Introduction to AI and Machine Learning Basics
Read more
[C++ Basic] STL Data Structure
for(auto x : range).for(auto && x : range)for(const auto & x : range).使用begin end
1 | vector<int>& nums1 |
以下是整理和改正后的迭代器笔记。
定义:随机访问迭代器是一种迭代器类型,允许在常数时间内访问序列中的任何元素,并支持灵活的迭代器操作。
运算支持:
+ 和 - 运算符,允许轻松地在迭代器位置上进行移动。[],使其用法与指针类似。it,可以通过 *(it + i) 或 it[i] 语法访问第 i 个元素。使用场景:
vector 和 deque 都提供随机访问迭代器。std::sort、std::nth_element)要求输入的迭代器必须是随机访问迭代器,以便快速定位和排序。概述:在 C++ 中,容器一般提供正向迭代器(begin() 到 end())和反向迭代器(rbegin() 到 rend()),二者在遍历方向上相反。
转换:正向迭代器和反向迭代器可以相互转换,但类型不同,需要显式转换。
正向迭代器到反向迭代器:可以将一个正向迭代器转换为反向迭代器。
1 | Iterator it; // 假设 it 是正向迭代器 |
反向迭代器到正向迭代器:反向迭代器的 base() 成员函数可以返回一个指向反向迭代器当前元素的下一个位置的正向迭代器。
1 | std::reverse_iterator<Iterator> rit; |
注意:
rit.base() 指向的并不是 rit 当前元素本身,而是 rit 指向元素的下一个位置。C++ 提供了 rbegin() 和 rend() 来支持容器的反向遍历:
rbegin() 返回一个反向迭代器,指向容器的最后一个元素。rend() 返回一个反向迭代器,指向容器反向遍历时的“结束位置”,即第一个元素之前的一个位置。++it 而非 --it,因为反向迭代器的递增操作相当于在正向迭代器上进行递减操作。1 | for (auto it = collection.rbegin(); it != collection.rend(); ++it) { |
std::prev 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向前移动指定偏移量后的迭代器。std::next 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向后移动指定偏移量后的迭代器。1 | auto prevIt = std::prev(it); |
bitset类型存储二进制数位。
1 | std::bitset<16> foo; |
将数转化为其二进制的字符串表示
1 | int i = 3; |
1 |
|
1 |
|
1 | string vowel = "AEIOUaeiou"; |
1 | std::string s0 ("Initial string"); |
读取空格分割的
1 | stringstream txt(s); |
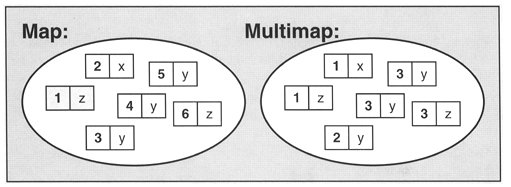
顺序容器包括vector、deque、list、forward_list、array、string,
关联容器包括set、map,
关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
链表,或者数组(如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。)
链式结构如下,注意左右孩子节点
1 | struct TreeNode { |
深度遍历: 前/中/后序遍历。
注意:这里前中后,其实指的就是中间节点/根节点的遍历顺序
堆(Heap)是计算机科学中一类特殊的数据结构的统称。
堆通常是一个可以被看做一棵完全二叉树的数组对象。
堆满足下列性质:
堆中某个节点的值总是不大于或不小于其父节点的值。
堆总是一棵完全二叉树。
make_heap()将区间内的元素转化为heap.
push_heap()对heap增加一个元素.
pop_heap()对heap取出下一个元素.
sort_heap()对heap转化为一个已排序群集.
1 |
|
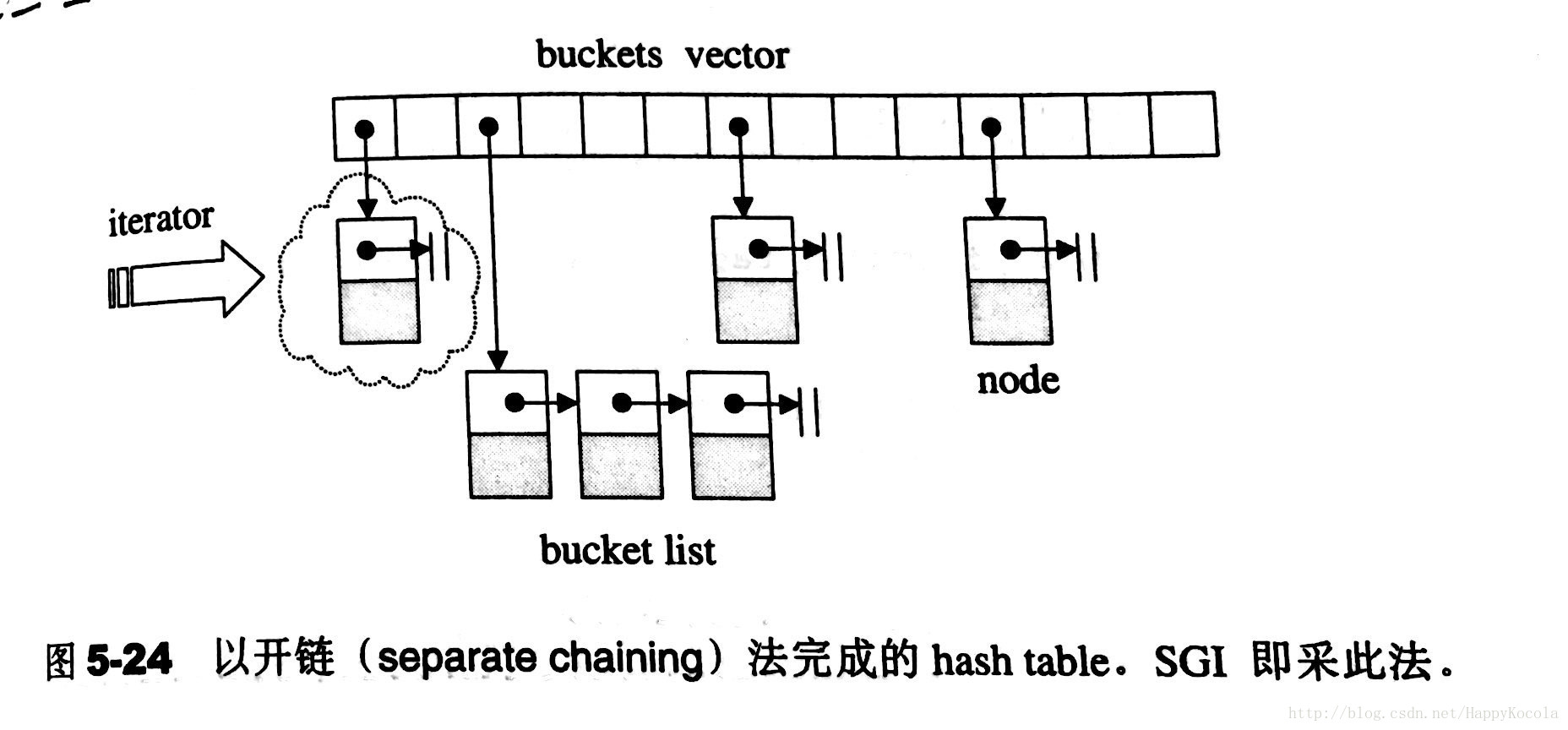
| 特性 | map | unordered_map |
|---|---|---|
| 元素排序 | 严格弱序 | 无 |
| 常见实现 | 平衡树或红黑树 | 哈希表 |
| 查找时间 | O(log(n)) | 平均 O(1),最坏 O(n)(哈希冲突) |
| 插入时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 删除时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 需要比较器 | 只需 < 运算符 |
只需 == 运算符 |
| 需要哈希函数 | 不需要 | 需要 |
| 常见用例 | 当无法提供良好哈希函数或哈希 | 在大多数其他情况下。当顺序不重要时 |
| 函数太慢,或者需要有序时 |
map的value是int,默认为0。可以直接++
1 |
|
1 | // insert 不能覆盖元素,已经存在会失败 |
1 | mymap.erase ('c'); // erasing by key |
1 | //unordered_map 类模板中,还提供有 at() 成员方法,和使用 [ ] 运算符一样,at() 成员方法也需要根据指定的键,才能从容器中找到该键对应的值; |
常用于 一个值是否存在 的相关问题
set(关键字即值,即只保存关键字的容器);使用红黑树,自动排序,关键字唯一。multiset(关键字可重复出现的set);unordered_set(用哈希函数组织的set);unordered_multiset(哈希组织的set,关键字可以重复出现)。默认红黑树,使用std::less 作为比较器, 升序序列。
| 存放数据类型 | 排序规则 |
|---|---|
| 整数、浮点数等 | 按从小到大的顺序排列 |
| 字符串 | 按字母表顺序排列 |
| 指针 | 按地址升序排列 |
| 指向某元素的指针 | 按指针地址递增的顺序排列 |
| 类(自定义) | 可以自定义排序规则 |
1 | // 自定义比较器,按降序排列 |
1 | //增改 |
并查集的基本操作
UnionFind(int n):每个元素初始化为自己的父节点。int find(int x):查找某个元素的根节点,并进行路径压缩以优化后续查找。int find(int x):将两个元素所在的集合合并为一个集合。核心是
C++ 中的容器适配器 stack、queue 和 priority_queue 依赖不同的基础容器来实现特定的数据结构行为。每种容器适配器都有特定的成员函数要求,默认选择的基础容器是为了更好地满足这些要求。
| 容器适配器 | 基础容器筛选条件 | 默认使用的基础容器 |
|---|---|---|
| stack | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- back() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque、list。 |
||
| queue | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- front() |
||
- back() |
||
- push_back() |
||
- pop_front() |
||
满足条件的基础容器有 deque、list。 |
||
| priority_queue | 基础容器需包含以下成员函数: | vector |
- empty() |
||
- size() |
||
- front() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque。 |
堆栈,先进先出
1 | stack<int> minStack; |
注意pop仅用于从堆栈中删除元素,并且没有返回值, 一般用法如下
1 | top_value = stIn.top(); |
1 |
|
deque 容器也擅长在序列尾部添加或删除元素(时间复杂度为O(1)),而不擅长在序列中间添加或删除元素。
1 |
|
1 |
|
1 | //降序队列(默认less<>), map/set默认也是使用less,但是是升序序列 |
一般是题目要求自己实现链表,而不是使用STL提供的链表list。
1 | // 单链表 |
STL list 容器,又称双向链表容器,即该容器的底层是以双向链表的形式实现的。
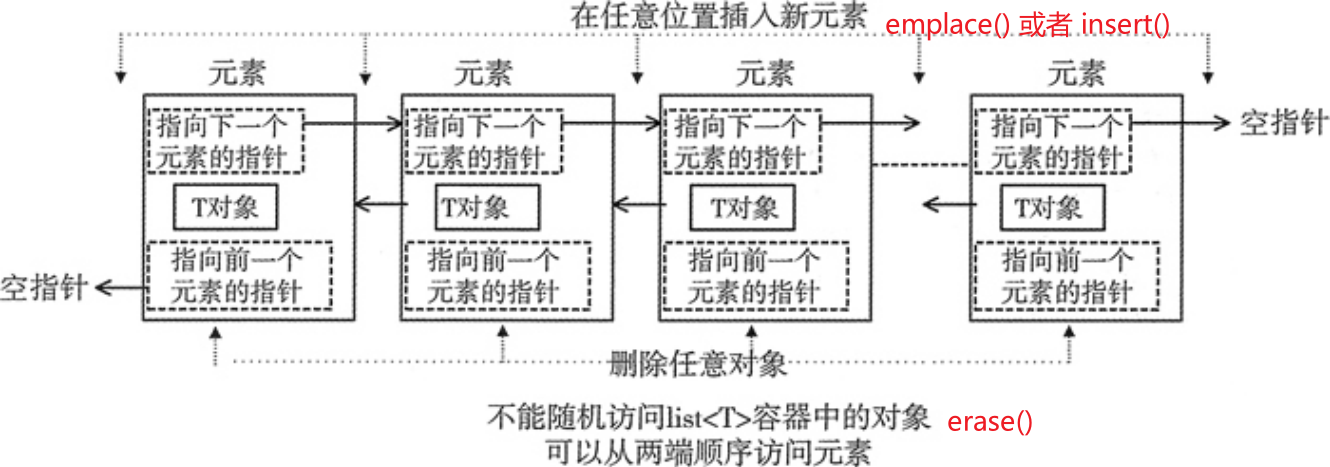
find()语法,经常使用unorder_map<key, list<xxx>::iterator> listMap保存元素位置来加速查找。for (it = list.begin(); it != list.end(); it++) if (it->key == key) break;1 | //插入 |
1 | int array[2][3] = { |
1 |
|

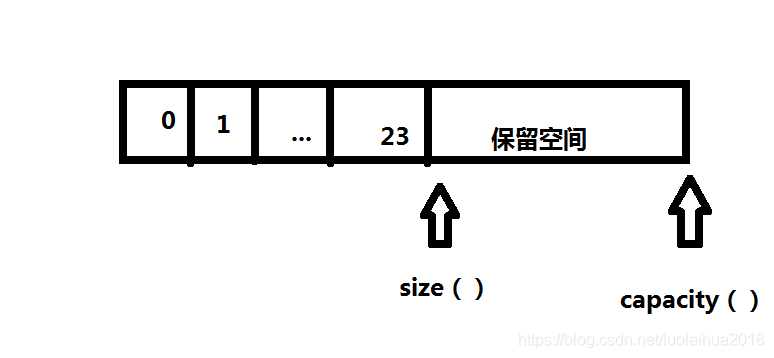
vector是变长的连续存储:
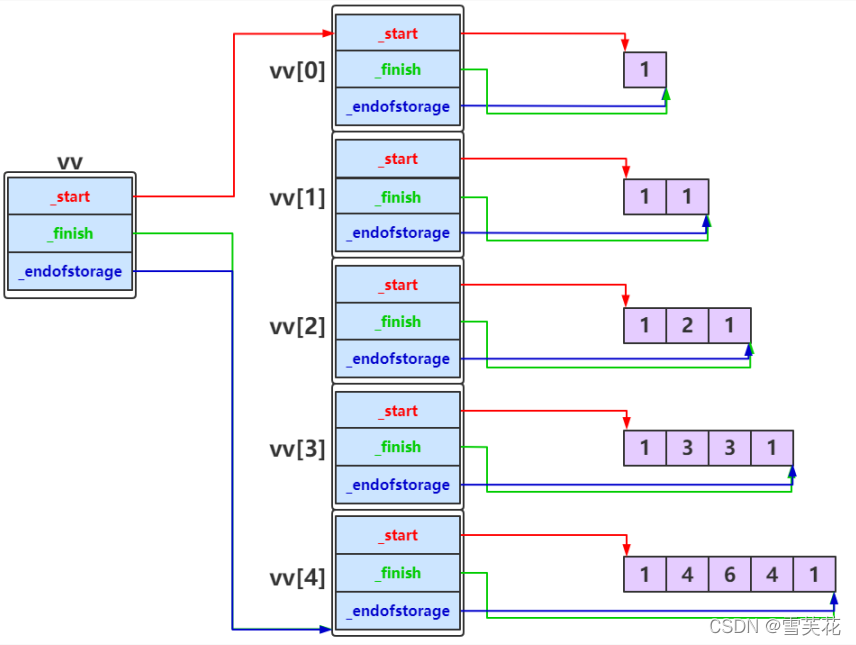
1 | //创建一个vector,元素个数为nSize |
1 | //改变大小,预分配空间,增加 vector 的容量(capacity),但 size 保持不变。 |
vector 也支持中间insert元素,但是性能远差于list。
1 | void push_back(const T& x) //向量尾部增加一个元素X |
1 | iterator erase(iterator it) :删除向量中迭代器指向元素 |
1 | void swap(vector&) :交换两个同类型向量的数据 |
1 | reference at(int pos) :返回pos位置元素的引用 |
返回表示
1 | vector<int> func() { |
1 |
|
static_cast 用于良性类型转换,一般不会导致意外发生,风险很低。
hash <K> 模板专用的算法取决于实现,但是如果它们遵循 C++14 标准的话,需要满足一些具体的要求。这些要求如下:
[^1]: How to use unordered_set with custom types?
https://www.runoob.com/w3cnote/cpp-vector-container-analysis.html
【C++容器】数组和vector、array三者区别和联系
https://blog.51cto.com/liangchaoxi/4056308
https://blog.csdn.net/y601500359/article/details/105297918
————————————————
版权声明:本文为CSDN博主「stitching」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40250056/article/details/114681940
————————————————
版权声明:本文为CSDN博主「FishBear_move_on」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/haluoluo211/article/details/80877558
————————————————
版权声明:本文为CSDN博主「SOC罗三炮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/luolaihua2018/article/details/109406092
————————————————
版权声明:本文为CSDN博主「鱼思故渊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yusiguyuan/article/details/40950735
虽然MPI属于OSI参考模型的第5层和更高层,但实现可以覆盖大多数层,其中在传输层中使用套接字和传输控制协议(TCP)。
MPI hardware research focuses on implementing MPI directly in hardware, for example via processor-in-memory, building MPI operations into the microcircuitry of the RAM chips in each node. By implication, this approach is independent of language, operating system, and CPU, but cannot be readily updated or removed.
MPI硬件研究的重点是直接在硬件中实现MPI,例如通过内存处理器,将MPI操作构建到每个节点中的RAM芯片的微电路中。通过暗示,这种方法独立于语言、操作系统和CPU,但是不能容易地更新或删除。
Another approach has been to add hardware acceleration to one or more parts of the operation, including hardware processing of MPI queues and using RDMA to directly transfer data between memory and the network interface controller(NIC 网卡) without CPU or OS kernel intervention.
另一种方法是将硬件加速添加到操作的一个或多个部分,包括MPI队列的硬件处理以及使用RDMA在存储器和网络接口控制器之间直接传输数据,而无需CPU或OS内核干预。
进程间通信都是Inter-process communication(IPC)的一种。常见有如下几种:
|mkfifo,具有p的文件属性线程共享存储器编程模型(如Pthreads和OpenMP)和消息传递编程(MPI/PVM)可以被认为是互补的,并且有时在具有多个大型共享存储器节点的服务器中一起使用。
后四个是MPI-2独有的
1 | #include <unistd.h> |
输出X个当前机器hostname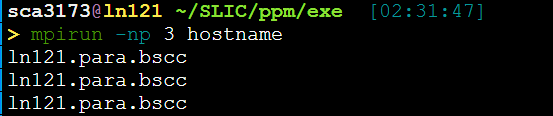
mpirun -np 6 -machinefile ./machinelist ./a.out 即可多节点执行。
MPI_Finalize()之后 ,MPI_Init()之前
https://www.open-mpi.org/doc/v4.0/man3/MPI_Init.3.php
不同的进程是怎么处理串行的部分的?都执行(重复执行?)。执行if(rank=num),那岂不是还要同步MPI_Barrier()。
而且写同一个文件怎么办?
MPI的两种最基本的并行程序设计模式 即对等模式和主从模式。
对等模式:各个部分地位相同,功能和代码基本一致,只不过是处理的数据或对象不同,也容易用同样的程序来实现。
主从模式:分为主进程和从进程,程序通信进程之间的一种主从或依赖关系 。MPI程序包括两套代码,主进程运行其中一套代码,从进程运行另一套代码。
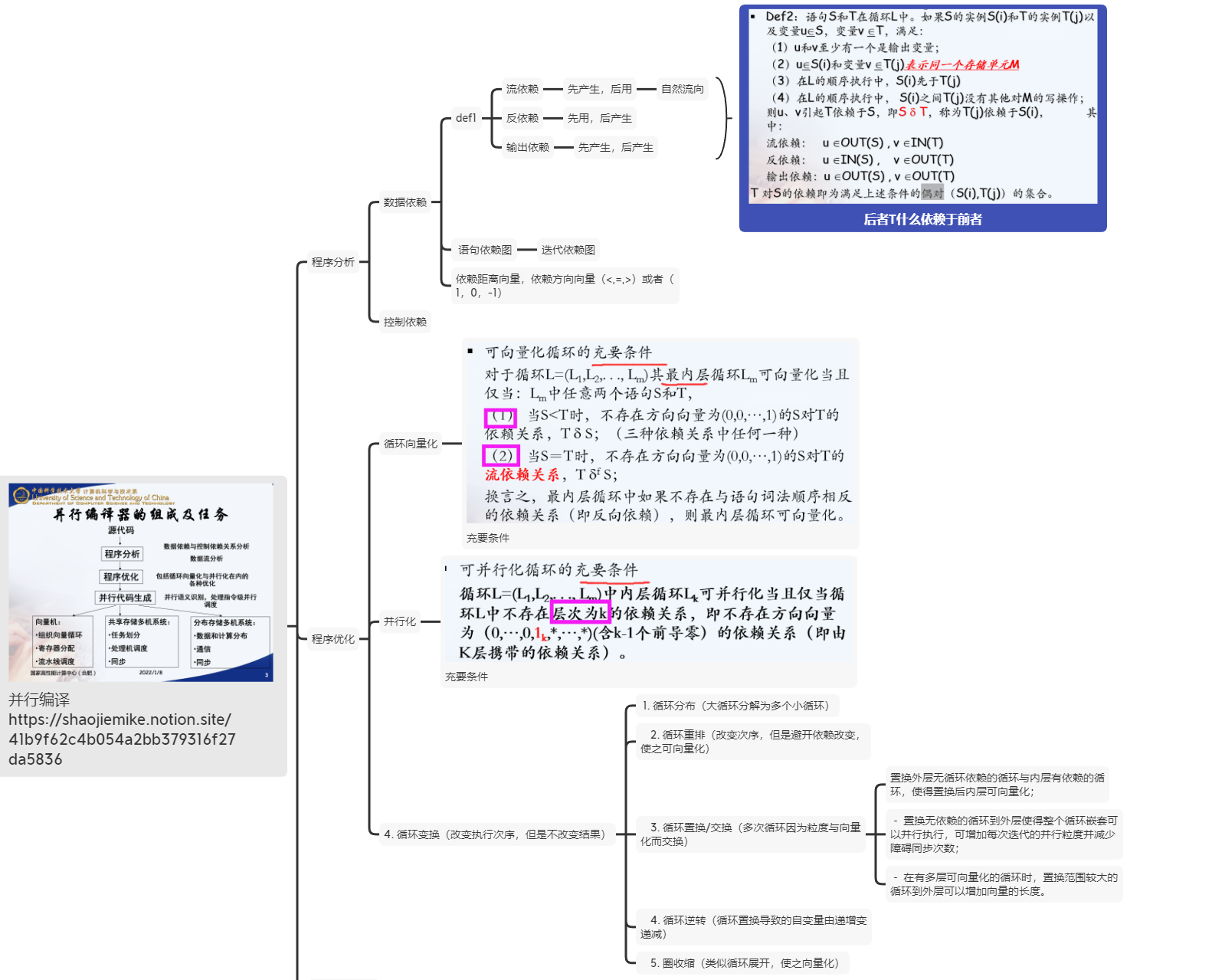
圈收缩(cycle shrinking)-此变换技术一般用于依赖距离大于1的循环中,它将一个串行循环分成两个紧嵌套循环,其中外层依然串行执行,而内层则是并行执行(一般粒度较小)
https://shaojiemike.notion.site/41b9f62c4b054a2bb379316f27da5836

MPI_PACKED预定义数据类型被用来实现传输地址空间不连续的数据项 。
1 | int MPI_Pack(const void *inbuf, |

The input value of position is the first location in the output buffer to be used for packing. position is incremented by the size of the packed message,
and the output value of position is the first location in the output buffer following the locations occupied by the packed message. The comm argument is the communicator that will be subsequently used for sending the packed message.
1 | //Returns the upper bound on the amount of space needed to pack a message |

例子:
这里的A+i*j应该写成A+i*2吧???
来定义由数据类型不同且地址空间不连续的数据项组成的消息。
1 | //启用与弃用数据类型 |

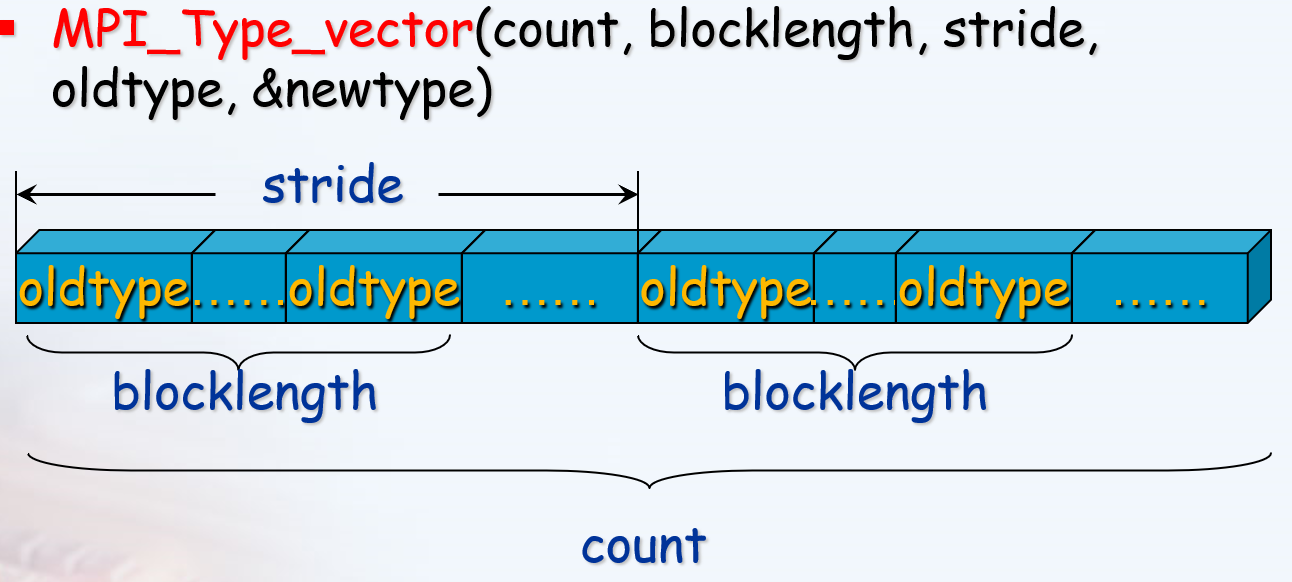
1 | //成块的相同元素组成的类型,块长度和偏移由参数指定 |

1 | //由不同数据类型的元素组成的类型, 块长度和偏移(肯定也不一样)由参数指定 |

MPI_Cart_create
确定了虚拟网络每一维度的大小后,需要为这种拓扑建立通信域。组函数MPI_Cart_create可以完成此任务,其声明如下:
1 | // Makes a new communicator to which topology拓扑 information has been attached |
1 | int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm * newcomm) |
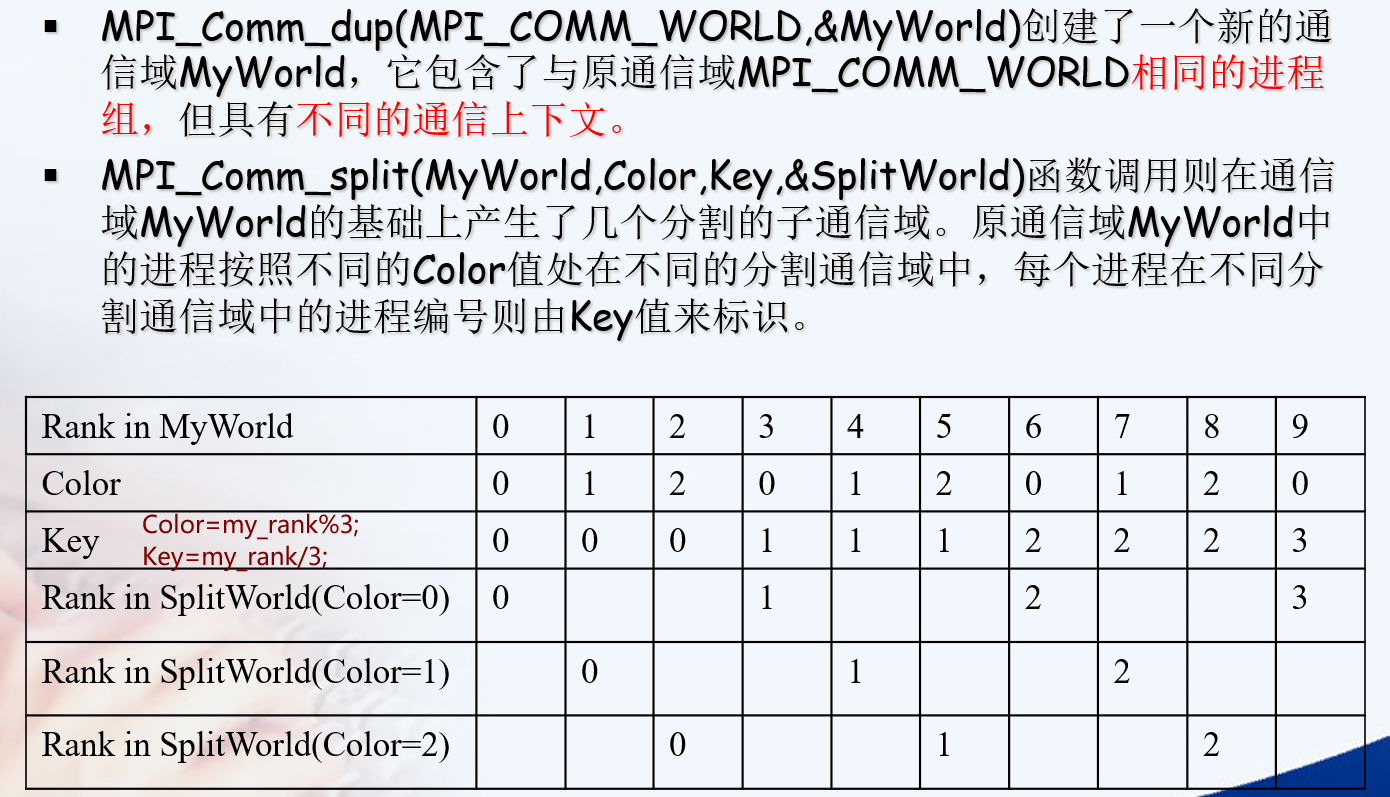
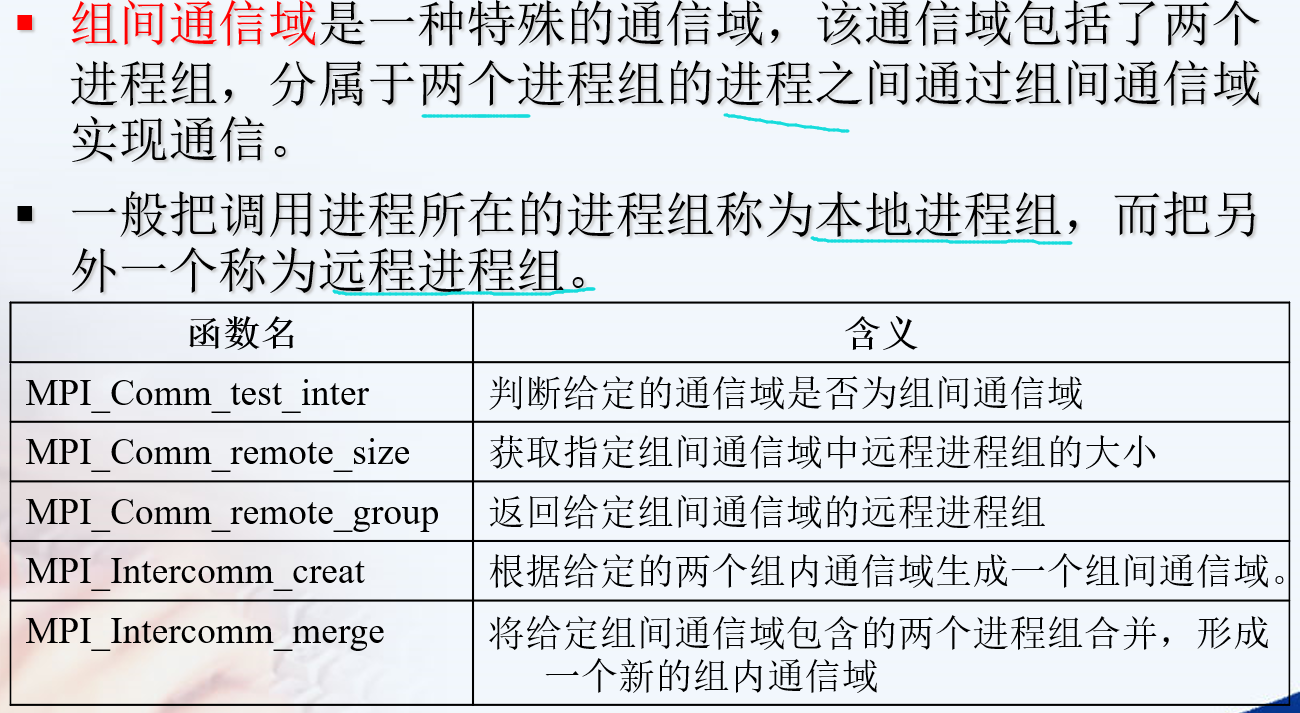
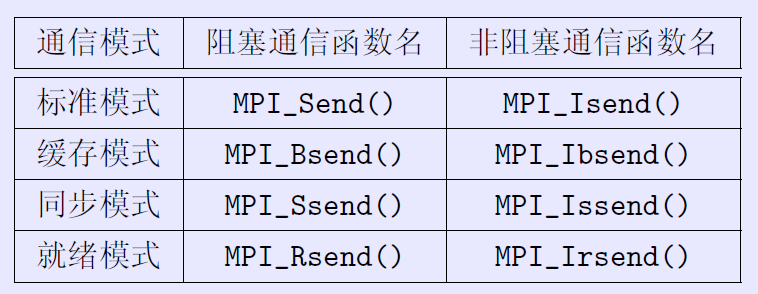
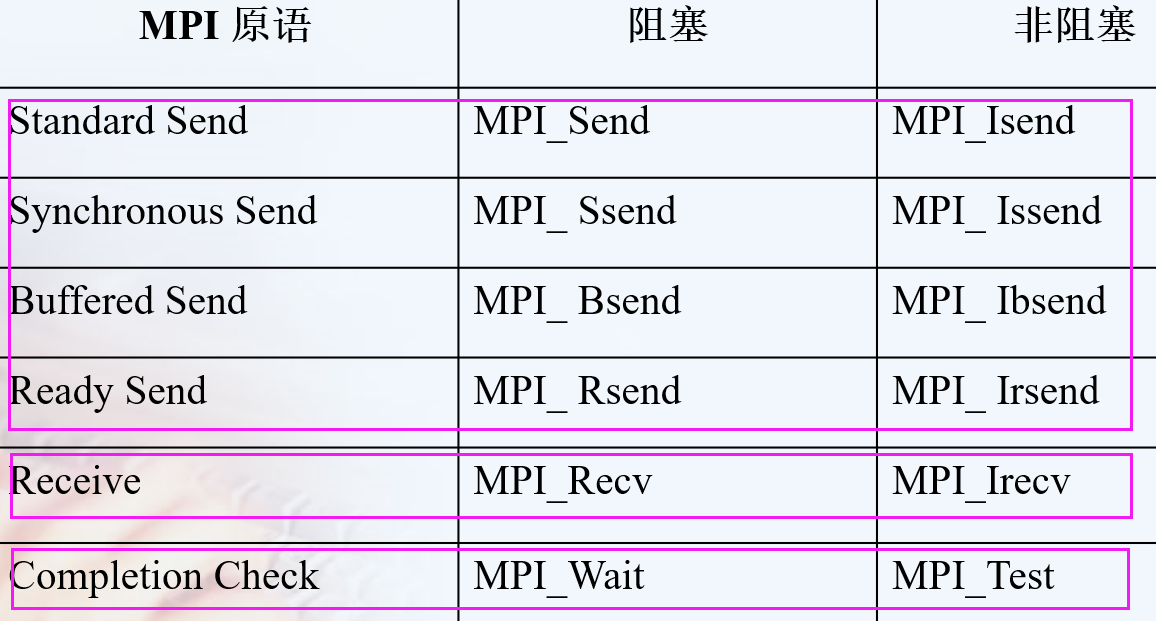
特殊的函数
1 | int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype, |
特别适用于在进程链(环)中进行“移位”操作,而避免在通讯为阻塞方式时出现死锁。
There is also another error. The MPI standard requires that the send and the receive buffers be disjoint不相交 (i.e. they should not overlap重叠), which is not the case with your code. Your send and receive buffers not only overlap but they are one and the same buffer. If you want to perform the swap in the same buffer, MPI provides the MPI_Sendrecv_replace operation.
1 | //MPI标准阻塞通信函数,没发出去就不会结束该命令。 |

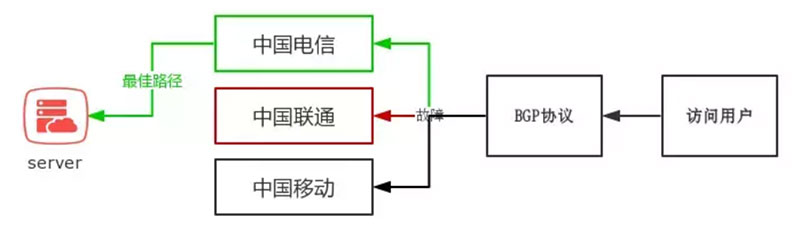
可能大家会想到这会死锁,如下图:
但是实际情况可能并不会死锁,这与调用的MPI库的底层实现有关。

MPI_Send将阻塞,直到发送方可以重用发送方缓冲区为止。当缓冲区已发送到较低的通信层时,某些实现将返回给调用方。当另一端有匹配的MPI_Recv()时,其他一些将返回到呼叫者。
但是为了避免这种情况,可以调换Send与Recv的顺序,或者**使用MPI_Isend()或MPI_Issend()**代替非阻塞发送,从而避免死锁。
1 | /* |
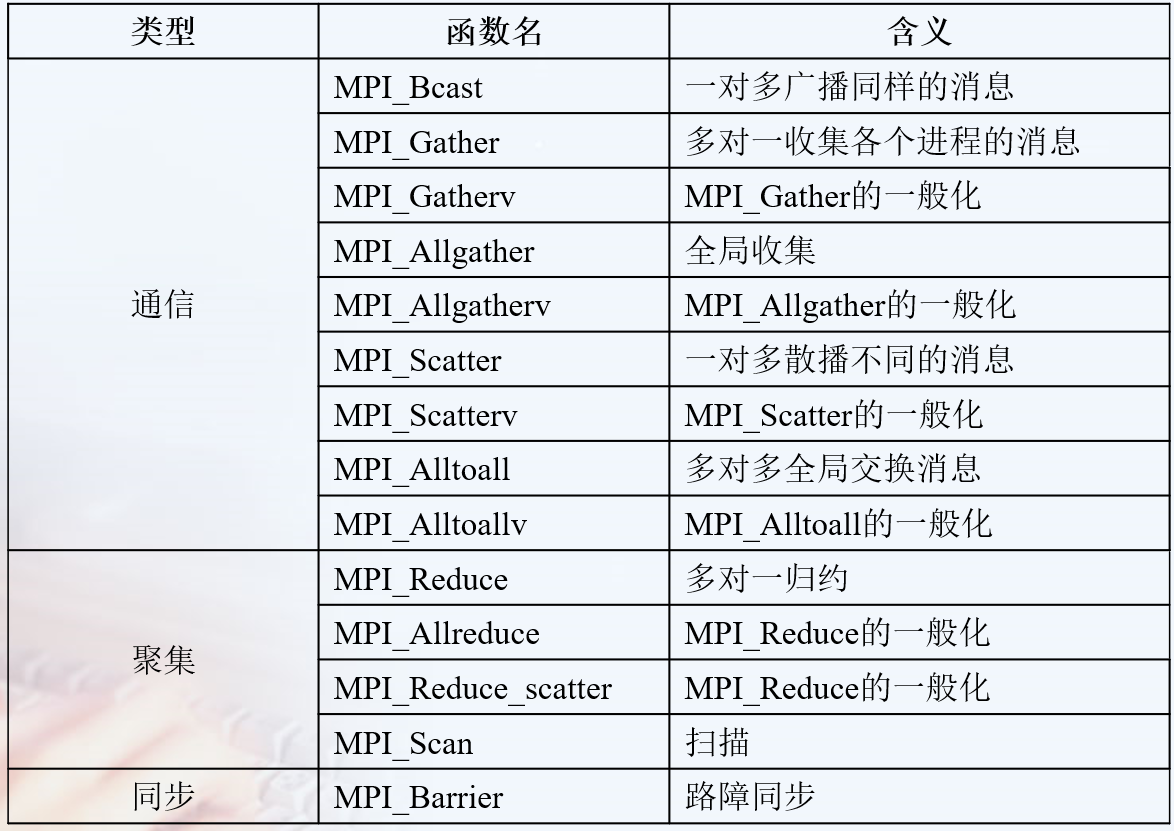
一个进程组中的所有进程都参加的全局通信操作。
实现三个功能:通信、聚集和同步。
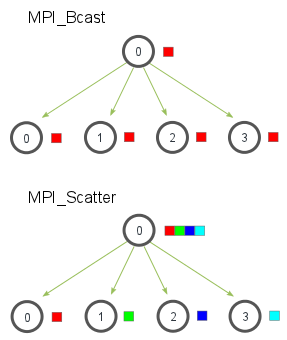
1 | //将一个进程中得数据发送到所有进程中的广播函数 |
注意data_p在root 或者scr_process进程里是发送缓存也是接收缓存,但是在其余进程里是接收缓存。
MPI_Scatter?
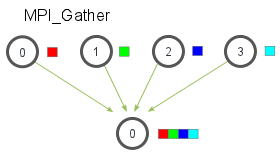
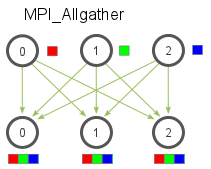
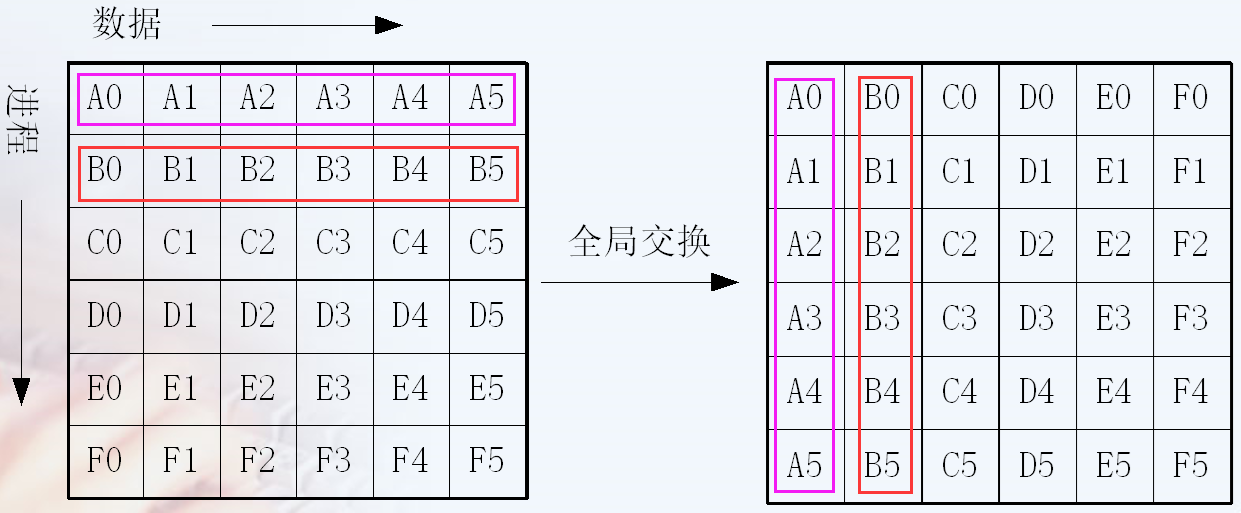
1 | int MPI_Allgather(void * sendbuff, int sendcount, MPI_Datatype sendtype, |
number of elements received from any process (integer)
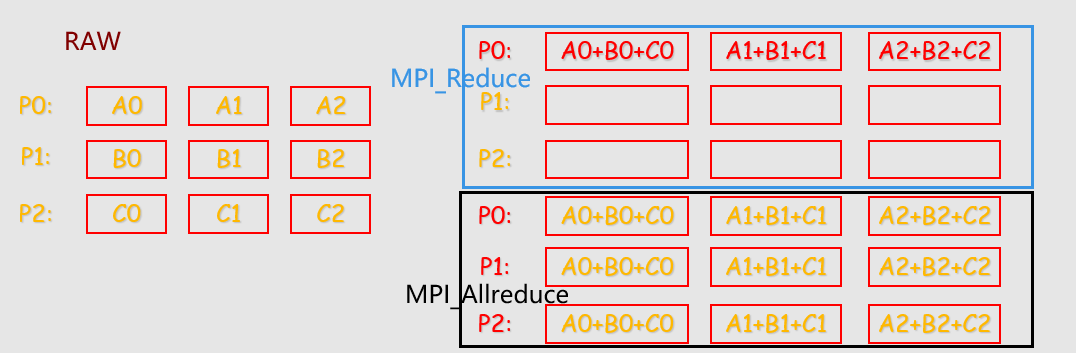
MPI聚合的功能分三步实现
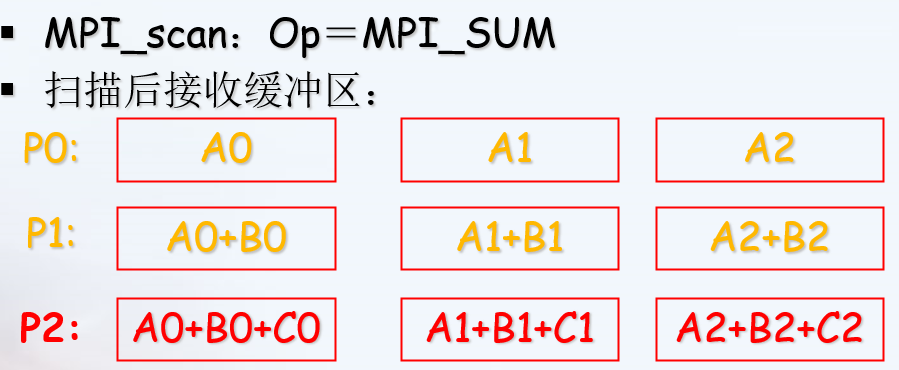
MPI提供了两种类型的聚合操作: 归约和扫描。
1 | int MPI_Reduce( |
1 | int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op) |
用户自定义函数 functiontypedef void MPI_User_function(void *invec, void *inoutvec, int *len, MPI_Datatype *datatype)
1 | for(i=0;i<*len;i++) { |
必须具备四个参数:
也可以认为invec和inoutvec 是函数中长度为len的数组, 归约的结果重写了inoutvec 的值。
1 | /* |
MPI_Group https://www.rookiehpc.com/mpi/docs/mpi_group.php
并行IO文件
1997年推出了MPI的最新版本MPI-2
MPI-2加入了许多新特性,主要包括
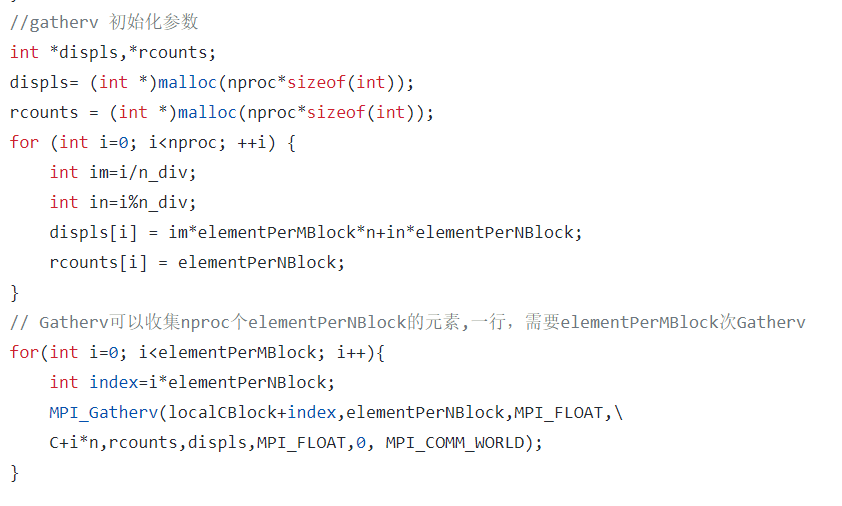
数据发送和收集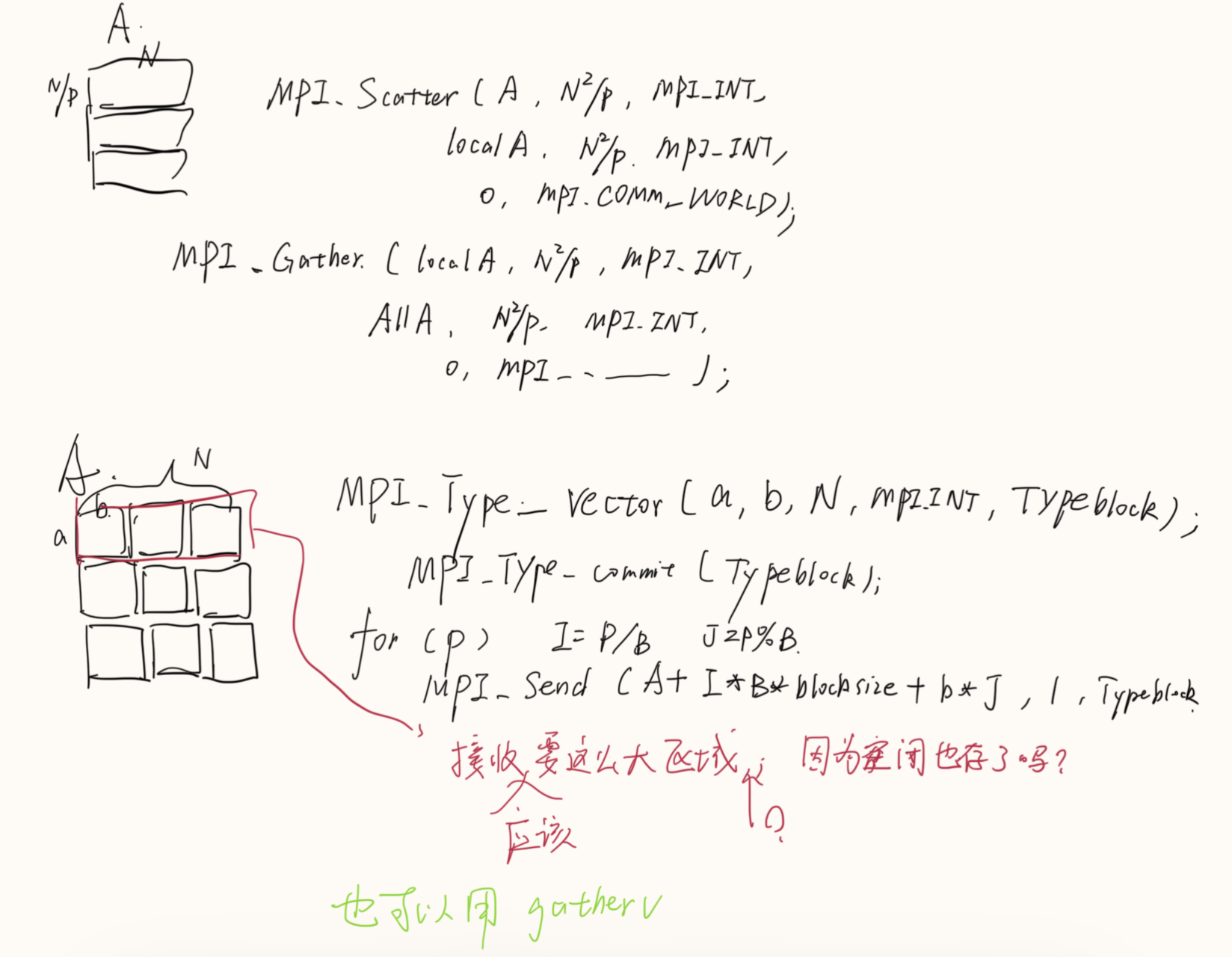
https://blog.csdn.net/susan_wang1/article/details/50033823
https://blog.csdn.net/u012417189/article/details/25798705
是否死锁: https://stackoverflow.com/questions/20448283/deadlock-with-mpi
https://mpitutorial.com/tutorials/
http://staff.ustc.edu.cn/~qlzheng/pp11/ 第5讲写得特别详细
vpn:英文全称是“Virtual Private Network”,翻译过来就是“虚拟专用网络”。vpn通常拿来做2个事情:
一句话,vpn在IP层工作,而ss在TCP层工作。

理解 VPN 路由(以及任何网络路由)配置的关键是认识到一个 IP packet 如何被传输,以下描述的是极度简化后的单向传输过程:
为什么机器 A 的本地路由表里会有 172.29.1.0/24 这个网段的路由规则?通常情况下,这是 OpenVPN 服务端推送给客户端,由客户端在建立 VPN 连接时自动添加的。也可以由服务端自定义,比如wireguard
这个时候,如果机器 B 想要回复 A(比如发个 ACK),就会出问题,因为 packet 的来源地址还是 10.8.0.123, 而 10.8.0.0/24 网段并不属于当前局域网,是 VPN 服务端私有的——机器 B 往 10.8.0.123 发送的 ACK 会在某个位置(比如默认网关)遇到 “host unreachable” 而被丢弃。对于机器 A 来说,表面现象可能是连接超时或 ping 不通。
解决方法是,在 packet 离开 VPN 服务端时,将其「伪装」成来自 172.29.0.3(举例VPN 服务端的局域网地址),这样机器 B 发送的 ACK 就能顺利回到 VPN 服务端,然后发给机器 A. 这就是所谓的 SNAT。
在 Linux 系统中由 iptables 来管理,具体命令是:
1 | iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE. |
连接 OpenVPN 的两个 client 之间可以互相通信,这是因为服务端推送的路由里包含了对应的网段。但是想从 Client A 到达 Client B 所在局域网的其他机器,还需要额外的配置。因为 OpenVPN 服务端缺少 Client B 局域网相关的路由规则。
1 | server.conf |
在前两节所给的配置基础上,只需要再加一点配置,就能实现 OpenVPN 服务端所在局域网与客户端所在局域网的互访。配置内容是,在各自局域网的默认网关上添加路由,将对方局域网网段的下一跳设为 OpenVPN 服务端 / 客户端所在机器,同时用 iptables 配置相应的 SNAT 规则。
Based on the info in clashio, we select some cheap vpns to try.
| name | 每月价格(¥/GB/off on holiday) | 每月单价(GB/¥) | 每年单价(GB/¥) | 节点数与稳定性 | 使用速度感觉 |
|---|---|---|---|---|---|
| fastlink 2019 | 20/100/-30% | 5 | 100+, 节点速度高达5Gbps | 峰值 5Gbps (1) | |
| totoro 2023 | 15/100/-20%(2) | 6.6 | ??? | ??? | |
| 冲浪猫 2022 | 16/200/-12%(3) | 12.5 | ??? | 峰值 1Gbps | |
| 奈云机场 2021 | 10.6/168/-30%(4) | 15.8 | 230624购买,240109几天全面掉线 | 峰值 5Gbps (6) | |
| FatCat 2023 | 6/60/-20% | 10 | ??? | 峰值 xx Gbps |
!!! question annotate “My Choice: 单价,大小,速度,优惠码有效期”
1. 优惠码(春节 中秋 双十一)
1. [fastlink](https://v02.fl-aff.com/auth/register?code=rotu) 用了两年了,还是x3很快的。但是相当于一个月只有30GB, 不够用。
3. [奈云机场](https://www.naiun2.top/#/register?code=gL7mHyh9)(可靠性暂时不行),[冲浪猫](https://b.msclm.net/#/register?code=AAUF1Efg) 平衡比较好。
现在组合:奈云机场(2) + fastlink。 等fastlink过期了(1),看要不要转成 冲浪猫。
&flag=clash下载config.yamlbrook vpn+ Amazon American node
[^1]: BGP 漫谈

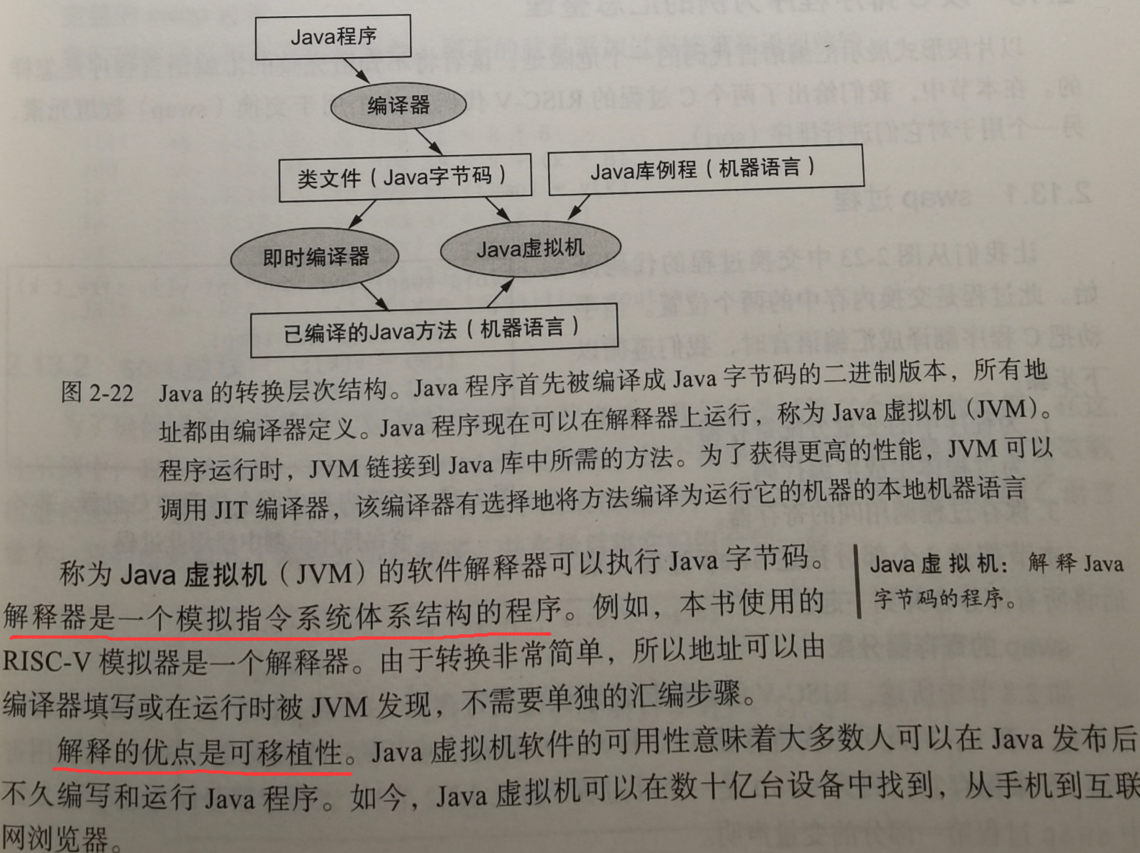

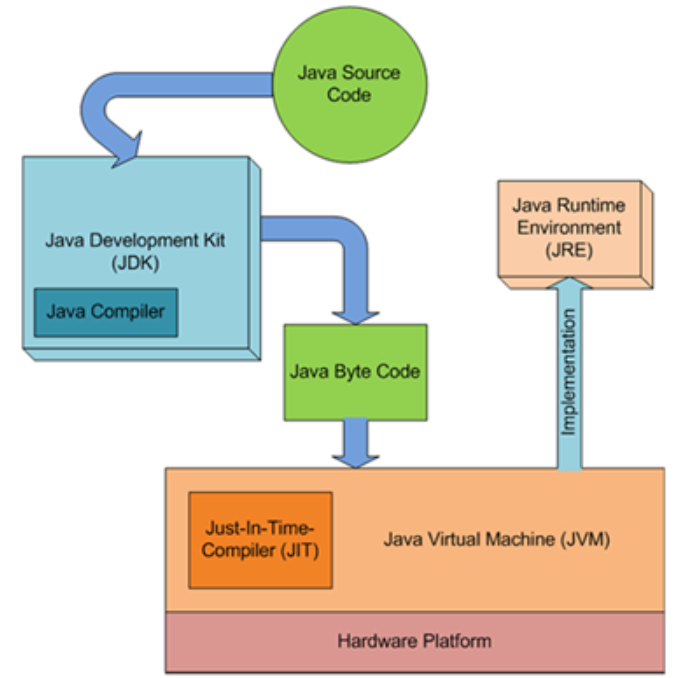
java 21 SDK seems not contain Java Control Panel (javacpl.exe), you need to install Java SE Development Kit 8u381 which include JDK 1.8 and JRE 1.8https://www.topcoder.com to allowed website (Attention: https)ContestAppletProd.jnlp127.0.0.1 proxy and HTTP TUNE 1 to connect to server暂无
暂无
Disk C: make room for installation
C 盘没空间了,啊啊啊~