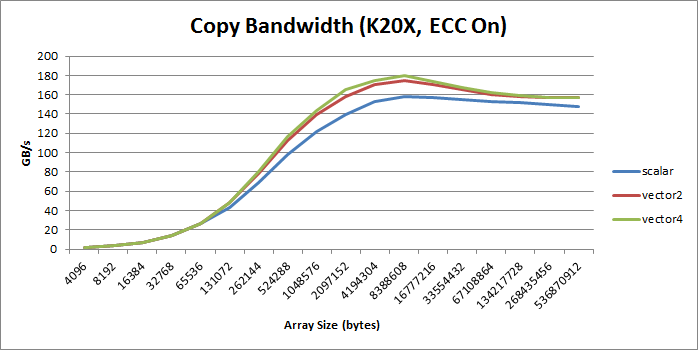
__global__ voiddevice_copy_vector4_kernel(int* d_in, int* d_out, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) { reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i]; }
// in only one thread, process final elements (if there are any) int remainder = N%4; if (idx==N/4 && remainder!=0) { while(remainder) { int idx = N - remainder--; d_out[idx] = d_in[idx]; } } }
voiddevice_copy_vector4(int* d_in, int* d_out, int N) { int threads = 128; int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
Integer multiply-add with extract: multiply R3 with R5, extract upper half, sum that upper half with constant in bank 0, offset 0x24, store in R7 with carry-in.
line3
1
/*0040*/ LD.E R2, [R6]; //load
LD.E is a load from global memory using 64-bit address in R6,R7(表面上是R6,其实是R6 与 R7 组成的地址对)
summary
1 2 3
R6 = R3*R5 + c[0x0][0x20], saving carry to CC R7 = (R3*R5 + c[0x0][0x24])>>32 + CC R2 = *(R7<<32 + R6)
寄存器是32位的原因是 SMEM的bank是4字节的。c数组将32位的基地址分开存了。
first two commands multiply two 32-bit values (R3 and R5) and add 64-bit value c[0x0][0x24]<<32+c[0x0][0x20],