# shaojiemike @ node5 in ~ [23:55:47] $ docker run -v $OVPN_DATA:/etc/openvpn --rm -it kylemanna/openvpn ovpn_initpki
init-pki complete; you may now create a CA or requests. Your newly created PKI dir is: /etc/openvpn/pki
Using SSL: openssl OpenSSL 1.1.1g 21 Apr 2020
Enter New CA Key Passphrase: Re-Enter New CA Key Passphrase: Generating RSA private key, 2048 bit long modulus (2 primes) .........+++++ ...................+++++ e is 65537 (0x010001) You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Common Name (eg: your user, host, or server name) [Easy-RSA CA]:tsj-node5
CA creation complete and you may now import and sign cert requests. Your new CA certificate file for publishing is at: /etc/openvpn/pki/ca.crt
Using SSL: openssl OpenSSL 1.1.1g 21 Apr 2020 Generating DH parameters, 2048 bit long safe prime, generator 2 This is going to take a long time ......................+.......................+..........................................................+........................................................................................................+........................................+...................................................................................................................................+.....................................................................................................................+......................................................................................................................................................................................................................................+......++*++*++*++*
DH parameters of size 2048 created at /etc/openvpn/pki/dh.pem
Using SSL: openssl OpenSSL 1.1.1g 21 Apr 2020 Generating a RSA private key .......................................+++++ .........................................+++++ writing new private key to '/etc/openvpn/pki/easy-rsa-73.EeNnaB/tmp.jhHaaF' ----- Using configuration from /etc/openvpn/pki/easy-rsa-73.EeNnaB/tmp.LGnDjB Enter pass phrase for /etc/openvpn/pki/private/ca.key: Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'node5.xydustc.me' Certificate is to be certified until Jan 1 15:58:37 2025 GMT (825 days) Write out database with 1 new entries Data Base Updated Using SSL: openssl OpenSSL 1.1.1g 21 Apr 2020 Using configuration from /etc/openvpn/pki/easy-rsa-148.CDCEmf/tmp.iJCIGL Enter pass phrase for /etc/openvpn/pki/private/ca.key: An updated CRL has been created.
# shaojiemike @ node5 in ~ [0:16:46] $ docker run -v $OVPN_DATA:/etc/openvpn -d -p 1194:1194/udp --cap-add=NET_ADMIN kylemanna/openvpn cb0f7e78f389f112c3c3b230d20d2b50818f6cf59eea2edfaa076c7e8fad7128
# shaojiemike @ node5 in ~ [0:06:01] $ docker container list CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6c716b27b3f1 kylemanna/openvpn "ovpn_run" 49 seconds ago Up 48 seconds 1194/udp, 0.0.0.0:1195->1195/udp, :::1195->1195/udp charming_zhukovsky
# 上面是错误的
# shaojiemike @ node5 in ~ [0:16:50] $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cb0f7e78f389 kylemanna/openvpn "ovpn_run" About a minute ago Up About a minute 0.0.0.0:1194->1194/udp, :::1194->1194/udp pedantic_euler
# shaojiemike @ node5 in ~ [0:07:27] C:2 $ docker run -v $OVPN_DATA:/etc/openvpn --rm -it kylemanna/openvpn easyrsa build-client-full tsj-node5-client nopass Using SSL: openssl OpenSSL 1.1.1g 21 Apr 2020 Generating a RSA private key ...............+++++ ...............................+++++ writing new private key to '/etc/openvpn/pki/easy-rsa-1.olaINa/tmp.MfohAO' ----- Using configuration from /etc/openvpn/pki/easy-rsa-1.olaINa/tmp.EMkEHF Enter pass phrase for /etc/openvpn/pki/private/ca.key: 139775495048520:error:28078065:UI routines:UI_set_result_ex:result too small:crypto/ui/ui_lib.c:905:You must typein 4 to 1023 characters Enter pass phrase for /etc/openvpn/pki/private/ca.key: Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'tsj-node5-client' Certificate is to be certified until Jan 1 16:08:23 2025 GMT (825 days) Write out database with 1 new entries Data Base Updated # shaojiemike @ node5 in ~ [0:08:24] $ docker run -v $OVPN_DATA:/etc/openvpn --rm kylemanna/openvpn ovpn_getclient tsj-node5-client > tsj-node5-client.ovpn # shaojiemike @ node5 in ~ [0:09:20] $ ls tsj-node5-client.ovpn tsj-node5-client.ovpn
直播客户端获取到的并不是一个完整的数据流,HLS协议在服务器端将直播数据流存储为连续的、很短时长的媒体文件(MPEG-TS格式)(MPEG-2 Transport Stream;又称MPEG-TS、MTS、TS),而客户端则不断的下载并播放这些小文件,因为服务器总是会将最新的直播数据生成新的小文件,这样客户端只要不停的按顺序播放从服务器获取到的文件,就实现了直播。
Moonlight (formerly Limelight) is an open source implementation of NVIDIA’s GameStream protocol.
那么 NVIDIA’s GameStream protocol是什么呢?
NVIDIA uses high speed, low latency video encoders built into GeForce GTX or RTX GPUs along with an efficient streaming software protocol integrated into GeForce Experience.
我只能说看上去像自研的~但是马上也要没了
Nvidia isn’t just ending support for GameStream, it’s planning to fully remove the feature from existing Shield hardware in February 2023. Nvidia is recommending that Shield users switch to Steam Link, which is a similar way of streaming PC games to a Shield device.
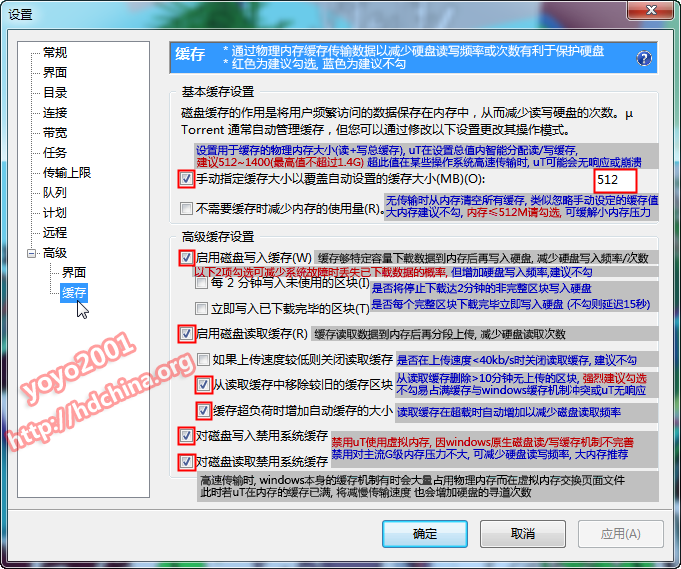
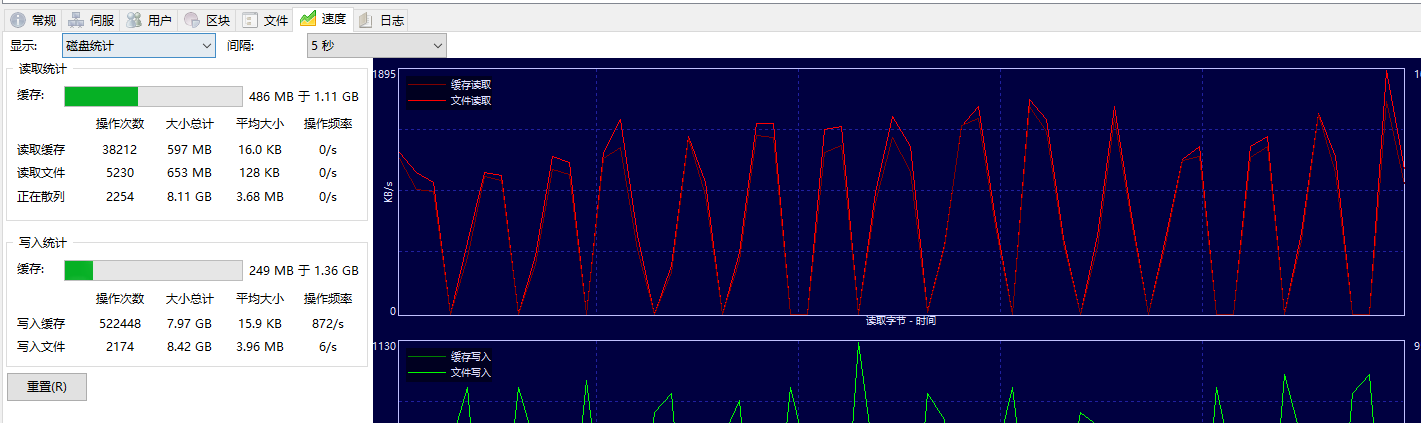
This is because the cache size is too big, lower to 512MB or 1GB to fix this.[^1] But the size bigger the faster, 1.4GB is the biggest available value which ut can support.
[root@ax6s ~]$ ip route get to 192.168.233.242 from 192.168.233.142 iif lan2 192.168.233.242 from 192.168.233.142 dev br-lan cache iif lan2 [root@ax6s ~]$ ip route get to 192.168.233.255 from 192.168.233.142 iif lan2 broadcast 192.168.233.255 from 192.168.233.142 dev lo table local cache <local,brd> iif lan2 [root@ax6s ~]$ ip route get to 255.255.255.255 from 192.168.233.142 iif lan2 broadcast 255.255.255.255 from 192.168.233.142 dev lo cache <local,brd> iif lan2
电脑需要远程被远程唤醒
电脑设置
「网络连接」
以太网(有线网)属性
【网络】(Realtek PCIe 2.5GbE Family Controller)下配置
【电源管理】勾选「允许此设备唤醒计算机」以及「只允许幻数据包唤醒计算机」
BIOS打开相关选项
1 2 3 4 5
Automatic Power On Wake on LAN/WLAN Power Management Power On by Onboard LAN Power On by PCI-E Devices
# RESTful web API listening address external-controller:127.0.0.1:9090
# DNS server settings # This section is optional. When not present, the DNS server will be disabled. dns: enable:false listen:0.0.0.0:53 ipv6:false# when the false, response to AAAA questions will be empty
# These nameservers are used to resolve the DNS nameserver hostnames below. # 默认只支持ip default-nameserver: -8.8.8.8
# 支持 UDP, TCP, DoT, DoH. 和指定端口 # 所有DNS请求都会不经过代理被转发到这些服务器,Clash会选择一个最快的返回结果 nameserver: -https://223.5.5.5/dns-query# 阿里云 -https://doh.pub/dns-query#腾讯云 -tls://dns.rubyfish.cn:853# DNS over TLS -https://1.1.1.1/dns-query# DNS over HTTPS -dhcp://en0# dns from dhcp
# 对于所有DNS请求,fallback和nameserver内的服务器都会同时查找 # 如果DNS结果为非国内IP(GEOIP country is not `CN`),会使用fallback内的服务器的结果 # 因为nameserver内为国内服务器,对国外域名可能有DNS污染。fallback内是国外服务器,能防止国外域名被DNS污染 fallback: -https://162.159.36.1/dns-query -https://dns.google/dns-query -tls://8.8.8.8:853
# DNS污染攻击的对策 fallback-filter: geoip:false# If geoip is true, when geoip matches geoip-code, clash will use nameserver results. Otherwise, Clash will only use fallback results. # geoip-code: CN ipcidr:# IPs in these subnets will be considered polluted, when nameserver results match these ip, clash will use fallback results. -0.0.0.0/8 -10.0.0.0/8 -100.64.0.0/10 -127.0.0.0/8 -169.254.0.0/16 -172.16.0.0/12 -192.0.0.0/24 -192.0.2.0/24 -192.88.99.0/24 -192.168.0.0/16 -198.18.0.0/15 -198.51.100.0/24 -203.0.113.0/24 -224.0.0.0/4 -240.0.0.0/4 -255.255.255.255/32 domain:#Domains in these list will be considered polluted, when lookup these domains, clash will use fallback results. -+.google.com -+.facebook.com -+.youtube.com -+.githubusercontent.com