非阻塞MPI

MPI_Send & MPI_receive

MPI_AllTogether()更慢,需要4s
手动向量化对齐
debug
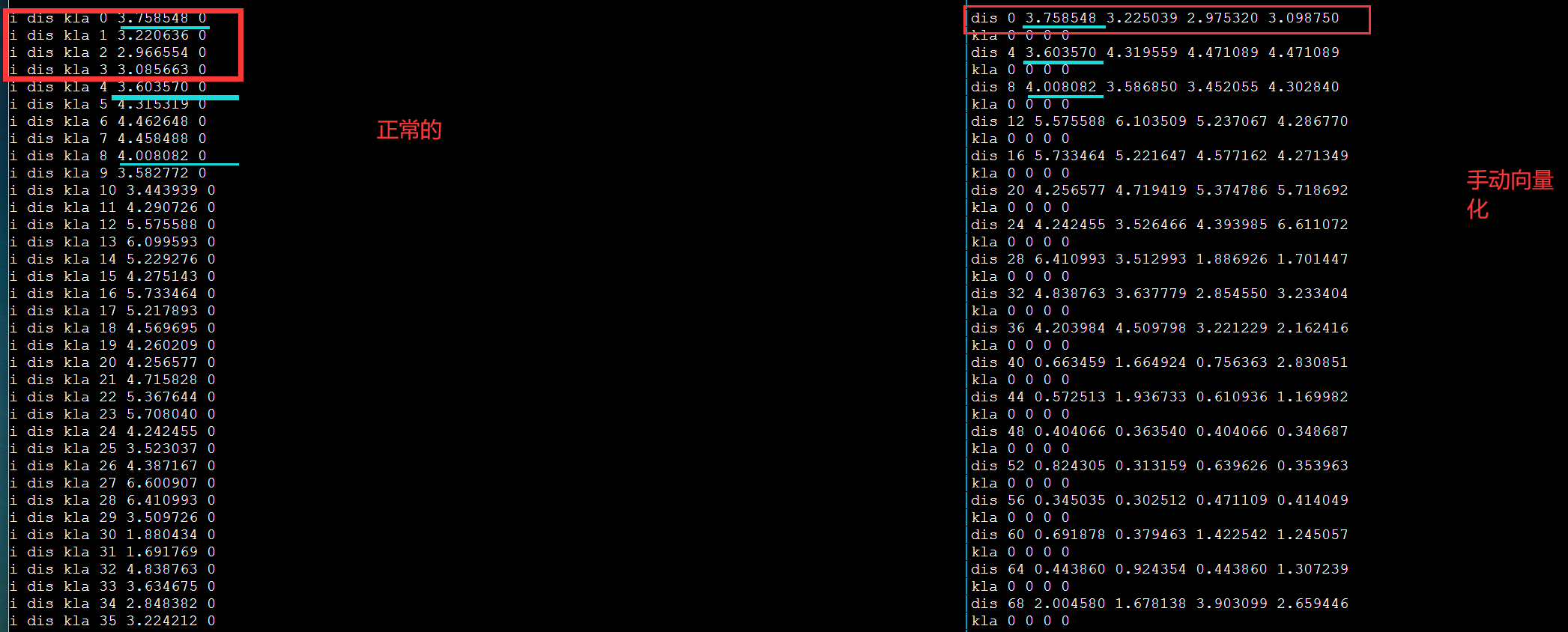
1
2
| vx = _mm256_set_pd(x); #改成
vx = _mm256_set_pd(x+3,x+2,x+1,x);
|
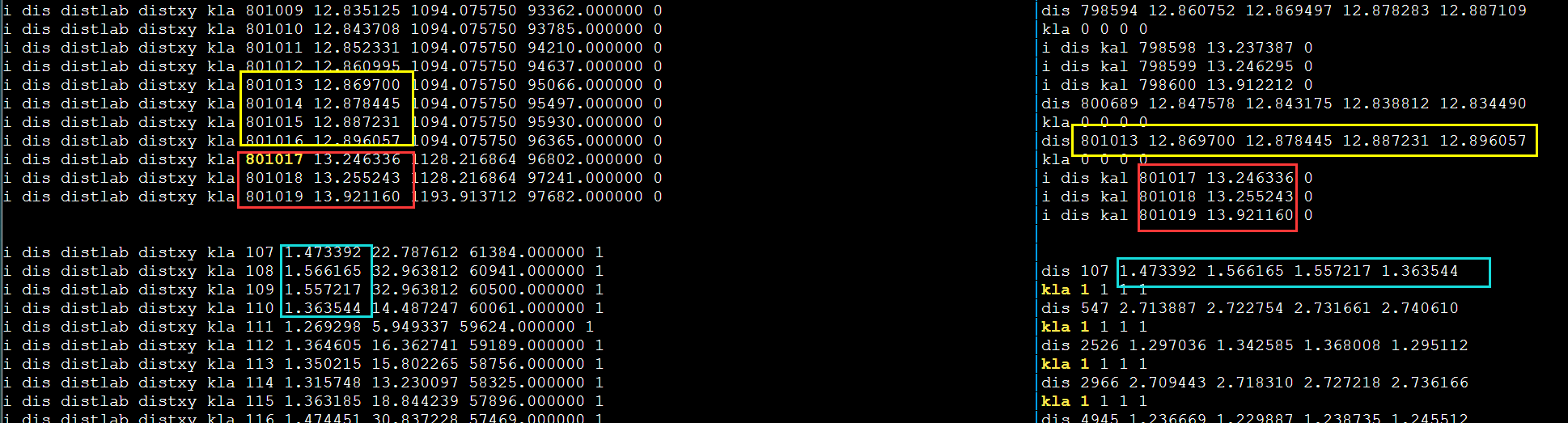

发现不对劲,打印更多输出。第一次循环肯定是对的因为和DBL_MAX比较。
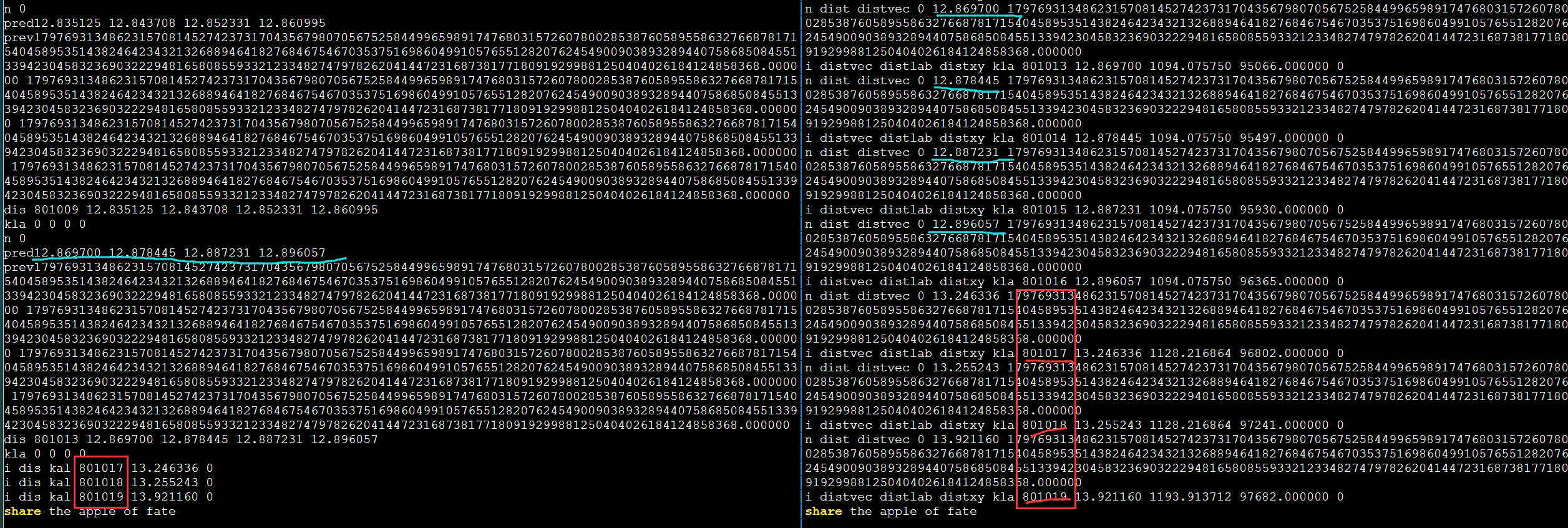

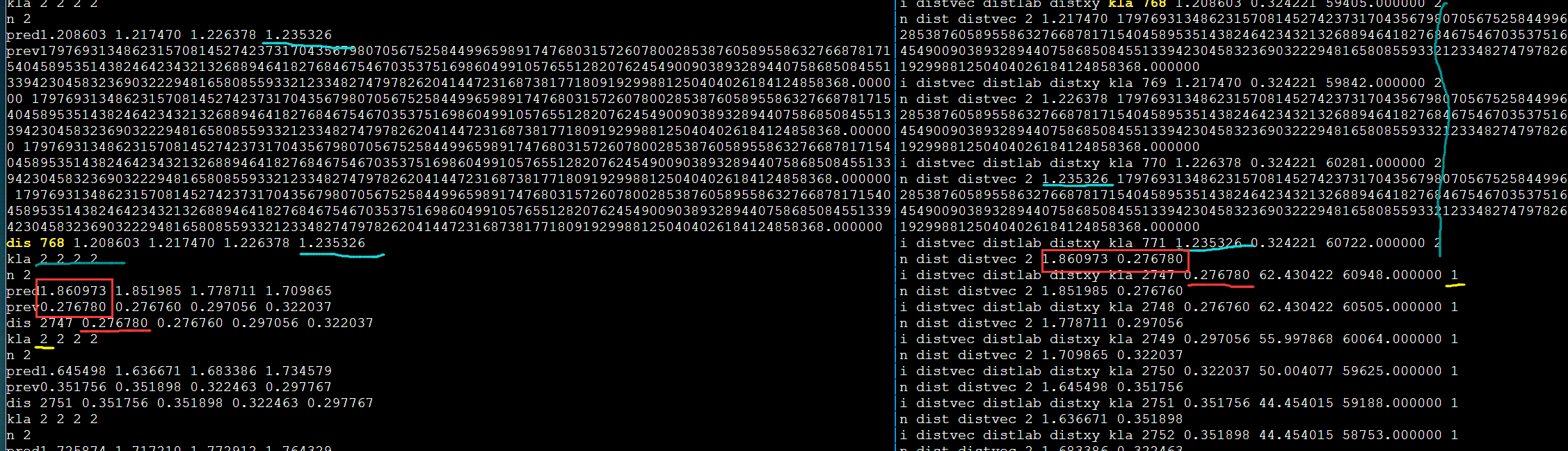
需要进一步的研究学习
为什么明明有56GB的IB网,传输速度还是这么慢呢?写比较慢?
7*8=56 8条通道
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无