隧道
1 | ssh -L 8050:127.0.0.1:8050 -vN -f -l shaojiemike 202.38.72.23 |
In scientific research plotting, it’s always bar charts instead of line charts.
Possible reasons:
font things, Attention, global settings have higher priority to get work
1 |
|
1 |
1 | # mpl |
1 | # mpl: Adjust the left margin to make room for the legend, left & right chart vertical line position from [0,1] |
1 | # mpl: |
1 | # mpl |
1 | # mpl ? |
1 | # mpl: Create a bar chart with bold outlines |
1 | # mpl: |
1 | # mpl: white hugo hatch with black bar edge. |
To draw symmetry chart, we need to special highlight the overflow bar number.
If the ancher point locate in the plot box, it’s easy to show text above the ceil line using textposition="bottom" like option. In the opposite scenario, plotly and mathplotlib all will hide the out-box text.
1 | # plotly |
But mlb can write text out box.
1 | ax.text(1, -1.6, 'Increasing', ha="center") |
mathplotlib(mpl) can achieve this using ref, but there are few blogs about plotly.
1 | # mpl: from 1*1 size full-graph (0.5,0.2) to point (1,0.8) |
1 | # mpl: |
如果防火墙是关闭的,你可以直接部署在external address上。使用docker也是可行的办法
1 | app.run_server(debug=True, host='202.38.72.23') |
1 | import matplotlib.pyplot as plt |
在柱状图中,用于表示上下浮动的元素通常被称为“误差条”(Error Bars)。误差条是用于显示数据点或柱状图中的不确定性或误差范围的线条或线段。它们在柱状图中以垂直方向延伸,可以显示上下浮动的范围,提供了一种可视化的方式来表示数据的变化或不确定性。误差条通常通过标准差、标准误差、置信区间或其他统计指标来计算和表示数据的浮动范围。
Errorbars + StackedBars stacked 的过程中由于向上的error线的会被后面的Bar遮盖,然后下面的error线由于arrayminus=[i-j for i,j in zip(sumList,down_error)]导致大部分时间说负值,也不会显示。
1 | fig = go.Figure() |
类似股票上下跳动的浮标被称为”Candlestick”(蜡烛图)或”OHLC”(开盘-最高-最低-收盘)图表。
暂无
暂无
上面回答部分来自ChatGPT-3.5,暂时没有校验其可靠性(看上去貌似说得通)。
[1] Saket, B., Endert, A. and Demiralp, Ç., 2018. Task-based effectiveness of basic visualizations.IEEE transactions on visualization and computer graphics,25(7), pp.2505-2512.
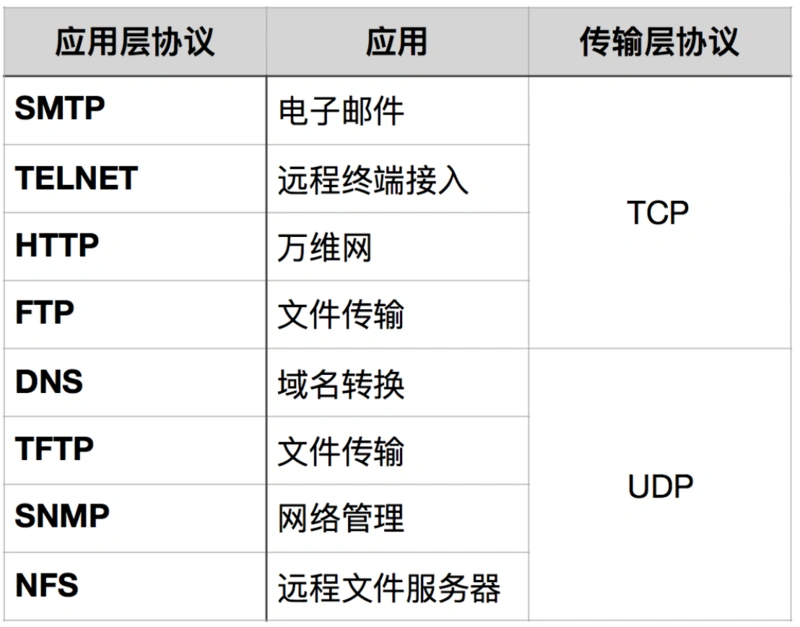
对比如下:
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 是否有序 | 无序 | 有序,消息在传输过程中可能会乱序,TCP 会重新排序 |
| 传输速度 | 快 | 慢 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
总结:
TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
TCP主要提供了检验和、序列号/确认应答、超时重传、滑动窗口、拥塞控制和 流量控制等方法实现了可靠性传输。
TCP 一共使用了四种算法来实现拥塞控制:
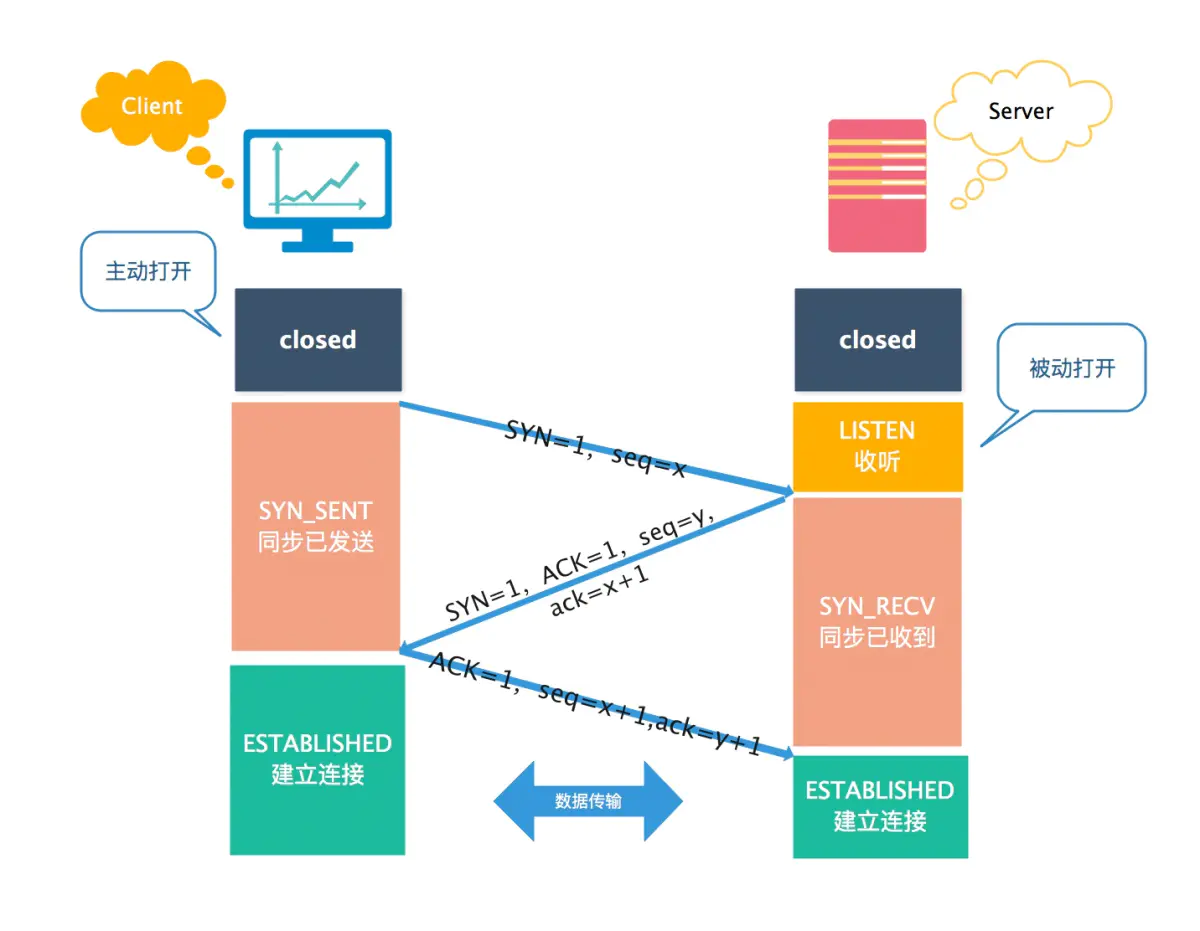
三次握手机制:
seq = x 作为初始序列号,ack = x + 1,同时选择一个随机数 seq = y 作为初始序列号,ack = y + 1,序列号为 seq = x + 1,理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
主要有三个原因:
防止已过期的连接请求报文突然又传送到服务器,因而产生错误和资源浪费。
在双方两次握手即可建立连接的情况下,假设客户端发送 A 报文段请求建立连接,由于网络原因造成 A 暂时无法到达服务器,服务器接收不到请求报文段就不会返回确认报文段。
客户端在长时间得不到应答的情况下重新发送请求报文段 B,这次 B 顺利到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,客户端在收到 确认报文后也进入 ESTABLISHED 状态,双方建立连接并传输数据,之后正常断开连接。
此时姗姗来迟的 A 报文段才到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,但是已经进入 CLOSED 状态的客户端无法再接受确认报文段,更无法进入 ESTABLISHED 状态,这将导致服务器长时间单方面等待,造成资源浪费。
三次握手才能让双方均确认自己和对方的发送和接收能力都正常。
第一次握手:客户端只是发送处请求报文段,什么都无法确认,而服务器可以确认自己的接收能力和对方的发送能力正常;
第二次握手:客户端可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
第三次握手:服务器可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
可见三次握手才能让双方都确认自己和对方的发送和接收能力全部正常,这样就可以愉快地进行通信了。
告知对方自己的初始序号值,并确认收到对方的初始序号值。
TCP 实现了可靠的数据传输,原因之一就是 TCP 报文段中维护了序号字段和确认序号字段,通过这两个字段双方都可以知道在自己发出的数据中,哪些是已经被对方确认接收的。这两个字段的值会在初始序号值得基础递增,如果是两次握手,只有发起方的初始序号可以得到确认,而另一方的初始序号则得不到确认。
因为三次握手已经可以确认双方的发送接收能力正常,双方都知道彼此已经准备好,而且也可以完成对双方初始序号值得确认,也就无需再第四次握手了。
SYN洪泛攻击属于 DOS 攻击的一种,它利用 TCP 协议缺陷,通过发送大量的半连接请求,耗费 CPU 和内存资源。
原理:
[SYN/ACK] 包(第二个包)之后、收到客户端的 [ACK] 包(第三个包)之前的 TCP 连接称为半连接(half-open connect),SYN_RECV(等待客户端响应)状态。如果接收到客户端的 [ACK],则 TCP 连接成功,[SYN] 包,服务器回复 [SYN/ACK] 包,并等待客户的确认。由于源地址是不存在的,服务器需要不断的重发直至超时。[SYN] 包将长时间占用未连接队列,影响了正常的 SYN,导致目标系统运行缓慢、网络堵塞甚至系统瘫痪。检测:当在服务器上看到大量的半连接状态时,特别是源 IP 地址是随机的,基本上可以断定这是一次 SYN 攻击。
防范:
服务端:
客户端:
客户端认为这个连接已经建立,如果客户端向服务端发送数据,服务端将以RST包(Reset,标示复位,用于异常的关闭连接)响应。此时,客户端知道第三次握手失败。
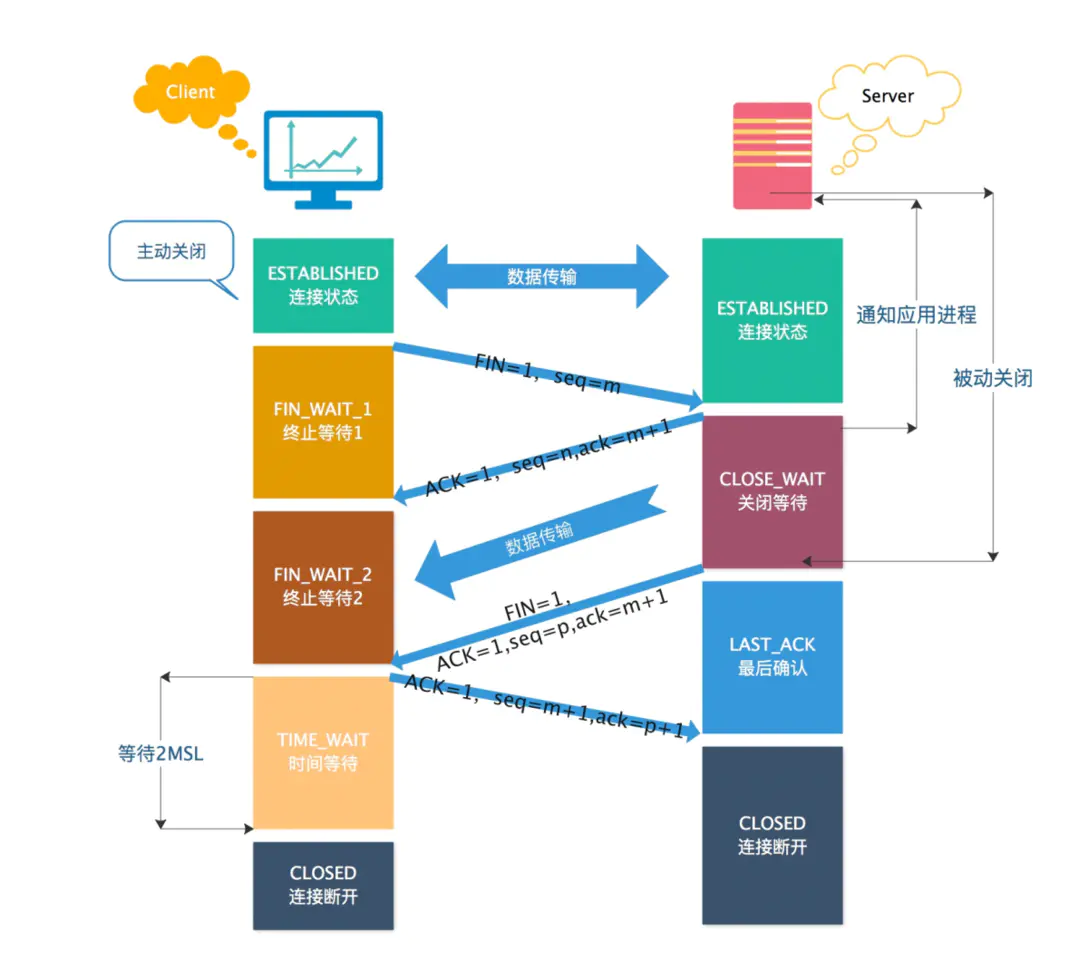
第一次挥手:客户端向服务端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待服务端的确认。
第二次挥手:服务端收到连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = k,确认号 ack = u + 1。
这时 TCP 连接处于半关闭状态,即客户端到服务端的连接已经释放了,但是服务端到客户端的连接还未释放。这表示客户端已经没有数据发送了,但是服务端可能还要给客户端发送数据。
第三次挥手:服务端向客户端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待 A 的确认。
第四次挥手:客户端收到服务端的连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = u + 1,确认号为 ack = w + 1。
此时,客户端就进入了 TIME-WAIT 状态。注意此时客户端到 TCP 连接还没有释放,必须经过 2*MSL(最长报文段寿命)的时间后,才进入 CLOSED 状态。而服务端只要收到客户端发出的确认,就立即进入 CLOSED 状态。可以看到,服务端结束 TCP 连接的时间要比客户端早一些。
服务器在收到客户端的 FIN 报文段后,可能还有一些数据要传输,所以不能马上关闭连接,但是会做出应答,返回 ACK 报文段.
接下来可能会继续发送数据,在数据发送完后,服务器会向客户单发送 FIN 报文,表示数据已经发送完毕,请求关闭连接。服务器的ACK和FIN一般都会分开发送,从而导致多了一次,因此一共需要四次挥手。
主要有两个原因:
确保 ACK 报文能够到达服务端,从而使服务端正常关闭连接。
第四次挥手时,客户端第四次挥手的 ACK 报文不一定会到达服务端。服务端会超时重传 FIN/ACK 报文,此时如果客户端已经断开了连接,那么就无法响应服务端的二次请求,这样服务端迟迟收不到 FIN/ACK 报文的确认,就无法正常断开连接。
MSL 是报文段在网络上存活的最长时间。客户端等待 2MSL 时间,即「客户端 ACK 报文 1MSL 超时 + 服务端 FIN 报文 1MSL 传输」,就能够收到服务端重传的 FIN/ACK 报文,然后客户端重传一次 ACK 报文,并重新启动 2MSL 计时器。如此保证服务端能够正常关闭。
如果服务端重发的 FIN 没有成功地在 2MSL 时间里传给客户端,服务端则会继续超时重试直到断开连接。
防止已失效的连接请求报文段出现在之后的连接中。
TCP 要求在 2MSL 内不使用相同的序列号。客户端在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以保证本连接持续的时间内产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。或者即使收到这些过时的报文,也可以不处理它。
或者说,如果三次握手阶段、四次挥手阶段的包丢失了怎么办?如“服务端重发 FIN丢失”的问题。
简而言之,通过定时器 + 超时重试机制,尝试获取确认,直到最后会自动断开连接。
具体而言,TCP 设有一个保活计时器。服务器每收到一次客户端的数据,都会重新复位这个计时器,时间通常是设置为 2 小时。若 2 小时还没有收到客户端的任何数据,服务器就开始重试:每隔 75 分钟发送一个探测报文段,若一连发送 10 个探测报文后客户端依然没有回应,那么服务器就认为连接已经断开了。
从服务器来讲,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,严重消耗着服务器的资源,此时部分客户端就会显示连接不上。
从客户端来讲,客户端TIME_WAIT过多,就会导致端口资源被占用,因为端口就65536个,被占满就会导致无法创建新的连接。
解决办法:
服务器可以设置 SO_REUSEADDR 套接字选项来避免 TIME_WAIT状态,此套接字选项告诉内核,即使此端口正忙(处于
TIME_WAIT状态),也请继续并重用它。
调整系统内核参数,修改/etc/sysctl.conf文件,即修改net.ipv4.tcp_tw_reuse 和 tcp_timestamps
1 | net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; |
强制关闭,发送 RST 包越过TIME_WAIT状态,直接进入CLOSED状态。
TIME_WAIT 是主动断开连接的一方会进入的状态,一般情况下,都是客户端所处的状态;服务器端一般设置不主动关闭连接。
TIME_WAIT 需要等待 2MSL,在大量短连接的情况下,TIME_WAIT会太多,这也会消耗很多系统资源。对于服务器来说,在 HTTP 协议里指定 KeepAlive(浏览器重用一个 TCP 连接来处理多个 HTTP 请求),由浏览器来主动断开连接,可以一定程度上减少服务器的这个问题。
现在有一个数据部分长度为8192B的数据需要通过UDP在以太网上传播,经过分片化为多个IP数据报片,这些片中的数据部分长度都有哪些?(假设按照最大长度分片), 计网习题
暂无
暂无
GCC Compiler Option 1 : Optimization Options
全体选项其中一部分是Optimize-Options
1 | # 会列出可选项 |
编译时最好按照其分类有效组织, 例子如下:
1 | g++ |
-Wxxx 对 xxx 启动warning, -fxxx 启动xxx的编译器功能。-fno-xxx 关闭对应选项???-gxxx debug 相关-mxxx 特定机器架构的选项| 名称 | 含义 |
|---|---|
| -Wall | 打开常见的所有warning选项 |
| -Werror | 把warning当成error |
| -std= | C or C++ language standard. eg ‘c++11’ == ‘c++0x’ ‘c++17’ == ‘c++1z’, which ‘c++0x’,’c++17’ is develop codename |
| -Wunknown-pragmas | 未知的pragma会报错(-Wno-unknown-pragmas 应该是相反的) |
| -fomit-frame-pointer | 不生成栈帧指针,属于-O1优化 |
| -Wstack-protector | 没有防止堆栈崩溃的函数时warning (-fno-stack-protector) |
| -MMD | only user header files, not system header files. |
| -fexceptions | Enable exception handling. |
| -funwind-tables | Unwind tables contain debug frame information which is also necessary for the handling of such exceptions |
| -fasynchronous-unwind-tables | Generate unwind table in DWARF format. so it can be used for stack unwinding from asynchronous events |
| -fabi-version=n | Use version n of the C++ ABI. The default is version 0.(Version 2 is the version of the C++ ABI that first appeared in G++ 3.4, and was the default through G++ 4.9.) ABI: an application binary interface (ABI) is an interface between two binary program modules. Often, one of these modules is a library or operating system facility, and the other is a program that is being run by a user. |
| -fno-rtti | Disable generation of information about every class with virtual functions for use by the C++ run-time type identification features (dynamic_cast and typeid). If you don’t use those parts of the language, you can save some space by using this flag |
| -faligned-new | Enable support for C++17 new of types that require more alignment than void* ::operator new(std::size_t) provides. A numeric argument such as -faligned-new=32 can be used to specify how much alignment (in bytes) is provided by that function, but few users will need to override the default of alignof(std::max_align_t). This flag is enabled by default for -std=c++17. |
| -Wl, xxx | pass xxx option to linker, e.g., -Wl,-R/staff/shaojiemike/github/MultiPIM_icarus0/common/libconfig/lib specify a runtime library search path for dynamic libraries (shared libraries) during the linking process. |
-O3 turns on all optimizations specified by -O2
and also turns on the -finline-functions, -funswitch-loops, -fpredictive-commoning, -fgcse-after-reload, -ftree-loop-vectorize, -ftree-loop-distribute-patterns, -ftree-slp-vectorize, -fvect-cost-model, -ftree-partial-pre and -fipa-cp-clone options
允许使用浮点计算获得更高的性能,但可能会略微降低精度。
更快但是有保证正确
(仅限 GNU)链接时优化,当程序链接时检查文件之间的函数调用的步骤。该标志必须用于编译和链接时。使用此标志的编译时间很长,但是根据应用程序,当与 -O* 标志结合使用时,可能会有明显的性能改进。这个标志和任何优化标志都必须传递给链接器,并且应该调用 gcc/g++/gfortran 进行链接而不是直接调用 ld。
此标志对特定处理器类型进行额外调整,但它不会生成额外的 SIMD 指令,因此不存在体系结构兼容性问题。调整将涉及对处理器缓存大小、首选指令顺序等的优化。
在 AMD Bulldozer 节点上使用的值为 bdver1,在 AMD Epyc 节点上使用的值为 znver2。是zen ver2的简称。
-fprefetch-loop-arrays-Os禁用https://zhuanlan.zhihu.com/p/496435946
下面没有特别指明都是O3,默认开启
-ftree-loop-distribution-ftree-loop-distribute-patterns-floop-interchange-floop-unroll-and-jam(不是计算访问的数据)
-falign-functions=n:m:n2:m2-freorder-blocksUnroll loops whose number of iterations can be determined at compile time or upon entry to the loop. -funroll-loops implies -frerun-cse-after-loop. This option makes code larger, and may or may not make it run faster.
Unroll all loops, even if their number of iterations is uncertain when the loop is entered. This usually makes programs run more slowly. -funroll-all-loops implies the same options as -funroll-loops,
The maximum number of instructions that a loop should have if that loop is unrolled, and if the loop is unrolled, it determines how many times the loop code is unrolled.
如果循环被展开,则循环应具有的最大指令数,如果循环被展开,则它确定循环代码被展开的次数。
The maximum number of instructions biased by probabilities of their execution that a loop should have if that loop is unrolled, and if the loop is unrolled, it determines how many times the loop code is unrolled.
如果一个循环被展开,则根据其执行概率偏置的最大指令数,如果该循环被展开,则确定循环代码被展开的次数。
The maximum number of unrollings of a single loop.
单个循环的最大展开次数。
会自动检测,但有可能检测不对。
这将为特定架构生成 SIMD 指令并应用 -mtune 优化。 arch 的有用值与上面的 -mtune 标志相同。
1 | g++ -march=native -m32 ... -Q --help=target |
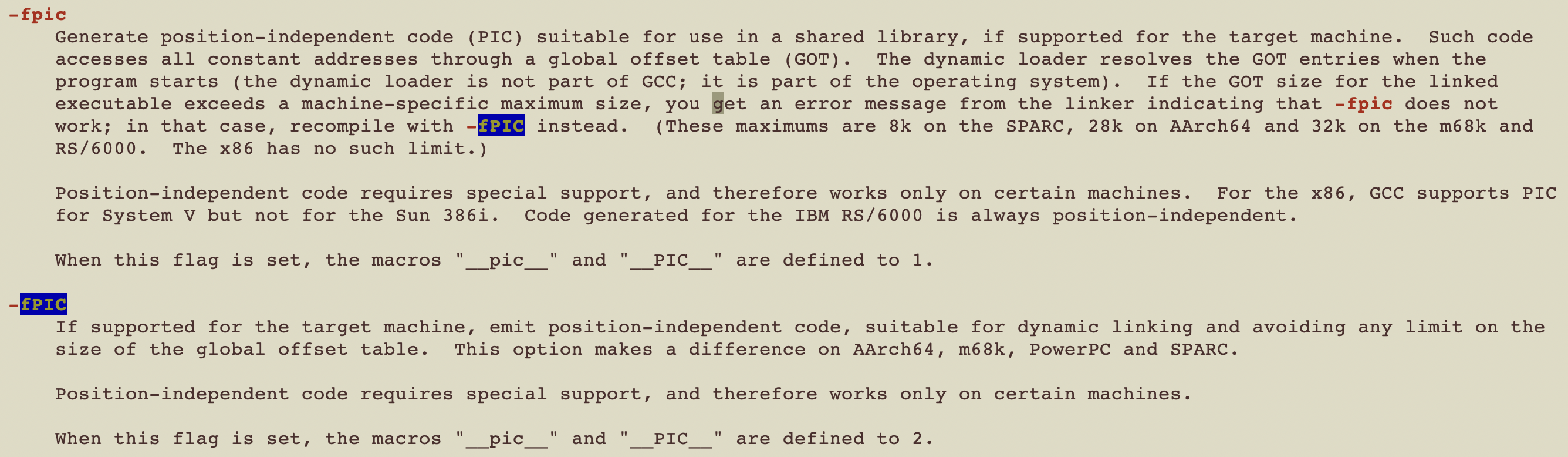
position-independent code(PIC)
暂无
暂无