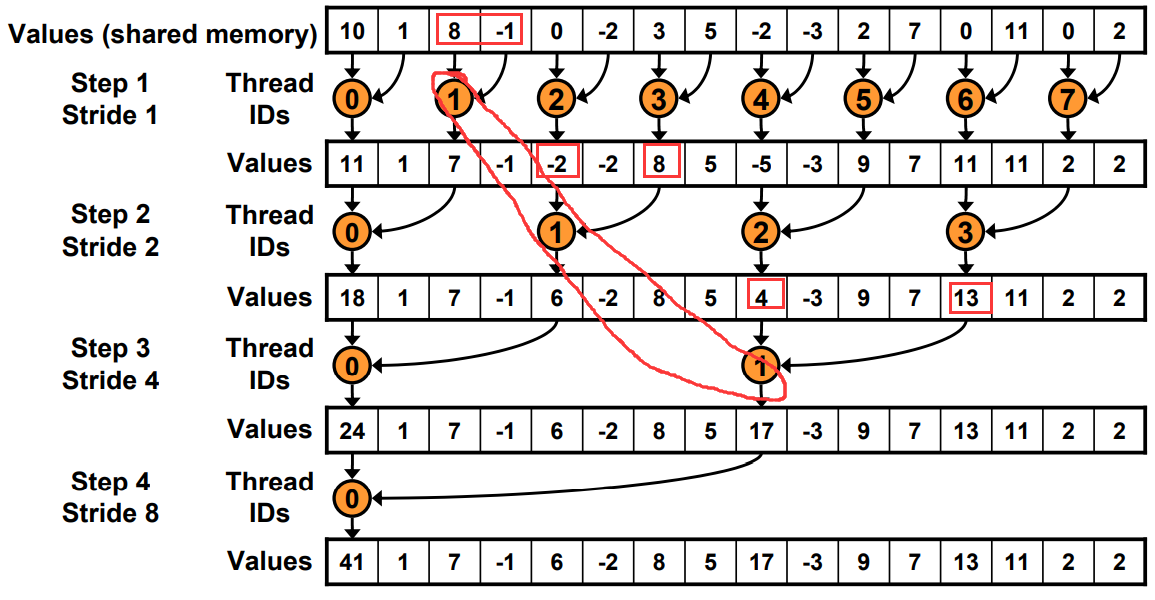
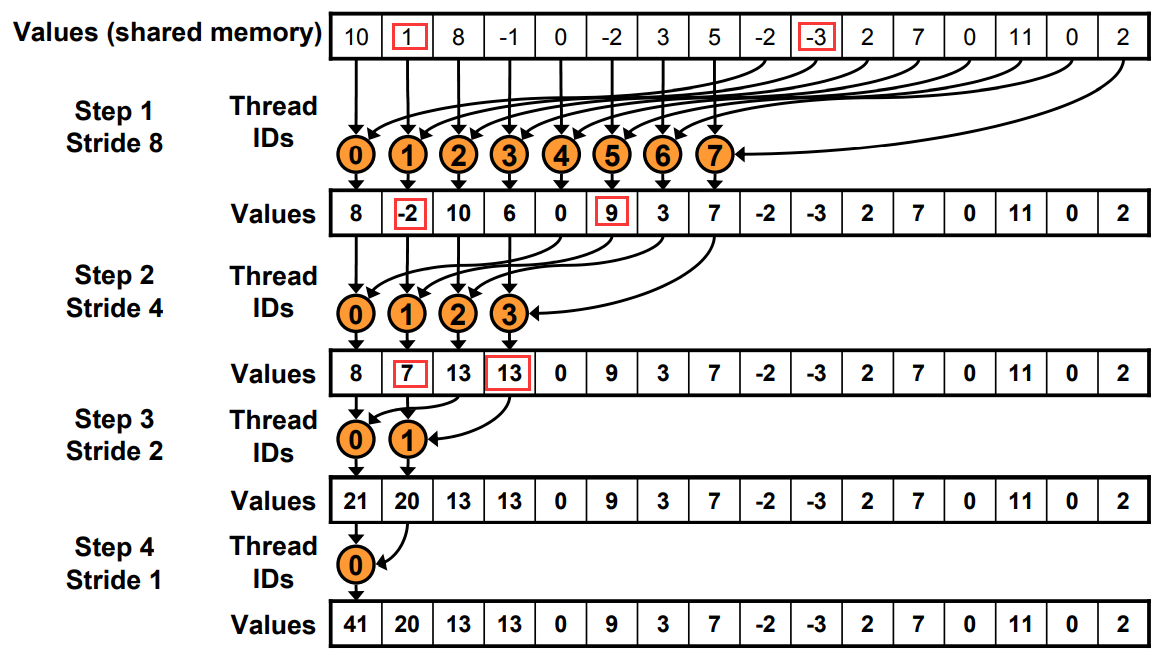
Nsight system compute & Graph 的关系
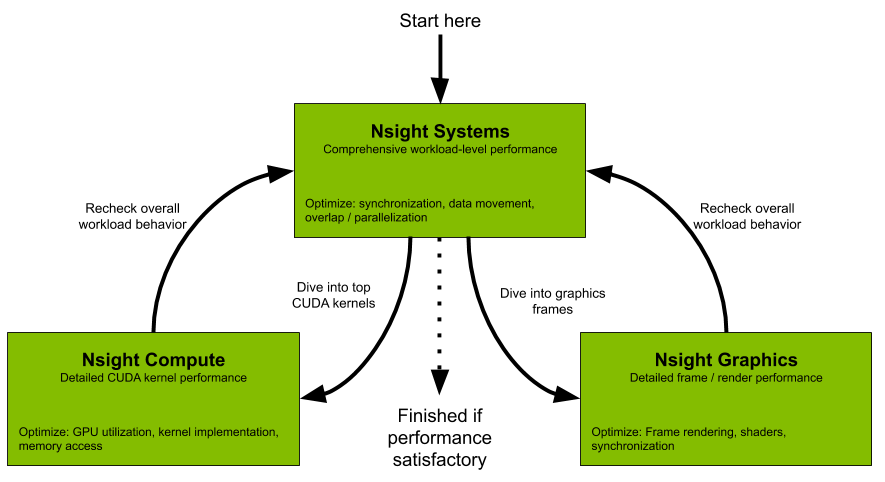
Nsight Systems
All developers should start with Nsight Systems to identify the largest optimization opportunities. Nsight Systems provides developers a system-wide visualization of an applications performance. Developers can optimize bottlenecks to scale efficiently across any number or size of CPUs and GPUs; from large servers to our smallest SoC. For further optimizations to compute kernels developers should use Nsight Compute or to further optimize a graphics workloads, use Nsight Graphics.
Nsight Compute
Nsight Compute is an interactive kernel profiler for CUDA applications. It provides detailed performance metrics and API debugging via a user interface and command line tool. Nsight Compute also provides customizable and data-driven user interface and metric collection that can be extended with analysis scripts for post-processing results.
Nsight Graphics
Nsight Graphics is a standalone application for the debugging, profiling, and analysis of graphics applications on Microsoft Windows and Linux. It allows you to optimize the performance of your Direct3D 11, Direct3D 12, DirectX Raytracing 1.1, OpenGL, Vulkan, and KHR Vulkan Ray Tracing Extension based applications.
Install Nsight local
- check the perf config To collect thread scheduling data and IP (instruction pointer) samples
cat /proc/sys/kernel/perf_event_paranoid- 如果大于2,临时改变
sudo sh -c 'echo 2 >/proc/sys/kernel/perf_event_paranoid'重启会重置 - 永久修改
sudo sh -c 'echo kernel.perf_event_paranoid=2 > /etc/sysctl.d/local.conf'
- 下载Nsight
- 但是单独下载要会员
- 下载cuda toolkit,有集成
Nsight System
目标与功能
运行 nsight-sys,可以从整体上看GPU,CPU资源的使用情况,和分辨出热点函数和kernel,但是对于为什么是热点给不出具体分析。
基本使用
勾选了CUDA-trace, GPU Metrics选项
Profile 速度
大致2到3倍时间:默认采样率,单独运行52s, Nsight-sys模拟需要135s。
HPC APP : PCIE, GPU DRAM Bandwidth, Warp
GPU Metrics选项能看出 PCIE, GPU DRAM Bandwidth, Warp的使用情况。
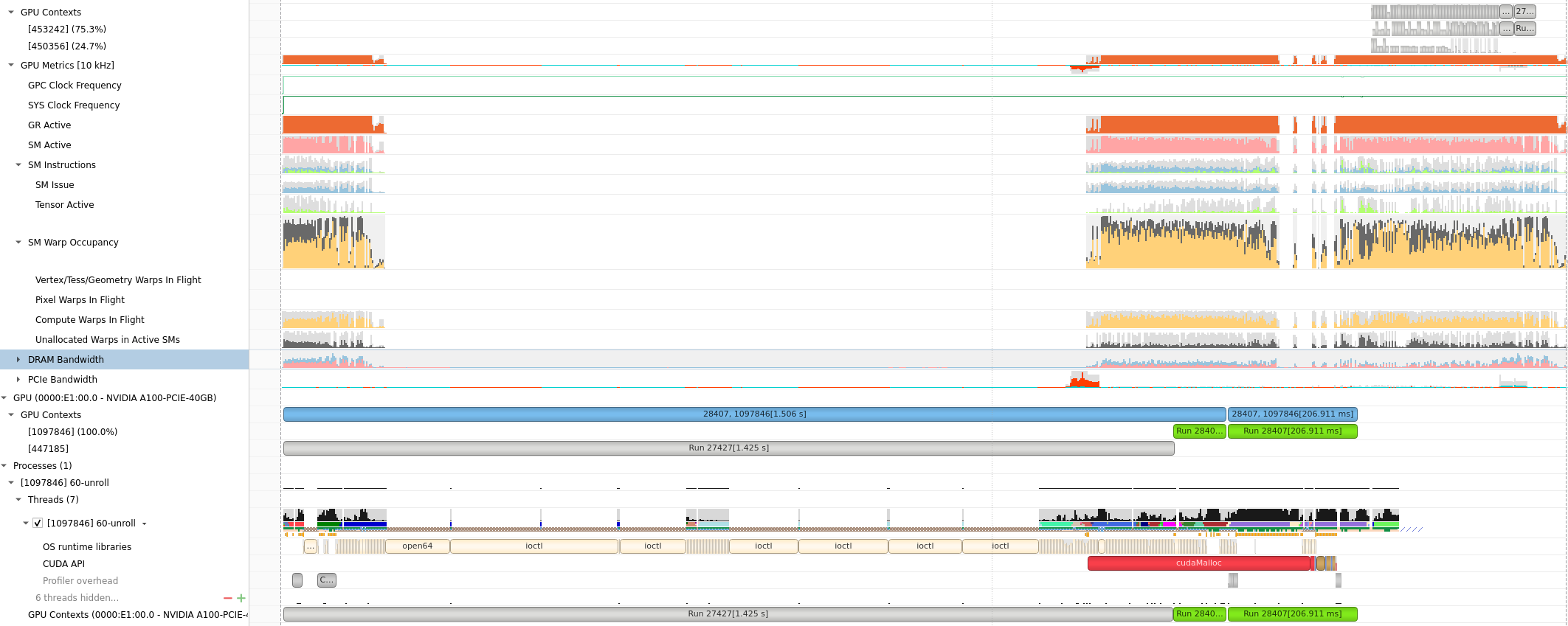
Compute Warps in Flight
将鼠标放在上面会有具体的数值或者名称的解释,(正在使用的Warps)

Unallocated Warps in Active SMs
- Definition: This metric represents the number of warps that are not actively executing but are assigned to an active Streaming Multiprocessor (SM).
- Interpretation: In CUDA, SMs are the fundamental processing units on the GPU. Each SM can execute multiple warps concurrently. “Unallocated Warps in Active SMs” indicates the number of warps that are ready to be scheduled on an SM but are currently waiting due to resource contention or other factors. A high number may suggest that there is room for additional work but available resources are not fully utilized.
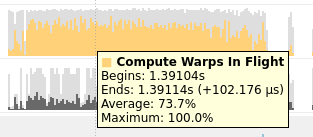
NVTX
由于没有根据kernel function区分,很难读。为此提供了NVTX来给代码打标签
AI APP: Stable Diffusion XL

具体分析见 Deploy Stable Diffusion to A100
Nsight Compute
- Nsight Systems 就是nvprof的继任者,NVIDIA最新的用于监测 kernel timeline的工具。
- NVIDIA 计算能力7.5及以上的GPU设备(从A100开始)不再支持nvprof工具进行性能剖析,提示使用Nsight Compute作为替代品.
目标与功能
默认kernel模式,会根据 function的调度关系,将程序划分为kernel
- Summary: 给出in-order执行的每个kernel的参数,时间,资源占用(寄存器,计算访存单元)信息。
- Detail: 对于被选择的kernel给出, NV的优化建议
- Source:对于被选择的kernel给出, 给出源代码
基本使用
1 | # recommand running under sudo |
Profile速度
目测模拟时间慢百倍。
使用Nsight Compute CLI (nv-nsight-cu-cli / ncu) 输出数据
nv-nsight-cu-cli -> ncu
下面是一个使用样例:
1 | /usr/local/NVIDIA-Nsight-Compute/nv-nsight-cu-cli -o mnist -f --csv --profile-from-start off /usr/bin/python3 mnist.py |
其中-o是为了输出.nsight-cuprof-report文件用于后续的可视化查看,-f为强制覆盖原有文件,–csv可是在console输出除 timeline 以外数据的时候以逗号分隔数据,方便拷贝至csv文件, –profile-from-start的使用方法和Nsight System以及nvprof一样。其余flag选项可见文档。
上面的例子会生成mnist.nsight-cuprof-report文件。
注意
最前面的可执行文件需要绝对路径,如上面的python3需要使用 /usr/bin/python3。
生成过程中可能会产生很大的临时文件(几十G)。如果本次磁盘空间不够,可以设置如下环境变量来调整存储临时文件的地址。没有找到能直接使用 Nsight Compute 修改临时文件地址的方式。
1 | export /TMPDIR=/path/for/tmp |
ncu与nvprof命令行抓取参数的映射表
https://www.freesion.com/article/34871449930/
ncu-ui教程
为了显示原代码makefile添加 -g -G选项
对应CmakeList.txt
1 | target_compile_options(better PUBLIC $<$<COMPILE_LANGUAGE:CUDA>:--extended-lambda |
https://blog.csdn.net/yan31415/article/details/109491749
ncu-ui表格&图
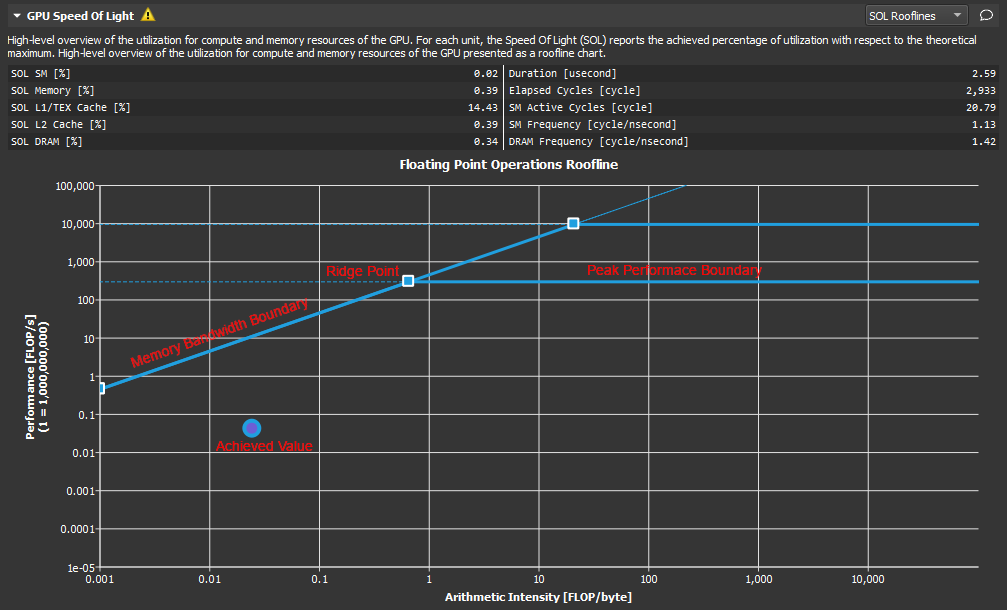
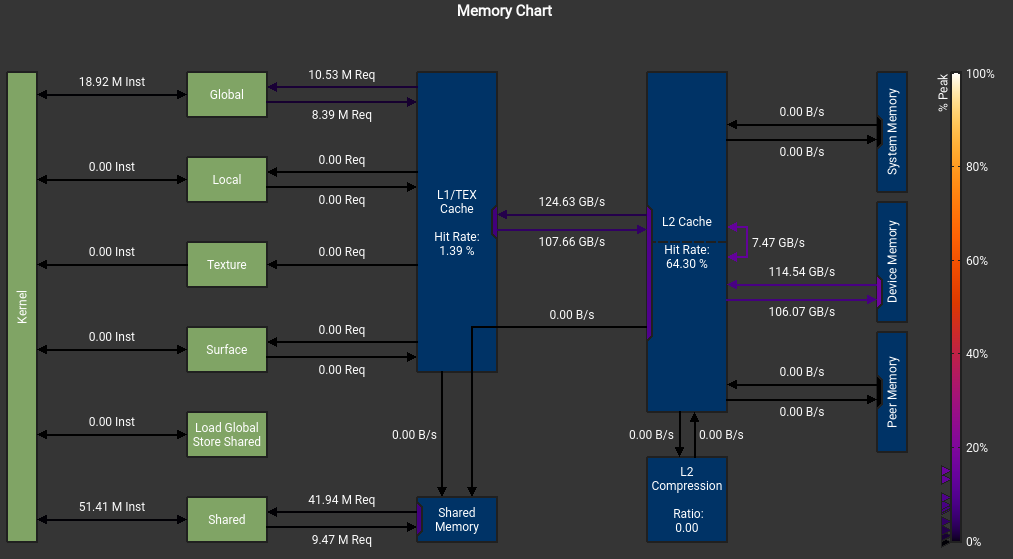
我不明白我的SMEM怎么不是从DRAM来的, 而且峰值怎么这么低?
这个错误也是令人迷惑
The memory access pattern for loads from L1TEX to L2 is not optimal. The granularity of an L1TEX request to L2 is a 128 byte cache line. That is 4 consecutive 32-byte sectors per L2 request. However, this kernel only accesses an average of 3.7 sectors out of the possible 4 sectors per cache line. Check the Source Counters section for uncoalesced loads and try to minimize how many cache lines need to be accessed per memory request.

不知道为什么有1%和2% 的bank conflict
可以看到 SMEM, Register,Block Size是怎么影响GPU Warp的分配调度的。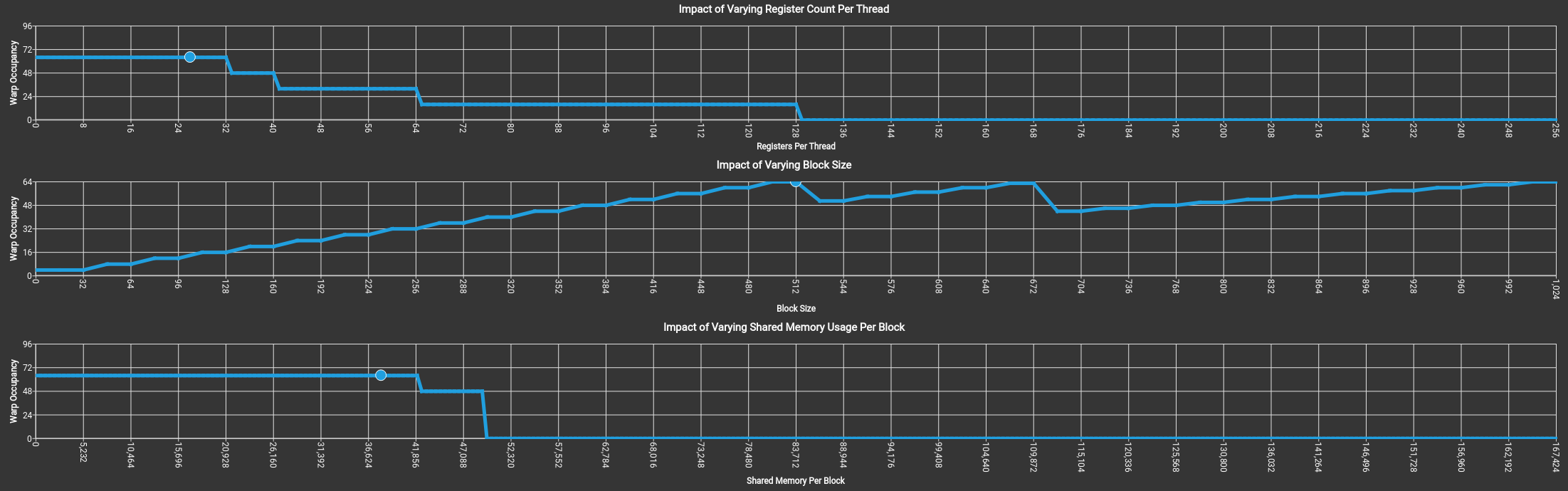
上图没有拖累,吃满了64个warp。
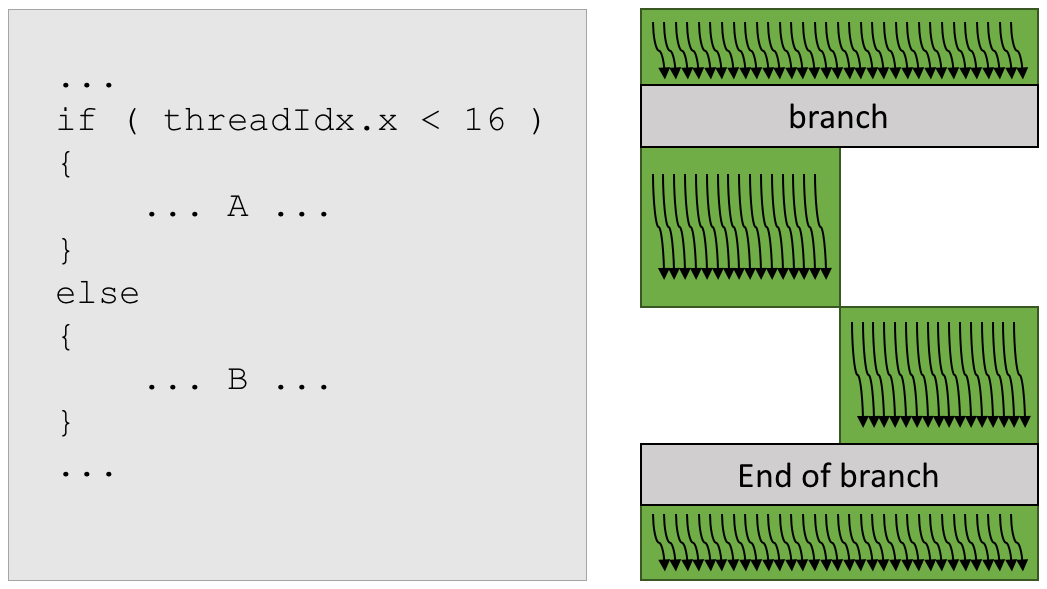
关于if语句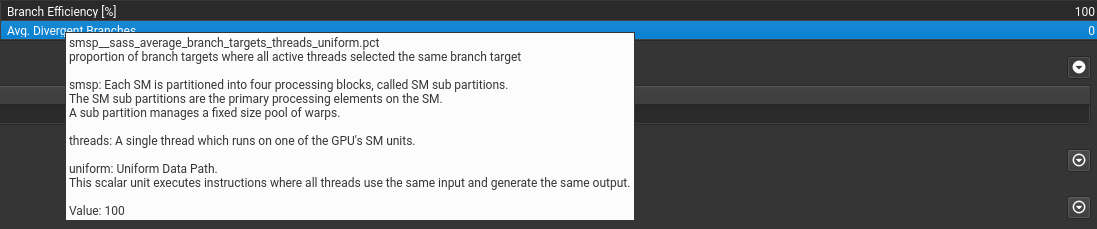
if语句只要warp里执行相同就行。
可以提示出不连续访问的地方。(这里是这样设计的,已经避免了绝大部分的不连续访问)
显示stall最多的指令是什么以及在等待什么。还有执行最多的指令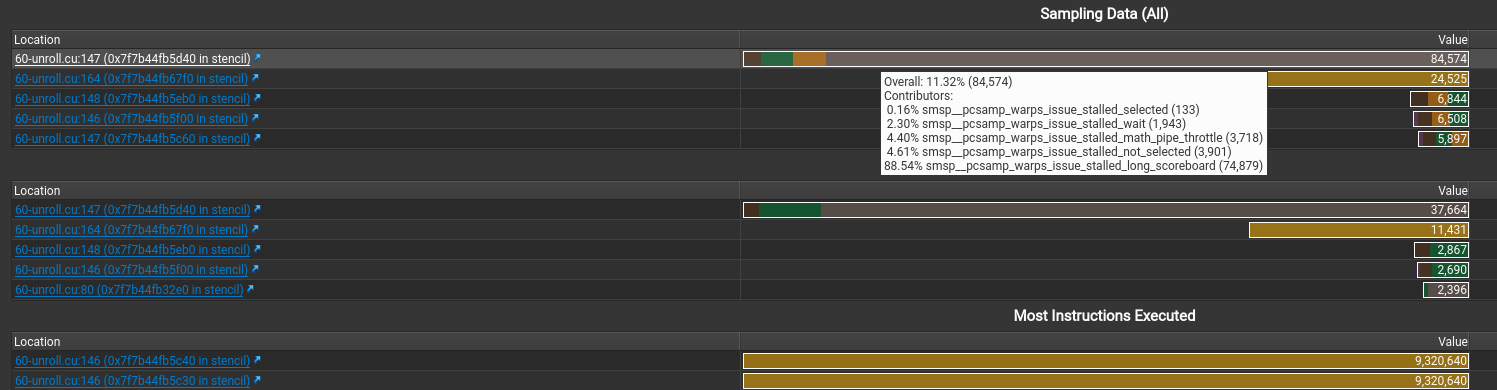
假如 file mismatched 手动选择文件就行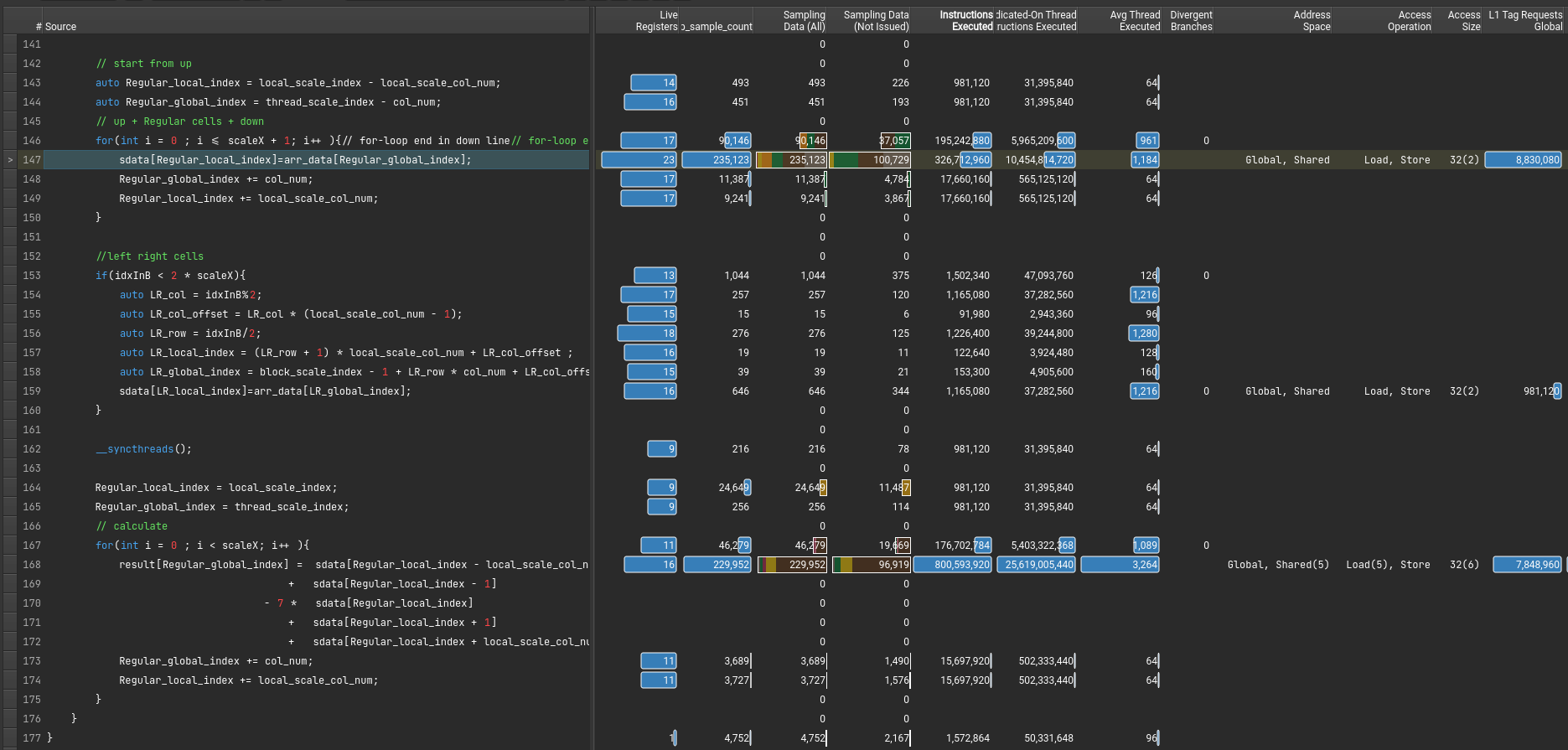
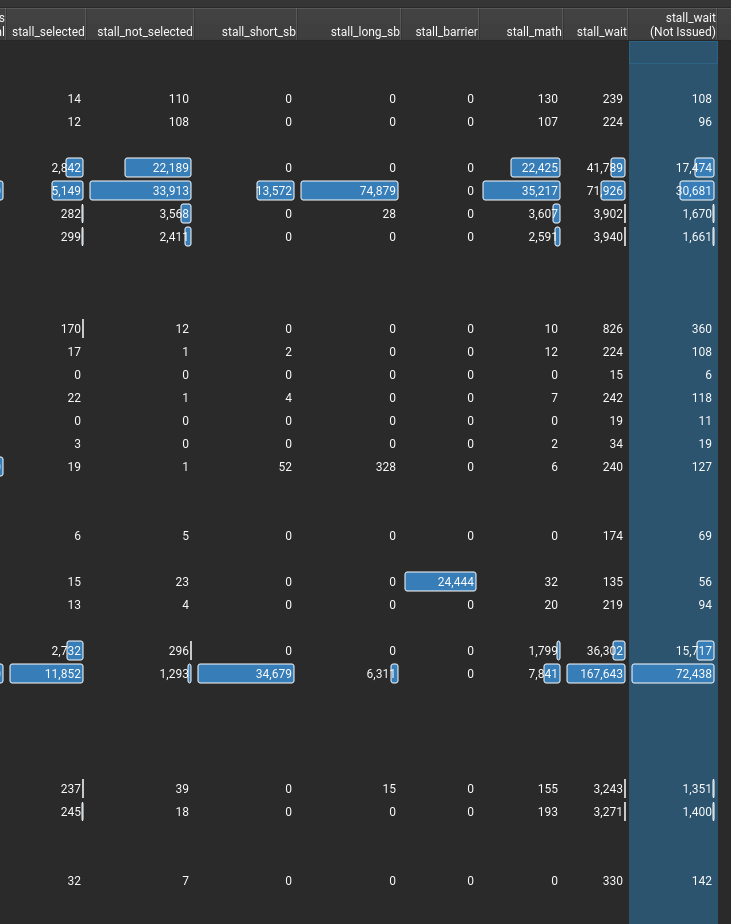
stall的信息,感觉就这些有点用。(其中sb是scoreboard的意思)
ncu-ui 分析汇编
PTX&SASS汇编说明
有两种汇编
请看PTX SASS一文
基本说明
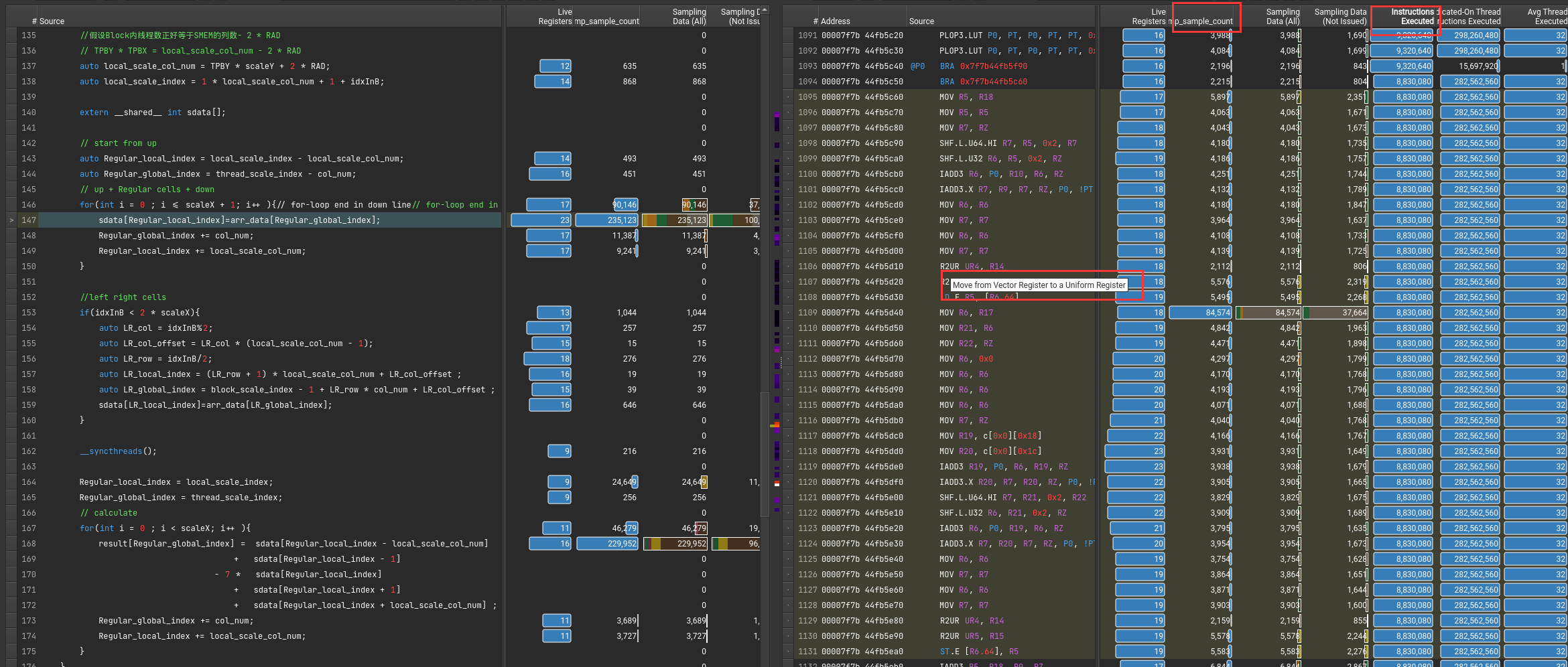
可以通过指令执行数或者采样率来得知,执行最多的指令。
鼠标悬停可以知道具体命令的含义
Ex1: for循环头
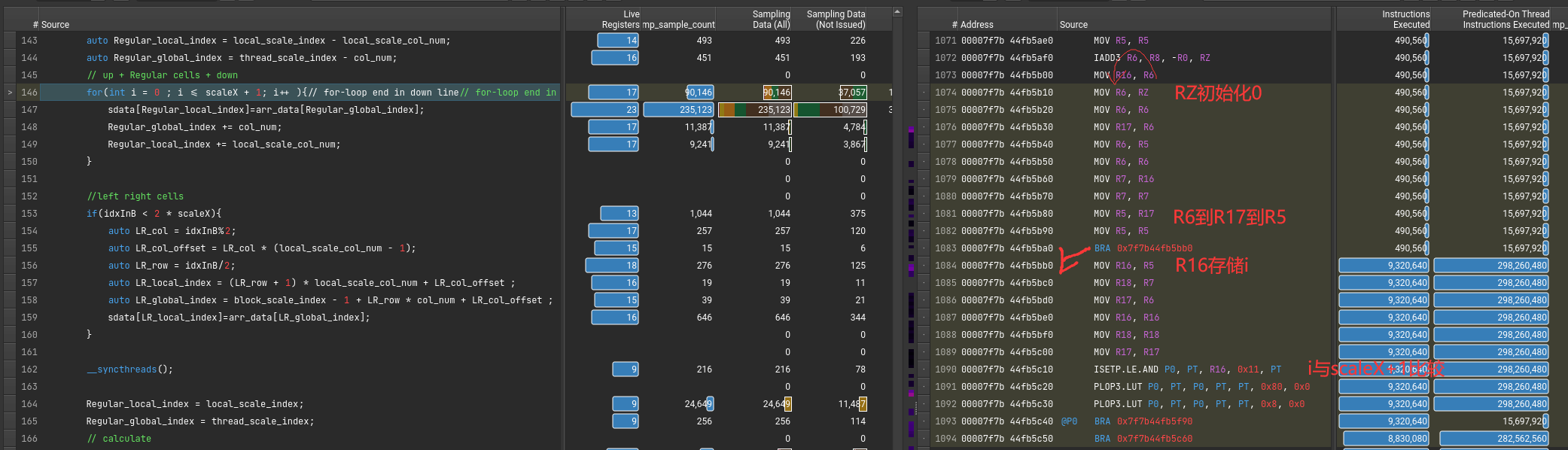
Ex2: for-loop kernel
1 | sdata[Regular_local_index]=arr_data[Regular_global_index]; |
该从DRAM里读取到SMEM的指令对应的PTX和SASS代码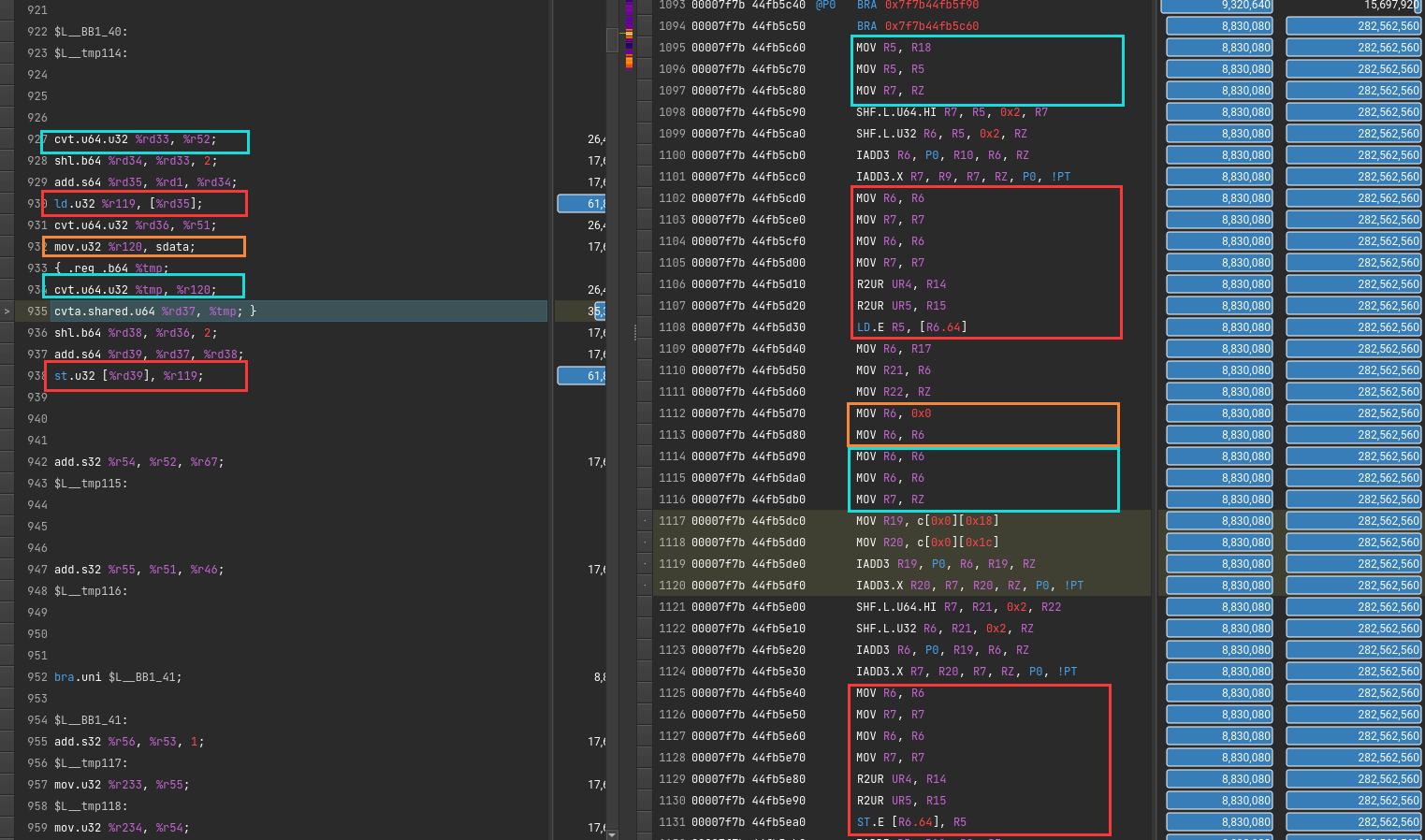
1 | cvt.f32.u16 d, a; // convert 16-bit unsigned to 32-bit float |
问题:无效self-mov?
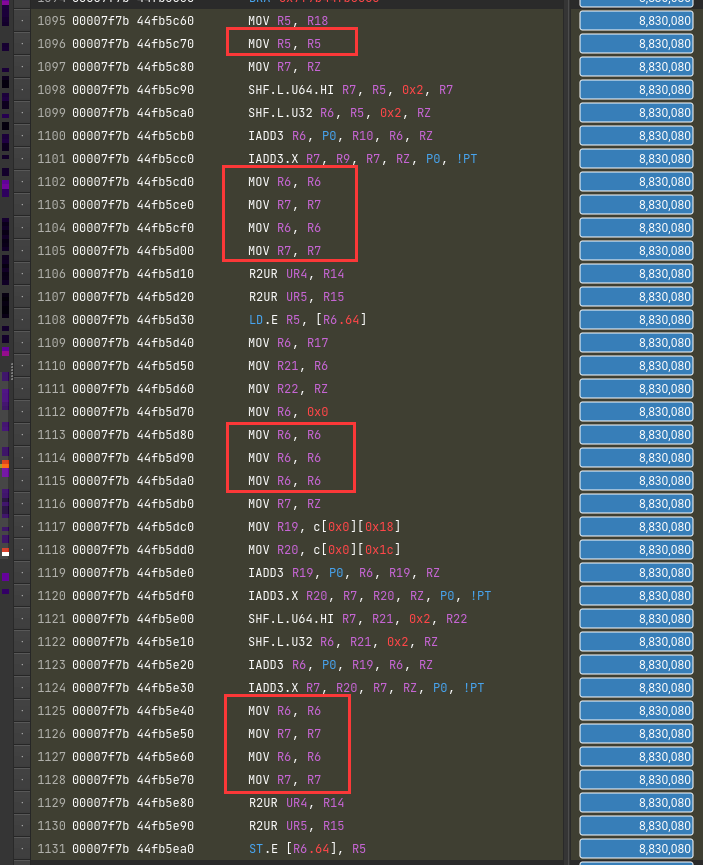
为了隐藏延迟?
直接原因是PTX翻译成SASS。一条mov变多条了

CUDA Visual Profiler
老一代debugger工具,逐渐被Nsight淘汰
1 | nvprof # 命令行,nsys 之前的名称叫做 nvprof |
在more里有建议
nvprof捕获信息存储
1 | nvprof --analysis-metrics -o nbody-analysis.nvprof ./nbody --benchmark -numdevices=2 -i=1 |
CUDA Visual Profiler 问题
Nsight Compute 问题
OpenGL 没有安装
1 | Warning: Failed to get OpenGL version. OpenGL version 2.0 or higher is required. |
解决办法
1 | sudo apt-get install libxcb-xinerama0 |
Qt插件缺失
1 | qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found. |
按照说明 export QT_DEBUG_PLUGINS=1再次运行, 显示具体问题
1 | Cannot load library /staff/shaojiemike/Install/cuda_11.7.0_515.43.04_linux/nsight-compute-2022.2.0/host/linux-desktop-glibc_2_11_3-x64/Plugins/platforms/libqxcb.so: (libxcb-xinput.so.0: cannot open shared object file: No such file or directory) |
解决 sudo apt-get install libxcb-xinput0
kernel没权限profile
ERR_NVGPUCTRPERM - The user does not have permission to profile on the target device
要用sudo,或者最新的NV
could not connect to display localhost:10.0 under sudo
1 | $ sudo ncu-ui |
解决办法(原因是sudo相当于切换到root用户,丢失了xauth信息)
1 | $ xauth list |
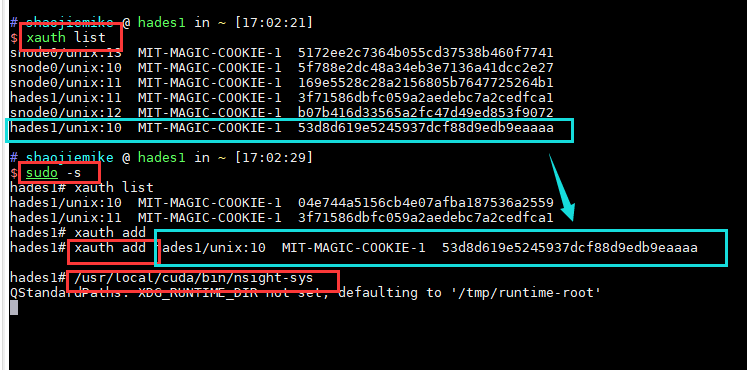
GPU Metrics [0]: Sampling buffer overflow.
- 只勾选CUDA Metrics 和 GPU Metrics
- 降低采样频率
Error 0: UnsupportedGpu
原因是 软件对GPU的支持是逐步的需要安装最新的。
不支持的Nsight的可以尝试老的debugger工具 CUDA Visual Profiler
Error: Profiling is not supported on this device
Pascal support was deprecated, then dropped from Nsight Compute after Nsight Compute 2019.5.1.
The profiling tools that support Pascal in the CUDA Toolkit 11.1 and later are nvprof and visual profiler.
需要进一步的研究学习
暂无
遇到的问题
NVTX问题
开题缘由、总结、反思、吐槽~~
参考文献
https://developer.nvidia.com/tools-overview
https://www.365seal.com/y/zyn1yxJQn3.html
[^1]: Usage of NVTX