常规广度优先搜索的局限性
简单bfs是每次从队列中取出当前的访问节点后,之后就将它的邻接节点加入到队列中,这样明显不利于并行化。
实现一: 两队列
使用了两个队列,第一个队列存当前同一层的节点,第二个队列用来存储当前层节点的所有邻接节点(下一层节点),等到当前层的节点全部访问完毕后,再将第一个队列与第二个队列进行交换,即可。
这样做的优势在于便于以后的并行化。同一层的节点可以一起运行,不会受到下一层节点的干扰。
但是写有问题,并行计算要储存下一层节点时,push操作不是原子的,需要加锁。
1 | q1.push(1); |
实现二:PBFS

思想和实现一一样,但是对并行时竞争情况有处理。
思想:都是将并行处理的一层节点bag的相邻节点存到下一次处理的bag中。
竞争:
- 第 18 行的 v.dist 更新为 d+1。
- 幸运的是,由于都是设置为同一个值,该竞争不影响结果。
- 第19行,可能同时将同一个节点加入out-bag,导致额外的工作
- 但是这个bag数据结构是具有元素各异的性质,正好解决这个问题。
- 根本没有元素各异好吧。
- 第19行,可能同时将同一个节点加入out-bag,不会写同一个地方吗?insert
最后还是要加锁,屮。
辅助数据结构 - pennant
辅助数据结构,称为 “pennant”, 是一个\(2^k\)个节点的特殊树。根只有个left子节点,该子节点有个完整是二叉树。
通过这个辅助数据结构,可以实现动态无序集的 bag 数据结构
注意,普通的k层完全二叉树,有$$1+2+4+2^{k-1}=2^k-1$$个节点。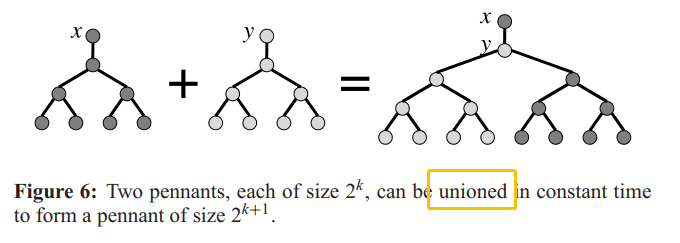
1 | PENNANT-UNION(x,y) |
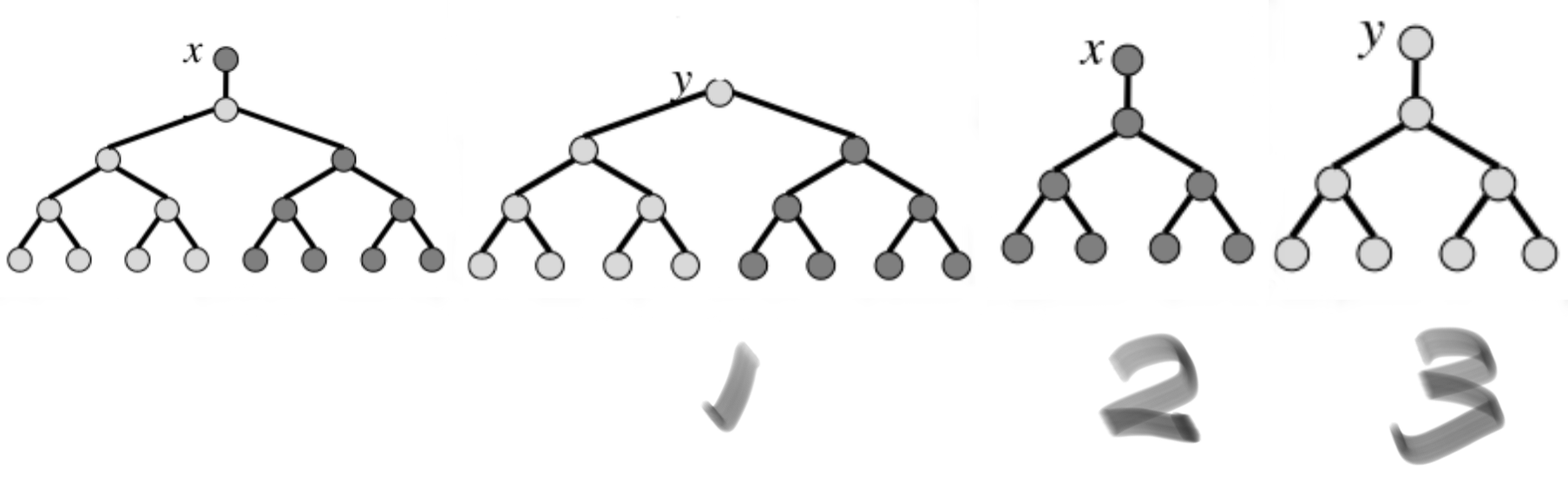
1 | PENNANT-SPLIT(x) |
数据结构 - bags
bag是pennant的集合,其中没有相同大小的pennant。PBFS采用固定大小的数组S[0…r]称作 backbone 骨干。
数组中的第k元素S[k]为空或者保存着指向大小为\(2^k\)的pennant。可知,整个数组S[0…r]最多保存\(2^{r+1}\)元素。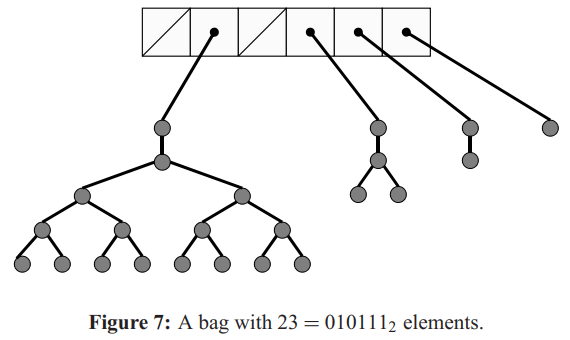
所以BAG-CREATE分配了保存空指针固定大小的数组backbone,会花费Θ(r)时间。
This bound can be improved to O(1) by
keeping track of the largest nonempty index in the backbone.
BAG-Insert类似二进制计数器递增的过程
1 | BAG-INSERT(S,x) |
1 | BAG-UNION(S1,S2) |
BAG-UNION(S1,S2)因为每一个PENNANT-UNION都需要固定的时间,计算FA(x,y,z)的值也需要恒定的时间。计算结果包主干中的所有条目需要Θ(r)时间。该算法可以改进为Θ(lgn),其中n是两个包中较小的包中的元素数,方法是保持每个包主干的最大非空索引,并将索引较小的包合并为索引较大的包
其中FA(x,y,z)相当于三个数的加法,c是进位,s是余位。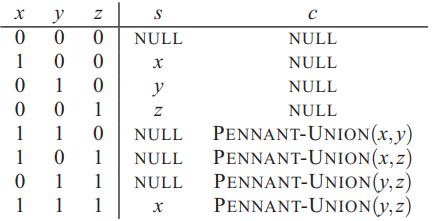
函数解释
函数时间开销
BAG-CREATE O(1)
BAG-INSERT(n) O(1)-O(lgn)
BAG-UNION(n) ~O(lgn)
函数时间开销
需要进一步的研究学习
暂无
遇到的问题
PBFS:
- 11行为什么是lg呢,全部遍历不好吗?
- 因为存的是\(2^r\)的元素
This bound can be improved to O(1) by
keeping track of the largest nonempty index in the backbone.
开题缘由、总结、反思、吐槽~~
flood fill的需要
参考文献
https://www.cnblogs.com/JsonZhangAA/p/9016896.html
https://zhuanlan.zhihu.com/p/134637247
A Work-Efficient Parallel Breadth-First Search Algorithm (or How to Cope with the Nondeterminism of Reducers) from ACM SPAA 2010