导言
之前ipcc比赛认为很神奇的CPU侧的double2int8的转换,其实思想就是AI推理的常见低比特量化思路。
关于X86 与 arm的寄存器的区别写在了arm那篇下
https://developer.arm.com/documentation/dui0068/b/CIHEDHIF

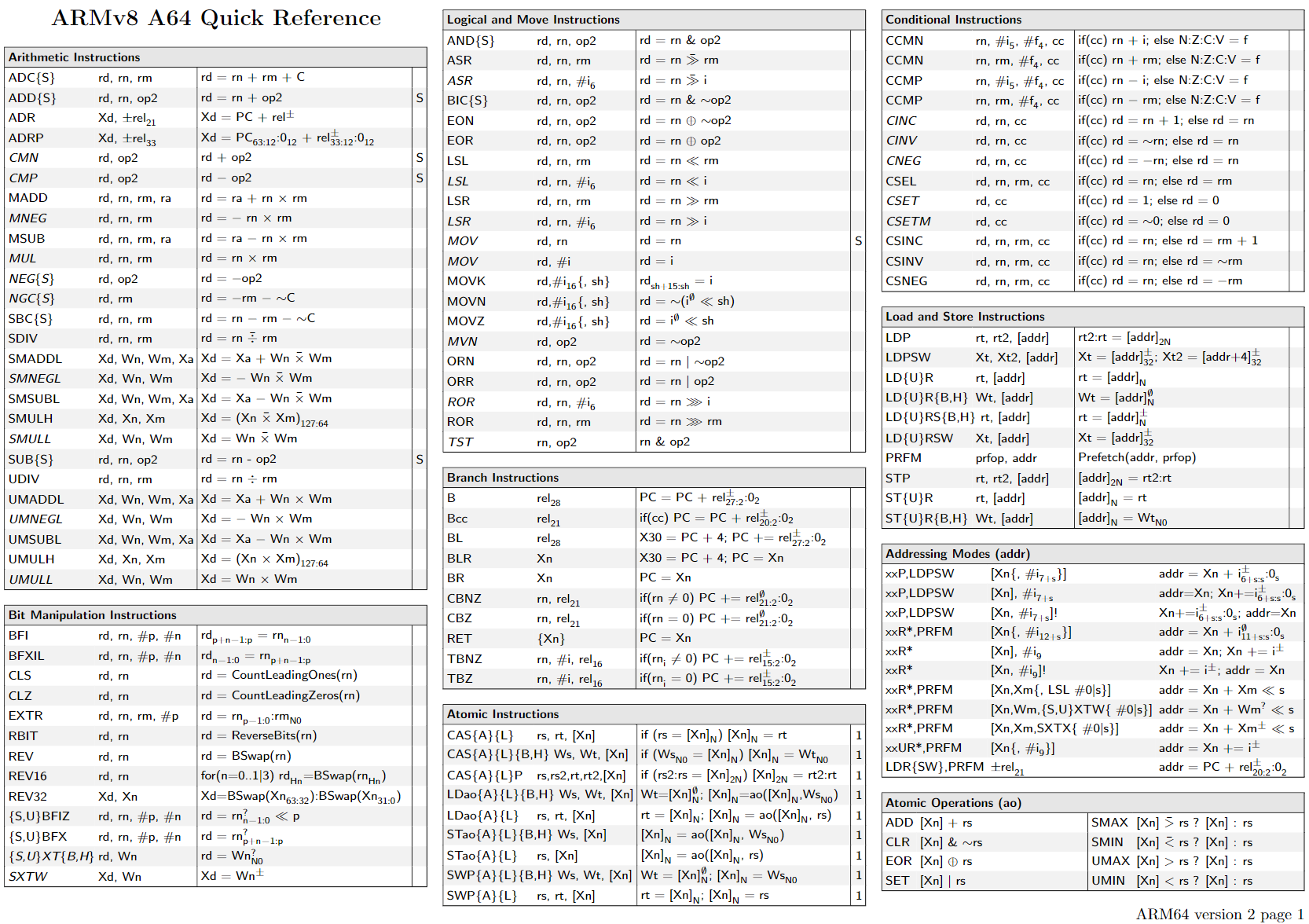
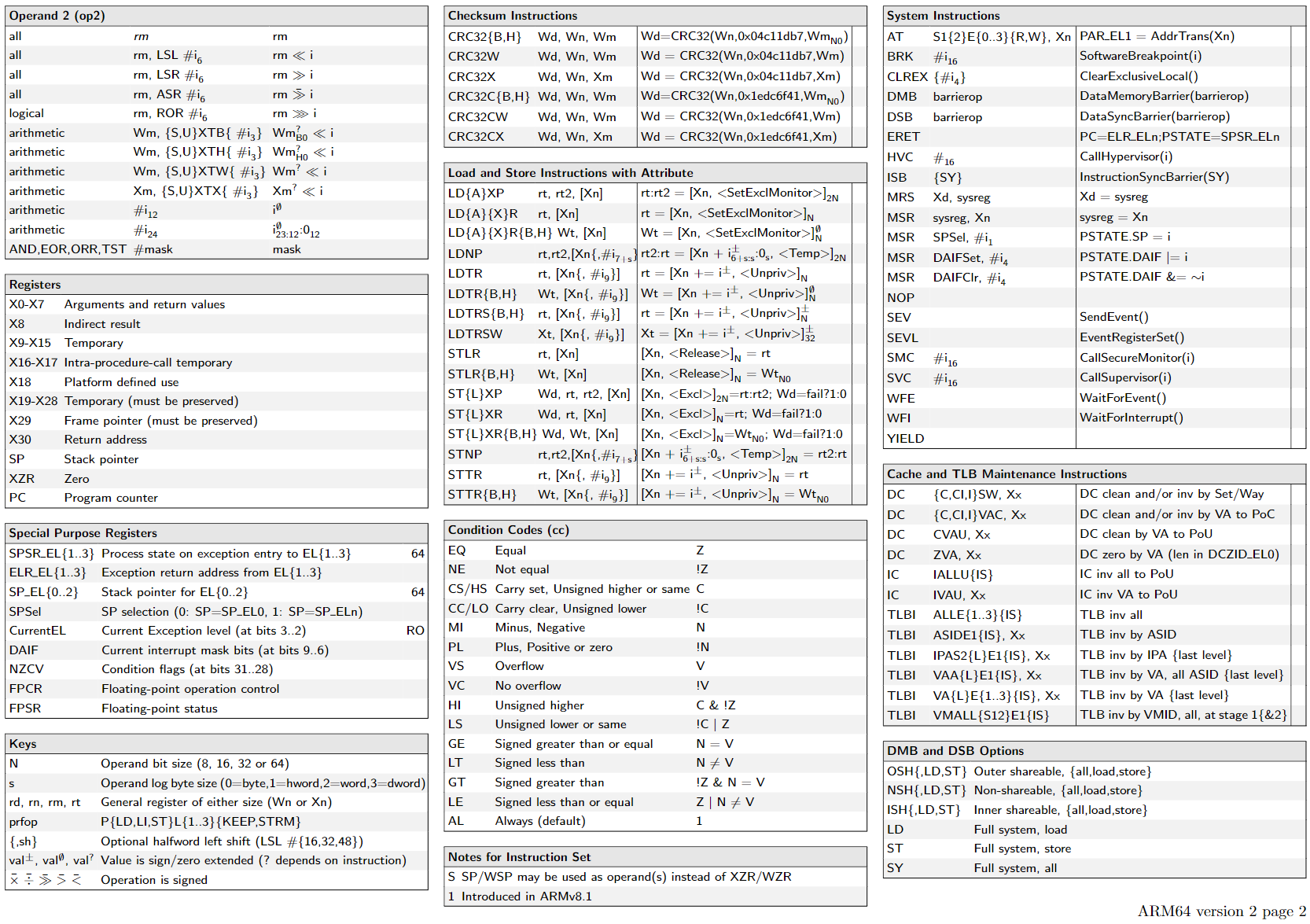
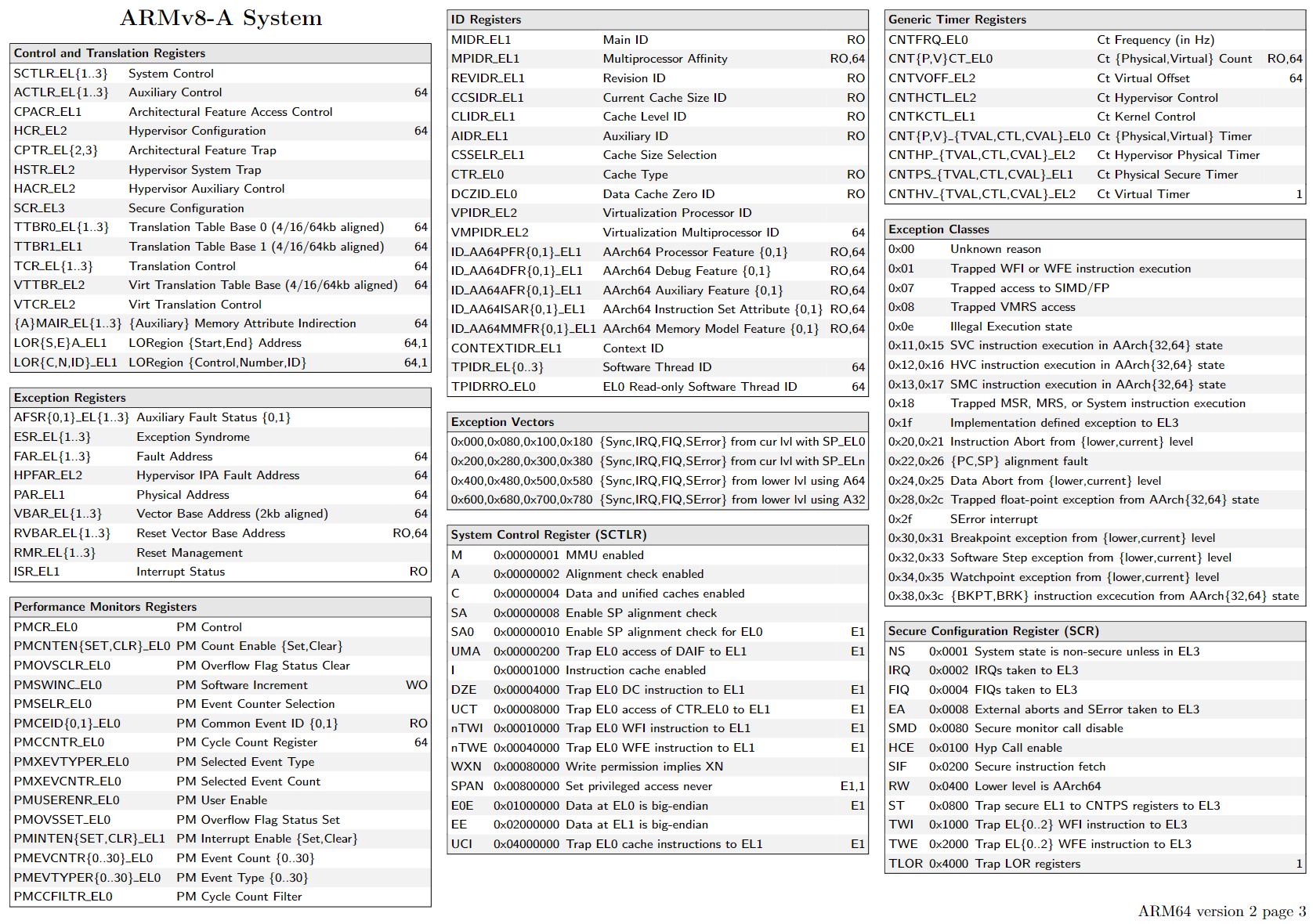
Arm A64 Instruction Set Architecture
https://modexp.wordpress.com/2018/10/30/arm64-assembly/
直接阅读文档 Arm® A64 Instruction Set Architecture
Armv8, for Armv8-A architecture profile最有效
read from ARMv8 Instruction Set Overview 4.2 Instruction Mnemonics
The container is one of: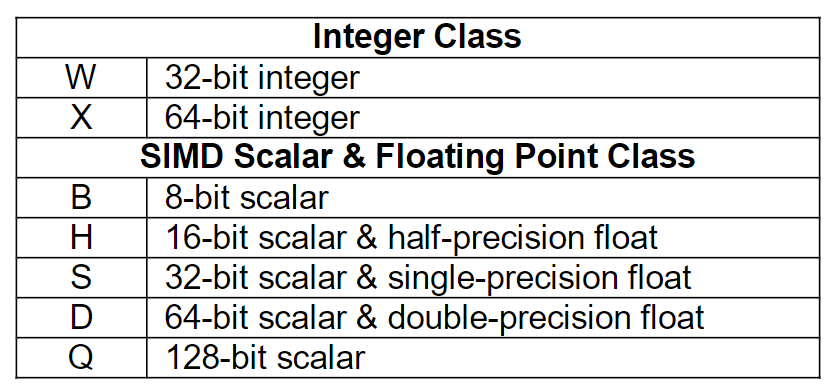
The subtype is one of: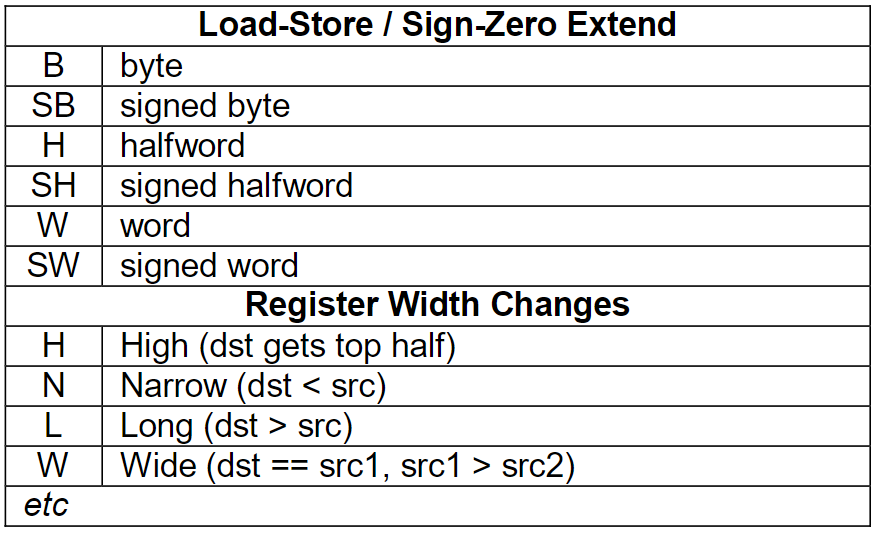
combine
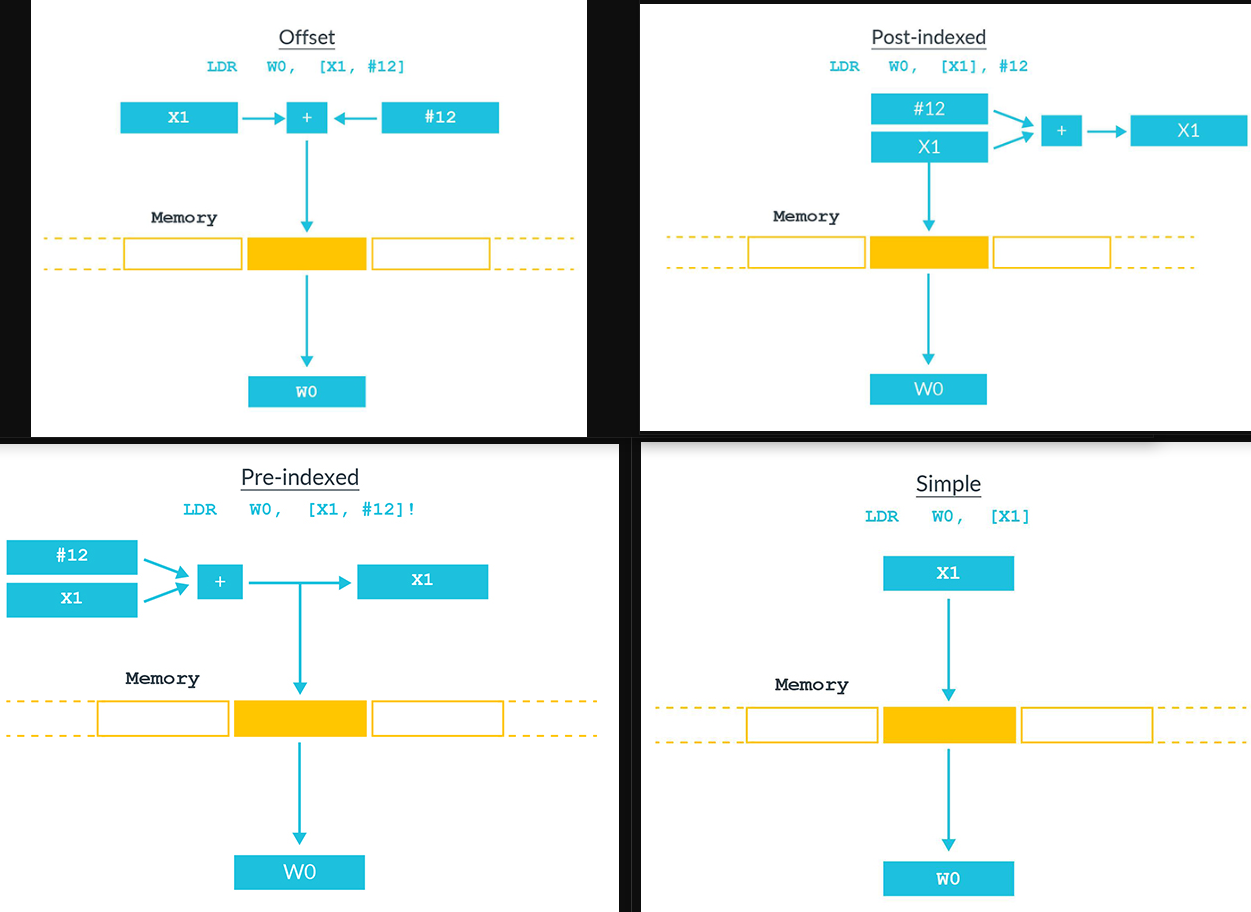
1 | <name>{<subtype>} <container> |
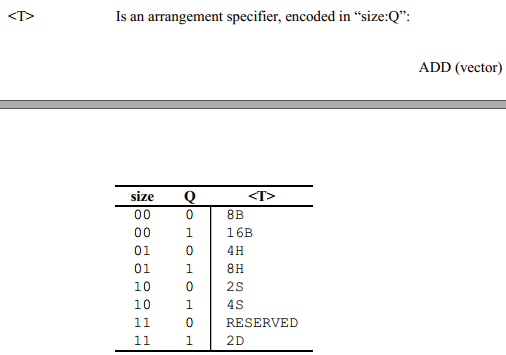
注意后缀的作用主体

官网查找指令: https://developer.arm.com/architectures/instruction-sets/intrinsics
https://armconverter.com/?disasm&code=0786b04e
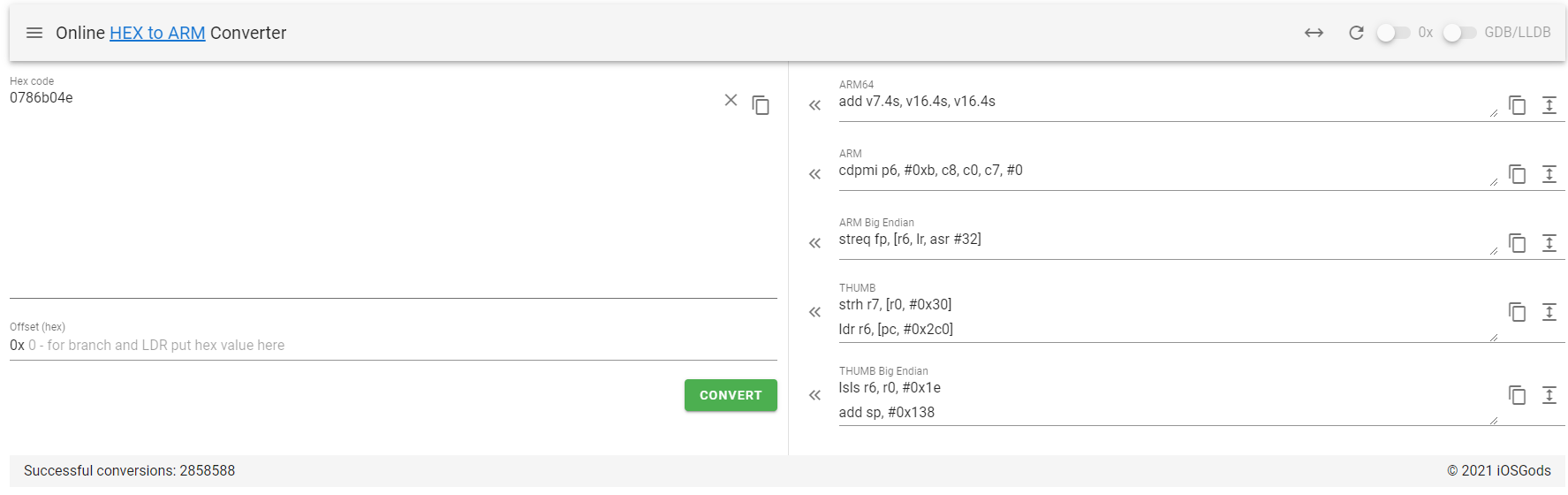
几乎每个指令都可以同时作用在不同寄存器和vector或者scalar上。比如add指令,并没有像X86一样设计vadd或者addps等单独
的指令,如果一定要区分,只能从寄存器是不是vector下手。
根据这个图,确实是有做向量操作的add,FADD是float-add的意思,ADDP是将相邻的寄存器相加放入目的寄存器的意思。不影响是标量scalar还是向量vector的操作。addv是将一个向量寄存器里的每个分量归约求和的意思,确实只能用在向量指令。
由于需要满足64或者128位只有下面几种情况
需要额外注意的是另外一种写法,位操作指令,不在乎寄存器形状shape
1 | # 128位and |
是同一个意思,但是不支持and v3.8h, v3.8h, v7.8h
1 | DUP //Duplicate general-purpose register to vector.or Duplicate vector element to vector or scalar. |
1 | add |
1 | ADRP // Form PC-relative address to 4KB page. |
1 | b.cond // branch condition eg. b.ne |
1 | ldrb // b是byte的意思 |
1 | ccmp // comdition compare |
1 | ASRV //Arithmetic Shift Right Variable |
1 | uxtb // zero extend byte 无符号(Unsigned)扩展一个字节(Byte)到 32位 |
1 | dmb //data memory barrier |
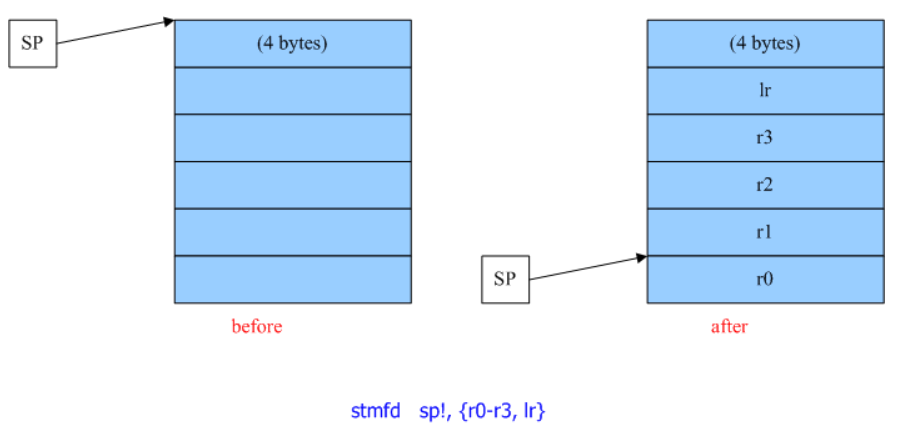
1 | PUSH {r3} |
are aliases for
1 | str r3, [sp, #-4]! |
暂无
暂无
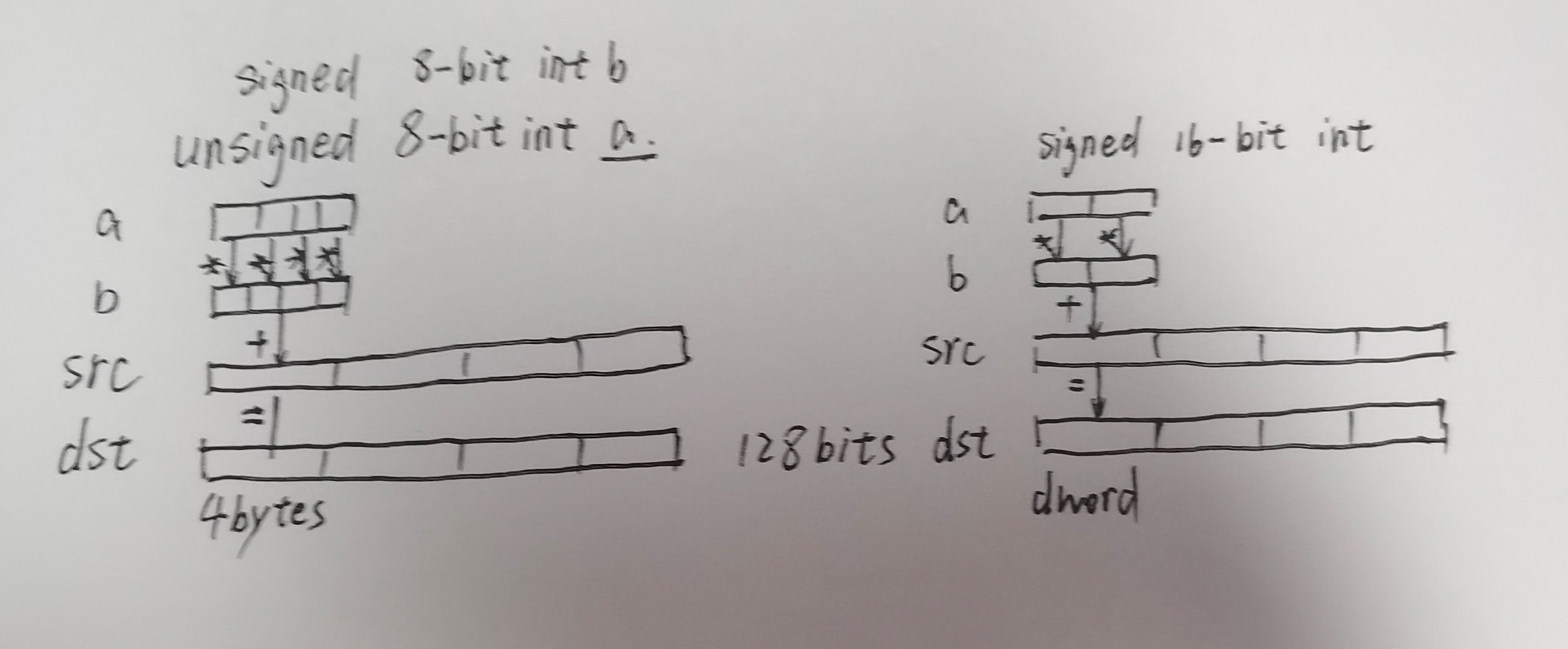
_mm_sin_ps intrinsic is a packed 128-bit vector of four 32-bit precision floating point numbers.The intrinsic computes the sine of each of these four numbers and returns the four results in a packed 128-bit vector.
AVX2在AVX的基础上完善了256位寄存器的一些实现
float-point multiply add/sub
include 128/256 bits regs
AVX-VNNI is a VEX-coded variant of the AVX512-VNNI instruction set extension. It provides the same set of operations, but is limited to 256-bit vectors and does not support any additional features of EVEX encoding, such as broadcasting, opmask registers or accessing more than 16 vector registers. This extension allows to support VNNI operations even when full AVX-512 support is not implemented by the processor.
1 | dpbusd //_mm_dpbusd_avx_epi32 |
有时间再看吧
current generation of Intel Xeon Phi co-processors (codename “Knight’s Corner“, abbreviated KNC) supports 512-bit SIMD instruction set called “Intel® Initial Many Core Instructions” (abbreviated Intel® IMCI).
Intel® Advanced Matrix Extensions (Intel® AMX) is a new 64-bit programming paradigm consisting of two components:
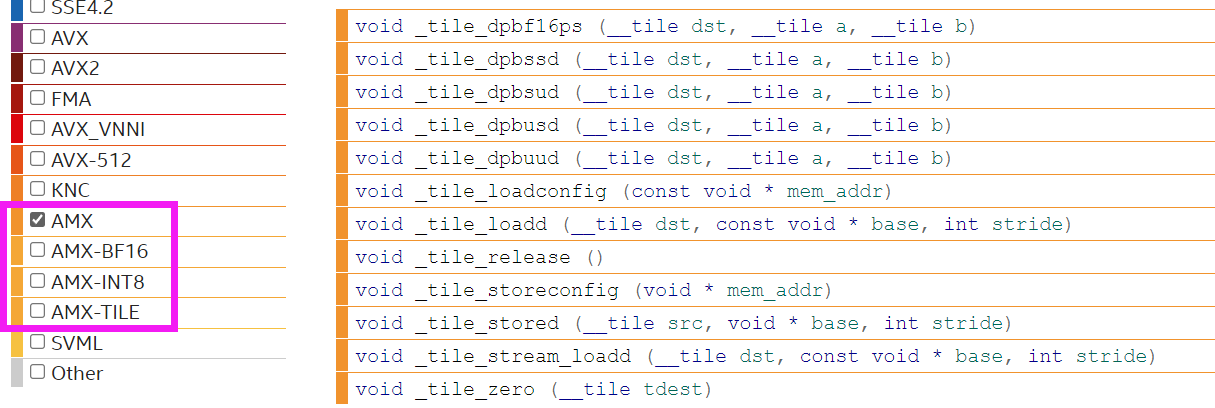
这个不适用于特殊矩阵和稀疏矩阵,这类一般先转换化简再SIMD
Short Vector Math Library Operations (SVML)
The Intel® oneAPI DPC++/C++ Compiler provides short vector math library (SVML) intrinsics to compute vector math functions. These intrinsics are available for IA-32 and Intel® 64 architectures running on supported operating systems. The prototypes for the SVML intrinsics are available in the immintrin.h file.
Using SVML intrinsics is faster than repeatedly calling the scalar math functions. However, the intrinsics differ from the scalar functions in accuracy.
暂无
暂无
The __m256 data type can hold eight 32-bit floating-point values.
The __m256d data type can hold four 64-bit double precision floating-point values.
The __m256i data type can hold thirty-two 8-bit, sixteen 16-bit, eight 32-bit, or four 64-bit integer values
1 | _mm512_mask_prefetch_i32extgather_ps |
1 | __m256i _mm256_loadu_epi32 (void const* mem_addr) //读入连续的256位数据,为32位int |
1 | _mm256_stream_pd // 跳过cache直接写入内存,但是需要对齐 |
1 | long long int vindexList = [0,2,4,6]; |
1 | __m256d _mm256_set_pd (double e3, double e2, double e1, double e0) // 设置为四个元素 |
1 | _mm256_hadd_epi16 // Horizontally add eg.dst[15:0] := a[31:16] + a[15:0] |
1 | _mm256_reduce_add_ph // 求和 |
1 | static const double DP_SIGN_One = 0x7fffffffffffffff; |
1 | _mm_bsrli_si128 // byte shift right |
1 | _mm_test_all_zeros |
向量化 取反、sqrt
1 | _mm256_cvtepi32_pd // Convert_Int32_To_FP64 |
1 | _mm256_cmp_pd // 按照double 32 bit 比较 |
1 | _mm256_blendv_pd // 根据mask结果,从a和b里选择写入dst |
1 | __m256d _mm256_undefined_pd (void) |
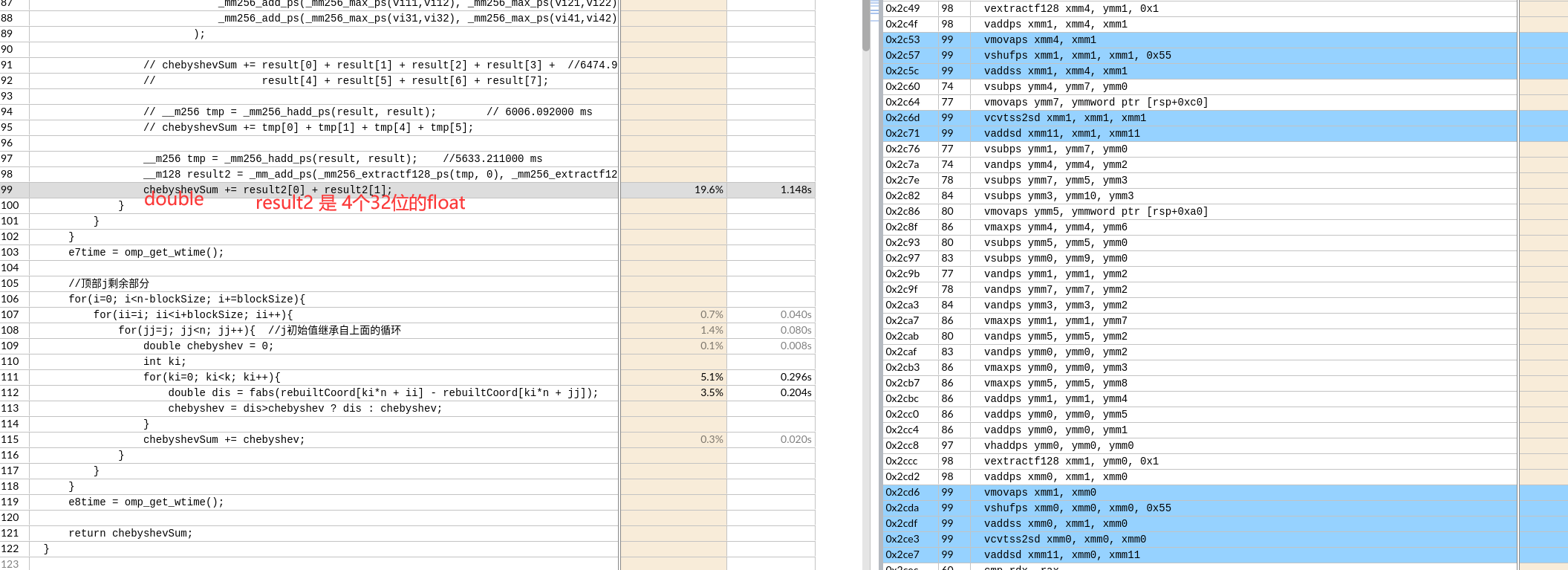
1 | Select4(SRC, control) { |
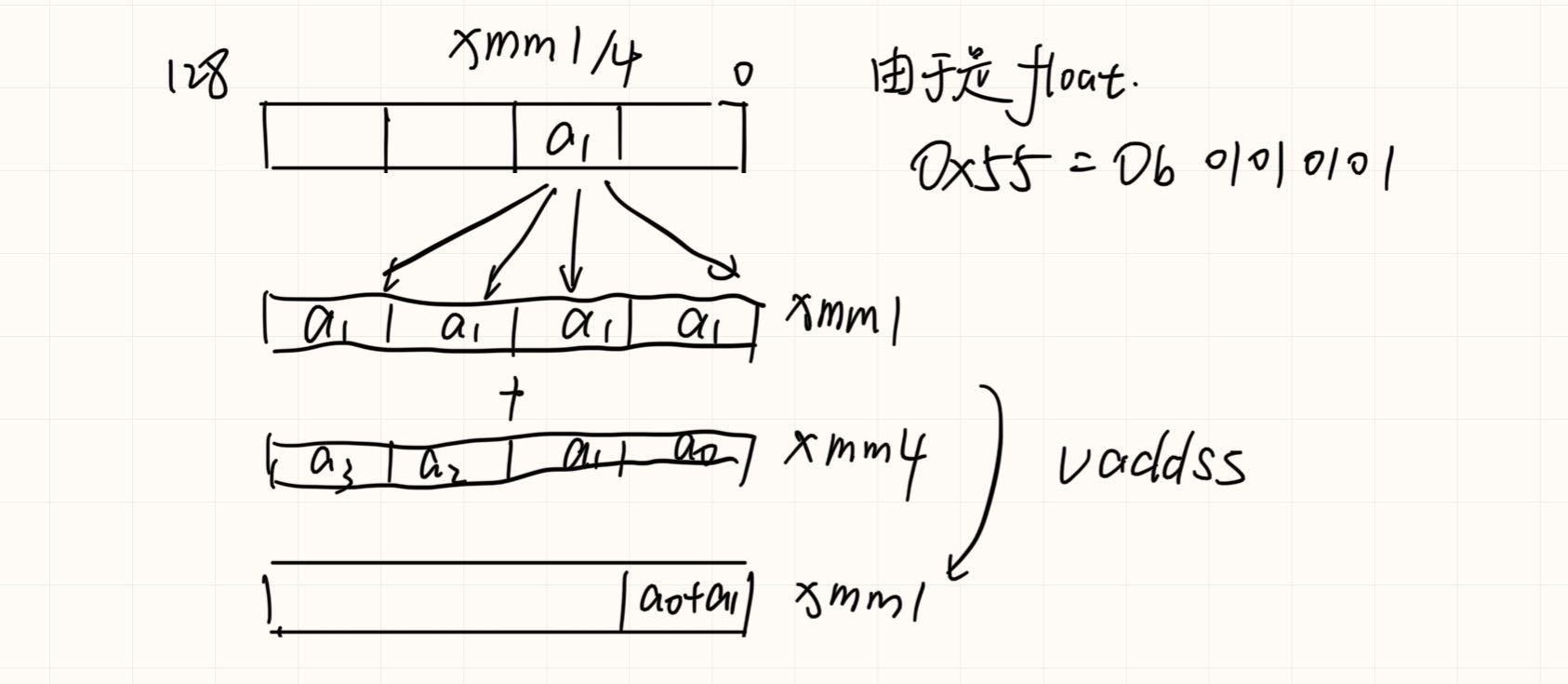
之后float类型转换为double,再求和。
暂无
暂无
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
通过使用矢量寄存器,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如 AMD的3D NOW!技术
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE为Streaming SIMD Extensions的缩写。Intel SSE指令通过128bit位宽的专用寄存器, 支持一次操作128bit数据. float是单精度浮点数, 占32bit, 那么可以使用一条SSE指令一次计算4个float数。注意这些SSE指令要求参数中的内存地址必须对齐于16字节边界。
SSE有8个128位寄存器,XMM0 ~XMM7。此外SSE还提供了新的控制/状态寄存器MXCSR。为了回答这个问题,我们需要了解CPU的架构。每个core是独占register的
addps xmm0, xmm1 ; reg-reg
addps xmm0, [ebx] ; reg-mem
sse提供了两个版本的指令,其一以后缀ps结尾,这组指令对打包单精度浮点值执行类似mmx操作运算,而第二种后缀ss

Advanced Vector Extensions。较新的Intel CPU都支持AVX指令集, 它可以一次操作256bit数据, 是SSE的2倍,可以使用一条AVX指令一次计算8个float数。AVX指令要求内存地址对齐于32字节边界。


根据参考文章,其中用gcc编译AVX版代码时需要加-mavx选项.
开启-O3选项,一般不用将代码改成多次计算和内存对齐。
1 | gcc -march=native -c -Q --help=target # 查看支持的指令集 |
c++函数在linux系统下编译之后会变成如下样子
1 | _ZNK4Json5ValueixEPKc |
在linux命令行使用c++filter
1 | $ c++filt _ZNK4Json5ValueixEPKc |
可以得到函数的原始名称, 展开后续追踪
1 | -Rpass=loop-vectorize |
1 | xmm 寄存器 |

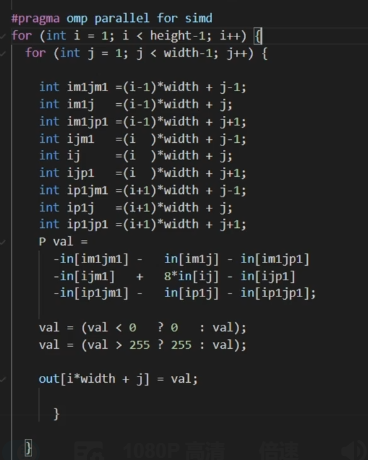
循环展开8次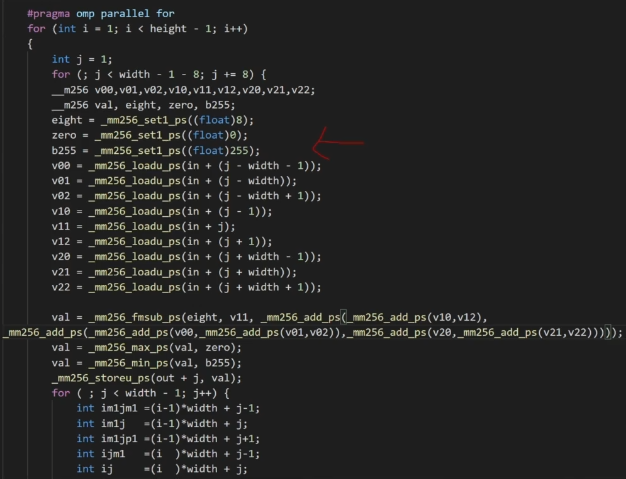
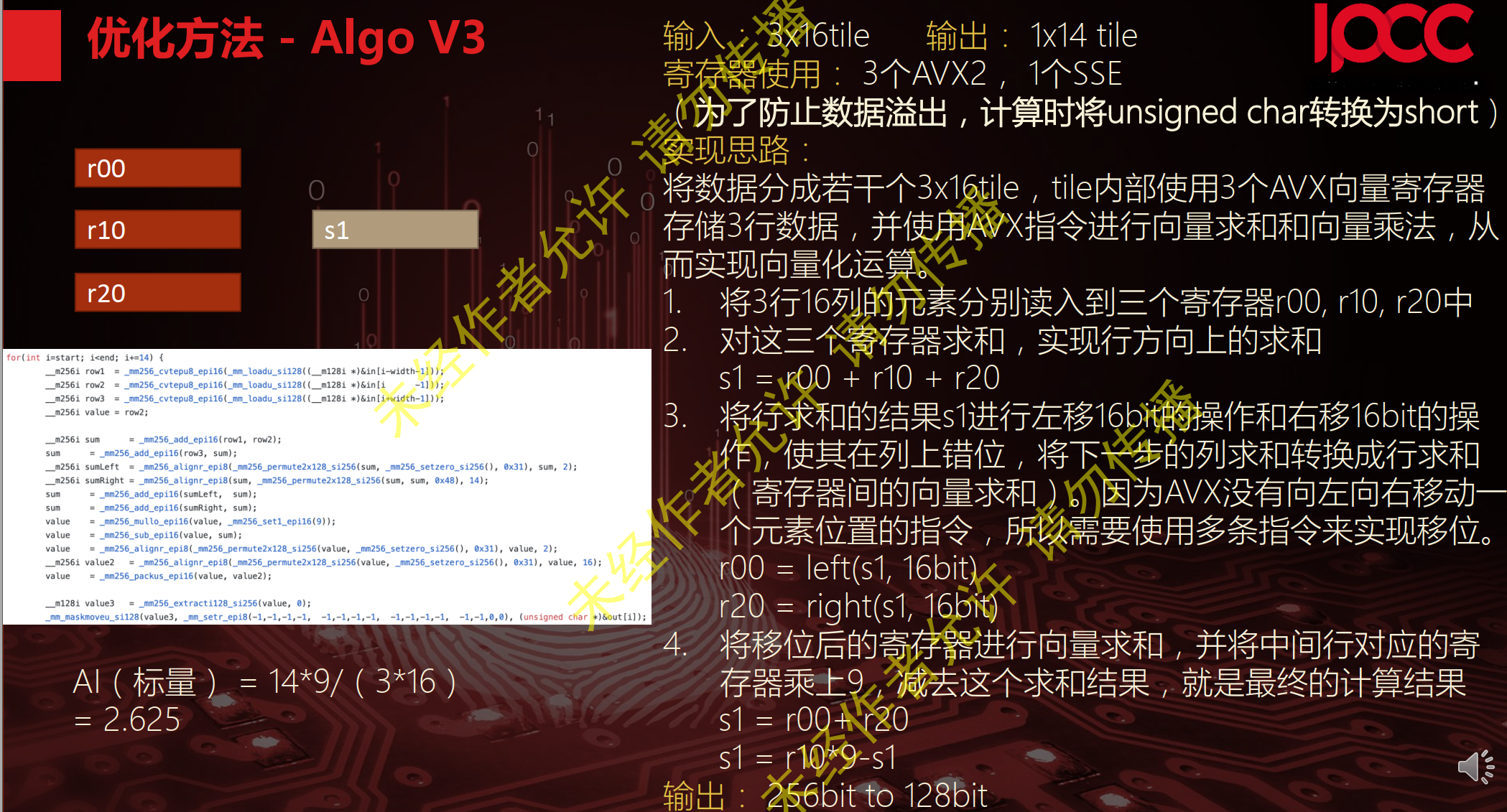
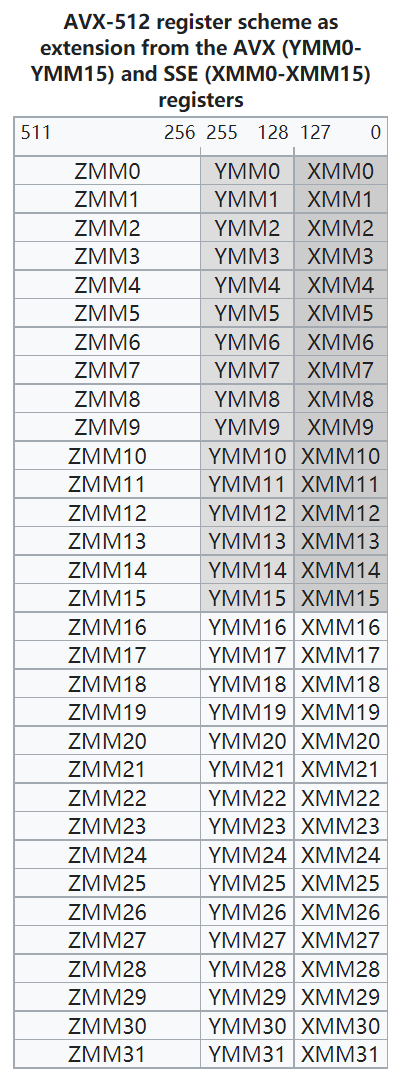
暂无
暂无
https://www.dazhuanlan.com/2020/02/01/5e3475c89d5bd/
https://software.intel.com/sites/landingpage/IntrinsicsGuide/