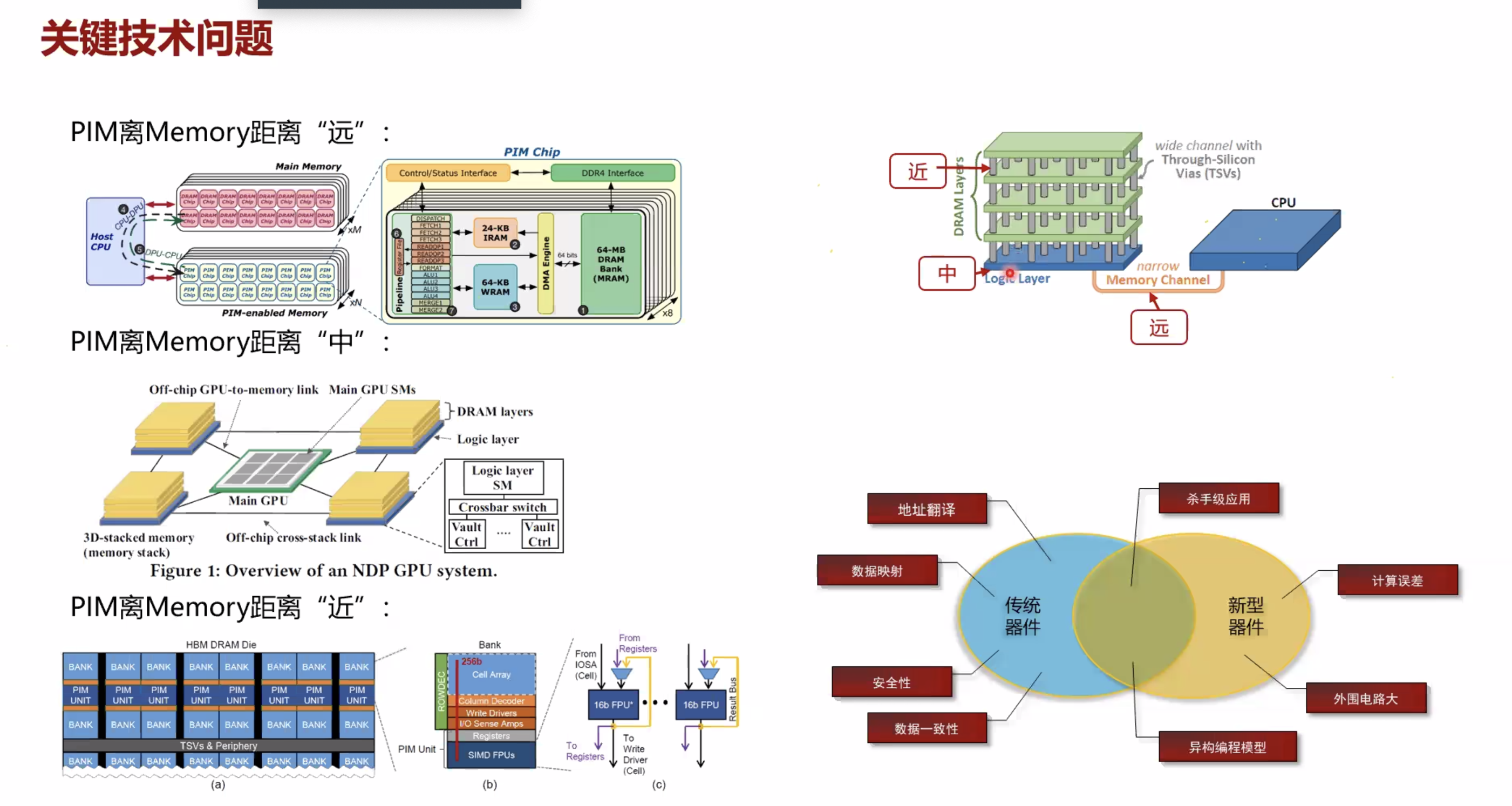
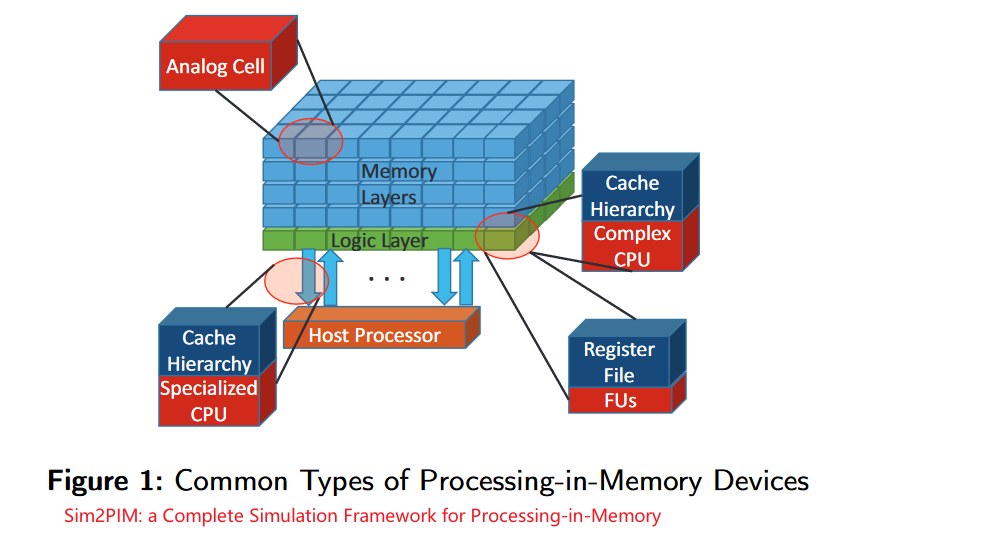
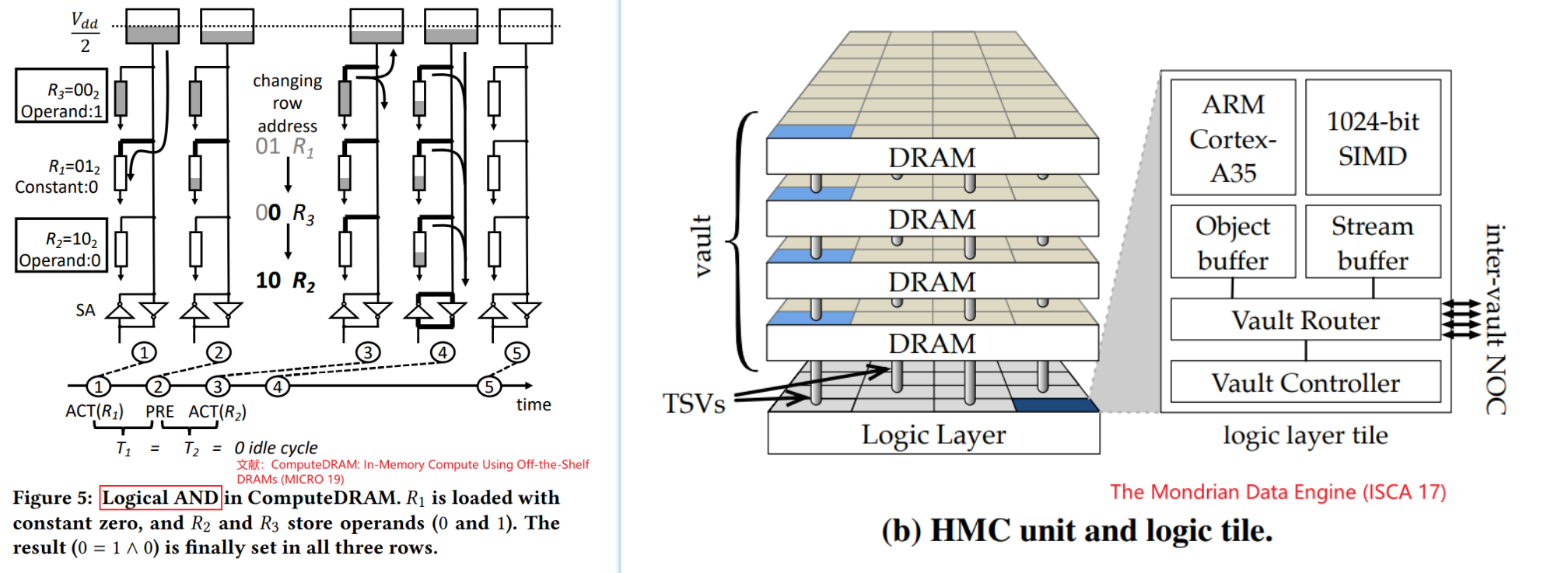
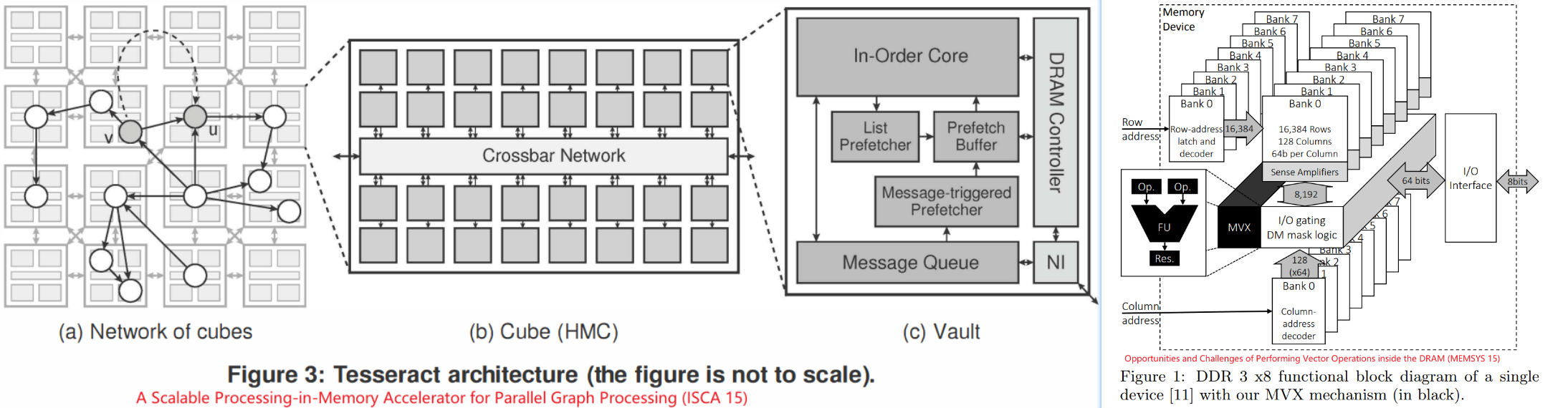
PIM 模拟器的基本分类
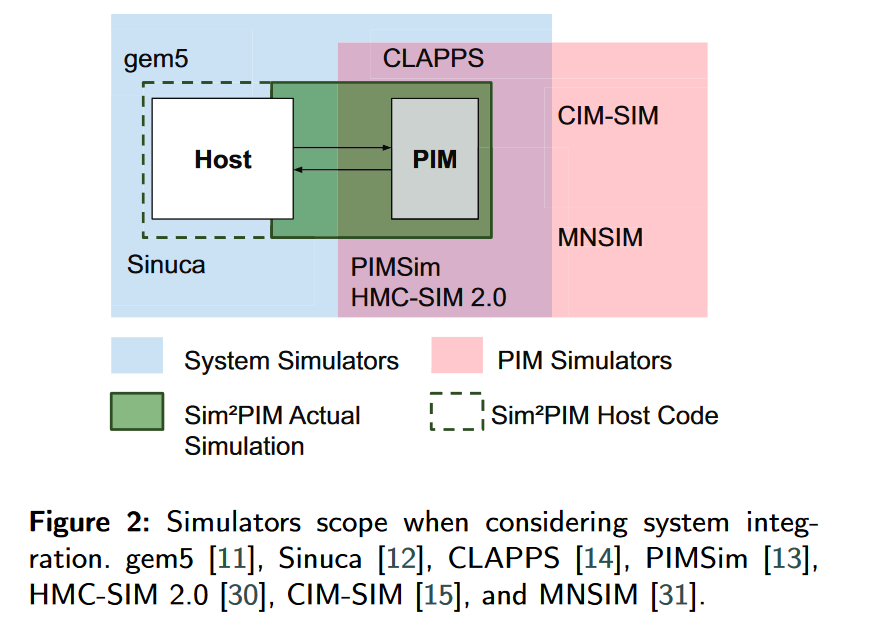
| 技术路线 | 代表 |
|---|---|
| 全系统模拟 | gem5 |
| 基于平台无关的PIM的trace代码的模拟 | Sinuca (HPCC’15) |
| Host端为真实机器,只模拟PIM端 | $Sim^2PIM$ (DATE’21) |
| PIMSim( IEEE Computer Architecture Letters’19) |
memory operations采集
- Intel’s Pin Software 采集 user-mode memory operations
- Bochs full system emulator / ZSim / gem5
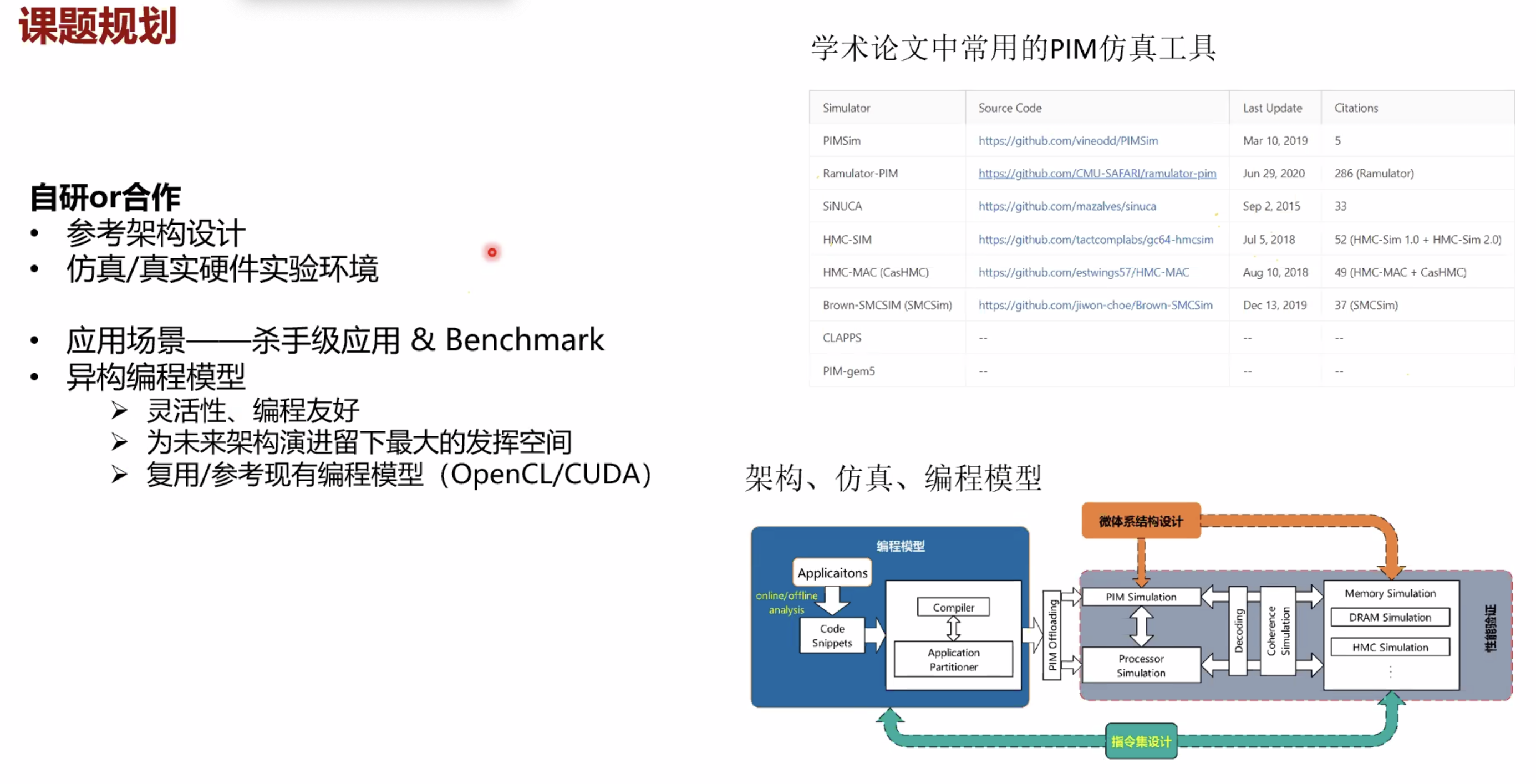
各种PIM论文里的模拟器环境
| 文献 | 环境 | 特点 |
|---|---|---|
| CoNDA(ISCA ’19) | gem5(X86 full-system) + DRAMSim2 | 魔改了gem5的内存模型 |
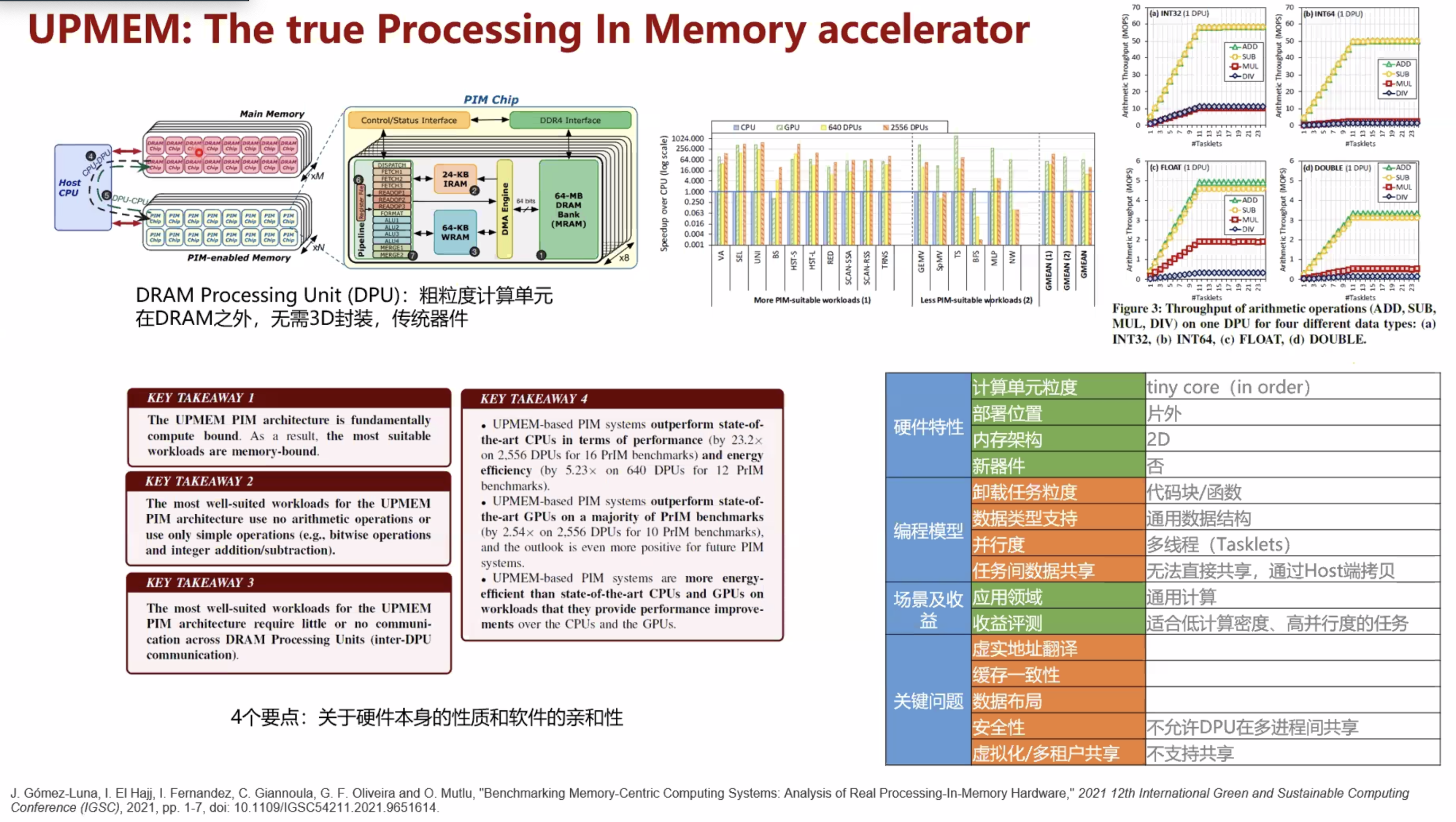
| Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud(IEEE Micro) | 讨论了三种PIM架构1. UPMEM(真实系统) 2. Mensa(Google’s Edge TPU in-house simulator) 3. SIMDRAM(gem5) | |
| Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology(Micro 17) | gem5 | |
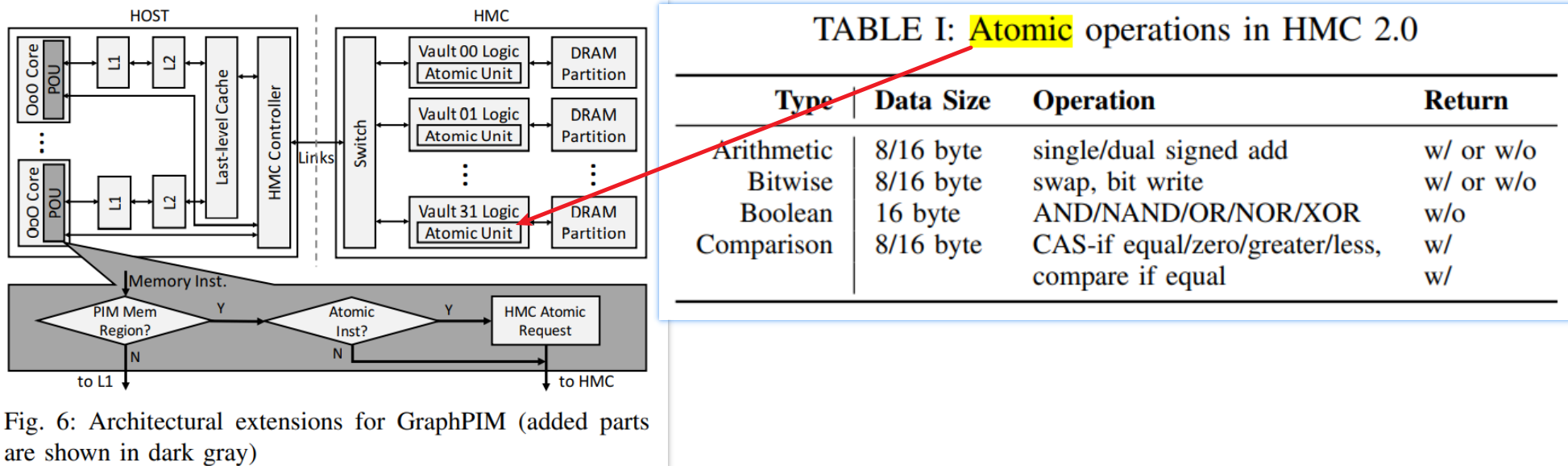
| GraphPIM: Enabling Instruction-Level PIM Offloading in Graph Computing Frameworks | Structural Simulation Toolkit (SST) [28] with MacSim [29], a cycle-level architecture simulator. HMC is simulated by VaultSim, a 3D-stacked memory simulator. We extend VaultSim with extra timing models based on DRAMSim2 | |
| ProPRAM: Exploiting the Transparent Logic Resources in Non-Volatile Memory for Near Data Computing | Multi2Sim + DRAMSim2 + NVSim | |
| Operand Size Reconfiguration for Big Data Processing in Memory(RVU 架构 DATE 17 B会) | SiNUCA(类似gem5) |
越来越多的工作在real PIM system上开展,基于专门的PIM模拟器的貌似很少???为什么无法满足定制的要求吗?
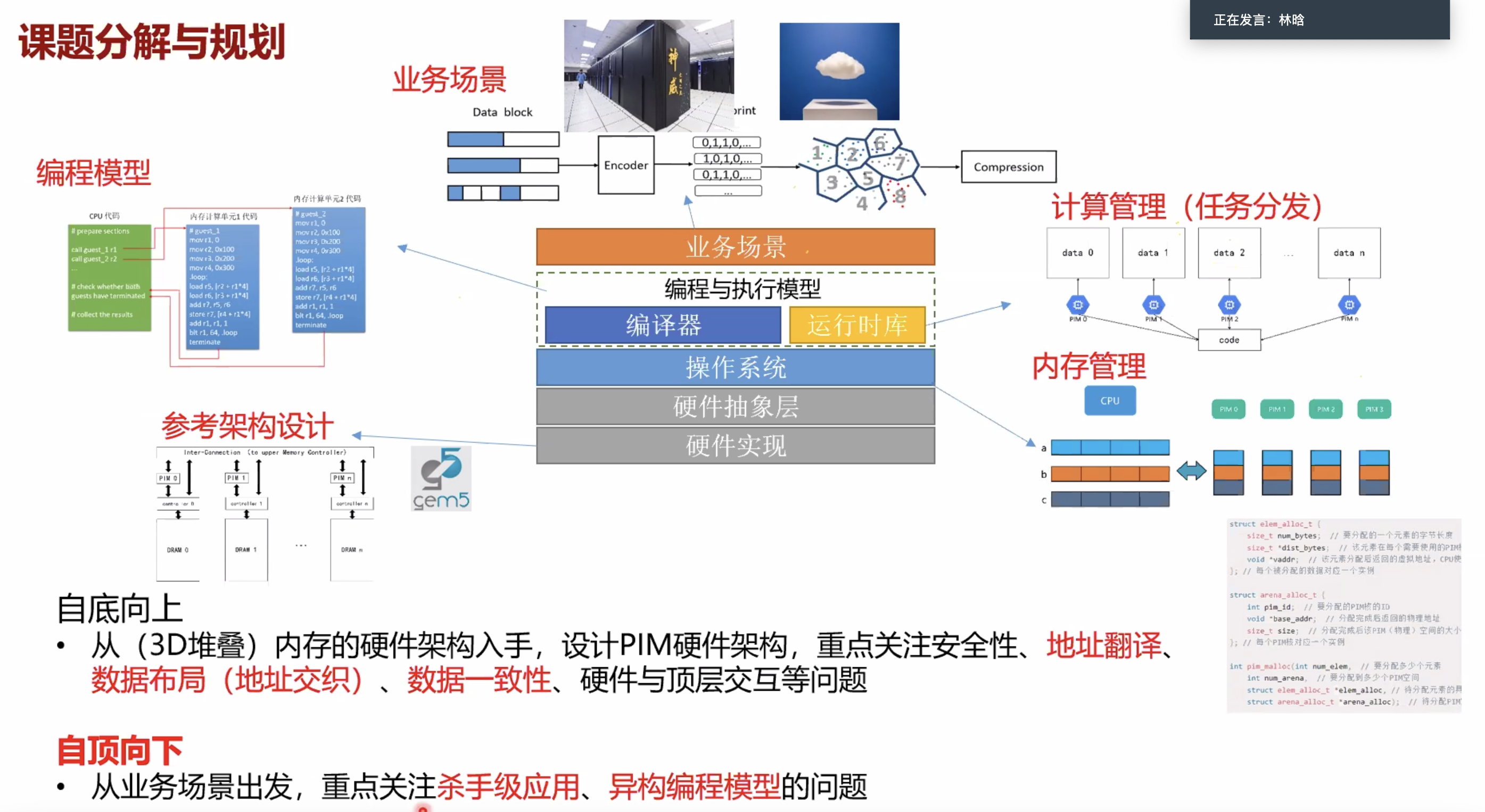
PIM 编译器
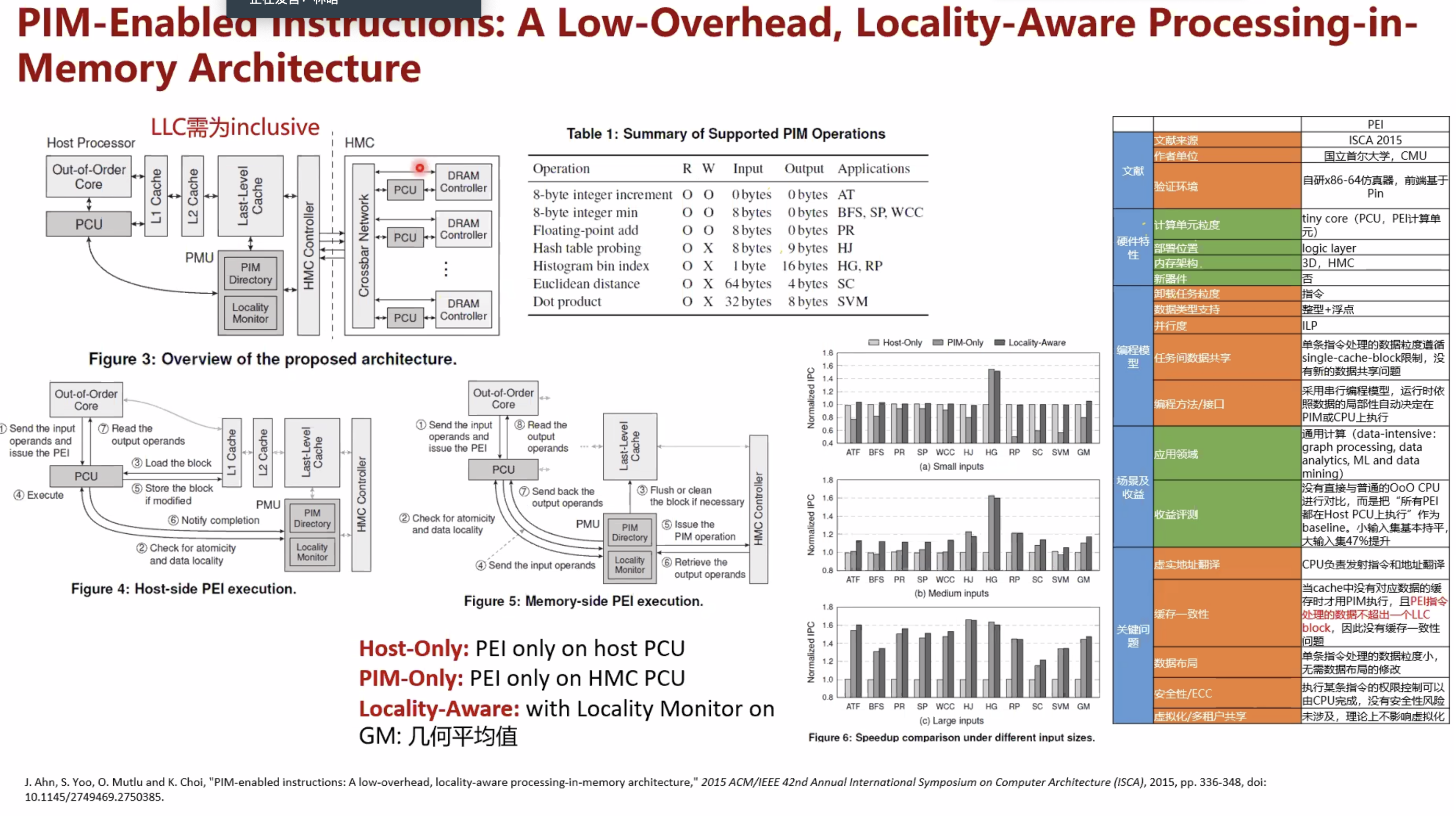
A compiler for automatic selection of suitable processing-in-memory instructions,
PIM cache coherence实现
Providing plug n’ play for processing-in-memory accelerators,
LazyPIM: An Efficient Cache Coherence Mechanism for Processing-in-Memory,
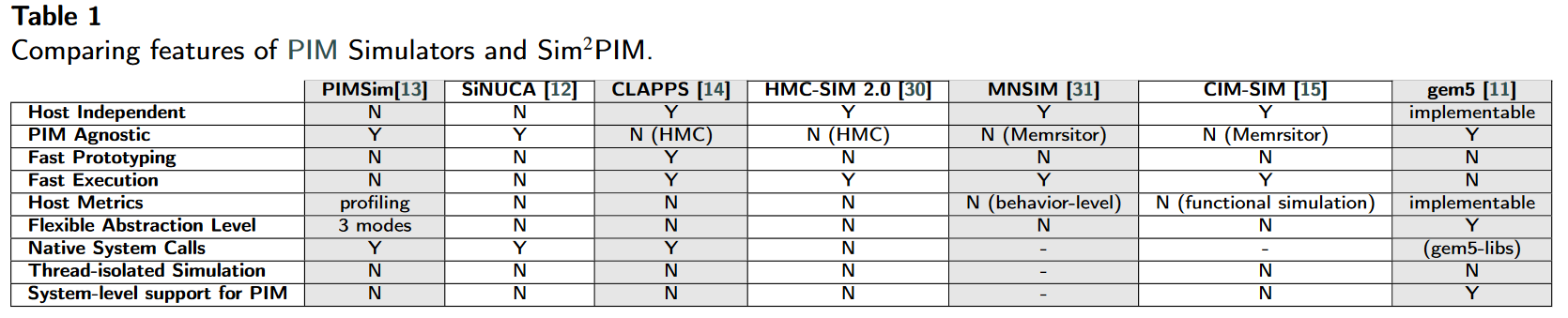
各种的PIM模拟器
比较,优点和局限性
| 模拟器名称 | 文献 | 代码 | 特点 |
|---|---|---|---|
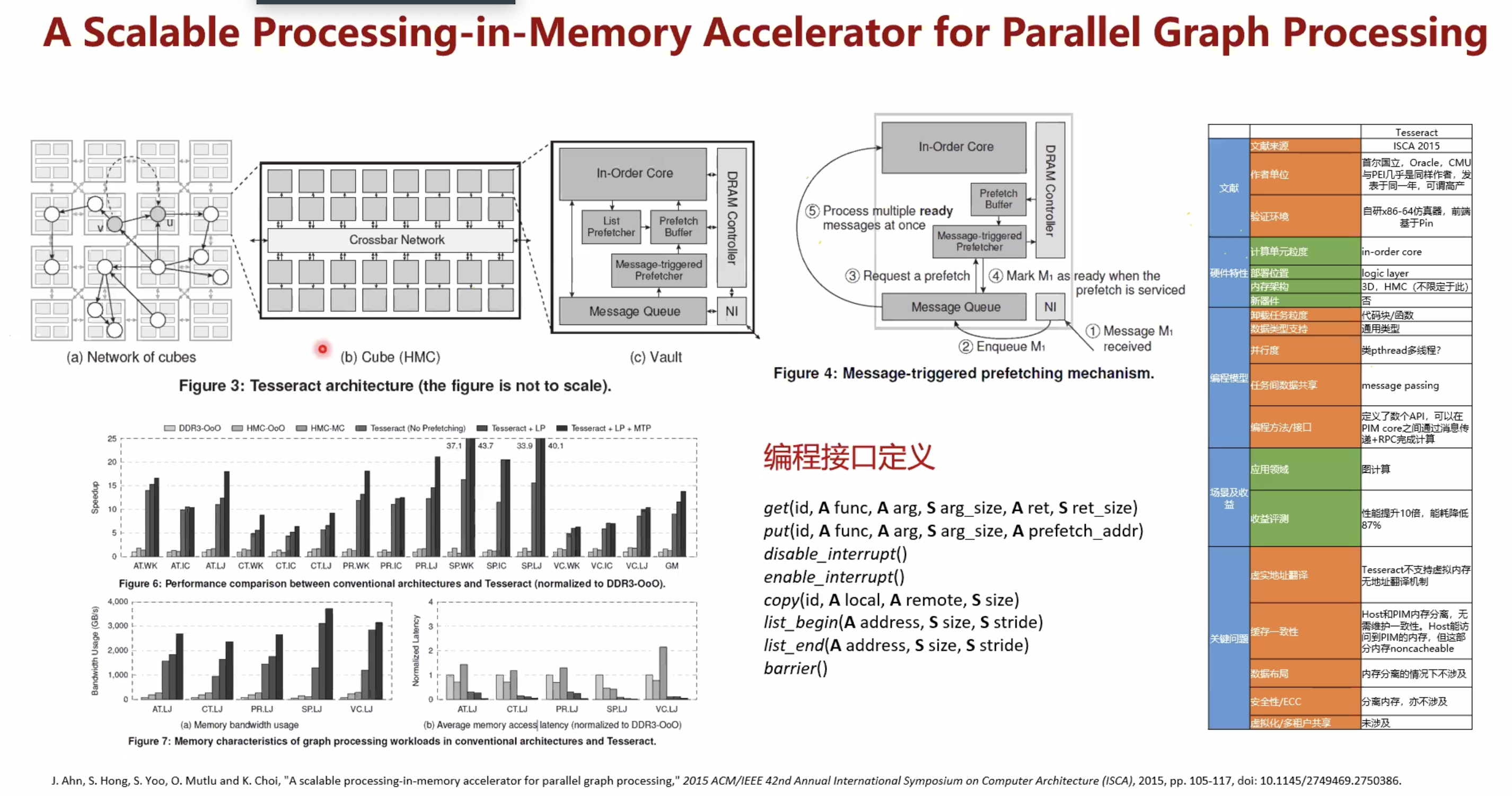
| ZSim + Ramulator | Processing-in-memory: A workload-driven perspective | https://github.com/CMU-SAFARI/ramulator-pim/ | ZSim(类似gem5)+Ramulator(HMC logic layer add PIM core) 了解实现原理后,其memory端的拓展性值得期待 |
| Sim2PIM | 暂无 | 可以将任意PIM架构和任意host端结合,多线程very fast as perf(通过利用Host系统OS的pthread和硬件计数器来实现)缺点:Host端的cache策略等不能任意定制 | |
| gem5 | SiNUCA文章指出gem5的DRAM模拟误差可以达到36% | ||
| Sinuca(HPCC 15) | Sinuca: A validated micro-architecture simulator | use real trace-based simulator(但是不能采OS和多线程的) | |
| PinTools | Pin: Building customized program analysis tools with dynamic instrumentation, | 类似上面的,JIT执行 | |
| MultiPIM | Multipim: A detailed and configurable multistack processing-in-memory simulator | ||
| Pimsim | Pimsim: A flexible and detailed processing-in-memory simulator | 太慢 | |
| Hmc-sim-2.0: A simulation platform for exploring custom memory cube operations | 特定架构 | ||
| Cycle Accurate Parallel PIM Simulator (CLAPPS) | A generic processing in memory cycle accurate simulator under hybrid memory cube architecture | 无 | 依赖system模拟器(SystemC HMC simulation) |
| Mnsim: Simulation platform for memristor-based neuromorphic computing system | 不是全系统的模拟(忆阻器PIM 模拟器) | ||
| Cim-sim | Non-Volatile Memory(忆阻器PIM 模拟器) |
ZSim + Ramulator 功能
host CPU cores and general-purpose PIM cores.
The PIM cores are placed in the logic layer of a 3D-stacked memory (Ramulator’s HMC model).
The simulation framework does not currently support concurrent execution on host and PIM cores.
主机CPU核和通用PIM核的计算系统。PIM核心被放置在一个3d堆叠存储器(Ramulator的HMC模型)的逻辑层中。通过这个模拟框架,我们可以模拟主机CPU核和通用PIM核,目的是比较两者对于一个应用程序或其部分的性能。该仿真框架目前不支持主机和PIM核心上的并发执行。
use ZSim to generate memory traces that are fed to Ramulator.
Zim跟踪内存的使用,还可以模拟主机的缓存层次结构(包括coherence协议)。ZSim还可以模拟硬件预取器。
Ramulator simulates the memory accesses of the host cores and the PIM cores
Ramulator contains simple models of out-of-order and in-order cores that can be used for simulation of host and PIM.
需要进一步的研究学习
暂无
遇到的问题
暂无