SIMD
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
通过使用矢量寄存器,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如 AMD的3D NOW!技术
MMX
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE
SSE为Streaming SIMD Extensions的缩写。Intel SSE指令通过128bit位宽的专用寄存器, 支持一次操作128bit数据. float是单精度浮点数, 占32bit, 那么可以使用一条SSE指令一次计算4个float数。注意这些SSE指令要求参数中的内存地址必须对齐于16字节边界。
SSE专用矢量寄存器个数,是每个core一个吗?
SSE有8个128位寄存器,XMM0 ~XMM7。此外SSE还提供了新的控制/状态寄存器MXCSR。为了回答这个问题,我们需要了解CPU的架构。每个core是独占register的
SSE 相关编译命令
addps xmm0, xmm1 ; reg-reg
addps xmm0, [ebx] ; reg-mem
sse提供了两个版本的指令,其一以后缀ps结尾,这组指令对打包单精度浮点值执行类似mmx操作运算,而第二种后缀ss
SSE 相关函数
- load系列 eg.__m128 _mm_load_ss (float *p)
- store系列 eg.__m128 _mm_set_ss (float w)
- 其他操作 eg.__m128 _mm_add_ss (__m128 a, __m128 b)包括加法、减法、乘法、除法、开方、最大值、最小值、近似求倒数、求开方的倒数等等浮点操作
SSE指令集的发展

- SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.
- SSE3支持一些更加复杂的算术计算.
- SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
- 由于2007年8月,AMD抢先宣布了SSE5指令集。之后Intel将新出的叫做AVX指令集。由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集
AVX
Advanced Vector Extensions。较新的Intel CPU都支持AVX指令集, 它可以一次操作256bit数据, 是SSE的2倍,可以使用一条AVX指令一次计算8个float数。AVX指令要求内存地址对齐于32字节边界。
SSE 与 AVX的发展


性能对比
根据参考文章,其中用gcc编译AVX版代码时需要加-mavx选项.
开启-O3选项,一般不用将代码改成多次计算和内存对齐。
判断是否向量化,看汇编
GNU
1 | gcc -march=native -c -Q --help=target # 查看支持的指令集 |
c++函数在linux系统下编译之后会变成如下样子
1 | _ZNK4Json5ValueixEPKc |
在linux命令行使用c++filter
1 | $ c++filt _ZNK4Json5ValueixEPKc |
可以得到函数的原始名称, 展开后续追踪
intel icpc
clang
1 | -Rpass=loop-vectorize |
常见汇编代码
1 | xmm 寄存器 |
MMX指令

手动向量化
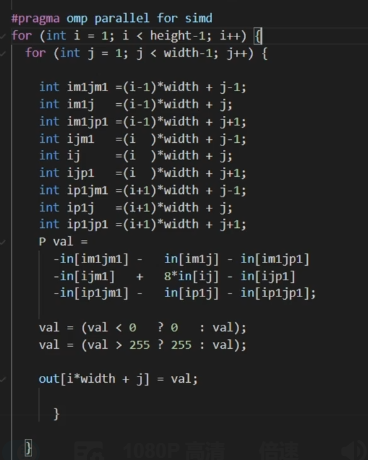
循环展开8次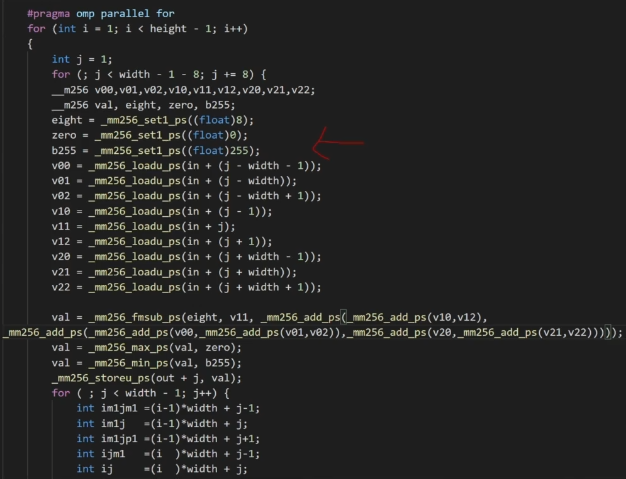
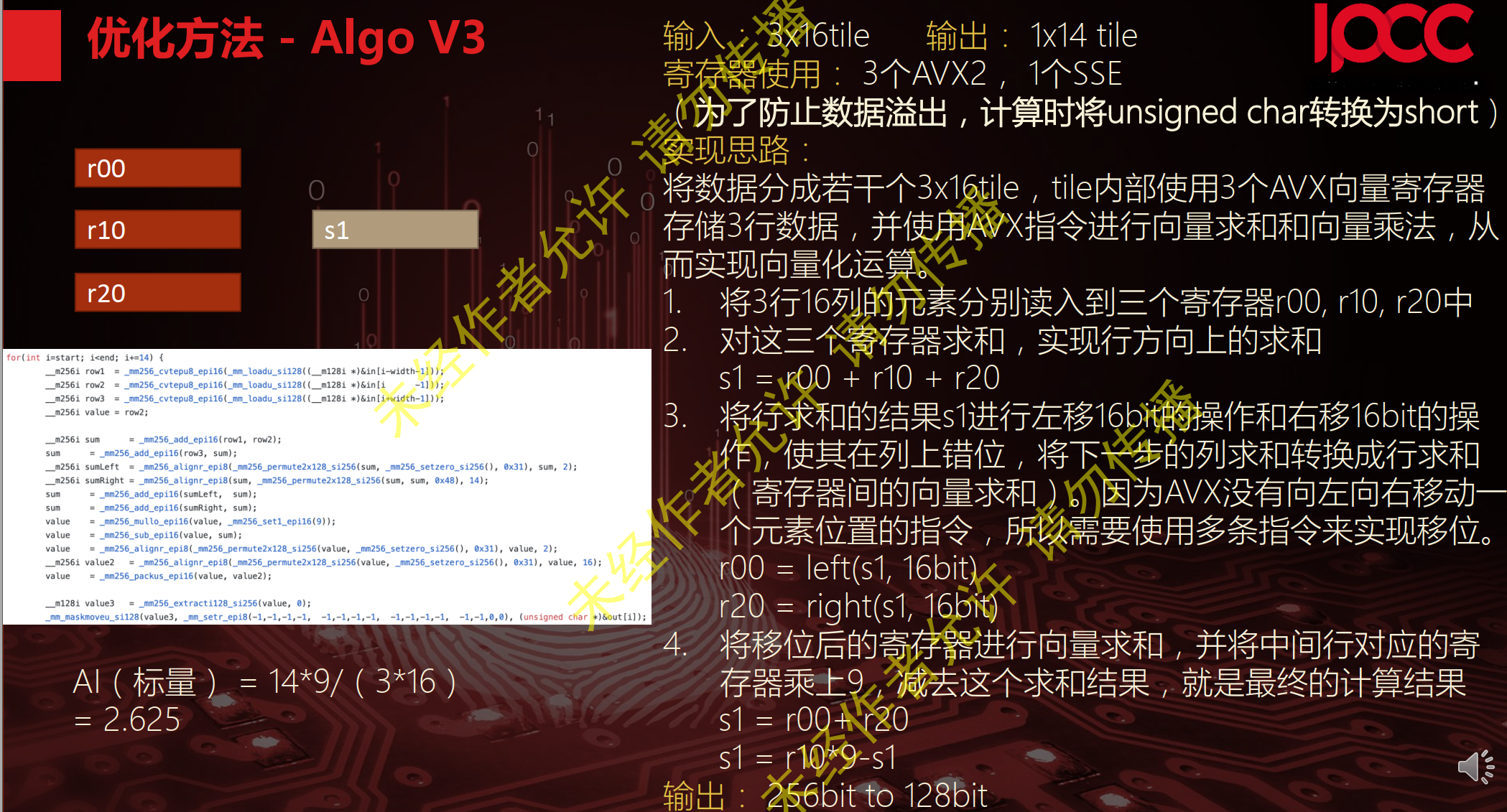
例子1
SIMD寄存器
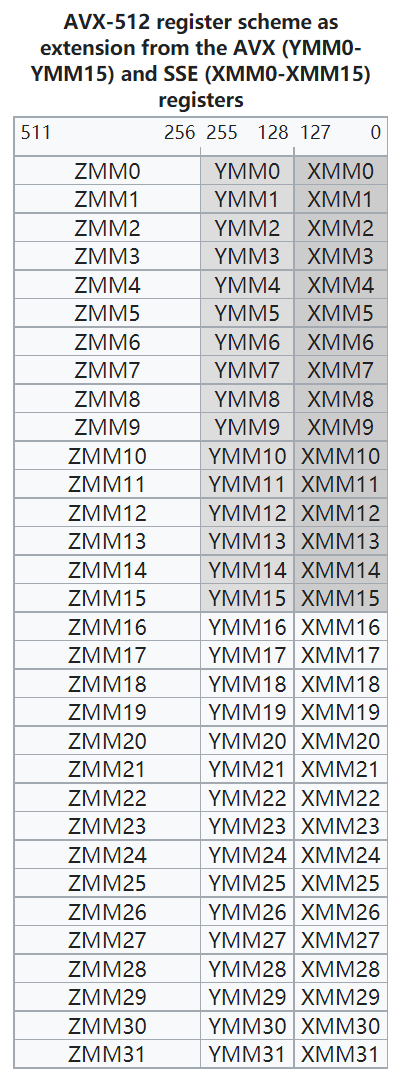
需要进一步的研究学习
暂无
遇到的问题
暂无
参考文献
https://www.dazhuanlan.com/2020/02/01/5e3475c89d5bd/
https://software.intel.com/sites/landingpage/IntrinsicsGuide/