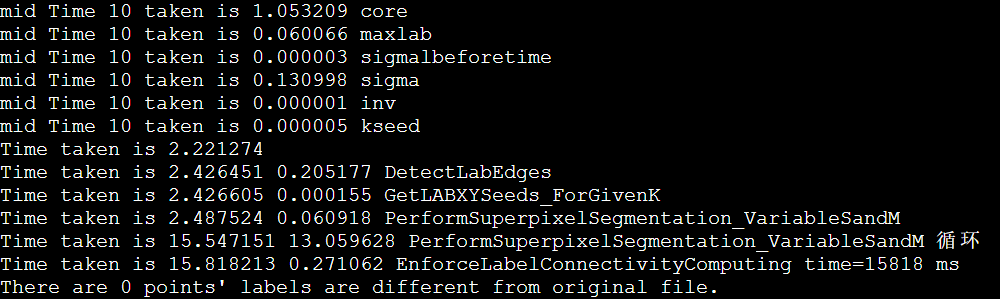
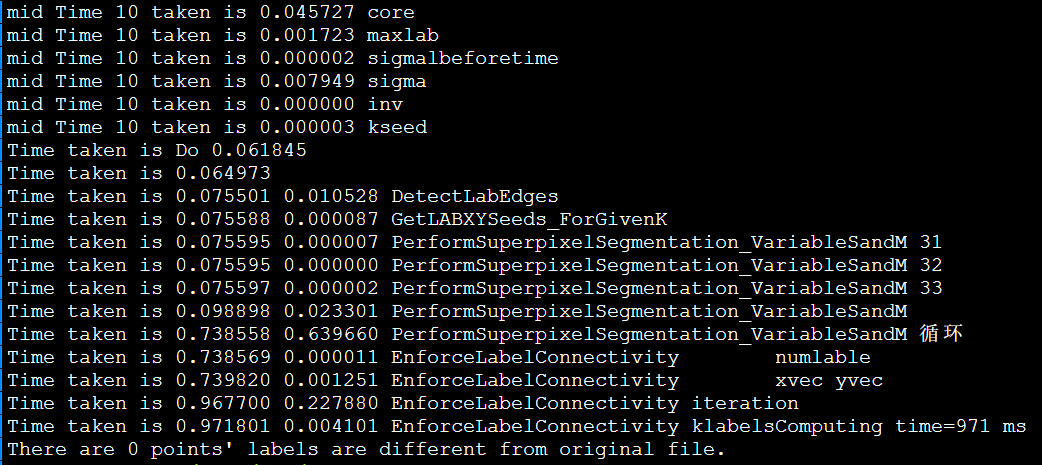
非阻塞MPI

MPI_Send & MPI_receive
MPI_AllTogether()更慢,需要4s
手动向量化对齐
debug
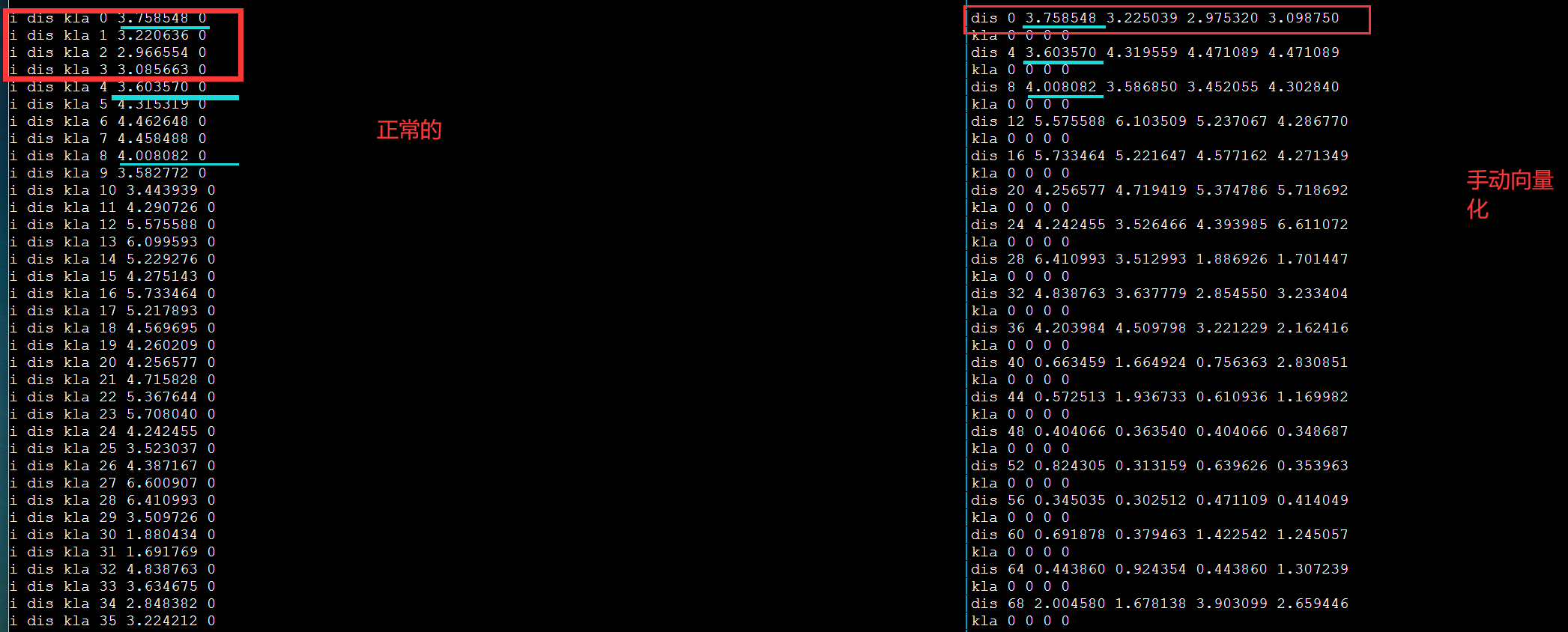
1 | vx = _mm256_set_pd(x); #改成 |
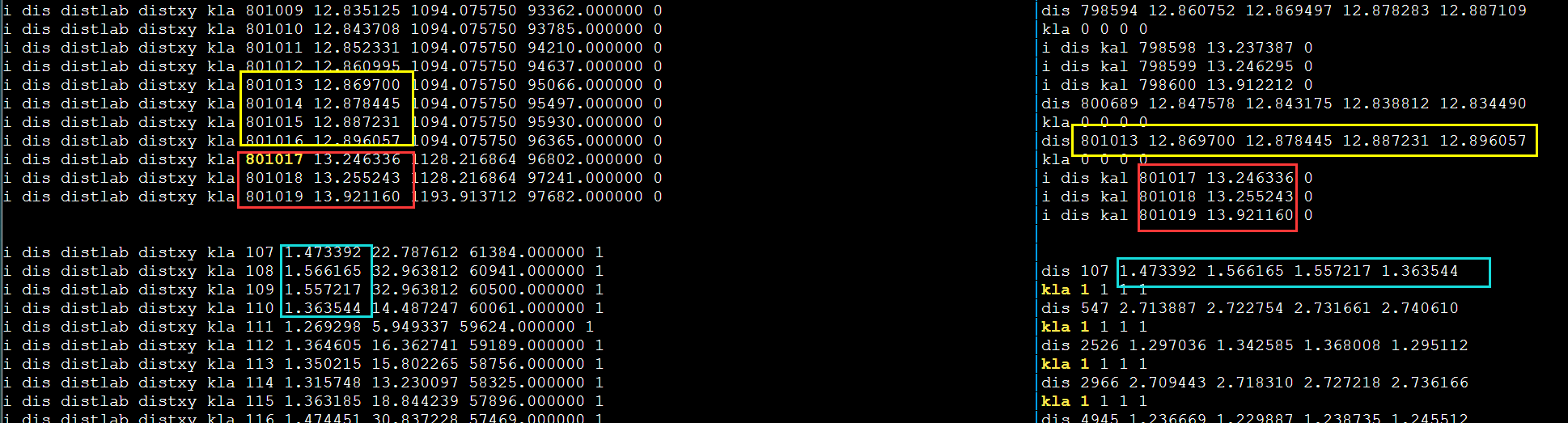

发现不对劲,打印更多输出。第一次循环肯定是对的因为和DBL_MAX比较。
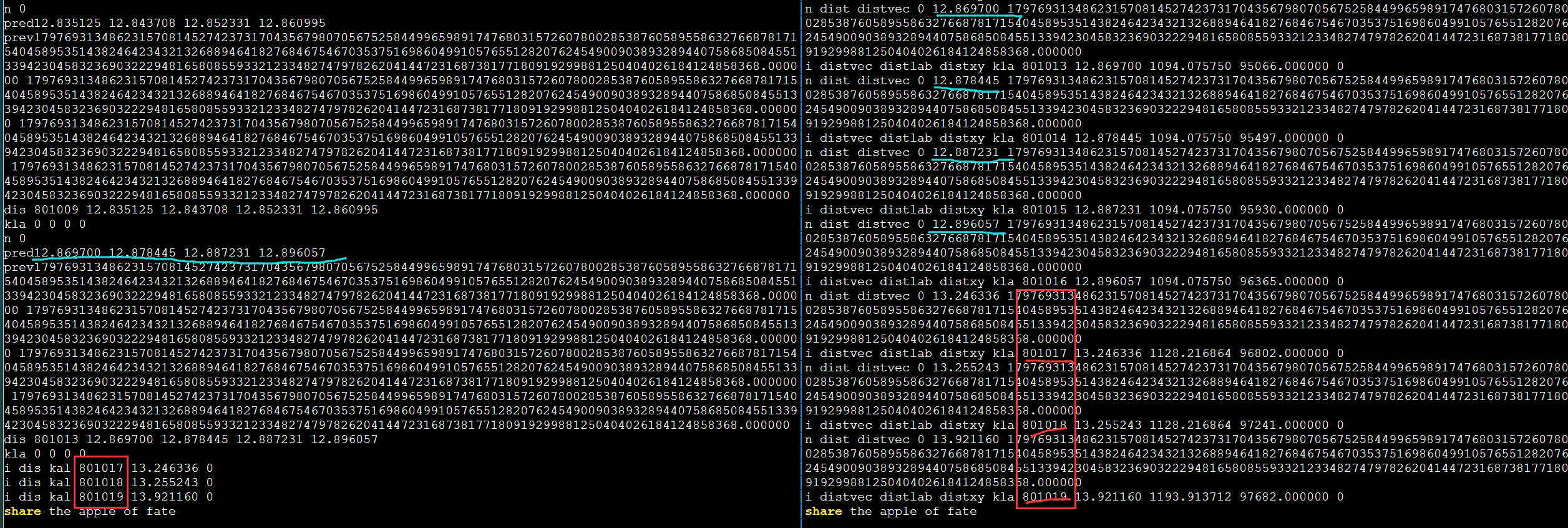

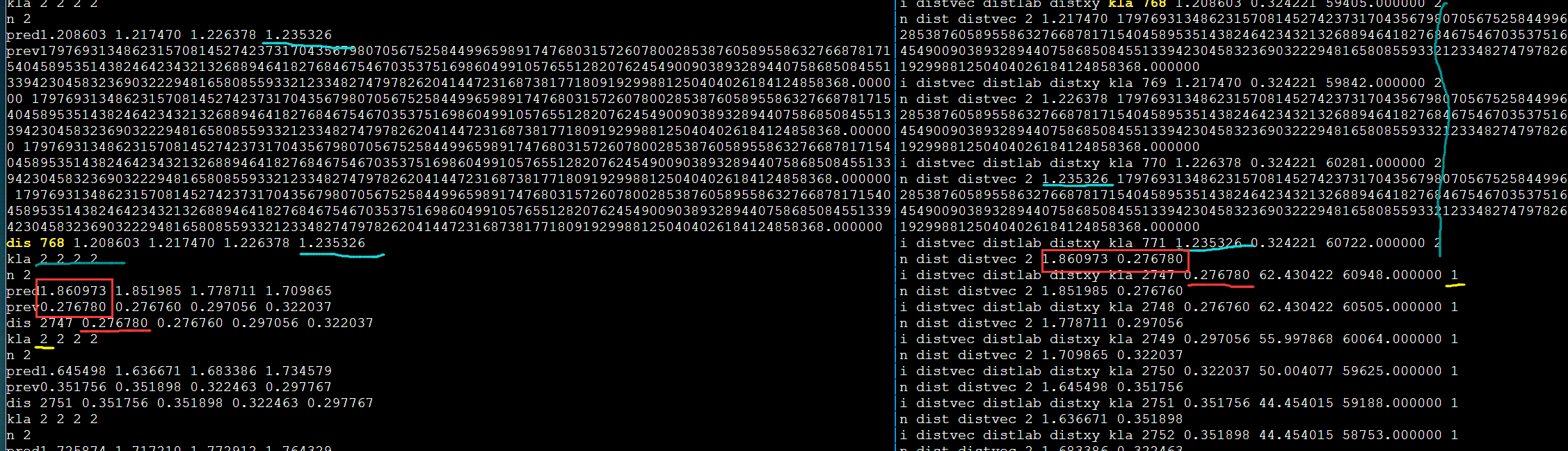
需要进一步的研究学习
为什么明明有56GB的IB网,传输速度还是这么慢呢?写比较慢?
7*8=56 8条通道
遇到的问题
暂无
Hybrid Multithreaded/OpenMP + MPI parallel Programs
https://www.nhr.kit.edu/userdocs/horeka/batch_slurm_mpi_multithread/ 看这个
还有个ppt 16
google hydrid openmpi openmp
这里值得要注意的是,似乎直接用mpif90/mpicxx编译的库会报错,所以需要用
icc -openmp hello.cpp -o hello -DMPICH_IGNORE_CXX_SEEK -L/Path/to/mpi/lib/ -lmpi_mt -lmpiic -I/path/to/mpi/include
其中-DMPICH_IGNORE_CXX_SEEK为防止MPI2协议中一个重复定义问题所使用的选项,为了保证线程安全,必须使用mpi_mt库
对于intel的mpirun,必须在mpirun后加上-env I_MPI_PIN_DOMAIN omp使得每个mpi进程会启动openmp线程。
通过export OMP_NUM_THREADS来控制每个MPI产生多少线程。
1 | shell$ ompi_info | grep "Thread support" |
“MPI_THREAD_MULTIPLE: yes”说明是支持的。
1 | #include <mpi.h> |
required 可选值 分别是0,1,2,3
1 | MPI_THREAD_SINGLE |
MPI_Init_thread调用MPI_thread_SINGLE等同于调用MPI_Init。
3.1.6的多线程支持还在初级阶段。开销很高(虽然我不知道为什么)
学习MapReduce或者Hadoop? pthread vs openmp?
暂无
IPCC Preliminary SLIC Optimization 5: MPI + OpenMP
| 技术路线 | 描述 | 总时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 161.7s s | 1 | |
| more3omp | 前面都是可以证明的有效优化 omp_num=32 | 14.08s | ||
| more3omp | 前面都是可以证明的有效优化 omp_num=64 | 11.4s | ||
| deletevector | 把sz大小的3个vector,移到全局变量,但是需要提前知道sz大小/声明一个特别大的 | 10.64s | 可以看出写成全局变量也不会影响访问时间 | |
| enforce_Lscan | IPCC opt 4 | 8.49s | 19 | |
| enforce_Lscan_MPI_intel | intel icpc | 3.8s | 42.36 | |
| Baseline2-max ppm | 1.2GB ppm 10*1024*40*1024 | 928s | ||
| enforce_Lscan | Baseline2 | 43.79s | 21.2 | |
| enforce_Lscan_MPI_intel | intel icpc + 双节点两个时间 + MPI(DoRGBtoLABConversion) | 18.8s / 20s | 46.4 | |
| enforce_Lscan_intel | intel icpc + 单节点 | 15.8s | 58.74 | MPI(DoRGBtoLABConversion)负优化了2s |
| manualSIMD | 13.9s | |||
| stream | 13.6s | |||
| vec2mallocOMP | 11.0s | |||
| mmap | 10.6s | |||
| + -O3 | enforce_Lscan_intel | 16.2s | ||
| + -xHost | 结果不对 | 17.8s | ||
| -Ofast | 16.9s | |||
| -ipo | 15.9s | |||
| -O3 -ipo | 16.8s | |||
| -O3 -march=core-avx2 -fma -ftz -fomit-frame-pointer | 16.0s | |||
| g++ suggested options | -O3 -march-znver1 -mtune=znver1 -fma -mavx2 -m3dnow -fomit-frame-pointer | 18.1s | ||
| g++ suggested options2 | -O3 -march-znver2 -mtune=znver2 -fma -mavx2 -m3dnow -fomit-frame-pointer | 19.79s | ||
| g++ -Ofast | 16.9s | |||
| aocc -Ofast | 16.3s | |||
| aocc suggested options | 16.2s |
由于是打算两节点两进程MPI,虽然没有OpenMP的共享内存,但是也希望通信能少一点。
下面关于同步区域的想法是错误的:
因为中心点移动会十分不确定,所以全部同步是最好的。
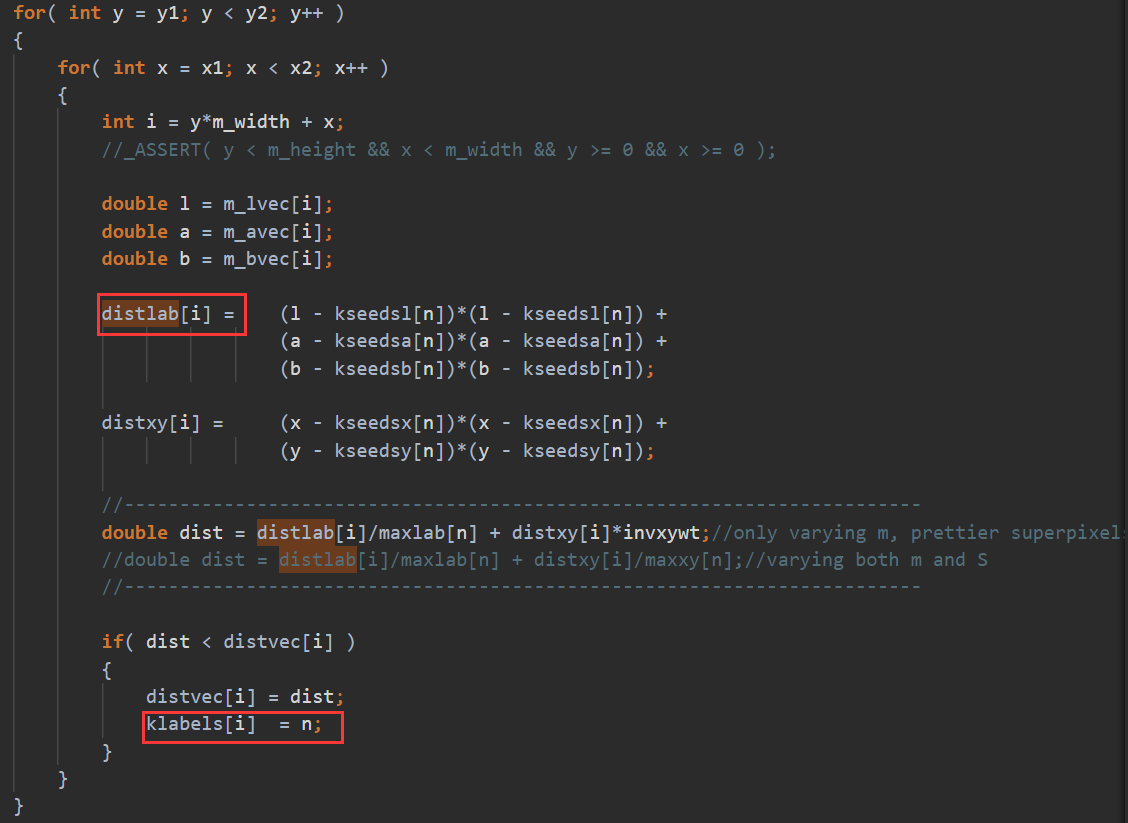

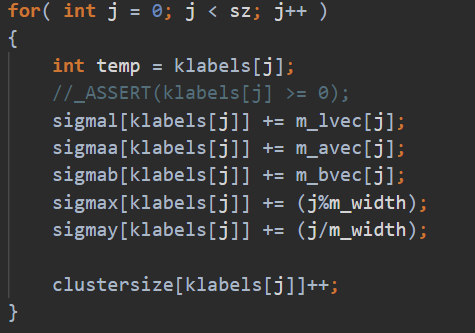
用MPI_Send写,但是一开始没注意是阻塞的,但是为什么这么慢呢?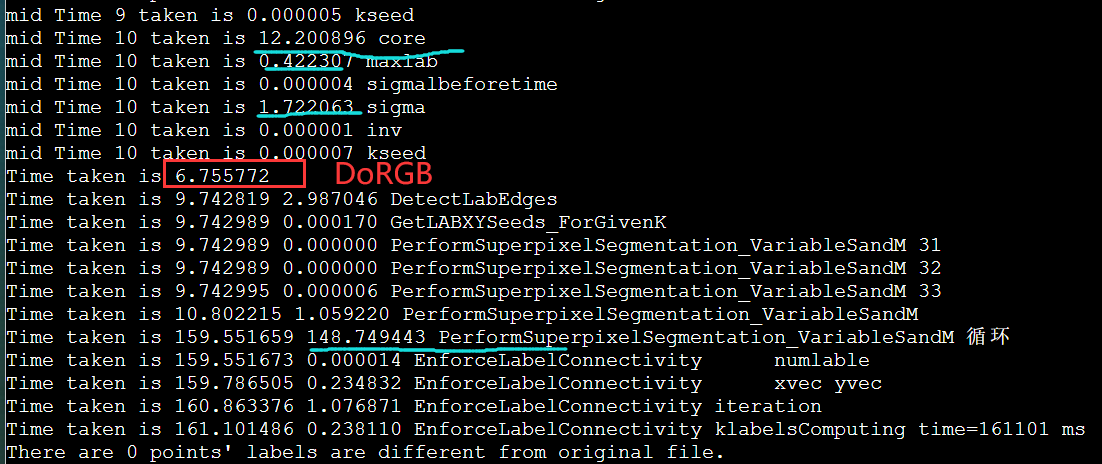
慢了10~20倍猜测:
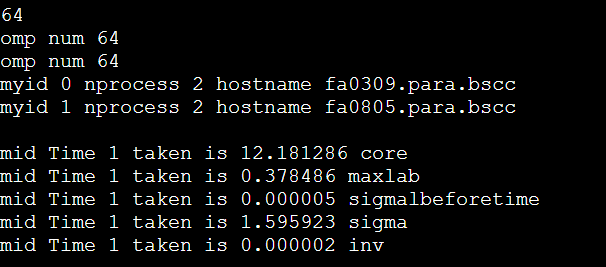
好像是openmp没正常运行omp_num的值为 1,32,64时间都一样。感觉是混合编程的编译问题, 而且好像是假Openmp并行,哪里有锁的样子。突然想起来,Quest的混合变成cmake需要打开multthread类似的支持,但是这里并没用。
好像也不是mpi_init_thread的问题
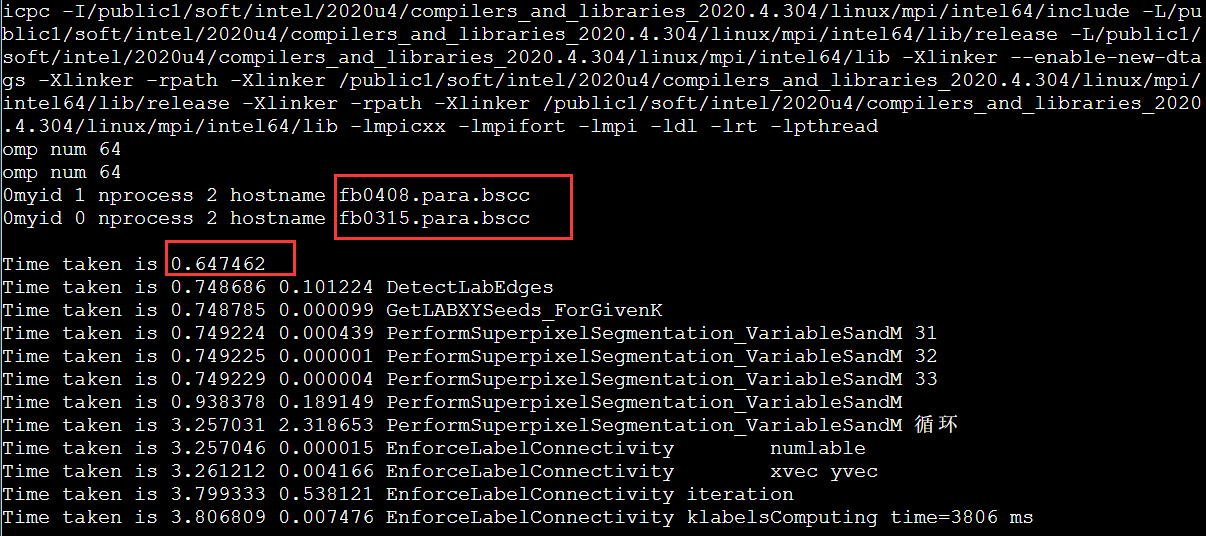
果然有奇效。(结果是对的,后面我没截图了)。看到这里,可能你会觉得这个问题是OpenMPI有地方不支持openmp。但是后面有神奇的事情,如果NODELIST是fa,而不是fb就不能跑,会直接卡住。😰
首先没找到官方手册说明不同,然后研究一下这两个分区的不同。好吧从IB,cpu,内存都没区别。
限制nodelist再跑一遍。
加上打印时间,用fb分区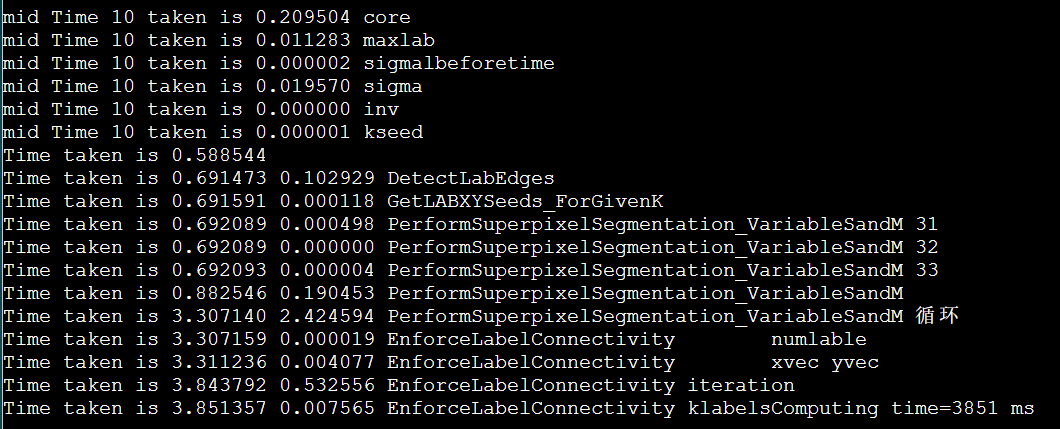
这个问题又没有了,但是fa分区由于经常跑可能会热一些。
由于时间已经进5s了。所以我们需要更大的例子,再讨论2节点的开销收益,之前的例子是256034000。
这里生成了1024040960的ppm.再大ppm程序的数组都申请不到栈空间了,需要重新数据结构。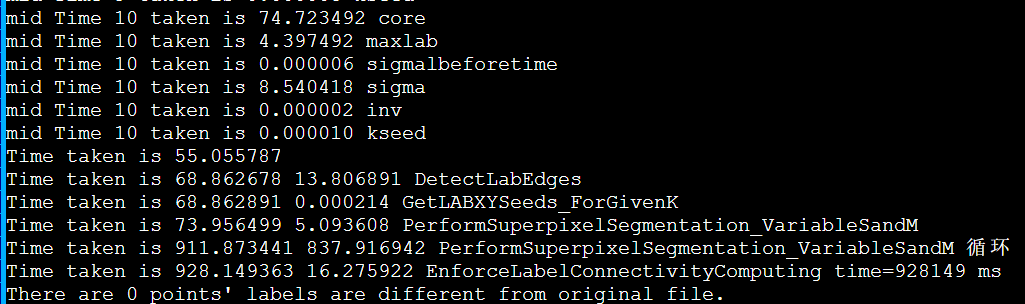
重跑当前最快的enforce_Lscan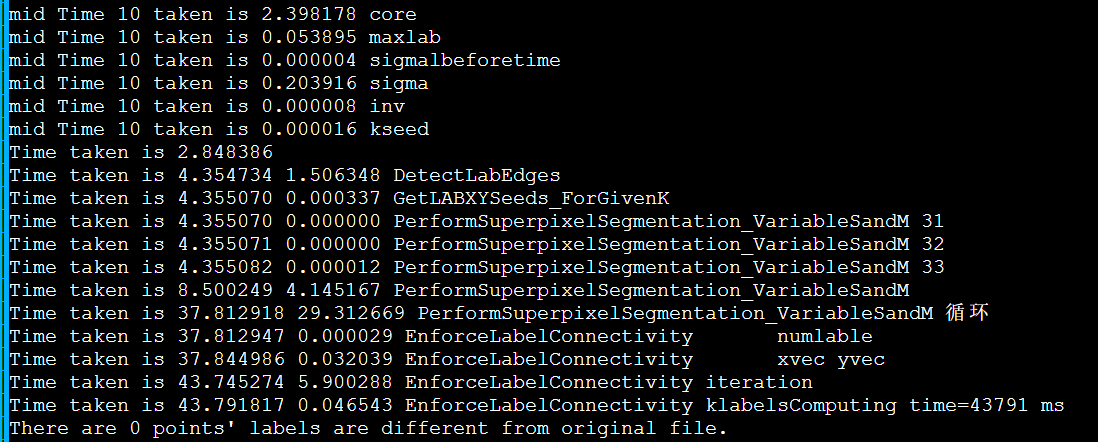
icpc + enforce_Lscan_MPI(DoRGBtoLABConversion)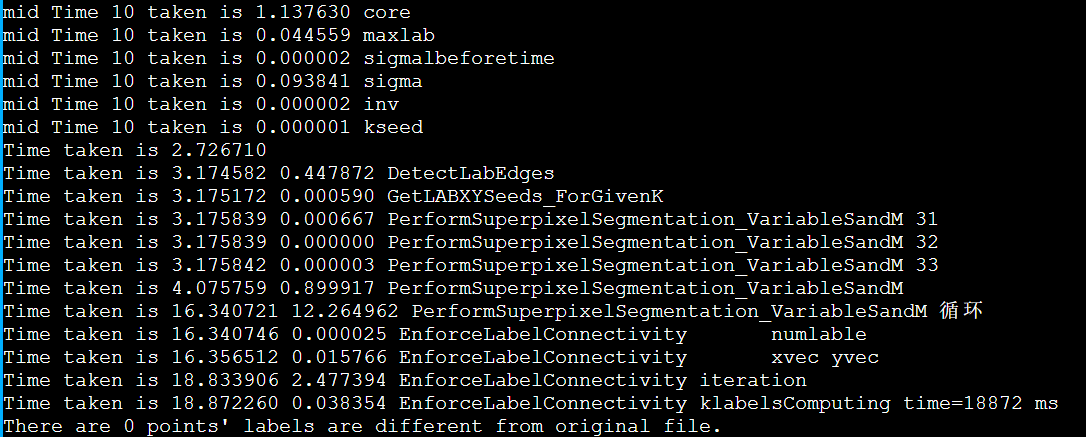
icpc + enforce_Lscan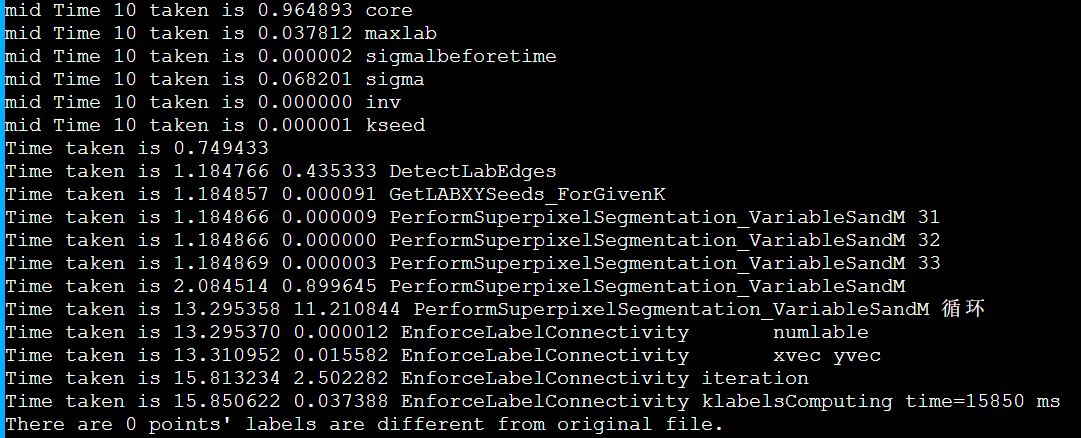
g++ suggested options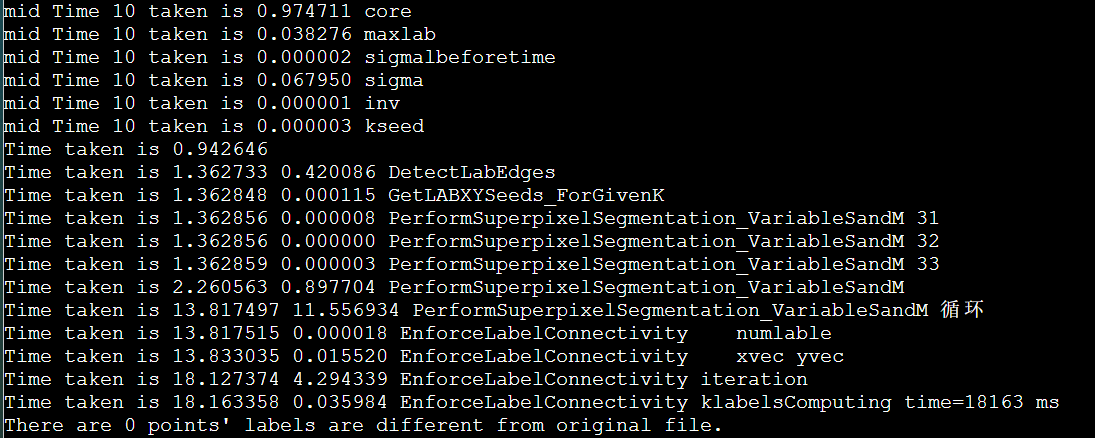
icpc + manualSIMD + lessLscan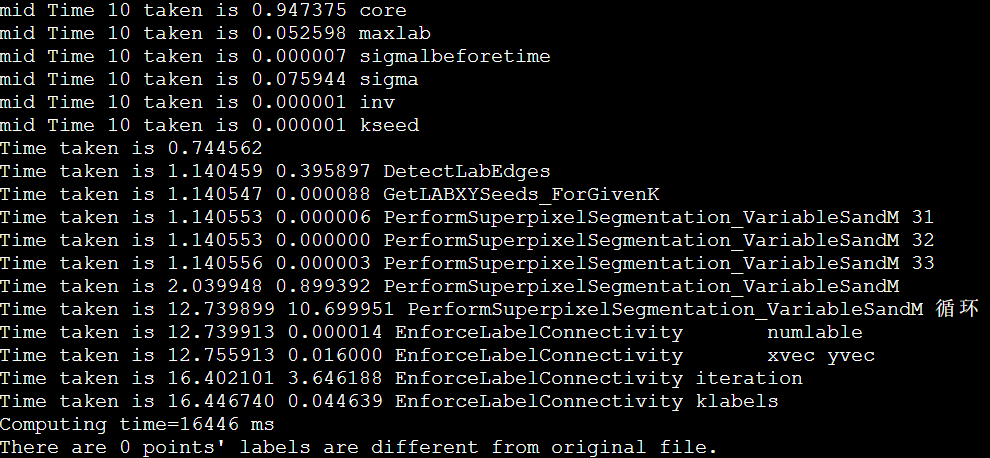
icpc + manualSIMD + LscanSimple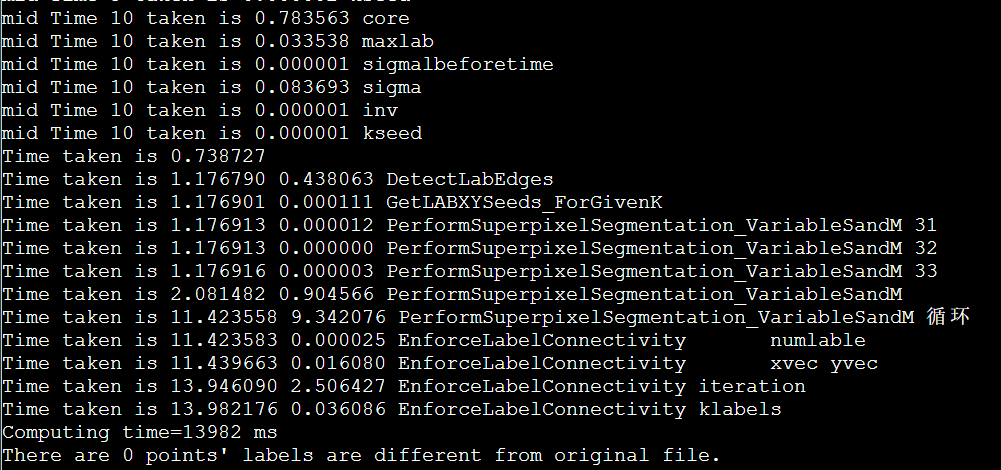
icpc + manualSIMD + LscanSimple + stream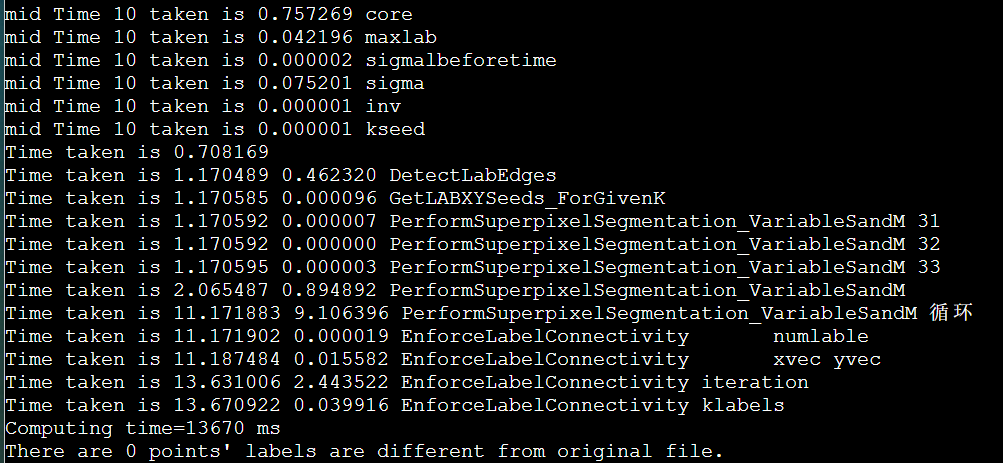
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit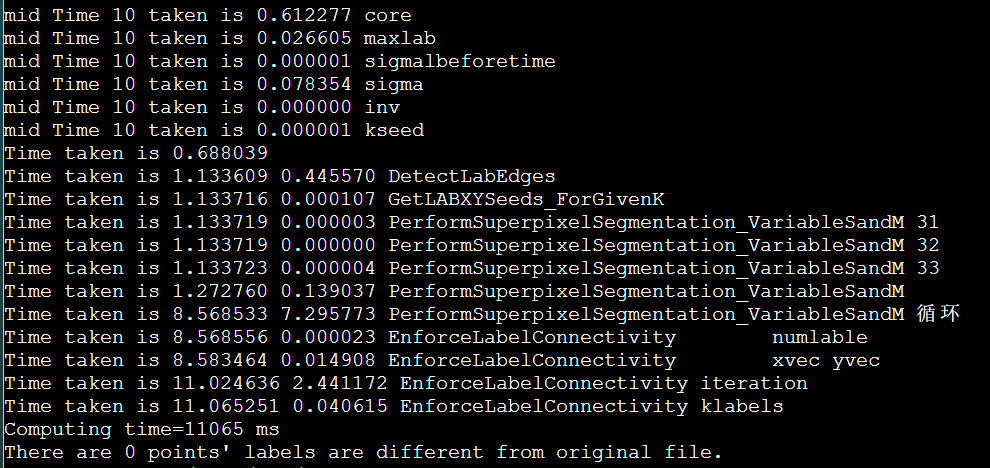
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap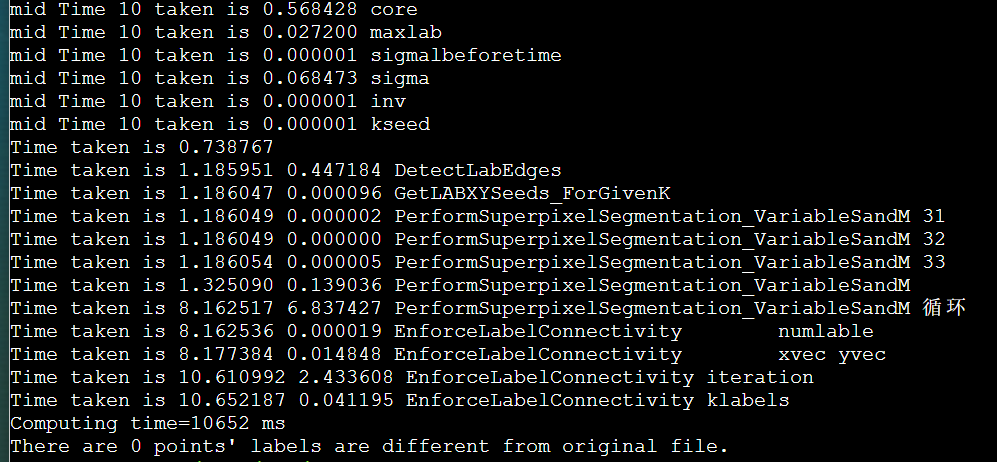
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap + unrollLoop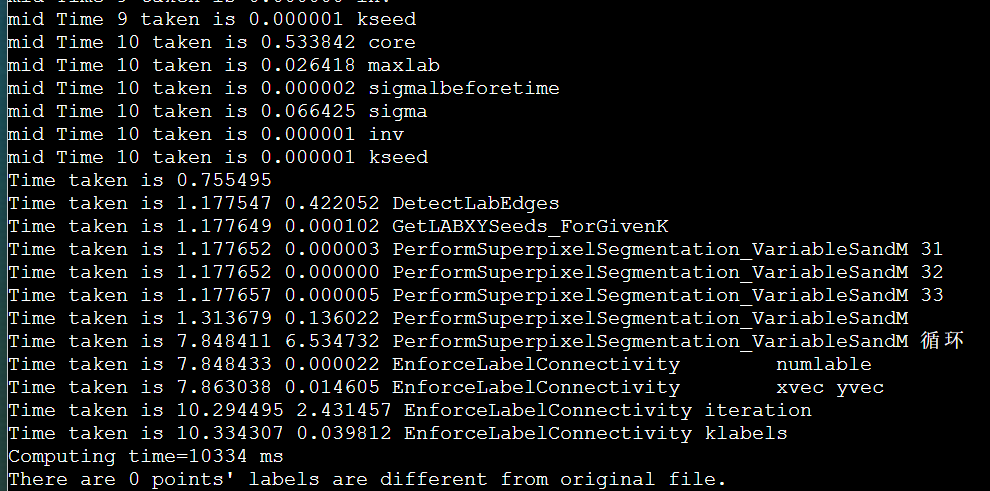
https://www.bilibili.com/video/BV1a44y1q782 58mins-58min50s
暂无
无
IPCC Preliminary SLIC Optimization 4: EnforceLabelConnectivity
| 技术路线 | 描述 | 总时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 207 s | 1 | |
| more3omp | 0.4+5+0.3 | 23.0s | ||
| 时间细划,初始化omp | 0.03+5+0.1 | 21.2s | ||
| 不换算法,必须加锁 | 特别满 | |||
| 扫描行算法 | 0.03+2.2+0.1 | 18.5s | ||
| 扫描行算法 + task动态线程池 | 26s | |||
| 扫描行算法 + task动态线程池 + 延迟发射 | 26s | |||
| 扫描行算法 + task动态线程池 + 延迟发射 | 26s | |||
| 扫描行算法 + 化解重复,提高粒度:每个线程一行,不同线程杜绝同一行扫描行算法 | 但是没并行起来 | 106s | ||
| 扫描行算法 + 常驻64线程 | 86s |
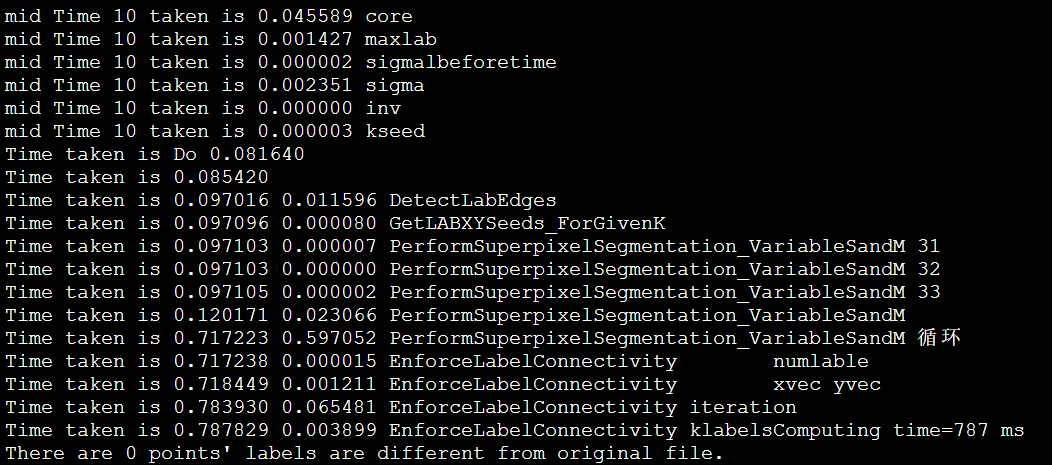
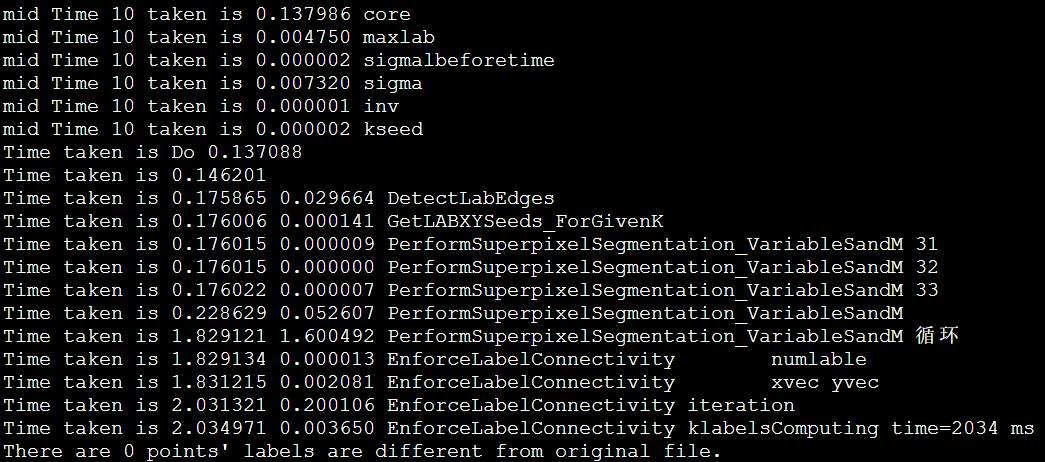
1 | Time taken is 21.364595 6.066717 EnforceLabelConnectivityComputing |
细致划分,malloc size大小的空间不耗时,是初始化为-1耗时
1 | Time taken is 16.963094 0.000025 EnforceLabelConnectivity numlable |
修改后
1 | Time taken is 16.063057 0.000026 EnforceLabelConnectivity numlable |
但是可能会导致adjlabel的值不对,导致结果不对
4分钟+, 满核结束不了,已经混乱了。
5分钟+,满核结束不了,大翻车。
可能的原因:
我又想到是不是只有一个锁,有没有多个锁的实现。还是超时结束不了。
1 | omp_set_lock(&lock[nindex]); //获得互斥器 |
多个锁满足了nlabels的竞争,但是count的竞争还是只能一个锁。除非将数组保存变成队列才有可能,因为没计数器了。
好耶,segmentation fault (core dumped)。果然读到外面去了。
不好耶了,并行的地方加了锁,还是会
1 | double free or corruption (out) //内存越界之类的 |

200~400行不等seg fault。
然后我打了时间戳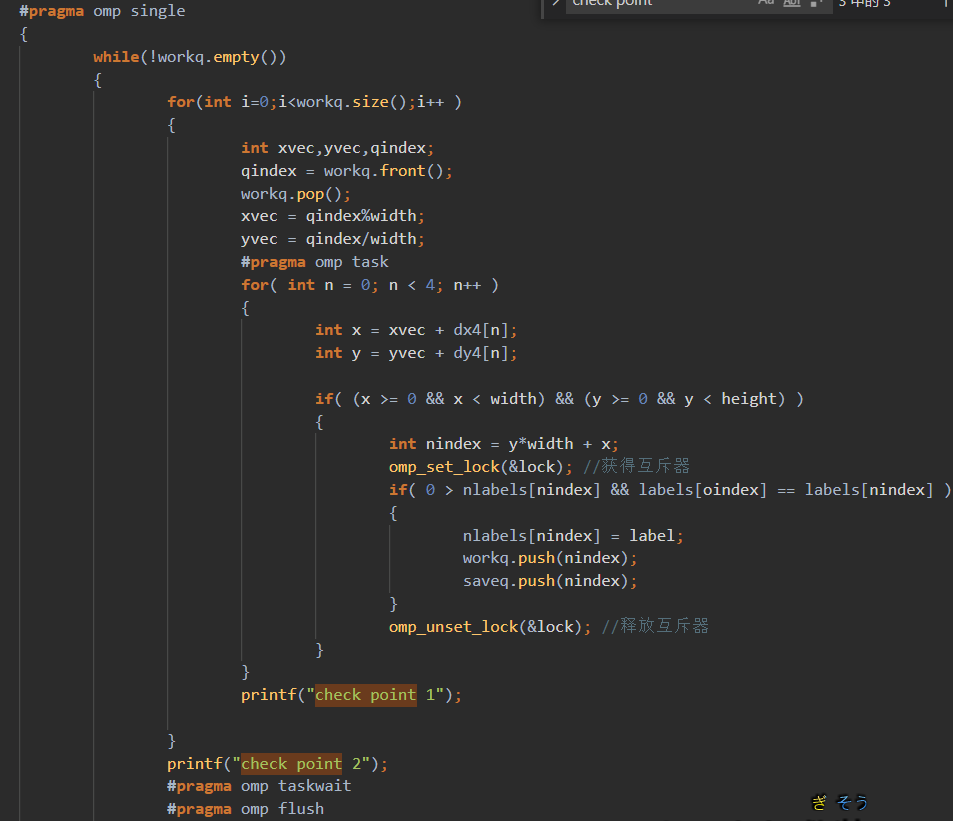
可以看出至少前面是正常的。
多运行几次,有时候segfault,有时corruption,我服了。
但是位置好像还是在上面的循环
每次报错位置还不一样,但是迭代的点还是对的。
https://stackoverflow.com/questions/32227321/atomic-operation-on-queuet
1 | munmap_chunk(): invalid pointer |
黑人问号?纳尼
没办法,只能加锁,读取,写入都加锁,但是就是特别慢,4分钟+。
1 | omp_set_lock(&lock); //获得互斥器 |
读取,写入不是同一个队列,尝试用2个锁,还是特别慢,5分钟根本跑不完。
q.front()变成了q.top()
扫描线算法至少比每像素算法快一个数量级。
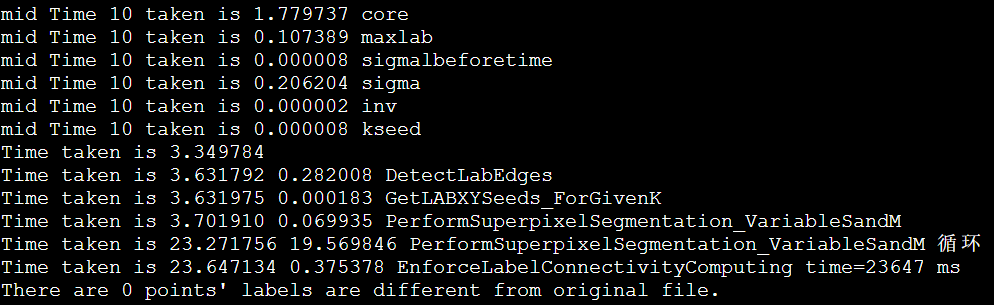
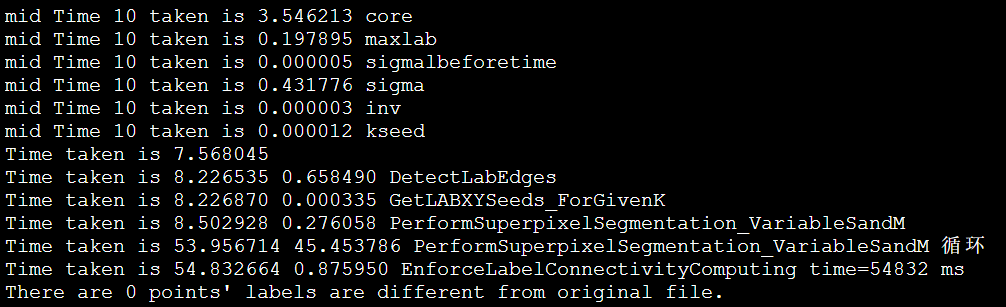
1 | Time taken is 16.144375 13.062605 PerformSuperpixelSegmentation_VariableSandM 循环 |
不知道哪里错了,需要debug。简单debug,发现小问题。
1 | Time taken is 15.670141 0.000024 EnforceLabelConnectivity numlable |
但是尴尬的是并没有快。哭哭哭~~~~。
优化一下变量,快了3秒,大胜利!!!
1 | Time taken is 16.203514 0.000029 EnforceLabelConnectivity numlable |
虽然我在总结里写了,很难控制。但是,哎,我就是不信邪,就是玩😉
喜提segfault,打印task调用,发现task从上到下,之字形调用,而且没用一个结束的。按照设想,横向x增加比调用task快的,现在好像task堵塞的样子。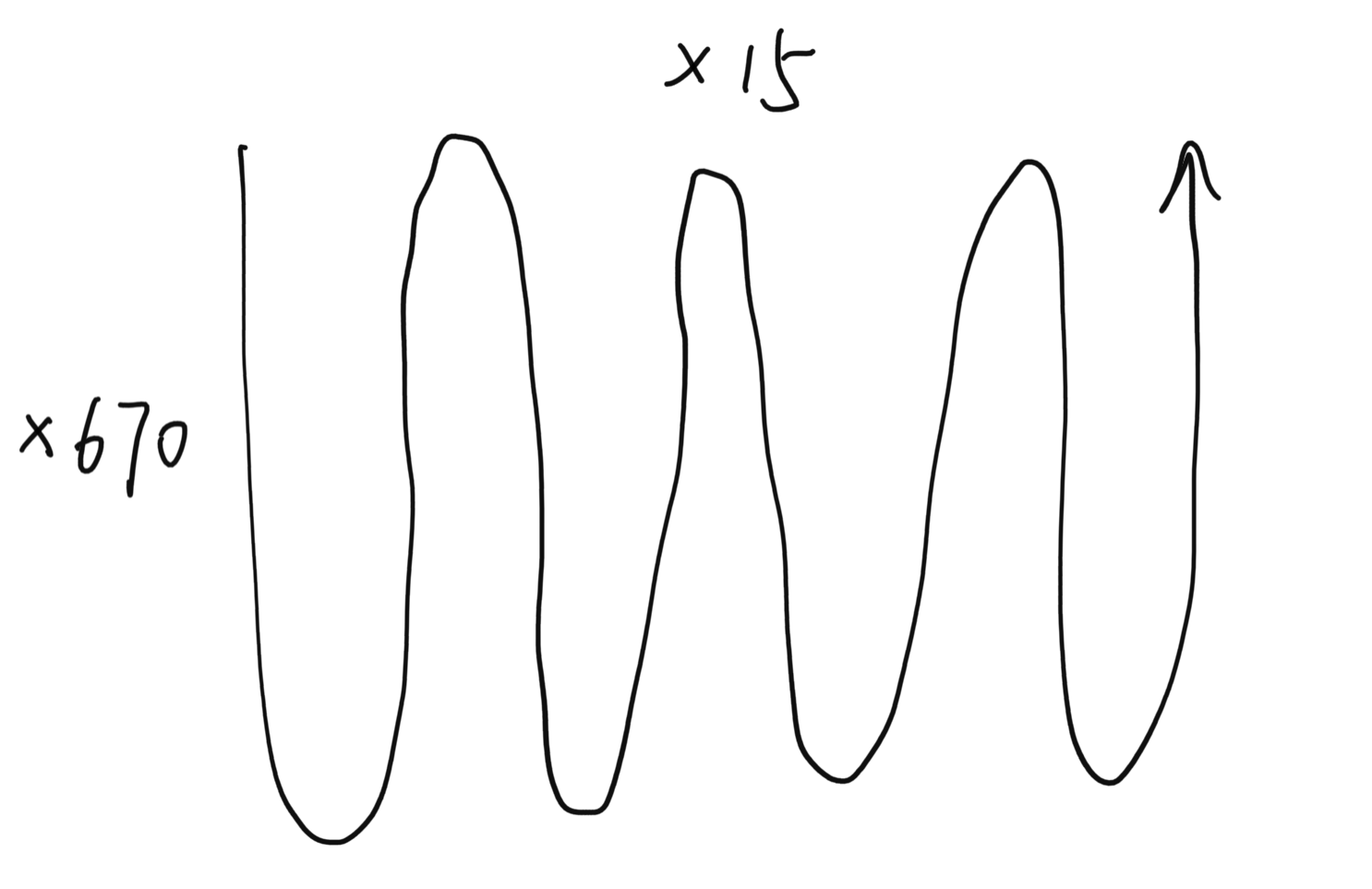
好像是没加,但是结果不对
1 | #pragma omp parallel num_threads(64) |
让我们仔细分析一下是怎么偏离预期的: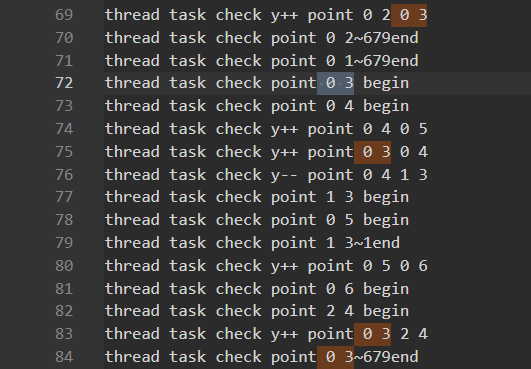


尝试把占用时间的print去掉。时间不短(重复调用),还是错的。(后面才发现,错误是threadcount,threadq里,每次循环完忘记清空了。日~~~)
1 | Time taken is 16.226124 0.000024 EnforceLabelConnectivity numlable |
现在的想法是要有先后顺序,把对(x,y)一行都处理完,再发射task。或者采取延迟发射的。
1 | Time taken is 17.344073 0.000027 EnforceLabelConnectivity numlable |
很奇怪,结果不对。难道是delay的值太小。
把delay的值从10调整到750,甚至是2600,大于宽度了,结果还是不对。这是不对劲的,因为这时相当于把对(x,y)一行都处理完,再发射task。
这时我才感觉到是其他地方写错了,错误是threadcount,threadq里,每次循环完忘记清空了。日~~~
delay = 2600 结果是对了,但是也太慢了,至少要比串行快啊?
1 | Time taken is 15.538704 0.000026 EnforceLabelConnectivity numlable |
delay = 20 快了一点,哭
1 | Time taken is 15.631368 0.000025 EnforceLabelConnectivity numlable |
打上时间戳
1 | end Time 84 32839 taken is 0.000000 dxy4 |
说明还是并行没写好。
检查是否调用64核,htop显示是64核
猜测原因
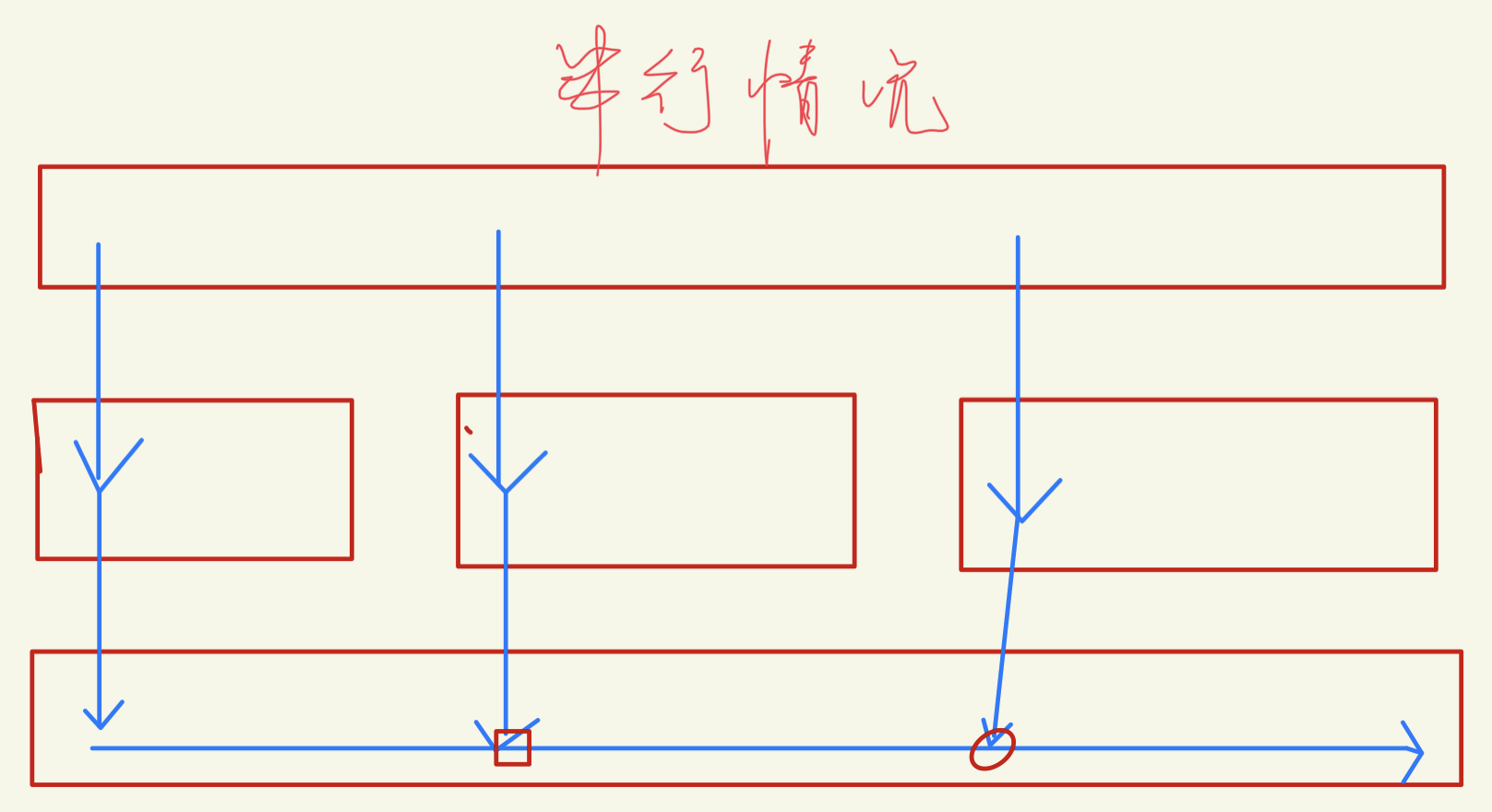
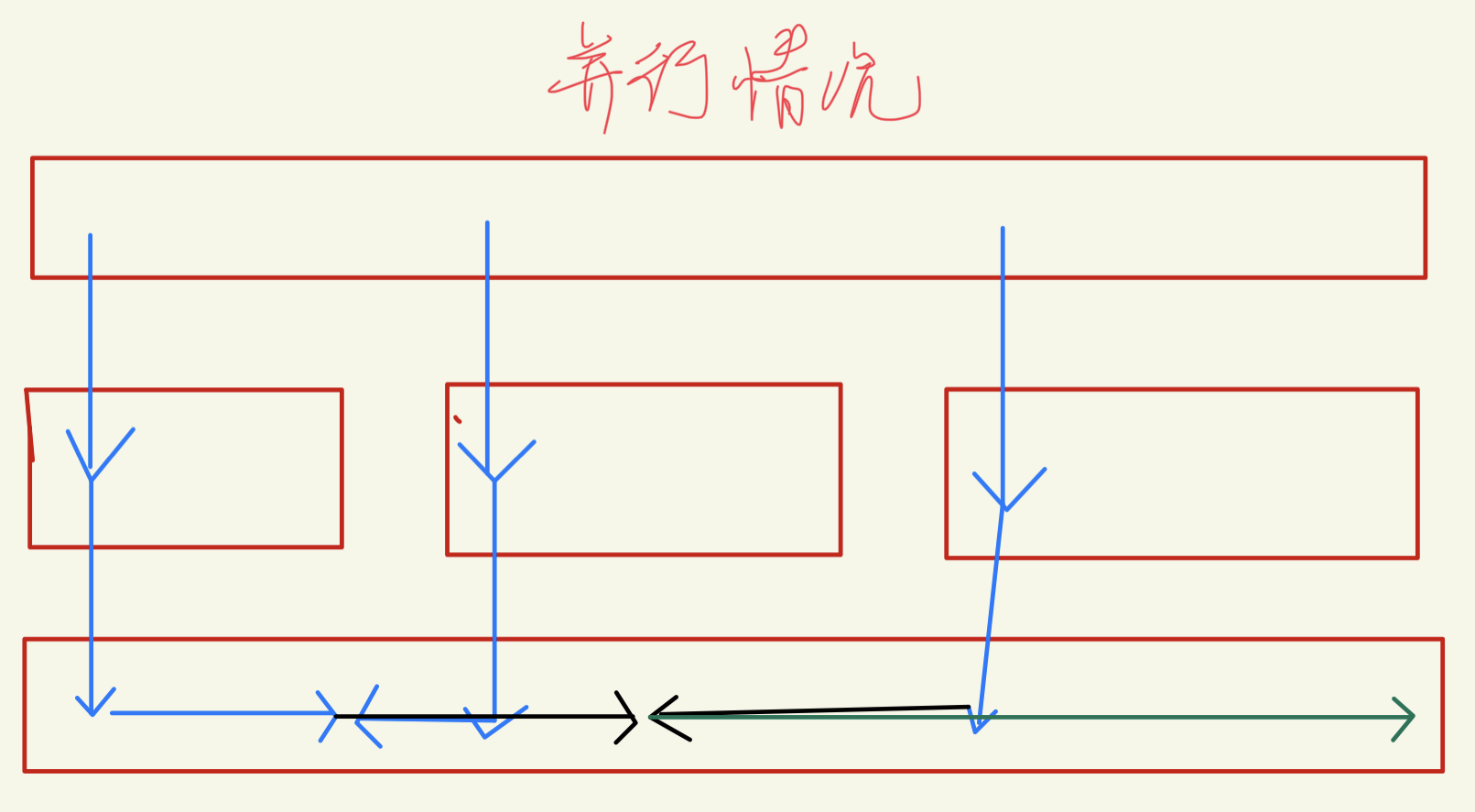
可以行分割或列分割,根据输入
想法很美好,但是最后的效果并不是每次64线程,基本都只有1-5个任务。导致近似单线程还有调用开销。(node6有人,node5慢些)
1 | Time taken is 36.212269 32.876626 PerformSuperpixelSegmentation_VariableSandM 循环 |
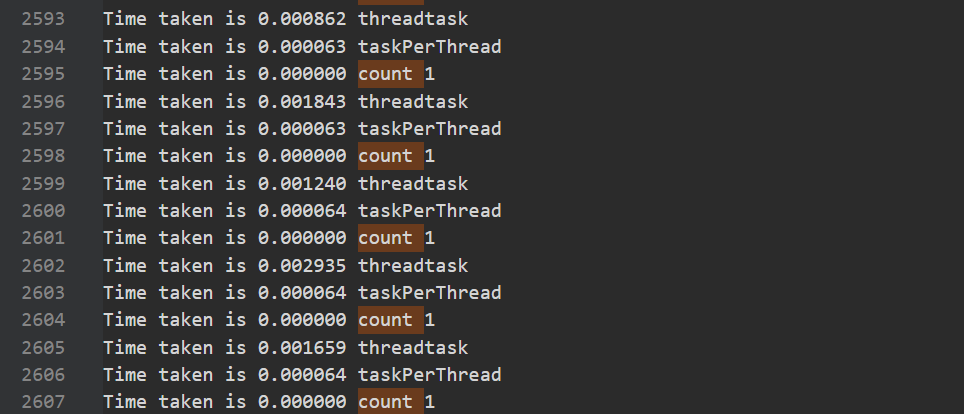
这个原因感觉是一开始只有1个,然后一般也就产生1/2个任务。将其初始任务改成64个就行。
但是如何一开始启动64个呢,我又提前不知道任务。
写完又是segFault,debug
1 | Time taken is 28.219408 0.000017 EnforceLabelConnectivity numlable |
没时间研究
没时间研究
感觉要自己写个结构体
暂无
在这次并行中,让我意识到几点
好吧,我感觉我分析了一堆,就是在放屁。还是串行快,这个问题就难划分。就不是并行的算法。
这次编程遇到的问题,大多数如下:
无
IPCC Preliminary SLIC Optimization 3
因为例子太小,导致之前的分析时间波动太大。所以写了个了大一点的例子,而且给每个函数加上了时间的输出,好分析是否有加速。(Qrz,node5有人在用。
| 技术路线 | 描述 | 总时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 207 s | 1 | |
| simpleomp | 两处omp | 57s | ||
| more1omp | maxlab | 48s | ||
| more2omp | sigma + delete maxxy | 24.8s | 8.35 | |
| more3omp | DetectLabEdges + EnforceLabelConnectivity(该算法无法并行) | 21.2s | ||
| icpc | 13.4s | |||
| + -O3 | 13.2s | |||
| + -xHost | 13.09s | |||
| + -Ofast -xHost | 基于icpc | 12.97s | ||
| + -ipo | 12.73s | 16.26 | ||
| -no-prec-div -static -fp-model fast=2 | 14.2s | 时间还多了,具体其他选项需要到AMD机器上试 |
| 技术路线 | 描述 | 总时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 161.7s s | 1 | |
| more3omp | 前面都是可以证明的有效优化 omp_num=32 | 14.08s | ||
| more3omp | 前面都是可以证明的有效优化 omp_num=64 | 11.4s | ||
| deletevector | 把sz大小的3个vector,移到全局变量,但是需要提前知道sz大小/声明一个特别大的 | 10.64s | 可以看出写成全局变量也不会影响访问时间 | |
| enforce_Lscan | ipcc opt 4 | 8.49s |
暂无
无
IPCC Preliminary SLIC Optimization 2
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 21872 ms | 1 | |
| 核心循环openmp | 未指定 | 8079ms | ||
| 核心循环openmp | 单节点64核 | 7690ms | 2.84 | |
| 换intel的ipcp | 基于上一步 | 3071 ms | 7.12 | |
| -xHOST | 其余不行,基于上一步 | 4012ms | ||
| -O3 | 基于上一步 | 3593ms |
Intel(R) Xeon(R) Platinum 8153 CPU @ 2.00GHz
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 29240 ms | 1 | |
| 核心循环openmp | 未指定(htop看出64核) | 12244 ms | ||
| 去除无用计算+两个numk的for循环 | 080501 | 11953 ms 10054 ms | ||
| 计算融合(去除inv) | 080502 | 15702 ms 14923 ms 15438 ms 11987 ms | ||
| maxlab openmp | 基于第三行080503 | 13872 ms 11716 ms | ||
| 循环展开?? | 14436 ms 14232 ms 15680 ms |
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT, AVX2, AVX512F, ADX and AVX512CD instructions. |
-xCORE-AVX2
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT and AVX2 instructions |
没有 FXSAVE,BMI,LZCNT 有BMI1,BMI2
使用-xAVX,或者-xHOST 来选择可用的最先进指令集
1 | Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT and AVX instructions. |
1 | ld: cannot find -lstdc++ |
icpc -Ofast -march=core-avx2 -ipo -mdynamic-no-pic -unroll-aggressive -no-prec-div -fp-mode fast=2 -funroll-all-loops -falign-loops -fma -ftz -fomit-frame-pointer -std=c++11 -qopenmp SLIC_openmp.cpp -o SLIC_slurm_intel_o3
基于核心的openmp并行
1 | delete all maxxy |
暂无
暂无
无
IPCC Preliminary SLIC Analysis part4 : cluster environment
id
1 | [sca3173@ln121%bscc-a5 ~]$ id sca3173 |
cpu
1 | Intel(R) Xeon(R) Silver 4208 CPU @ 2.10GHz |
slurm
1 | ON AVAIL TIMELIMIT NODES STATE NODELIST |
memery
1 | [sca3173@ln121%bscc-a5 ~]$ cat /proc/meminfo |
architecture
1 | [sca3173@ln121%bscc-a5 public1]$ lsb_release -d | awk -F"\t" '{print $2}' |
GPU 集显
1 | [sca3173@ln121%bscc-a5 public1]$ lshw -numeric -C display |
disk
1 | [sca3173@ln121%bscc-a5 public1]$ df -h /public1 |
IP 内网IP
1 | [sca3173@ln121%bscc-a5 public1]$ hostname -I | awk '{print $1}' |
1 | > cat lscpu.txt |
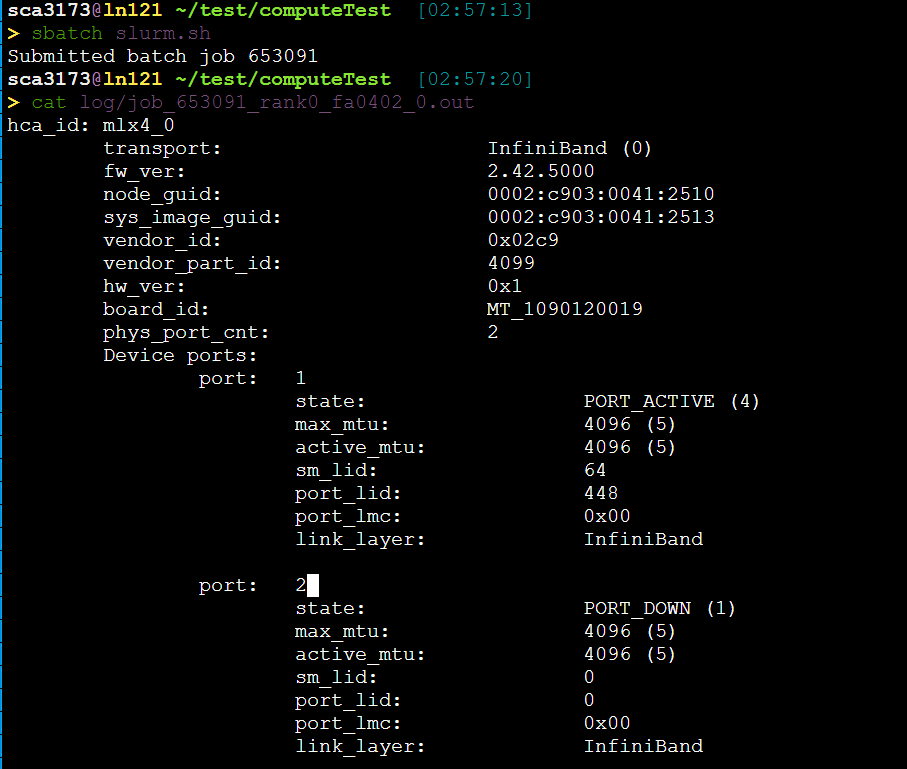

没有gcc/7.3.0
比赛是2节点128核的环境
我们是A5 分区。
没有找到手册,只有一个官网图。但是虽然频率是2.35GHz,但是内存只有251GB啊,什么情况。

IPCC Preliminary SLIC Analysis part3 : Hot spot analysis





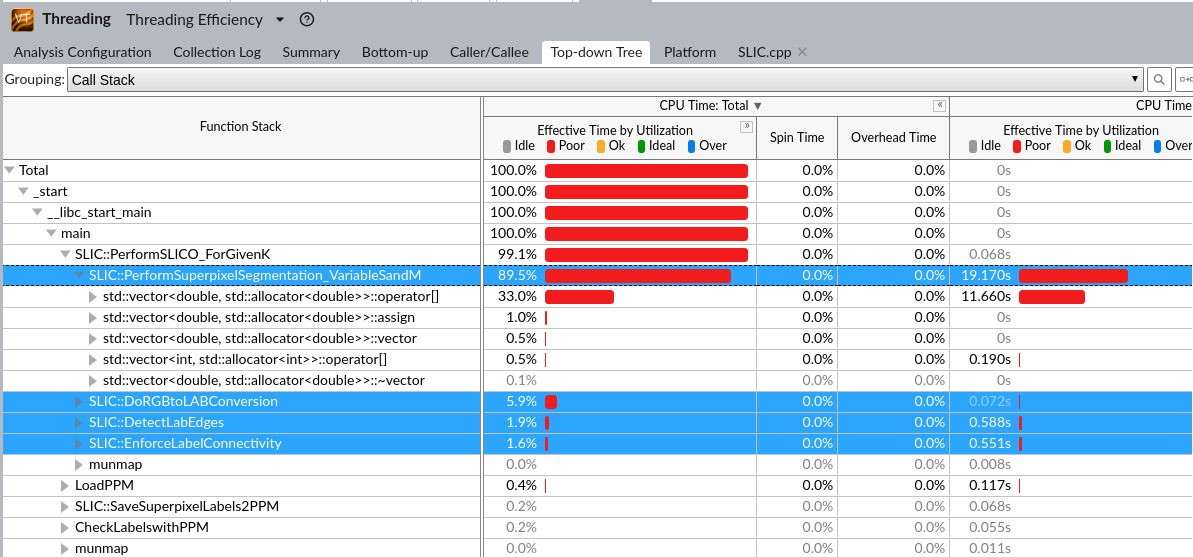

1 | g++ -pg -g -std=c++11 SLIC.cpp -o SLIC |


没什么用
根据具体资源情况来,貌似是一个节点,那可以从OpenMP入手
Intel编译器的自动并行化功能可以自动的将串行程序的一部分转换为线程化代码。进行自动向量化主要包括的步骤有,找到有良好的工作共享(worksharing)的候选循环;对循环进行数据流(dataflow)分析,确认并行执行可以得到正确结果;使用OpenMP指令生成线程化代码。
/Qparallel:允许编译器进行自动并行化
/Qpar-reportn:n为0、1、2、3,输出自动并行化的报告
说明:/Qparallel必须在使用O2/3选项下有效
所谓的向量化,简单理解,就是使用高级的向量化SIMD指令(如SSE、SSE2等)优化程序,属于数据并行的范畴。
向量化的目标是生成SIMD指令,那么很显然,要对代码进行向量化,
第一是依靠编译器来生成这些指令;
第二是使用汇编或Intrinsics函数。
Intel编译器中,利用其自动向量分析器(auto-vectorizer)对代码进行分析并生成SIMD指令。另外,也会提供一些pragmas等方式使得用户能更好的处理代码来帮助编译器进行向量化。
基本向量化
/Qvec:开启自动向量化功能,需要在O2以上使用。在O2以上,这是默认的向量化选项,默认开启的。此选项生成的代码能用于Intel处理器和非Intel处理器。向量化还可能受其他选项影响。由于此选项是默认开启的,所以不需要在命令行增加此选项。
针对指令集(处理器)的向量化
/QxHost:针对当前使用的主机处理器选择最优的指令集优化。
对于双重循环,外层循环被自动并行化了,而内层循环并没有被自动并行化,内层循环被会自动向量化。
看汇编代码
没成功需要手动内联向量化汇编代码???
暂无
暂无
https://blog.csdn.net/gengshenghong/article/details/7027186
IPCC Preliminary SLIC Analysis part2 : Run process

 由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。
由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。


1 | a.size() |
同RGB颜色空间相比,Lab是一种不常用的色彩空间。1976年,经修改后被正式命名为CIELab。Lab颜色空间中的L分量用于表示像素的亮度,取值范围是[0,100],表示从纯黑到纯白;a表示从红色到绿色的范围,取值范围是[127,-128];b表示从黄色到蓝色的范围,取值范围是[127,-128]。
RGB颜色空间不能直接转换为Lab颜色空间,需要借助XYZ颜色空间,把RGB颜色空间转换到XYZ颜色空间,之后再把XYZ颜色空间转换到Lab颜色空间。
RGB与XYZ颜色空间有如下关系:
LAB与XYZ颜色空间有如下关系:
X,Y,Z会分别除以0.950456、1.0、1.088754。
暂无
暂无
无


