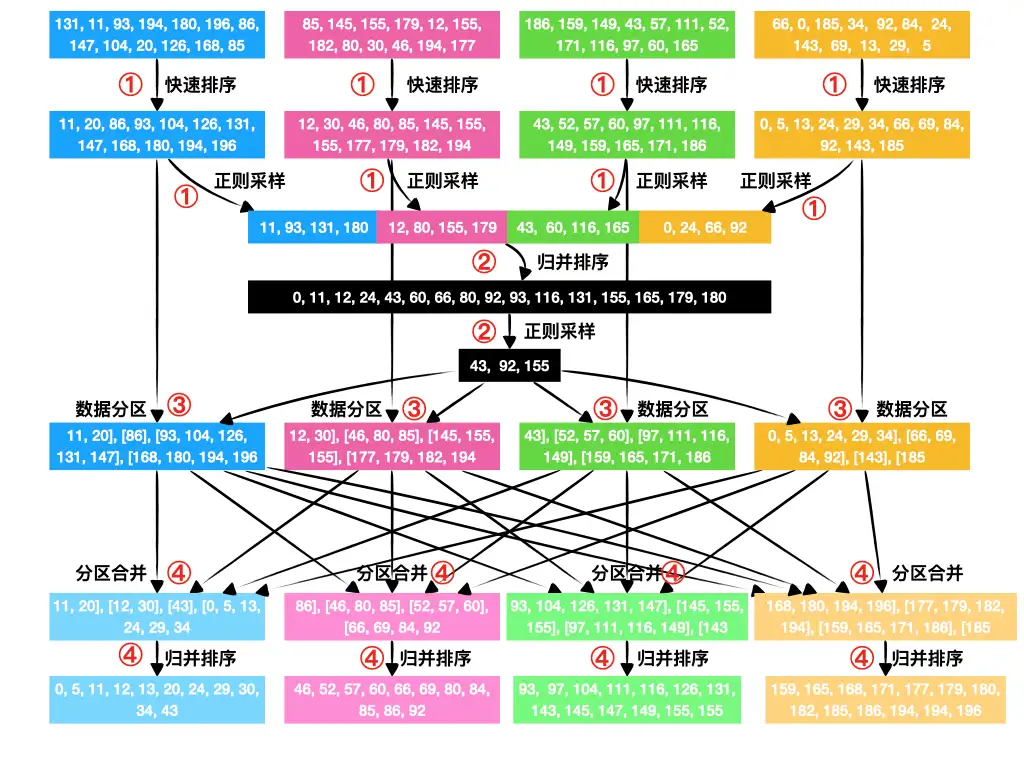
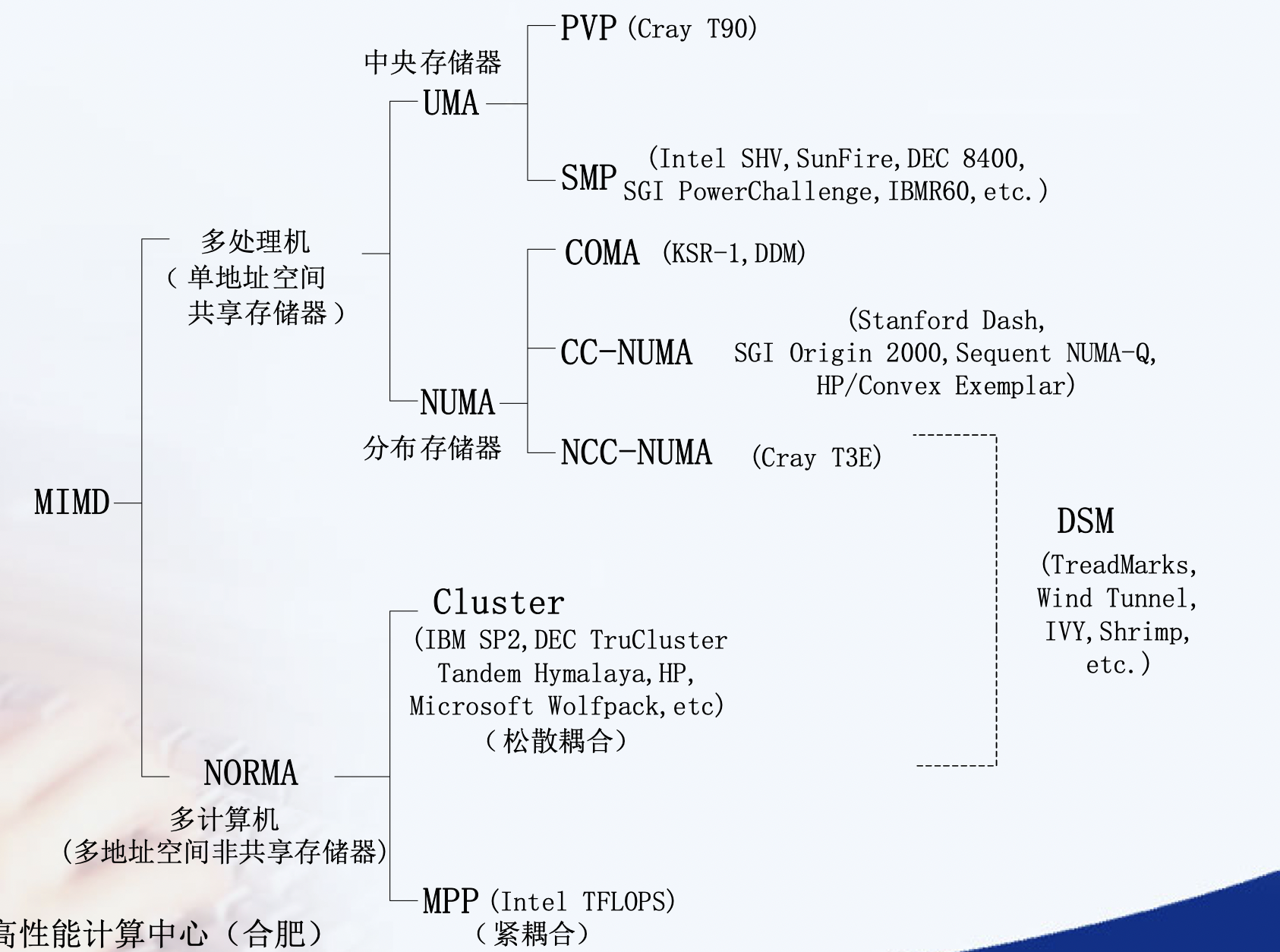
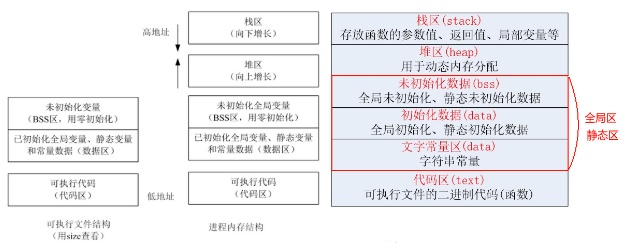
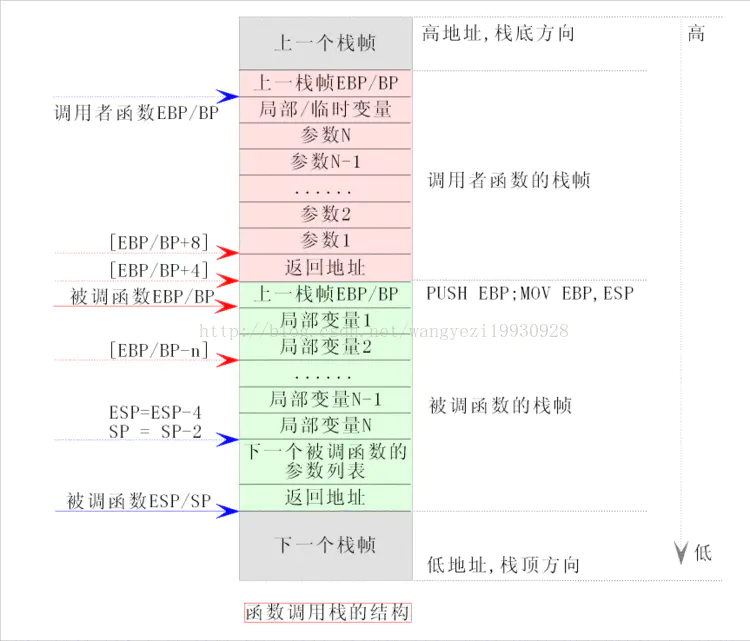
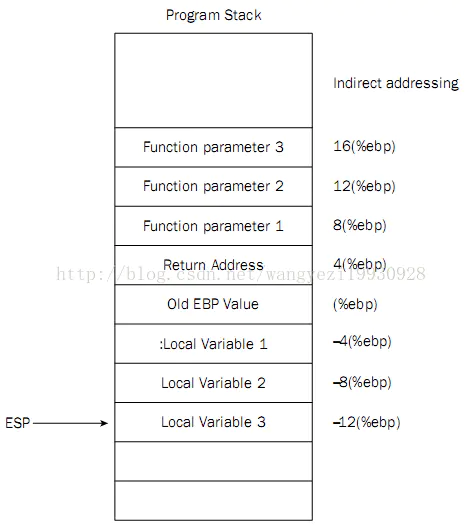
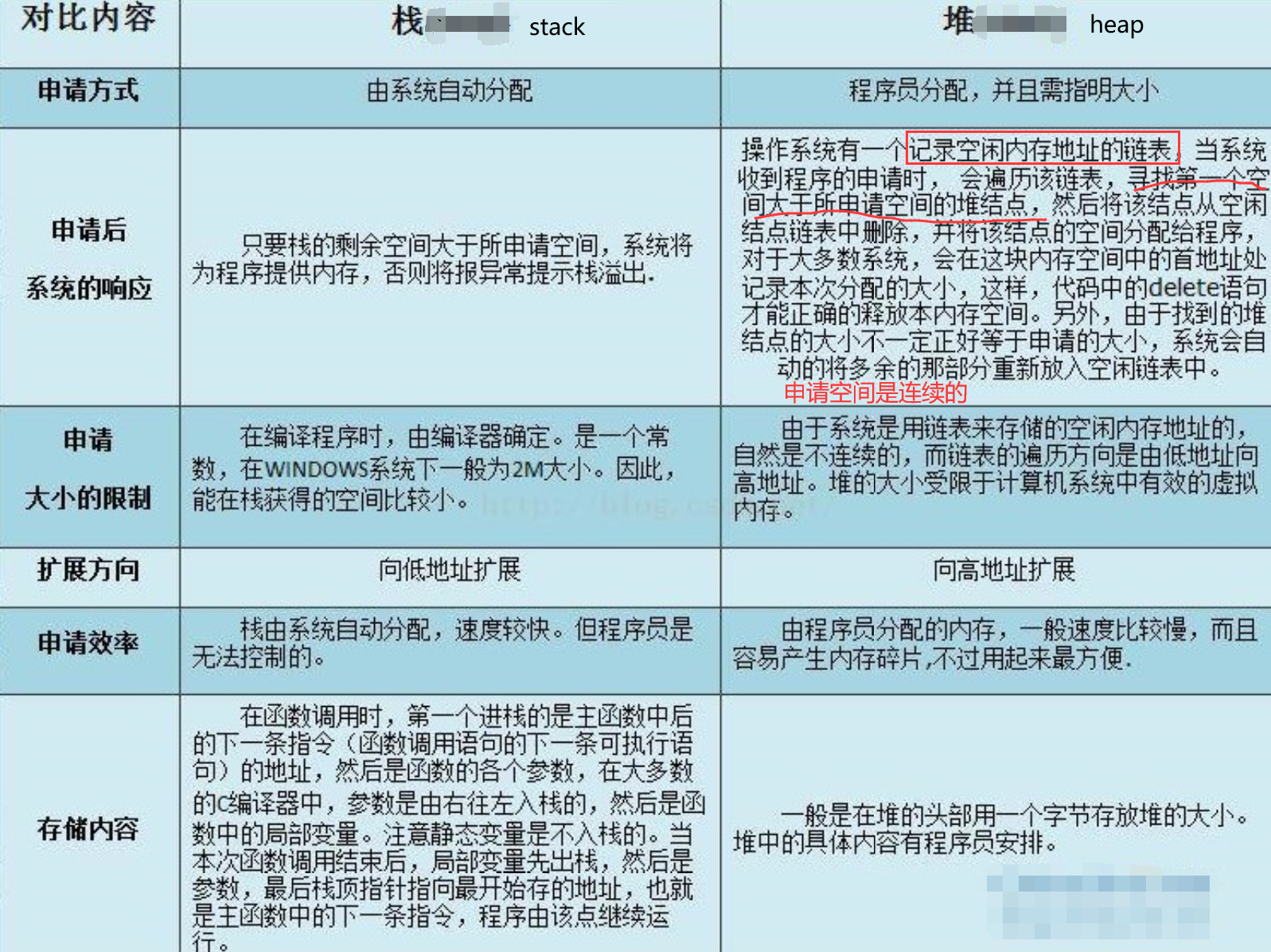
NUMA : NUMA (non-uniform memory access) is a method of configuring a cluster of microprocessor in a multiprocessing system so that they can share memory locally, improving performance and the ability of the system to be expanded. NUMA is used in a symmetric multiprocessing ( SMP ) system.
Remote Direct Memory Access (RDMA) is an extension of the Direct Memory Access (DMA) technology, which is the ability to access host memory directly without CPU intervention. RDMA allows for accessing memory data from one host to another.
远程直接内存访问(英语:Remote Direct Memory Access,RDMA)是一种从一台计算机的内存到另一台计算机的内存的直接内存访问,而不涉及任何一台计算机的操作系统。这允许高吞吐量、低延迟联网,这在大规模并行计算机集群中特别有用。
Most high performance computing clusters are nowadays composed of large multicore machines that expose Non-Uniform Memory Access (NUMA), and they are interconnected using modern communication paradigms, such as Remote Direct Memory Access (RDMA).
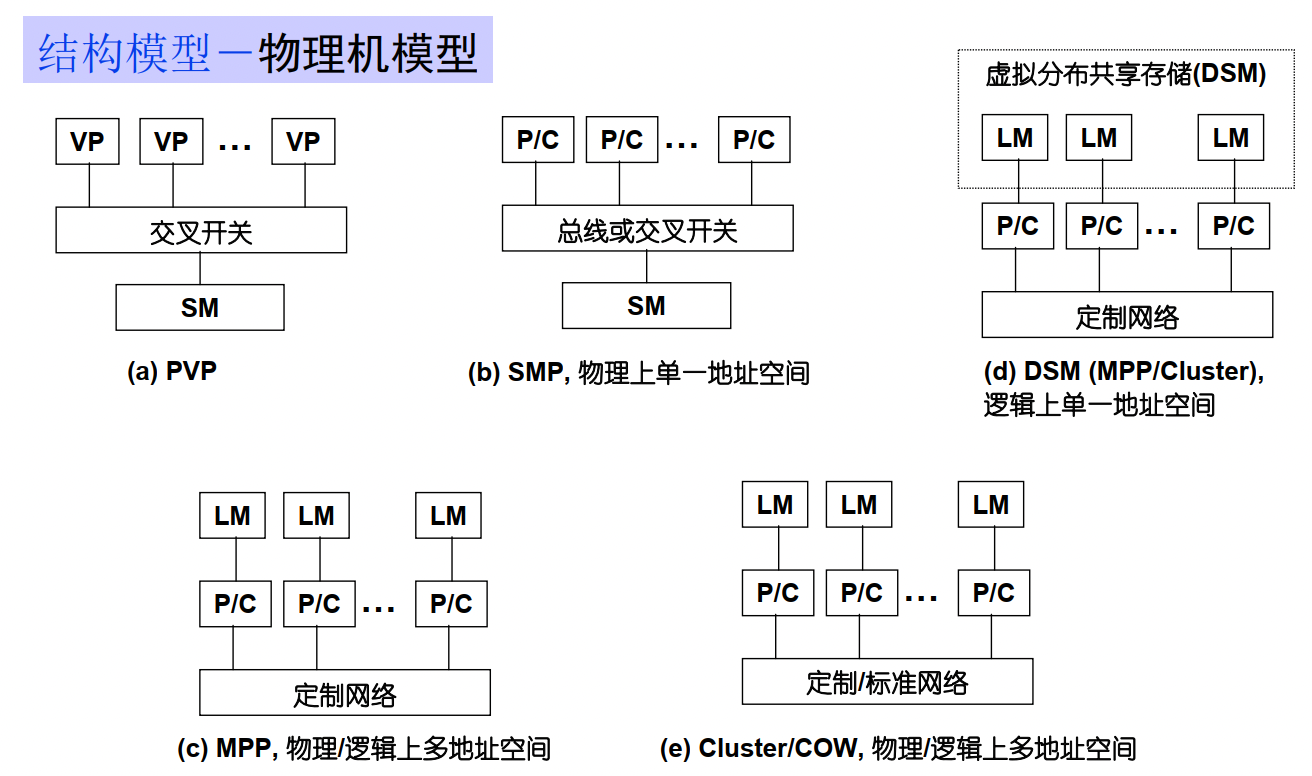
结构类型
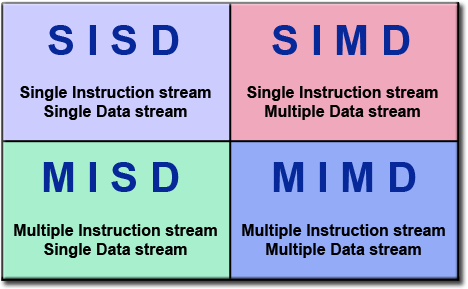
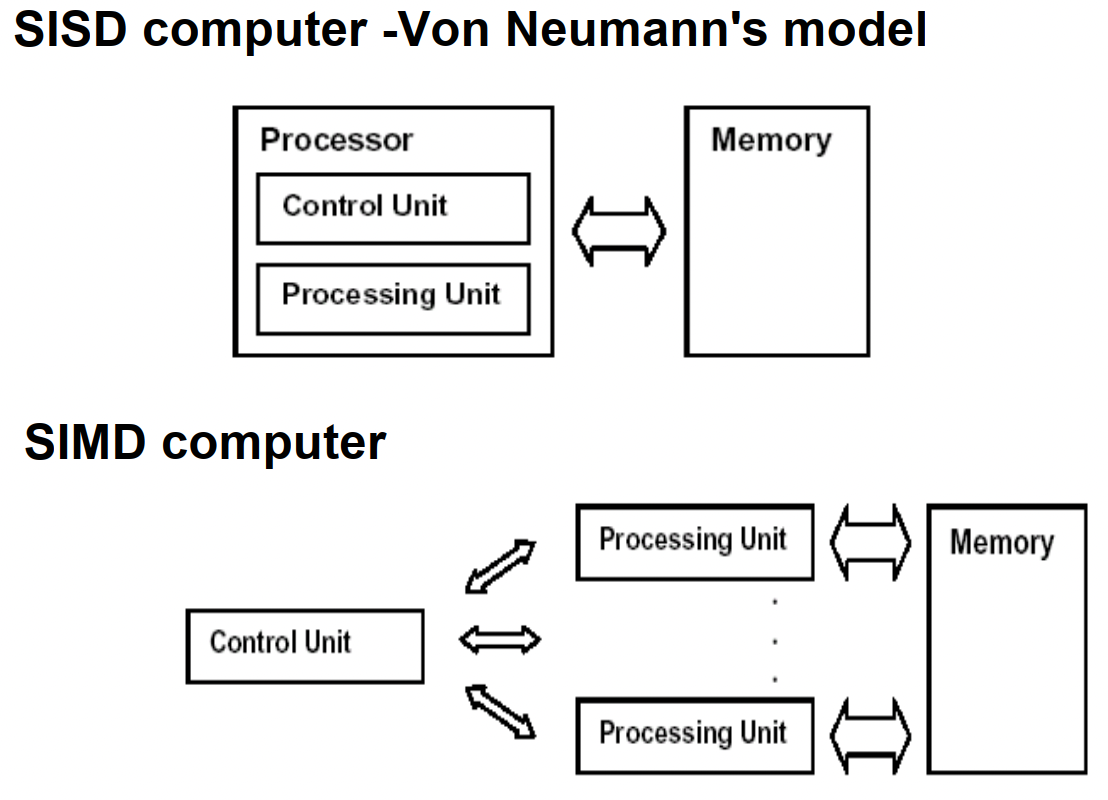
SISD:单指令流单数据流计算机(冯诺依曼机)
SIMD:单指令流多数据流计算机
MISD:多指令流单数据流计算机, 实际不存在
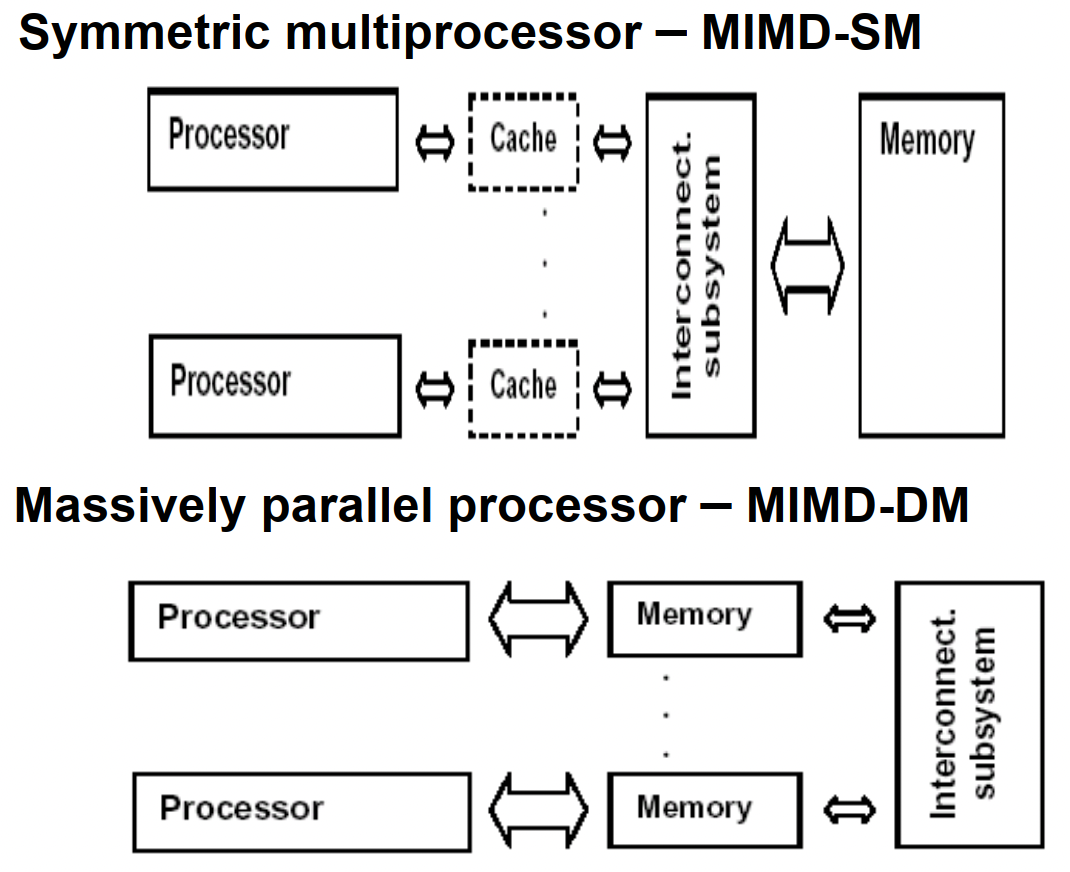
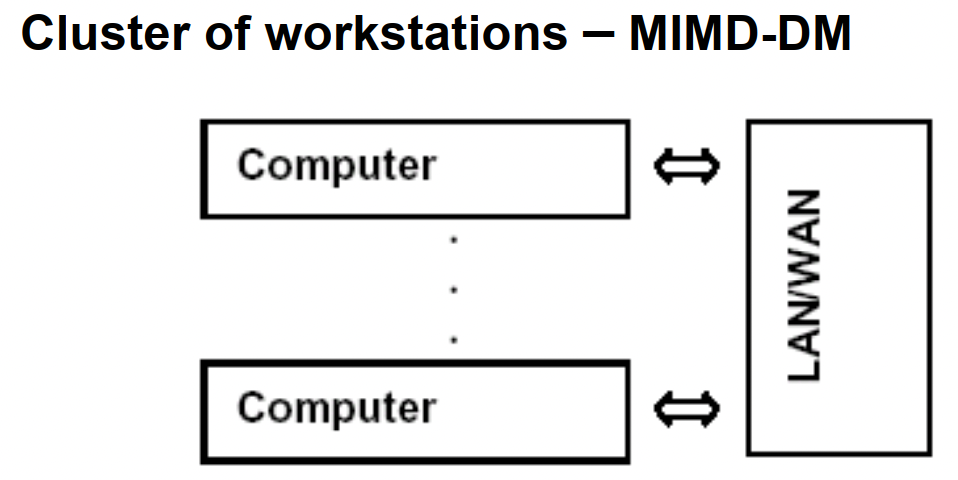
MIMD:多指令流多数据流计算机
SIMD-SM
PRAM(Parallel Random Access Machine)模型是单指令流多数据流(SIMD)并行机中的一种具有共享存储的模型。
GUPS (Giga十亿 UPdates per Second) is a measurement that profiles the memory architecture of a system and is a measure of performance similar to MFLOPS.
The HPCS HPCchallenge RandomAccess benchmark is intended to exercise the GUPS capability of a system, much like the LINPACK benchmark is intended to exercise the MFLOPS capability of a computer. In each case, we would expect these benchmarks to achieve close to the “peak” capability of the memory system. The extent of the similarities between RandomAccess and LINPACK are limited to both benchmarks attempting to calculate a peak system capability.
definition of GUPS
GUPS is calculated by identifying the number of memory locations that can be randomly updated in one second, divided by 1 billion (1e9).
The term “randomly“ means that there is little relationship between one address to be updated and the next, except that they occur in the space of one half the total system memory. (只用一半内存?)
An update is a read-modify-write operation on a table of 64-bit words. An address is generated, the value at that address read from memory, modified by an integer operation (add, and, or, xor) with a literal value, and that new value is written back to memory.
Extensibility
We are interested in knowing the GUPS performance of both entire systems and system subcomponents — e.g., the GUPS rating of a distributed memory multiprocessor the GUPS rating of an SMP node, and the GUPS rating of a single processor.
While there is typically a scaling of FLOPS with processor count, a similar phenomenon may not always occur for GUPS.
Principle
Select the memory size to be the power of two such that 2^n <= 1/2 of the total memory. Each CPU operates on its own address stream, and the single table may be distributed among nodes. The distribution of memory to nodes is left to the implementer. A uniform data distribution may help balance the workload, while non-uniform data distributions may simplify the calculations that identify processor location by eliminating the requirement for integer divides. A small (less than 1%) percentage of missed updates are permitted.
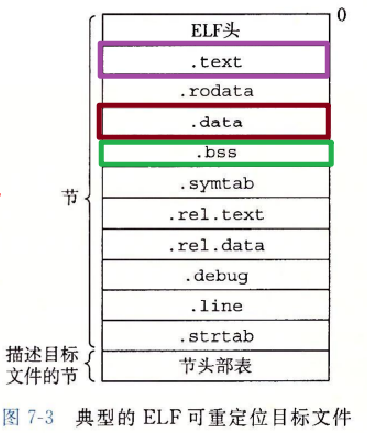
This section holds the procedure linkage table. See ‘‘Special Sections’’ in Part 1 and ‘‘Procedure Linkage Table’’ in Part 2 for more information.
Function symbols (those with type STT_FUNC) in shared object files have special significance. When another object file references a function from a shared object, the link editor automatically creates a procedure linkage table entry for the referenced symbol.
re* 匹配0个或多个的表达式。 re+ 匹配1个或多个的表达式。 re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 re{ n} 精确匹配 n 个前面表达式。 例如, o{2} 不能匹配 "Bob" 中的 "o", 但是能匹配 "food" 中的两个 o。 re{ n,} 匹配 n 个前面表达式。 例如, o{2,} 不能匹配"Bob"中的"o", 但能匹配 "foooood"中的所有 o。 "o{1,}" 等价于 "o+"。 "o{0,}" 则等价于 "o*"。 re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
match exactlly str
1 2 3 4 5 6 7
# find should use \ to represent the (6|12|3) $ find ~/github/gapbs/ -type f -regex '.*/kron-\(6\|12\|3\).*' /staff/shaojiemike/github/gapbs/kron-12.wsg /staff/shaojiemike/github/gapbs/kron-3.sg /staff/shaojiemike/github/gapbs/kron-3.wsg /staff/shaojiemike/github/gapbs/kron-6.sg /staff/shaojiemike/github/gapbs/kron-6.wsg
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
re.match函数
从字符串的起始位置匹配
1
re.match(pattern, string, flags=0)
flags
多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M被设置成 I 和 M 标志: