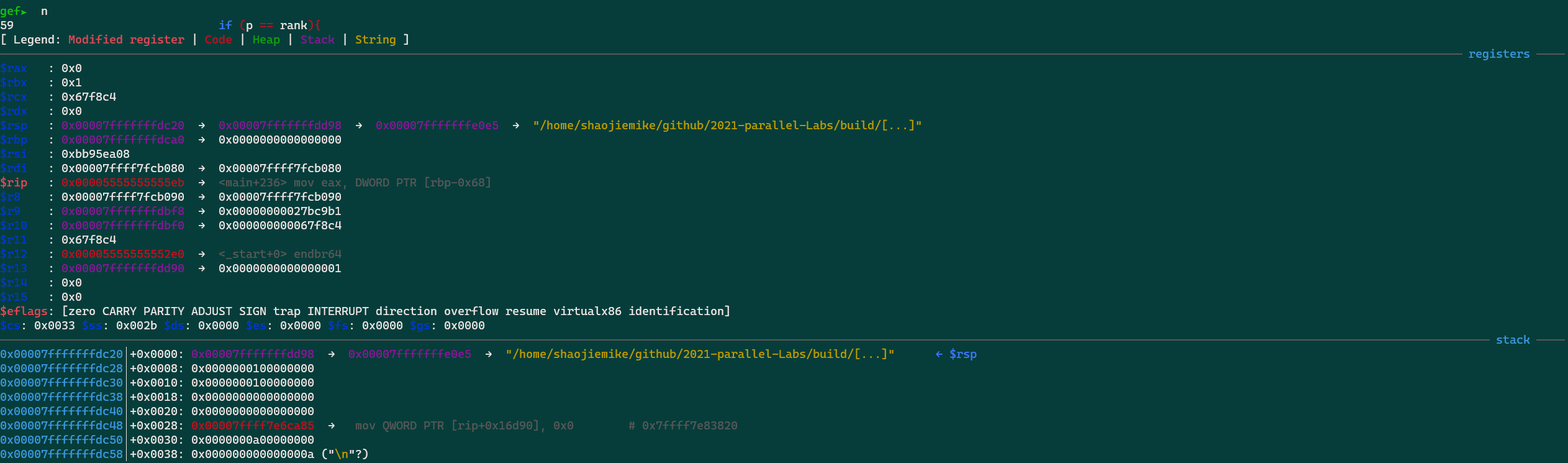
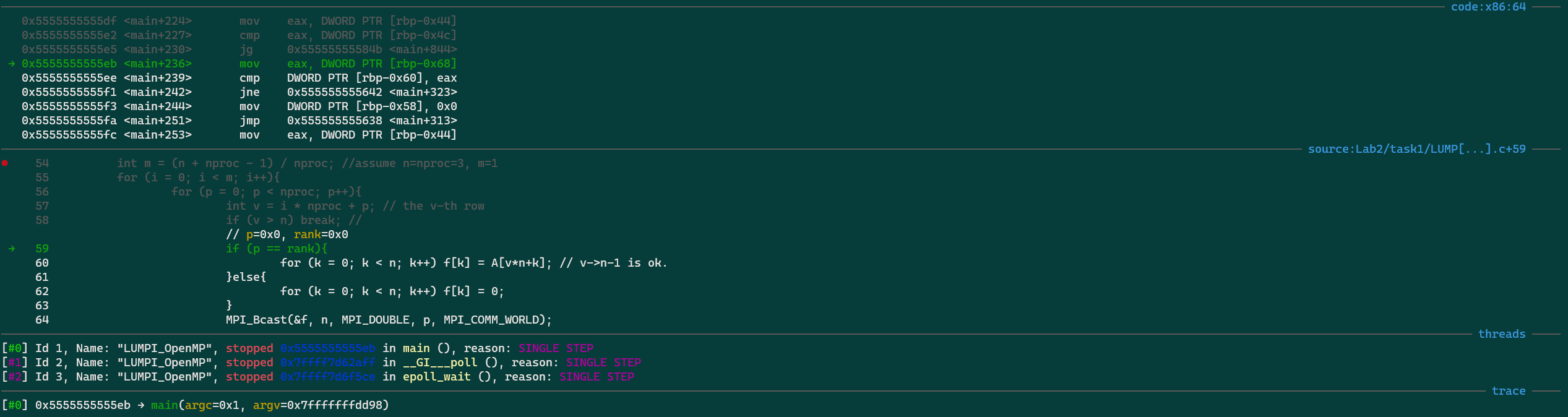
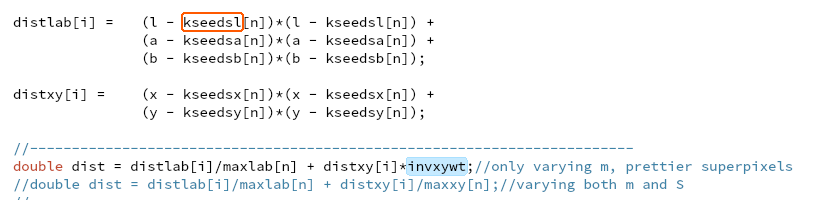
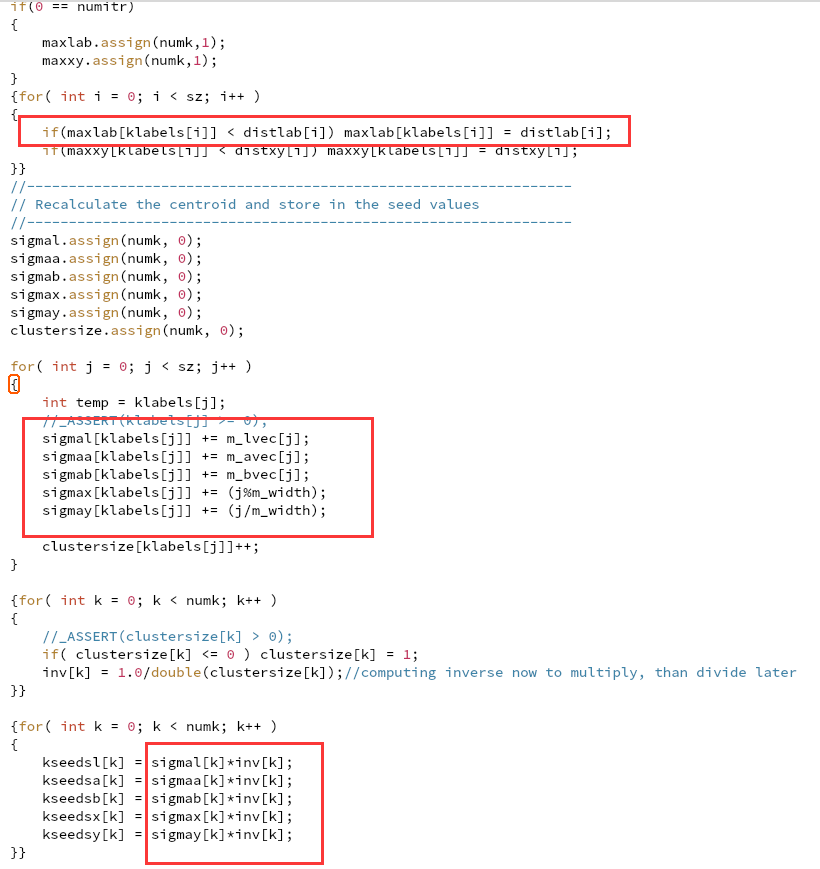
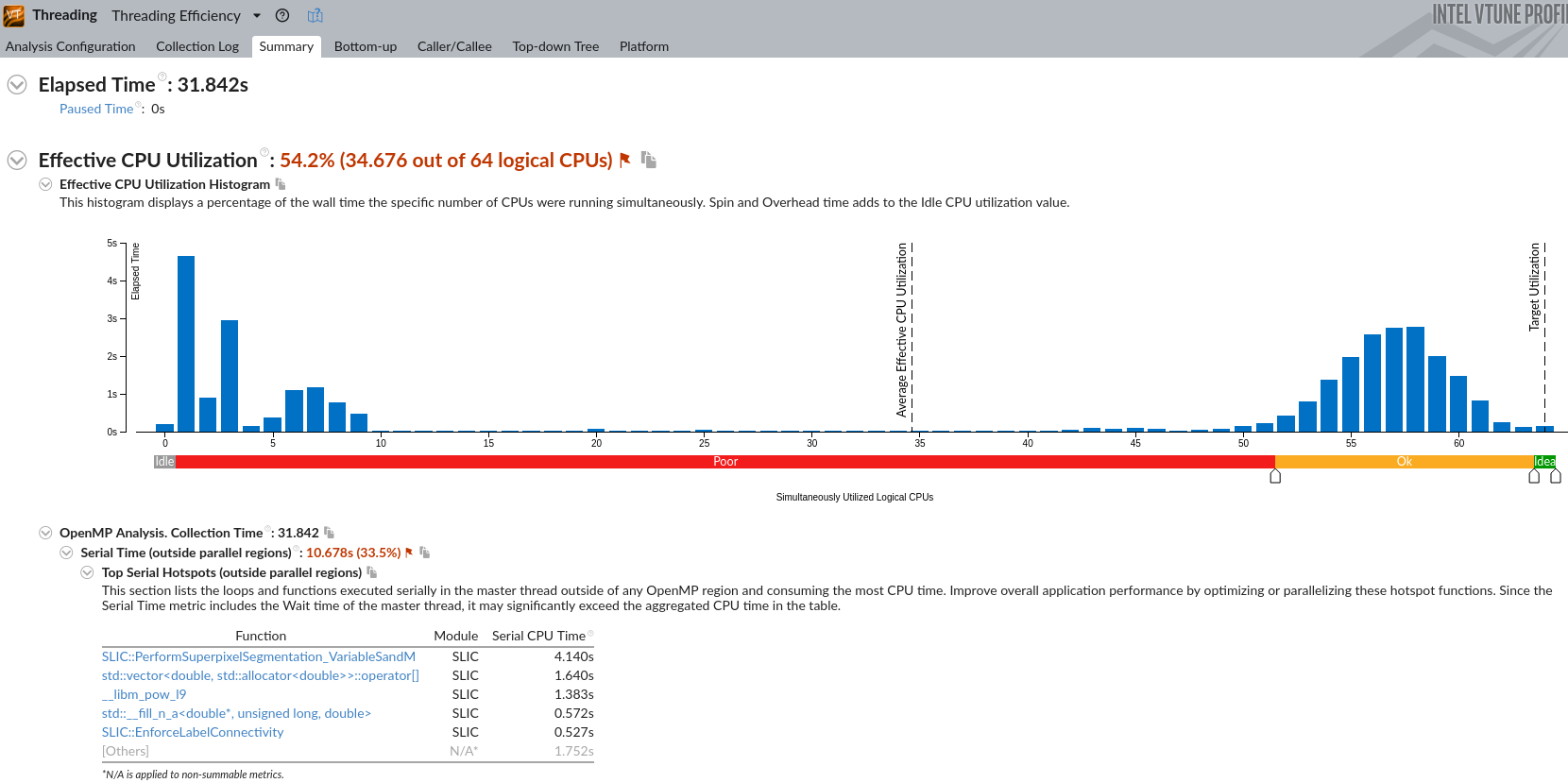
(gdb) bt #0 0x00002af6047e4a4b in fgets () from /lib64/libc.so.6 #1 0x000000000040450a in LoadPPM (filename=0x407e63 "input_image.ppm", data=0x7ffecda55cc8, width=0x7ffecda55cc4, height=0x7ffecda55cc0) at SLIC_raw.cpp:692 #2 0x00000000004049e1 in main (argc=1, argv=0x7ffecda55de8) at SLIC_raw.cpp:794
python 程序
1 2 3 4 5 6 7
# add debug file for gdb cd /compile_path/build cp dbg/libtorch_npu.so.debug /path2conda/site-packages/torch_npu/lib # gdb need the same python env conda activate xxx gdb python core_xxx # bt