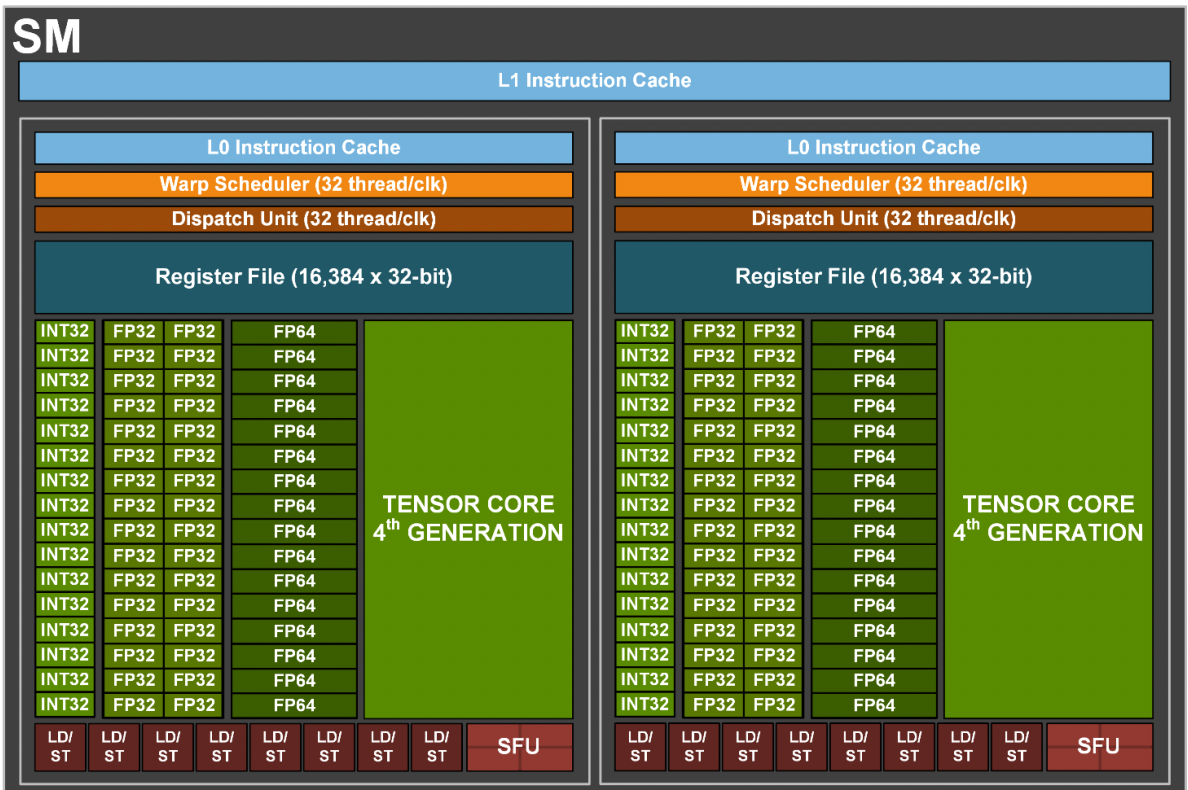
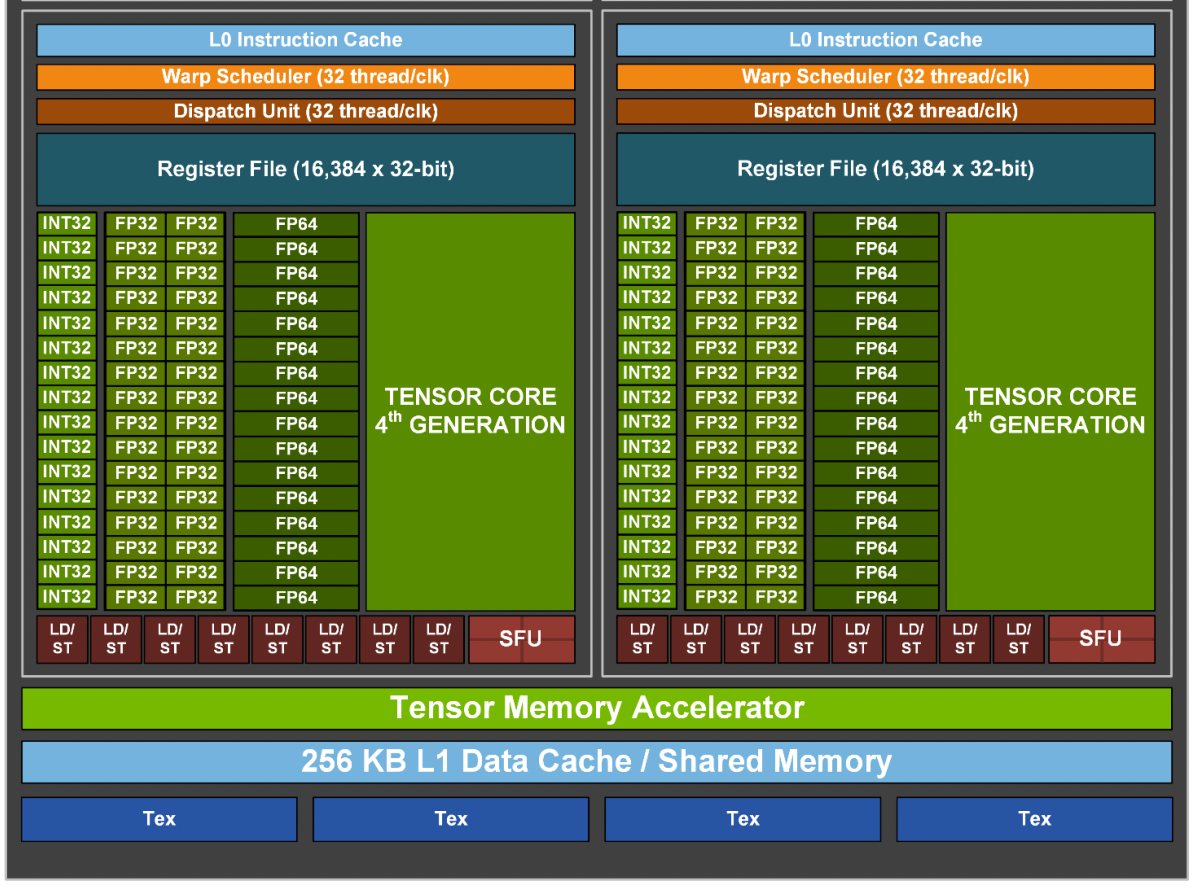
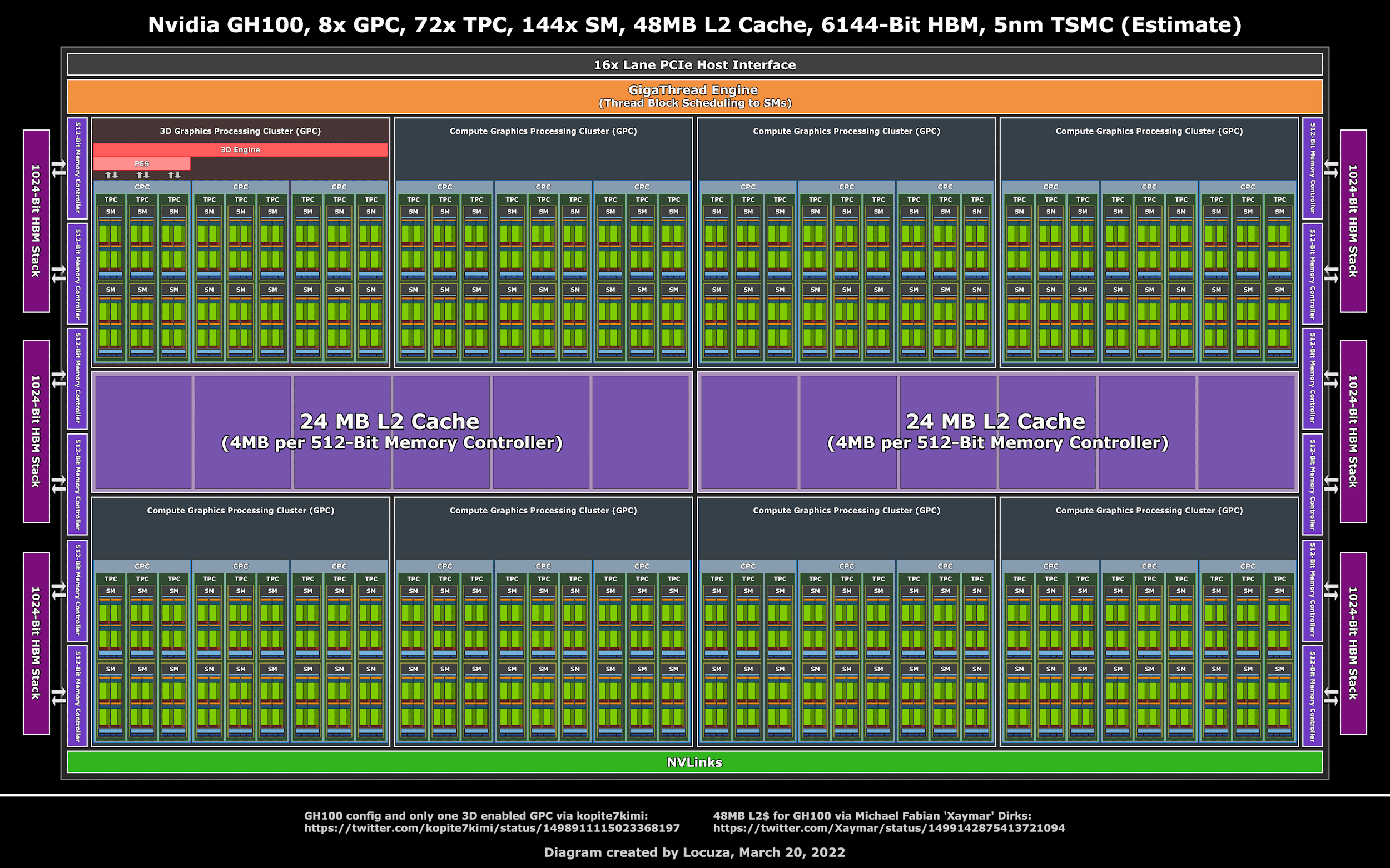
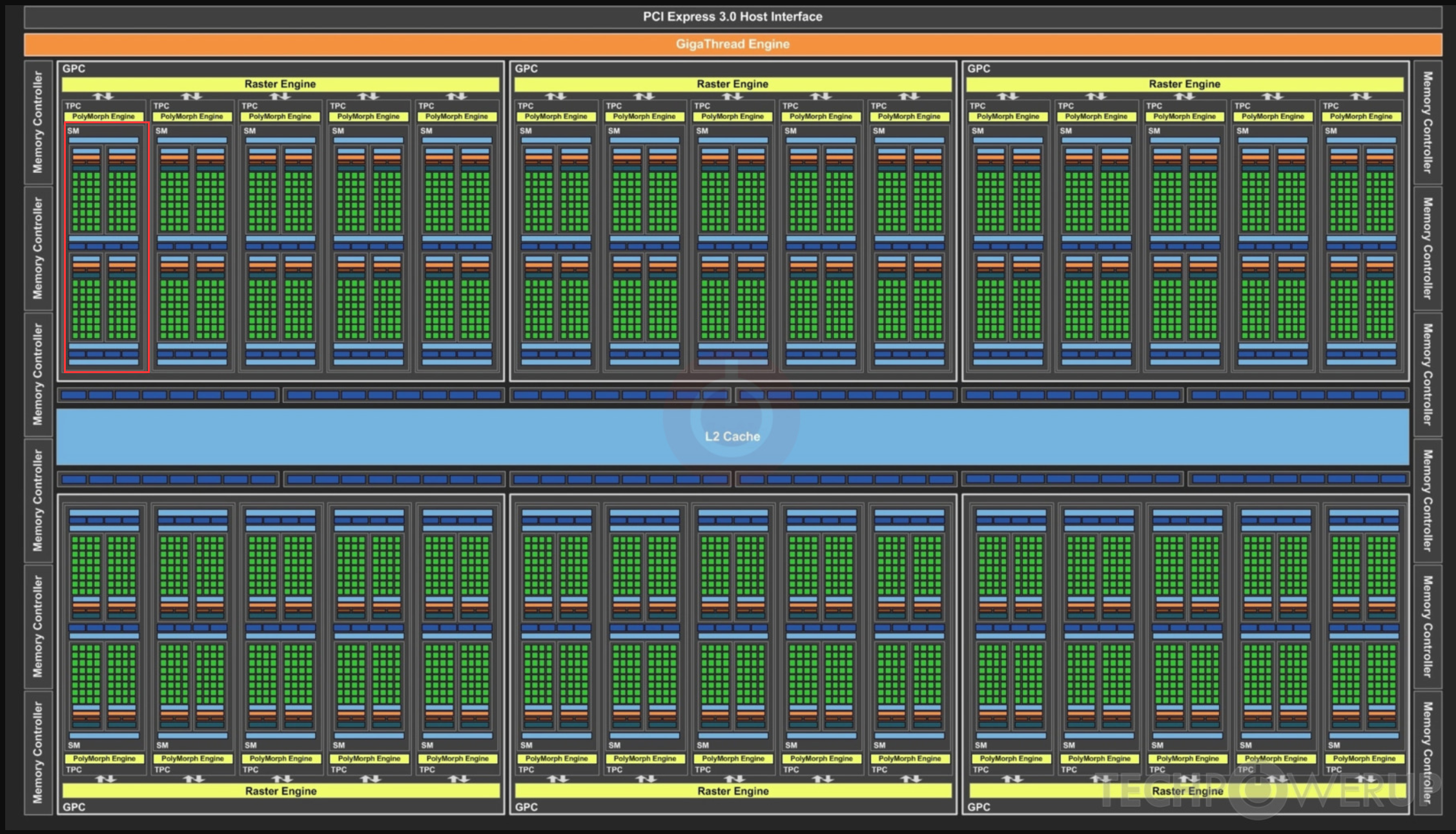
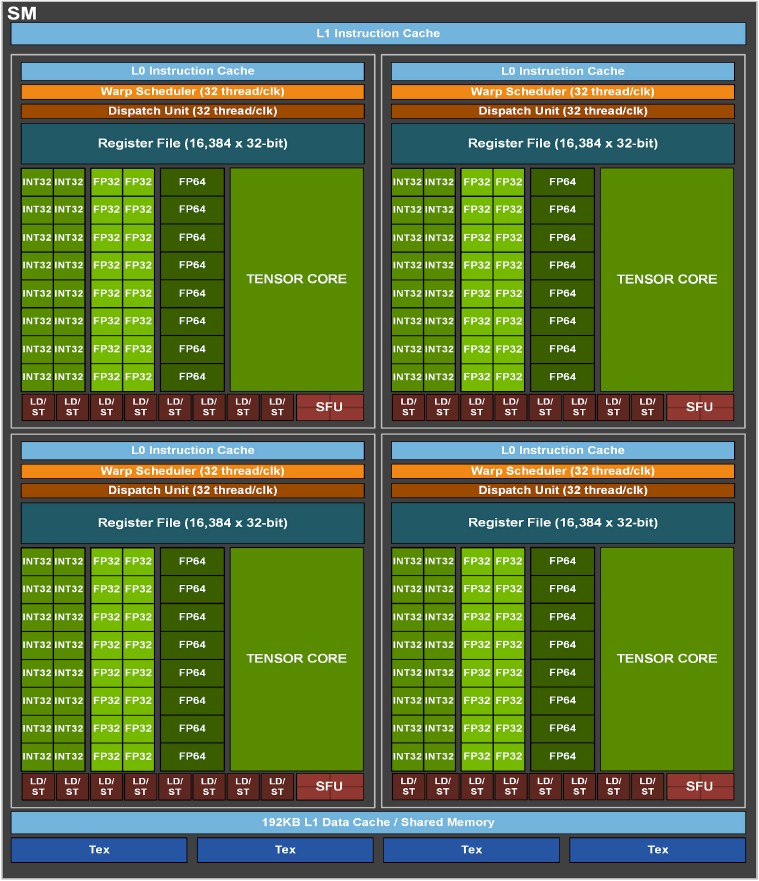
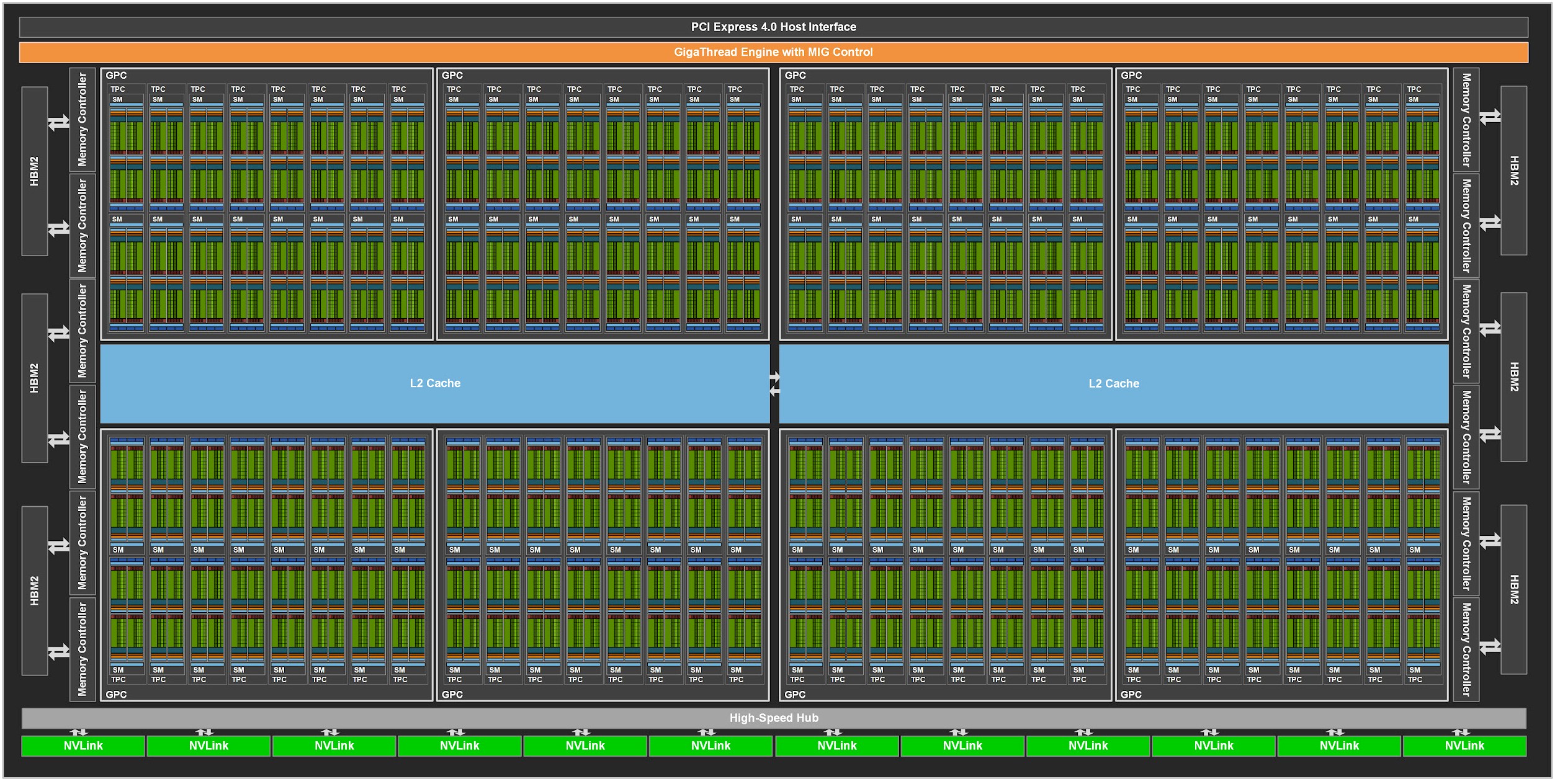
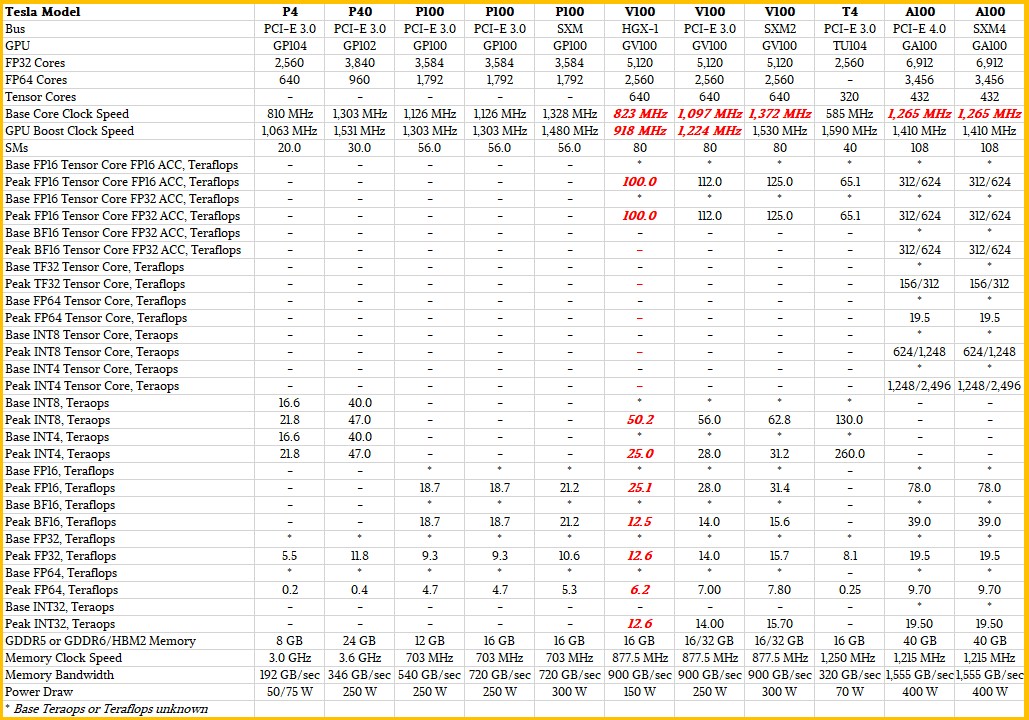
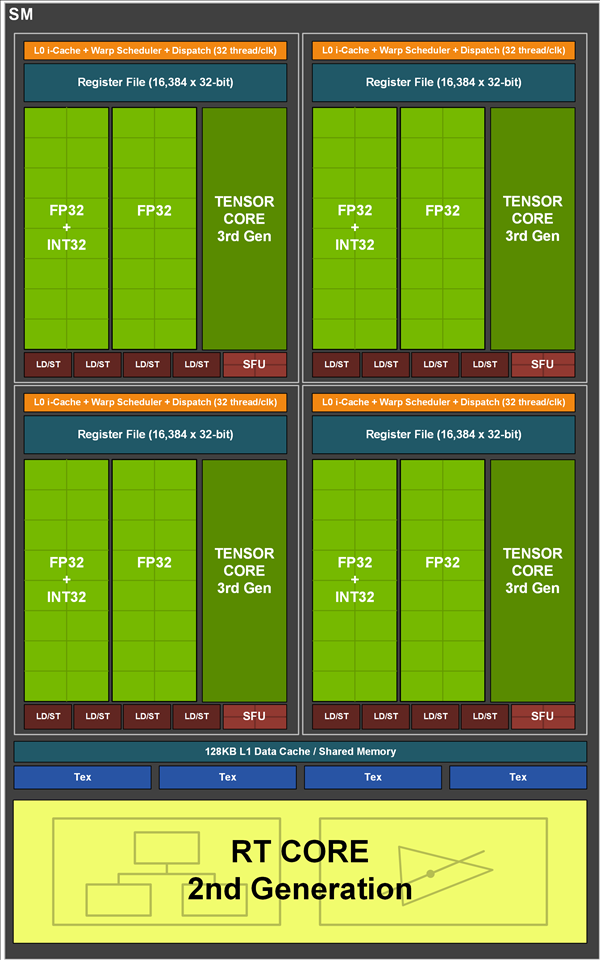
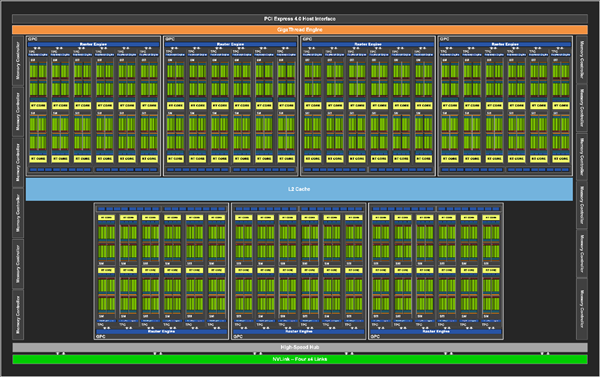
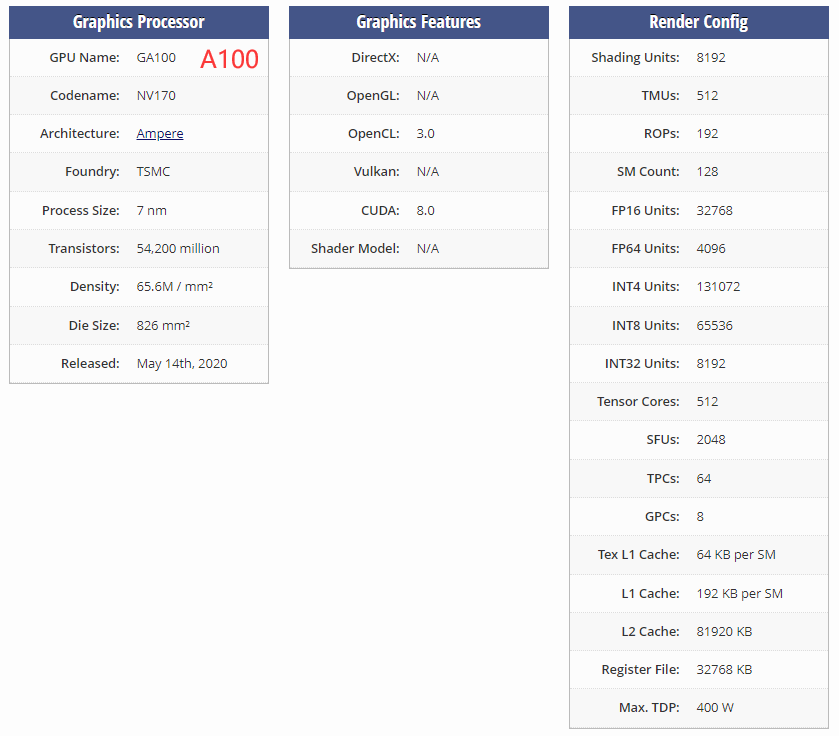
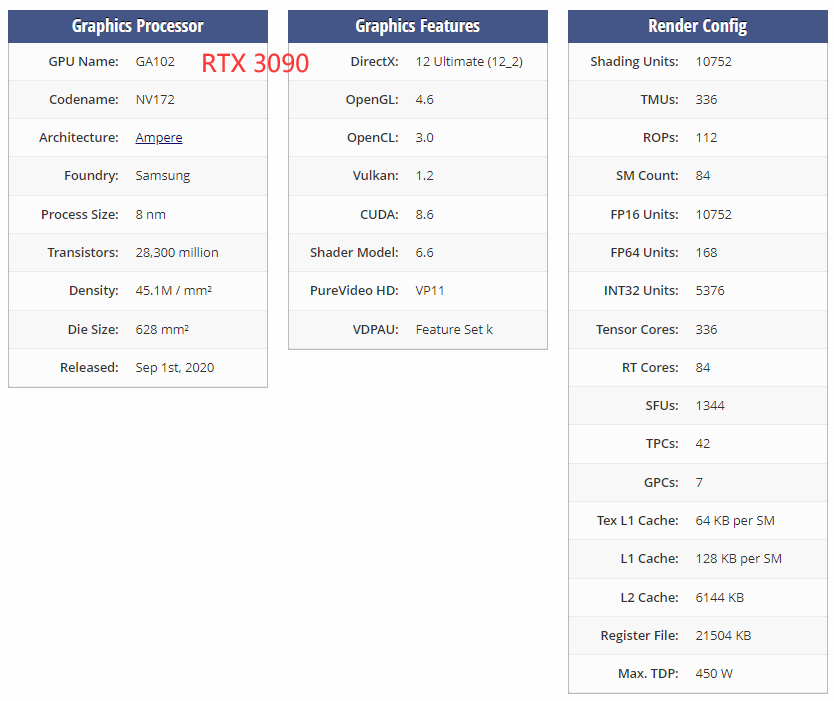
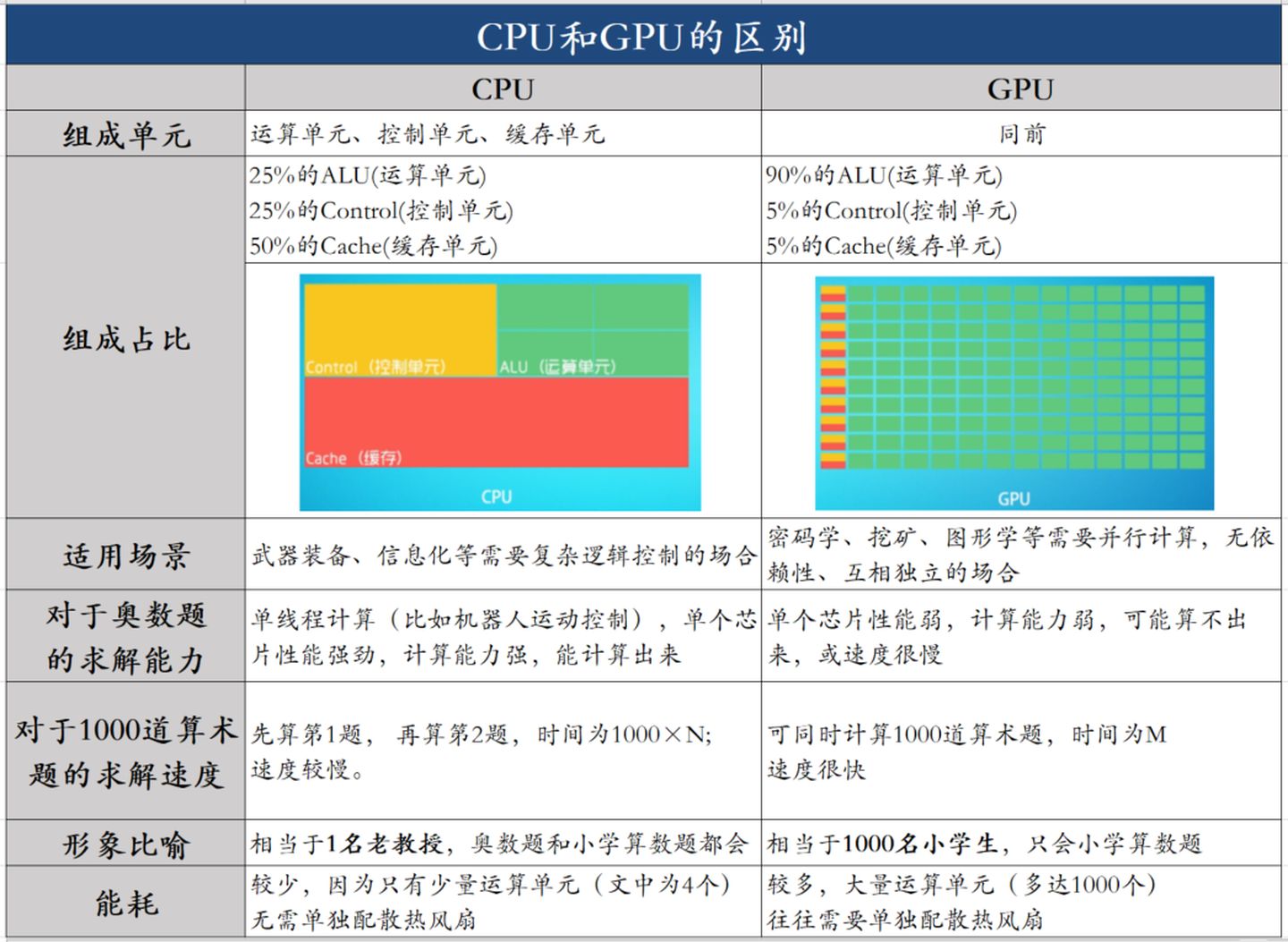
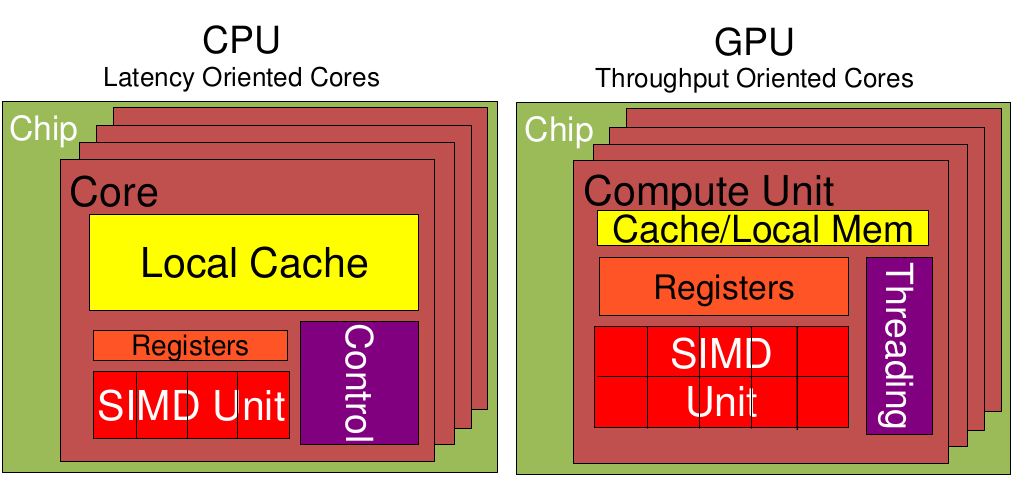
GPU vs CPU
CPU: latency-oriented design 低延时的设计思路
large L1 caches to reduce the average latency of data时钟周期的频率是非常高的,达到3-4GHz
Instruction-level parallelism to compute partial results ahead of time to further reduce latency
当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。
相比之下计算能力只是CPU很小的一部分。擅长逻辑控制,串行的运算。
GPU: throughput-oriented design 大吞吐量设计思路
GPU采用了数量众多的计算单元和超长的流水线
但只有非常简单的控制逻辑
几乎省去了Cache。缓存的目的不是保存后面需要访问的数据的,减少cache miss。这点和CPU不同,而是为thread提高服务的。
GPU “over-subscribed” threads: GPU运行任务会启动远超物理核数的thread,原因是借助极小的上下文切换开销,GPU能通过快速切换Threads/warps来隐藏访存延迟。
GPU线程的创建与调度使用硬件而不是操作系统,速度很快(PowerPC创建线程需要37万个周期)[^1]
Cost to switch between warps allocated to a warp scheduler is 0 cycles and can happen every cycle.[^2]
对带宽大的密集计算并行性能出众,擅长的是大规模并发计算。
对比项
CPU
GPU
说明
Cache, local memory
多
低延时
Threads(线程数)
多
Registers
多
多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。
SIMD Unit
多
单指令多数据流,以同步方式,在同一时间内执行同一条指令
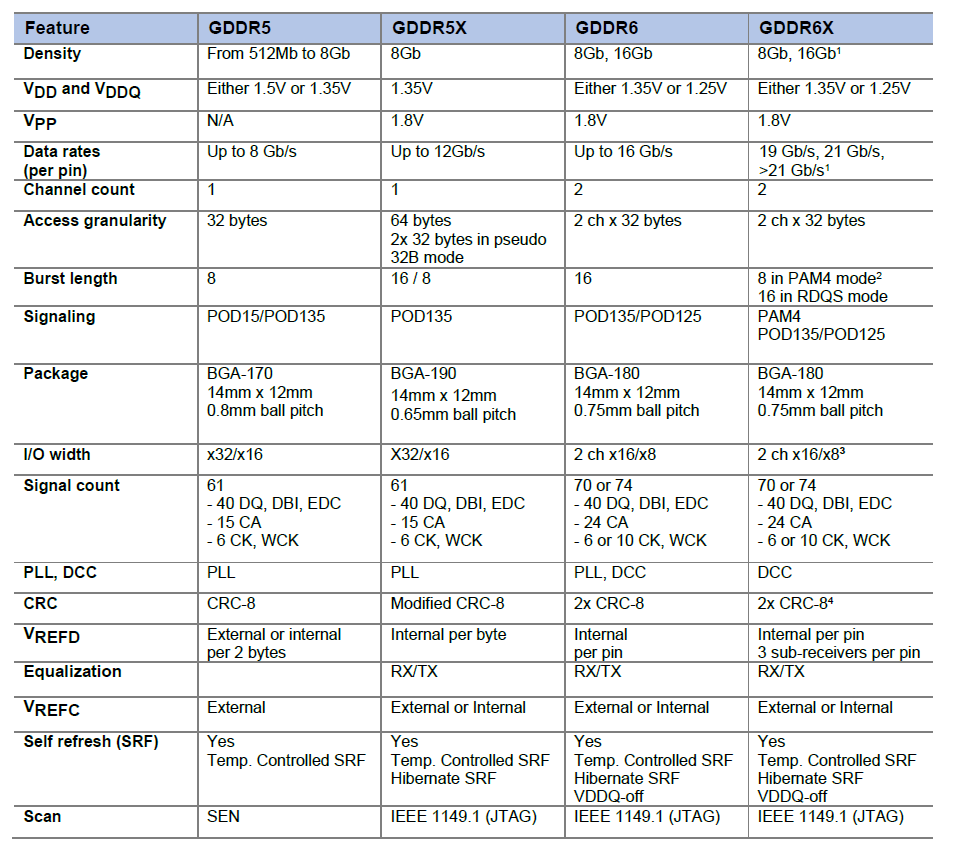
DRAM vs GDRAM 其实最早用在显卡上的DDR颗粒与用在内存上的DDR颗粒仍然是一样的。后来由于GPU特殊的需要,显存颗粒与内存颗粒开始分道扬镳,这其中包括了几方面的因素:
GPU需要比CPU更高的带宽 GPU不像CPU那样有大容量二三级缓存,GPU与显存之间的数据交换远比CPU频繁,而且大多都是突发性的数据流,因此GPU比CPU更加渴望得到更高的显存带宽支持。位宽×频率=带宽 ,因此提高带宽的方法就是增加位宽和提高频率,但GPU对于位宽和频率的需求还有其它的因素。显卡需要高位宽的显存 显卡PCB空间是有限的,在有限的空间内如何合理的安排显存颗粒,无论高中低端显卡都面临这个问题。从布线、成本、性能等多种角度来看,显存都需要达到更高的位宽。 3090是384位。而内存则没有那么多要求,多年来内存条都是64bit,所以单颗内存颗粒没必要设计成高位宽,只要提高容量就行了,所以位宽一直维持在4/8bit。显卡能让显存达到更高的频率 显存颗粒与GPU配套使用时,一般都经过专门的设计和优化,而不像内存那样有太多顾忌。GPU的显存控制器比CPU或北桥内存控制器性能优异,而且显卡PCB可以随意的进行优化,因此显存一般都能达到更高的频率。而内存受到内存PCB、主板走线、北桥CPU得诸多因素的限制很难冲击高频率。由此算来,显存与内存“分家”既是意料之外,又是情理之中的事情了。为了更好地满足显卡GPU的特殊要求,一些厂商(如三星等)推出了专门为图形系统设计的高速DDR显存,称为“Graphics Double Data Rate DRAM”,也就是我们现在常见的GDDR。
内存频率 1 2 sudo dmidecode|grep -A16 "Memory Device" |grep "Speed" Speed: 2666 MT/s
显存等效频率 因为显存可以在一个时钟周期内的上升沿和下降沿同时传送数据,所以显存的实际频率应该是标称频率的一半。
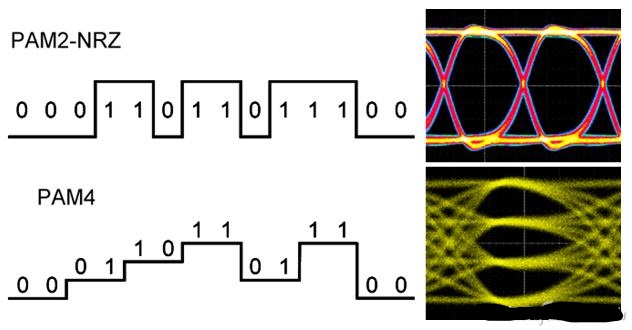
从GDDR5开始用两路传输,GDDR6采用四路传输(达到类似效果)。
GDDR6X的频率估计应该至少从16Gbps(GDDR6目前的极限)起跳,20Gbps为主,这样在同样的位宽下,带宽比目前常见的14Gbps GDDR6大一半。比如在常见的中高端显卡256bit~384位宽下能提供512GB/s~768GB/s的带宽。
RTX 3090的GDDR6X显存位宽384bit,等效频率19Gbps到21Gbps,带宽可达912GB/s到1006GB/s,达到T级。(384*19/8=912)
RTX 3090 加速频率 (GHz) 1.7, 基础频率 (GHz) 1.4
1 2 19/1.4 = 13.57 21/1.7 = 12.35
消费者设备 GDDR6x DDR4 的带宽对比
上一小节 RTX 3090 带宽在912GB/s到1006GB/s 附近
DRAM Types 一文里有分析,个人主机插满4条DDR4带宽” 3.2 Gbps * 64 bits * 2 / 8 = 51.2GB/s
可见两者差了20倍左右。
GPU / CPU workload preference 通过上面的例子,大致能知道: 需要高访存带宽和高并行度的SIMD的应用适合分配在GPU上。
最佳并行线程数 $$ 144 SM * 4 warpScheduler/SM * 32 Threads/warps = 18432 $$
参考文献 https://zhuanlan.zhihu.com/p/156171120?utm_source=wechat_session
https://www.cnblogs.com/biglucky/p/4223565.html
https://www.zhihu.com/question/36825227/answer/69351247
https://baijiahao.baidu.com/s?id=1675253413370892973&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/62234511
https://kknews.cc/digital/x6v69xq.html
[^1]: 并行计算课程-CUDA 密码pa22