简介
软件产品的商业成功要点是什么?
秋招面试时遇到高铁柱前辈。问了相关的问题(对AI专业的人可能是基础知识)

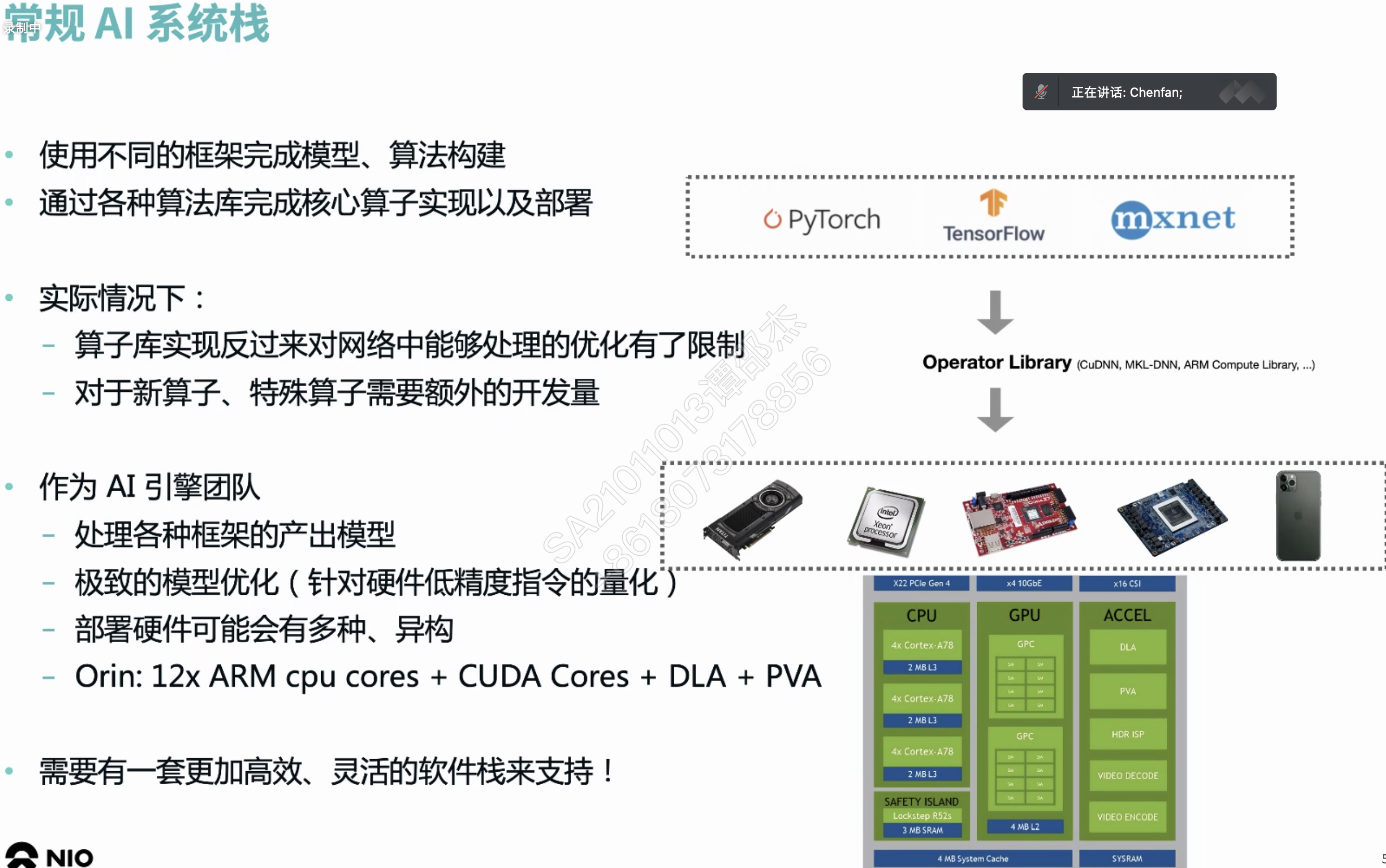
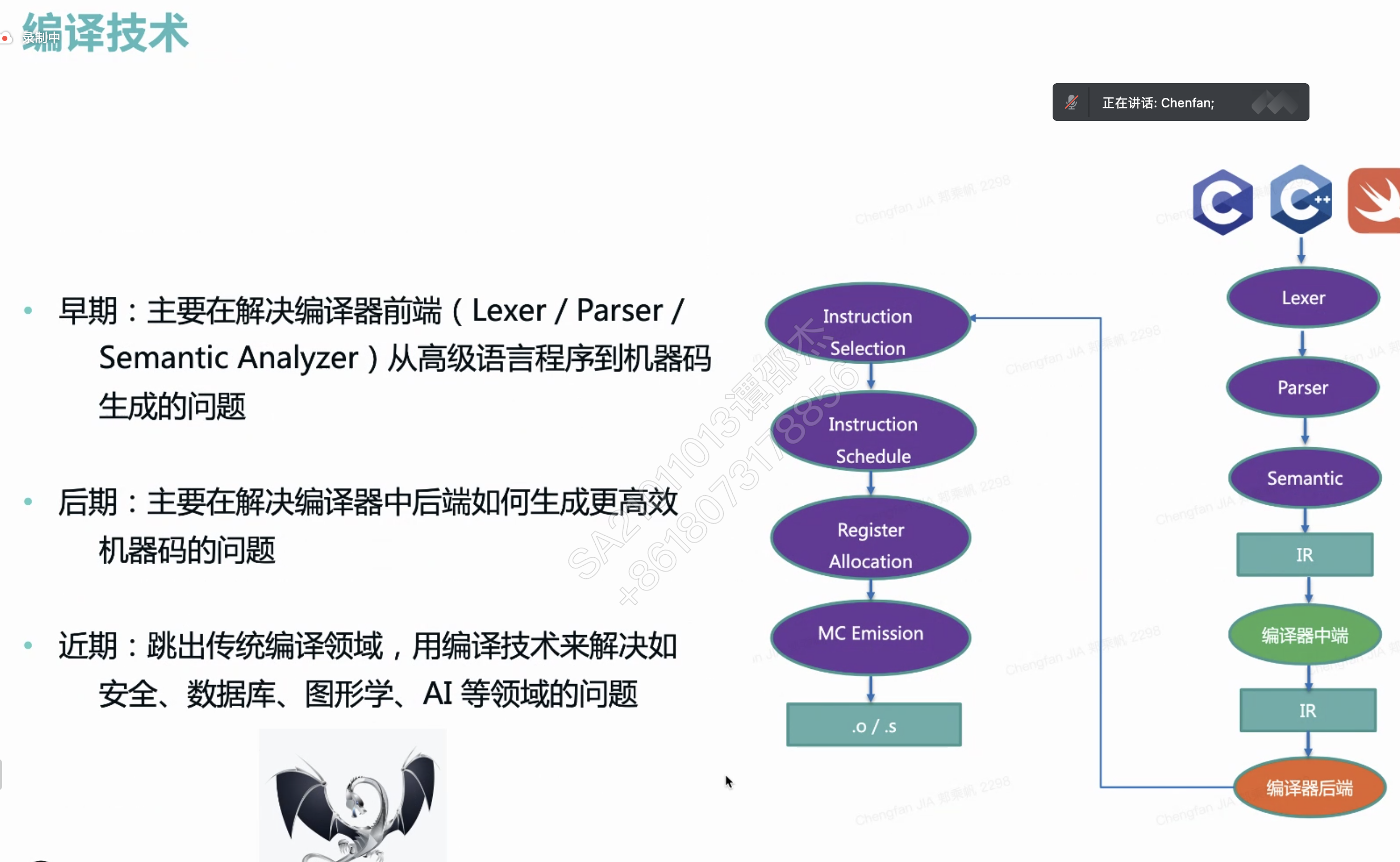
数字信号处理器 (Digital signal processor)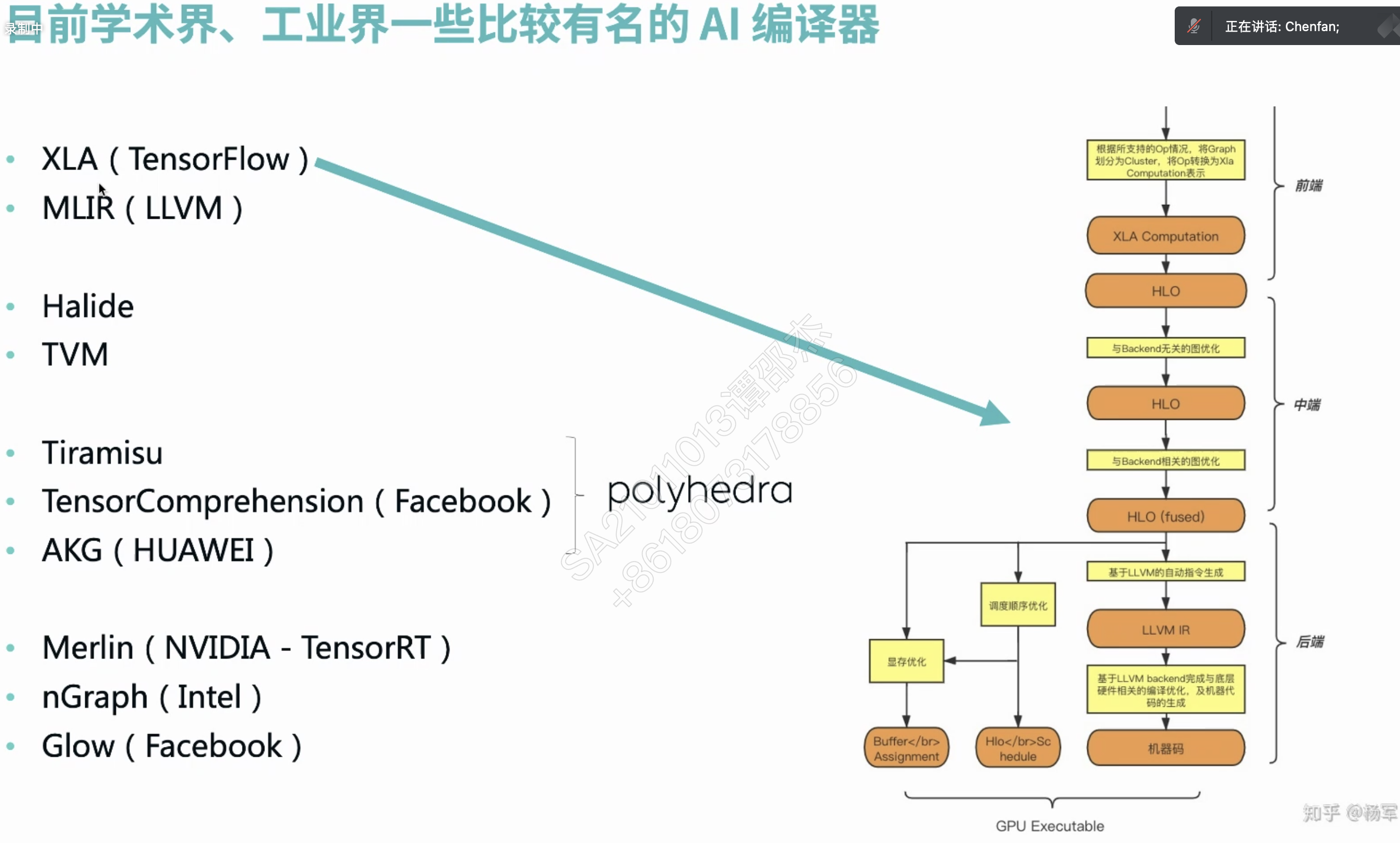
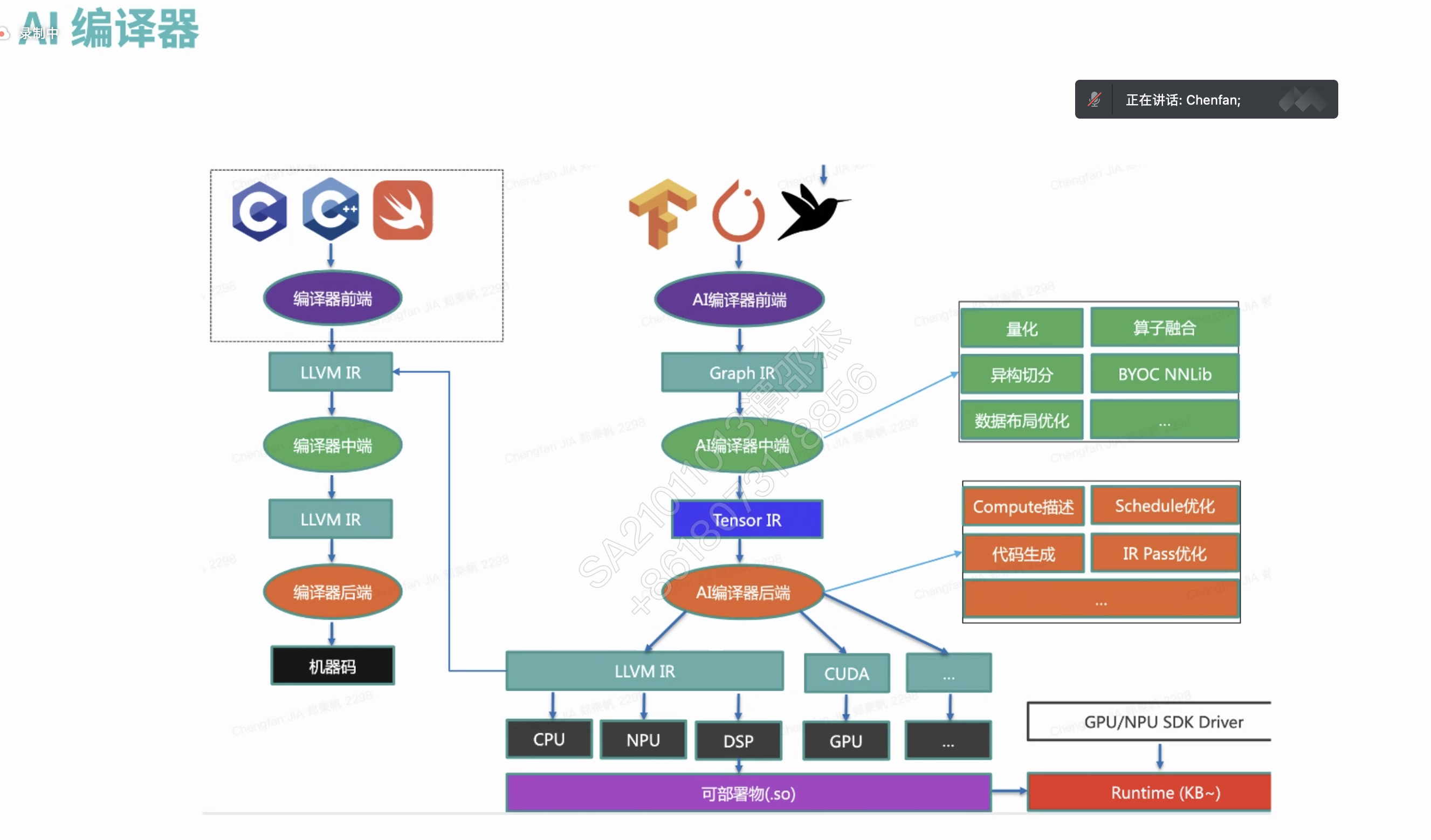
HLO 简单理解为编译器 IR。
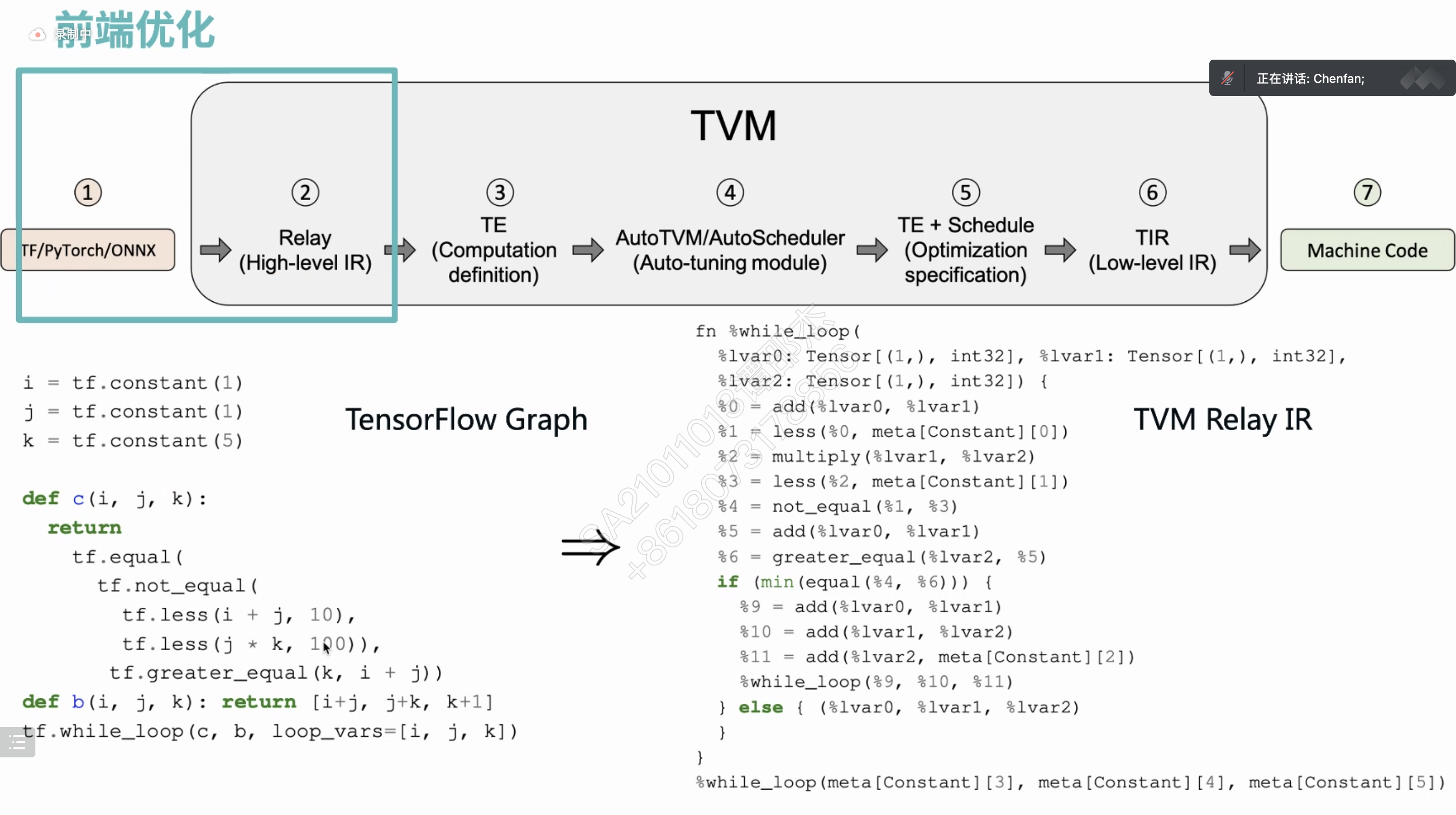
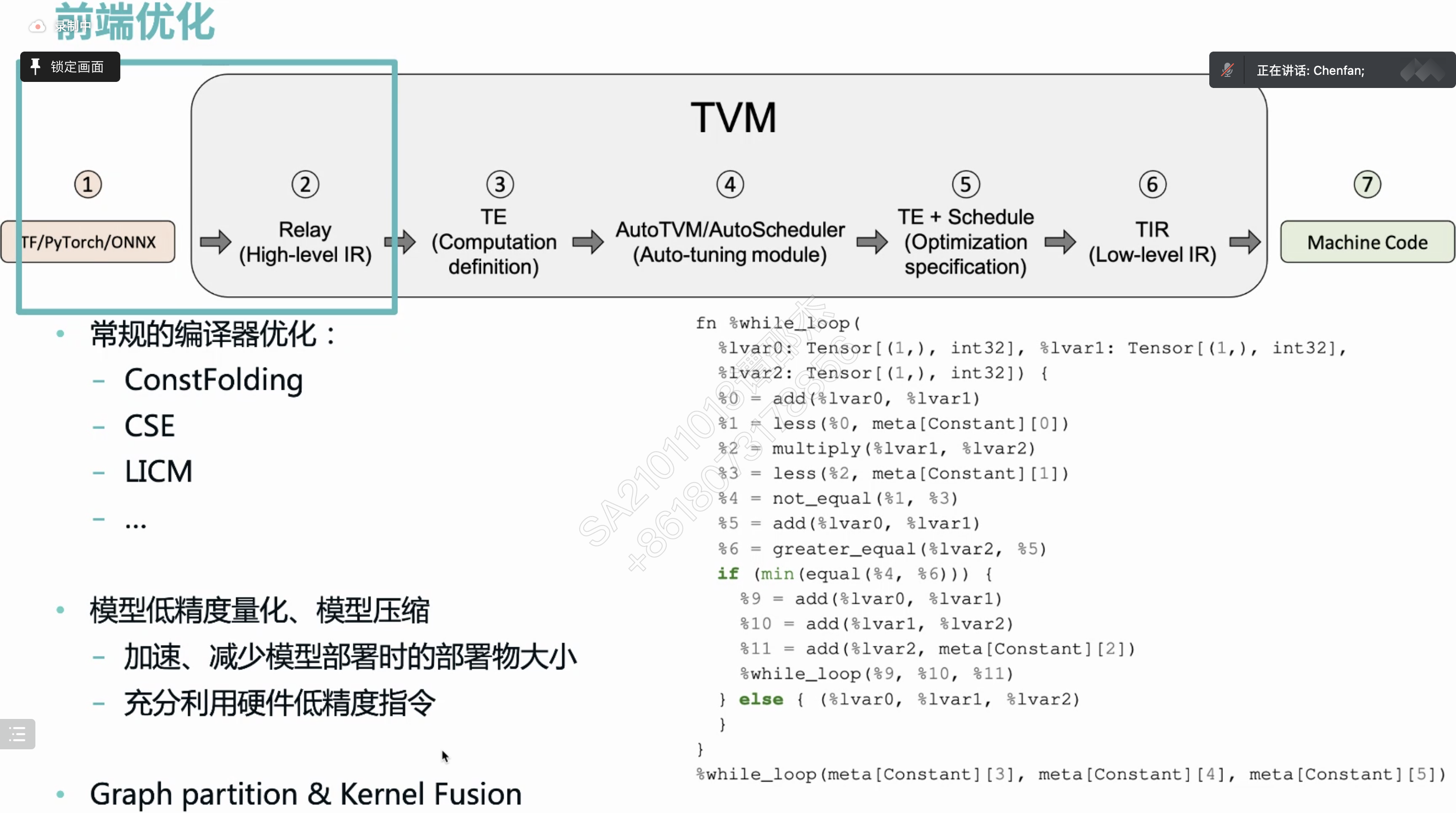
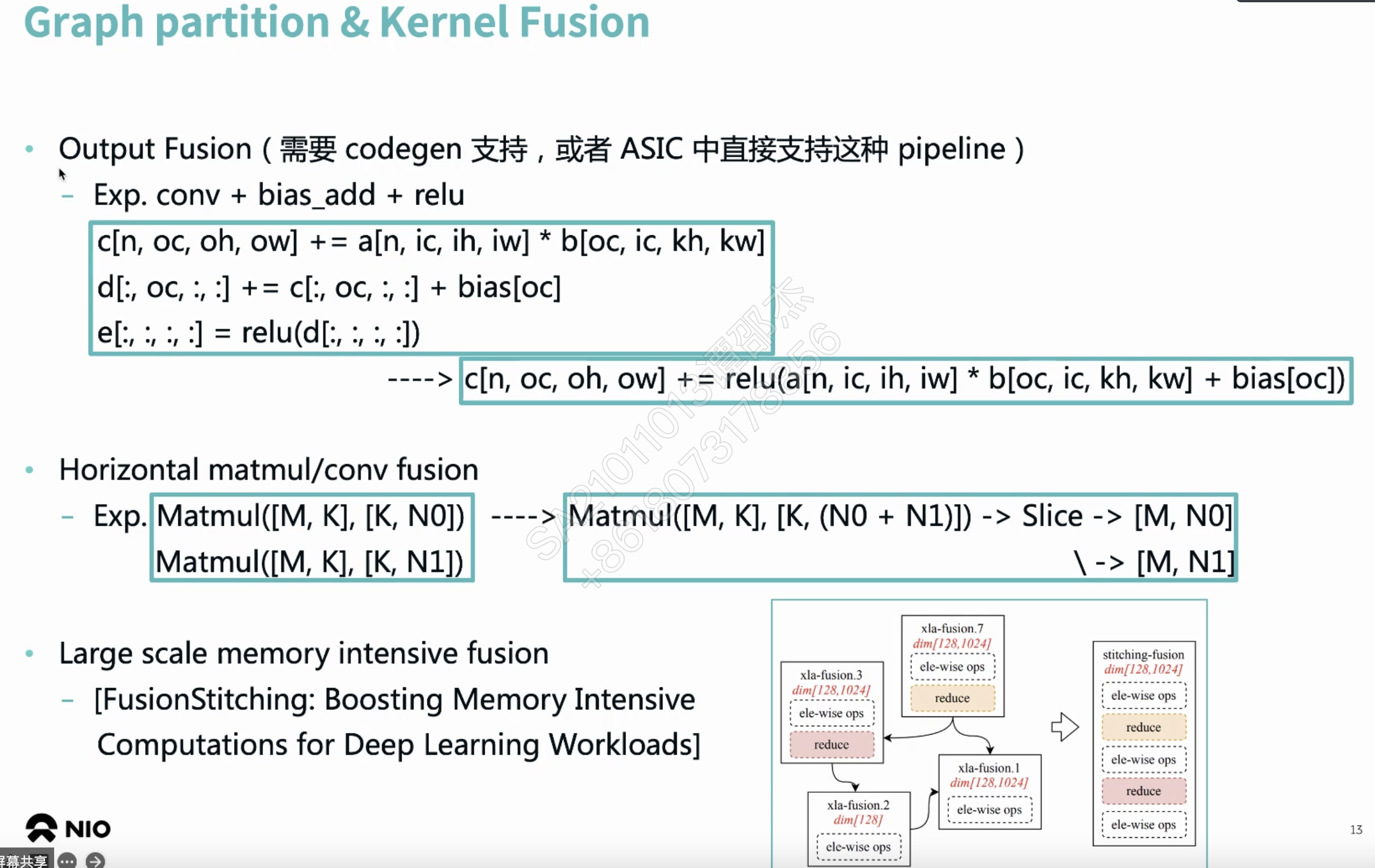
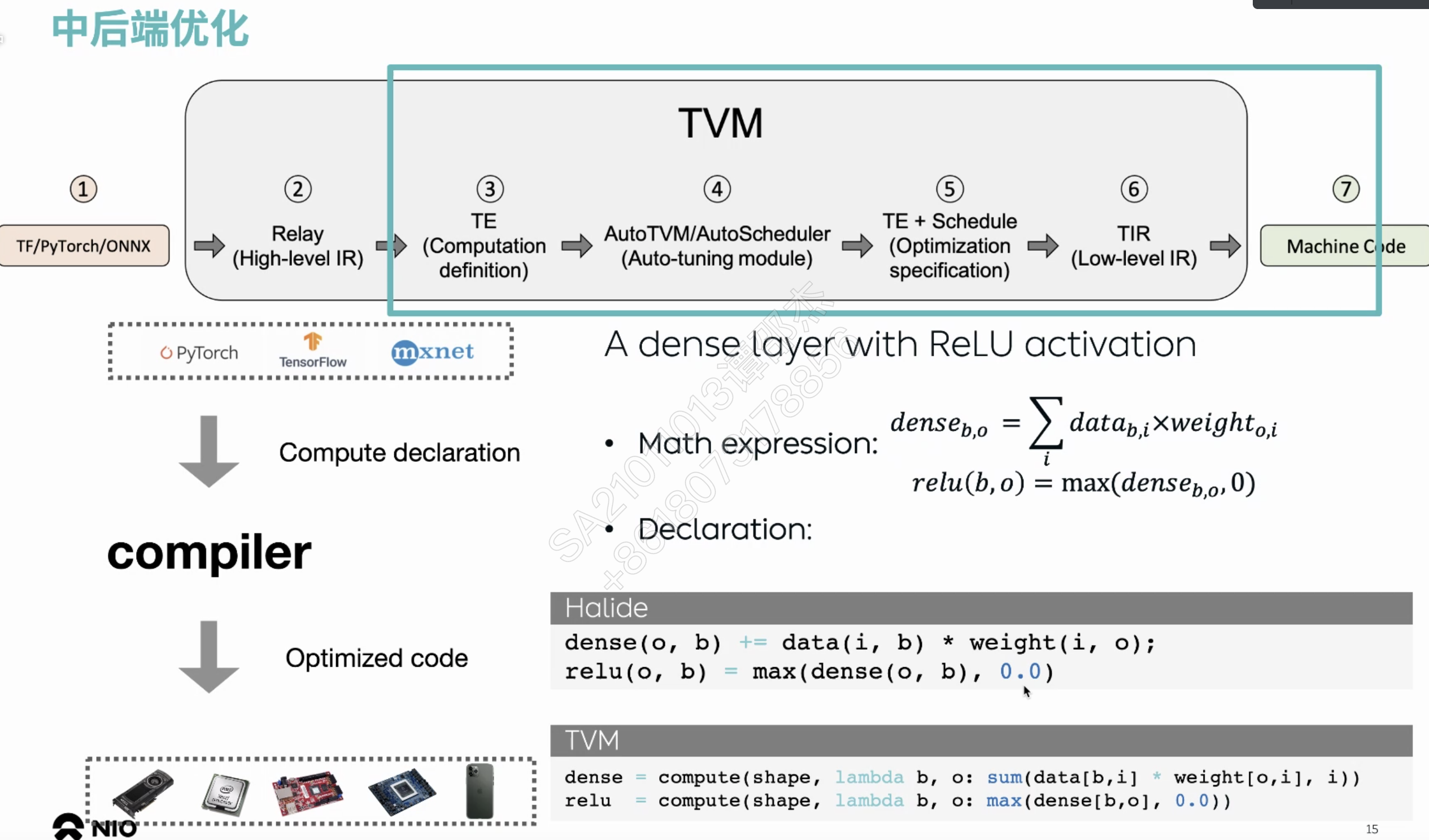
把中间算子库替换成编译器?

暂时不好支持张量
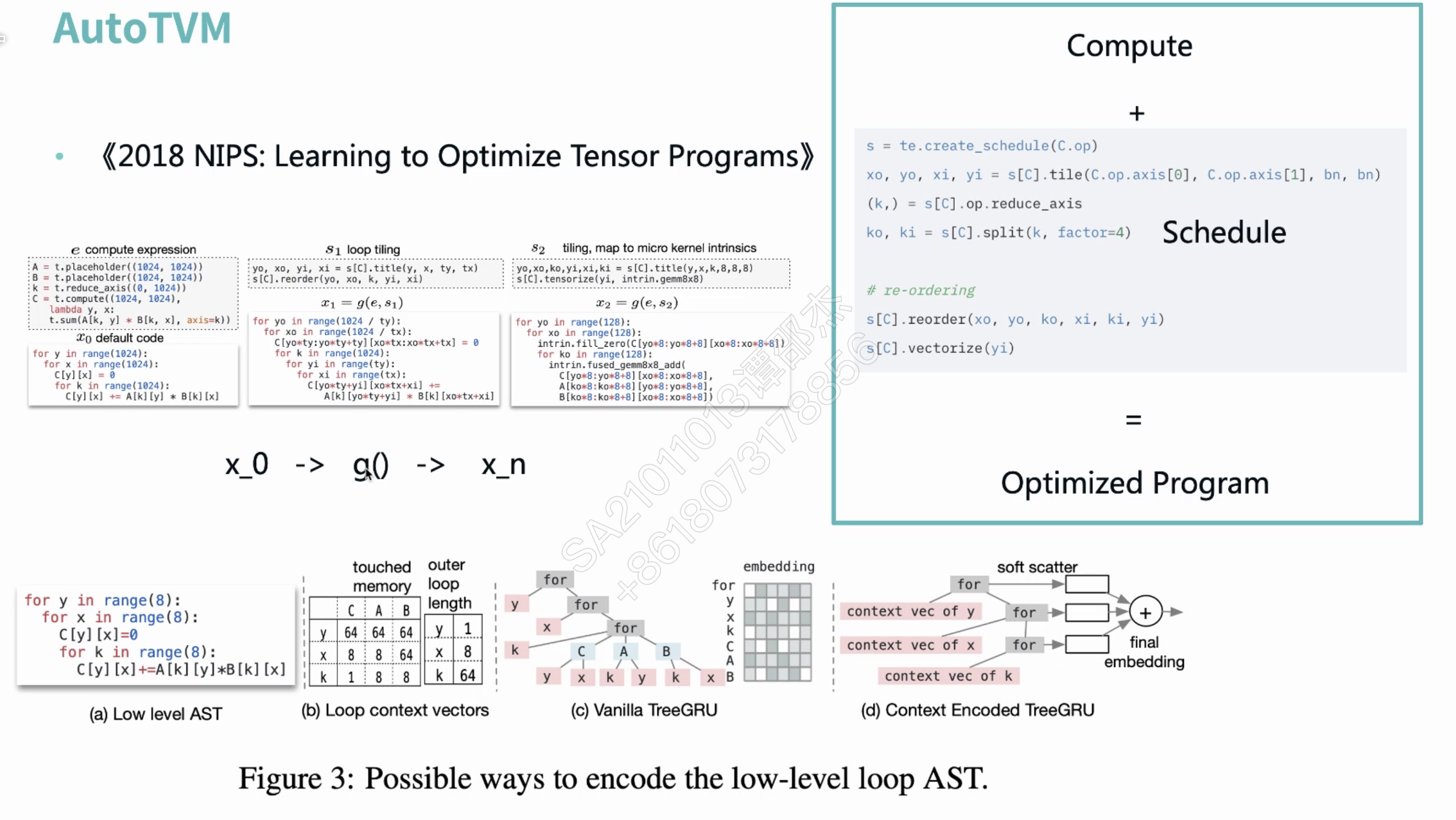
AI自动调整变化来调优
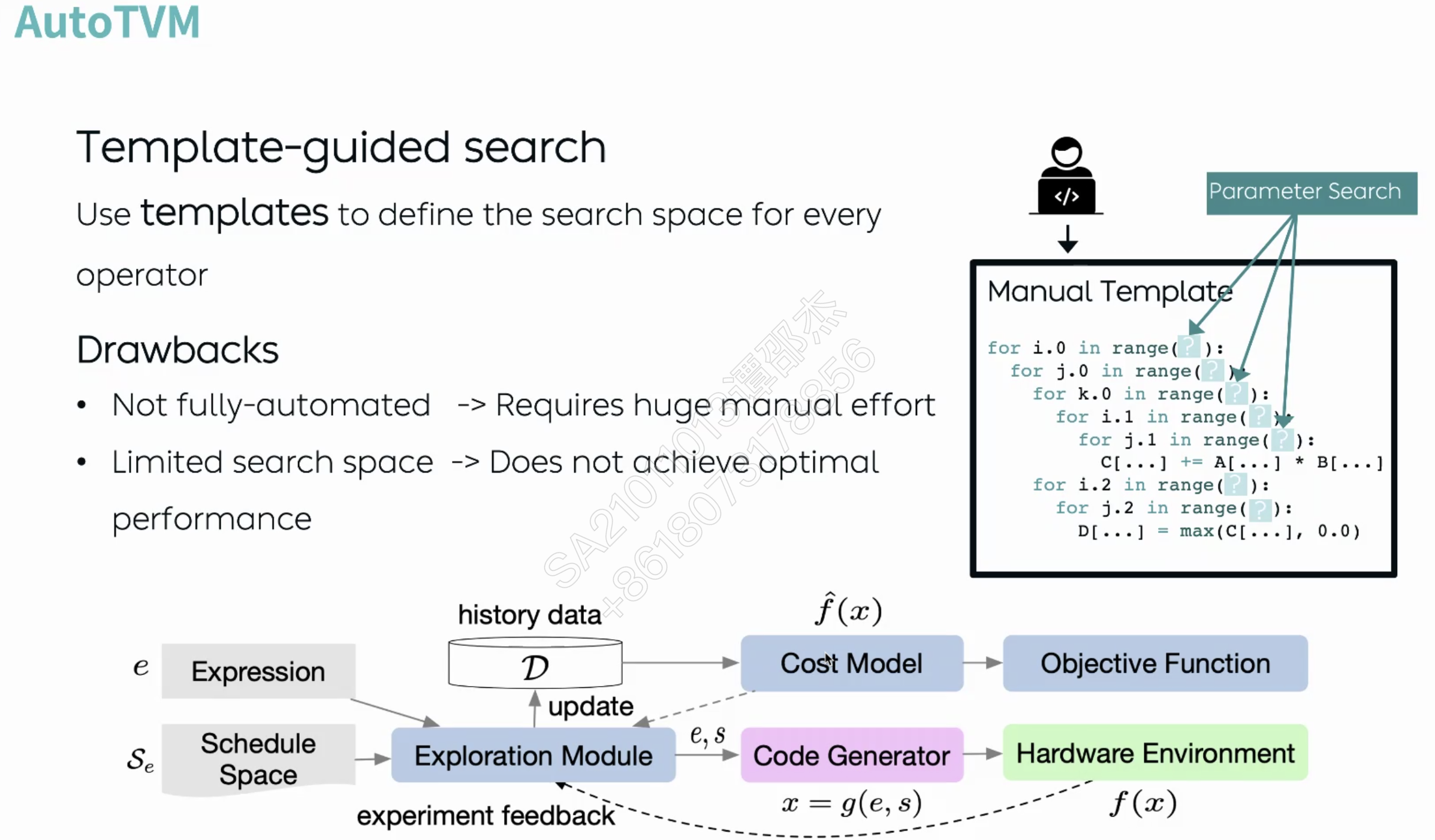
自动调参。缺点:

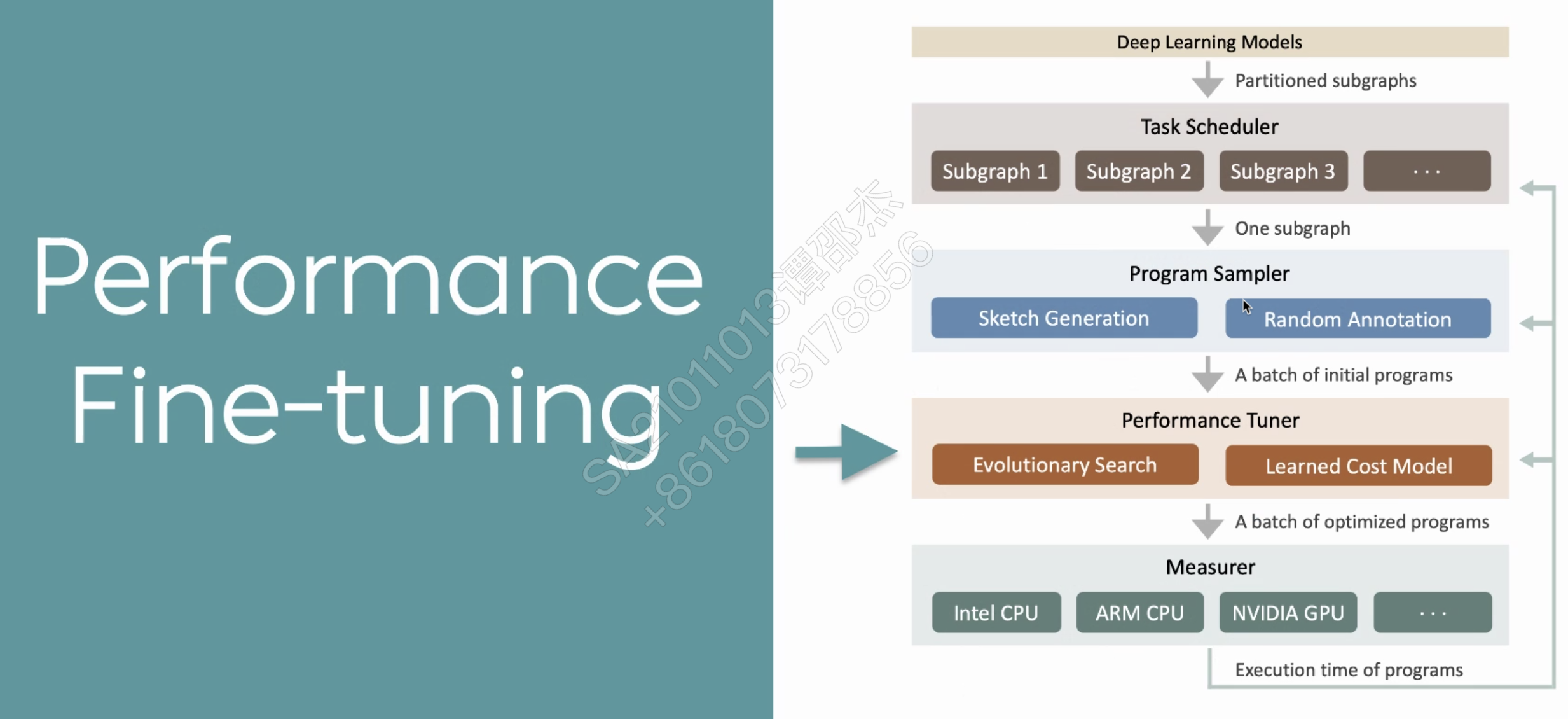
随机各级循环应用优化策略(并行,循环展开,向量化

介绍了Ansor效果很好
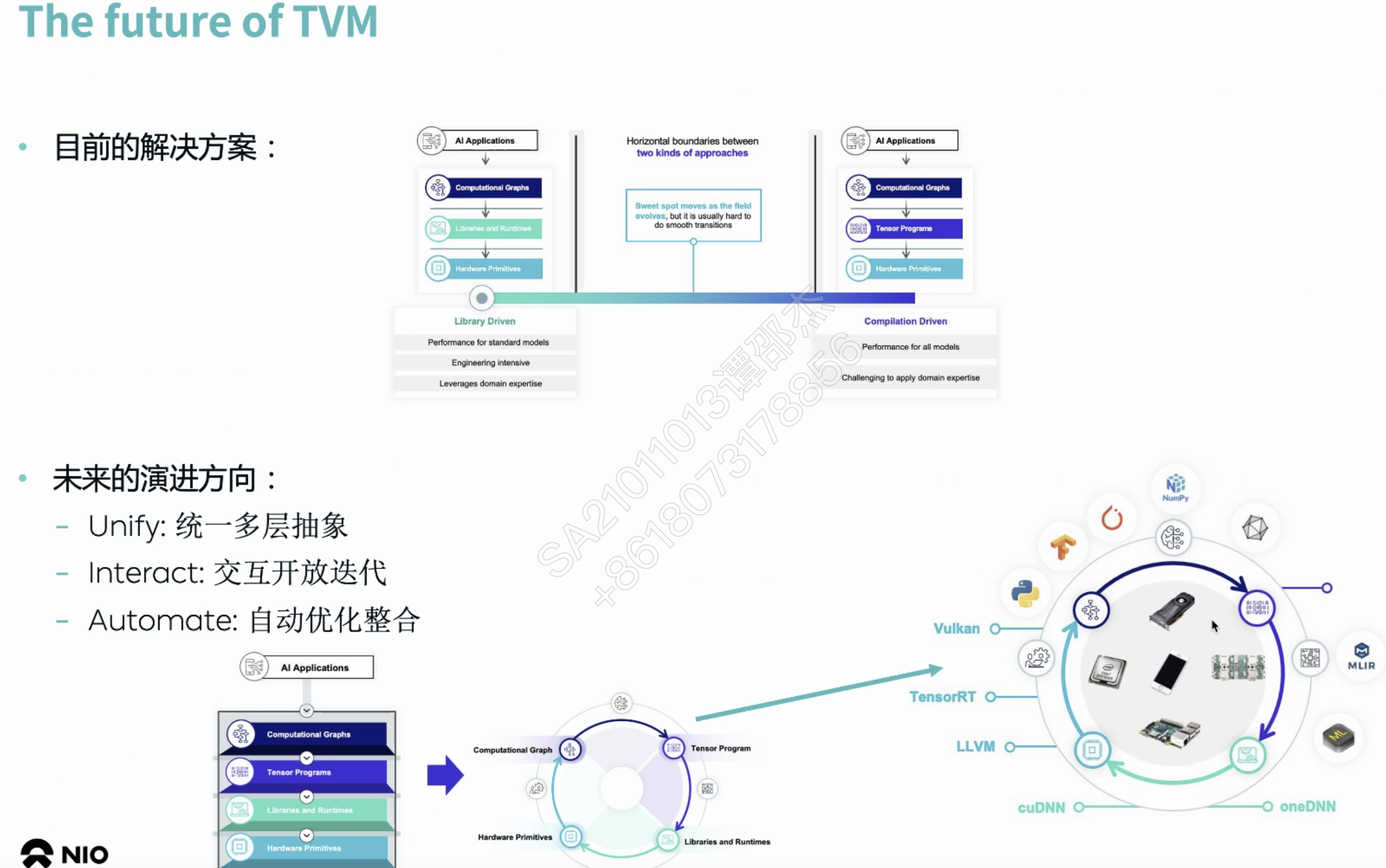
暂无
暂无
官网要钱,有泄漏的50G的模型,B站有up抽取了其中的一个做了整合包
不知道,会不会有版权问题下架了。
1 | https://pan.baidu.com/s/1AAHoNYYano6q7XBl3luCcg |
可以把start.bat改成sh脚本在实验室A100上跑
作者:秋葉aaaki https://www.bilibili.com/read/cv19038600?spm_id_from=333.788.b_636f6d6d656e74.7 出处:bilibili