超算机器用vtune的命令行文件分析
首先找到vtune程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14> module load intel/2022.1
> which icc
/public1/soft/oneAPI/2022.1/compiler/latest/linux/bin/intel64/icc
> cd /public1/soft/oneAPI/2022.1
> find . -executable -type f -name "*vtune*"
./vtune/2022.0.0/bin64/vtune-worker-crash-reporter
./vtune/2022.0.0/bin64/vtune-gui.desktop
./vtune/2022.0.0/bin64/vtune-gui
./vtune/2022.0.0/bin64/vtune-agent
./vtune/2022.0.0/bin64/vtune-self-checker.sh
./vtune/2022.0.0/bin64/vtune-backend
./vtune/2022.0.0/bin64/vtune-worker
./vtune/2022.0.0/bin64/vtune
./vtune/2022.0.0/bin64/vtune-set-perf-caps.shvtune-gui获取可执行命令1
/opt/intel/oneapi/vtune/2021.1.1/bin64/vtune -collect hotspots -knob enable-stack-collection=true -knob stack-size=4096 -data-limit=1024000 -app-working-dir /home/shaojiemike/github/IPCC2022first/build/bin -- /home/shaojiemike/github/IPCC2022first/build/bin/pivot /home/shaojiemike/github/IPCC2022first/src/uniformvector-2dim-5h.txt
编写
sbatch_vtune.sh1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#SBATCH -o ./slurmlog/job_%j_rank%t_%N_%n.out
#SBATCH -p IPCC
#SBATCH -t 15:00
#SBATCH --nodes=1
#SBATCH --exclude=
#SBATCH --cpus-per-task=64
#SBATCH --mail-type=FAIL
#SBATCH [email protected]
source /public1/soft/modules/module.sh
module purge
module load intel/2022.1
logname=vtune
export OMP_PROC_BIND=close; export OMP_PLACES=cores
# ./pivot |tee ./log/$logname
/public1/soft/oneAPI/2022.1/vtune/2022.0.0/bin64/vtune -collect hotspots -knob enable-stack-collection=true -knob stack-size=4096 -data-limit=1024000 -app-working-dir /public1/home/ipcc22_0029/shaojiemike/slurm -- /public1/home/ipcc22_0029/shaojiemike/slurm/pivot /public1/home/ipcc22_0029/shaojiemike/slurm/uniformvector-2dim-5h.txt |tee ./log/$lognamelog文件如下,但是将生成的trace文件
r000hs导入识别不了AMD1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22> cat log/vtune
dim = 2, n = 500, k = 2
Using time : 452.232000 ms
max : 143 351 58880.823709
min : 83 226 21884.924801
Elapsed Time: 0.486s
CPU Time: 3.540s
Effective Time: 3.540s
Spin Time: 0s
Overhead Time: 0s
Total Thread Count: 8
Paused Time: 0s
Top Hotspots
Function Module CPU Time % of CPU Time(%)
--------------- ------ -------- ----------------
SumDistance pivot 0.940s 26.6%
_mm256_add_pd pivot 0.540s 15.3%
_mm256_and_pd pivot 0.320s 9.0%
_mm256_loadu_pd pivot 0.300s 8.5%
Combination pivot 0.250s 7.1%
[Others] N/A 1.190s 33.6%
汇编
1 | objdump -Sd ../build/bin/pivot > pivot1.s |
汇编分析技巧
https://blog.csdn.net/thisinnocence/article/details/80767776
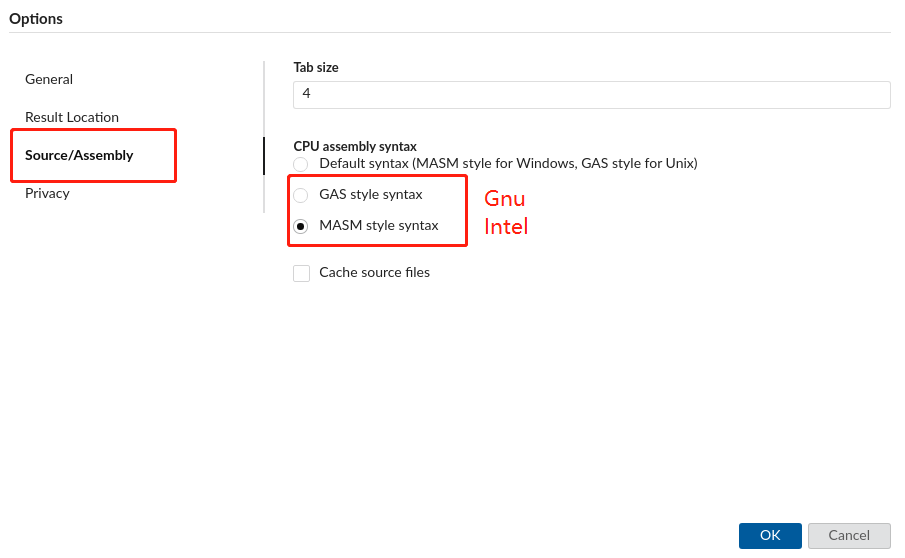
如何设置GNU和Intel汇编语法
vtune汇编实例
(没有开O3,默认值)
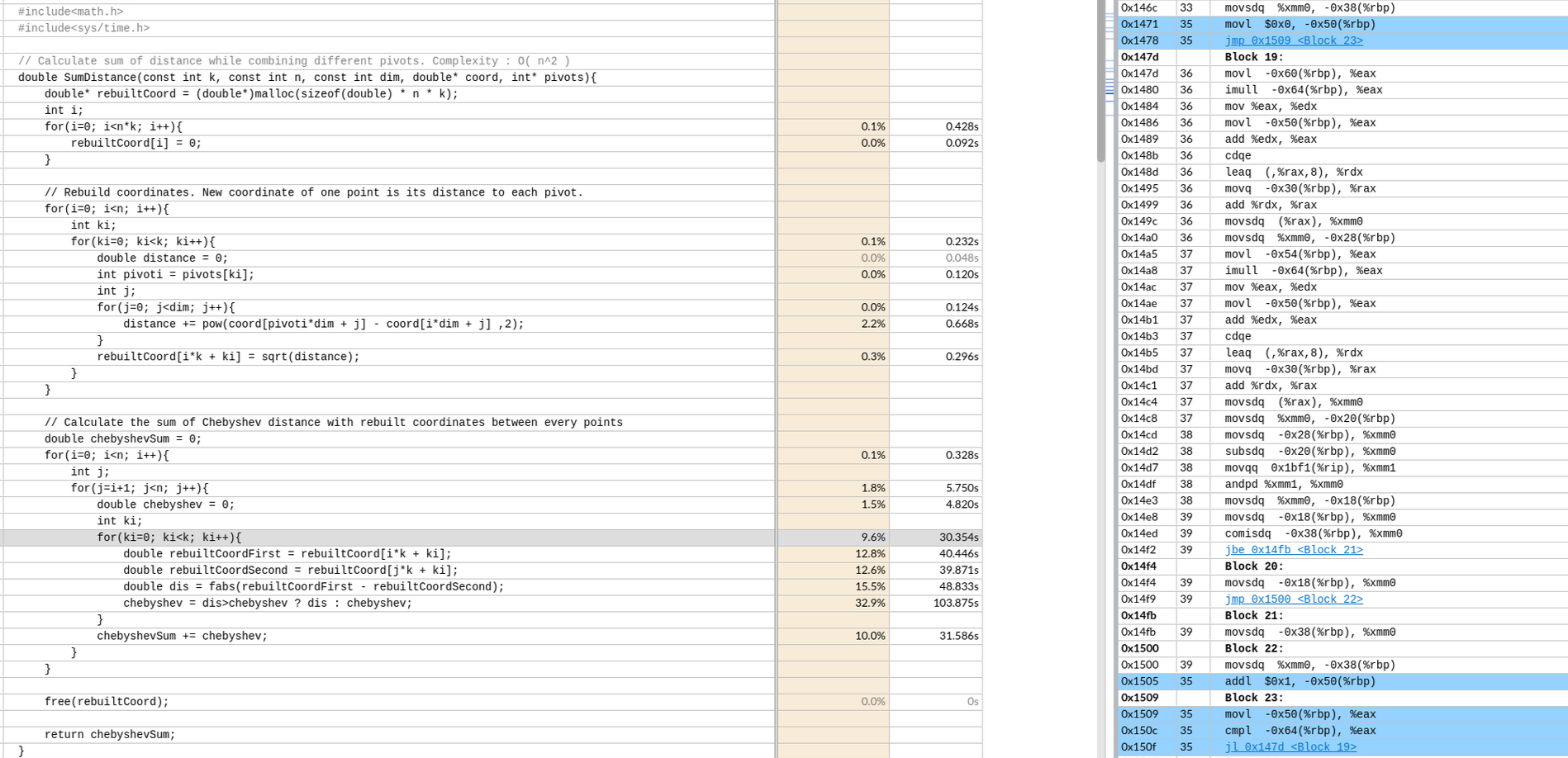
偏移 -64 是k
-50 是ki
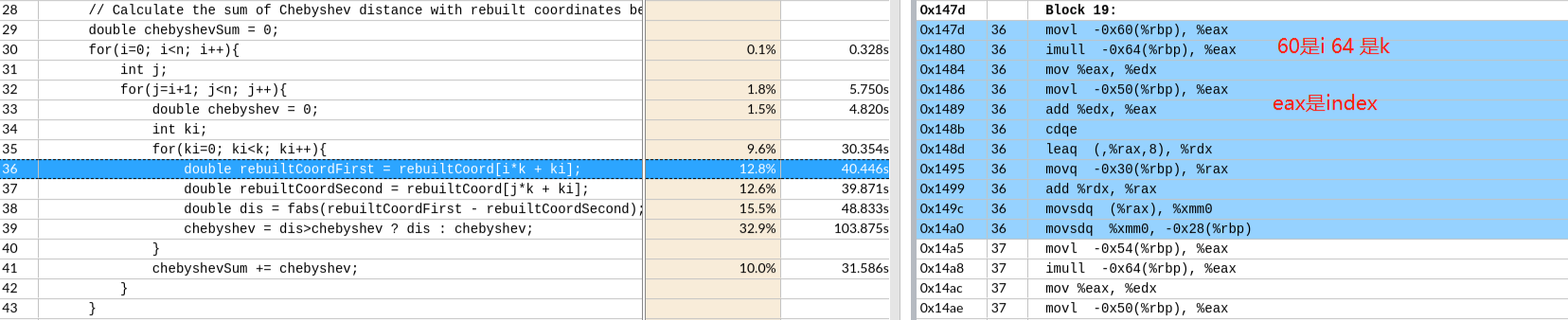
CDQE复制EAX寄存器双字的符号位(bit 31)到RAX的高32位。

这里的movsdq的q在intel里的64位,相当于使用了128位的寄存器,做了64位的事情,并没有自动向量化。
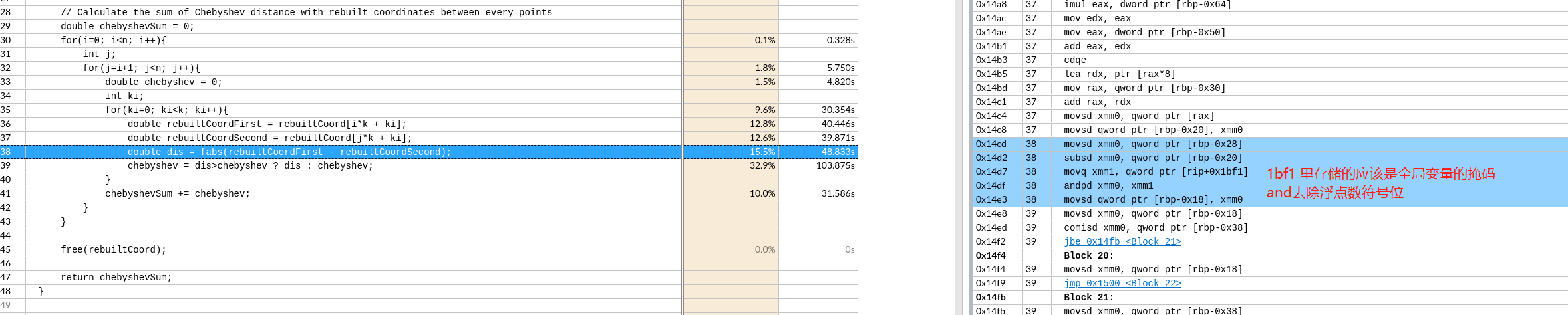
生成带代码注释的O3汇编代码
如果想把 C 语言变量的名称作为汇编语言语句中的注释,可以加上 -fverbose-asm 选项:
1 | gcc -S -O3 -fverbose-asm ../src/pivot.c -o pivot_O1.s |
1 | .L15: |
vtune O3汇编分析
原本以为O3是看不了原代码与汇编的对应关系的,但实际可以-g -O3 是不冲突的。
指令的精简合并
- 访存指令的合并
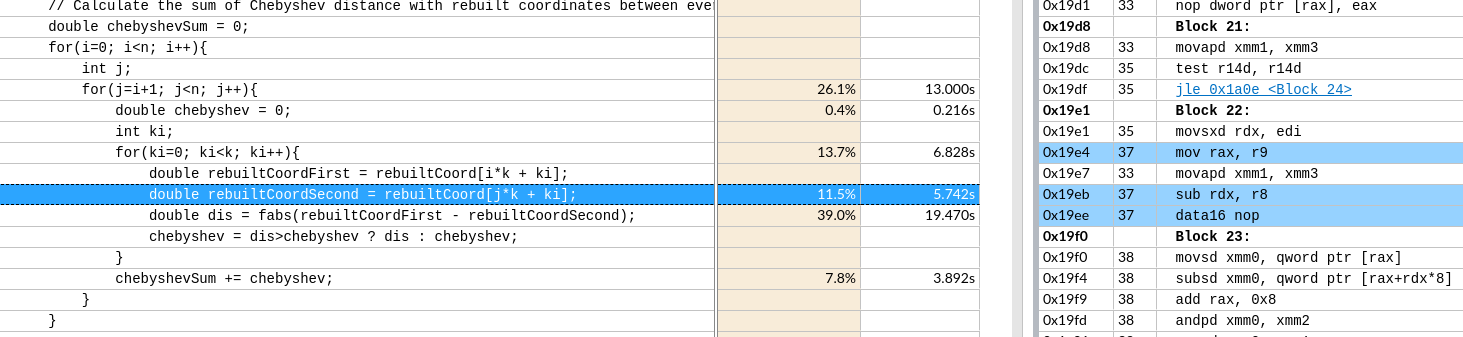
- 将
r9mov到rax里,- 又
leaq (%r12,%r8,8), %r9。其中r12是rebuiltCoord,所以r8原本存储的是[i*k]的值 rax是rebuiltCoord+[i*k]的地址,由于和i有关,index的计算在外层就计算好了。
- 又
rdx的值减去r8存储在rdx里rdx原本存储的是[j*k]的地址r8原本存储的是[i*k]的值rdx之后存储的是[(j-i)*k]的地址
data16 nop是为了对齐插入的nop
- 将
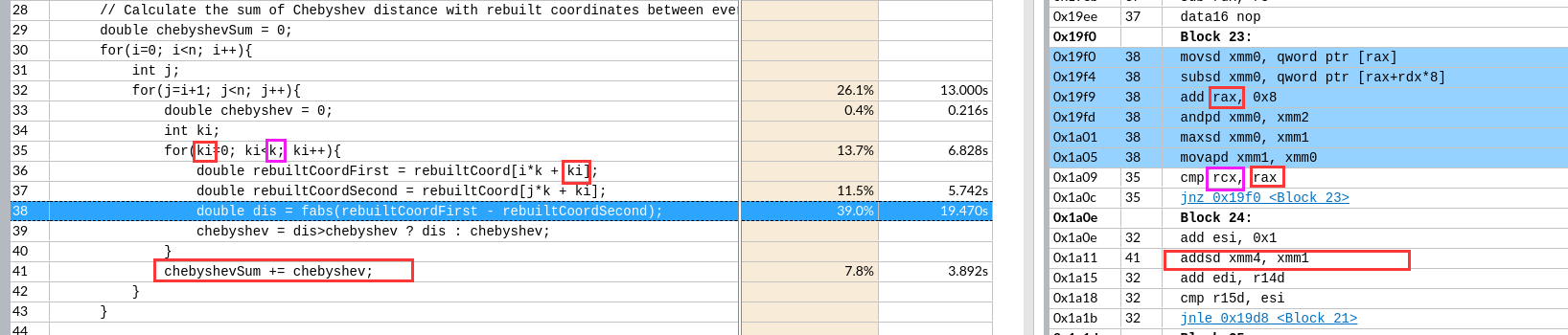
- 值得注意的是取最大值操作,这里变成了
maxsd xmm0是缓存值xmm1是chebyshevxmm2是fabs的掩码xmm4是chebyshevSum
- 值得注意的是取最大值操作,这里变成了
自动循环展开形成流水
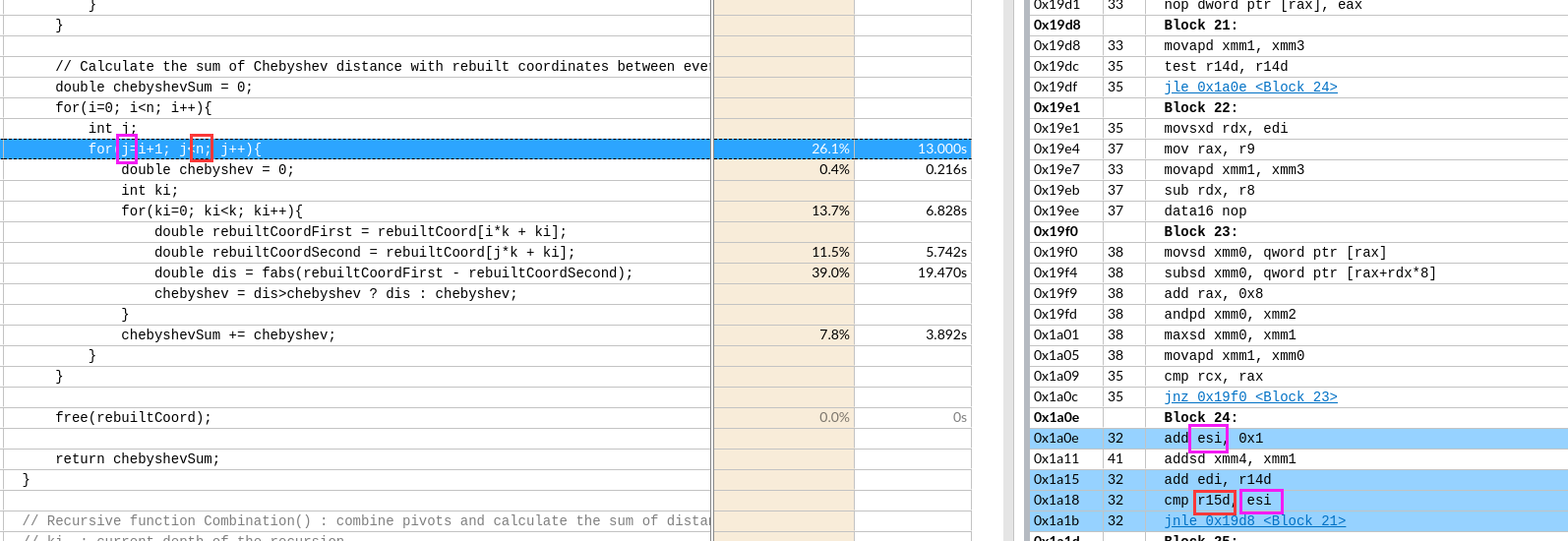
r14d存储k的值,所以edi存储j*k值- Block22后的指令验证了
rdx原本存储的是[j*k]的地址
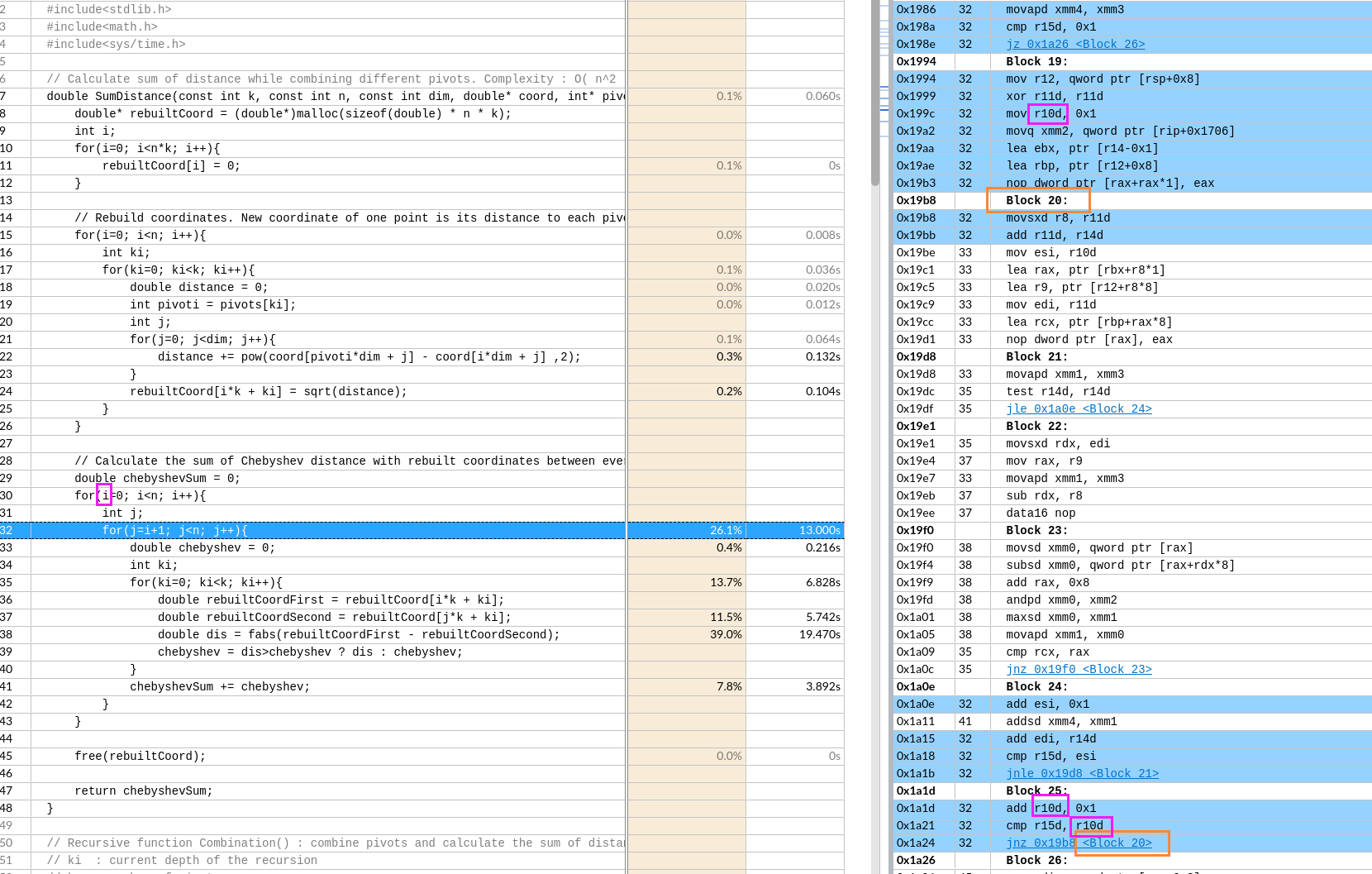
- 最外层循环
- 因为
r14d存储k的值,r8和r11d存储了i*k的值
从汇编看不出有该操作,需要开启编译选项
自动向量化
从汇编看不出有该操作,需要开启编译选项
自动数据预取
从汇编看不出有该操作,需要开启编译选项
问题
为什么求和耗时这么多
添加向量化选项
gcc
Baseline

-mavx2 -march=core-avx2

- 阅读文档, 虽然全部变成了
vmov,vadd的操作,但是实际还是64位的工作。- 这点
add rax, 0x8没有变成add rax, 0x16可以体现 - 但是avx2不是256位的向量化吗?用的还是xmm0这类的寄存器。
- 这点
1 | VADDSD (VEX.128 encoded version) |
-march=skylake-avx512
汇编代码表面没变,但是快了10s(49s - 39s)
下图是avx2的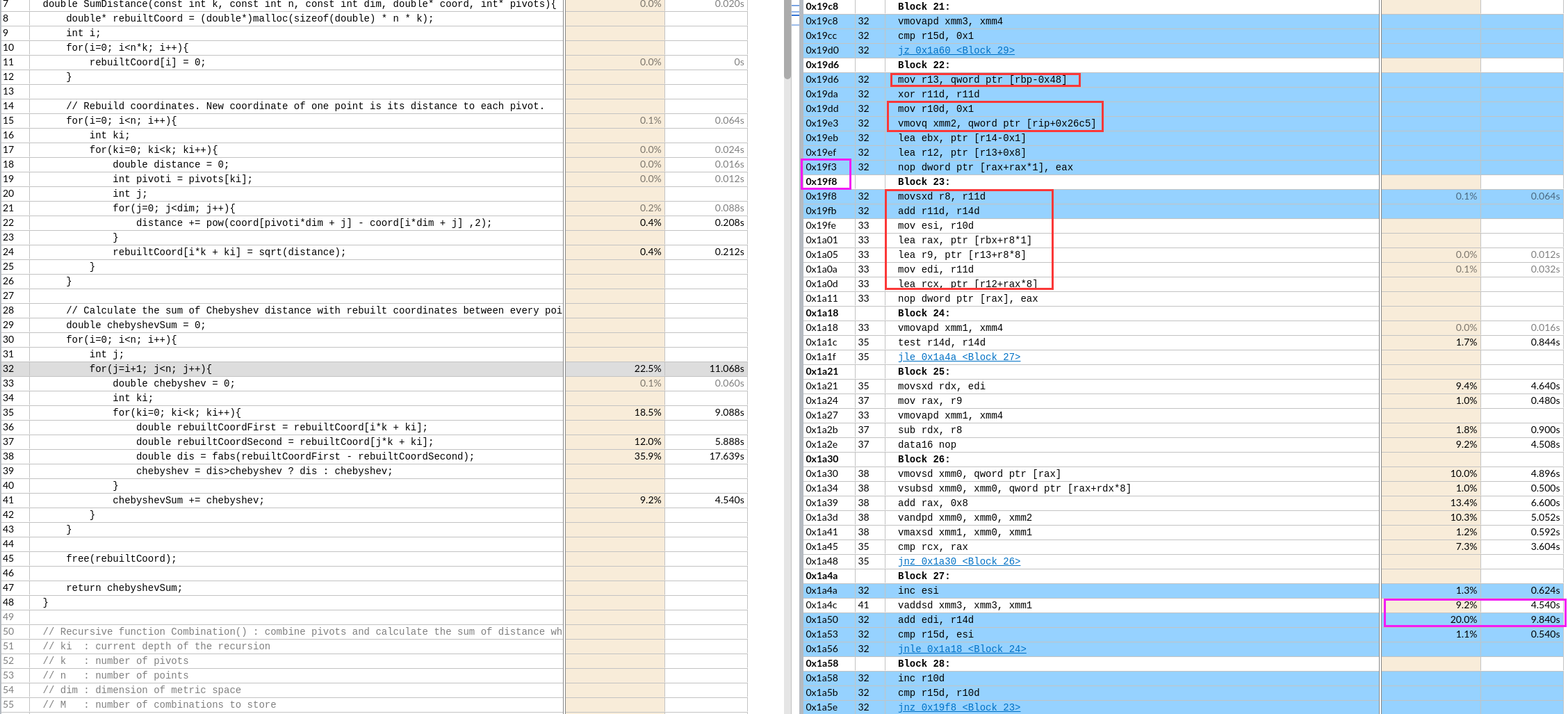
下图是avx512的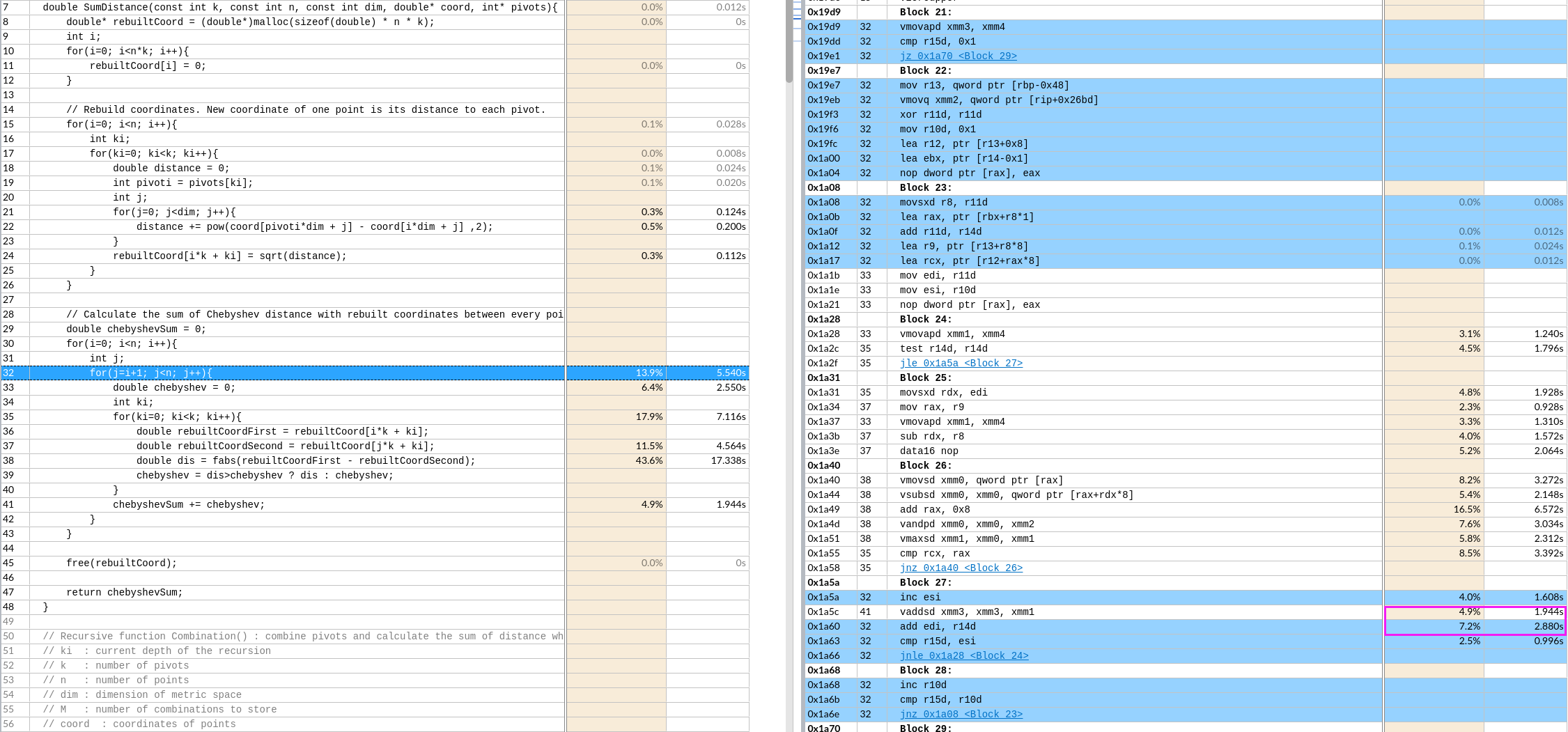
猜测注意原因是
- nop指令导致代码没对齐
- 不太可能和红框里的代码顺序有关
添加数据预取选项
判断机器是否支持
1 | lscpu|grep pref |
应该是支持的
汇编分析
虽然时间基本没变,主要是对主体循环没有进行预取操作,对其余循环(热点占比少的)有重新调整。如下图增加了预取指令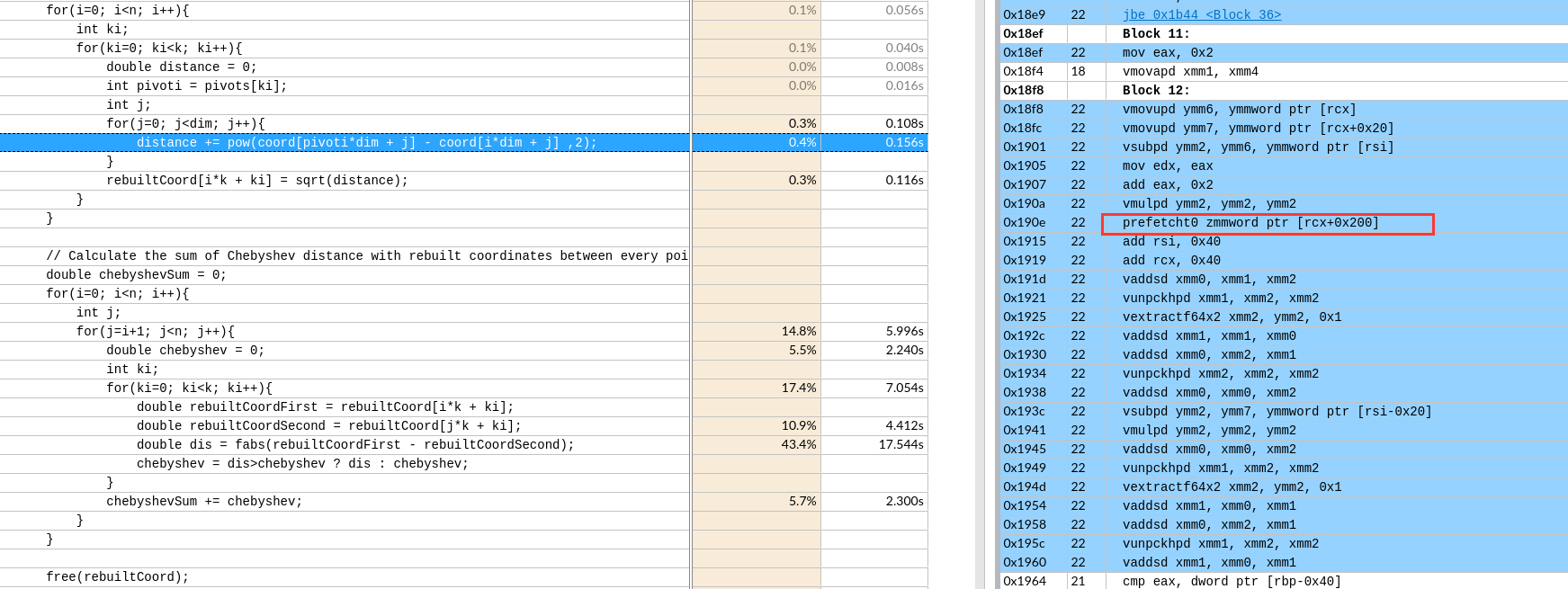
添加循环展开选项
变慢很多(39s -> 55s)
-funroll-loops
汇编实现,在最内层循环根据k的值直接跳转到对应的展开块,这里k是2。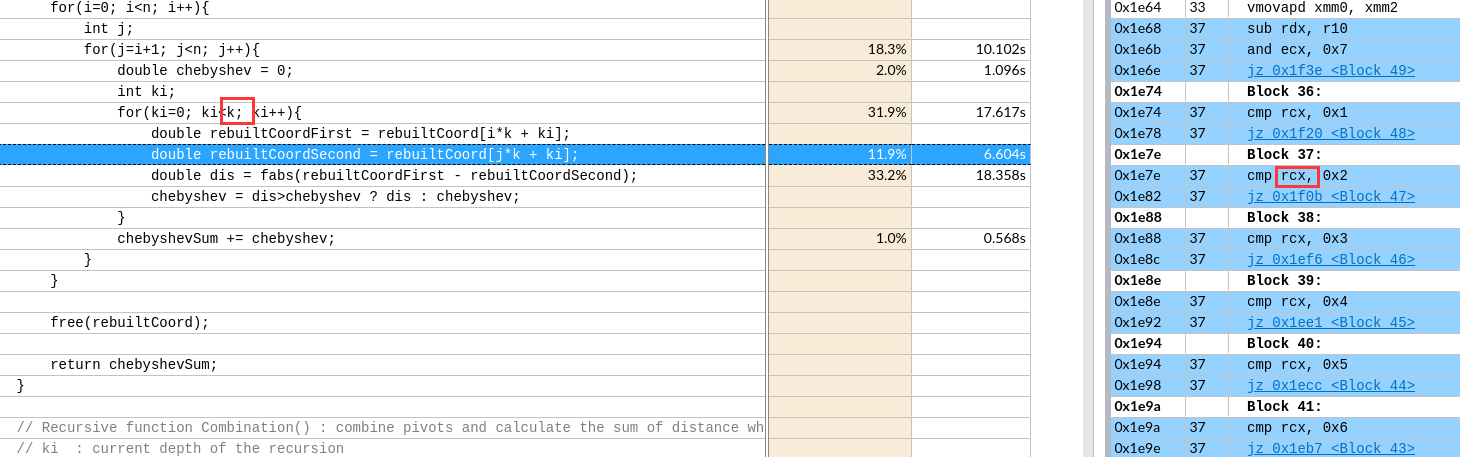
默认是展开了8层,这应该和xmm寄存器总数有关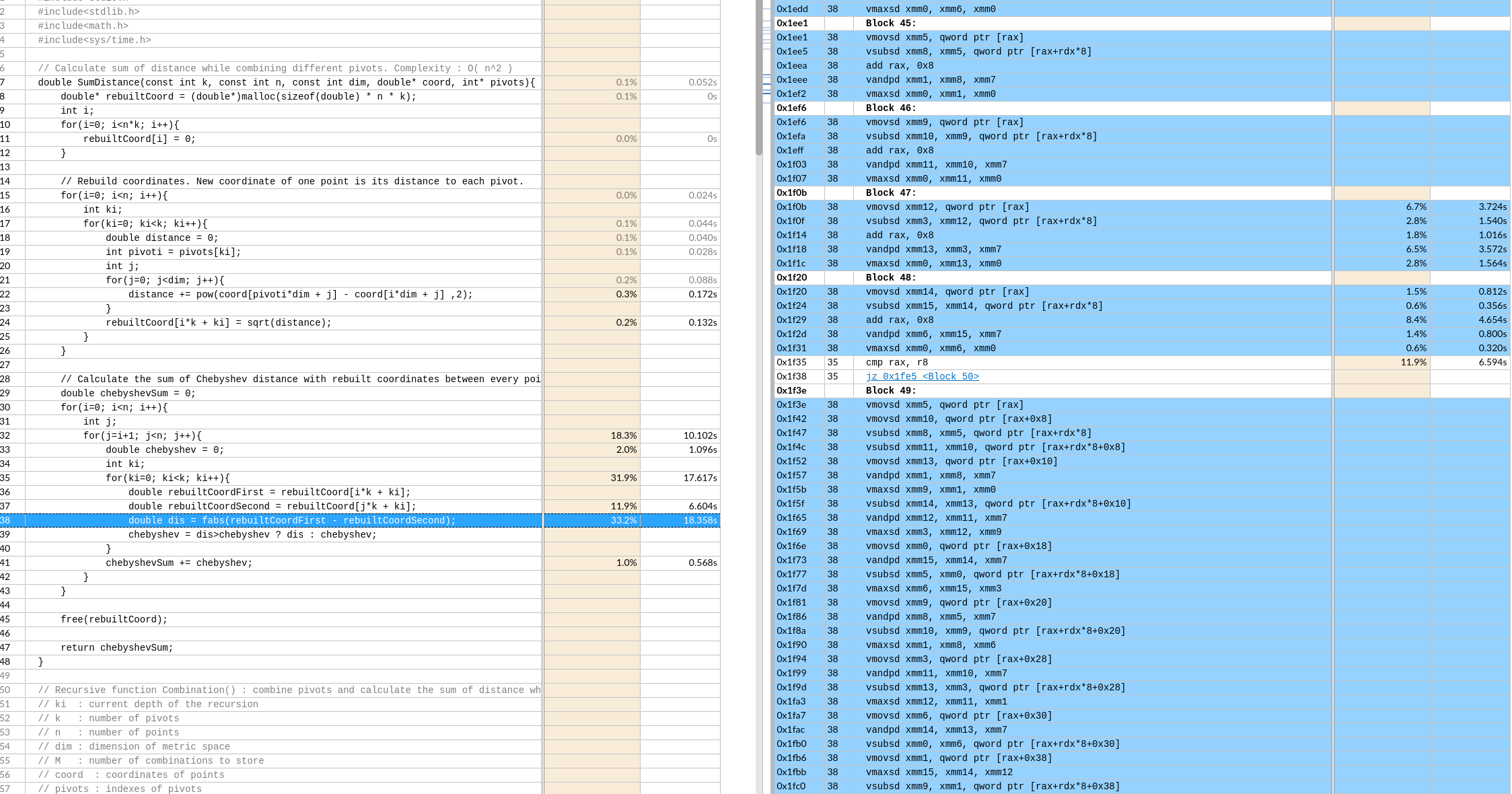
分析原因
- 循环展开的核心是形成计算和访存的流水
- 不是简单的少几个跳转指令
- 这种简单堆叠循环核心的循环展开,并不能形成流水。所以时间不会减少
- 但是完全无法解释循环控制的时间增加
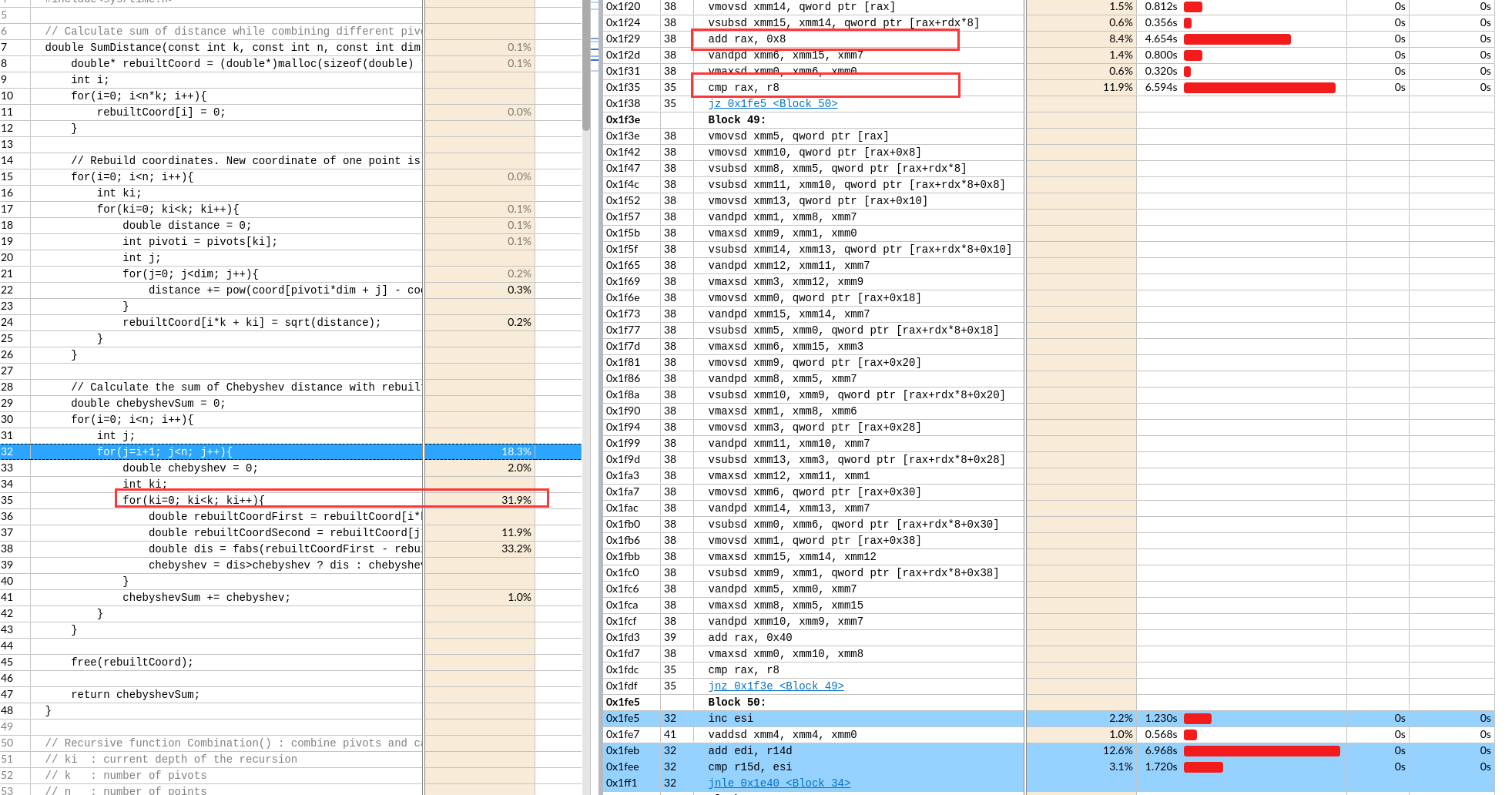
- 比如图中cmp的次数应该减半了,时间反而翻倍了
手动分块
由于数据L1能全部存储下,没有提升
手动数据预取
并没有形成想象中预取的流水。每512位取,还有重复。
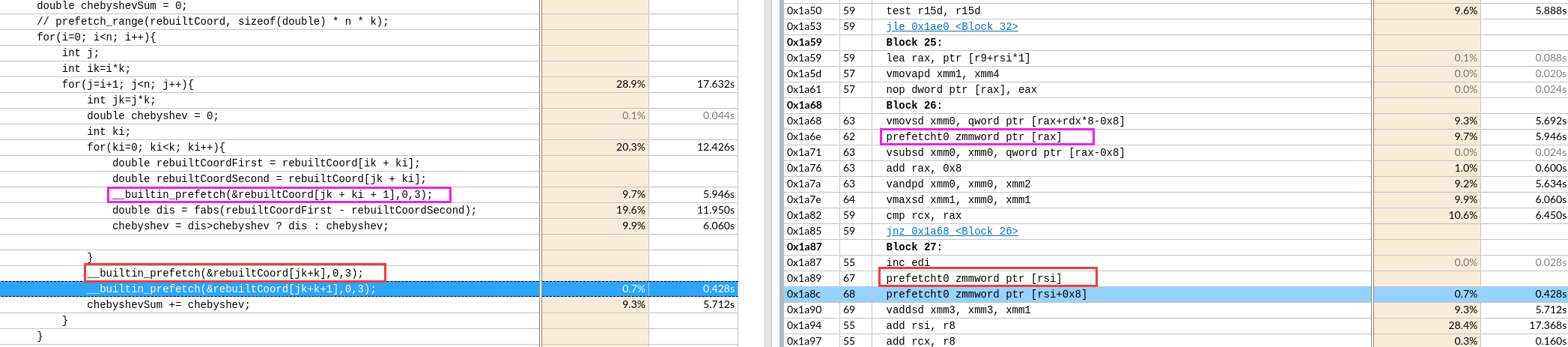
每次预取一个Cache Line,后面两条指令预取的数据还有重复部分(导致时间增加 39s->61s)
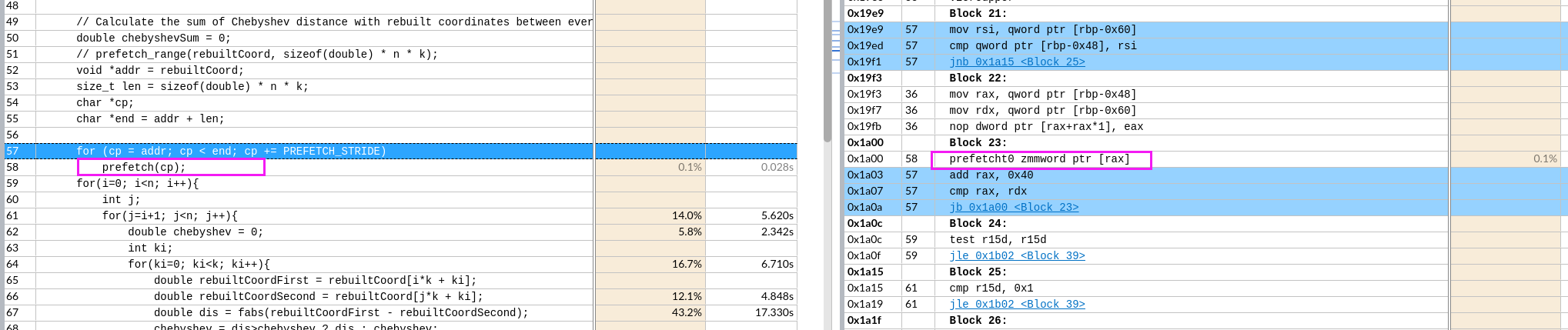
想预取全部,循环每次预取了512位=64字节
手动向量化
avx2
(能便于编译器自动展开来使用所有的向量寄存器,avx2
39s -> 10s -> 8.4s 编译器
1 | for(i=0; i<n-blockSize; i+=blockSize){ |
明明展开了一次,但是编译器继续展开了,总共8次。用满了YMM 16个向量寄存器。
下图是avx512,都出现寄存器ymm26了。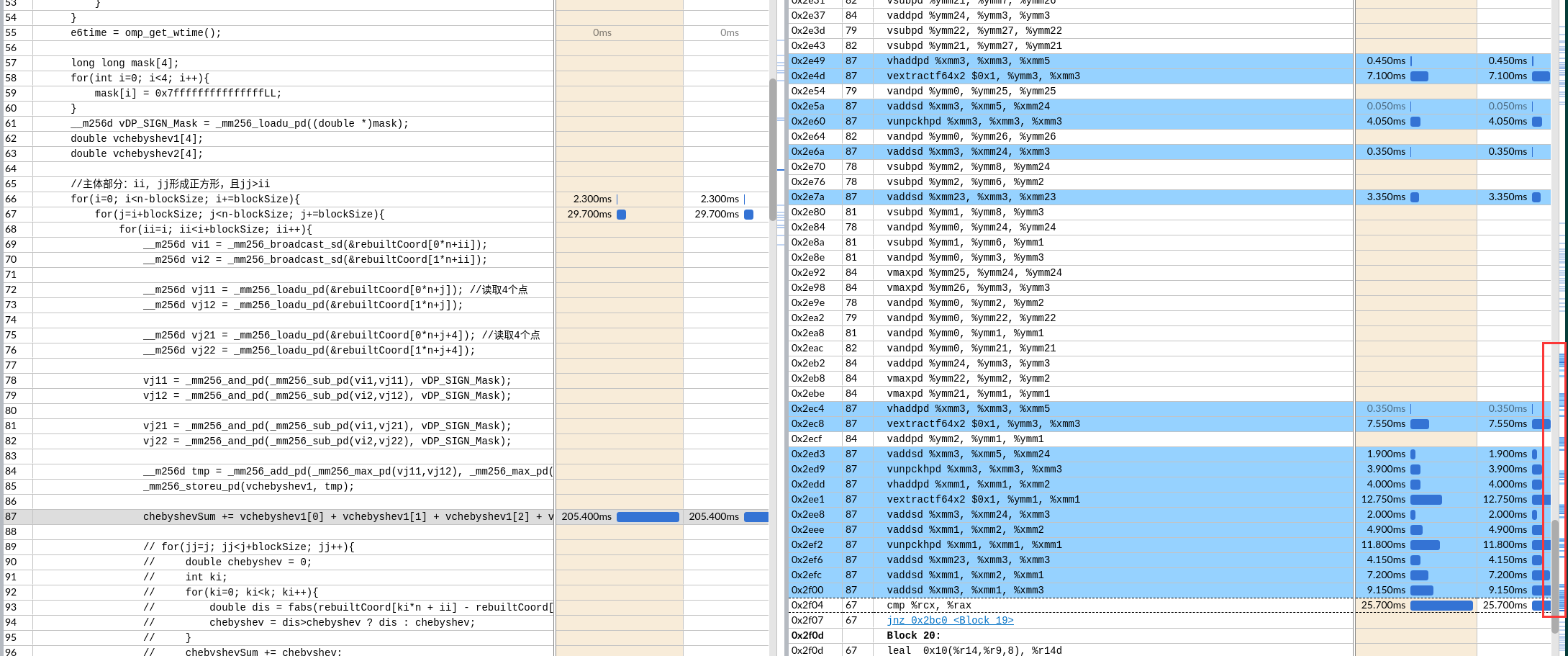
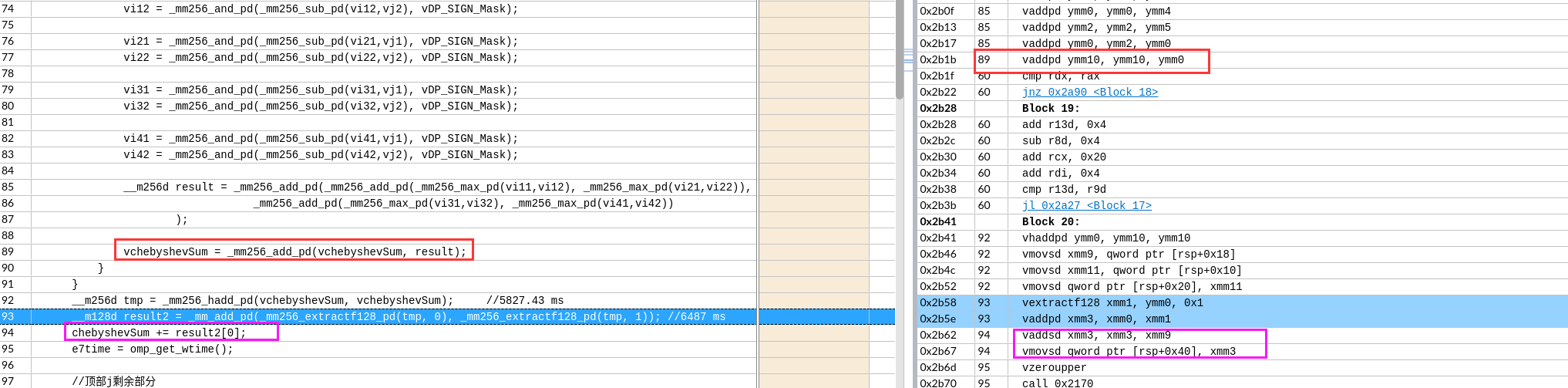
vhaddpd是水平的向量内加法指令
avx512
当在avx512的情况下展开4次,形成了相当工整的代码。
- 向量用到了寄存器
ymm18,估计只能展开到6次了。- avx2 应该寄存器不够
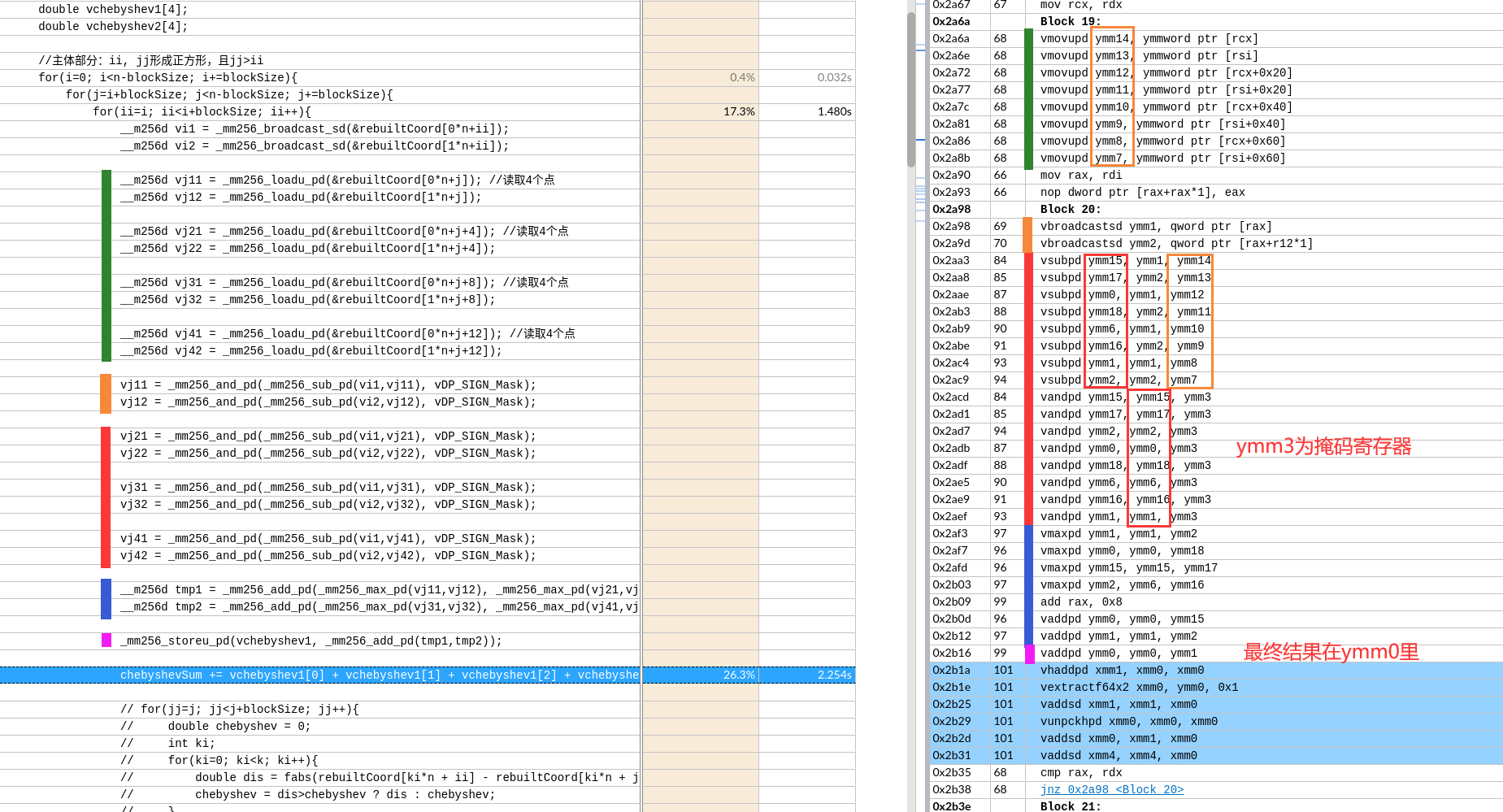
- avx2 应该寄存器不够
最后求和的处理,编译器首先识别出了,不需要实际store。还是在寄存器层面完成了计算。并且通过三次add和两次数据 移动指令自动实现了二叉树型求和。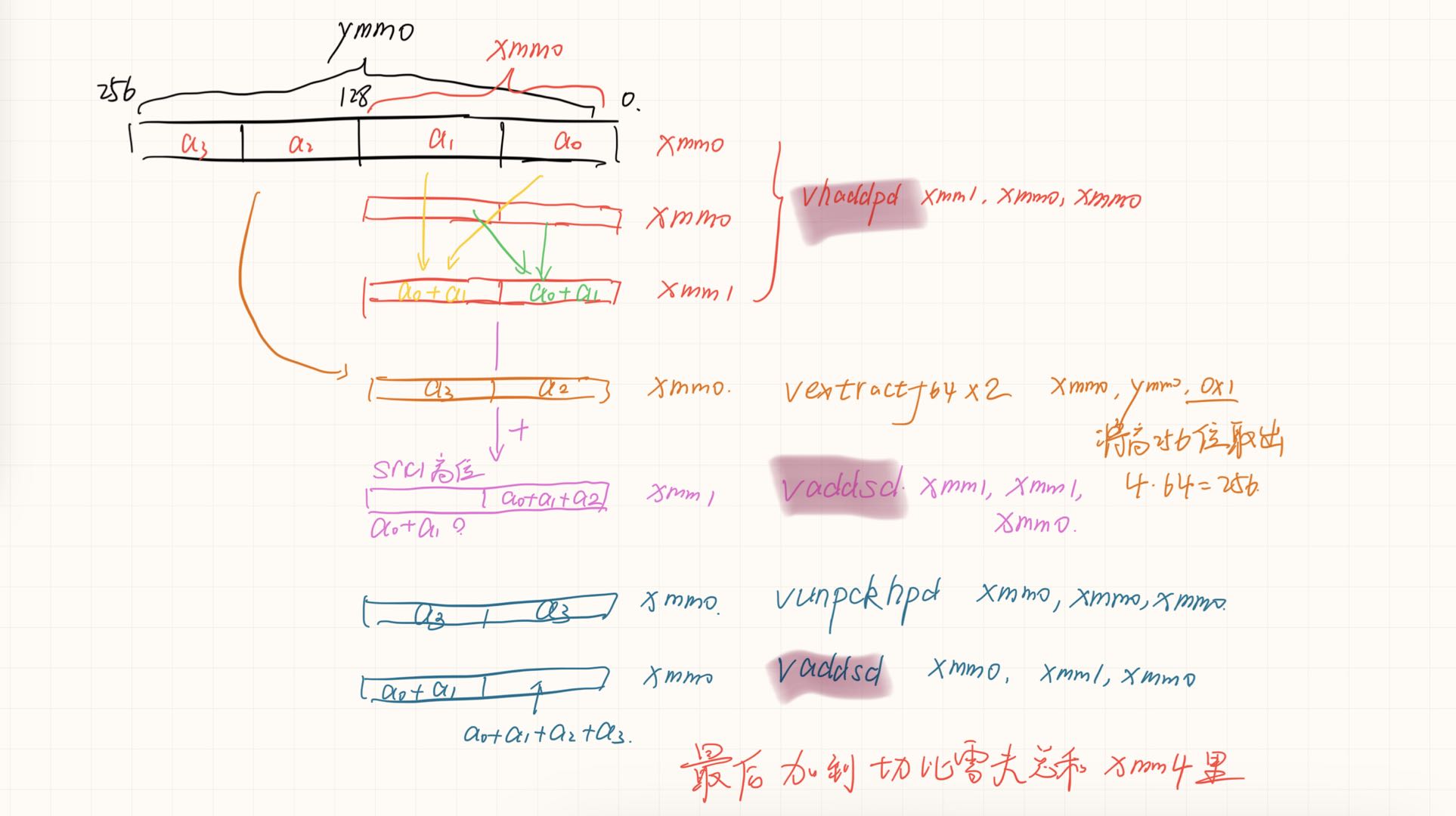
avx2 寄存器不够会出现下面的情况。
avx求和的更快速归约
假如硬件存在四个一起归约的就好了,但是对于底层元件可能过于复杂了。
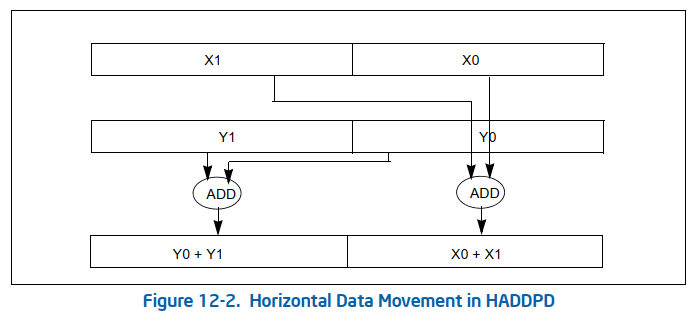
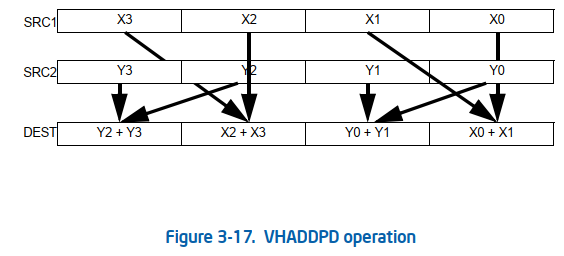
1 | __m256d _mm256_hadd_pd (__m256d a, __m256d b); |
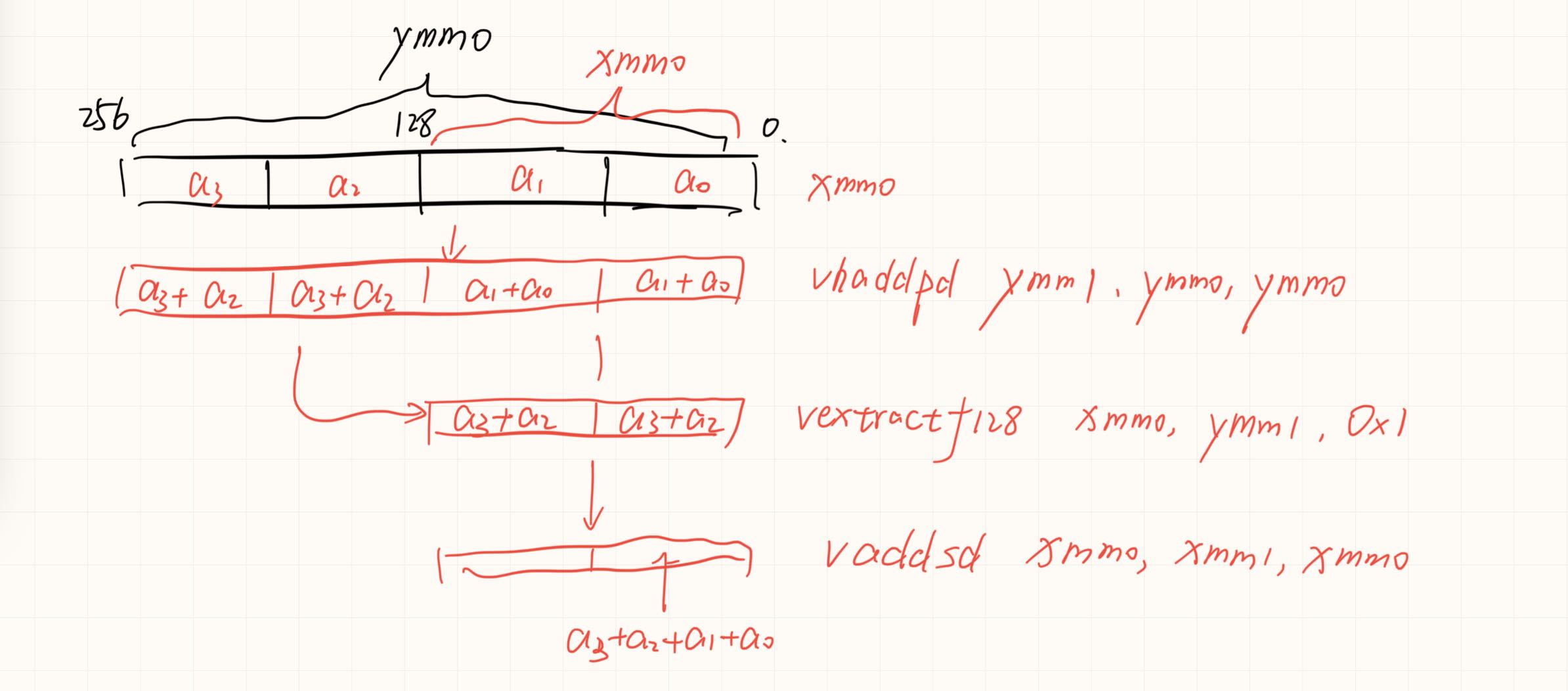
如果可以实现会节约一次数据移动和一次数据add。没有分析两种情况的寄存器依赖。可能依赖长度是一样的,导致优化后时间反而增加一点。
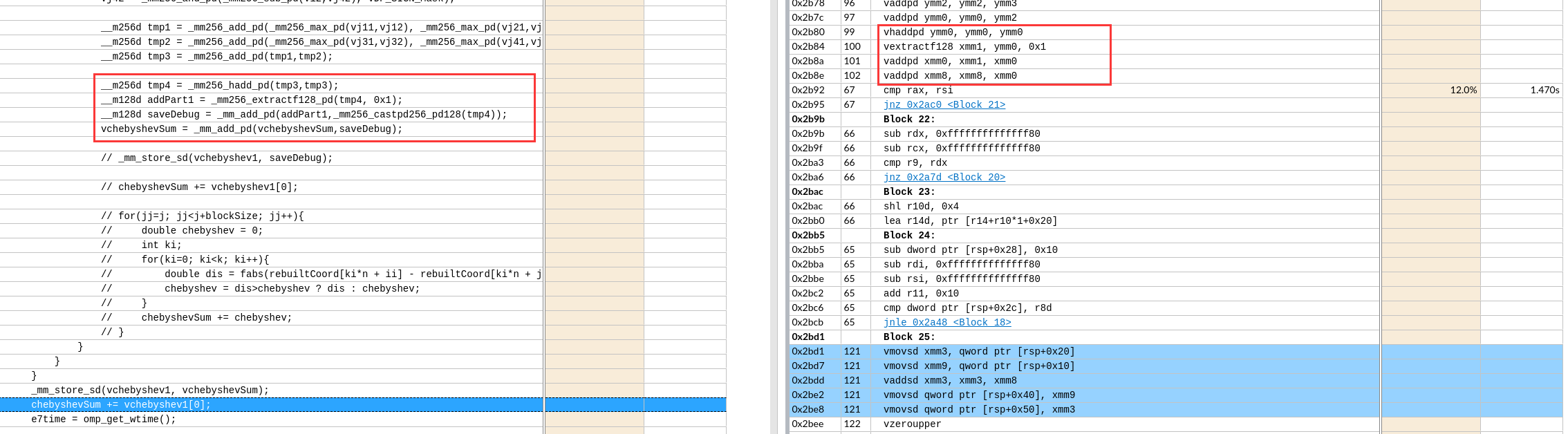
对于int还有这种实现
将横向归约全部提取到外面
并且将j的循环展开变成i的循环展开
手动向量化+手动循环展开?
支持的理由:打破了循环间的壁垒,编译器会识别出无效中间变量,在for的jump指令划出的基本块内指令会乱序执行,并通过寄存器重命名来形成最密集的计算访存流水。
不支持的理由:如果编译器为了形成某一指令的流水,占用了太多资源。导致需要缓存其他结果(比如,向量寄存器不够,反而需要额外的指令来写回,和产生延迟。
理想的平衡: 在不会达到资源瓶颈的情况下展开。
支持的分析例子
手动展开后,识别出来了连续的访存应该在一起进行,并自动调度。将+1的偏移编译器提前计算了。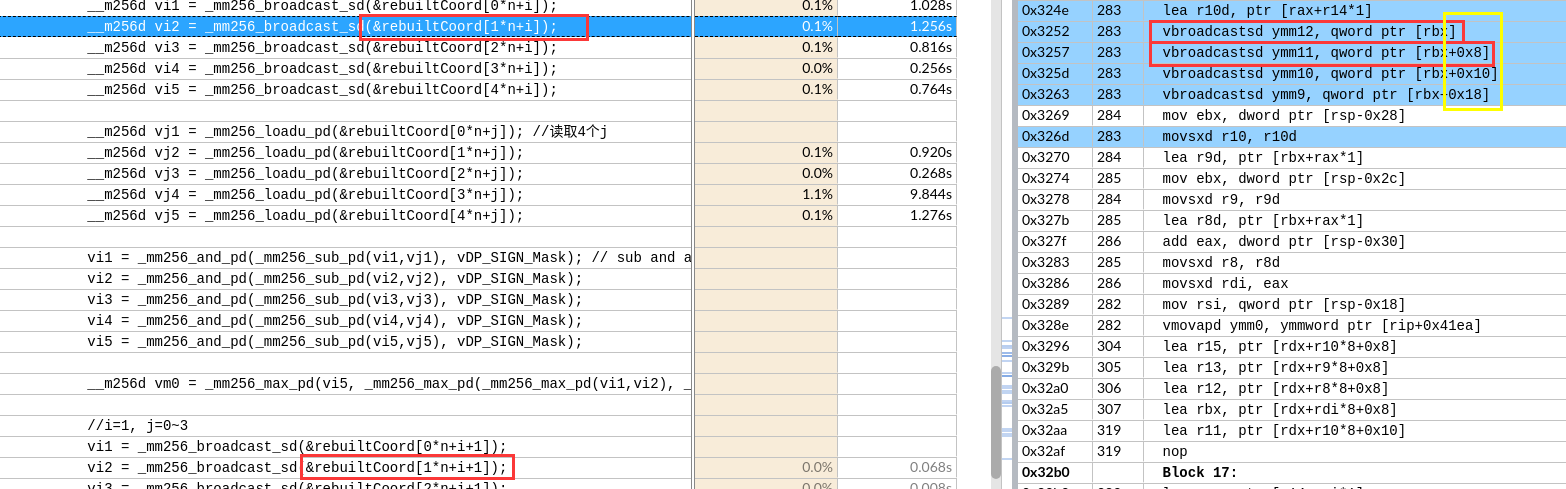
如果写成macro define,可以发现编译器自动重排了汇编。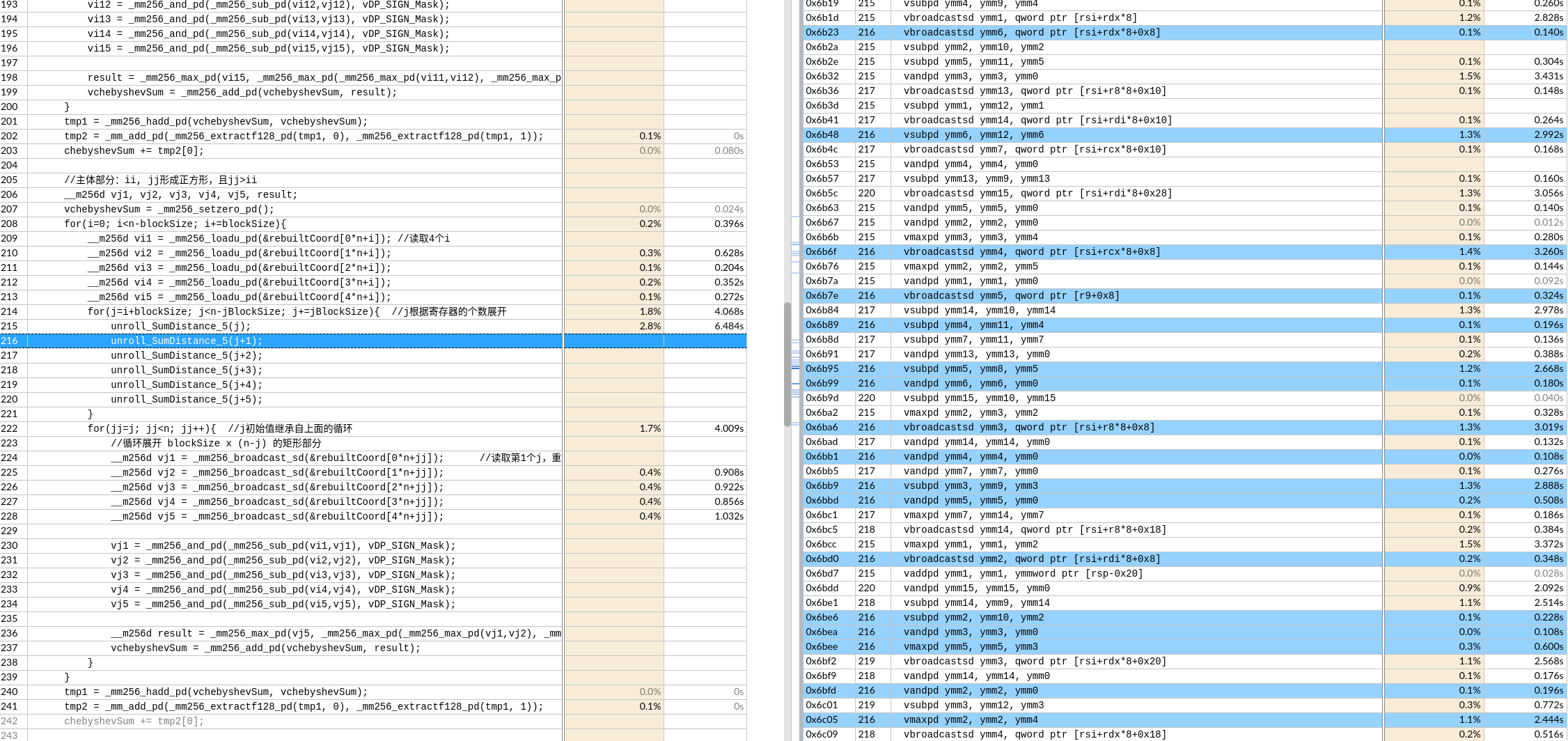
不支持的分析例子
avx2可以看出有写回的操作,把值从内存读出来压入栈中。
寄存器足够时没有这种问题
寻找理想的展开次数
由于不同代码对向量寄存器的使用次数不同,不同机器的向量寄存器个数和其他资源数不同。汇编也难以分析。在写好单次循环之后,最佳的展开次数需要手动测量。如下图,6次应该是在不会达到资源瓶颈的情况下展开来获得最大流水。
1 | for(j=beginJ; j<n-jBlockSize; j+=jBlockSize){ / |
由于基本块内乱序执行,代码的顺序也不重要。
加上寄存器重命名来形成流水的存在,寄存器名也不重要。当然数据依赖还是要正确。
对于两层循环的双层手动展开
思路: 外层多load数据到寄存器,但是运行的任何时候也不要超过寄存器数量的上限(特别注意在内层循环运行一遍到末尾时)。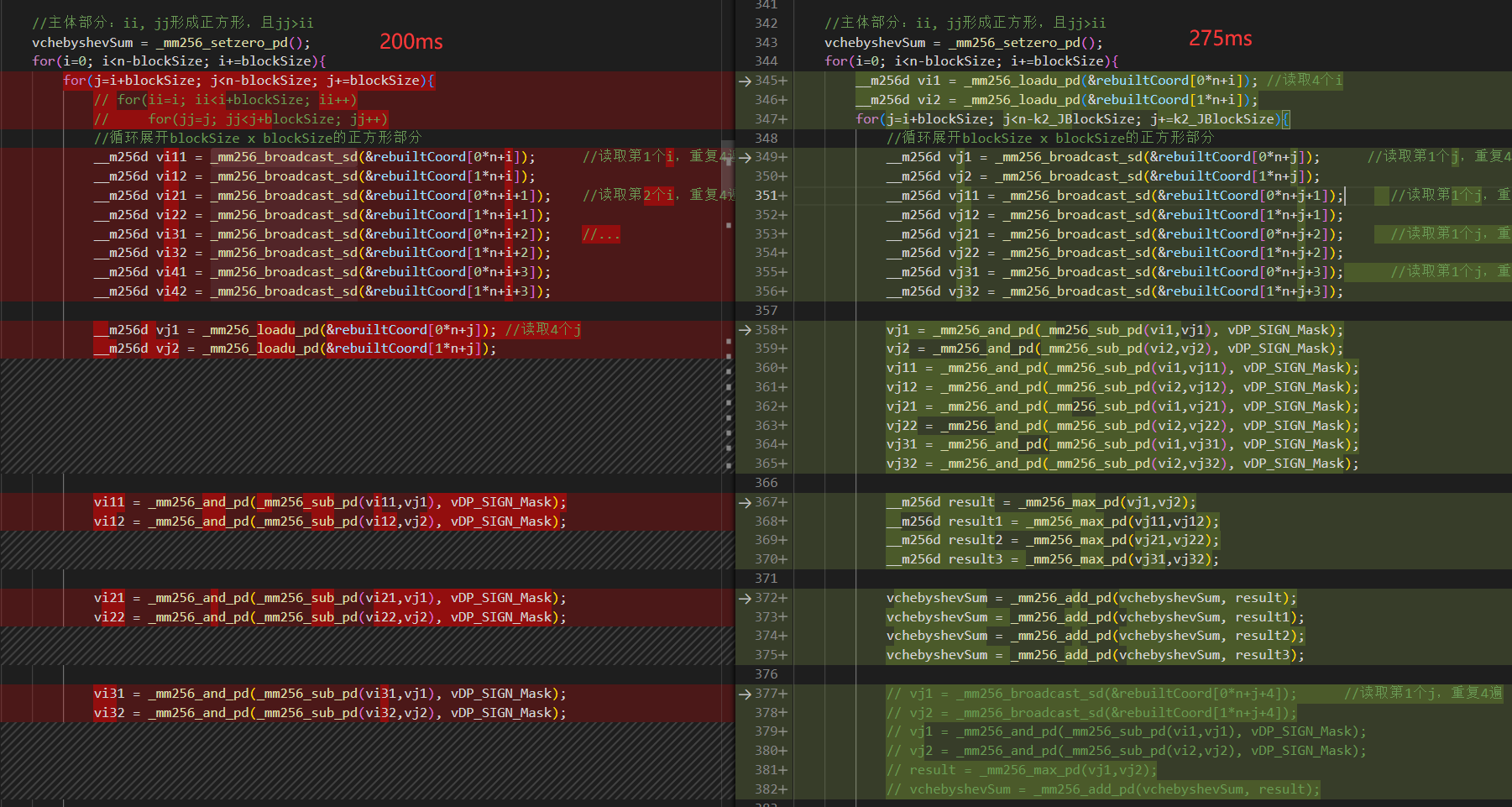
左图外层load了8个寄存器,但是右边只有2个。
特别注意在内层循环运行一遍到末尾时: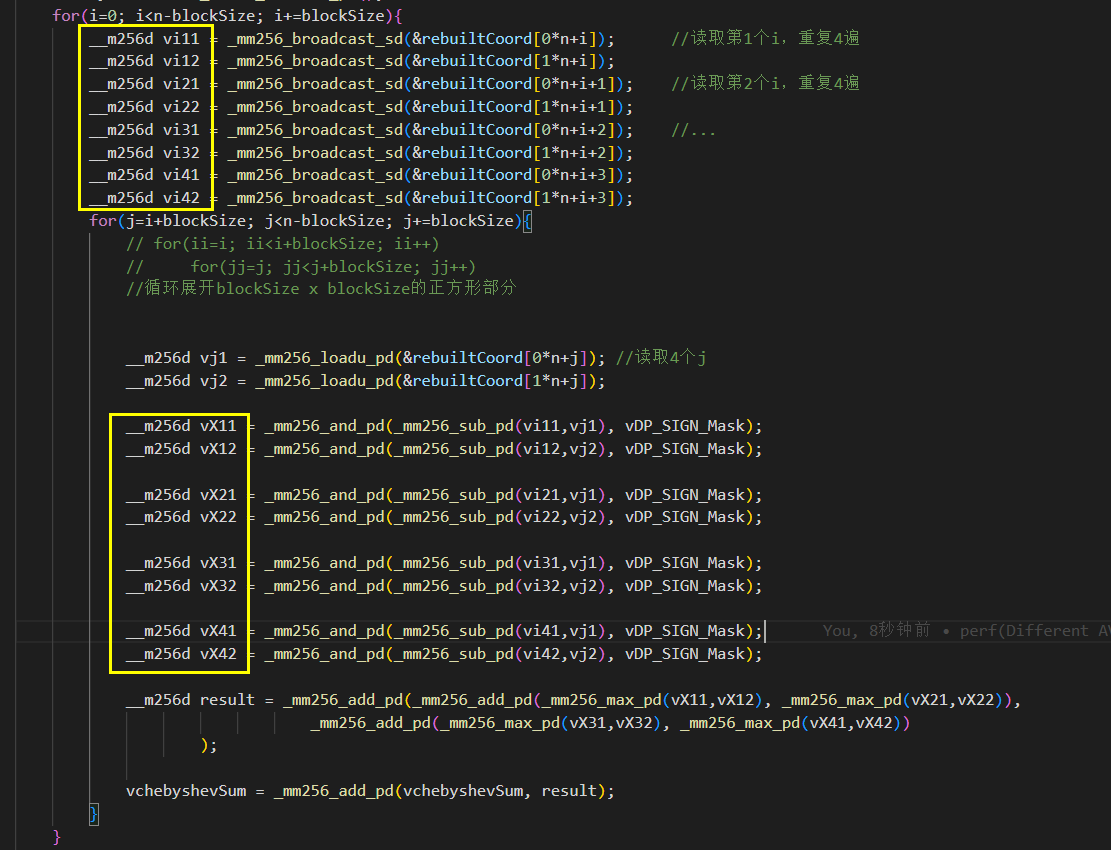
如图,黄框就有16个了。
注意load的速度也有区别
所以内层调用次数多,尽量用快的
1 | _mm256_loadu_ps >> _mm256_broadcast_ss > _mm256_set_epi16 |
1 | vsub vmax ps 0.02 Latency 4 |
|指令|精度|时间(吞吐延迟和实际依赖导致)|Latency|Throughput
|-|-|-|-|-|-|
|_mm256_loadu_ps /_mm256_broadcast_ss|||7|0.5
|vsub vmax | ps| 0.02 | 4|0.5
vand ||0.02| 1|0.33
vadd |ps |0.80 |4| 0.5
vhadd ||0.8| 7|2
vcvtps2pd || 2.00 | 7|1
vextractf128 || 0.50 | 3|1
向量化double变单精度没有提升
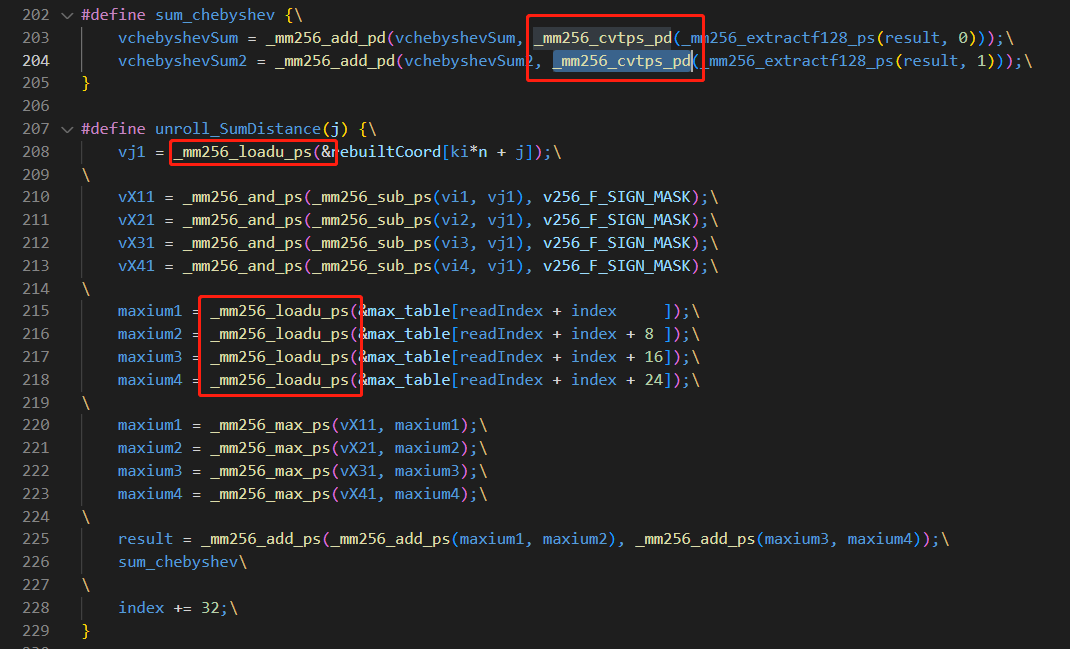
17条avx计算 5load 2cvt 2extract
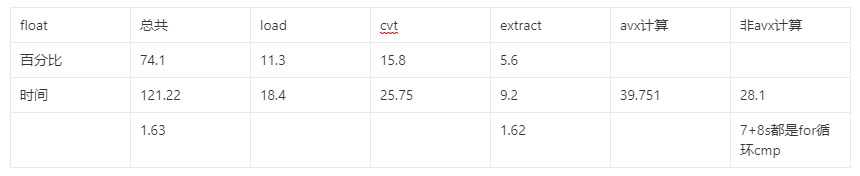
| 单位时间 | avx计算 | load | cvt | extract |
|---|---|---|---|---|
| 2.33 | 3.68 | 12.875 | 4.1 |
可见类型转换相当耗费时间,最好在循环外,精度不够,每几次循环做一次转换。
GCC编译器优化
-march=skylake-avx512是一条指令
-mavx2 是两条指令
1 | vmovupd xmm7, xmmword ptr [rdx+rsi*8] |
O3对于核心已经向量化的代码还有加速吗?
将IPCC初赛的代码去掉O3发现还是慢了10倍。
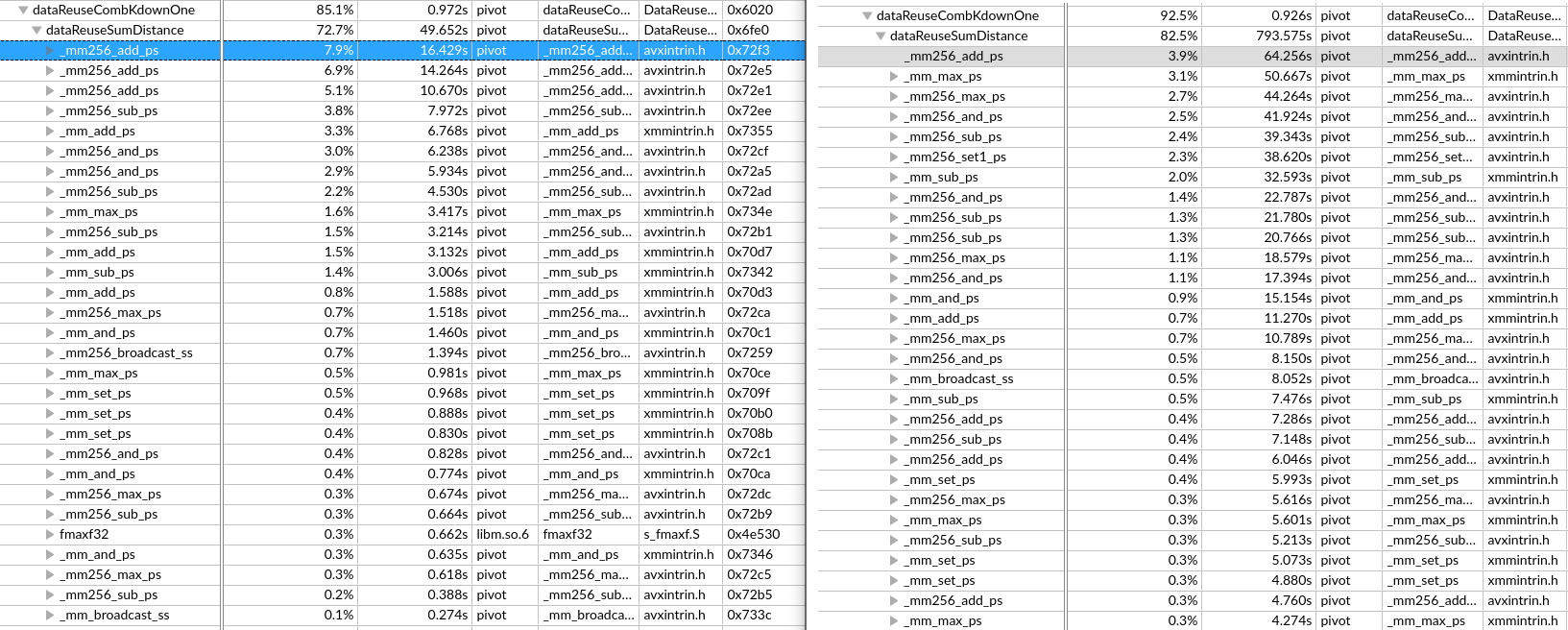
为什么连汇编函数调用也慢这么多呢?
这个不开O3的编译器所属有点弱智了,一条指令的两个操作数竟然在rbp的栈里存来存去的。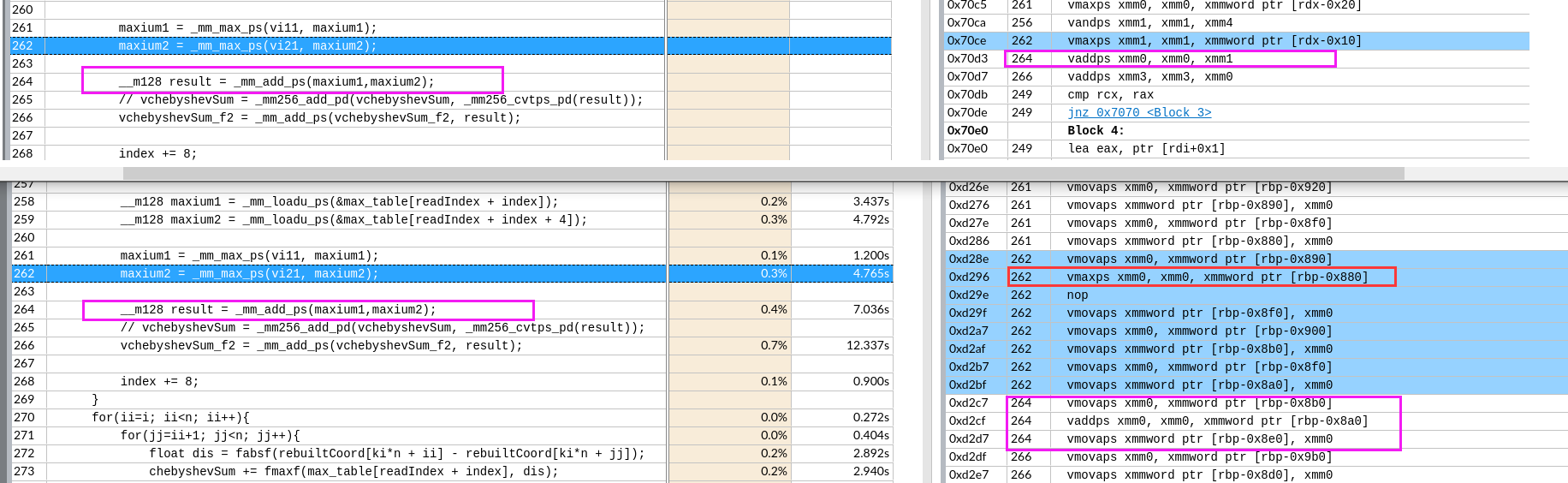
需要进一步的研究学习
暂无
遇到的问题
暂无