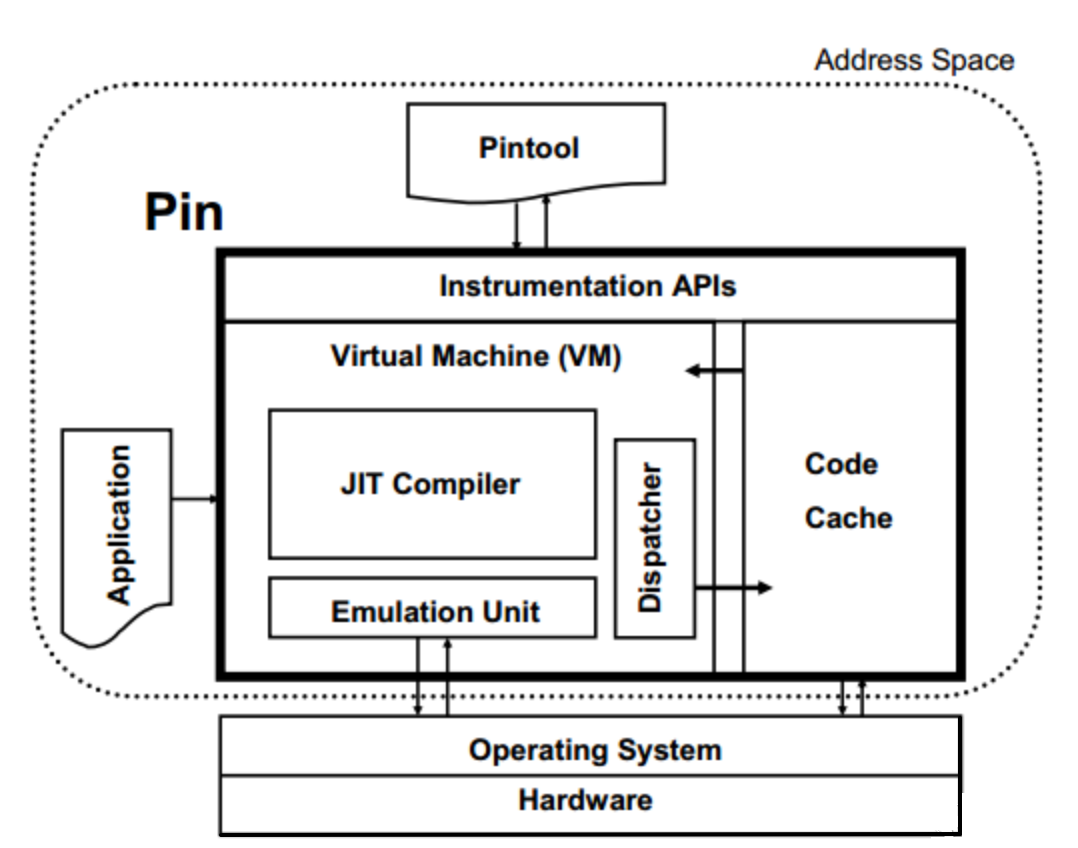
Because the compatibility problem may you should install pin with archlinux package
Installation
This part is always needed by pintool, for example Zsim, Sniper.
When you meet the following situation, you should consider update your pin version even you can ignore this warning by use flags like -ifeellucky under high compatibility risk.
1 2 3
shaojiemike@snode6 ~/github/ramulator-pim/zsim-ramulator/pin [08:05:47] > ./pin E: 5.4 is not a supported linux release
because this will easily lead to the problem
1
Pin app terminated abnormally due to signal 6. # or signal 4.
Install pintool(zsim) by reconfig pin version
My first idea is try a compatible pin version (passd a simple test pintool, whatever) instead of the old pin.
Find the suitable simpler pintool can reproduce the situation (old pin failed, but newest pin is passed)
TODO: build(fix pin2.14 CXX_ABI compatibility bug), test suitability
debug the pin tool in details (See in another blog)
for (SEC sec = IMG_SecHead(img); SEC_Valid(sec); sec = SEC_Next(sec)) { for (RTN rtn = SEC_RtnHead(sec); RTN_Valid(rtn); rtn = RTN_Next(rtn)) { // Prepare for processing of RTN, an RTN is not broken up into BBLs, // it is merely a sequence of INSs RTN_Open(rtn);
for (INS ins = RTN_InsHead(rtn); INS_Valid(ins); ins = INS_Next(ins)) { count++; }
// to preserve space, release data associated with RTN after we have processed it RTN_Close(rtn); } }
IMG_AddInstrumentFunction() Use this to register a call back to catch the loading of an image
插桩不仅可以对每个指令插桩,还可以通过分类筛选后,只对符合要求的指令进行插桩
比如,使用INS_InsertPredicatedCall()
遍历所有的指令
1 2 3 4 5
// Forward pass over all instructions in bbl for( INS ins= BBL_InsHead(bbl); INS_Valid(ins); ins = INS_Next(ins) ) // Forward pass over all instructions in routine for( INS ins= RTN_InsHead(rtn); INS_Valid(ins); ins = INS_Next(ins) )
遍历trace内BBLs
1 2 3 4 5 6
// Visit every basic block in the trace for (BBL bbl = TRACE_BblHead(trace); BBL_Valid(bbl); bbl = BBL_Next(bbl)) { // Insert a call to docount before every bbl, passing the number of instructions BBL_InsertCall(bbl, IPOINT_BEFORE, (AFUNPTR)docount, IARG_UINT32, BBL_NumIns(bbl), IARG_END); }
遍历指令里的memOperands
1 2 3 4 5 6 7
UINT32 memOperands = INS_MemoryOperandCount(ins); // Iterate over each memory operand of the instruction. for (UINT32 memOp = 0; memOp < memOperands; memOp++){ if (INS_MemoryOperandIsRead(ins, memOp)||INS_MemoryOperandIsWritten(ins, memOp) //xxx }
// IPOINT_BEFORE 时运行的分析函数 VOID printip(VOID* ip) { fprintf(trace, "%p\n", ip); } // Pin calls this function every time a new instruction is encountered VOID InstructionFuc(INS ins, VOID* v) { // Insert a call to printip before every instruction, and pass it the IP // IARG_INST_PTR:指令地址 一类的全局变量??? INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)printip, IARG_INST_PTR, IARG_END); }
uname -a #intel64 cdsource/tools/ManualExamples # source/tools/Config/makefile.config list all make option make all OPT=-O0 DEBUG=1 TARGET=intel64 |tee make.log|my_hl # or just select one: make obj-intel64/inscount0.so # $(OBJDIR)%$(PINTOOL_SUFFIX) - Default rule for building tools. # Example: make obj-intel64/mytool.so
测试运行
1
../../../pin -t obj-intel64/inscount0.so -- ./a.out #正常统计指令数 to inscount.out
下面介绍Pin 提供的debug工具:
首先创建所需的-g的stack-debugger.so和应用fibonacci.exe
1 2
cdsource/tools/ManualExamples make OPT=-O0 DEBUG=1 stack-debugger.test
其中OPT=-O0选项来自官方文档Using Fast Call Linkages小节,说明需要OPT=-O0选项来屏蔽makefile中的-fomit-frame-pointer选项,使得GDB能正常显示stack trace(函数堆栈?)
Debug application in Pin JIT mode
1 2 3 4
$ ../../../pin -appdebug -t obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000 Application stopped until continued from debugger. Start GDB, then issue this command at the prompt: target remote :33030
static ADDRINT OnStackChangeIf(ADDRINT sp, ADDRINT addrInfo) { TINFO *tinfo = reinterpret_cast<TINFO *>(addrInfo); // The stack pointer may go above the base slightly. (For example, the application's dynamic // loader does this briefly during start-up.) // if (sp > tinfo->_stackBase) return0; // Keep track of the maximum stack usage. // size_t size = tinfo->_stackBase - sp; if (size > tinfo->_max) tinfo->_max = size; //更新stack使用大小 // See if we need to trigger a breakpoint. // if (BreakOnNewMax && size > tinfo->_maxReported) return1; if (BreakOnSize && size >= BreakOnSize) return1; return0; } static VOID DoBreakpoint(const CONTEXT *ctxt, THREADID tid) { TINFO *tinfo = reinterpret_cast<TINFO *>(PIN_GetContextReg(ctxt, RegTinfo)); // Keep track of the maximum reported stack usage for "stackbreak newmax". // size_t size = tinfo->_stackBase - PIN_GetContextReg(ctxt, REG_STACK_PTR); if (size > tinfo->_maxReported) tinfo->_maxReported = size; ConnectDebugger(); // Ask the user to connect a debugger, if it is not already connected. // Construct a string that the debugger will print when it stops. If a debugger is // not connected, no breakpoint is triggered and execution resumes immediately. // tinfo->_os.str(""); tinfo->_os << "Thread " << std::dec << tid << " uses " << size << " bytes of stack."; PIN_ApplicationBreakpoint(ctxt, tid, FALSE, tinfo->_os.str()); }
staticvoidConnectDebugger() { if (PIN_GetDebugStatus() != DEBUG_STATUS_UNCONNECTED) //判断是不是已有debugger连接 return; DEBUG_CONNECTION_INFO info; if (!PIN_GetDebugConnectionInfo(&info) || info._type != DEBUG_CONNECTION_TYPE_TCP_SERVER) //PIN_GetDebugConnectionInfo()获取GDB所需的tcp连接端口 return; *Output << "Triggered stack-limit breakpoint.\n"; *Output << "Start GDB and enter this command:\n"; *Output << " target remote :" << std::dec << info._tcpServer._tcpPort << "\n"; *Output << std::flush; if (PIN_WaitForDebuggerToConnect(1000*KnobTimeout.Value())) //等待其余GDB窗口的连接 return; *Output << "No debugger attached after " << KnobTimeout.Value() << " seconds.\n"; *Output << "Resuming application without stopping.\n"; *Output << std::flush; }
Tips for Debugging a Pintool
这部分讲述了如何debug Pintool中的问题。(对Pintool的原理也能更了解
为此,pin使用了-pause_tool n 暂停n秒等待gdb连接。
1 2 3 4 5 6 7 8
../../../pin -pause_tool 10 -t /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000 Pausing for 10 seconds to attach to process with pid 3502000 To load the debug info to gdb use: ***************************************************************** set sysroot /not/existing/dir file add-symbol-file /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so 0x7f3105f24170 -s .data 0x7f31061288a0 -s .bss 0x7f3106129280 *****************************************************************
(gdb) add-symbol-file /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so 0x7f3105f24170 -s .data 0x7f31061288a0 -s .bss 0x7f3106129280 (gdb) b main #或者 b stack-debugger.cpp:94 gef➤ info b Num Type Disp Enb Address What 1 breakpoint keep y <MULTIPLE> 1.1 y 0x00000000000f4460 <main> # 无法访问的地址,需要去除 1.2 y 0x00007f3105f36b65 in main(int, char**) at stack-debugger.cpp:94 (gdb) del 1.1 (gdb) c