- Hugo is a Go-based static site generator known for its speed and flexibility in 2013.
- Hugo has set itself apart by being fast. More precisely, it has set itself apart by being much faster than Jekyll.
- Jekyll uses
Liquidas its templating language. Hugo usesGotemplating. Most people seem to agree that it is a little bit easier to learn Jekyll’s syntax than Hugo’s.^1
命令行查看当前机器公网ip
1 | > curl myip.ipip.net |
检测机器端口开放
1 | # 网页服务直接下载检查内容 |
或者扫描指定端口
1 | # IPV6 也行 |
全部端口,但是会很慢。50分钟
1 | sudo nmap -sT -p- 4.shaojiemike.top |
wireshark
显示过滤
上方的过滤窗口
1 | tcp.port==80&&(ip.dst==192.168.1.2||ip.dst==192.168.1.3) |
捕捉过滤
抓包前在capture option中设置,仅捕获符合条件的包,可以避免产生较大的捕获文件和内存占用,但不能完整的复现测试时的网络环境。
1 | host 192.168.1.1 //抓取192.168.1.1 收到和发出的所有数据包 |
color 含义

tcpdump
传统命令行抓包工具
常用参数
注意过滤规则间的and
-nn:- 单个 n 表示不解析域名,直接显示 IP;
- 两个 n 表示不解析域名和端口。
- 方便查看 IP 和端口号,
- 不需要域名解析会非常高效。
-i指定网卡-D查看网卡-v,-vv和-vvv来显示更多的详细信息port 80抓取 80 端口上的流量,通常是 HTTP。在前面加src,dst限定词tcpudmp -i eth0 -n arp host 192.168.199抓取192.168.199.* 网段的arp协议包,arp可以换为tcp,udp等。
-A,-X,-xx会逐渐显示包内容更多信息-e: 显示数据链路层信息。- 默认情况下 tcpdump 不会显示数据链路层信息,使用 -e 选项可以显示源和目的 MAC 地址,以及 VLAN tag 信息。
输出说明
1 | 192.168.1.106.56166 > 124.192.132.54.80 |
- ip 是 192.168.1.106,源端口是 56166,
- 目的地址是 124.192.132.54,目的端口是 80。
>符号代表数据的方向。
Flags
常见的三次握手 TCP 报文的 Flags:
1 | [S] : SYN(开始连接) |
常见用途
- 根据目的IP,筛选网络经过的网卡和端口
- 能抓各种协议的包比如ping,ssh
案例分析
1 | curl --trace-ascii - www.github.com |
github ip 为 20.205.243.166
ifconfig显示 ibs5的网卡有21TB的带宽上限,肯定是IB卡了。
1 | sudo tcpdump -i ibs5 '((tcp) and (host 20.205.243.166))' |
1 | $ sudo tcpdump -i ibs5 -nn -vvv -e '((port 80) and (tcp) and (host 20.205.243.166))' tcpdump: listening on ibs5, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes |
snode0 ip 是 10.1.13.50
traceroute
mtr = traceroute+ping
1 | $ traceroute www.baid.com |
traceroute命令用于显示数据包到主机间的路径。
NETWORKMANAGER 管理
1 | # shaojiemike @ snode0 in /etc/NetworkManager [16:49:55] |
好像之前使用过的样子。
1 | # shaojiemike @ snode0 in /etc/NetworkManager [16:56:36] C:127 |
应该是这个 Secure site-to-site connection with Linux IPsec VPN 来设置的
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
FJW说所有网络都是通过NFS一起出去的
参考文献
无通过IPMI芯片的静态IP远程重启和配置机器
https://cloud.tencent.com/developer/article/1448642
Group
当前组
1 | shaojiemike@snode6:~$ groups shaojiemike |
所有组
1 | cat /etc/group |
User
whoami
一般用户位置
/etc/passwd
LDAP教程
如果发现自己不在/etc/passwd里,很可能使用了ldap 集中身份认证。可以在多台机器上实现分布式账号登录,用同一个账号。
1 | getent passwd |
first reboot server
1 | ctrl + alt + F3 |
限制当前shell用户爆内存
宕机一般是爆内存,进程分配肯定会注意不超过物理核个数。
在zshrc里写入 25*1024*1024 = 25GB的内存上限
1 | ulimit -v 26214400 |
当前shell程序超内存,会输出Memory Error结束。
测试读取200GB大文件到内存
1 | with open("/home/shaojiemike/test/DynamoRIO/OpenBLASRawAssembly/openblas_utest.log", 'r') as f: |
有文章说Linux有些版本内核会失效
PyTorch Geometric Liberty
PyG是一个基于PyTorch的用于处理不规则数据(比如图)的库,或者说是一个用于在图等数据上快速实现表征学习的框架。它的运行速度很快,训练模型速度可以达到DGL(Deep Graph Library )v0.2 的40倍(数据来自论文)。除了出色的运行速度外,PyG中也集成了很多论文中提出的方法(GCN,SGC,GAT,SAGE等等)和常用数据集。因此对于复现论文来说也是相当方便。
经典的库才有函数可以支持,自己的模型,自己根据自动微分实现。还要自己写GPU并行。
MessagePassing 是网络交互的核心
数据
数据怎么存储
torch_geometric.data.Data (下面简称Data) 用于构建图
- 每个节点的特征 x
- 形状是[num_nodes, num_node_features]。
- 节点之间的边 edge_index
- 形状是 [2, num_edges]
- 节点的标签 y
- 假如有。形状是[num_nodes, *]
- 边的特征 edge_attr
- [num_edges, num_edge_features]
数据支持自定义
通过data.face来扩展Data
获取数据
在 PyG 中,我们使用的不是这种写法,而是在get()函数中根据 index 返回torch_geometric.data.Data类型的数据,在Data里包含了数据和 label。
数据处理的例子
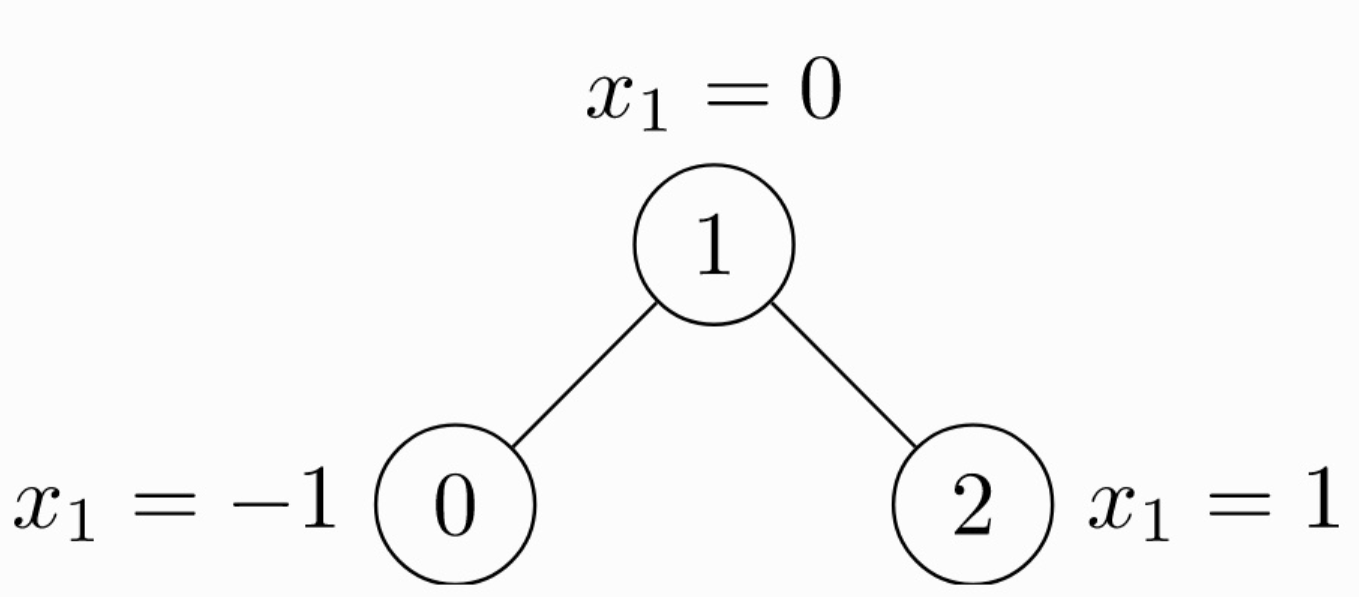
由于是无向图,因此有 4 条边:(0 -> 1), (1 -> 0), (1 -> 2), (2 -> 1)。每个节点都有自己的特征。上面这个图可以使用 torch_geometric.data.Data来表示如下:
1 | import torch |
注意edge_index中边的存储方式,有两个list,第 1 个list是边的起始点,第 2 个list是边的目标节点。注意与下面的存储方式的区别。
1 | import torch |
这种情况edge_index需要先转置然后使用contiguous()方法。关于contiguous()函数的作用,查看 PyTorch中的contiguous。
数据集
Dataset
1 | import torch |
DataLoader
DataLoader 这个类允许你通过batch的方式feed数据。创建一个DotaLoader实例,可以简单的指定数据集和你期望的batch size。
1 | loader = DataLoader(dataset, batch_size=512, shuffle=True) |
DataLoader的每一次迭代都会产生一个Batch对象。它非常像Data对象。但是带有一个‘batch’属性。它指明了了对应图上的节点连接关系。因为DataLoader聚合来自不同图的的batch的x,y 和edge_index,所以GNN模型需要batch信息去知道那个节点属于哪一图。
1 | for batch in loader: |
MessagePassing(核心)
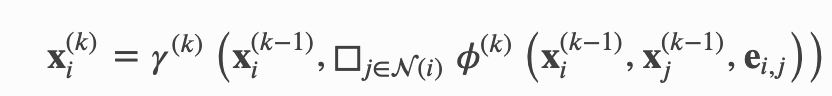
其中,x 表示表格节点的 embedding,e 表示边的特征,ϕ 表示 message 函数,□ 表示聚合 aggregation 函数,γ 表示 update 函数。上标表示层的 index,比如说,当 k = 1 时,x 则表示所有输入网络的图结构的数据。
为了实现这个,我们需要定义:
- message
- 定义了对于每个节点对 (xi,xj),怎样生成信息(message)。
- update
- aggregation scheme
- propagate(edge_index, size=None, **kwargs)
- 这个函数最终会按序调用 message、aggregate 和 update 函数。
- update(aggr_out, **kwargs)
- 这个函数利用聚合好的信息(message)更新每个节点的 embedding。
propagate(edge_index: Union[torch.Tensor, torch_sparse.tensor.SparseTensor], size: Optional[Tuple[int, int]] = None, **kwargs)
- edge_index (Tensor or SparseTensor)
- 输入的边的信息,定义底层图形连接/消息传递流。
- torch.LongTensor类型
- its shape must be defined as
[2, num_messages], where messages from nodes inedge_index[0]are sent to nodes inedge_index[1]
- its shape must be defined as
- torch_sparse.SparseTensor类型
- its sparse indices (row, col) should relate to row = edge_index[1] and col = edge_index[0].
- 也不一定是方形节点矩阵。x=(x_N, x_M).
MessagePassing.message(…)
会根据 flow=“source_to_target”和if flow=“target_to_source”或者x_i,x_j,来区分处理的边。
x_j表示提升张量,它包含每个边的源节点特征,即每个节点的邻居。通过在变量名后添加_i或_j,可以自动提升节点特征。事实上,任何张量都可以通过这种方式转换,只要它们包含源节点或目标节点特征。
_j表示每条边的起点,_i表示每条边的终点。x_j表示的就是每条边起点的x值(也就是Feature)。如果你手动加了别的内容,那么它的_j, _i也会自动进行处理,这个自己稍微单步执行一下就知道了
在实现message的时候,节点特征会自动map到各自的source and target nodes。
aggregate(inputs: torch.Tensor, index: torch.Tensor, ptr: Optional[torch.Tensor] = None, dim_size: Optional[int] = None, aggr: Optional[str] = None) → torch.Tensor
aggregation scheme 只需要设置参数就好,“add”, “mean”, “min”, “max” and “mul” operations
MessagePassing.update(aggr_out, …)
aggregation 输出作为第一个参数,后面的参数是 propagate()的
实现GCN 例子
$$
\mathbf{x}i^{(k)} = \sum{j \in \mathcal{N}(i) \cup { i }} \frac{1}{\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}} \cdot \left( \mathbf{\Theta}^{\top} \cdot \mathbf{x}_j^{(k-1)} \right)
$$
该式子先将周围的节点与权重矩阵\theta相乘, 然后通过节点的度degree正则化,最后相加
步骤可以拆分如下
- 添加self-loop 到邻接矩阵(Adjacency Matrix)。
- 节点特征的线性变换。
- 计算归一化系数
- Normalize 节点特征。
- sum相邻节点的feature(“add”聚合)。
步骤1 和 2 需要在message passing 前被计算好。 3 - 5 可以torch_geometric.nn.MessagePassing 类。
添加self-loop的目的是让featrue在聚合的过程中加入当前节点自己的feature,没有self-loop聚合的就只有邻居节点的信息。
1 | import torch |
所有的逻辑代码都在forward()里面,当我们调用propagate()函数之后,它将会在内部调用message()和update()。
使用 GCN 的例子
1 | conv = GCNConv(16, 32) |
SAGE的例子
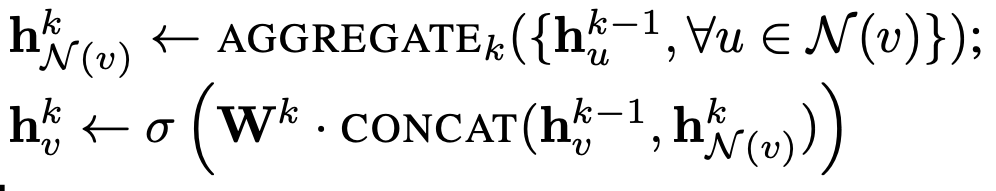
聚合函数(aggregation)我们用最大池化(max pooling),这样上述公示中的 AGGREGATE 可以写为: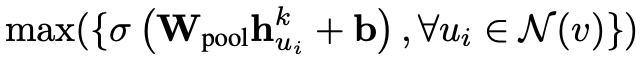
上述公式中,对于每个邻居节点,都和一个 weighted matrix 相乘,并且加上一个 bias,传给一个激活函数。相关代码如下(对应第二个图):
1 | class SAGEConv(MessagePassing): |
对于 update 方法,我们需要聚合更新每个节点的 embedding,然后加上权重矩阵和偏置(对应第一个图第二行):
1 | class SAGEConv(MessagePassing): |
综上所述,SageConv 层的定于方法如下:
1 | import torch |
batch的实现
GNN的batch实现和传统的有区别。
zzq的观点
将网络复制batch次,batchSize的数据产生batchSize个Loss。通过Sum或者Max处理Loss,整体同时更新所有的网络参数。至于网络中循环输入和输出的H^(t-1)和H^t。(感觉直接平均就行了。
有几个可能的问题
- 网络中参数不是线性层,CNN这种的网络。pytorch会自动并行吗?还需要手动
- 还有个问题,如果你还想用PyG的X和edge。并不能额外拓展维度。
图像和语言处理领域的传统基本思路:
通过 rescaling or padding(填充) 将相同大小的网络复制,来实现新添加维度。而新添加维度的大小就是batch_size。
但是由于图神经网络的特殊性:边和节点的表示。传统的方法要么不可行,要么会有数据的重复表示产生的大量内存消耗。
ADVANCED MINI-BATCHING in PyG
为此引入了ADVANCED MINI-BATCHING来实现对大量数据的并行。
https://pytorch-geometric.readthedocs.io/en/latest/notes/batching.html
实现:
- 邻接矩阵以对角线的方式堆叠(创建包含多个孤立子图的巨大图)
- 节点和目标特征只是在节点维度中串联???
优势
- 依赖message passing 方案的GNN operators不需要修改,因为消息仍然不能在属于不同图的两个节点之间交换。
- 没有计算或内存开销。例如,此batching 过程完全可以在不填充节点或边特征的情况下工作。请注意,邻接矩阵没有额外的内存开销,因为它们以稀疏方式保存,只保存非零项,即边。
torch_geometric.loader.DataLoader
可以实现将多个图batch成一个大图。 通过重写collate()来实现,并继承了pytorch的所有参数,比如num_workers.
在合并的时候,除开edge_index [2, num_edges]通过增加第二维度。其余(节点)都是增加第一维度的个数。
最重要的作用
1 | # 原本是[2*4] |
torch_geometric.loader.DataLoader 例子1
1 | from torch_geometric.data import Data |
torch_geometric.loader.DataLoader 例子2
1 | from torch_geometric.datasets import TUDataset |
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无图神经网络(Graph Neural Networks,GNN)以及特点
- GNN可以分析对象之间的关系,来实现精准的推荐
- 问题
- 因为图是不规则的,每个图都有一个大小可变的无序节点,图中的每个节点都有不同数量的相邻节点,导致卷积等操作不适合图。
- 现有深度学习算法的一个核心假设是数据样本之间彼此独立。对于图来说,每个数据样本(节点)都会有边与图中其他实数据样本(节点)相关,这些信息可用于捕获实例之间的相互依赖关系。
图嵌入 & 网络嵌入
图神经网络的研究与图嵌入(对图嵌入不了解的读者可以参考我的这篇文章《图嵌入综述》)或网络嵌入密切相关。
真实的图(网络)往往是高维、难以处理的,图嵌入的目标是发现高维图的低维向量表示。
图分析任务
- 节点分类,
- 链接预测,
- 聚类,
- 可视化
图神经网络分类
- 图卷积网络(Graph Convolution Networks,GCN)
- 图注意力网络(Graph Attention Networks)
- 图注意力网络(GAT)是一种基于空间的图卷积网络,它的注意机制是在聚合特征信息时,将注意机制用于确定节点邻域的权重。
- 图自编码器( Graph Autoencoders)
- 图生成网络( Graph Generative Networks)
- 图时空网络(Graph Spatial-temporal Networks)。
图卷积网络(Graph Convolution Networks,GCN)
GCN可谓是图神经网络的“开山之作”,它首次将图像处理中的卷积操作简单的用到图结构数据处理中来,并且给出了具体的推导,这里面涉及到复杂的谱图理论。推导过程还是比较复杂的,然而最后的结果却非常简单。
聚合邻居节点的特征然后做一个线性变换吗?没错,确实是这样,同时为了使得GCN能够捕捉到K-hop的邻居节点的信息,作者还堆叠多层GCN layers,如堆叠K层有: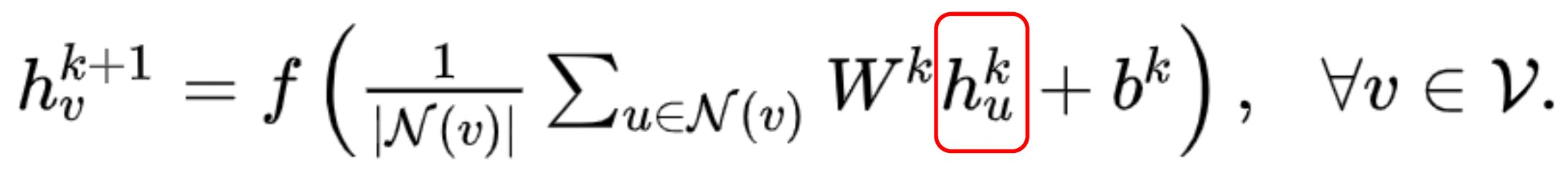
经典的简单几类
Semi-supervised learning for node-level classification:
给定一个网络,其中部分节点被标记,其他节点未标记,ConvGNNs可以学习一个鲁棒模型,有效地识别未标记节点的类标签。为此,可以通过叠加一对图卷积层,然后是用于多类分类的softmax层来构建端到端框架。见图(a)
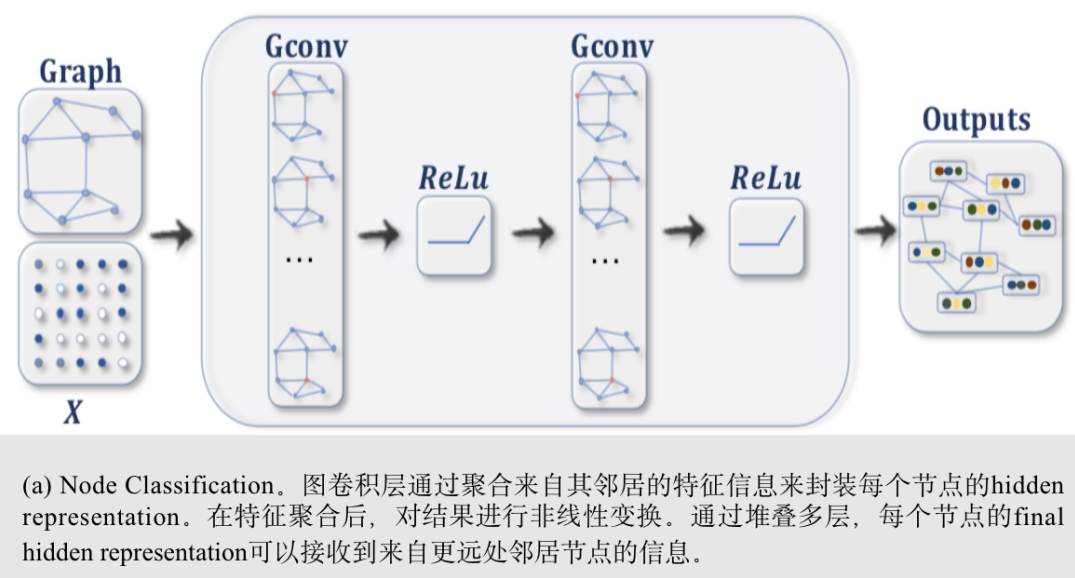
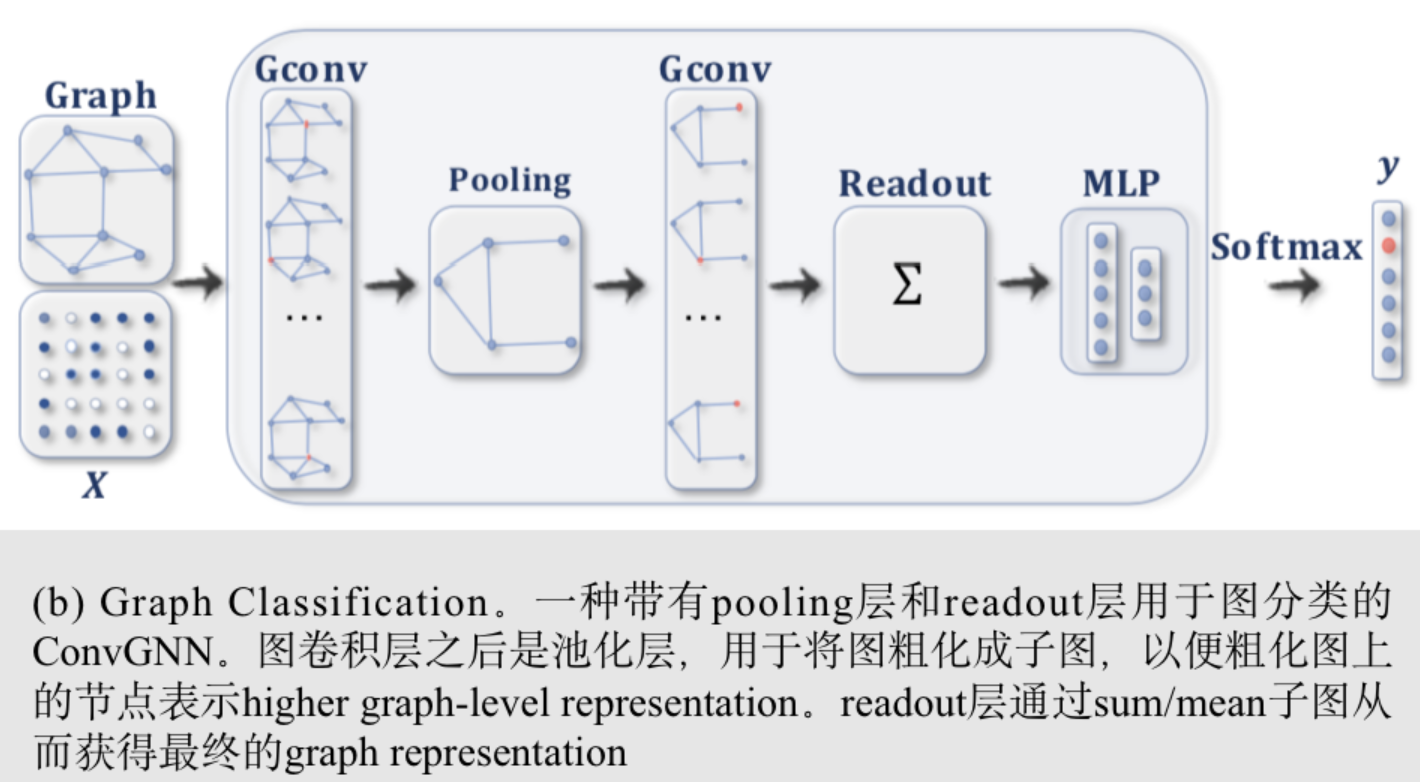
Supervised learning for graph-level classification:
图级分类的目的是预测整个图的类标签。该任务的端到端学习可以结合图卷积层、图池层和/或readout层来实现。图卷积层负责精确的高级节点表示,图池层则扮演下采样的角色,每次都将每个图粗化成一个子结构。readout层将每个图的节点表示折叠成一个图表示。通过在图表示中应用一个多层感知器和一个softmax层,我们可以建立一个端到端图分类框架。见图(b)
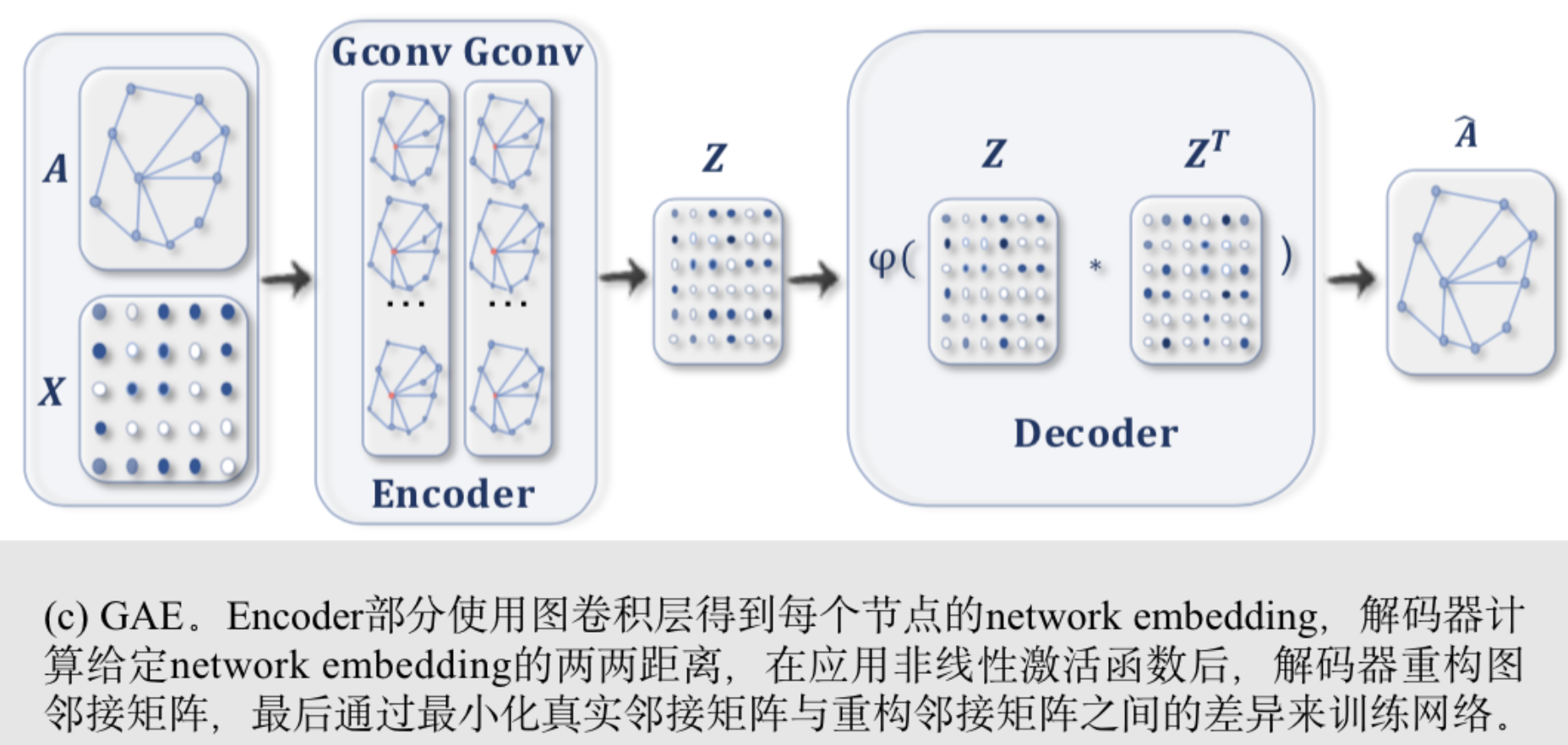
Unsupervised learning for graph embedding:
当图中没有可用的类标签时,我们可以学习在端到端框架中以完全无监督的方式嵌入图。这些算法以两种方式利用边缘级信息。一种简单的方法是采用自编码器框架,编码器使用图卷积层将图嵌入到潜在表示中,在潜在表示上使用解码器重构图结构。另一种常用的方法是利用负采样方法(negative sampling),即对图中有链接的部分节点对进行负采样,而对图中有链接的节点对进行正采样。然后应用逻辑回归层对的正负配对进行区分。见图(c)
图自动编码器(Graph autoencoders, GAEs)是一种无监督学习框架,它将node或者graph编码成一个潜在的向量空间,并从编码的信息重构图数据。该算法用于学习network embedding和图生成分布。对于network embedding,GAEs通过重构图的邻接矩阵等图结构信息来学习潜在节点表示。对于图的生成,有的方法是一步一步生成图的节点和边,有的方法是一次性输出整个图。
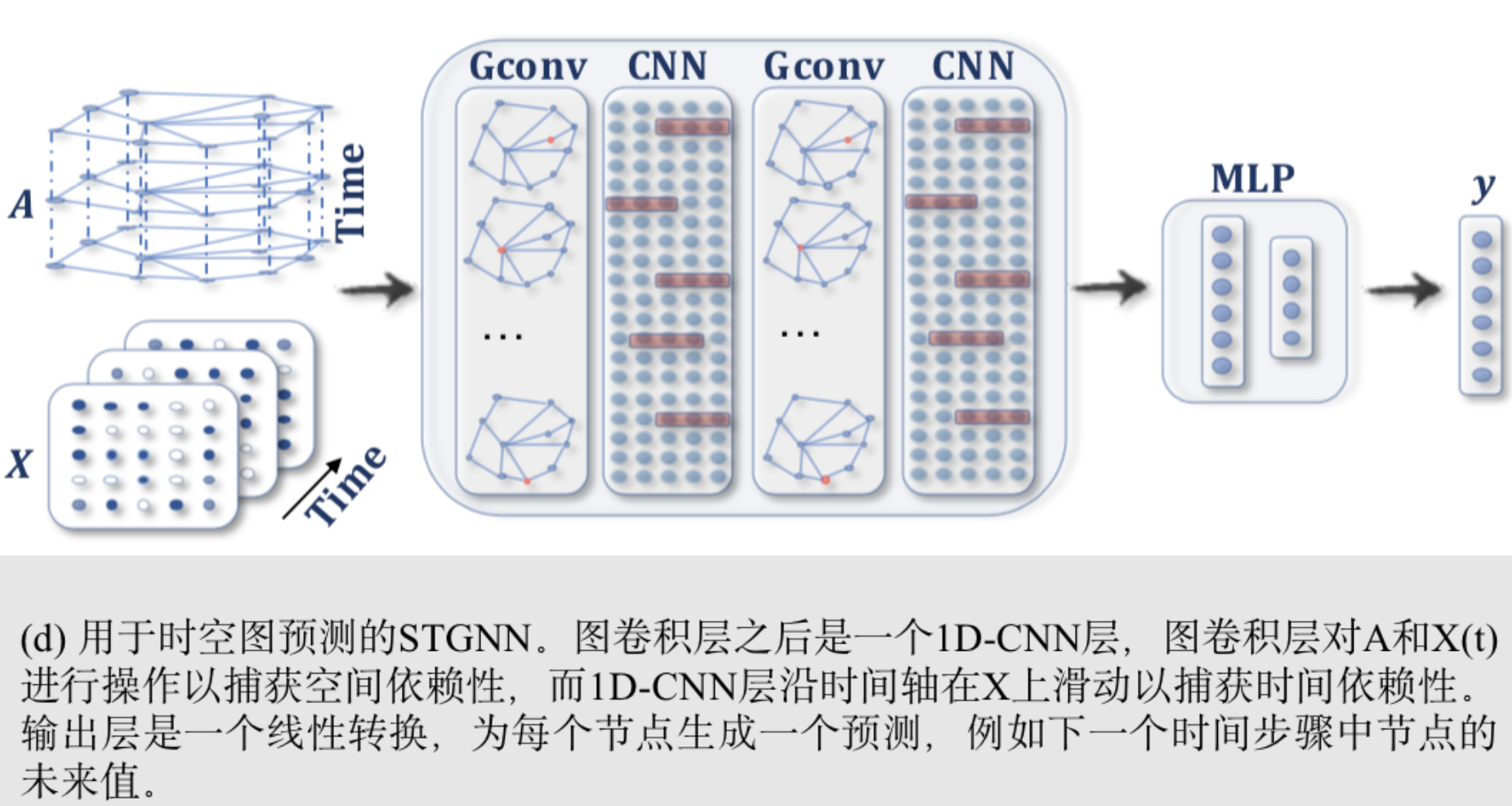
时空图神经网络(Spatial-temporal graph neural network, STGNNs)
旨在从时空图中学习隐藏的模式,在交通速度预测、驾驶员操纵预测和人类行为识别等多种应用中发挥着越来越重要的作用。STGNNs的核心思想是同时考虑空间依赖和时间依赖。目前的许多方法都是通过图卷积来捕获与RNNs或CNNs的空间依赖关系,从而对时间依赖关系进行建模。下图是STGNNs流程图模型。
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
https://zhuanlan.zhihu.com/p/136521625
https://zhuanlan.zhihu.com/p/75307407
https://mp.weixin.qq.com/s/PSrgm7frsXIobSrlcoCWxw
https://zhuanlan.zhihu.com/p/142948273
https://developer.huaweicloud.com/hero/forum.php?mod=viewthread&tid=109580
OpenLDAP
分布式、多平台集成认证系统
ibug在实验室机器整活还行
https://ibug.io/blog/2022/03/linux-openldap-server/
https://harrychen.xyz/2021/01/17/openldap-linux-auth/
https://www.cnblogs.com/dufeixiang/p/11624210.html
改shell
复杂还有bug,我还是改profile吧
https://ibug.io/blog/2022/03/linux-openldap-server/#user-chsh
挂载
挂在同一个地方,肯定是一样的
1 | # shaojiemike @ snode2 in ~ [20:18:20] |
tmpfs是磁盘里的虚拟内存的意思。
设置
具体设置要登录到中央机器上去
1 | # shaojiemike @ hades1 in ~ [20:41:06] |
1 | # shaojiemike @ snode0 in ~ [20:36:26] |
需要进一步的研究学习
- 总共涉及几台机器
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无全局解释器锁(GIL,Global Interpreter Lock)
Python代码的执行由Python虚拟机(解释器)来控制。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同时只有一个线程在运行。所以就会出现尽管你设置了多线程的任务,但是只能跑一个的情况。
但是I/O密集的程序(爬虫)相对好一点,因为I/O操作会调用内建的操作系统C代码,所以这时会释放GIL锁,达到部分多线程的效果。
通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。