way1: Linux transparent huge page (THP) support allows the kernel to automatically promote regular memory pages into huge pages, cat /sys/kernel/mm/transparent_hugepage/enabled but achieve this needs some details.
way2: Huge pages are allocated from a reserved pool which needs to change sys-config. for example echo 20 > /proc/sys/vm/nr_hugepages. And you need to write speacial C++ code to use the hugo page
1 2 3 4
# using mmap system call to request huge page mount -t hugetlbfs \ -o uid=<value>,gid=<value>,mode=<value>,pagesize=<value>,size=<value>,\ min_size=<value>,nr_inodes=<value> none /mnt/huge
without recompile
But there is a blog using unmaintained tool hugeadm and iodlr library to do this.
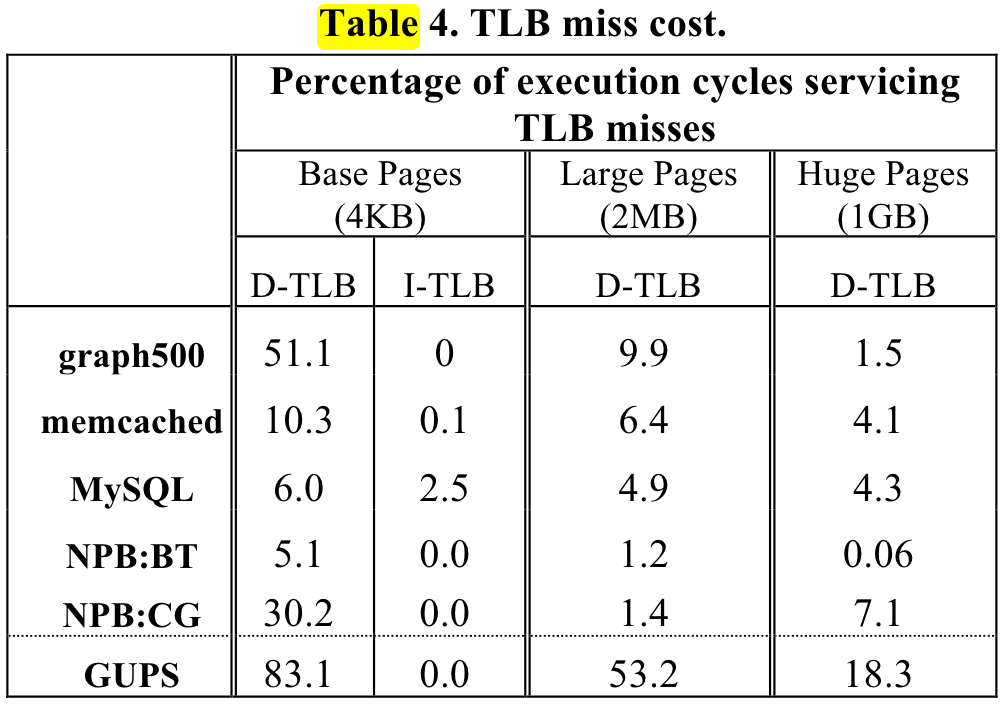
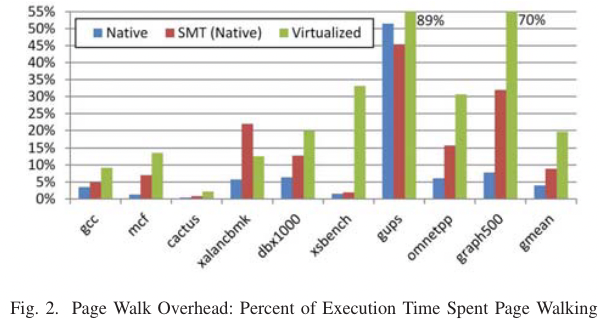
Any algorithm that does random accesses into a large memory region will likely suffer from TLB misses. Examples are plenty: binary search in a big array, large hash tables, histogram-like algorithms, etc.
try: # sth except Exception as e: # 可以使用rich包 pprint.pprint(list) raise e finally: un_set()
for
间隔值
调参需要测试间隔值
1 2
for i inrange(1, 101, 3): print(i)
遍历修改值
使用 enumerate 函数结合 for 循环遍历 list,以修改 list 中的元素。
enumerate 函数返回一个包含元组的迭代器,其中每个元组包含当前遍历元素的索引和值。在 for 循环中,我们通过索引 i 修改了列表中的元素。
1 2 3 4 5
# 对于 二维list appDataDict baseline = appDataDict[0][0] # CPU Total for i, line inenumerate(appDataDict): for j, entry inenumerate(line): appDataDict[i][j] = round(entry/baseline, 7)
rows = max(len(list1), len(list2)) cols = max(len(row) for row in list1 + list2)
result = [[0] * cols for _ inrange(rows)]
for i inrange(rows): for j inrange(cols): if i < len(list1) and j < len(list1[i]): result[i][j] += list1[i][j] if i < len(list2) and j < len(list2[i]): result[i][j] += list2[i][j]
print(result)
# 将一个二维列表的所有元素除以一个数A result = [[element / A for element in row] for row in list1]
a_dict = {'color': 'blue'} for key in a_dict: print(key) # color for key in a_dict: print(key, '->', a_dict[key]) # color -> blue for item in a_dict.items(): print(item) # ('color', 'blue') for key, value in a_dict.items(): print(key, '->', value) # color -> blue
# 判断是否存在指定的键 if my_dict.get("key2") isnotNone: print("Key 'key2' exists in the dictionary.") else: print("Key 'key2' does not exist in the dictionary.")