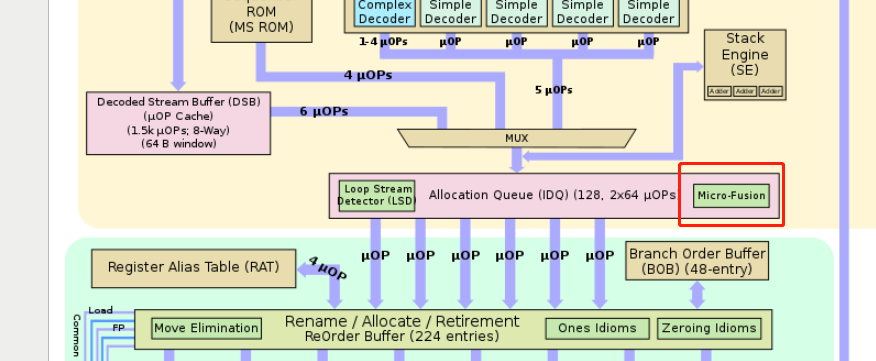
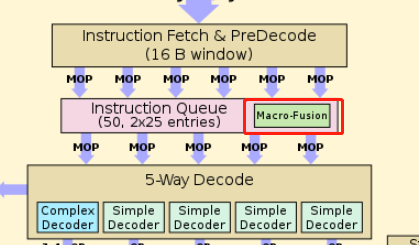
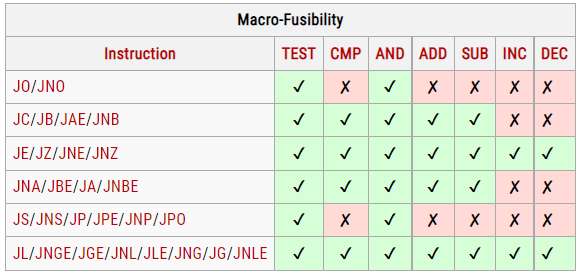
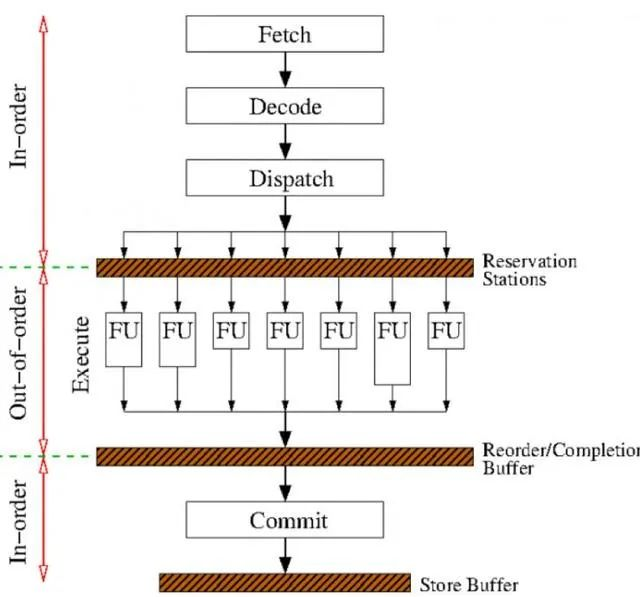
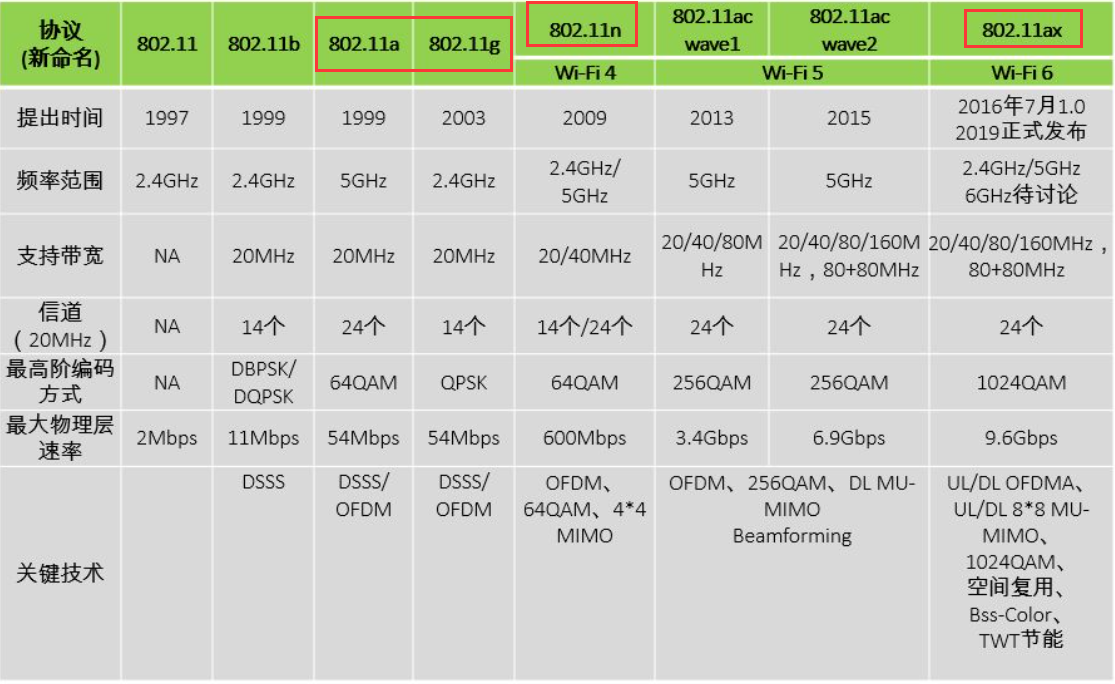
乱序执行的步骤
简单来说每个阶段执行的操作如下:^1
1)获取指令,解码后存放到执行缓冲区Reservations Stations
取指令/uops
指令(uops)dispatch 到instruction queue (/instruction buffer / reservation stations).
指令等待操作数指令可用,然后可以在前后指令前离开等待队列
issue到对应port单元执行,并且在 scheduler(reservation station)里跟踪uops依赖。
结果缓存在(re-order buffer, ROB)
在Tomasulo算法中,重排序缓冲区(英语:re-order buffer, ROB))可以使指令在乱序执行,之后按照原有顺序提交。
按照程序序结束(只有前面的指令都完成写回寄存器的操作),该指令才能retire
在retire的时候,重新排序运算结果来实现指令的顺序执行中的运行结果
why out-of-order execution retire/commit in program order
对于程序员外部视角来看,程序还是按序执行的。
如果指令出错,可以精确定位exceptions 位置,并且执行回滚来复原。
???寄存器数据依赖(重命名打破?)
乱序执行的实现 scoreboard 只有当一条指令与之前已发射(issue)的指令之间的冲突消失之后,这条指令才会被发射、执行。
如果某条指令由于数据冲突而停顿,计分板会监视正在执行的指令流,在所有数据相关性造成的冲突化解之后通知停顿 的指令开始执行。
Tomasulo 托马苏洛算法 通过寄存器重命名 机制,来解决后两种数据依赖。
使用了共享数据总线(common data bus, CDB)将已计算出的值广播 给所有需要这个值作为指令源操作数的保留站 。
在指令的发射(issue)阶段,如果操作数和保留站都准备就绪 ,那么指令就可以直接发射 并执行。
如果操作数未就绪 ,则进入保留站的指令会跟踪 即将产生这个所需操作数的那个功能单元。
乱序执行的发展 随着流水线pipeline的加深和主存(或者缓存)和处理器间的速度差的变大。在顺序执行处理器等待数据的过程中,乱序执行处理器能够执行大量的指令。使得乱序执行更加重要。
Register Renaming 来由 已知可以通过乱序执行来实现,硬件资源的高效利用(避免计算指令等待访存指令的完成)。为了实现乱序执行,需要通过寄存器重命名来打破寄存器的之间的读写依赖。
例子1 对于原始代码
1 2 3 4 5 6 1. R1=M[1024] 2. R1=R1+2 3. M[1032]=R1 4. R1=M[2048] 5. R1=R1+4 6. M[2056]=R1
原本代码前后3条是没有关系的,可以并行的。需要使用寄存器重命名来解决R1的读后写依赖。
1 2 3 1. R1=M[1024] 4. R2=M[2048] 2. R1=R1+2 5. R2=R2+4 3. M[1032]=R1 6. M[2056]=R2
数据冲突 如果多条指令使用了同一个存储位置,这些指令如果不按程序地址顺序执行可能会导致3种数据冲突(data hazard):
先写后读 (Read -after-write,RAW):从寄存器或者内存中读取的数据,必然是之前的指令存入此处的。直接数据相关(true data dependency)
先写后写 (Write -after-write,WAW):连续写入特定的寄存器或内存,那么该存储位置最终只包含第二次写的数据。这可以取消或者废除第一次写入操作。WAW相关也被说成是“输出相关”(output dependencies)。
先读后写 (Write -after-read,WAR):读操作获得的数据是此前写入的,而不是此后写操作的结果。因此并行和乱序时无法改善的资源冲突(antidependency)。
后面两个WAW和WAR可以通过寄存器重命名解决(register renaming),不必等待前面的读写操作完成后再执行写操作,可以保持这个存储位置的两份副本:老值与新值。
前一条指令的读老值的操作可以继续进行,无需考虑那些后一条指令的写新值甚至该写新值指令之后的读新值的操作。产生了额外的乱序执行机会。当所有读老值操作被满足后,老值所使用的寄存器既可以释放。这是寄存器重命名的实质 。
重命名存储对象 任何被读或写的存储都是可以被重名。
最常考虑的是通用整数寄存器与浮点寄存器。
标志寄存器、状态寄存器甚至单个状态位也是常见的重命名的对象。
内存位置也可以被重命名,虽然这么做不太常见。
通用(逻辑)寄存器和物理寄存器 对于某种ISA,有固定的供编译器/汇编器 访问使用的寄存器。例如,Alpha ISA使用32个64位宽整数寄存器,32个64位宽浮点寄存器。
但是一款特定的处理器,实现了这种处理器体系结构。例如Alpha 21264有80个整数寄存器、72个浮点寄存器,作为处理器内物理实现的寄存器。
寄存器个数设计考虑 如果寄存器个数很多,就不需要寄存器重命名机制。比如IA-64指令集体系结构提供了128个通用寄存器。但是这会导致一些问题:
编译器如果需要重用寄存器会很容易导致程序尺寸大增 。
程序的循环 连续迭代执行就需要复制 循环体的代码以使用不同的寄存器,这种技术叫做循环展开。
代码尺寸增加,会导致指令高速缓存的未命中(cache miss)增加 ,处理器执行停顿等待从低级存储中读入代码。这对运算性能的影响是致命的。
大量的寄存器,需要在指令的操作数中需要很多位表示 ,导致程序尺寸变大。
很多指令集在历史上就使用了很少的寄存器,出于兼容 原因现在也很难改变。
实现方法简述
tag索引的寄存器堆(tag-indexed register file)
保留站(reservation station)方法
通常是每个执行单元的输入口都有一个物理寄存器堆
相关寄存器部件
远期寄存器堆(Future File):
处理器对分支做投机执行的寄存器的状态保存于此。
使用逻辑寄存器号来索引访问。
历史缓冲区(History Buffer):
用于保存分支时的逻辑寄存器状态。
如果分支预测失败,将使用历史缓冲区的数据来恢复执行状态。
排缓冲区(Reorder Buffer,ROB):
为了实现指令的顺序提交,处理器内部使用了一个Buffer。如果在该缓冲区中排在一条指令之前的所有都已经提交,没有处于未提交状态的(称作in flight),则该指令也被提交(即确认执行完毕)。
因此重排缓冲区是在远期寄存器堆之后,体系结构寄存器堆之前。提交的指令的结果写入体系寄存器堆。
体系结构寄存器堆(Architectural Register File)或者引退寄存器堆(Retirement Register File,RRF):
存储了被提交的体系寄存器的状态。通过逻辑寄存器的号来查询这个寄存器堆。
重排序缓冲区(reorder buffer)中的引退(retired)或者说提交(committed)指令,把结果写入这个寄存器堆。
所属部件
编译器
会尽力检测出类似这样的问题,并把不同的寄存器分配给不同的指令使用。但是,受指令集体系结构的限制,汇编程序可以使用的寄存器名字的数量是有限的。
硬件实现
在处理器指令流水线执行时把这些指令集体系结构寄存器映射为不同的物理寄存器。
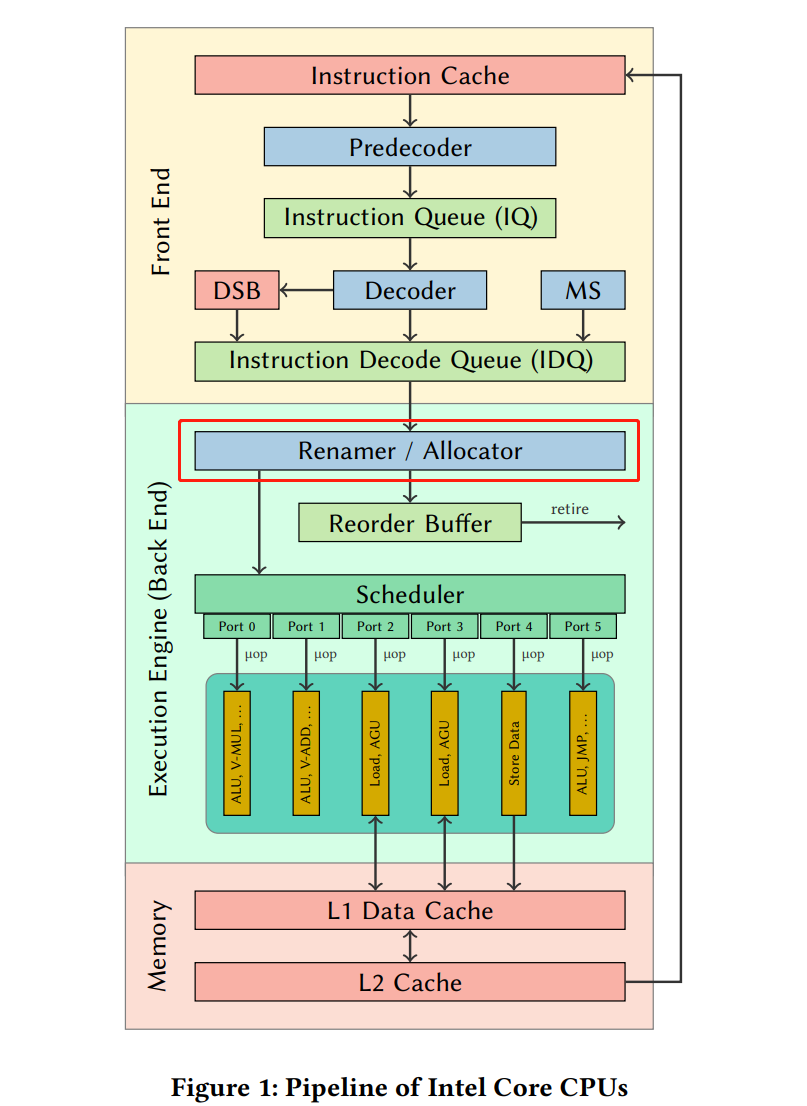
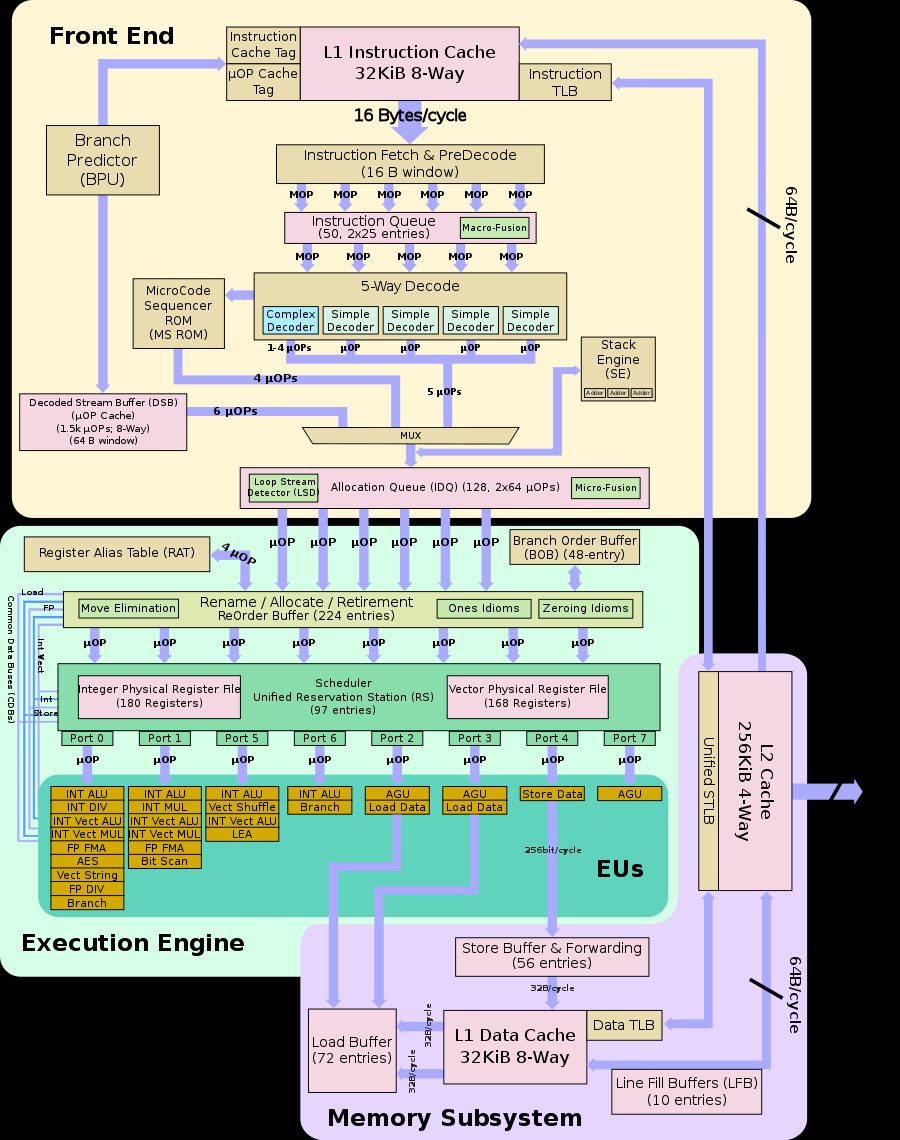
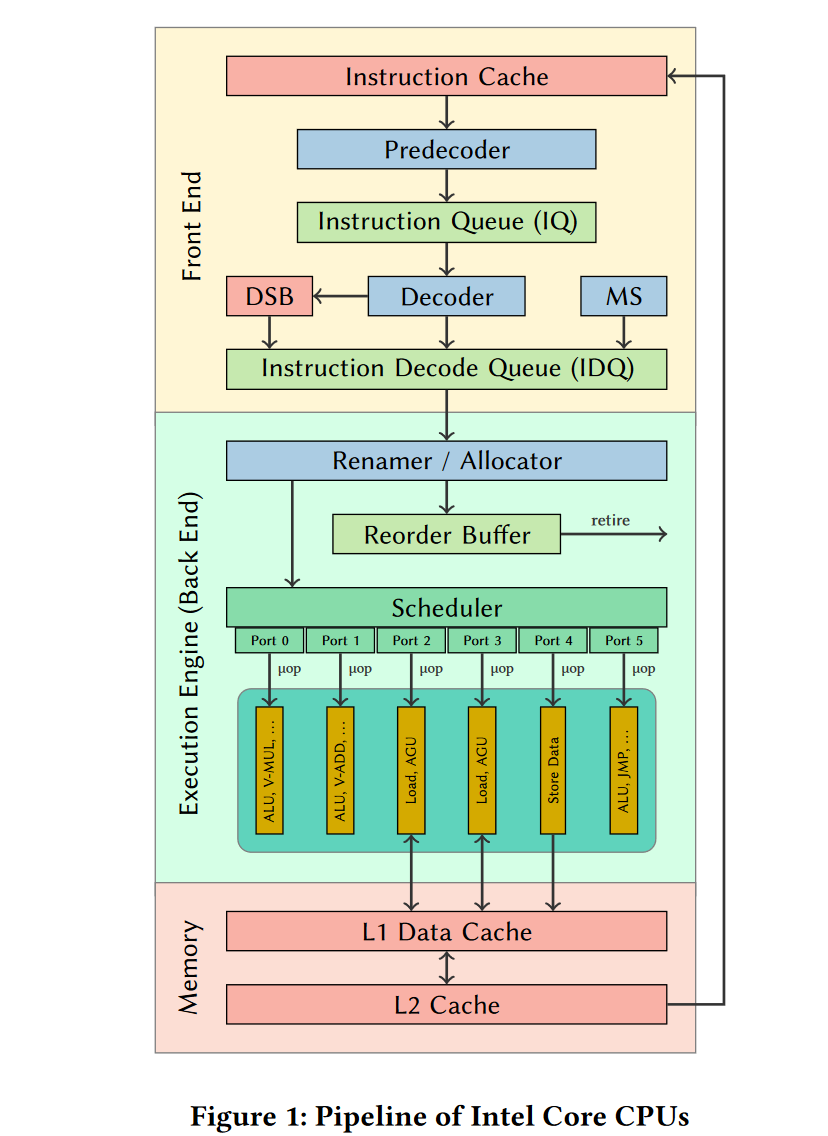
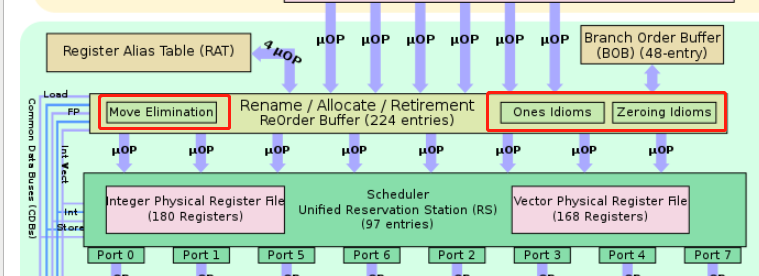
比如下图的Renamer / Allocator(也称为Resource Allocation Table (RAT))将 架构寄存器 映射到物理寄存器 。 它还为loads and stores分配资源,并将uops分到不同端口。
需要进一步的研究学习 暂无
遇到的问题 暂无
开题缘由、总结、反思、吐槽~~ 参考文献 https://zh.wikipedia.org/zh-cn/%E4%B9%B1%E5%BA%8F%E6%89%A7%E8%A1%8C
https://easyperf.net/blog/2018/04/22/What-optimizations-you-can-expect-from-CPU