IPCC Preliminary SLIC Analysis part4 : cluster environment
login node
id
1 | [sca3173@ln121%bscc-a5 ~]$ id sca3173 |
cpu
1 | Intel(R) Xeon(R) Silver 4208 CPU @ 2.10GHz |
slurm
1 | ON AVAIL TIMELIMIT NODES STATE NODELIST |
memery
1 | [sca3173@ln121%bscc-a5 ~]$ cat /proc/meminfo |
architecture
1 | [sca3173@ln121%bscc-a5 public1]$ lsb_release -d | awk -F"\t" '{print $2}' |
GPU 集显
1 | [sca3173@ln121%bscc-a5 public1]$ lshw -numeric -C display |
disk
1 | [sca3173@ln121%bscc-a5 public1]$ df -h /public1 |
IP 内网IP
1 | [sca3173@ln121%bscc-a5 public1]$ hostname -I | awk '{print $1}' |
compute node
1 | > cat lscpu.txt |

没有gcc/7.3.0
比赛是2节点128核的环境
计算节点网络拓扑图
我们是A5 分区。
没有找到手册,只有一个官网图。但是虽然频率是2.35GHz,但是内存只有251GB啊,什么情况。






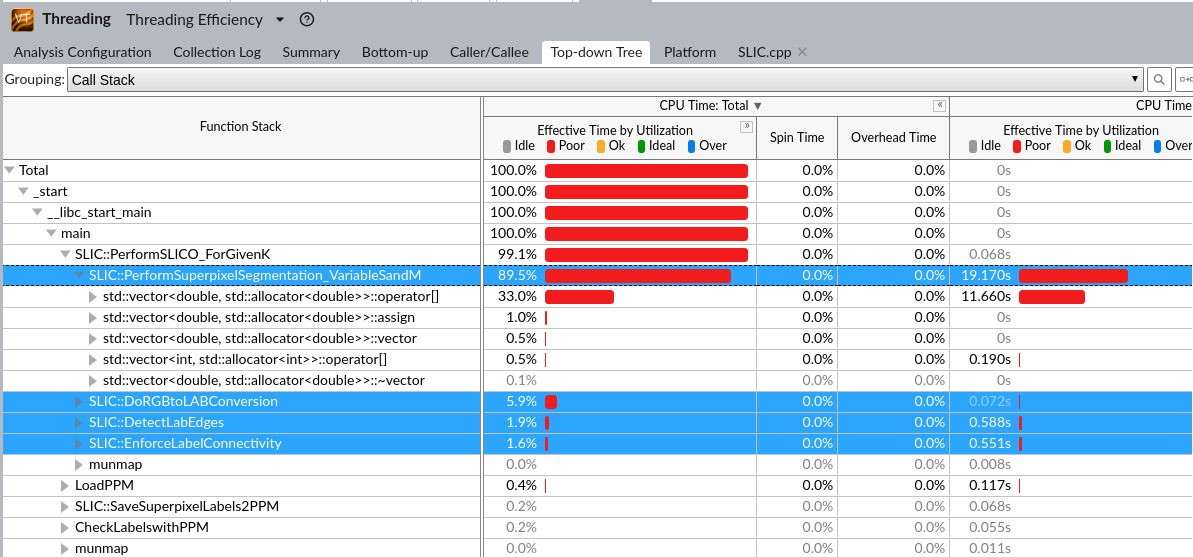

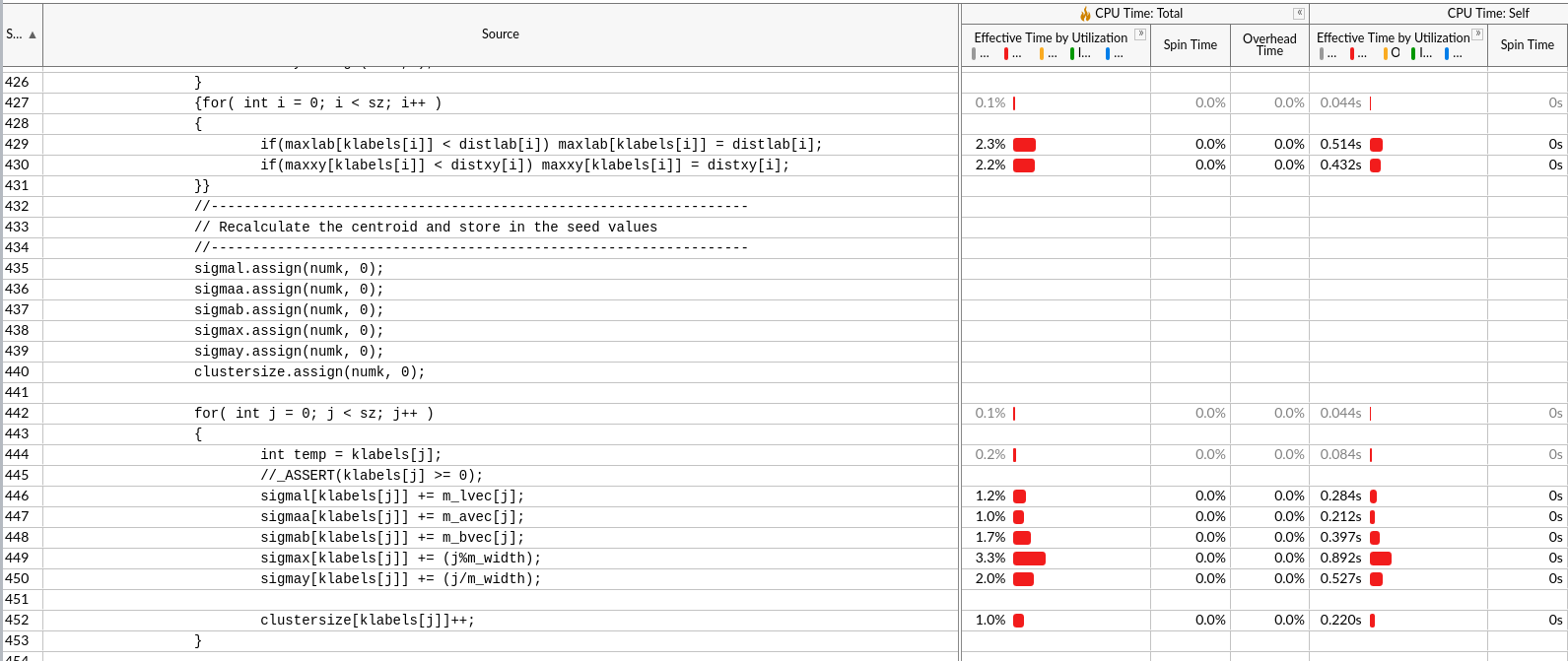



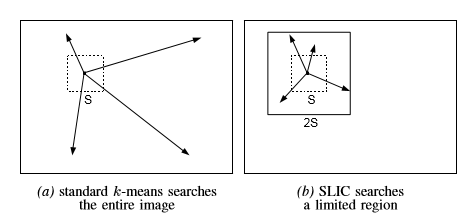
 由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。
由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。