CPU(s):64 = the number of logical cores = “Thread(s) per core” × “Core(s) per socket” × “Socket(s)” = 1 * 32 * 2
One socket is one physical CPU package (which occupies one socket on the motherboard);
each socket hosts a number of physical cores, and each core can run one or more threads.
In this case, you have two sockets, each containing a 32-core AMD EPYC 7452 CPU, and since that not supports hyper-threading, each core just run a thread.
syscall: SYSCALL (Fast System Call) and SYSRET (Return From Fast System Call) nx:执行禁用 # NX 位(不执行)是 CPU 中使用的一项技术,用于分隔内存区域,以供处理器指令(代码)存储或数据存储使用 mmxext: AMD MMX extensions fxsr_opt: FXSAVE/FXRSTOR optimizations pdpe1gb: One GB pages (allows hugepagesz=1G) rdtscp: Read Time-Stamp Counter and Processor ID lm: Long Mode (x86-64: amd64, also known as Intel 64, i.e. 64-bit capable)
constant_tsc:TSC(Time Stamp Counter) 以恒定速率滴答 art: Always-Running Timer rep_good:rep 微码运行良好 nopl: The NOPL (0F 1F) instructions # NOPL is long-sized bytes "do nothing" operation nonstop_tsc: TSC does not stop in C states extd_apicid: has extended APICID (8 bits) (Advanced Programmable Interrupt Controller) aperfmperf: APERFMPERF # On x86 hardware, APERF and MPERF are MSR registers that can provide feedback on current CPU frequency. eagerfpu: Non lazy FPU restore
Intel-defined CPU features, CPUID level 0x00000001 (ecx)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
pni: SSE-3 (“2004年,新内核Prescott New Instructions”) pclmulqdq: 执行四字指令的无进位乘法 - GCM 的加速器) monitor: Monitor/Mwait support (Intel SSE3 supplements) ssse3:补充 SSE-3 fma:融合乘加 cx16: CMPXCHG16B # double-width compare-and-swap (DWCAS) implemented by instructions such as x86 CMPXCHG16B sse4_1:SSE-4.1 sse4_2:SSE-4.2 x2apic: x2APIC movbe:交换字节指令后移动数据 popcnt:返回设置为1指令的位数的计数(汉明权,即位计数) aes/aes-ni:高级加密标准(新指令) xsave:保存处理器扩展状态:还提供 XGETBY、XRSTOR、XSETBY avx:高级矢量扩展 f16c:16 位 fp 转换 (CVT16) rdrand:从硬件随机数生成器指令中读取随机数
More extended AMD flags: CPUID level 0x80000001, ecx
异常简单,默认安装在自己.local/bin下,会自动修改bashrc/zshrc On Linux and macOS systems, this is done as follows:
1
curl https://sh.rustup.rs -sSf | sh
基础语法
printf
1 2 3 4 5 6 7
impl ClassName { pub fn printFunc() { let a = 12; println!("a is {0}, a again is {0}", a); //println 不是一个函数,而是一个宏规则。所以有感叹号 } }
变量
Rust 是强类型语言,但具有自动判断变量类型的能力。
1 2 3 4 5 6 7 8 9 10 11
//可以指定类型 let a: u64 = 123; //不可变变量 let a = 123; let a = 456; //不是复制是,重新绑定 let s2 = s1.clone(); //这才是真复制 //变量 let mut a = 123; a = 456; //常量 const a: i32 = 123;
函数
函数返回值
Rust 函数声明返回值类型的方式:在参数声明之后用 -> 来声明函数返回值的类型(不是 : )。
不写return是将最后一个当作返回值?(貌似是
Rust是如何实现内存安全的呢?
内存安全
buffer overflow
null pointer dereference
use after free
use of uninitialized memory
illegal free (of an already-freed pointer, or a non-malloced pointer)
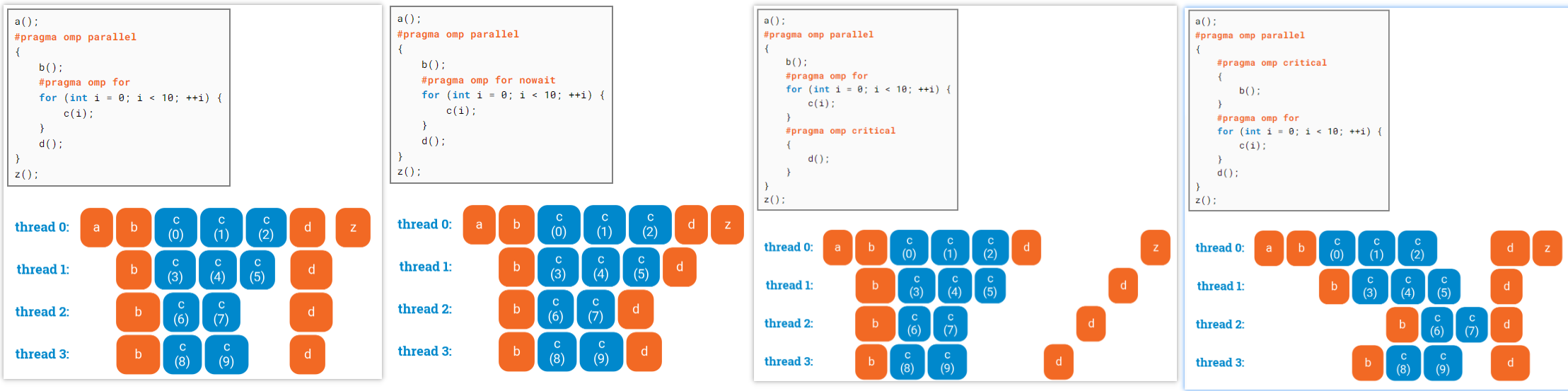
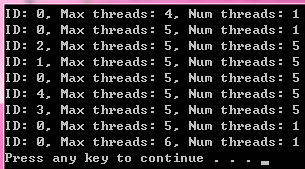
### critical vs atomic The fastest way is neither critical nor atomic. Approximately, addition with critical section is 200 times more expensive than simple addition, atomic addition is 25 times more expensive then simple addition.(**maybe no so much expensive**, the atomic operation will have a few cycle overhead (synchronizing a cache line) on the cost of roughly a cycle. A critical section incurs **the cost of a lock**.)
The fastest option (not always applicable) is to give each thread its own counter and make reduce operation when you need total sum.
### critical vs ordered omp critical is for mutual exclusion(互斥), omp ordered refers to a specific loop and ensures that the region **executes sequentually in the order of loop iterations**. Therefore omp ordered is stronger than omp critical, but also only makes sense within a loop.
omp ordered has some other clauses, such as simd to enforce the use of a single SIMD lane only. You can also specify dependencies manually with the depend clause.
Note: Both omp critical and omp ordered regions have an implicit memory flush at the entry and the exit.
### ordered example
vector<int> v;
#pragma omp parallel for ordered schedule(dynamic, anyChunkSizeGreaterThan1) for (int i = 0; i < n; ++i){ … … … #pragma omp ordered v.push_back(i); }
1 2 3 4 5 6
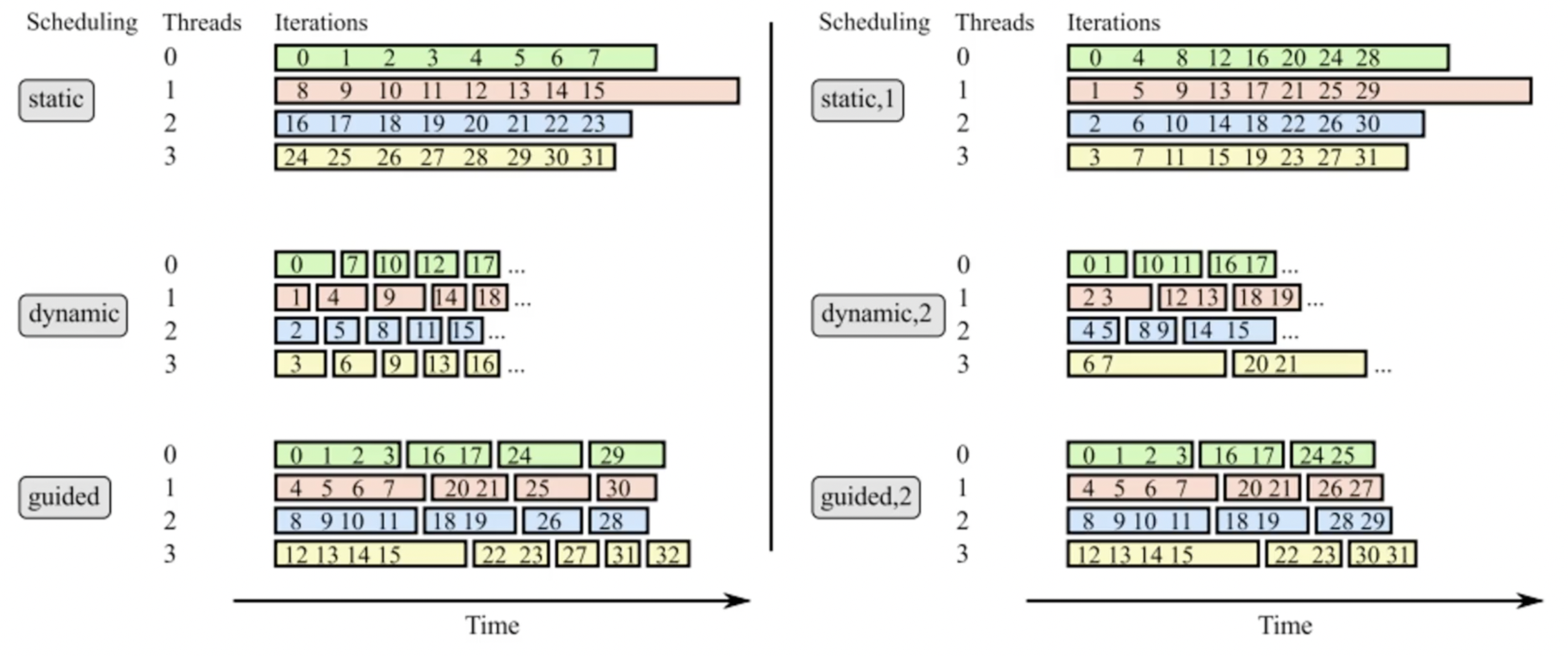
``` tid List of Timeline iterations 0 0,1,2 ==o==o==o 1 3,4,5 ==.......o==o==o 2 6,7,8 ==..............o==o==o
= shows that the thread is executing code in parallel. o is when the thread is executing the ordered region. . is the thread being idle, waiting for its turn to execute the ordered region.
With schedule(static,1) the following would happen:
1 2 3 4 5
tid List of Timeline iterations 0 0,3,6 ==o==o==o 1 1,4,7 ==.o==o==o 2 2,5,8 ==..o==o==o
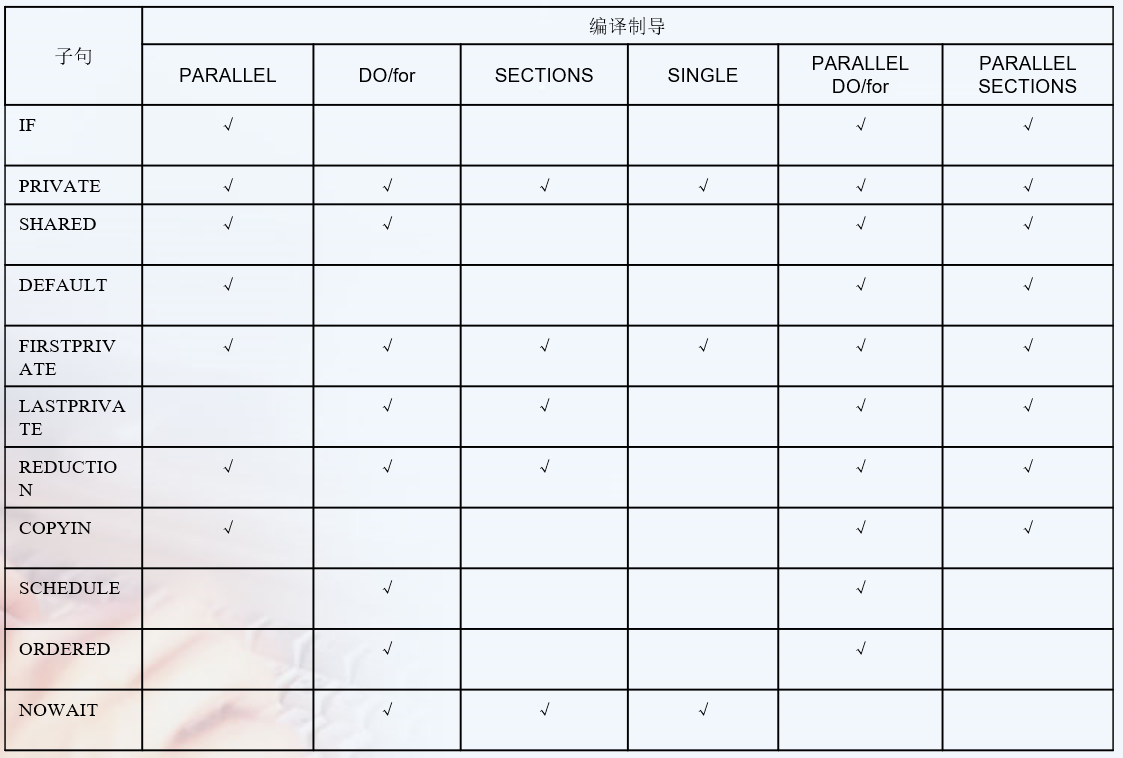
private variables are not initialised, i.e. they start with random values like any other local automatic variable
firstprivate initial the value as the before value.
lastprivate save the value to the after region. 这个last的意思不是实际最后运行的一个线程,而是调度发射队列的最后一个线程。从另一个角度上说,如果你保存的值来自随机一个线程,这也是没有意义的。 firstprivate and lastprivate are just special cases of private
1 2 3 4 5 6 7
#pragma omp parallel { #pragma omp for lastprivate(i) for (i=0; i<n-1; i++) a[i] = b[i] + b[i+1]; } a[i]=b[i];
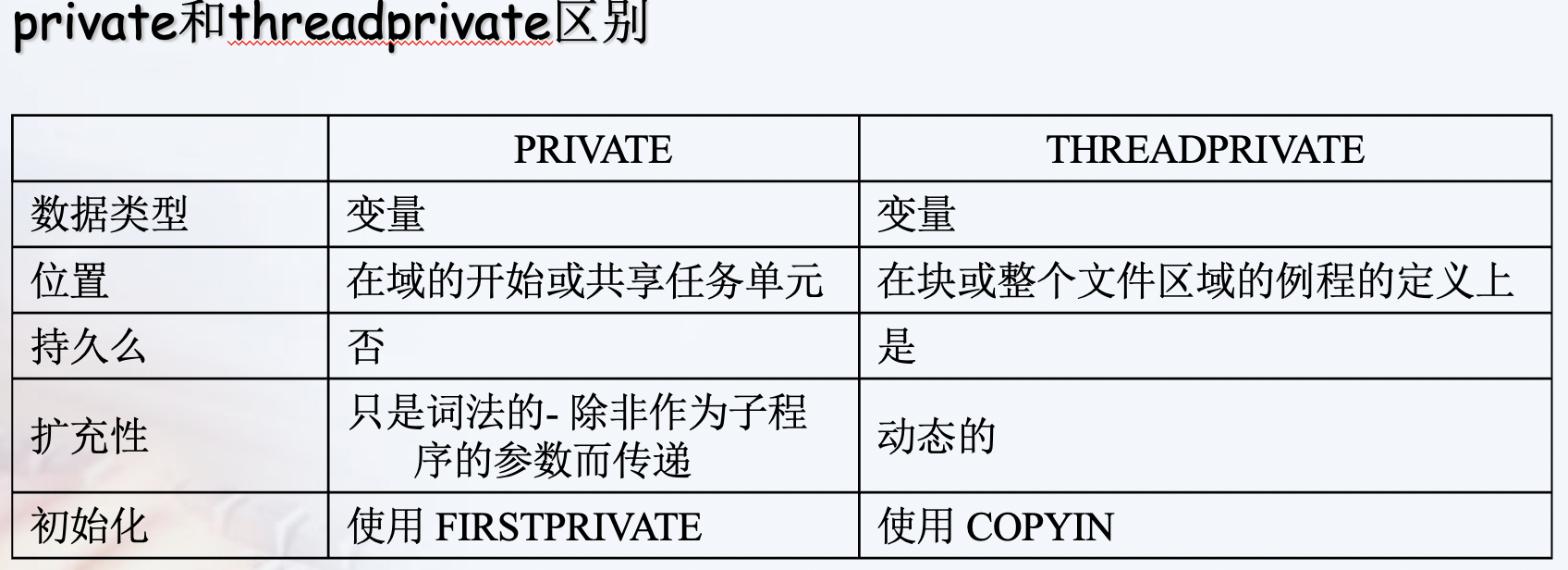
private vs threadprivate
A private variable is local to a region and will most of the time be placed on the stack. The lifetime of the variable’s privacy is the duration defined of the data scoping clause. Every thread (including the master thread) makes a private copy of the original variable (the new variable is no longer storage-associated with the original variable).
A threadprivate variable on the other hand will be most likely placed in the heap or in the thread local storage (that can be seen as a global memory local to a thread). A threadprivate variable persist across regions (depending on some restrictions). The master thread uses the original variable, all other threads make a private copy of the original variable (the master variable is still storage-associated with the original variable).