DRAM types: Size, Latency, Bandwidth, Energy Consumption
这篇文章主要聚焦于各种计算设备的DRAM的参数,以及发展趋势。
DRAM types: Size, Latency, Bandwidth, Energy Consumption
这篇文章主要聚焦于各种计算设备的DRAM的参数,以及发展趋势。
按照PIM core和memory的距离分类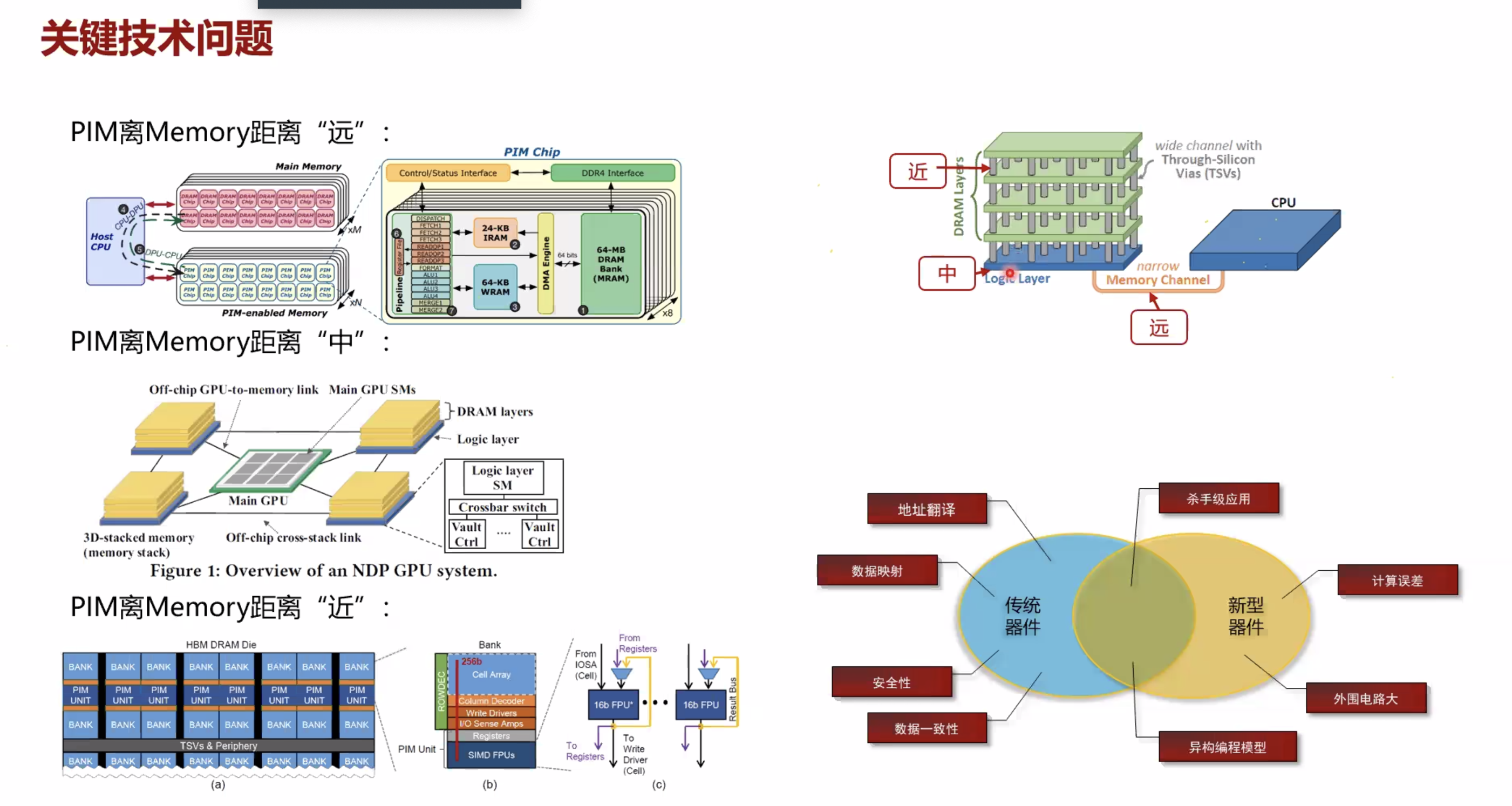
新的内存工艺使得内存的最小电路单元具有计算能力(忆阻器)
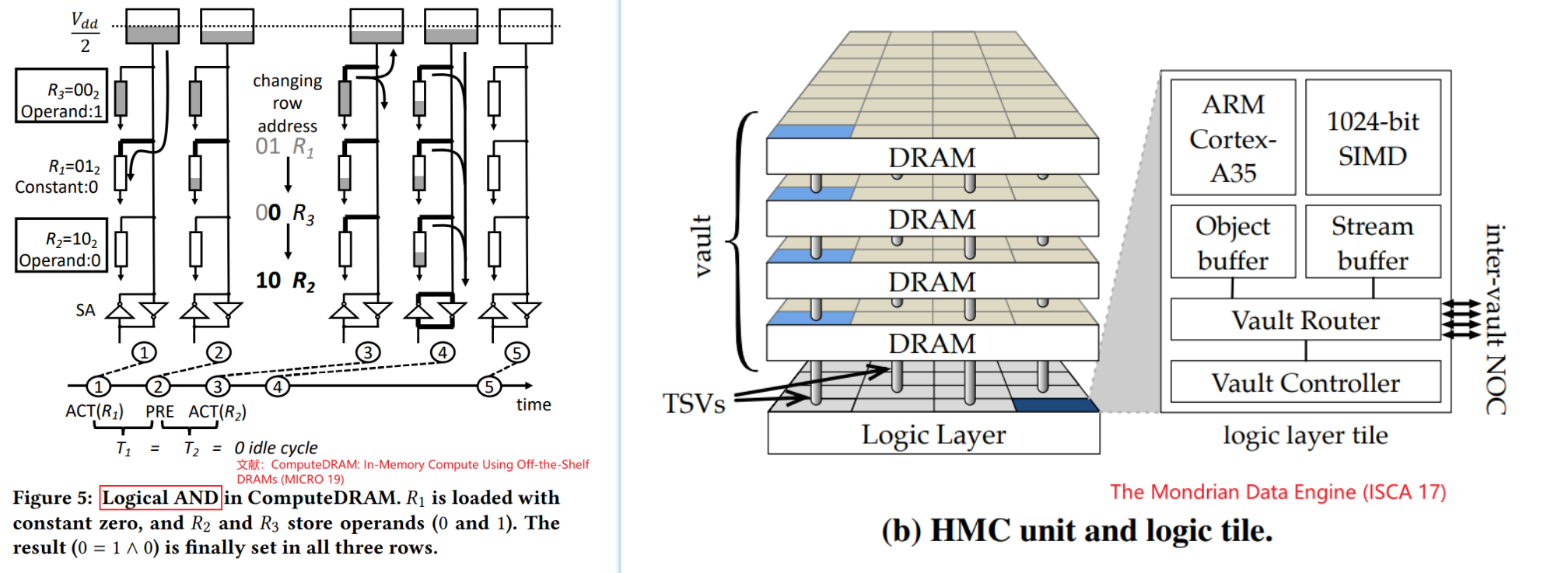
基于现有的商业DRAM和处理器的设计(加速的上限低一些,但是落地推广应用的阻力也越小, 应用范围更广,编程困难低)
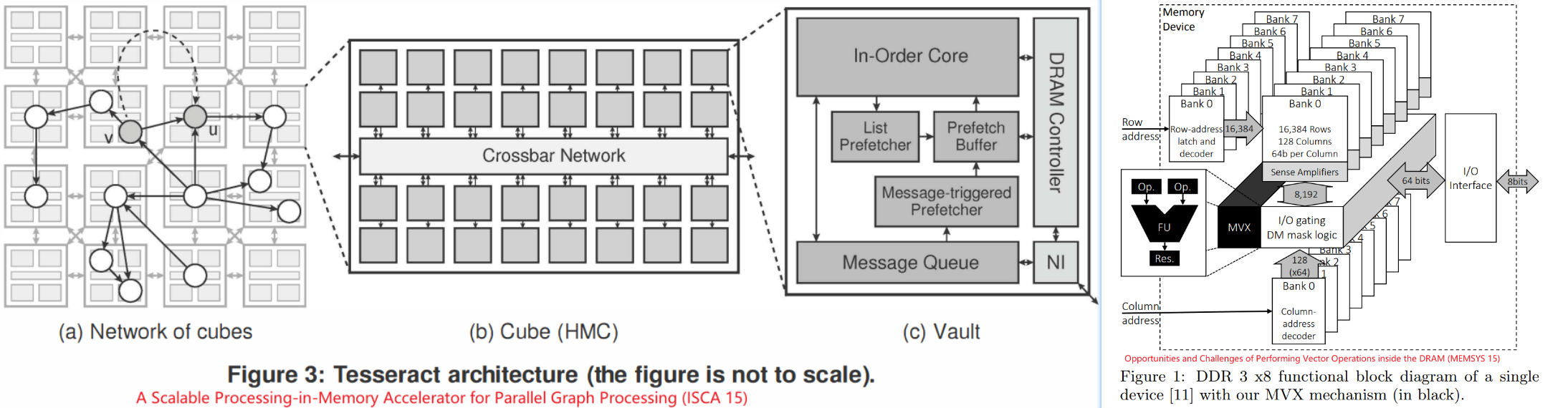
基于3D堆叠memory(HMC)的设计(Starting from HMC 2.0, it supports the execution of
18 atomic operations in its logic layer.)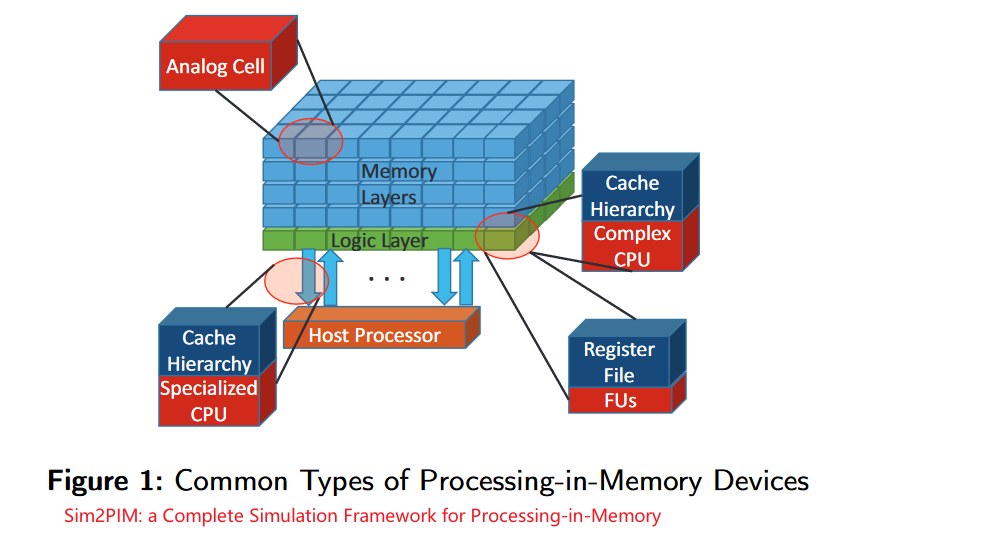
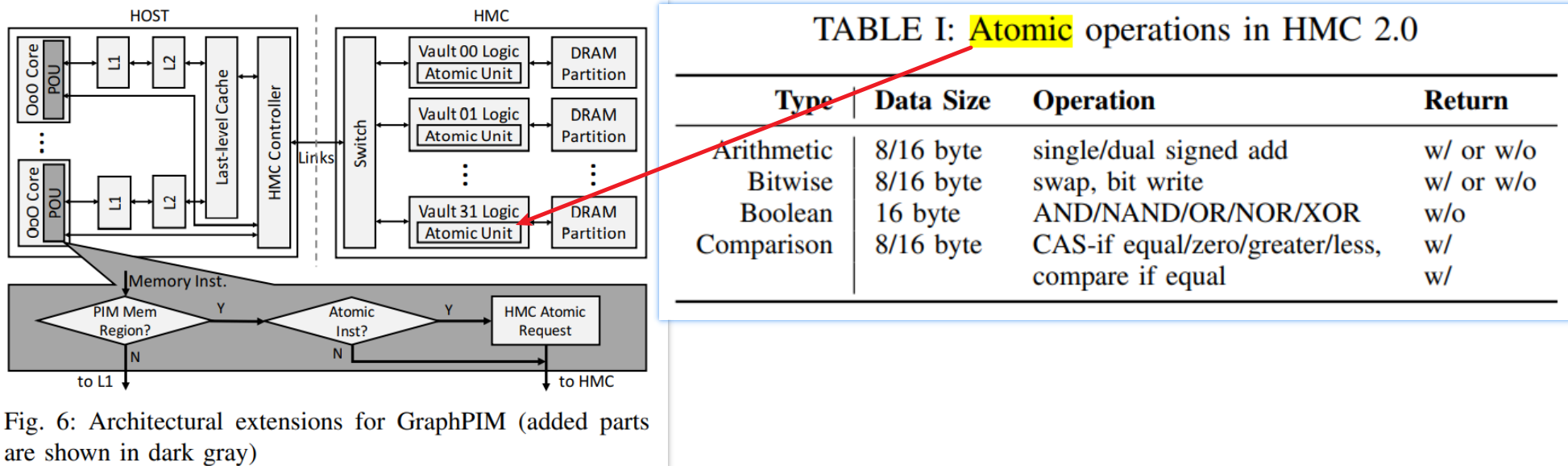
根据PIM距离Memory的距离分成三类
https://arxiv.org/pdf/2110.01709.pdf
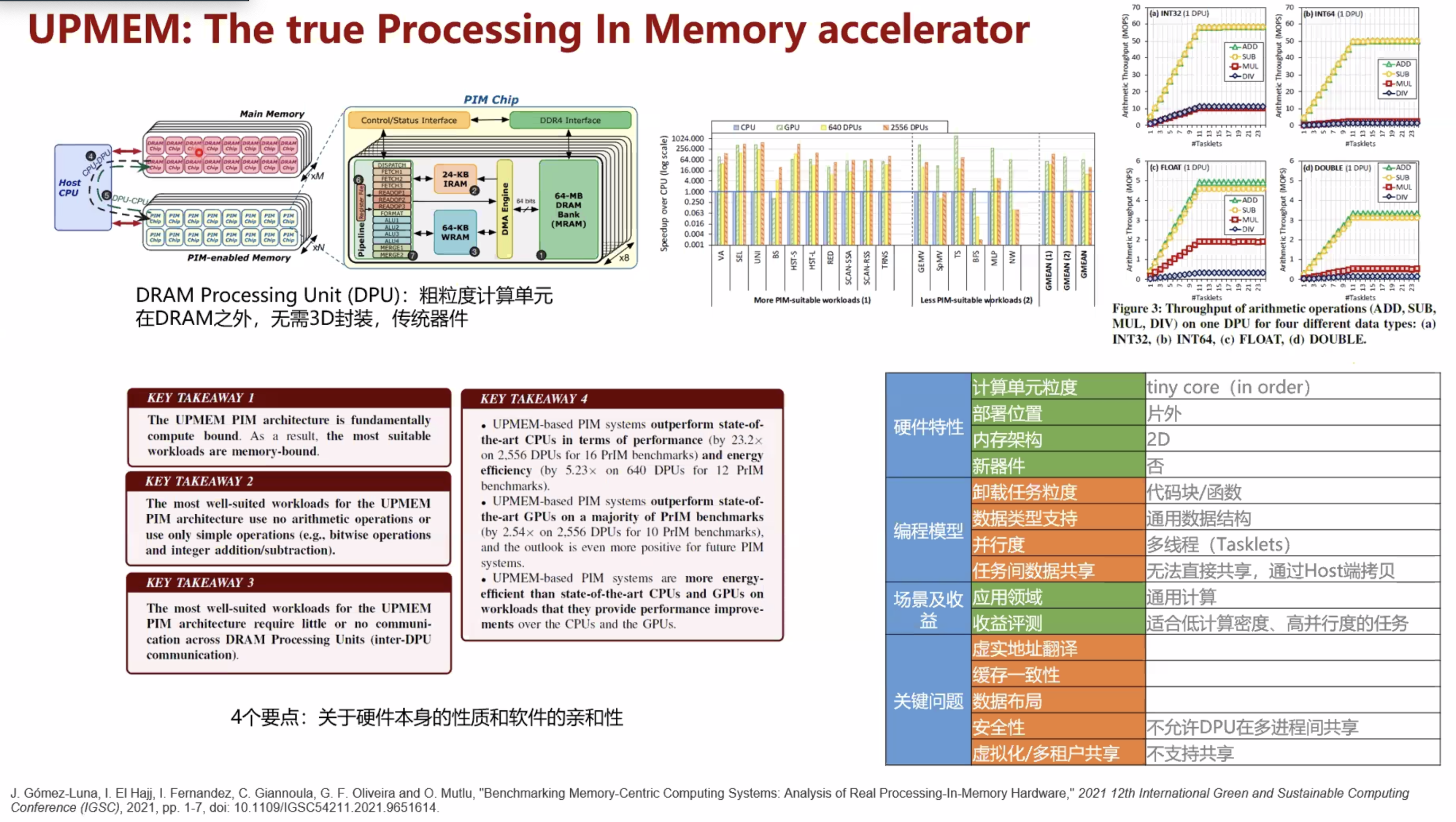
hardware architecture and software stack for pim based on commercial dram technology

pim-enabled instructions a low-overhead locality-aware processing-in-memory architecture
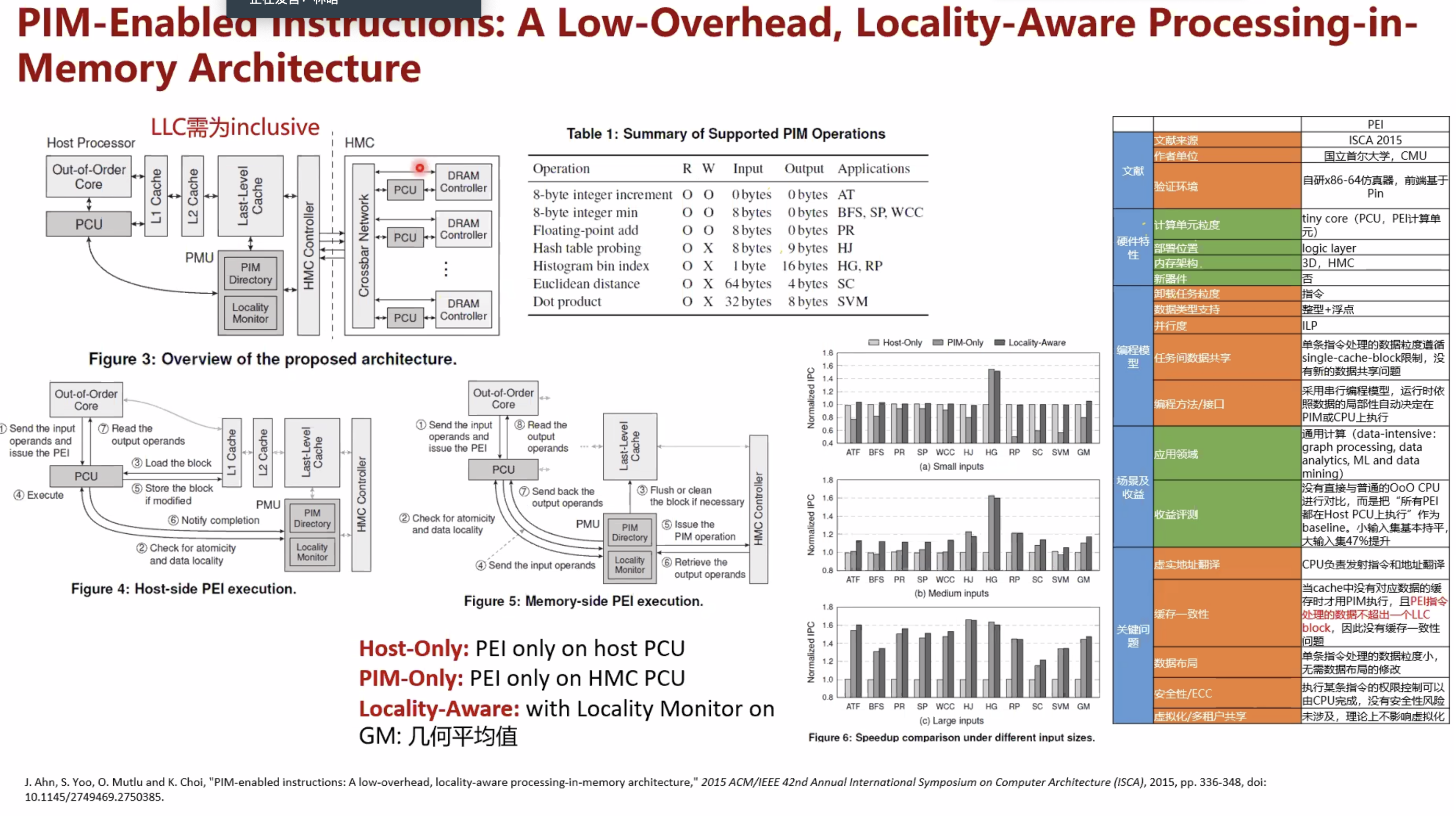
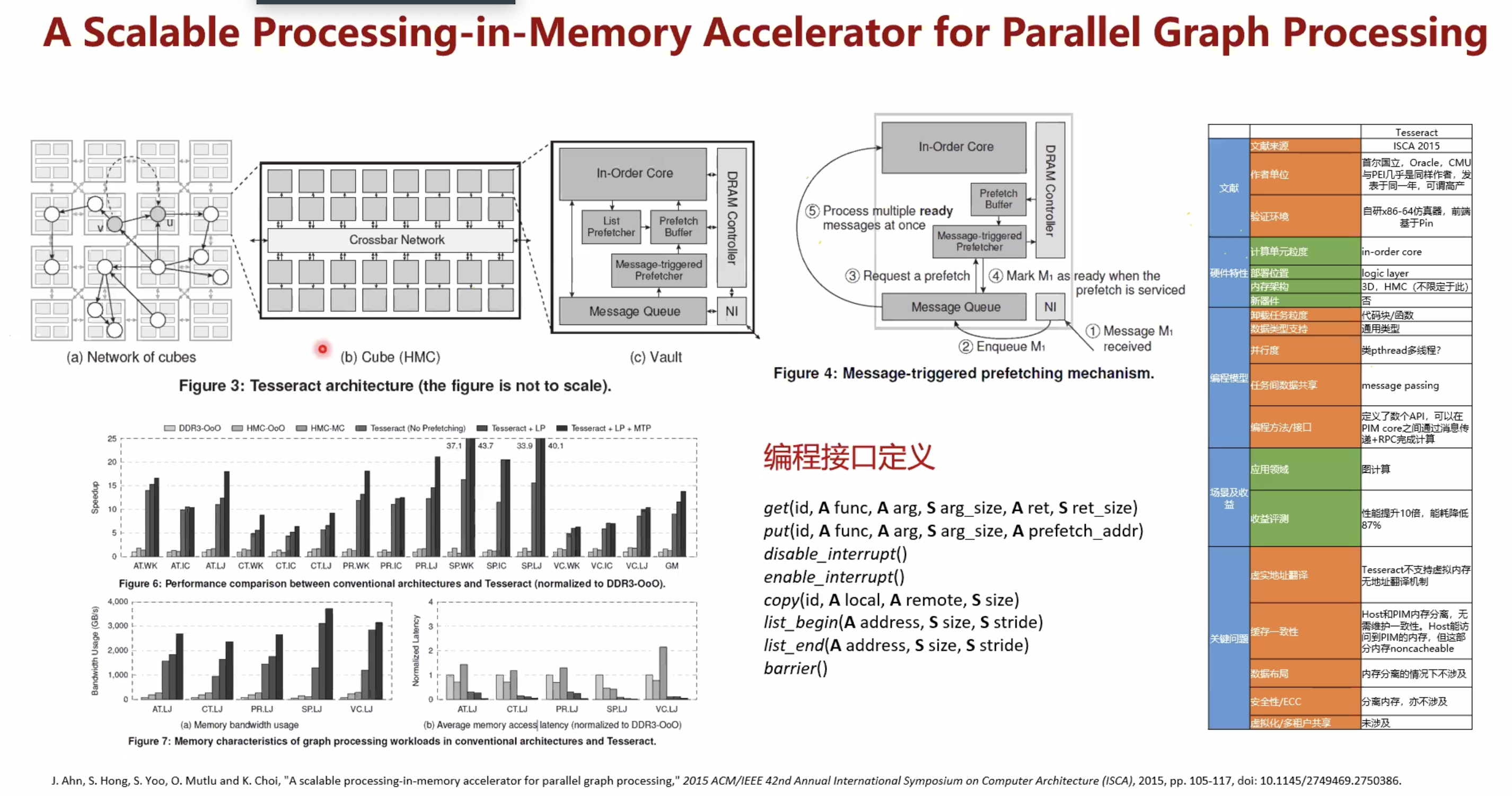

暂无
暂无
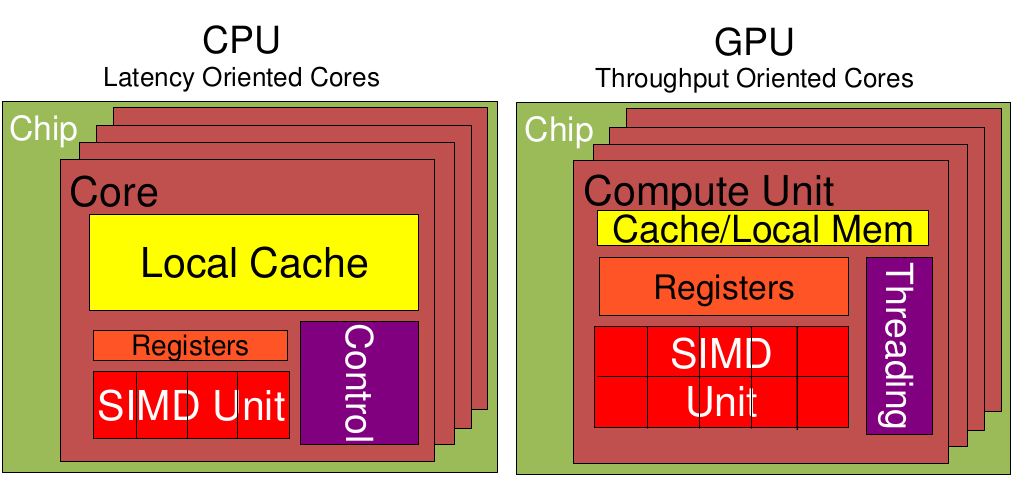
低延时的设计思路
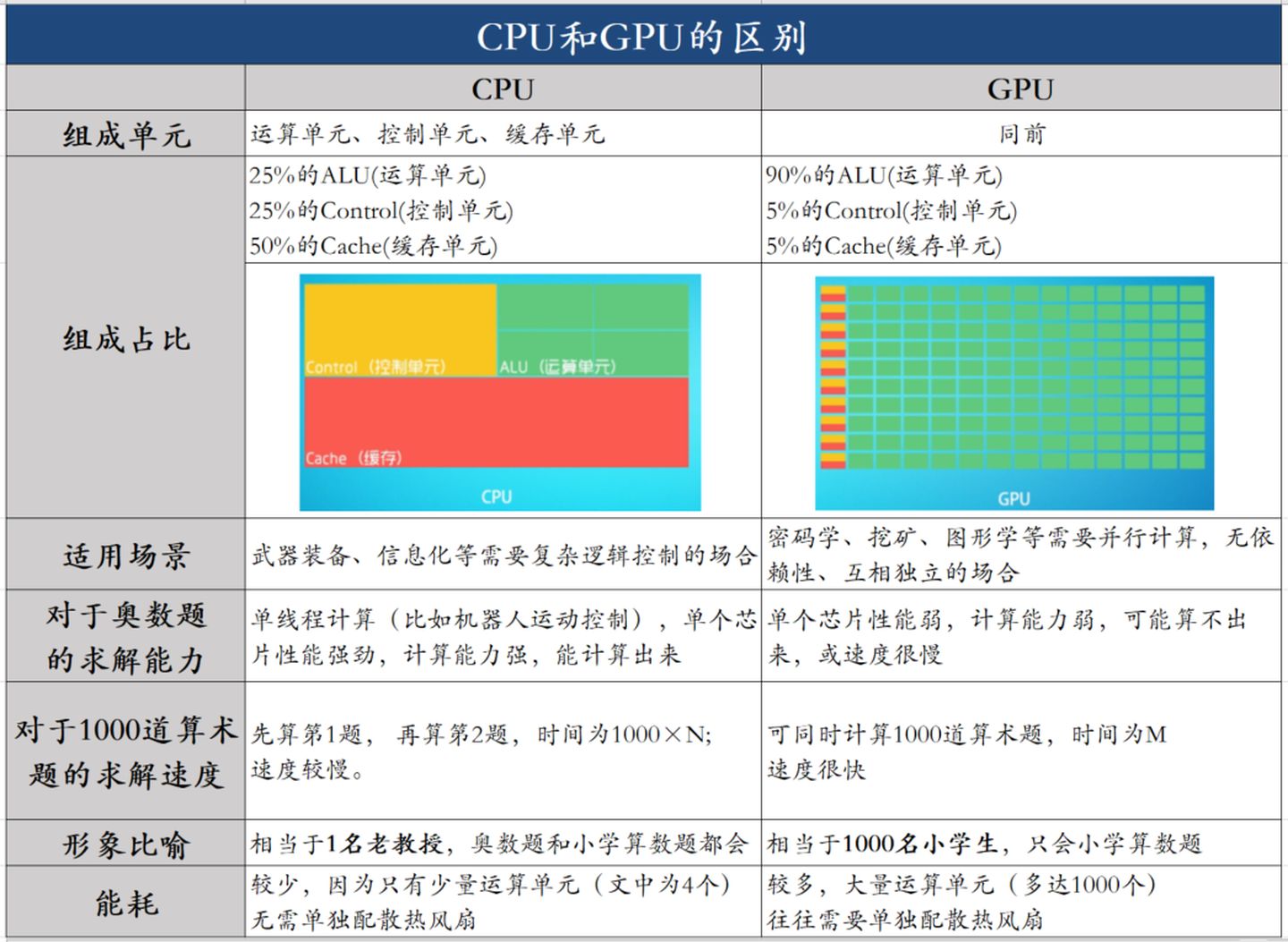
相比之下计算能力只是CPU很小的一部分。擅长逻辑控制,串行的运算。
大吞吐量设计思路
0 cycles and can happen every cycle.[^2]对带宽大的密集计算并行性能出众,擅长的是大规模并发计算。
| 对比项 | CPU | GPU | 说明 |
|---|---|---|---|
| Cache, local memory | 多 | 低延时 | |
| Threads(线程数) | 多 | ||
| Registers | 多 | 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。 | |
| SIMD Unit | 多 | 单指令多数据流,以同步方式,在同一时间内执行同一条指令 |
其实最早用在显卡上的DDR颗粒与用在内存上的DDR颗粒仍然是一样的。后来由于GPU特殊的需要,显存颗粒与内存颗粒开始分道扬镳,这其中包括了几方面的因素:
1 | sudo dmidecode|grep -A16 "Memory Device"|grep "Speed" |
因为显存可以在一个时钟周期内的上升沿和下降沿同时传送数据,所以显存的实际频率应该是标称频率的一半。
从GDDR5开始用两路传输,GDDR6采用四路传输(达到类似效果)。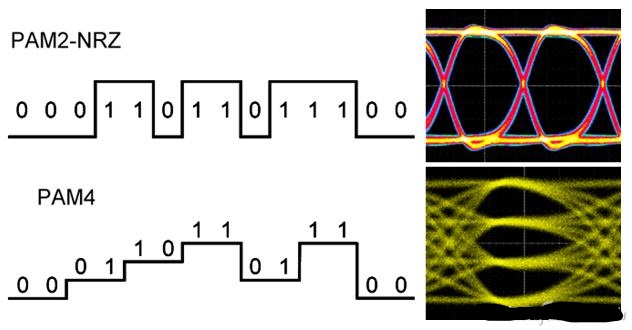
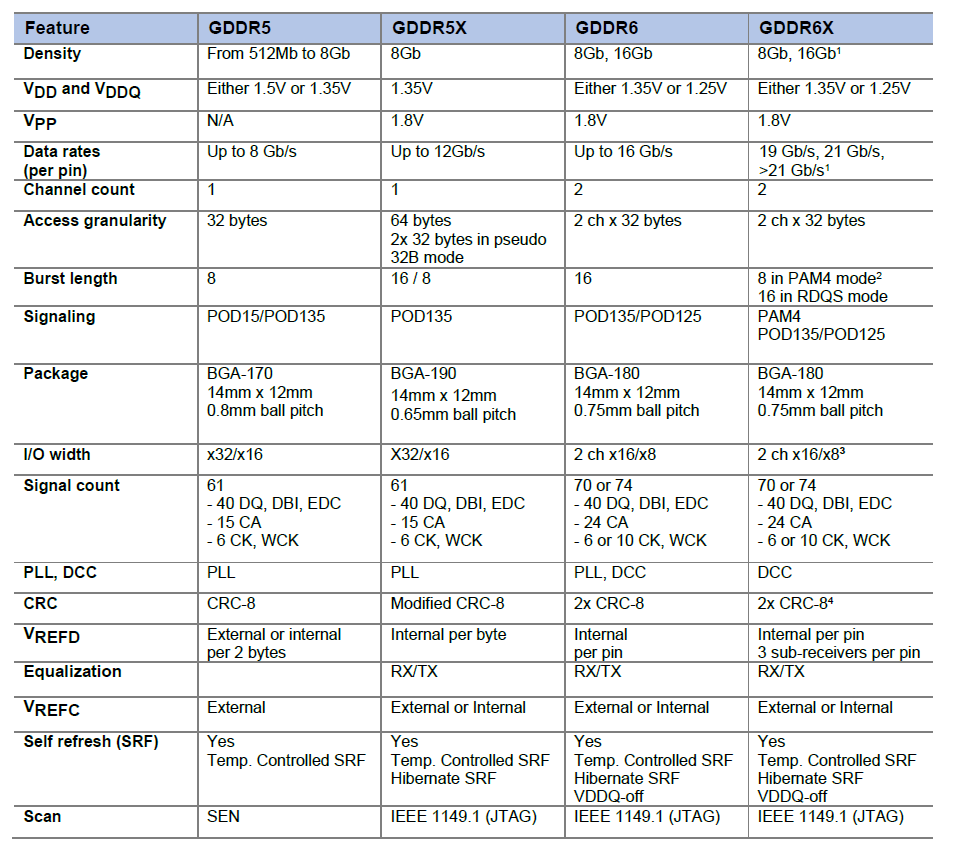
GDDR6X的频率估计应该至少从16Gbps(GDDR6目前的极限)起跳,20Gbps为主,这样在同样的位宽下,带宽比目前常见的14Gbps GDDR6大一半。比如在常见的中高端显卡256bit~384位宽下能提供512GB/s~768GB/s的带宽。
RTX 3090的GDDR6X显存位宽384bit,等效频率19Gbps到21Gbps,带宽可达912GB/s到1006GB/s,达到T级。(384*19/8=912)
RTX 3090 加速频率 (GHz) 1.7, 基础频率 (GHz) 1.4
1 | 19/1.4 = 13.57 |
912GB/s到1006GB/s 附近3.2 Gbps * 64 bits * 2 / 8 = 51.2GB/s可见两者差了20倍左右。
通过上面的例子,大致能知道: 需要高访存带宽和高并行度的SIMD的应用适合分配在GPU上。
$$ 144 SM * 4 warpScheduler/SM * 32 Threads/warps = 18432 $$
https://zhuanlan.zhihu.com/p/156171120?utm_source=wechat_session
https://www.cnblogs.com/biglucky/p/4223565.html
https://www.zhihu.com/question/36825227/answer/69351247
https://baijiahao.baidu.com/s?id=1675253413370892973&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/62234511
https://kknews.cc/digital/x6v69xq.html
[^1]: 并行计算课程-CUDA 密码pa22