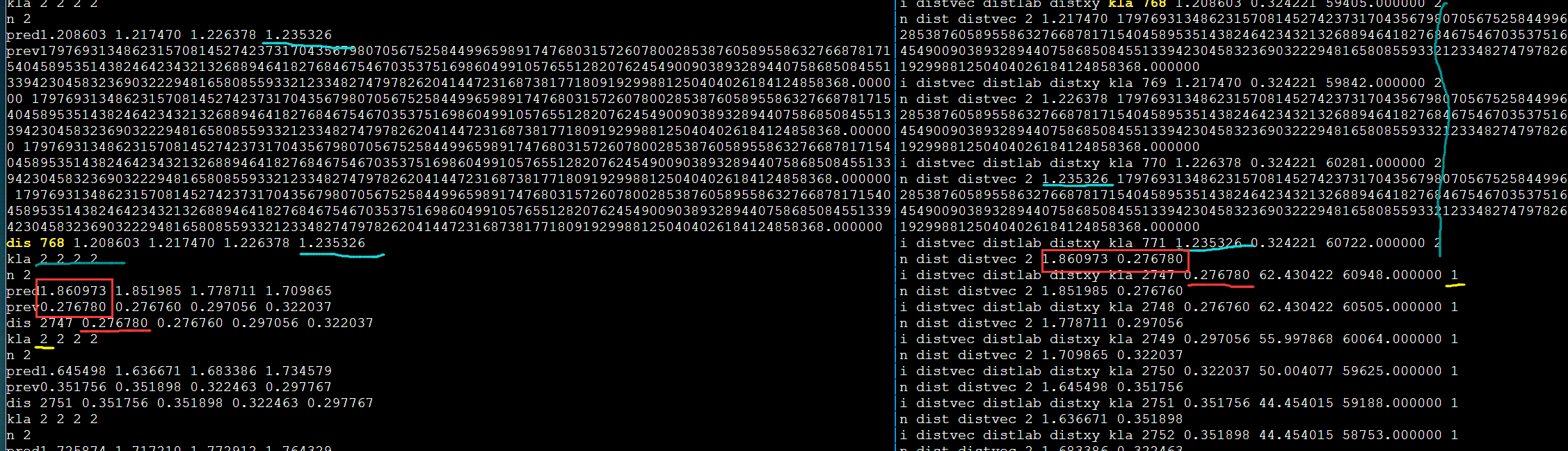
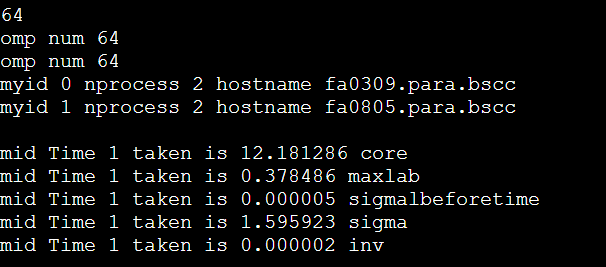
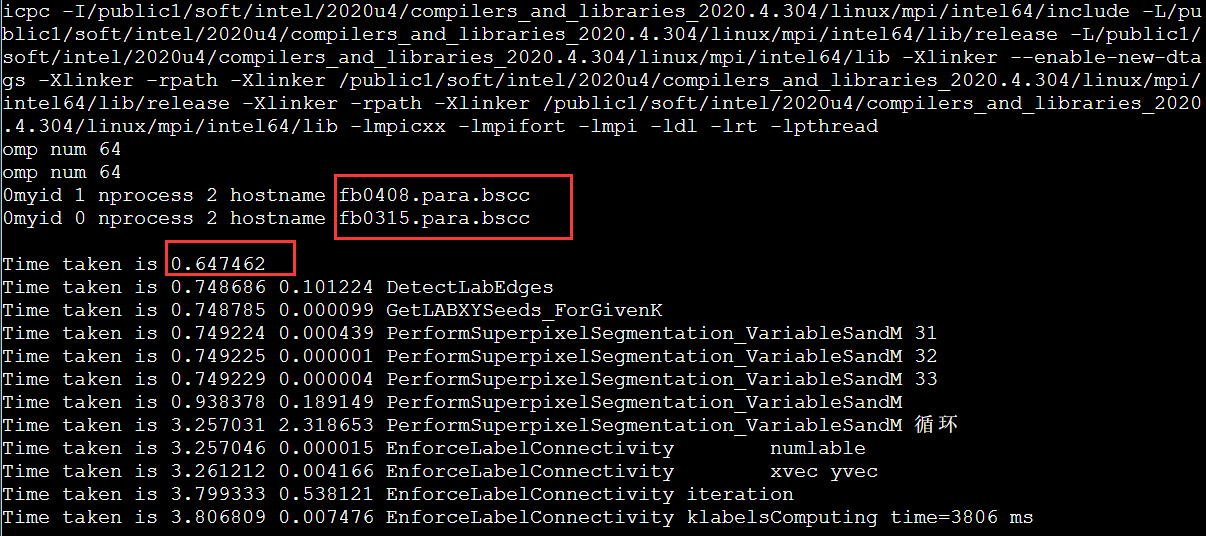
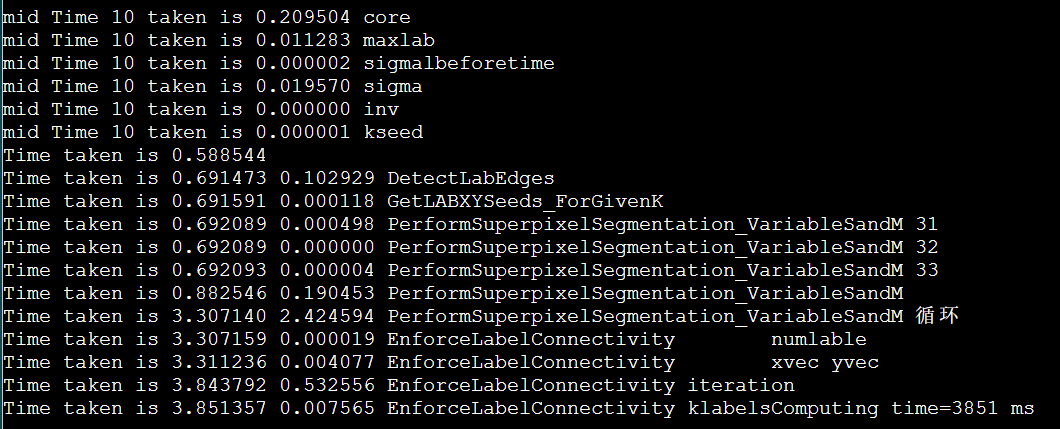
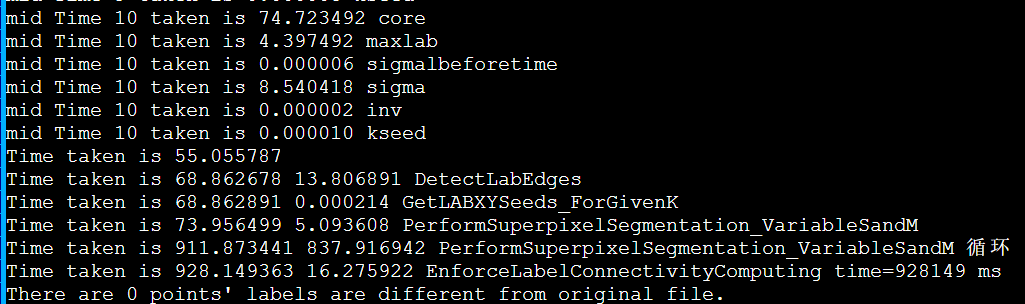
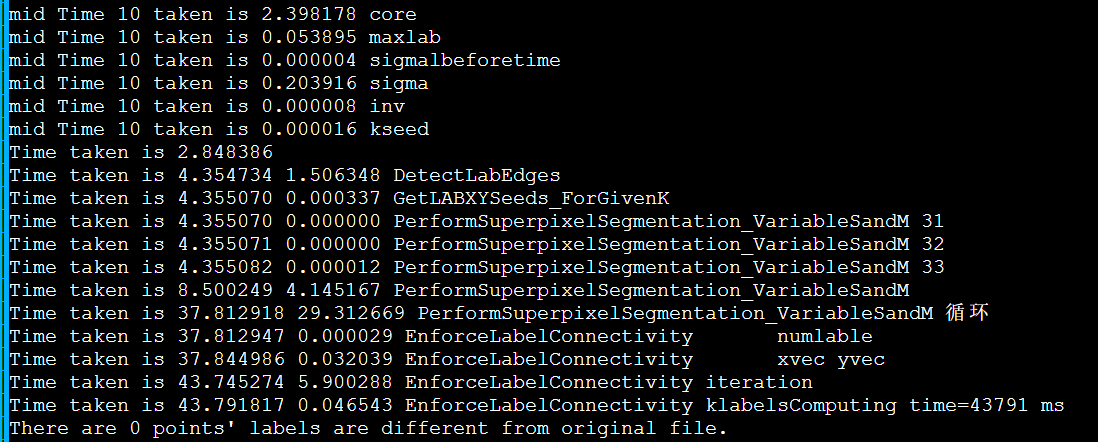
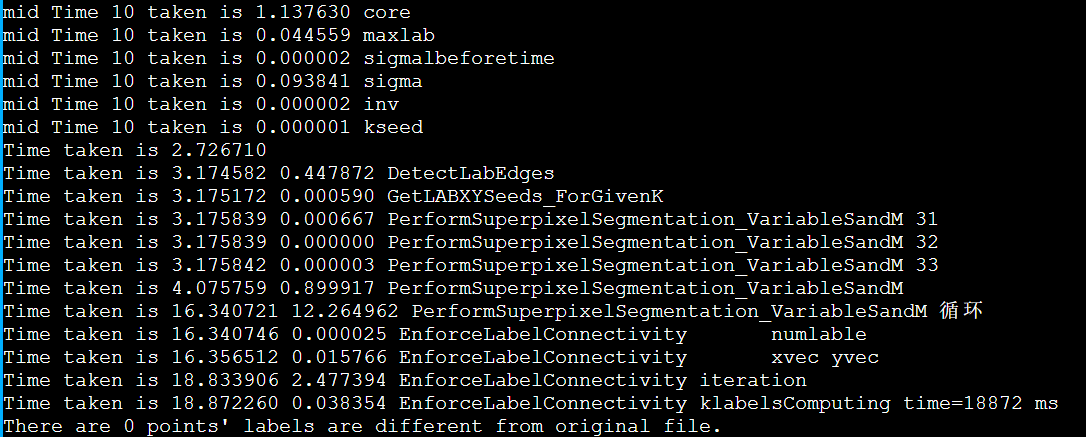
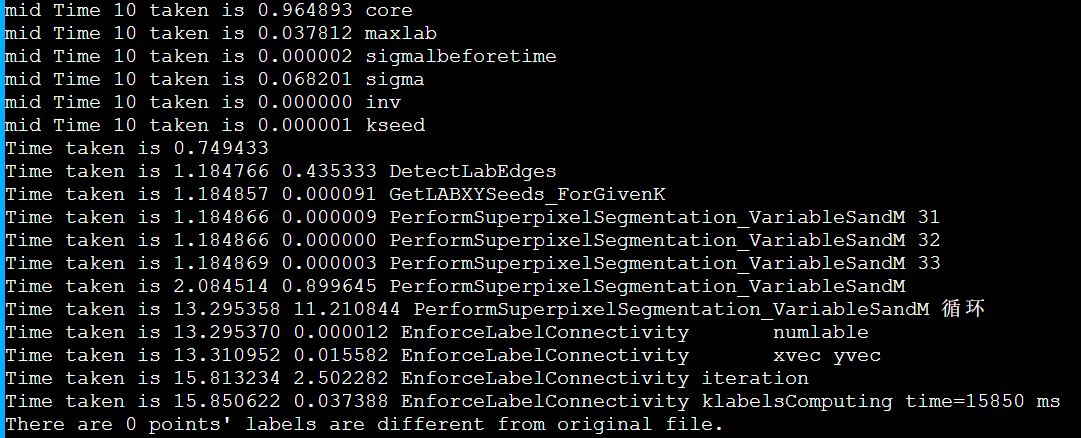
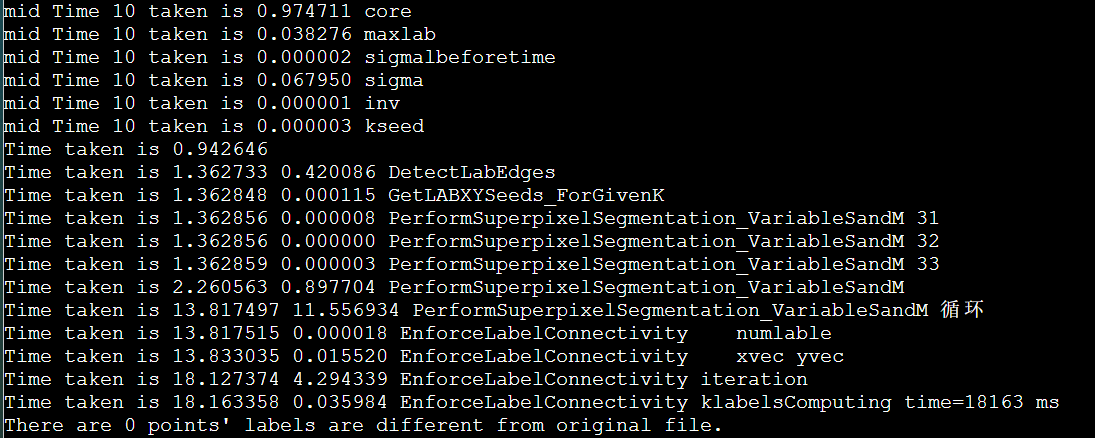
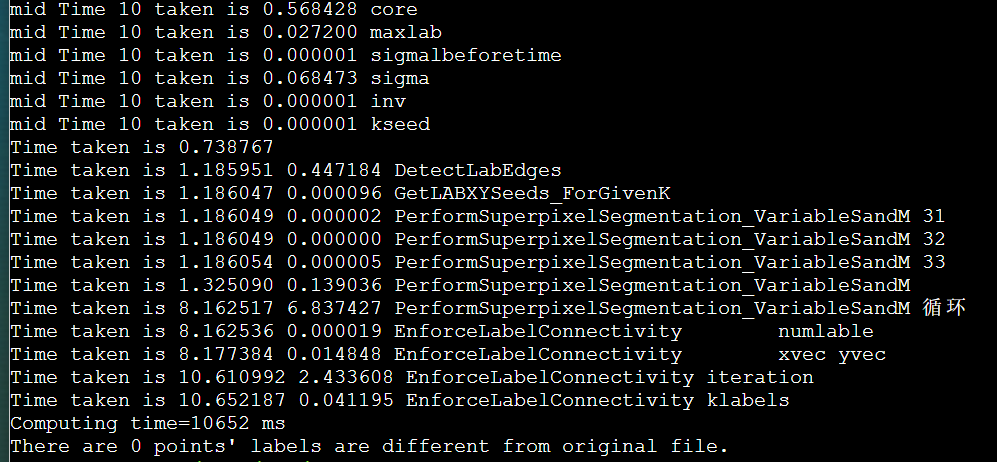
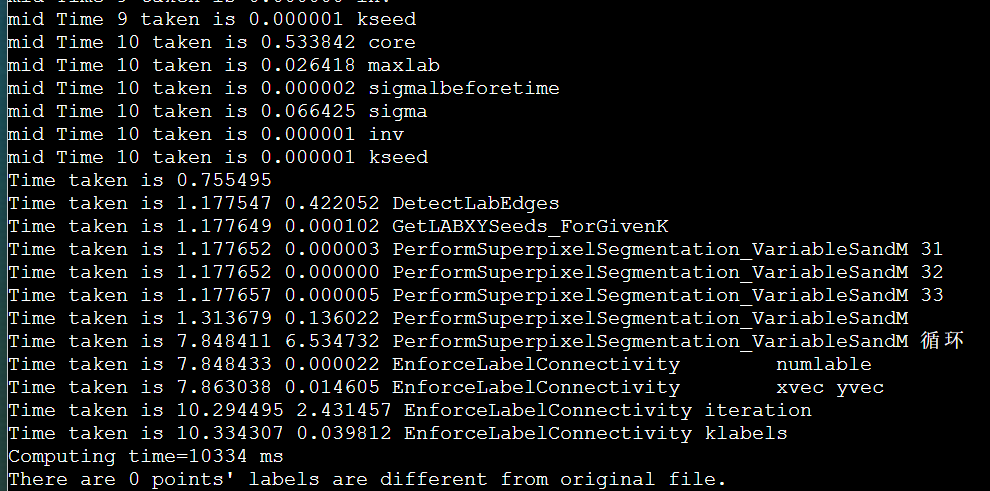
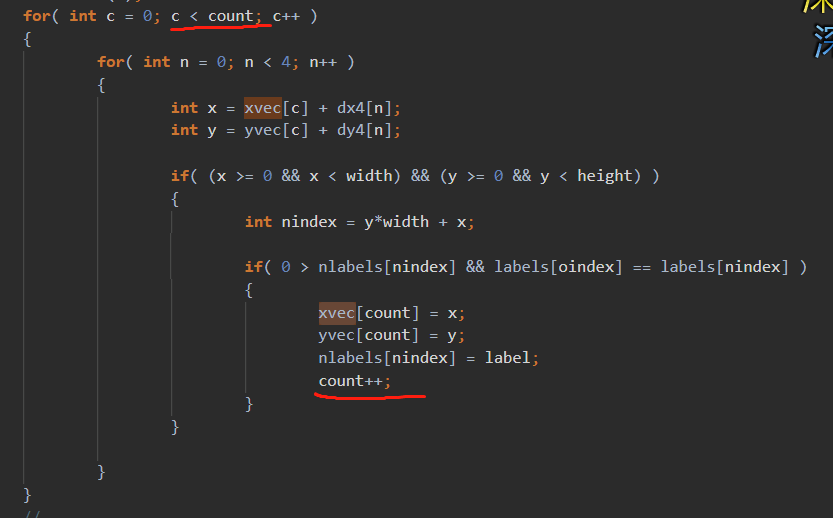
简介
- Message Passing Interface (消息传递接口 MPI) is a standardized and portable message-passing standard designed to function on parallel computing architectures.[1]
- The MPI standard defines the syntax 语法 and semantics 语意 of library routines that are useful to a wide range of users writing portable message-passing programs in C, C++, and Fortran.
- There are several open-source MPI implementations (MPICH,Open MPI), which fostered the development of a parallel software industry, and encouraged development of portable and scalable large-scale parallel applications.
历史
- 1994.6 MPI-1
- 主要的MPI-1模型没有共享内存的概念,
- point-to-point send/recieve, gather/reduce, synchronous, asynchronous,
- MPI-2只有一个有限的分布式共享内存的概念。尽管如此,MPI程序通常在共享内存计算机上运行,MPICH和Open MPI都可以使用共享内存进行消息传输(如果可用的话)。
- 围绕MPI模型(与显式共享内存模型相反)设计程序在NUMA体系结构上运行时具有优势,因为MPI鼓励内存局部性。显式共享内存编程是在MPI-3中引入的。
实现原理简介
虽然MPI属于OSI参考模型的第5层和更高层,但实现可以覆盖大多数层,其中在传输层中使用套接字和传输控制协议(TCP)。
与RDMA的区别
MPI hardware research focuses on implementing MPI directly in hardware, for example via processor-in-memory, building MPI operations into the microcircuitry of the RAM chips in each node. By implication, this approach is independent of language, operating system, and CPU, but cannot be readily updated or removed.
MPI硬件研究的重点是直接在硬件中实现MPI,例如通过内存处理器,将MPI操作构建到每个节点中的RAM芯片的微电路中。通过暗示,这种方法独立于语言、操作系统和CPU,但是不能容易地更新或删除。
Another approach has been to add hardware acceleration to one or more parts of the operation, including hardware processing of MPI queues and using RDMA to directly transfer data between memory and the network interface controller(NIC 网卡) without CPU or OS kernel intervention.
另一种方法是将硬件加速添加到操作的一个或多个部分,包括MPI队列的硬件处理以及使用RDMA在存储器和网络接口控制器之间直接传输数据,而无需CPU或OS内核干预。
与管道的区别
进程间通信都是Inter-process communication(IPC)的一种。常见有如下几种:
- 文件,进程写文件到磁盘,其余进程能并行读取。
- Memory-mapped file 存储在内存里的文件
- signal,多为控制信号
- 信号量(计数器)
- Network Socket
- Message queue 消息队列(没用过
- 管道
- Anonymous pipe 匿名管道(命令行的结果传递
|- 可用于单向进程间通信(IPC)的单FIFO通信通道
- A unidirectional data channel using standard input and output.
- named pipe 有名管道
- 持久化,
mkfifo,具有p的文件属性 - cat tail的例子说明,不建立写读连接会阻塞。
- 持久化,
- Anonymous pipe 匿名管道(命令行的结果传递
- Shared memory 共享内存(OpenMP
- Message passing 消息传递(类似MPI
与OpenMP的关系
线程共享存储器编程模型(如Pthreads和OpenMP)和消息传递编程(MPI/PVM)可以被认为是互补的,并且有时在具有多个大型共享存储器节点的服务器中一起使用。
基本概念
后四个是MPI-2独有的
- Communicator 进程组
- Point-to-point basics 点对点同步异步通信
- Collective basics 集体通信(eg. alltoall
- Derived data types 派生数据类型(自定义传输数据结构
- One-sided communication
- MPI-2定义了三个单边通信操作,分别是对远程存储器的写入、从远程存储器的读取以及跨多个任务对同一存储器的归约操作。
- Dynamic process management 类似进程池?没用过
- 并行文件IO
编程
C++ 查看在哪个节点
1 | #include <unistd.h> |
运行命令
输出X个当前机器hostname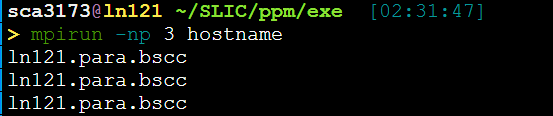
mpirun -np 6 -machinefile ./machinelist ./a.out 即可多节点执行。
问题
MPI_Finalize()之后 ,MPI_Init()之前
https://www.open-mpi.org/doc/v4.0/man3/MPI_Init.3.php
不同的进程是怎么处理串行的部分的?都执行(重复执行?)。执行if(rank=num),那岂不是还要同步MPI_Barrier()。
而且写同一个文件怎么办?
对等模式和主从模式
MPI的两种最基本的并行程序设计模式 即对等模式和主从模式。
对等模式:各个部分地位相同,功能和代码基本一致,只不过是处理的数据或对象不同,也容易用同样的程序来实现。
主从模式:分为主进程和从进程,程序通信进程之间的一种主从或依赖关系 。MPI程序包括两套代码,主进程运行其中一套代码,从进程运行另一套代码。
程序并行可行性分析
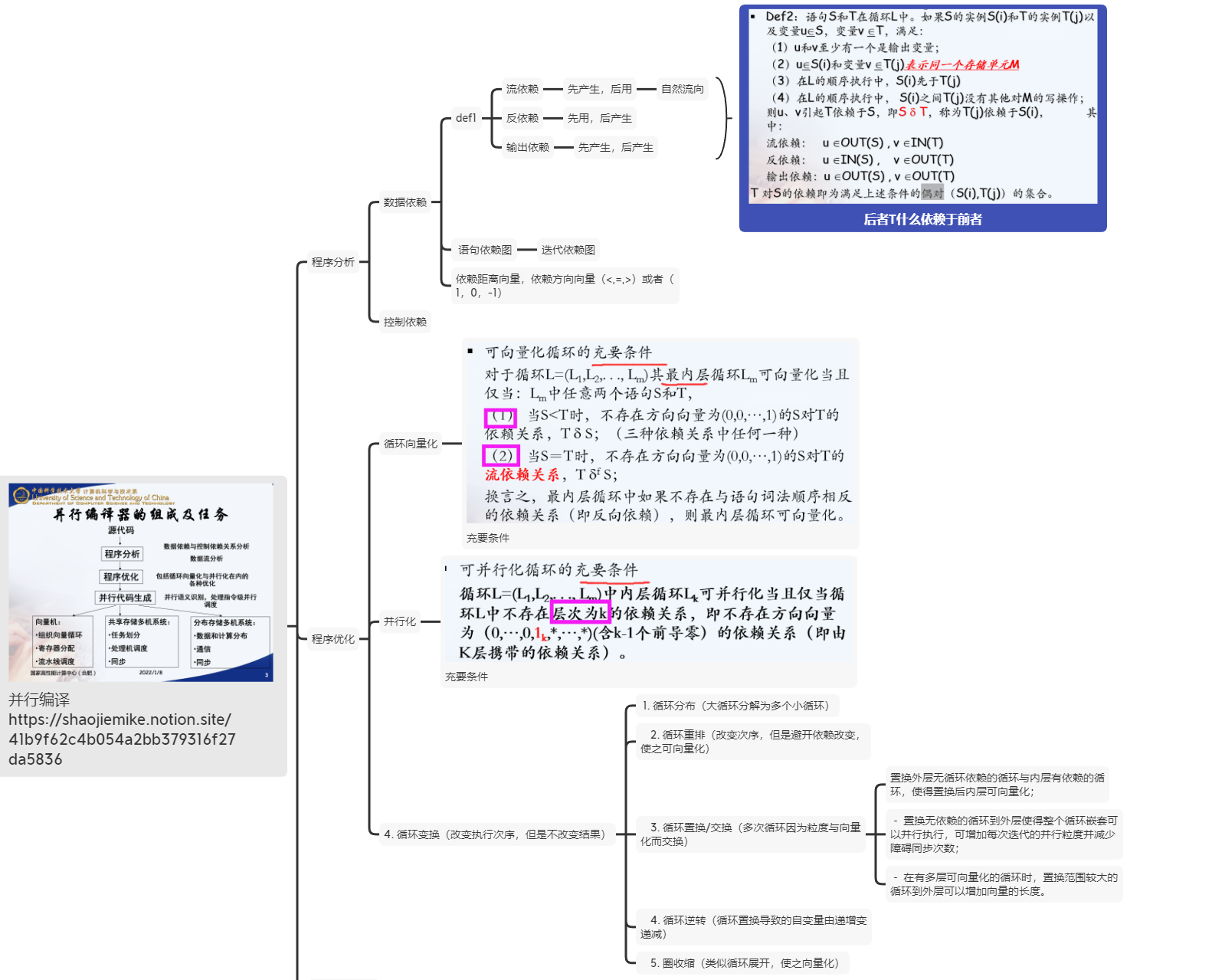
圈收缩(cycle shrinking)-此变换技术一般用于依赖距离大于1的循环中,它将一个串行循环分成两个紧嵌套循环,其中外层依然串行执行,而内层则是并行执行(一般粒度较小)
https://shaojiemike.notion.site/41b9f62c4b054a2bb379316f27da5836
MPI消息

预定义类型消息——特殊MPI_PACKED
MPI_PACKED预定义数据类型被用来实现传输地址空间不连续的数据项 。
1 | int MPI_Pack(const void *inbuf, |

The input value of position is the first location in the output buffer to be used for packing. position is incremented by the size of the packed message,
and the output value of position is the first location in the output buffer following the locations occupied by the packed message. The comm argument is the communicator that will be subsequently used for sending the packed message.
1 | //Returns the upper bound on the amount of space needed to pack a message |

例子:
这里的A+i*j应该写成A+i*2吧???
派生数据类型(Derived Data Type)
来定义由数据类型不同且地址空间不连续的数据项组成的消息。
1 | //启用与弃用数据类型 |

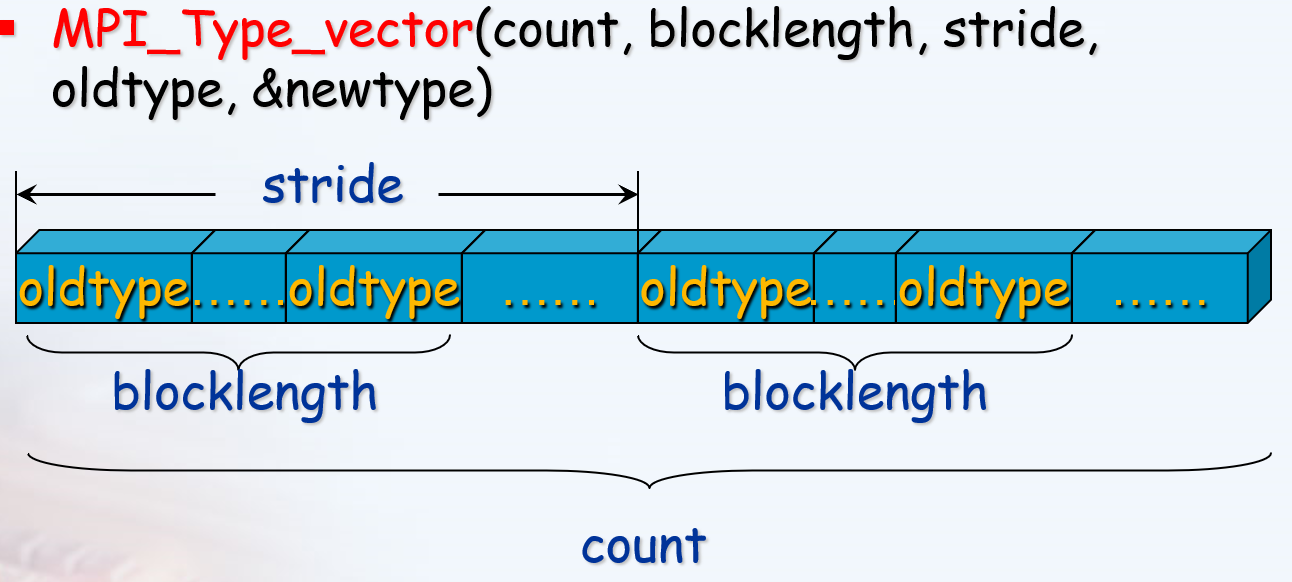
1 | //成块的相同元素组成的类型,块长度和偏移由参数指定 |

1 | //由不同数据类型的元素组成的类型, 块长度和偏移(肯定也不一样)由参数指定 |

通讯域映射为网格表示
MPI_Cart_create
确定了虚拟网络每一维度的大小后,需要为这种拓扑建立通信域。组函数MPI_Cart_create可以完成此任务,其声明如下:
1 | // Makes a new communicator to which topology拓扑 information has been attached |
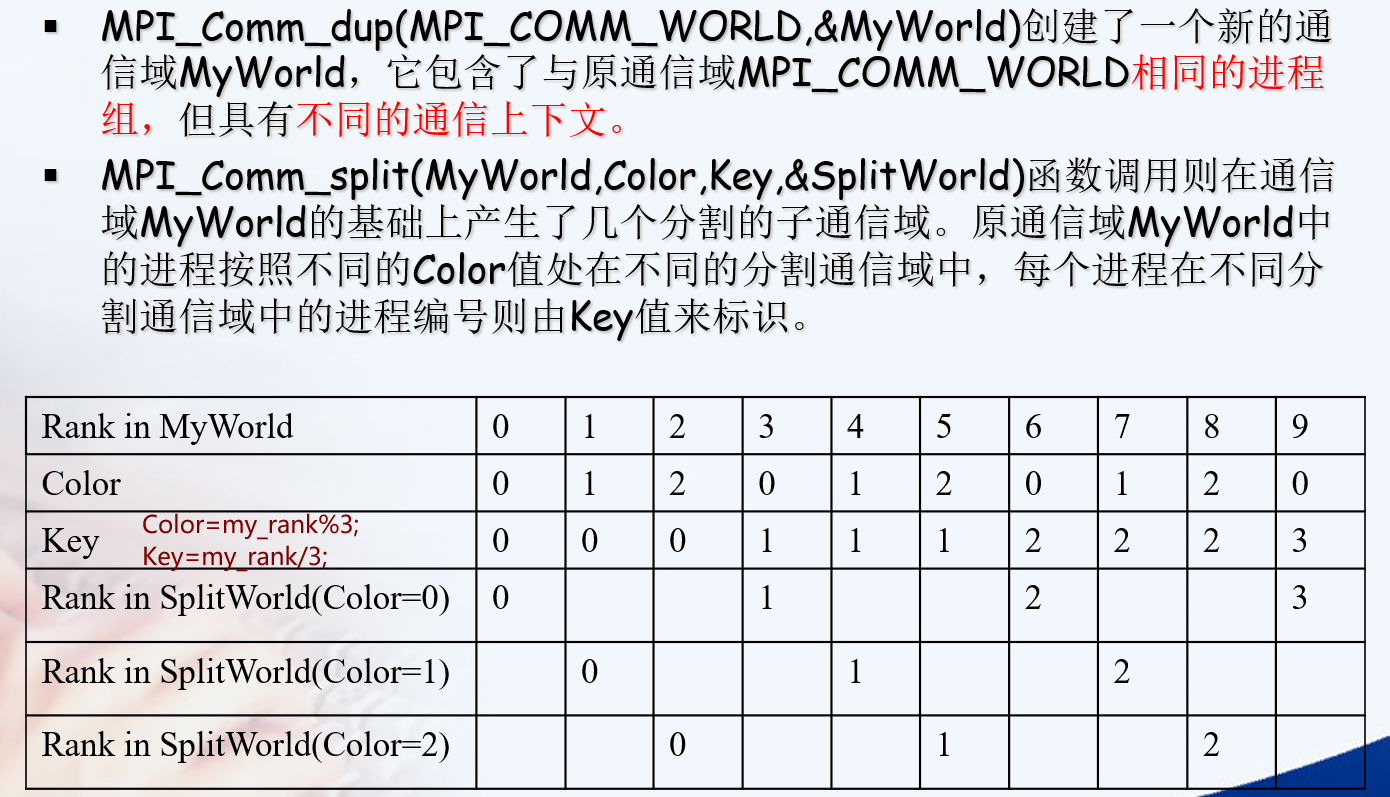
通信域划分
1 | int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm * newcomm) |
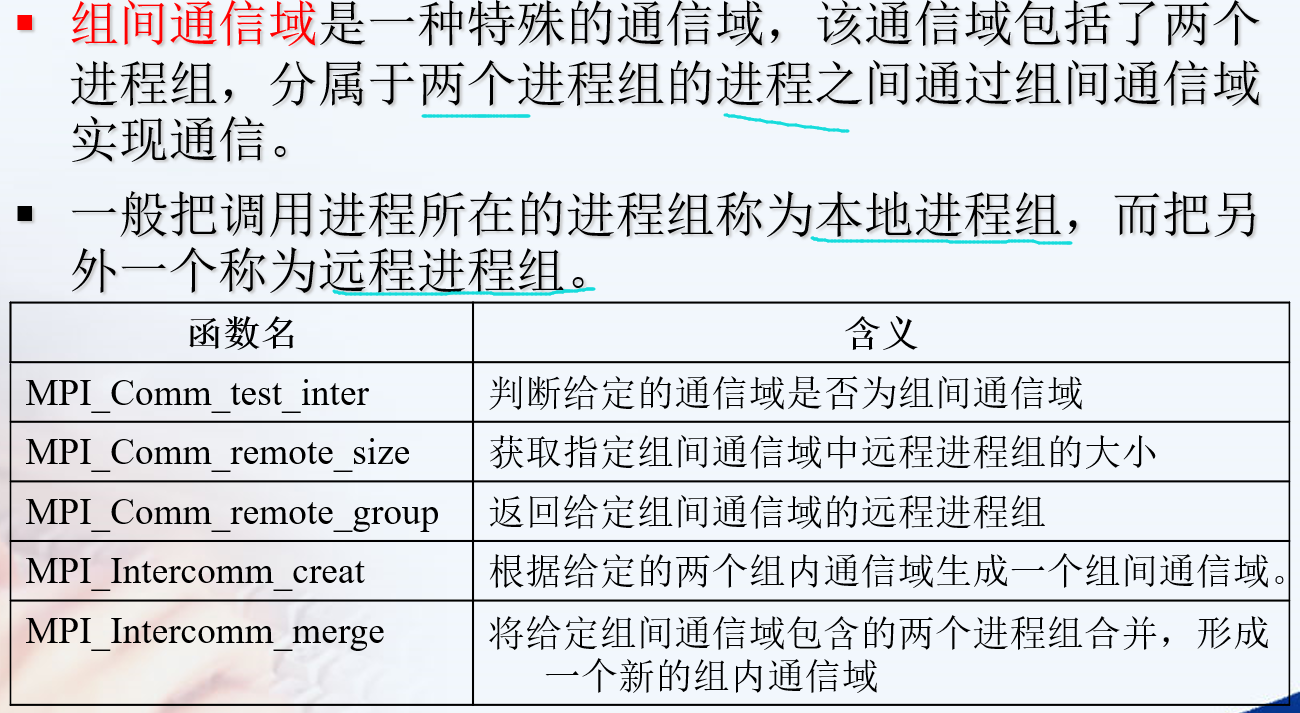
组间通信域
点对点通信
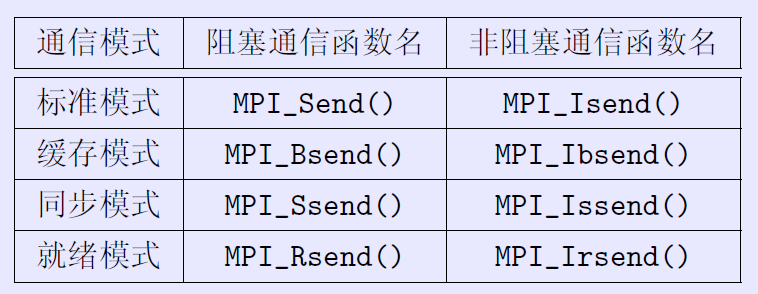
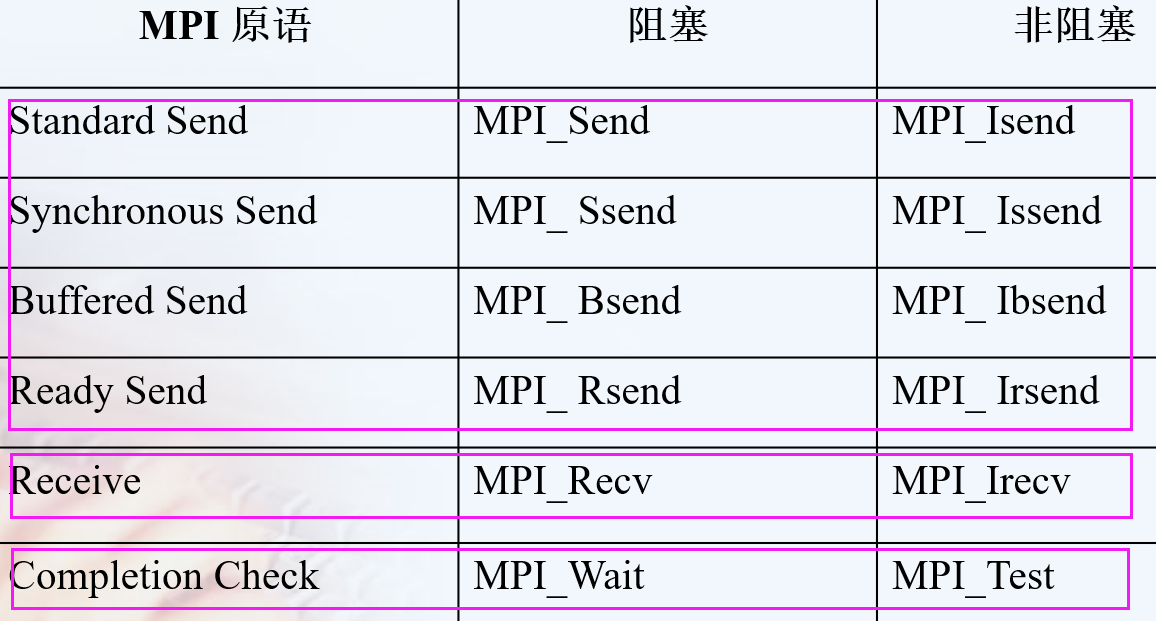
特殊的函数
1 | int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype, |
特别适用于在进程链(环)中进行“移位”操作,而避免在通讯为阻塞方式时出现死锁。
There is also another error. The MPI standard requires that the send and the receive buffers be disjoint不相交 (i.e. they should not overlap重叠), which is not the case with your code. Your send and receive buffers not only overlap but they are one and the same buffer. If you want to perform the swap in the same buffer, MPI provides the MPI_Sendrecv_replace operation.
1 | //MPI标准阻塞通信函数,没发出去就不会结束该命令。 |
是否会导致死锁

可能大家会想到这会死锁,如下图:
但是实际情况可能并不会死锁,这与调用的MPI库的底层实现有关。

MPI_Send将阻塞,直到发送方可以重用发送方缓冲区为止。当缓冲区已发送到较低的通信层时,某些实现将返回给调用方。当另一端有匹配的MPI_Recv()时,其他一些将返回到呼叫者。
但是为了避免这种情况,可以调换Send与Recv的顺序,或者**使用MPI_Isend()或MPI_Issend()**代替非阻塞发送,从而避免死锁。
梯形积分
1 | /* |
群集通讯
一个进程组中的所有进程都参加的全局通信操作。
实现三个功能:通信、聚集和同步。
- 通信功能主要完成组内数据的传输
- 聚集功能在通信的基础上对给定的数据完成一定的操作
- 同步功能实现组内所有进程在执行进度上取得一致
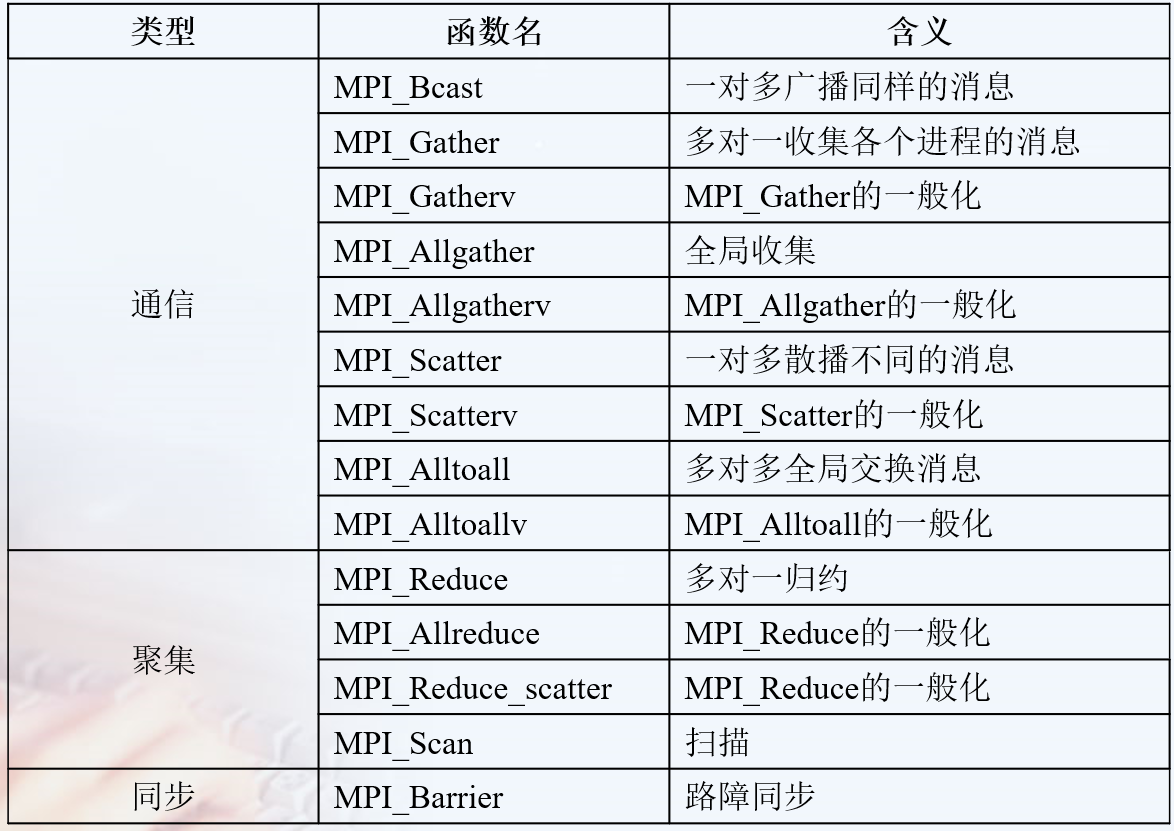
常见的通讯
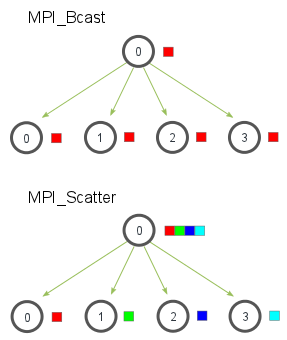
1 | //将一个进程中得数据发送到所有进程中的广播函数 |
注意data_p在root 或者scr_process进程里是发送缓存也是接收缓存,但是在其余进程里是接收缓存。
MPI_Scatter?
区别
- MPI_Scatter与MPI_Bcast非常相似,都是一对多的通信方式,不同的是后者的0号进程将相同的信息发送给所有的进程,而前者则是将一段array的不同部分发送给所有的进程,其区别可以用下图概括:
- MPI_Gather,作用是从所有的进程中将每个进程的数据集中到根进程中,同样根据进程的编号对array元素排序,
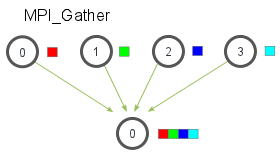
- 接收缓冲由三元组<RecvAddress, RecvCount, RecvDatatype>标识,发送缓冲由三元组<SendAddress, SendCount, SendDatatype>标识,所有非Root进程忽略接收缓冲。
- MPI_Allgather 当数据分布在所有的进程中时,MPI_Allgather将所有的数据聚合到每个进程中。
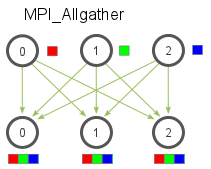
- Allgather操作相当于每个进程都作为ROOT进程执行了一次Gather调用,即每一个进程都按照Gather的方式收集来自所有进程(包括自己)的数据。
- MPI_GATHERV扩展了功能,提供新的参数disp,是一个整数数组,包含存放从每个进程接收的数据相对于recvbuf的偏移地址
- MPI_alltoall()
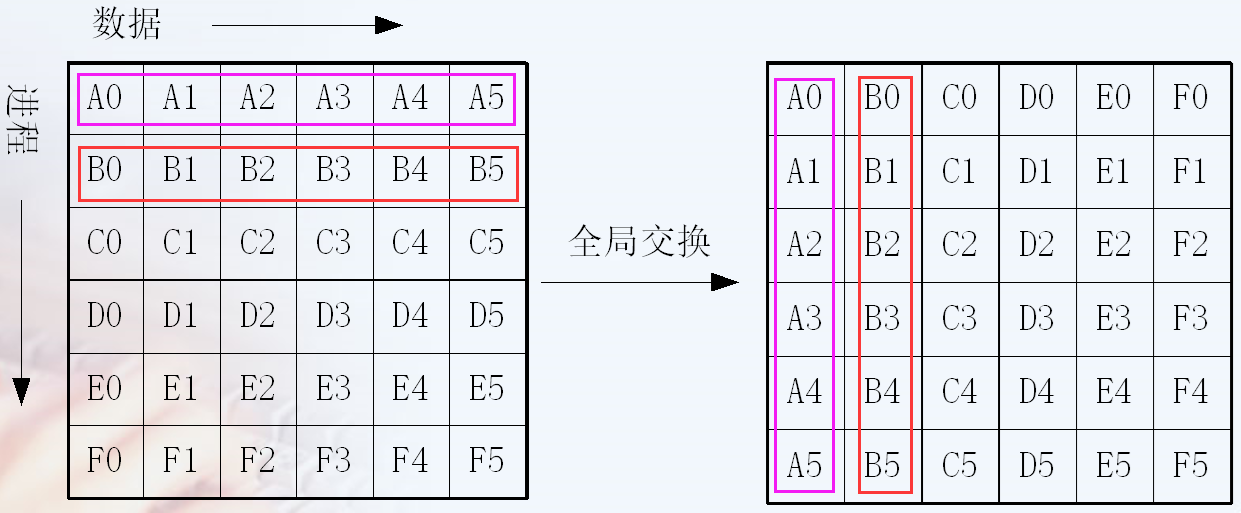
- 等价于每个进程作为Root进程执行了一次MPI_Scatter散播操作。recvcount gather和allgather是一样的
1
2
3
4
5
6int MPI_Allgather(void * sendbuff, int sendcount, MPI_Datatype sendtype,
void * recvbuf, int recvcount, MPI_Datatype recvtype,
MPI_Comm comm)
int MPI_Allgatherv(void * sendbuff, int sendcount, MPI_Datatype sendtype,
void * recvbuf, int * recvcounts, int * displs,
MPI_Datatype recvtype, MPI_Comm comm)
number of elements received from any process (integer)
注意
- 通信域中的所有进程必须调用群集通信函数。如果只有通信域中的一部分成员调用了群集通信函数而其它没有调用,则是错误的。
- 除MPI_Barrier以外,每个群集通信函数使用类似于点对点通信中的标准、阻塞的通信模式。也就是说,一个进程一旦结束了它所参与的群集操作就从群集函数中返回,但是并不保证其它进程执行该群集函数已经完成。
- 一个群集通信操作是不是同步操作取决于实现。MPI要求用户负责保证他的代码无论实现是否同步都必须是正确的。 ???与后面矛盾了 mpich官网说明的。
- 关于同步最后一个要注意的地方是:始终记得每一个你调用的集体通信方法都是同步的。
- 在MPI-3.0之前MPI中的所有集合操作都是阻塞的,这意味着在返回之后使用传递给它们的所有缓冲区是安全的.特别是,这意味着当其中一个函数返回时,会收到所有数据.(但是,它并不意味着所有数据都已发送!)因此,如果所有缓冲区都已有效,则在集合操作之前/之后MPI_Barrier不是必需的(或非常有用).
- 对用户的建议:为保证程序正确性而依赖于集合操作中同步的副作用是很危险的作法.例如,即便一个特定的实现策略可以提供一个带有同步副作用的广播通信例程, 但标准却不支持它,因此依赖于此副作用的程序将不可移植.从另一方面讲,一个正确的、可移植的程序必须能容忍集合操作可能带来同步这样 一个事实.尽管一个程序可以丝毫不依赖于这种同步的副作用,编程时也必须这样做.这个问题在4.12节中还将进一步讨论(对用户的建议结尾) https://scc.ustc.edu.cn/zlsc/cxyy/200910/MPICH/mpi41.htm
- 关于不同的进程运行同一句Bcast的效果
- 当根节点(在我们的例子是节点0)调用 MPI_Bcast 函数的时候,data 变量里的值会被发送到其他的节点上。当其他的节点调用 MPI_Bcast 的时候,data 变量会被赋值成从根节点接受到的数据。
- 所以如果有进程无法到达该语句Bcast,同步的性质会导致到达Bcast的命令需要等待。
聚合
MPI聚合的功能分三步实现
- 首先是通信的功能,即消息根据要求发送到目标进程,目标进程也已经收到了各自需要的消息;
- 然后是对消息的处理,即执行计算功能;
- 最后把处理结果放入指定的接收缓冲区。
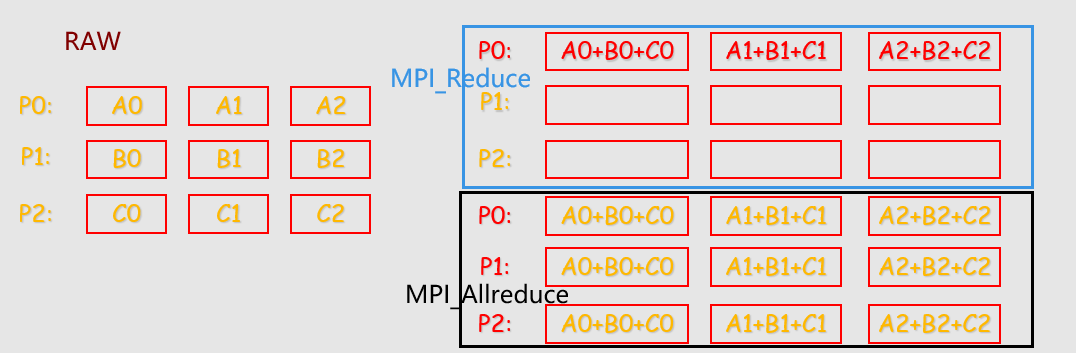
MPI提供了两种类型的聚合操作: 归约和扫描。
聚合——归约
1 | int MPI_Reduce( |
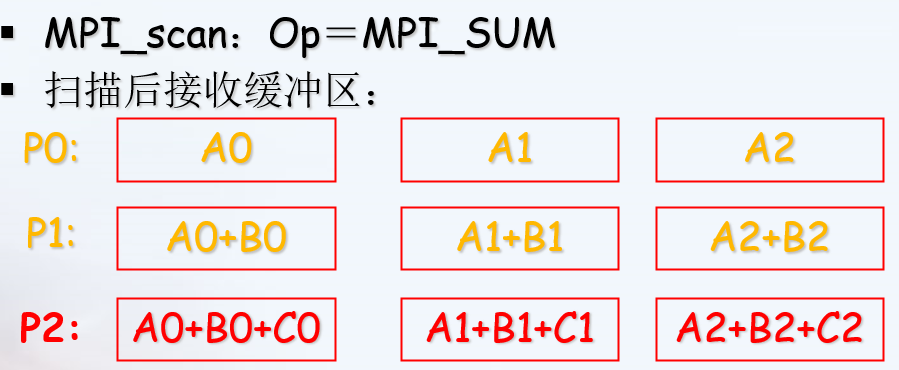
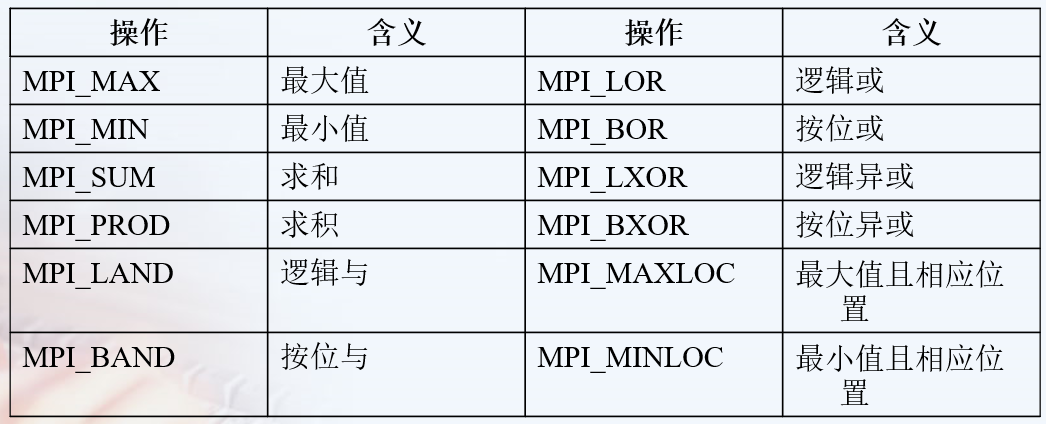
自定义归约操作
1 | int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op) |
用户自定义函数 functiontypedef void MPI_User_function(void *invec, void *inoutvec, int *len, MPI_Datatype *datatype)
1 | for(i=0;i<*len;i++) { |
必须具备四个参数:
- invec 和 inoutvec 分别指出将要被归约的数据所在的缓冲区的首地址,
- len指出将要归约的元素的个数, datatype 指出归约对象的数据类型
也可以认为invec和inoutvec 是函数中长度为len的数组, 归约的结果重写了inoutvec 的值。
梯形积分(MPI_Reduce)
1 | /* |
注意事项
- 除了#include “mpi.h”
需要进一步的研究学习
MPI_Group https://www.rookiehpc.com/mpi/docs/mpi_group.php
并行IO文件
1997年推出了MPI的最新版本MPI-2
MPI-2加入了许多新特性,主要包括
- 动态进程(Dynamic Process)
- 远程存储访问(Remote Memory Access)
- 并行I/O访问(Parallel I/O Access)
- MPI-1没有对并行文件I/O给出任何定义,原因在于并行I/O过于复杂,很难找到一个统一的标准。
more
- MPI-1没有对并行文件I/O给出任何定义,原因在于并行I/O过于复杂,很难找到一个统一的标准。
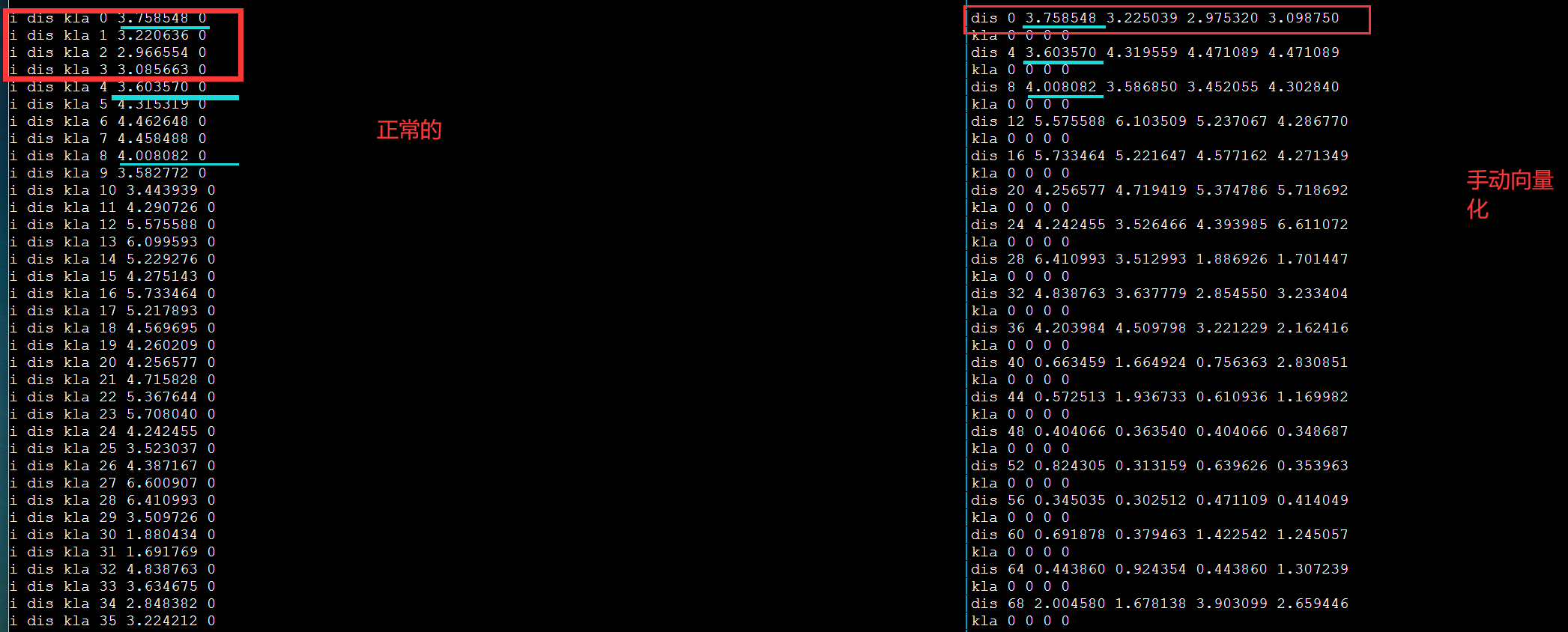
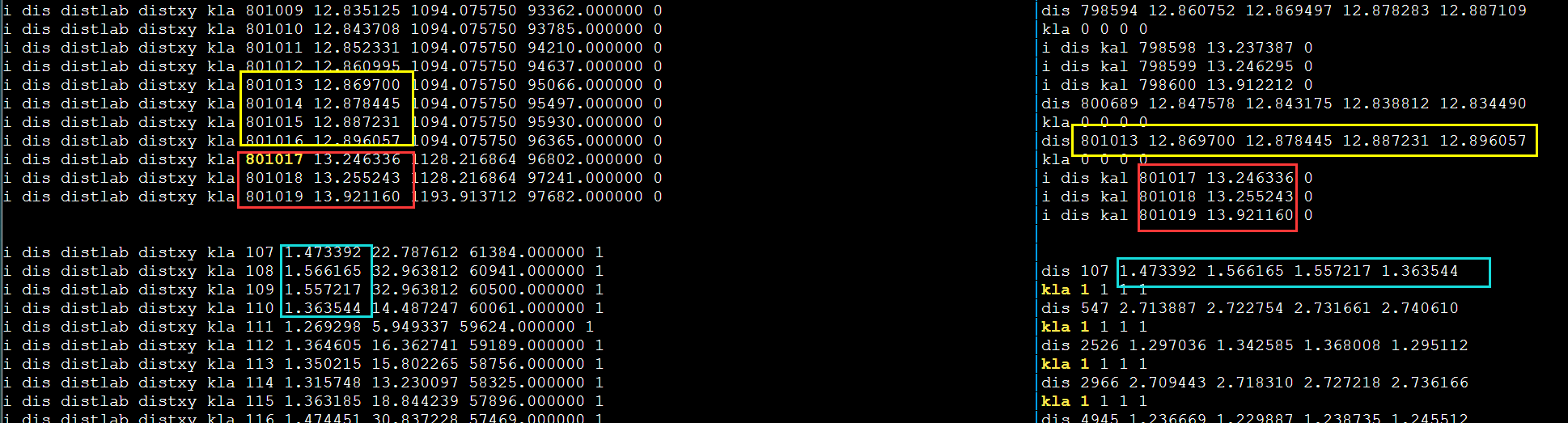
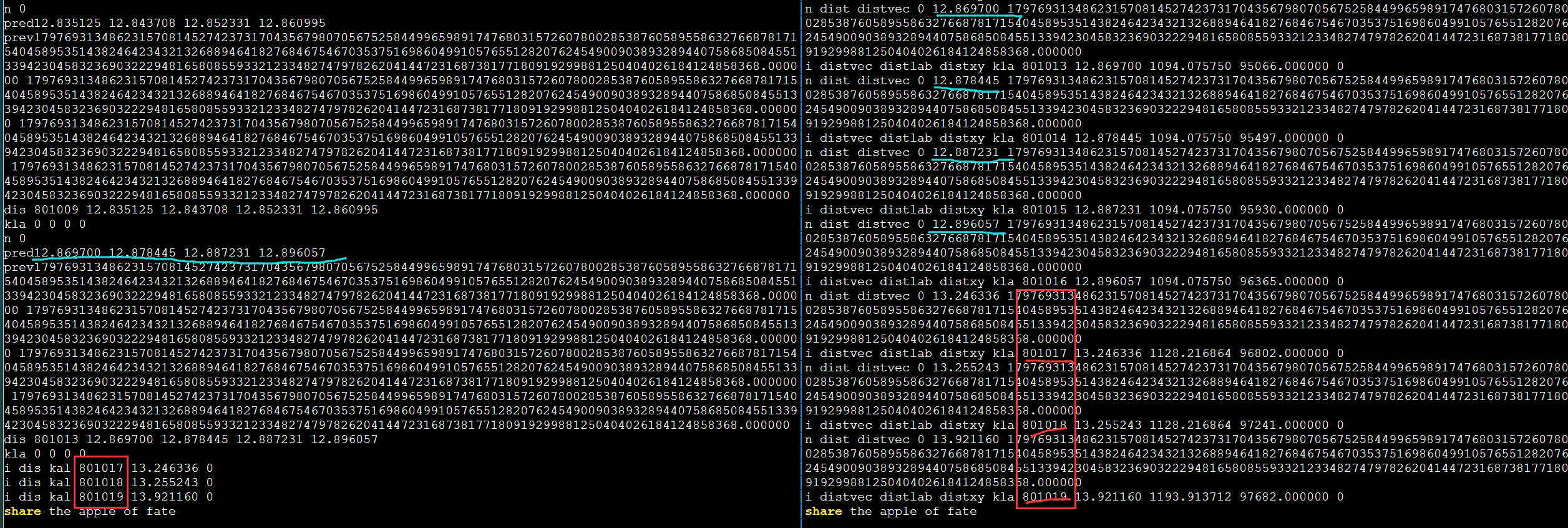
遇到的问题
数据发送和收集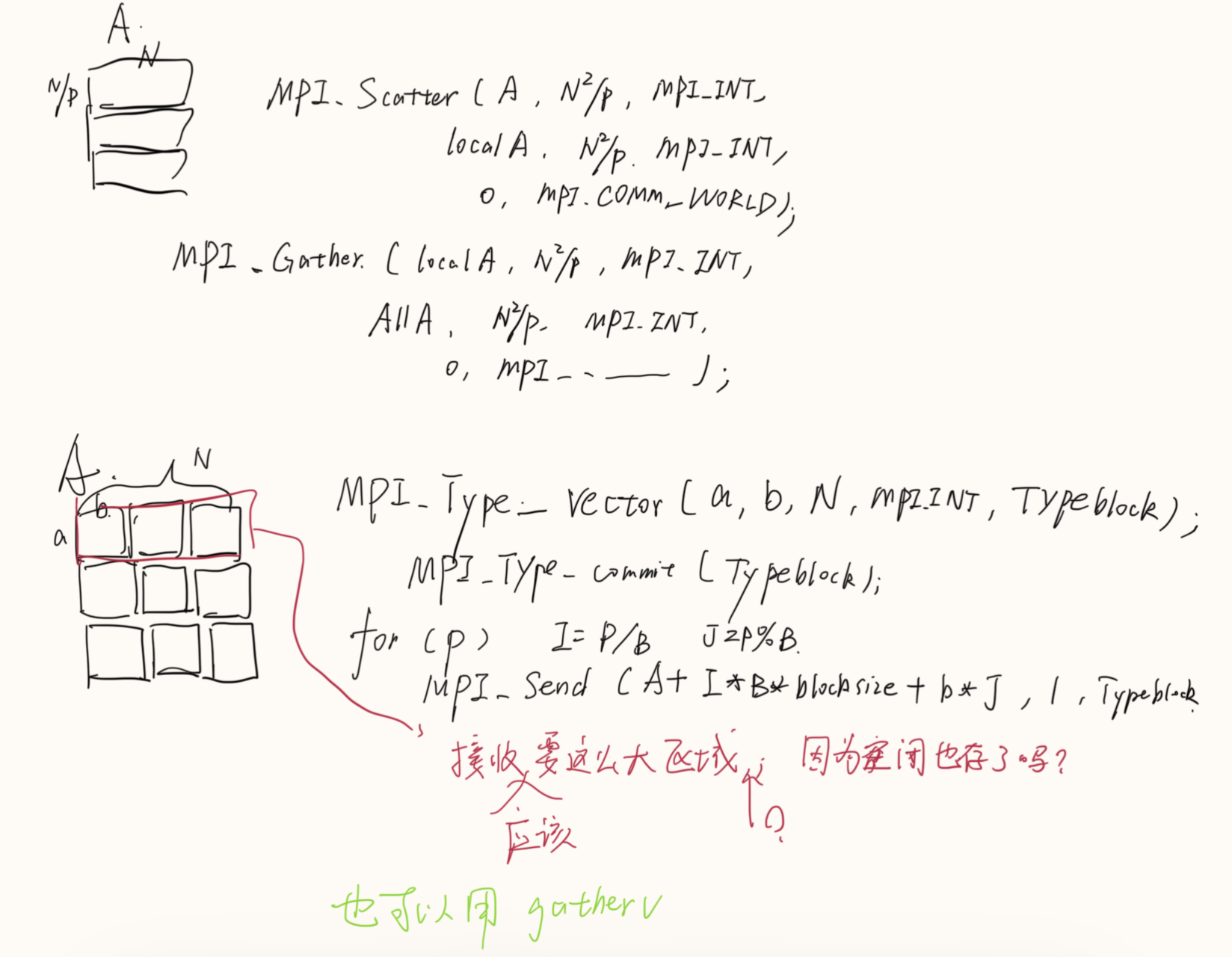
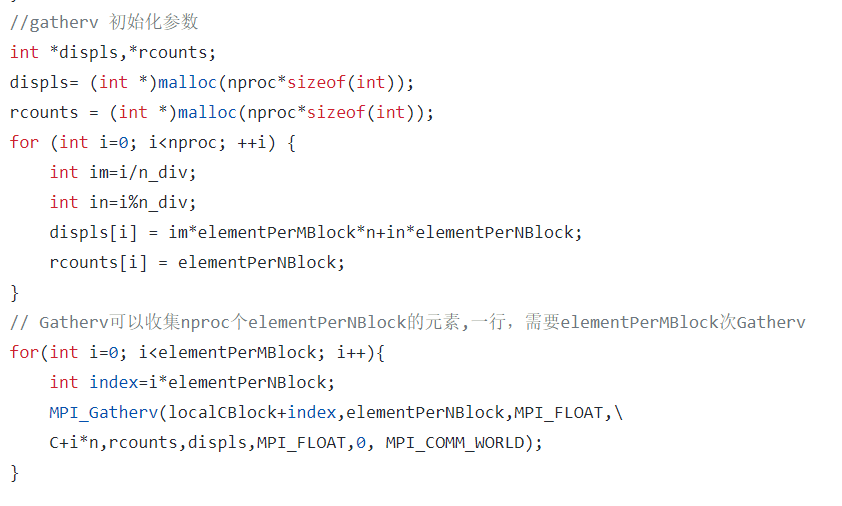
开题缘由、总结、反思、吐槽~~
参考文献
https://blog.csdn.net/susan_wang1/article/details/50033823
https://blog.csdn.net/u012417189/article/details/25798705
是否死锁: https://stackoverflow.com/questions/20448283/deadlock-with-mpi
https://mpitutorial.com/tutorials/
http://staff.ustc.edu.cn/~qlzheng/pp11/ 第5讲写得特别详细