This section holds the procedure linkage table. See ‘‘Special Sections’’ in Part 1 and ‘‘Procedure Linkage Table’’ in Part 2 for more information.
Function symbols (those with type STT_FUNC) in shared object files have special significance. When another object file references a function from a shared object, the link editor automatically creates a procedure linkage table entry for the referenced symbol.
### critical vs atomic The fastest way is neither critical nor atomic. Approximately, addition with critical section is 200 times more expensive than simple addition, atomic addition is 25 times more expensive then simple addition.(**maybe no so much expensive**, the atomic operation will have a few cycle overhead (synchronizing a cache line) on the cost of roughly a cycle. A critical section incurs **the cost of a lock**.)
The fastest option (not always applicable) is to give each thread its own counter and make reduce operation when you need total sum.
### critical vs ordered omp critical is for mutual exclusion(互斥), omp ordered refers to a specific loop and ensures that the region **executes sequentually in the order of loop iterations**. Therefore omp ordered is stronger than omp critical, but also only makes sense within a loop.
omp ordered has some other clauses, such as simd to enforce the use of a single SIMD lane only. You can also specify dependencies manually with the depend clause.
Note: Both omp critical and omp ordered regions have an implicit memory flush at the entry and the exit.
### ordered example
vector<int> v;
#pragma omp parallel for ordered schedule(dynamic, anyChunkSizeGreaterThan1) for (int i = 0; i < n; ++i){ … … … #pragma omp ordered v.push_back(i); }
1 2 3 4 5 6
``` tid List of Timeline iterations 0 0,1,2 ==o==o==o 1 3,4,5 ==.......o==o==o 2 6,7,8 ==..............o==o==o
= shows that the thread is executing code in parallel. o is when the thread is executing the ordered region. . is the thread being idle, waiting for its turn to execute the ordered region.
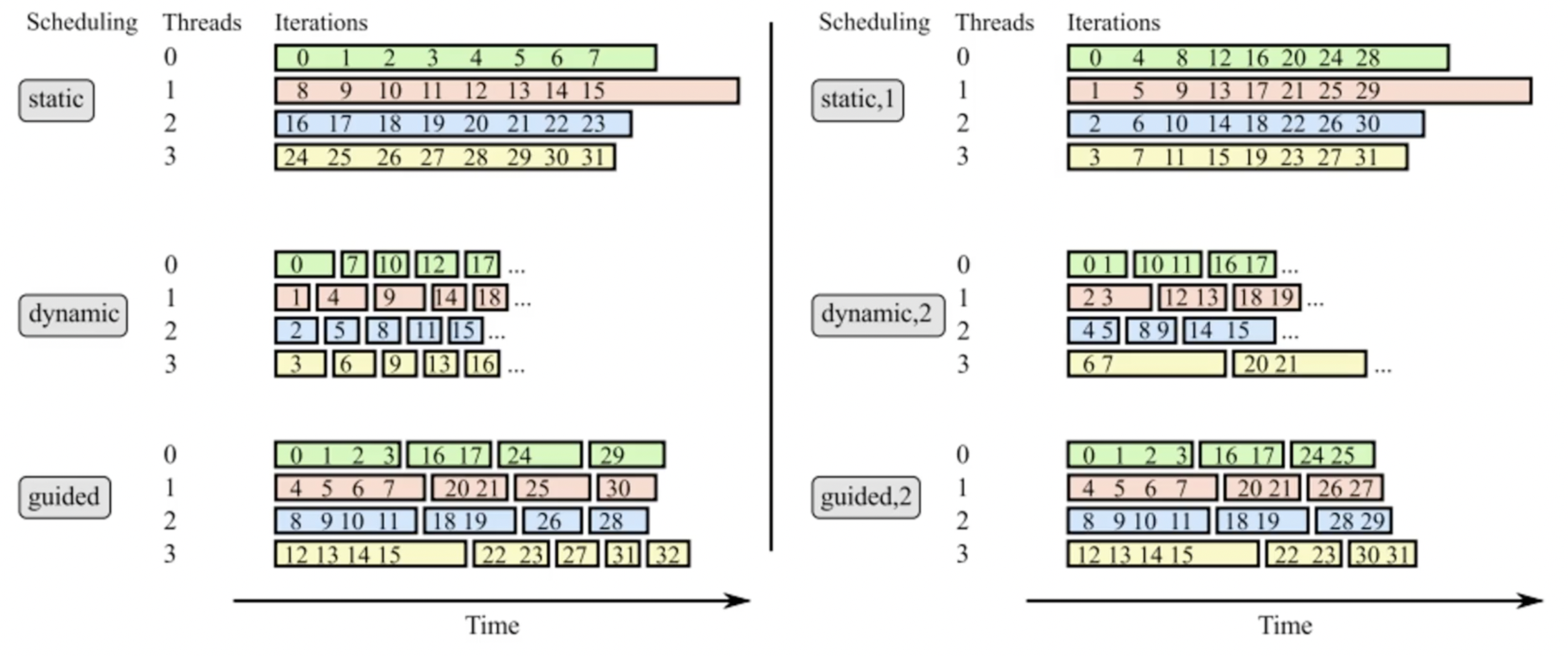
With schedule(static,1) the following would happen:
1 2 3 4 5
tid List of Timeline iterations 0 0,3,6 ==o==o==o 1 1,4,7 ==.o==o==o 2 2,5,8 ==..o==o==o
private variables are not initialised, i.e. they start with random values like any other local automatic variable
firstprivate initial the value as the before value.
lastprivate save the value to the after region. 这个last的意思不是实际最后运行的一个线程,而是调度发射队列的最后一个线程。从另一个角度上说,如果你保存的值来自随机一个线程,这也是没有意义的。 firstprivate and lastprivate are just special cases of private
1 2 3 4 5 6 7
#pragma omp parallel { #pragma omp for lastprivate(i) for (i=0; i<n-1; i++) a[i] = b[i] + b[i+1]; } a[i]=b[i];
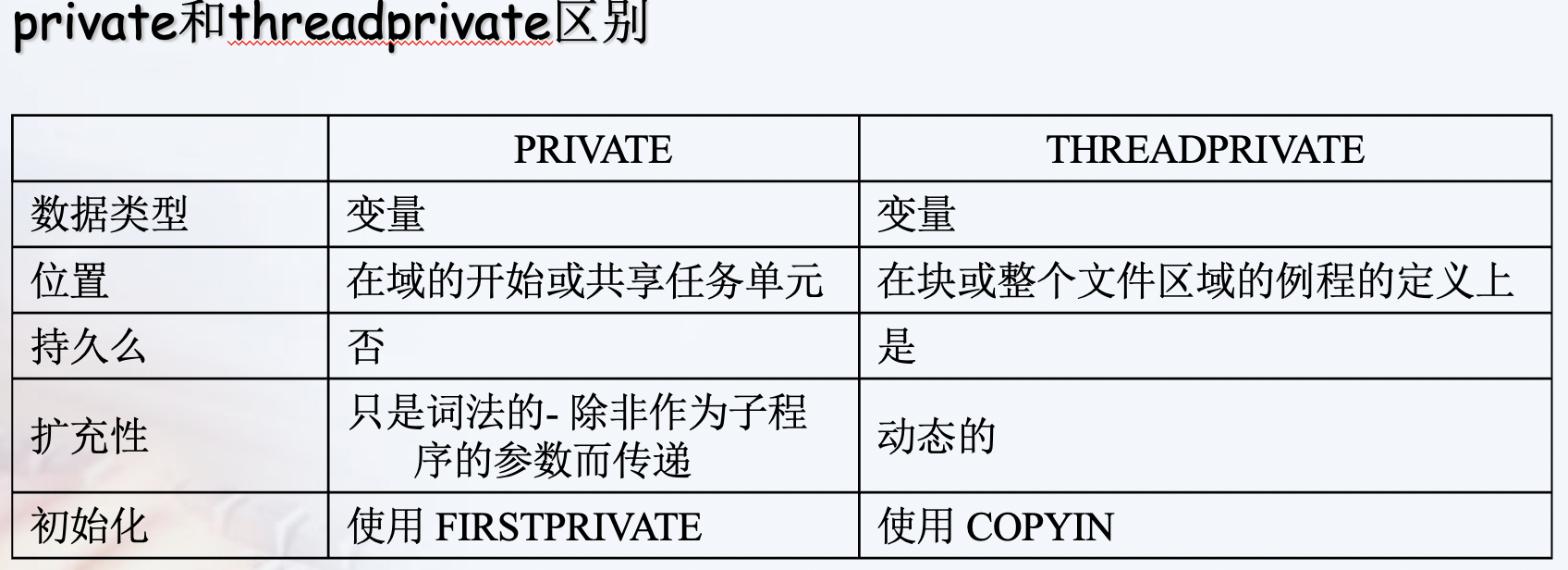
private vs threadprivate
A private variable is local to a region and will most of the time be placed on the stack. The lifetime of the variable’s privacy is the duration defined of the data scoping clause. Every thread (including the master thread) makes a private copy of the original variable (the new variable is no longer storage-associated with the original variable).
A threadprivate variable on the other hand will be most likely placed in the heap or in the thread local storage (that can be seen as a global memory local to a thread). A threadprivate variable persist across regions (depending on some restrictions). The master thread uses the original variable, all other threads make a private copy of the original variable (the master variable is still storage-associated with the original variable).
double result = 0; #pragma omp parallel num_threads(ndata) { double local_result; int num = omp_get_thread_num(); if (num==0) local_result = f(x); elseif (num==1) local_result = g(x); elseif (num==2) local_result = h(x); #pragma omp critical result += local_result; }
double result = 0; #pragma omp parallel { double local_result; #pragma omp for for (i=0; i<N; i++) { local_result = f(x,i); #pragma omp critical result += local_result; } // end of for loop }
intmymax(int r,int n) { // r is the already reduced value // n is the new value int m; if (n>r) { m = n; } else { m = r; } return m; } #pragma omp declare reduction \ (rwz:int:omp_out=mymax(omp_out,omp_in)) \ initializer(omp_priv=INT_MIN) m = INT_MIN; #pragma omp parallel for reduction(rwz:m) for (int idata=0; idata<ndata; idata++) m = mymax(m,data[idata]);